深度学习:Softmax回归
在前面,我们介绍了线性回归模型的原理及实现。线性回归适合于预测连续值,而对于分类问题的离散值则束手无策。因此引出了本文所要介绍的softmax回归模型,该模型是针对多分类问题所提出的。下面我们将从softmax回归模型的原理开始介绍,最后我们同样会基于PyTorch来实现基本的softmax模型。
1、分类问题
假设现在我们需要对图像进行分类,每次输入的数据是一个2x2的灰度图像。如果用一个标量来表示每个像素值,则每个图像可以对应x1,x2,x3,x4x_1,x_2,x_3,x_4x1,x2,x3,x4四个特征,因此可以用一个特征向量(x1,x2,x3,x4)(x_1,x_2,x_3,x_4)(x1,x2,x3,x4)来表示图像。
另外,假设每个图像属于类别“猫”,“鸡”和“狗”其中一个,那么我们可以使用独热编码(one-hot encoding)来表示分类数据。例如标签yyy是一个三维向量,其中[1,0,0]对应“猫”类别、[0,1,0]对应“鸡”类别、[0,0,1]对应“狗”类别:
y∈{(1,0,0),(0,1,0),(0,0,1)}.(1)y\in\{(1,0,0),(0,1,0),(0,0,1)\}.\tag{1} y∈{(1,0,0),(0,1,0),(0,0,1)}.(1)
2、模型网络架构
在分类问题中,我们需要估计一张图像对于所有类别的条件概率,每一个类别对应则一个输出,则该模型是一个具有n个输入和m个输出的回归模型(n是图像的特征向量长度,m是类别数量)。
在上面的例子中,我们有4个输入特征和3个可能的输出类别,因此我们需要12个标量来表示权重(w),3个标量来表示偏置(b),计算每个类别未规范化的条件概率:
o1=x1w11+x2w12+x3w13+x4w14+b1o2=x1w21+x2w22+x3w23+x4w24+b2o3=x1w31+x2w32+x3w33+x4w34+b3.(2)o_1=x_1w_{11}+x_2w_{12}+x_3w_{13}+x_4w_{14}+b_1 \\ o_2=x_1w_{21}+x_2w_{22}+x_3w_{23}+x_4w_{24}+b_2 \\ o_3=x_1w_{31}+x_2w_{32}+x_3w_{33}+x_4w_{34}+b_3 .\tag{2} o1=x1w11+x2w12+x3w13+x4w14+b1o2=x1w21+x2w22+x3w23+x4w24+b2o3=x1w31+x2w32+x3w33+x4w34+b3.(2)
(2)中的o1,o2,o3o_1,o_2,o_3o1,o2,o3就是图像对于所有类别的条件概率,只不过此时还没有对概率进行规范化,还不能符合我们的要求(所有类别的条件概率之和为1)。
我们用矩阵形式来表示 x,W,b,ox,W,b,ox,W,b,o:
x=[x1x2x3x4]W=[w11w12w13w14w21w22w23w24w31w32w33w34]b=[b1b2b3]o=[o1o2o3].(3)x=\begin{bmatrix} x_1 & x_2 & x_3 & x_4 \end{bmatrix}\\\ \\W=\begin{bmatrix} w_{11} & w_{12} & w_{13} & w_{14}\\ w_{21} & w_{22} & w_{23} & w_{24}\\ w_{31} & w_{32} & w_{33} & w_{34}\\ \end{bmatrix} \,\,\,\,\,\,b=\begin{bmatrix} b_1 & b_2 & b_3 \end{bmatrix}\\\ \\o=\begin{bmatrix} o_1 & o_2 & o_3 \end{bmatrix} .\tag{3} x=[x1x2x3x4] W=⎣⎡w11w21w31w12w22w32w13w23w33w14w24w34⎦⎤b=[b1b2b3] o=[o1o2o3].(3)
则(2)可以表示为:
o=xWT+b.(4)o=xW^T+b.\tag{4} o=xWT+b.(4)
我们还可以用神经网络图(图1)来表示softmax回归模型。与线性回归一样,softmax回归也是单层的神经网络。由于每个输出o1,o2,o3o_1,o_2,o_3o1,o2,o3都依赖于所有的输入x1,x2,x3,x4x_1,x_2,x_3,x_4x1,x2,x3,x4,因此softmax回归的输出层还是一个全连接层。
 图1:softmax回归的神经网络图
图1:softmax回归的神经网络图
3、softmax运算
在上面,我们由权重与输⼊特征进⾏矩阵-向量乘法再加上偏置b得到的输出o1,o2,o3o_1,o_2,o_3o1,o2,o3。为了获取最终的预测结果,我们使用argmaxjoj\arg\underset{j}{\max}o_jargjmaxoj来选择最大的输出ojo_joj作为预测概率。然而,直接将线性层的输出视为概率时存在⼀些问题:一方面,我们没有限制这些输出值的总和为1。另⼀方面,根据输入的不同,输出值甚至可能为负值。
为了解决上述问题,社会科学家邓肯·卢斯于1959年在选择模型(choice model)的理论基础上发明了softmax函数。 softmax函数将未规范化的预测值变换为非负并且总和为1的概率值,同时保证模型可导。我们⾸先对每个未规范化的预测求幂,这样可以确保输出非负。为了确保最终输出的总和为1,我们再对每个求幂后的结果除以它们的总和。如下式:
