MyBatis学习笔记-源码分析篇
引言
SQL 语句的执行涉及多个组件,其中比较重要的是 Executor、 StatementHandler、 ParameterHandler 和 ResultSetHandler。 Executor 主要负责维护一级缓存和二级缓存, 并提供事务管理的相关操作,它会将数据库相关操作委托给 StatementHandler 完成。 StatementHandler 首先通过 ParameterHandler 完成 SQL 语句的实参绑定,然后通过 java.sql.Statement 对象执行 SQL 语句并得到结果集,最后通过 ResultSetHandler 完成结果集的映射,得到结果对象并返回。
- 方法代理:其目的是简化对MyBatis使用,本身不会影响执行逻辑,底层使用动态代理实现。
- 会话:提供增删改查API,其本身不作任何业务逻辑的处理,所有处理都交给执行器。这是一个典型的门面模式设计。另外他不是线程安全的所以不能跨线程调用。
- 执行器:核心作用是处理SQL请求、事物管理、维护缓存以及批处理等。
- JDBC处理器:他的作用就是用于通过JDBC具体处理SQL和参数的。在会话中每调用一次CRUD,JDBC处理器就会生成一个实例与之对应(命中缓存除外)。
在一次SQL会话过程当中四个组件的实例比值分别是 1:1:1:n 。
MyBatis是一个基于JDBC的数据库访问组件。首先回顾一下JDBC执行流程:
![]()
/** 第一步: 获取连接 */
Connection connection = DriverManager.getConnection(JDBC.URL, JDBC.USERNAME, JDBC.PASSWORD);
/** 第二步: 预编译SQL */
PreparedStatement statement = connection.prepareStatement("select * from users ");
/** 第三步: 执行查询 */
ResultSet resultSet = statement.executeQuery();
/** 第四步: 读取结果 */
readResultSet(resultSet);
在回顾了JDBC的执行流程之后,接下来我们来看看在MyBatis中是如何使用的吧!
会话
MapperProxy
在单独使用 MyBatis 进行数据库操作时,我们通常都会先调用 SqlSession 接口的 getMapper 方法为我们的 Mapper 接口生成实现类。然后就可以通过 Mapper 进行数据库操作。比如像下面这样:
ArticleMapper articleMapper = session.getMapper(ArticleMapper.class);
Article article = articleMapper.findOne(1);
如果大家对 MyBatis 较为理解,会知道 SqlSession 是通过 JDK 动态代理的方式为接口生成代理对象的。在调用接口方法时,方法调用会被代理逻辑拦截。在代理逻辑中可根据方法名及方法归属接口获取到当前方法对应的 SQL 以及其他一些信息,拿到这些信息即可进行数据库操作。
上面是一个简版的 SQL 执行过程,省略了很多细节。下面我们先按照这个简版的流程进行分析,首先我们来看一下 Mapper 接口的代理对象创建过程。
为 Mapper 接口创建代理对象
本节,我们从 DefaultSqlSession 的 getMapper 方法开始看起,如下:
// -☆- DefaultSqlSession
public <T> T getMapper(Class<T> type) {return configuration.<T>getMapper(type, this);
}// -☆- Configuration
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {return mapperRegistry.getMapper(type, sqlSession);
}// -☆- MapperRegistry
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {// 从 knownMappers 中获取与 type 对应的 MapperProxyFactoryfinal MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);if (mapperProxyFactory == null) {throw new BindingException("Type " + type + " is not known to the MapperRegistry.");}try {// 创建代理对象return mapperProxyFactory.newInstance(sqlSession);} catch (Exception e) {throw new BindingException("Error getting mapper instance. Cause: " + e, e);}
}
如上,经过连续的调用,Mapper 接口代理对象的创建逻辑初现端倪。如果没看过我前面的分析文章,大家可能不知道 knownMappers 集合中的元素是何时存入的。这里再说一遍吧,MyBatis 在解析配置文件的 <mappers> 节点的过程中,会调用 MapperRegistry 的 addMapper 方法将 Class 到 MapperProxyFactory 对象的映射关系存入到 knownMappers。具体的代码就不分析了,大家可以阅读我之前写的文章,或者自行分析相关的代码。
在获取到 MapperProxyFactory 对象后,即可调用工厂方法为 Mapper 接口生成代理对象了。相关逻辑如下:
// -☆- MapperProxyFactory
public T newInstance(SqlSession sqlSession) {/** 创建 MapperProxy 对象,MapperProxy 实现了 * InvocationHandler 接口,代理逻辑封装在此类中*/final MapperProxy<T> mapperProxy = new MapperProxy<T>(sqlSession, mapperInterface, methodCache);return newInstance(mapperProxy);
}protected T newInstance(MapperProxy<T> mapperProxy) {// 通过 JDK 动态代理创建代理对象return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[]{mapperInterface}, mapperProxy);
}
上面的代码首先创建了一个 MapperProxy 对象,该对象实现了 InvocationHandler 接口。然后将对象作为参数传给重载方法,并在重载方法中调用 JDK 动态代理接口为 Mapper 生成代理对象。
到此,关于 Mapper 接口代理对象的创建过程就分析完了。现在我们的 ArticleMapper 接口指向的代理对象已经创建完毕,下面就可以调用接口方法进行数据库操作了。由于接口方法会被代理逻辑拦截,所以下面我们把目光聚焦在代理逻辑上面,看看代理逻辑会做哪些事情。
执行代理逻辑
在 MyBatis 中,Mapper 接口方法的代理逻辑实现的比较简单。该逻辑首先会对拦截的方法进行一些检测,以决定是否执行后续的数据库操作。对应的代码如下:
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {try {// 如果方法是定义在 Object 类中的,则直接调用if (Object.class.equals(method.getDeclaringClass())) {return method.invoke(this, args);/** 下面的代码最早出现在 mybatis-3.4.2 版本中,用于支持 JDK 1.8 中的* 新特性 - 默认方法。这段代码的逻辑就不分析了,有兴趣的同学可以* 去 Github 上看一下相关的相关的讨论(issue #709),链接如下:* * https://github.com/mybatis/mybatis-3/issues/709*/ } else if (isDefaultMethod(method)) {return invokeDefaultMethod(proxy, method, args);}} catch (Throwable t) {throw ExceptionUtil.unwrapThrowable(t);}// 从缓存中获取 MapperMethod 对象,若缓存未命中,则创建 MapperMethod 对象final MapperMethod mapperMethod = cachedMapperMethod(method);// 调用 execute 方法执行 SQLreturn mapperMethod.execute(sqlSession, args);
}
如上,代理逻辑会首先检测被拦截的方法是不是定义在 Object 中的,比如 equals、hashCode 方法等。对于这类方法,直接执行即可。除此之外,MyBatis 从 3.4.2 版本开始,对 JDK 1.8 接口的默认方法提供了支持,具体就不分析了。完成相关检测后,紧接着从缓存中获取或者创建 MapperMethod 对象,然后通过该对象中的 execute 方法执行 SQL。在分析 execute 方法之前,我们先来看一下 MapperMethod 对象的创建过程。MapperMethod 的创建过程看似普通,但却包含了一些重要的逻辑,所以不能忽视。
创建 MapperMethod 对象
本节来分析一下 MapperMethod 的构造方法,看看它的构造方法中都包含了哪些逻辑。如下:
public class MapperMethod {private final SqlCommand command;private final MethodSignature method;public MapperMethod(Class<?> mapperInterface, Method method, Configuration config) {// 创建 SqlCommand 对象,该对象包含一些和 SQL 相关的信息this.command = new SqlCommand(config, mapperInterface, method);// 创建 MethodSignature 对象,从类名中可知,该对象包含了被拦截方法的一些信息this.method = new MethodSignature(config, mapperInterface, method);}
}
如上,MapperMethod 构造方法的逻辑很简单,主要是创建 SqlCommand 和 MethodSignature 对象。这两个对象分别记录了不同的信息,这些信息在后续的方法调用中都会被用到。下面我们深入到这两个类的构造方法中,探索它们的初始化逻辑。
创建 SqlCommand 对象
前面说了 SqlCommand 中保存了一些和 SQL 相关的信息,那具体有哪些信息呢?答案在下面的代码中。
public static class SqlCommand {private final String name;private final SqlCommandType type;public SqlCommand(Configuration configuration, Class<?> mapperInterface, Method method) {final String methodName = method.getName();final Class<?> declaringClass = method.getDeclaringClass();// 解析 MappedStatementMappedStatement ms = resolveMappedStatement(mapperInterface, methodName, declaringClass, configuration);// 检测当前方法是否有对应的 MappedStatementif (ms == null) {// 检测当前方法是否有 @Flush 注解if (method.getAnnotation(Flush.class) != null) {// 设置 name 和 type 遍历name = null;type = SqlCommandType.FLUSH;} else {/** 若 ms == null 且方法无 @Flush 注解,此时抛出异常。* 这个异常比较常见,大家应该眼熟吧*/ throw new BindingException("Invalid bound statement (not found): "+ mapperInterface.getName() + "." + methodName);}} else {// 设置 name 和 type 变量name = ms.getId();type = ms.getSqlCommandType();if (type == SqlCommandType.UNKNOWN) {throw new BindingException("Unknown execution method for: " + name);}}}
}
如上,SqlCommand 的构造方法主要用于初始化它的两个成员变量。代码不是很长,逻辑也不难理解,就不多说了。继续往下看。
创建 MethodSignature 对象
MethodSignature 即方法签名,顾名思义,该类保存了一些和目标方法相关的信息。比如目标方法的返回类型,目标方法的参数列表信息等。下面,我们来分析一下 MethodSignature 的构造方法。
public static class MethodSignature {private final boolean returnsMany;private final boolean returnsMap;private final boolean returnsVoid;private final boolean returnsCursor;private final Class<?> returnType;private final String mapKey;private final Integer resultHandlerIndex;private final Integer rowBoundsIndex;private final ParamNameResolver paramNameResolver;public MethodSignature(Configuration configuration, Class<?> mapperInterface, Method method) {// 通过反射解析方法返回类型Type resolvedReturnType = TypeParameterResolver.resolveReturnType(method, mapperInterface);if (resolvedReturnType instanceof Class<?>) {this.returnType = (Class<?>) resolvedReturnType;} else if (resolvedReturnType instanceof ParameterizedType) {this.returnType = (Class<?>) ((ParameterizedType) resolvedReturnType).getRawType();} else {this.returnType = method.getReturnType();}// 检测返回值类型是否是 void、集合或数组、Cursor、Map 等this.returnsVoid = void.class.equals(this.returnType);this.returnsMany = configuration.getObjectFactory().isCollection(this.returnType) || this.returnType.isArray();this.returnsCursor = Cursor.class.equals(this.returnType);// 解析 @MapKey 注解,获取注解内容this.mapKey = getMapKey(method);this.returnsMap = this.mapKey != null;/** 获取 RowBounds 参数在参数列表中的位置,如果参数列表中* 包含多个 RowBounds 参数,此方法会抛出异常*/ this.rowBoundsIndex = getUniqueParamIndex(method, RowBounds.class);// 获取 ResultHandler 参数在参数列表中的位置this.resultHandlerIndex = getUniqueParamIndex(method, ResultHandler.class);// 解析参数列表this.paramNameResolver = new ParamNameResolver(configuration, method);}
}
上面的代码用于检测目标方法的返回类型,以及解析目标方法参数列表。其中,检测返回类型的目的是为避免查询方法返回错误的类型。比如我们要求接口方法返回一个对象,结果却返回了对象集合,这会导致类型转换错误。关于返回值类型的解析过程先说到这,下面分析参数列表的解析过程。
public class ParamNameResolver {private static final String GENERIC_NAME_PREFIX = "param";private final SortedMap<Integer, String> names;public ParamNameResolver(Configuration config, Method method) {// 获取参数类型列表final Class<?>[] paramTypes = method.getParameterTypes();// 获取参数注解final Annotation[][] paramAnnotations = method.getParameterAnnotations();final SortedMap<Integer, String> map = new TreeMap<Integer, String>();int paramCount = paramAnnotations.length;for (int paramIndex = 0; paramIndex < paramCount; paramIndex++) {// 检测当前的参数类型是否为 RowBounds 或 ResultHandlerif (isSpecialParameter(paramTypes[paramIndex])) {continue;}String name = null;for (Annotation annotation : paramAnnotations[paramIndex]) {if (annotation instanceof Param) {hasParamAnnotation = true;// 获取 @Param 注解内容name = ((Param) annotation).value();break;}}// name 为空,表明未给参数配置 @Param 注解if (name == null) {// 检测是否设置了 useActualParamName 全局配置if (config.isUseActualParamName()) {/** 通过反射获取参数名称。此种方式要求 JDK 版本为 1.8+,* 且要求编译时加入 -parameters 参数,否则获取到的参数名* 仍然是 arg1, arg2, ..., argN*/name = getActualParamName(method, paramIndex);}if (name == null) {/** 使用 map.size() 返回值作为名称,思考一下为什么不这样写:* name = String.valueOf(paramIndex);* 因为如果参数列表中包含 RowBounds 或 ResultHandler,这两个参数* 会被忽略掉,这样将导致名称不连续。** 比如参数列表 (int p1, int p2, RowBounds rb, int p3)* - 期望得到名称列表为 ["0", "1", "2"]* - 实际得到名称列表为 ["0", "1", "3"]*/name = String.valueOf(map.size());}}// 存储 paramIndex 到 name 的映射map.put(paramIndex, name);}names = Collections.unmodifiableSortedMap(map);}