y^=softmax(o)其中yj^=exp(oj)∑k=1qexp(ok).(5)\hat{y}=softmax(o)\,\,\,\,\,\,其中\,\,\hat{y_j}=\frac{exp(o_j)}{\sum_{k=1}^{q}exp(o_k)}.\tag{5} y^=softmax(o)其中yj^=∑k=1qexp(ok)exp(oj).(5)
这⾥,对于所有的jjj总有0≤yj^≤10 ≤ \hat{y_j} ≤ 10≤yj^≤1。因此,$\hat{y_j} 可以视为⼀个正确的概率分布。softmax运算并不会改变未规范化的预测可以视为⼀个正确的概率分布。softmax运算并不会改变未规范化的预测可以视为⼀个正确的概率分布。softmax运算并不会改变未规范化的预测o$之间大小的顺序,只会将每个类别的预测值转换概率值。因此,在预测过程中,我们可以用下式来选择输入图像最有可能的类别:
argmaxjyj^=argmaxjoj.(6)\arg\underset{j}{\max}\hat{y_j}=\arg\underset{j}{\max}o_j.\tag{6} argjmaxyj^=argjmaxoj.(6)
尽管softmax是⼀个⾮线性函数,但softmax回归的输出仍然由输⼊特征的仿射变换决定。因此,softmax回归是⼀个线性模型(linear model)。
4、小批量样本的矢量化
为了提⾼计算效率并且充分利用GPU,我们通常会针对小批量数据执行矢量计算。假设我们读取了⼀个批量的样本XXX,其中特征维度(输⼊数量)为d,批量大小为n。此外,假设我们在输出中有q个类别。那么小批量样本的特征为X∈Rn×dX\in\R^{n×d}X∈Rn×d,权重为W∈Rd×qW\in\R^{d×q}W∈Rd×q,偏置为b∈R1×qb\in\R^{1×q}b∈R1×q。softmax回归的小批量样本的⽮量计算表达式为:
O=XWT+bY^=softmax(O).(7)O=XW^T+b\\ \hat{Y}=softmax(O).\tag{7} O=XWT+bY^=softmax(O).(7)
5、损失函数
接下来,我们需要一个损失函数来评估预测的效果。由于在softmax回归中,我们只关心正确类别的预测概率,而不需要像线性回归那么精确地预测数值,因此我们使用交叉熵损失函数来评估模型的预测效果:
l(y,y^)=−∑j=1qyjlogyj^.(8)l(y,\hat{y})=-\sum_{j=1}^{q}{y_j}log\,{\hat{y_j}}.\tag{8} l(y,y^)=−j=1∑qyjlogyj^.(8)
又因为正确标签向量yyy中只有一个标量为1,其余全为0,因此(8)可化简为:
l(y,y^)=−logyj^.(9)l(y,\hat{y})=-log\,\hat{y_j}.\tag{9} l(y,y^)=−logyj^.(9)
为了使(8)更好做偏导计算,我们将(5)代入(8)中:
l(y,y^)=−∑j=1qyjlogexp(oj)∑k=1qexp(ok)=∑j=1qyjlog∑k=1qexp(ok)−∑j=1qyjoj=log∑k=1qexp(ok)−∑j=1qyjoj.(10)l(y,\hat{y})=-\sum_{j=1}^{q}y_jlog\,\frac{exp(o_j)}{\sum_{k=1}^{q}exp(o_k)}\\ \qquad\qquad\quad=\sum_{j=1}^{q}y_jlog\,\sum_{k=1}^qexp(o_k)-\sum_{j=1}^qy_jo_j\\ \qquad\quad=log\sum_{k=1}^qexp(o_k)-\sum_{j=1}^qy_jo_j.\tag{10} l(y,y^)=−j=1∑qyjlog∑k=1qexp(ok)exp(oj)=j=1∑qyjlogk=1∑qexp(ok)−j=1∑qyjoj=logk=1∑qexp(ok)−j=1∑qyjoj.(10)
6、参数更新
我们对交叉熵损失函数(10)求导,获取l(y,y^)l(y,\hat{y})l(y,y^)关于ojo_joj的梯度:
∂ojl(y,y^)=exp(oj)∑k=1qexp(ok)−yj=softmax(o)j−yj.(11)\partial_{o_j}\,l(y,\hat{y})=\frac{exp(o_j)}{\sum_{k=1}^{q}exp(o_k)}-y_j\\ \qquad\qquad=softmax(o)_j-y_j.\tag{11} ∂ojl(y,y^)=∑k=1qexp(ok)exp(oj)−yj=softmax(o)j−yj.(11)
然后采用梯度下降法,softmax回归的训练过程为:采用正态分布来初始化权重WWW,然后通过下式进行迭代更新:
Wt+1←Wt−α[1N∑n=1N(softmax(o)j−yj)].(12)W_{t+1}←W_t-\alpha[\frac{1}{N}\sum_{n=1}^{N}(softmax(o)_j-y_j)].\tag{12} Wt+1←Wt−α[N1n=1∑N(softmax(o)j−yj)].(12)
7、实现softmax回归模型
7.1、读取数据集