}
以上就是方法参数列表的解析过程,解析完毕后,可得到参数下标到参数名的映射关系,这些映射关系最终存储在 ParamNameResolver 的 names 成员变量中。这些映射关系将会在后面的代码中被用到,大家留意一下。
执行 execute 方法
前面已经分析了 MapperMethod 的初始化过程,现在 MapperMethod 创建好了。那么,接下来要做的事情是调用 MapperMethod 的 execute 方法,执行 SQL。代码如下:
// -☆- MapperMethod
public Object execute(SqlSession sqlSession, Object[] args) {Object result;// 根据 SQL 类型执行相应的数据库操作switch (command.getType()) {case INSERT: {// 对用户传入的参数进行转换,下同Object param = method.convertArgsToSqlCommandParam(args);// 执行插入操作,rowCountResult 方法用于处理返回值result = rowCountResult(sqlSession.insert(command.getName(), param));break;}case UPDATE: {Object param = method.convertArgsToSqlCommandParam(args);// 执行更新操作result = rowCountResult(sqlSession.update(command.getName(), param));break;}case DELETE: {Object param = method.convertArgsToSqlCommandParam(args);// 执行删除操作result = rowCountResult(sqlSession.delete(command.getName(), param));break;}case SELECT:// 根据目标方法的返回类型进行相应的查询操作if (method.returnsVoid() && method.hasResultHandler()) {/** 如果方法返回值为 void,但参数列表中包含 ResultHandler,表明使用者* 想通过 ResultHandler 的方式获取查询结果,而非通过返回值获取结果*/executeWithResultHandler(sqlSession, args);result = null;} else if (method.returnsMany()) {// 执行查询操作,并返回多个结果 result = executeForMany(sqlSession, args);} else if (method.returnsMap()) {// 执行查询操作,并将结果封装在 Map 中返回result = executeForMap(sqlSession, args);} else if (method.returnsCursor()) {// 执行查询操作,并返回一个 Cursor 对象result = executeForCursor(sqlSession, args);} else {Object param = method.convertArgsToSqlCommandParam(args);// 执行查询操作,并返回一个结果result = sqlSession.selectOne(command.getName(), param);}break;case FLUSH:// 执行刷新操作result = sqlSession.flushStatements();break;default:throw new BindingException("Unknown execution method for: " + command.getName());}// 如果方法的返回值为基本类型,而返回值却为 null,此种情况下应抛出异常if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {throw new BindingException("Mapper method '" + command.getName()+ " attempted to return null from a method with a primitive return type (" + method.getReturnType()+ ").");}return result;
}
如上,execute 方法主要由一个 switch 语句组成,用于根据 SQL 类型执行相应的数据库操作。该方法的逻辑清晰,不需要太多的分析。不过在上面的方法中 convertArgsToSqlCommandParam 方法出现次数比较频繁,这里分析一下:
// -☆- MapperMethod
public Object convertArgsToSqlCommandParam(Object[] args) {return paramNameResolver.getNamedParams(args);
}public Object getNamedParams(Object[] args) {final int paramCount = names.size();if (args == null || paramCount == 0) {return null;} else if (!hasParamAnnotation && paramCount == 1) {/** 如果方法参数列表无 @Param 注解,且仅有一个非特别参数,则返回该参数的值。* 比如如下方法:* List findList(RowBounds rb, String name)* names 如下:* names = {1 : "0"}* 此种情况下,返回 args[names.firstKey()],即 args[1] -> name*/return args[names.firstKey()];} else {final Map<String, Object> param = new ParamMap<Object>();int i = 0;for (Map.Entry<Integer, String> entry : names.entrySet()) {// 添加 <参数名, 参数值> 键值对到 param 中param.put(entry.getValue(), args[entry.getKey()]);// genericParamName = param + index。比如 param1, param2, ... paramNfinal String genericParamName = GENERIC_NAME_PREFIX + String.valueOf(i + 1);/** 检测 names 中是否包含 genericParamName,什么情况下会包含?答案如下:** 使用者显式将参数名称配置为 param1,即 @Param("param1")*/if (!names.containsValue(genericParamName)) {// 添加 <param*, value> 到 param 中param.put(genericParamName, args[entry.getKey()]);}i++;}return param;}
}
如上,convertArgsToSqlCommandParam 是一个空壳方法,该方法最终调用了 ParamNameResolver 的 getNamedParams 方法。getNamedParams 方法的主要逻辑是根据条件返回不同的结果,该方法的代码不是很难理解,我也进行了比较详细的注释,就不多说了。
分析完 convertArgsToSqlCommandParam 的逻辑,接下来说说 MyBatis 对哪些 SQL 指令提供了支持,如下:
- 查询语句:SELECT
- 更新语句:INSERT/UPDATE/DELETE
- 存储过程:CALL
在上面的列表中,我刻意对 SELECT/INSERT/UPDATE/DELETE 等指令进行了分类,分类依据指令的功能以及 MyBatis 执行这些指令的过程。这里把 SELECT 称为查询语句,INSERT/UPDATE/DELETE 等称为更新语句。接下来,先来分析查询语句的执行过程。
查询语句对应的方法比较多,有如下几种:
- executeWithResultHandler
- executeForMany
- executeForMap
- executeForCursor
这些方法在内部调用了 SqlSession 中的一些 select* 方法,比如 selectList、selectMap、selectCursor 等。这些方法的返回值类型是不同的,因此对于每种返回类型,需要有专门的处理方法。以 selectList 方法为例,该方法的返回值类型为 List。但如果我们的 Mapper 或 Dao 的接口方法返回值类型为数组,或者 Set,直接将 List 类型的结果返回给 Mapper/Dao 就不合适了。execute* 等方法只是对 select* 等方法做了一层简单的封装,因此接下来我们应该把目光放在这些 select* 方法上。下面我们来分析一下 selectOne 方法的源码,如下:
本节选择分析 selectOne 方法,而不是其他的方法,大家或许会觉得奇怪。前面提及了 selectList、selectMap、selectCursor 等方法,这里却分析一个未提及的方法。这样做并没什么特别之处,主要原因是 selectOne 在内部会调用 selectList 方法。这里分析 selectOne 方法是为了告知大家,selectOne 和 selectList 方法是有联系的,同时分析 selectOne 方法等同于分析 selectList 方法。
SqlSession
会话(SqlSession)是myBatis的门面(采用门面模式设计),核心作用是为用户提供API。API包括增、删、改、查以及提交、关闭等。其自身是没有能力处理这些请求的,所以内部会包含一个唯一的执行器 Executor,所有请求都会交给执行器来处理。
下面是一个通过会话来使用 mybatis 的案例:
@Testpublic void sqlSessionTest() {SqlSession sqlSession = factory.openSession(ExecutorType.REUSE, true);Object user = sqlSession.selectOne("org.example.dao.UserDao.findById", 2);System.out.println(user);}
SqlSession 接口的默认实现为 DefaultSqlSession,跟踪代码可以看到,在 selectOne 内部,调用了 selectList 方法。
![]()
而 selectList 调用了执行器(CacheingExecutor)的查询方法(query)进行查询:
![]()
执行器
执行器(Executor)是一个大管家,核心功能包括:缓存维护、获取动态SQL、获取连接、以及最终的JDBC调用等。这么多事情无法全部亲力亲为,就需要把任务分派下去。所以Executor内部还会包含若干个组件:
- 缓存维护:cache
- 获取连接:Transaction
- 获取动态sql:SqlSource
- 调用jdbc:StatementHandler
上述组件中前三个和Executor是1对1关系,只有StatementHandler是1对多。每执行一次SQL 就会构造一个新的StatementHandler。想必你也能猜出StatementHandler的作用就是专门和JDBC打交道,执行SQL的。
下面是一个流程图,描述了会话及执行器的继承体系。
![]()
Executor
执行器的顶层接口为 Executor,定义了改、查、缓存维护、批处理刷新以及执行器的提交和关闭等一些接口。
目前有三个基本实现类,分别是SimpleExecutor、ReuseExecutor和BatchExecutor。各特性如下:
- SimpleExecutor:简单执行器,MyBatis的默认执行器,每次都会重新编译SQL、设置参数然后执行。
- ReuseExecutor:可复用执行器,会复用已经编译好的SQL,每次执行前只需要设置对应的参数即可执行。
- BatchExecutor:批处理执行器,编译一次SQL,然后多次设置参数,最后统一提交执行。
下面是三种执行器的使用案例:
// 简单执行器测试// SQL编译 2 次,设置参数 2 次,执行 2 次!(NNN)@Testpublic void simpleTest() throws SQLException {SimpleExecutor executor = new SimpleExecutor(configuration, jdbcTransaction);MappedStatement ms = configuration.getMappedStatement("org.example.dao.UserDao.findById");List<Object> list = executor.doQuery(ms, 2, RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER, ms.getBoundSql(2));list = executor.doQuery(ms, 2, RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER, ms.getBoundSql(2));}// 可重用执行器测试// SQL编译 1 次,设置参数 2 次,执行 2 次!(1NN)@Testpublic void reuseTest() throws SQLException {ReuseExecutor executor = new ReuseExecutor(configuration, jdbcTransaction);MappedStatement ms = configuration.getMappedStatement("org.example.dao.UserDao.findById");List<Object> list = executor.doQuery(ms, 2, RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER, ms.getBoundSql(2));list = executor.doQuery(ms, 2, RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER, ms.getBoundSql(2));}// 批处理执行器(仅针对增删改操作有效)// 编译 1 次,设置参数 2 次,提交 1 次!(1N1)@Testpublic void batchTest() throws SQLException {BatchExecutor executor = new BatchExecutor(configuration, jdbcTransaction);MappedStatement ms = configuration.getMappedStatement("org.example.dao.UserDao.setName");HashMap<Object, Object> param = new HashMap<>();param.put("arg0", 2);param.put("arg1", "batchTest");executor.doUpdate(ms, param);executor.doUpdate(ms, param);executor.doFlushStatements(false);}BaseExecutor
为了降低代码冗余,mybatis 将执行器的一些公共操作,如获取连接,一级缓存实现等操作抽象出一个基类 BaseExecutor。
我们可以将上例中执行器调用的 doQuery() 方法修改为父类的 query() 方法,这样就会走一级缓存逻辑。
// 执行器基类(BaseExecutor)测试 调 query() 走缓存// SQL编译 1 次,设置参数 1 次,执行 1 次// 第二次直接从缓存拿数据,无需执行!@Testpublic void baseExecutorTest() throws SQLException {SimpleExecutor executor = new SimpleExecutor(configuration, jdbcTransaction);MappedStatement ms = configuration.getMappedStatement("org.example.dao.UserDao.findById");List<Object> list = executor.query(ms, 2, RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER);list = executor.query(ms, 2, RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER);}跟踪代码可以看到,调用 query() 进入 BaseExecutor 类,并优先从缓存查找,如果缓存不存在则继续调用 doQuery() 进行数据库查询。
![]()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dnjz6KWc-1626662417637)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210525110419927.png)]
CachingExecutor
为了扩展二级缓存逻辑,mybatis添加了CachingExecutor,并采用了装饰器模式对三种执行器实现类进行装饰。看如下代码:
// 缓存执行器:通过装饰器模式执行二级缓存逻辑,然后把剩余逻辑交给装饰对象 delegate 执行。// 注意:1. 二级缓存必须提交后才会保存在内存中,因为二级缓存是跨线程的!// 2. 在 xml 配置中开启该 mapper 的二级缓存 <cache/>。@Testpublic void cacheExecutorTest() throws SQLException {SimpleExecutor executor = new SimpleExecutor(configuration, jdbcTransaction);CachingExecutor cachingExecutor = new CachingExecutor(executor);MappedStatement ms = configuration.getMappedStatement("org.example.dao.UserDao.findById");List<Object> list = cachingExecutor.query(ms, 2, RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER);cachingExecutor.commit(true);list = cachingExecutor.query(ms, 2, RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER); // Cache Hit Ratio [org.example.dao.UserDao]: 0.5list = cachingExecutor.query(ms, 2, RowBounds.DEFAULT, SimpleExecutor.NO_RESULT_HANDLER); // Cache Hit Ratio [org.example.dao.UserDao]: 0.6666666666666666}创建一个 SimpleExecutor,然后采用 CachingExecutor 进行装饰, 通过调用 CachingExecutor 的 query() 方法,即可执行二级缓存逻辑。
![]()
![]()
二级缓存也可以使用继承方式,在 Executor接口和BaseExecutor中加一层,或直接写在BaseExecutor中,但这会造成继承体系复杂或造成BaseExecutor类负担过重等问题,因此mybatis采用了装饰器的方式。
ClosedExecutor
在反序列后懒加载时告诉x,执行器已经关闭了!
一级缓存
命中场景
上文提到,mybatis 在 BaseExecutor 中实现了一级缓存逻辑,那么要命中一级缓存,需要满足哪些条件呢?