在本节中,我们用softmax回归来实现图像识别。在此之前,我们先下载Fashion-MNIST数据集。
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2ld2l.use_svg_display()
通过框架中的内置函数将Fashion-MNIST数据集下载并读取到内存中。
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式,
# 并除以255使得所有像素的数值均在0到1之间
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(root="/data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="/data", train=False, transform=trans, download=True)
Fashion-MNIST由10个类别的图像组成, 每个类别由训练数据集(train dataset)中的6000张图像 和测试数据集(test dataset)中的1000张图像组成。 因此,训练集和测试集分别包含60000和10000张图像。 测试数据集不会用于训练,只用于评估模型性能。
len(mnist_train), len(mnist_test)

每个输入图像的高度和宽度均为28像素。 数据集由灰度图像组成,其通道数为1。
mnist_train[0][0].shape
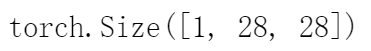
Fashion-MNIST中包含的10个类别,分别为t-shirt(T恤)、trouser(裤子)、pullover(套衫)、dress(连衣裙)、coat(外套)、sandal(凉鞋)、shirt(衬衫)、sneaker(运动鞋)、bag(包)和ankle boot(短靴)。 以下函数用于在数字标签索引及其文本名称之间进行转换。
def get_fashion_mnist_labels(labels): #@save"""返回Fashion-MNIST数据集的文本标签"""text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat','sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']return [text_labels[int(i)] for i in labels]
创建一个函数来可视化这些样本。
def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5): #@save"""绘制图像列表"""figsize = (num_cols * scale, num_rows * scale)_, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize)axes = axes.flatten()for i, (ax, img) in enumerate(zip(axes, imgs)):if torch.is_tensor(img):# 图片张量ax.imshow(img.numpy())else:# PIL图片ax.imshow(img)ax.axes.get_xaxis().set_visible(False)ax.axes.get_yaxis().set_visible(False)if titles:ax.set_title(titles[i])return axes
我们将一个小批量的数据集可视化出来看看。
X, y = next(iter(data.DataLoader(mnist_train, batch_size=15)))
show_images(X.reshape(15, 28, 28), 3, 5, titles=get_fashion_mnist_labels(y));

为了使我们在读取训练集和测试集时更容易,我们使用内置的数据迭代器,而不是从零开始创建。 回顾一下,在每次迭代中,数据加载器每次都会读取一小批量数据,大小为batch_size。 通过内置数据迭代器,我们可以随机打乱了所有样本,从而无偏见地读取小批量,并通过多线程来读取数据。
batch_size = 256def get_dataloader_workers(): #@save"""使用4个进程来读取数据"""return 4train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=get_dataloader_workers())
读取一个小批量数据集所需的时间:
timer = d2l.Timer()
for X, y in train_iter:continue
f'{timer.stop():.2f} sec'

为了方便使用,我们将上述的代码整合为一个函数。