- 同一个会话。一级缓存也称为会话级缓存,因为它是与会话绑定的。
- 同一个key。即StatementId(包含sql语句)、参数、RowBounds都相同。
- 未进行缓存刷新。会话提交、回滚以及执行配置了FlushCache=true的方法都会清空会话缓存。
另外还需注意:
- 一级缓存作用域是否为SESSION。可以在<setting>标签的localCacheScope属性配置。
- 是否关闭了二级缓存。如果打开了二级缓存,则会优先从二级缓存查找。
/*** 一级缓存测试。* 注意:* 1. 确保 setting 中一级缓存的作用域(localCacheScope属性)为 SESSION(默认值),而非STATEMENT。* 2. 确保在 setting 和 mapper 中没有都开启二级缓存(默认关闭)。*/
public class FirstCacheTest {SqlSessionFactory factory;SqlSession sqlSession;@Beforepublic void init() throws SQLException {factory = new SqlSessionFactoryBuilder().build(ExecutorTest.class.getResourceAsStream("/mybatis-config.xml"));sqlSession = factory.openSession();// 在此插入id为2和3的数据}// 1. sql和参数必须相同@Testpublic void test01() {UserDao userMapper = sqlSession.getMapper(UserDao.class);User user01 = userMapper.findById(2);User user02 = userMapper.findById(2); // 从缓存取值System.out.println(user01 == user02); // trueUser user03 = userMapper.findById(3);System.out.println(user01 == user03); // false (注意是否有数据,否则null==null。下面例子不再提及,自行注意!)}// 2. statementId(类名.方法名)必须一致。@Testpublic void test02() {UserDao userMapper = sqlSession.getMapper(UserDao.class);User user01 = userMapper.findById(2);User user02 = userMapper.findByIdCopy(2);System.out.println(user01 == user02); // false}// 3. sqlSession 必须一致。// 这也是一级缓存被称为会话级缓存的原因之一。// 注意:调用方式可以多样!@Testpublic void test03() {UserDao userMapper = sqlSession.getMapper(UserDao.class);User user01 = userMapper.findById(2);// 创建一个新的 SqlSessionSqlSession sqlSessionAnother = factory.openSession();UserDao userMapperAnother = sqlSessionAnother.getMapper(UserDao.class);User user02 = userMapperAnother.findById(2);System.out.println(user01 == user02); // false// 调用方式可以多样,确保为同一个sqlSession即可。List user03 = sqlSession.selectList("org.example.dao.UserDao.findById", 2);System.out.println(user01 == user03.get(0)); // true}// 4. RowBounds 必返回行范围比须一致。// 默认为 RowBounds.DEFAULT@Testpublic void test04() {UserDao userMapper = sqlSession.getMapper(UserDao.class);User user01 = userMapper.findById(2);// 设置分页RowBounds rowBounds = new RowBounds(0, 10);List user02 = sqlSession.selectList("org.example.dao.UserDao.findById", 2, rowBounds);System.out.println(user01 == user02.get(0)); // false// 默认分页条件RowBounds rowBoundsDefault = RowBounds.DEFAULT;List user03 = sqlSession.selectList("org.example.dao.UserDao.findById", 2, rowBoundsDefault);System.out.println(user01 == user03.get(0)); // true}// 5. 会话未进行提交、回滚和清除缓存等操作。// 1. sql和参数必须相同@Testpublic void test05() {UserDao userMapper = sqlSession.getMapper(UserDao.class);User user01 = userMapper.findById(2);// sqlSession.commit();// sqlSession.rollback();sqlSession.clearCache();User user02 = userMapper.findById(2);System.out.println(user01 == user02); // false}// 6. 未调用 flushCache=true 的方法。// 增删改的flushCache默认为true,查默认为false。@Testpublic void test06() {UserDao userMapper = sqlSession.getMapper(UserDao.class);User user01 = userMapper.findById(2);// 调用 flushCache 为true的方法,刷新缓存// userMapper.setName(3, "test06");User userFlush = userMapper.findByIdOptionsFlushCacheIsTrue(2);System.out.println(user01 == userFlush); // false 先刷新,再执行// 再次查询User user02 = userMapper.findById(2);System.out.println(user01 == user02); // false}}
源码分析
一级缓存的流程分析如图所示,主要的逻辑在 BaseExecutor 中完成。
![]()
首先,sqlSession 调用 CacheingExecutor 的 query() 方法,在query()方法中执行完二级缓存逻辑后,剩下的工作交由 BaseExecutor 完成。
![]()
在 BaseExecutor 的query()方法中,优先从缓存查询。如果没有查询到数据,则从queryFromDatabase内再次调用子类的 doQuery() 实现从数据库查询。
![]()
如果从缓存中查询到数据,则直接返回。
![]()
关于缓存key的几点疑问?
缓存的key时什么时候生成的?
答:在执行二级缓存逻辑时,通过delegate调用BaseExecutor的createCacheKey()方法生成key,二级用完后传给一级缓存使用。缓存key包含了哪些内容?
答:如图所示。
什么情况会清空一级缓存?
答:在BaseExecutor中选中clearLocalCache()方法,按ALT+F7查询用法。可以看到
会话提交、回滚和执行增删改语句都会清空缓存。
执行配置了FlushCache=true的查询或一级缓存作用域为SATEMENT,则在queryStack == 0时也会清空缓存。
为什么一级缓存是HashMap,而不是concurrentHashMap?
答:因为一级缓存与会话绑定,而会话本来就不是线程安全的,用concurrentHashMap是多此一举!
扩展:一级缓存失效
MyBatis在与Spring结合使用时,有时会出现一级缓存失效的场景,究竟是什么原因导致的呢?
在我们的MyBatis工程中导入整合Spring所需要的相关依赖。
<!--Spring--><dependency><groupId>org.springframework</groupId><artifactId>spring-context</artifactId><version>5.2.9.RELEASE</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-tx</artifactId><version>5.2.9.RELEASE</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-jdbc</artifactId><version>5.2.9.RELEASE</version></dependency><!--MyBatis-Spring--><dependency><groupId>org.mybatis</groupId><artifactId>mybatis-spring</artifactId><version>2.0.2</version></dependency><!-- 数据源 --><dependency><groupId>com.mchange</groupId><artifactId>c3p0</artifactId><version>0.9.5.5</version></dependency>
在Resources目录添加Spring的配置文件application.xml。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:aop="http://www.springframework.org/schema/aop"xmlns:tx="http://www.springframework.org/schema/tx"xmlns:context="http://www.springframework.org/schema/context"xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd"><!-- 配置 spring 创建容器时要扫描的包 --><context:component-scan base-package="org.example"/><bean id="txManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"><property name="dataSource" ref="dataSource"/></bean><bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource"><property name="driverClass" value="com.mysql.jdbc.Driver"></property><property name="jdbcUrl" value="jdbc:mysql://42.192.223.129:3306/test01"></property><property name="user" value="root"></property><property name="password" value="root"></property></bean><tx:annotation-driven transaction-manager="txManager"/><bean name="sqlSession" class="org.mybatis.spring.SqlSessionFactoryBean"><property name="dataSource" ref="dataSource"/></bean><bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"><property name="basePackage" value="org.example.dao" /></bean></beans>添加测试方法,经测试后发现,只有在开启事务后,一级缓存才会命中。
// 一级缓存失效测试@Testpublic void testBySpring() {ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("application.xml");UserDao userMapperFromSpring = context.getBean(UserDao.class);System.out.println("-------------");User user01 = userMapperFromSpring.findById(2); // 构造一个新会话,发起调用User user02 = userMapperFromSpring.findById(2); // 构造一个新会话,发起调用System.out.println(user01 == user02); //false// 开启事务后再次测试DataSourceTransactionManager transactionManager = context.getBean("txManager", DataSourceTransactionManager.class);TransactionStatus transactionStatus = transactionManager.getTransaction(new DefaultTransactionDefinition());System.out.println("-------------");User user03 = userMapperFromSpring.findById(2); // 构造一个新会话,发起调用User user04 = userMapperFromSpring.findById(2); // 提取线程变量中存储的会话System.out.println(user03 == user04); //true}上述测试案例执行的日志信息如下。
2021-05-26 14:05:03,590 2466 [ main] DEBUG mybatis.spring.SqlSessionUtils - Creating a new SqlSession
2021-05-26 14:05:03,606 2482 [ main] DEBUG mybatis.spring.SqlSessionUtils - SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@c7ba306] was not registered for synchronization because synchronization is not active
2021-05-26 14:05:03,653 2529 [ main] INFO l.AbstractPoolBackedDataSource - Initializing c3p0 pool... com.mchange.v2.c3p0.ComboPooledDataSource [ acquireIncrement -> 3, acquireRetryAttempts -> 30, acquireRetryDelay -> 1000, autoCommitOnClose -> false, automaticTestTable -> null, breakAfterAcquireFailure -> false, checkoutTimeout -> 0, connectionCustomizerClassName -> null, connectionTesterClassName -> com.mchange.v2.c3p0.impl.DefaultConnectionTester, contextClassLoaderSource -> caller, dataSourceName -> 1hge5ttah1aevl6q1nddg54|43599640, debugUnreturnedConnectionStackTraces -> false, description -> null, driverClass -> com.mysql.jdbc.Driver, extensions -> {}, factoryClassLocation -> null, forceIgnoreUnresolvedTransactions -> false, forceSynchronousCheckins -> false, forceUseNamedDriverClass -> false, identityToken -> 1hge5ttah1aevl6q1nddg54|43599640, idleConnectionTestPeriod -> 0, initialPoolSize -> 3, jdbcUrl -> jdbc:mysql://42.192.223.129:3306/test01, maxAdministrativeTaskTime -> 0, maxConnectionAge -> 0, maxIdleTime -> 0, maxIdleTimeExcessConnections -> 0, maxPoolSize -> 15, maxStatements -> 0, maxStatementsPerConnection -> 0, minPoolSize -> 3, numHelperThreads -> 3, preferredTestQuery -> null, privilegeSpawnedThreads -> false, properties -> {user=******, password=******}, propertyCycle -> 0, statementCacheNumDeferredCloseThreads -> 0, testConnectionOnCheckin -> false, testConnectionOnCheckout -> false, unreturnedConnectionTimeout -> 0, userOverrides -> {}, usesTraditionalReflectiveProxies -> false ]
2021-05-26 14:05:03,673 2549 [ main] DEBUG com.mchange.v2.cfg.MConfig - The configuration file for resource identifier '/mchange-commons.properties' could not be found. Skipping.
2021-05-26 14:05:03,673 2549 [ main] DEBUG com.mchange.v2.cfg.MConfig - The configuration file for resource identifier '/mchange-log.properties' could not be found. Skipping.
2021-05-26 14:05:03,673 2549 [ main] DEBUG com.mchange.v2.cfg.MConfig - The configuration file for resource identifier '/c3p0.properties' could not be found. Skipping.
2021-05-26 14:05:03,673 2549 [ main] DEBUG com.mchange.v2.cfg.MConfig - The configuration file for resource identifier 'hocon:/reference,/application,/c3p0,/' could not be found. Skipping.
2021-05-26 14:05:03,673 2549 [ main] DEBUG resourcepool.BasicResourcePool - com.mchange.v2.resourcepool.BasicResourcePool@4ae9cfc1 config: [start -> 3; min -> 3; max -> 15; inc -> 3; num_acq_attempts -> 30; acq_attempt_delay -> 1000; check_idle_resources_delay -> 0; max_resource_age -> 0; max_idle_time -> 0; excess_max_idle_time -> 0; destroy_unreturned_resc_time -> 0; expiration_enforcement_delay -> 0; break_on_acquisition_failure -> false; debug_store_checkout_exceptions -> false; force_synchronous_checkins -> false]
2021-05-26 14:05:03,673 2549 [ main] DEBUG 3P0PooledConnectionPoolManager - Created new pool for auth, username (masked): 'ro******'.
2021-05-26 14:05:03,673 2549 [ main] DEBUG resourcepool.BasicResourcePool - acquire test -- pool size: 0; target_pool_size: 3; desired target? 1
2021-05-26 14:05:03,673 2549 [ main] DEBUG resourcepool.BasicResourcePool - awaitAvailable(): [unknown]
2021-05-26 14:05:04,351 3227 [ main] DEBUG ction.SpringManagedTransaction - JDBC Connection [com.mchange.v2.c3p0.impl.NewProxyConnection@1458ed9c [wrapping: com.mysql.jdbc.JDBC4Connection@10a9d961]] will not be managed by Spring
2021-05-26 14:05:04,351 3227 [ main] DEBUG g.example.dao.UserDao.findById - ==> Preparing: SELECT * FROM user where id = ?
2021-05-26 14:05:04,398 3274 [ main] DEBUG g.example.dao.UserDao.findById - ==> Parameters: 2(Integer)
2021-05-26 14:05:04,461 3337 [ main] DEBUG g.example.dao.UserDao.findById - <== Total: 1
2021-05-26 14:05:04,461 3337 [ main] DEBUG mybatis.spring.SqlSessionUtils - Closing non transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@c7ba306]
2021-05-26 14:05:04,461 3337 [ main] DEBUG mybatis.spring.SqlSessionUtils - Creating a new SqlSession
2021-05-26 14:05:04,461 3337 [ main] DEBUG mybatis.spring.SqlSessionUtils - SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@484094a5] was not registered for synchronization because synchronization is not active
2021-05-26 14:05:04,461 3337 [ main] DEBUG ction.SpringManagedTransaction - JDBC Connection [com.mchange.v2.c3p0.impl.NewProxyConnection@63fbfaeb [wrapping: com.mysql.jdbc.JDBC4Connection@10a9d961]] will not be managed by Spring
2021-05-26 14:05:04,461 3337 [ main] DEBUG g.example.dao.UserDao.findById - ==> Preparing: SELECT * FROM user where id = ?
2021-05-26 14:05:04,461 3337 [ main] DEBUG g.example.dao.UserDao.findById - ==> Parameters: 2(Integer)
2021-05-26 14:05:04,508 3384 [ main] DEBUG g.example.dao.UserDao.findById - <== Total: 1
2021-05-26 14:05:04,508 3384 [ main] DEBUG mybatis.spring.SqlSessionUtils - Closing non transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@484094a5]
false
2021-05-26 14:05:04,570 3446 [ main] DEBUG mybatis.spring.SqlSessionUtils - Creating a new SqlSession
2021-05-26 14:05:04,570 3446 [ main] DEBUG mybatis.spring.SqlSessionUtils - Registering transaction synchronization for SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@e70f13a]
2021-05-26 14:05:04,570 3446 [ main] DEBUG ction.SpringManagedTransaction - JDBC Connection [com.mchange.v2.c3p0.impl.NewProxyConnection@466276d8 [wrapping: com.mysql.jdbc.JDBC4Connection@10a9d961]] will be managed by Spring
2021-05-26 14:05:04,570 3446 [ main] DEBUG g.example.dao.UserDao.findById - ==> Preparing: SELECT * FROM user where id = ?