# 整合上述所有组件
def load_data_fashion_mnist(batch_size, resize=None): #@save"""下载Fashion-MNIST数据集,然后将其加载到内存中"""trans = [transforms.ToTensor()]if resize:trans.insert(0, transforms.Resize(resize))trans = transforms.Compose(trans)mnist_train = torchvision.datasets.FashionMNIST(root="/data", train=True, transform=trans, download=True)mnist_test = torchvision.datasets.FashionMNIST(root="/data", train=False, transform=trans, download=True)return (data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=get_dataloader_workers()),data.DataLoader(mnist_test, batch_size, shuffle=False,num_workers=get_dataloader_workers()))
随后,我们使用load_data_fashion_mnist来读取数据集,并通过resize参数调整图像的尺寸。
train_iter, test_iter = load_data_fashion_mnist(32, resize=28)
for X, y in train_iter:print(X.shape, X.dtype, y.shape, y.dtype)break
for X,y in test_iter:print(X.shape, X.dtype, y.shape, y.dtype)break
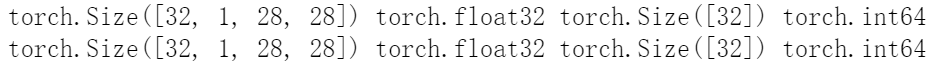
7.2、从零实现softmax回归
本节我们将使用刚刚在6.1节中引入的Fashion-MNIST数据集, 并设置数据迭代器的批量大小为256。
import torch
from IPython import display
from d2l import torch as d2lbatch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
7.2.1、初始化参数
和之前线性回归的例子一样,这里的每个样本都将用固定长度的向量表示。 原始数据集中的每个样本都是28×28的图像。 在本节中,我们将展平每个图像,把它们看作长度为784的向量。又因为我们的数据集有10个类别,所以网络输出维度为10。 因此,权重将构成一个784×10的矩阵, 偏置将构成一个1×10的行向量。 与线性回归一样,我们将使用正态分布初始化我们的权重W,偏置初始化为0。
num_inputs = 784
num_outputs = 10W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)
7.2.2、定义softmax激活函数
回想一下,实现softmax由三个步骤组成:
- 对每个项求幂(使用
exp); - 对每一行求和(小批量中每个样本是一行);
- 将每项除以所属行的和,确保结果的和为1。
softmax的公式定义:

实现如下:
def softmax(X):X_exp = torch.exp(X)partition = X_exp.sum(1, keepdim=True)return X_exp / partition # 这里应用了广播机制
我们来验证一下softmax激活函数的效果:
X = torch.normal(0, 1, (2, 5))
X_prob = softmax(X)
X, X_prob, X_prob.sum(1)

7.2.3、定义模型
定义softmax操作后,我们可以实现softmax回归模型。 下面的代码定义了输入如何通过网络映射到输出。 注意,将数据传递到模型之前,我们使用reshape函数将每张原始图像展平为向量。
def net(X):return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)
7.2.4、定义损失函数
在softmax回归中,我们只关心正确类别预测的概率,因此我们需要将正确类别的预测概率提取出来参与损失函数计算。
为了加快计算速度,我们使用y作为y_hat中概率的索引来提取正确类别的预测概率,而不会考虑使用for循环这种低效的方式。
y = torch.tensor([0, 2]) # 真实的标签
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]]) # 预测的概率
y_hat[[0, 1], y]
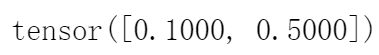
因此我们可以很便捷地实现交叉熵损失函数:
def cross_entropy(y_hat, y):return - torch.log(y_hat[range(len(y_hat)), y])cross_entropy(y_hat, y)
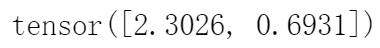
7.2.5、评估分类精度