2021-05-26 14:05:04,570 3446 [ main] DEBUG g.example.dao.UserDao.findById - ==> Parameters: 2(Integer)
2021-05-26 14:05:04,617 3493 [ main] DEBUG g.example.dao.UserDao.findById - <== Total: 1
2021-05-26 14:05:04,617 3493 [ main] DEBUG mybatis.spring.SqlSessionUtils - Releasing transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@e70f13a]
2021-05-26 14:05:04,617 3493 [ main] DEBUG mybatis.spring.SqlSessionUtils - Fetched SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@e70f13a] from current transaction
2021-05-26 14:05:04,617 3493 [ main] DEBUG mybatis.spring.SqlSessionUtils - Releasing transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@e70f13a]
true我们在userMapperFromSpring.findById(2)处打上断点,逐步跟踪源码查看。
首先进入MapperProxy的invoke方法,可以看到,Spring在此处动了手脚,把原本应该是DefaultSqlSession的类通过注入方式换成了SqlSessionTemplate。而SqlSessionTemplate是SqlSession接口的子类,所以可以无缝切换。
![]()
但切换后,为了不改变原有DefaultSession的逻辑,需要每个方法都从DefaultSession拷贝原有实现过来,再加上自己的逻辑,这显得非常麻烦。因此,MyBatis-Spring又使用了一次动态代理,创建了一个代理对象sqlSessionProxy作为SqlSessionTemplate的成员变量,在内部通过它来附加MyBatis-Spring想要实现的逻辑。
![]()
![]()
![]()
当执行sqlSessionProxy的selectOne时,进入invoke()方法,实现逻辑附加,而此处Object result = method.invoke(sqlSession, args)中的sqlSession才是我们原本的DefaultSqlSession。
![]()
SqlSessionInterceptor实现了InvocationHandler,作为SqlSessionTemplate的一个内部类,包含了代理SqlSession时的拦截处理逻辑。
分析可知,MyBatis与Spring整合后,执行流程变为如下:
- UserMapper:代理了SqlSession,简化SQL执行操作。
- SqlSessionTemplate:实现了SqlSession,注入到Mapper中替换原有的DefaultSqlSession。
- sqlSessionProxy:代理了SqlSession,在SqlSessionInterceptor中实现了代理逻辑。
- DefaultSqlSession:原MyBatis执行SQL的入口。
现在我们可以轻易发现,为什么一级缓存只有在开启事务的时候才会命中了!问题根源就在于下面方法。
SqlSession sqlSession = getSqlSession(SqlSessionTemplate.this.sqlSessionFactory,SqlSessionTemplate.this.executorType, SqlSessionTemplate.this.exceptionTranslator);
在关闭事务或开启事务第一次执行时,无法从ThreadLocal变量中获取原有的会话,就会创建一个新会话,导致了会话不一致,从而无法命中一级缓存。
![]()
而在开启事务且第二次及之后执行时,可以直接从ThreadLocal变量中获取原有的会话返回。
![]()
再看会话关闭时的处理,如果开启事务,会话只是被释放,而不开启事务,会话直接被关闭了!
![]()
二级缓存
下面是引入二级缓存后,mybatis的缓存体系图解。
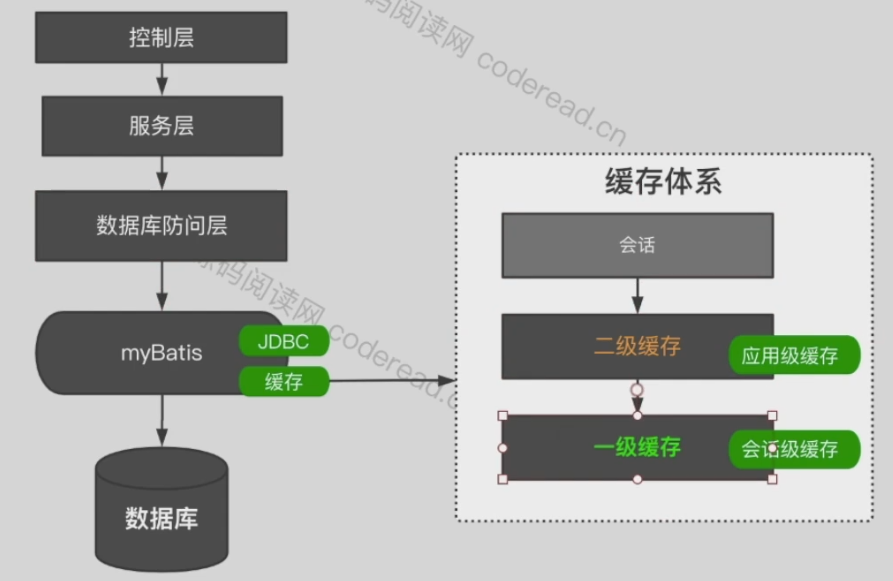
MyBatis的二级缓存也称为应用级缓存,与一级缓存不同的是,它的作用范围是整个应用,而且可以跨线程使用。所以二级缓存有更高的命中率,适合缓存一些修改较少的数据。
命中场景
二级缓存命中需要满足下面一些条件:
- 会话提交。查询结果(清空操作等)只有在会话提交后才会从暂存区提交到缓存区,这时查询才能命中(即使是同会话也必须提交)。
- 同一个key。即StatementId(包含sql语句)、参数、RowBounds都相同。
- 未进行缓存刷新操作。执行配置了flushCache=true的方法会置
clearOnCommit标记为true,不查询缓存区,且在提交时清空缓存。
另外还需注意:
- 全局缓存开关cacheEnabled和语句缓存开关useCache没有被关闭。
- 同一个接口,xml和注解的配置的缓存不能相互引用,需要显示进行缓存引用操作。
二级缓存和一级缓存的命中场景类似,不再做过多的代码演示,下面是一个简单的使用案例,可自行跟踪代码验证。
// 提交或关闭会话后,二级缓存才能被其他会话命中// 即使在打开会话时设置了自动提交,也需要手动提交后才会生效// 其他命中条件:StatementId一致(Sql一致)、执行参数一致、RowBounds一致。@Testpublic void cacheTest02() {System.out.println("================ 第一次执行 ================");SqlSession sqlSession01 = factory.openSession(true); // 设置自动提交并不能使二级缓存立即生效UserDao userMapper01 = sqlSession01.getMapper(UserDao.class);User user01 = userMapper01.findById(2); // 查询数据库System.out.println("================ 第二次执行 ================");SqlSession sqlSession02 = factory.openSession();UserDao userMapper02 = sqlSession02.getMapper(UserDao.class);User user02 = userMapper02.findById(2); // 也是查询数据库(看日志),因为 sqlSession01 还未提交sqlSession02.commit(); // 提交会话,sqlSession02 设置的二级缓存生效// sqlSession02.close(); // close()方法也会提交会话System.out.println("================ 第三次执行 ================");SqlSession sqlSession03 = factory.openSession();UserDao userMapper03 = sqlSession03.getMapper(UserDao.class);User user03 = userMapper03.findById(2); // 查询缓存}
为什么要提交后才能命中二级缓存?
答:二级缓存是跨线程的,如果会话一读取了会话二中未提交的数据,而会话二又进行了回滚,那么就会导致脏读。
扩展:二级缓存的清除策略
LRU(默认) – 最近最少使用:移除最长时间不被使用的对象。
FIFO– 先进先出:按对象进入缓存的顺序来移除它们。
SOFT– 软引用:基于垃圾回收器状态和软引用规则移除对象。
WEAK– 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。
内存结构
一个合格的缓存产品应该具有下面一些功能:
- 数据存储(内存、硬盘、第三方集成)
- 溢出淘汰(FIFO先进先出、LRU最近最少使用)
- 过期清理
- 线程安全
- 命中率统计
- 序列化
- …
那么MyBatis又是如何来实现这些功能的呢?