在实际预测时,我们必须输出最终的预测类别。为了计算分类的精度,首先,如果y_hat是矩阵,那么假定第二个维度存储每个类的预测分数。 我们使用argmax获得每行中最大元素的索引来获得预测类别。 然后我们将预测类别与真实y元素进行比较。 由于等式运算符“==”对数据类型很敏感, 因此我们将y_hat的数据类型转换为与y的数据类型一致。 结果是一个包含0(错)和1(对)的张量。 最后,我们求和会得到正确预测的数量。
def accuracy(y_hat, y): #@save"""计算预测正确的数量"""if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:y_hat = y_hat.argmax(axis=1)cmp = y_hat.type(y.dtype) == yreturn float(cmp.type(y.dtype).sum())
评估一下分类的精度:
accuracy(y_hat, y) / len(y)
同样,对于任意数据迭代器data_iter可访问的数据集, 我们可以评估在任意模型net的精度。
def evaluate_accuracy(net, data_iter): #@save"""计算在指定数据集上模型的精度"""if isinstance(net, torch.nn.Module):net.eval() # 将模型设置为评估模式metric = Accumulator(2) # 正确预测数、预测总数with torch.no_grad():for X, y in data_iter:metric.add(accuracy(net(X), y), y.numel())return metric[0] / metric[1]
这里定义一个实用程序类Accumulator,用于对多个变量进行累加。 在上面的evaluate_accuracy函数中, 我们在Accumulator实例中创建了2个变量, 分别用于存储正确预测的数量和预测的总数量。 当我们遍历数据集时,两者都将随着时间的推移而累加。
class Accumulator: #@save"""在n个变量上累加"""def __init__(self, n):self.data = [0.0] * ndef add(self, *args):self.data = [a + float(b) for a, b in zip(self.data, args)]def reset(self):self.data = [0.0] * len(self.data)def __getitem__(self, idx):return self.data[idx]
7.2.6、训练模型
首先,我们定义一个函数来训练一个迭代周期。 请注意,updater是更新模型参数的常用函数,它接受批量大小作为参数。 它可以是d2l.sgd函数,也可以是框架的内置优化函数。
def train_epoch_ch3(net, train_iter, loss, updater): #@save"""训练模型一个迭代周期"""# 将模型设置为训练模式if isinstance(net, torch.nn.Module):net.train()# 训练损失总和、训练准确度总和、样本数metric = Accumulator(3)for X, y in train_iter:# 计算梯度并更新参数y_hat = net(X)l = loss(y_hat, y)if isinstance(updater, torch.optim.Optimizer):# 使用PyTorch内置的优化器和损失函数updater.zero_grad()l.mean().backward()updater.step()else:# 使用定制的优化器和损失函数l.sum().backward()updater(X.shape[0])metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())# 返回训练损失和训练精度return metric[0] / metric[2], metric[1] / metric[2]
然后我们再定义一个Animator函数来可视化训练的过程:
class Animator: #@save"""在动画中绘制数据"""def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,ylim=None, xscale='linear', yscale='linear',fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,figsize=(3.5, 2.5)):# 增量地绘制多条线if legend is None:legend = []d2l.use_svg_display()self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)if nrows * ncols == 1:self.axes = [self.axes, ]# 使用lambda函数捕获参数self.config_axes = lambda: d2l.set_axes(self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)self.X, self.Y, self.fmts = None, None, fmtsdef add(self, x, y):# 向图表中添加多个数据点if not hasattr(y, "__len__"):y = [y]n = len(y)if not hasattr(x, "__len__"):x = [x] * nif not self.X:self.X = [[] for _ in range(n)]if not self.Y:self.Y = [[] for _ in range(n)]for i, (a, b) in enumerate(zip(x, y)):if a is not None and b is not None:self.X[i].append(a)self.Y[i].append(b)self.axes[0].cla()for x, y, fmt in zip(self.X, self.Y, self.fmts):self.axes[0].plot(x, y, fmt)self.config_axes()display.display(self.fig)display.clear_output(wait=True)
接下来我们实现一个训练函数, 它会在train_iter访问到的训练数据集上训练一个模型net。 该训练函数将会运行多个迭代周期(由num_epochs指定)。 在每个迭代周期结束时,利用test_iter访问到的测试数据集对模型进行评估。 我们将利用Animator类来可视化训练进度。
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save"""训练模型"""animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],legend=['train loss', 'train acc', 'test acc'])for epoch in range(num_epochs):train_metrics = train_epoch_ch3(net, train_iter, loss, updater)test_acc = evaluate_accuracy(net, test_iter)animator.add(epoch + 1, train_metrics + (test_acc,))train_loss, train_acc = train_metricsassert train_loss < 0.5, train_lossassert train_acc <= 1 and train_acc > 0.7, train_accassert test_acc <= 1 and test_acc > 0.7, test_acc
我们使用之前线性回归中所定义的小批量随机梯度下降来优化参数。其中,设置学习率lr为0.1。
lr = 0.1 # 学习率def updater(batch_size):return d2l.sgd([W, b], lr, batch_size)
现在,我们训练模型10个迭代周期。 请注意,迭代周期(num_epochs)和学习率(lr)都是可调节的超参数。 通过更改它们的值,我们可以提高模型的分类精度。
num_epochs = 10
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater)

7.2.7、预测
现在训练已经完成,我们的模型已经准备好对图像进行分类预测。 给定一系列图像,我们将比较它们的实际标签(文本输出的第一行)和模型预测(文本输出的第二行)。
def predict_ch3(net, test_iter, n=6): #@save"""预测标签"""for X, y in test_iter:breaktrues = d2l.get_fashion_mnist_labels(y)preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))titles = [true +'\n' + pred for true, pred in zip(trues, preds)]d2l.show_images(X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])predict_ch3(net, test_iter, 5)

8、总结
在本文中,我们讨论了softmax回归模型的基本原理和实现方法。softmax回归适合于离散的分类,线性回归适合于预测连续的数值。
9、参考资料
1、动手学深度学习 Release2.0.0-beta0
2、softmax回归原理及损失函数
3、神经网络与深度学习_邱锡鹏
4、深度学习:线性回归模型
深度学习:Softmax回归相关推荐
- 深度学习-softmax回归
softmax regression 1- softmax 基本概念 1-1 极大似然估计 2- Fashion-MNIST图像分类数据集 2-1 下载数据集 2-2 可视化 3- softmax回归 ...
- 跟李沐学深度学习-softmax回归
softmax回归 分类和回归的区别 无校验比例 校验比例 交叉熵 常见损失函数 均方误差 L2 loss 绝对值损失L1 loss 鲁棒损失 图像分类数据集 分类和回归的区别 回归:估计一个连续值 ...
- 动手学深度学习——softmax回归之OneHot、softmax与交叉熵
目录 一.从回归到多类分类 1. 回归估计一个连续值 2. 分类预测一个离散类别 二.独热编码OneHot 三.校验比例--激活函数softmax 四.损失函数--交叉熵 五.总结 回归可以用于预测多 ...
- 深度学习——Softmax回归+损失函数(笔记)
一.Softmax回归 1.Softmax回归,名字是回归,其实是一个分类问题. 2.回归和分类的区别是什么? ①回归估计的是一个连续值:比如预测二手房卖出的价格 Ⅰ回归是在自然区间R单连续值的输出 ...
- 深度学习pytorch--softmax回归(三)
softmax回归的简洁实现 获取和读取数据 定义和初始化模型 softmax和交叉熵损失函数 定义优化算法 模型评价 训练模型 小结 完整代码 前两篇链接: 深度学习pytorch–softmax回 ...
- 深度学习pytorch--softmax回归(二)
softmax回归的从零开始实现 实验前思考 获取和读取数据 获取数据集 查看数据集 查看下载后的.pt文件 查看mnist_train和mnist_test 读取数据集 查看数据迭代器内容 初始化模 ...
- 深度学习pytorch--softmax回归(一)
softmax回归 前几节介绍的线性回归模型适用于输出为连续值的情景.在另一类情景中,模型输出可以是一个像图像类别这样的离散值.对于这样的离散值预测问题,我们可以使用诸如softmax回归在内的分类模 ...
- 深度学习softmax与多层感知机分类模型
softmax 简单的分类问题 一个简单的图像分类问题,输入图像的高和宽均为2像素,色彩为灰度.图像中的4像素分别记为x1,x2,x3,x4x_1,x_2,x_3,x_4x1,x2,x3,x4 ...
- 电气论文实现:深度学习分位数回归实现电力负荷区间预测
个人电气博文目录链接:学好电气全靠它,个人电气博文目录(持续更新中-) 之前写过一版电力负荷区间预测:电气论文:负荷区间预测(机器学习简单实现) 这版区间负荷预测思维和上一版不一样. 核心代码见图(无 ...
- 深度学习利用回归算法进行数据预测
机床加工过程中,因热变形产生的热误差占机床加工总误差的40%-70%.热误差值补偿是解决热误差的主流技术,如何将神经网络建模与热误差值预测结合起来,是今天介绍的重点. 本项目研究对象为立式数控加工中心 ...
最新文章
- VMWare虚拟机网络连接
- Hyper-V下虚拟机无法启动的故障排除
- 《系统集成项目管理工程师》必背100个知识点-10项目可行性研究阶段
- 爬虫--BeautifulSoup使用
- Hessian局部线性嵌入算法(HLLE)——matlab实现
- 工程之道,解读业界最佳的深度学习推理性能优化方案
- (47)Verilog HDL UART接收设计
- python基础语法训练
- SpringBoot2集成Quartz配置独立数据源
- c语言词法分析例子,实验一词法分析器实验报告示例
- 音乐付费的大门为谁而开?
- android button 图片与文字一起
- 神经网络 语音识别,神经网络语音合成
- CSS3选择器(选择符)
- 安装busybox步骤
- des算法s盒java实现_DES算法详解
- 2020年8月20计算机大赛,NOI2020于8月17日正式开幕!今年哪些竞赛选手被保送清北计算机专业?...
- 百度地图:用于打印的地图展示
- 32 php 手摇泵_手摇泵基本原理及使用教程
- 利用java进行制作淘宝卖家买家采集软件工具