MyBatis中,二级缓存只有一个顶层接口Cache,且只包含了存、取和获取ID等几个简单的方法。
![]()
为了实现上述缓存所必需的功能,常规的做法是写一个大类,逐一进行功能实现。但这样代码显得很low,MyBatis使用了装饰器+责任链模式,每个功能由对应的功能类来实现,可以按需进行组合,下面是一个简单的图示。
![]()
下面是一段单独使用缓存的代码片段:
// 缓存组件和结构探究@Testpublic void cacheTest01() {Cache cache = configuration.getCache("org.example.dao.UserDao");User user = new User();user.setId(1);user.setUsername("hyx-Name");cache.putObject("hyx", user);Object value = cache.getObject("hyx");System.out.println(value);}
跟踪代码,在代码中可以看到如下的调用链。
![]()
执行流程
二级缓存是跨线程访问的,所以需要考虑多个会话的情形。MyBatis为每个会话定义了一个事务缓存管理器(TransationalCacheManager),然后在事务缓存管理器中管理打开的暂存空间。
会话的所有修改会先保存在暂存区,只有在会话提交后才转存到缓存区。缓存区个数和每个事务管理器的暂存区个数与缓存空间数一致,并且缓存区和暂存区是一对多的关系。
![]()
二级缓存主要逻辑在CachingExecutor中,我们跟踪代码来验证上述说明。
// 探究事务缓存管理器和缓存区@Testpublic void cacheTest03() {SqlSession sqlSession01 = factory.openSession(true); // 设置自动提交并不能使二级缓存立即生效System.out.println(sqlSession01);}
可以看到,DefaultSqlSession内部包装了CachingExecutor来真正执行CURD操作,CachingExecutor主要用于处理二级缓存逻辑,处理完后再把其他任务交给装饰对象delegate处理。而二级缓存的处理主要是依赖其内部的缓存事务管理器(tcm),tcm包含一个存储暂存区的HashMap (key为cache类型,就是缓存区,value为暂存区),保存了N个打开的缓存空间,而每个暂存区又指向其对应的缓存区,当会话被提交时,向缓存区更新数据。
![]()
下面是二级缓存的存取流程图,可自行跟踪代码验证。
![]()
// 二级缓存的执行流程验证(同会话)@Testpublic void cacheTest04() {SqlSession sqlSession01 = factory.openSession(true);UserDao userMapper01 = sqlSession01.getMapper(UserDao.class);User user01 = userMapper01.findById(2); // 查询数据库,并把查询结果保存在暂存区User user02 = userMapper01.findById(2); // 也是查询数据库(看日志),因为 sqlSession01 还未提交sqlSession01.commit(); // 提交会话,把暂存区的数据提交到缓存区User user03 = userMapper01.findById(2); // 直接查询缓存区数据}
为什么要使用clearOncommit标记?(#146)
update时清空暂存区,但查询时直接查缓存区,查到了已经清空的数据,这时候应该在update清空暂存区的时候标记下,缓存区已经不可用了,下次查询的时候要判断下标记。
Jdbc处理器
在JDBC中执行一次sql的步骤包括。预编译SQL、设置参数然后执行。Jdbc处理器(StatementHandler)就是用来处理这三步。同样它也需要两个助手分别是:
- 设置参数:ParameterHandler
- 读取结果:ResultSetHandler
另外的执行是由它自己完成。
我们来回顾下MyBatis的处理流程:先是SqlSession调用执行器执行SQL语句,执行器处理完共性问题(获取连接、缓存、事务、复用Statement等)后,如果确实需要访问数据库,再交给JDBC处理器完成数据库操作。
![]()
![]()
StatementHandler
JDBC处理器(StatementHandler)
基于JDBC构建Statement并设置参数,然后执行SQL,每使用会话当中一次SQL,都会有与之相对应的且唯一的Statement实例。
StatementHandler 主要功能有创建Statement、设置参数、执行SQL(查、改、批处理)以及一些获取BoundSql和参数处理器等辅助API。
为了适配 JDBC 中的三种 Statement,StatementHandler 也分别定义了三个对应的子类,并在其之上抽取一些如设置公共参数、设置返回行数等公共逻辑到BaseStatementHandler中。
StatementHandler的继承结构如下:
![]()
在开发中,我们一般使用 PreparedStatementHandler ,不仅可以防止SQL注入,并且由于预编译的原因,执行性能更高,下面我们将依据此类JDBC处理器进行讲解。
提示:在应用中使用哪类StatementHandler,可以在mapper文件中通过语句标签的StatementType属性来进行配置。
JDBC处理流程
StatementHandler执行流程从执行器发起,然后预编译->设置参数->执行->结果集映射为JavaBean。时序图如下:![]()
创建StatementHandler
首先定位到执行器的doQuery()方法,通过大管家Configuration创建一个``StatementHandler`对象。
![]()
![]()
在RoutingStatementHandler中,根据配置的StatementType 匹配到不同类型的JDBC处理器。
![]()
继续跟踪代码可以发现,在创建StatementHandler的同时在其内部创建了参数处理器和结果集处理器。
![]()
![]()
为什么要通过Configuration来创建StatementHandler呢?
答:使用简单工厂模式,方便拦截器的实现。
构建ParpareStatement
依旧是从执行器进入,先调用BaseExecutor的getConnection方法从事务获取连接
![]()
再通过RountingStatement的装饰对象(上一步实际创建的ParpareStatementHandler)创建ParpareStatement。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-r1grh0Px-1626662417697)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210531235002165.png)]
![]()
在这里调用子类的实际创建方法。
![]()
在ParpareStatementHandler中用传入的connection创建ParpareStatemen返回。
![]()
创建完成后,在BaseStatementHandler中处理共性(设置超时时间、返回行数等),最后返回创建好的ParpareStatement。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hfp17ZBW-1626662417704)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210531235358982.png)]
设置执行参数
在 SimpleExecutor 的 doQuery 中调用prepareStatement后,处理创建Statement外,还会进行参数设置。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bo7xeGfr-1626662417706)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210601000826525.png)]
![]()
![]()
调用paramterHandler进行参数映射,具体的参数映射流程,以及参数转换流程将会在下一章节讲解。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AOPFRTVn-1626662417710)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210601001158643.png)]
执行SQL
直接在ParpareStatementHandler中调用ParpareStatement.execute()方法。
![]()
![]()
![]()
结果集处理
SQL执行完后,直接调用resultSetHandler进行结果集处理,这会在下下一章节详细讲解。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-duxTT0NP-1626662417716)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210601001651312.png)]
参数处理详解
参数处理分为参数转换->参数映射->参数赋值三个过程,主要涉及的类如下:
![]()
提示:MyBatis在MapperMethod类中进行参数转换、调用Session以及结果转换。
参数转换
参数转换就是把多种类型的参数(基本类型、JavaBean等)转换为便于参数映射的数据对象(Object或ParamMap),主要处理逻辑在ParamNameResolver类中。
转换规则如下:
- 单个参数:如果没有设置
@Param注解,默认不做任何处理,直接返回Object对象。
// 单个基本/String类型/JavaBean类型 -> Object对象@Testpublic void singleTest() {// 基本类型userMapper.findById(2);// JavaBean类型User user = new User();user.setId(2);userMapper.findByUser(user);}![]()
![]()
![]()
转换后的参数如下图所示,Integer类型的2依然为Integer类型的2(存放在Object对象中)。
![]()
同理,JavaBean类型的单个参数User,转换后依然是User。
![]()
- 多个参数:转化为以
arg0、arg1...为key,参数值为 value 的ParamMap。同时添加``param1、param2…`为 key 的通用名称方便后续扩充。
// 多个参数或设置了@Param注解 -> map@Testpublic void multiTest() {User user = new User();user.setId(2);// 接口:User findByNameAndUser(String name, @Param("user") User user)// SQL:SELECT * FROM user where name = #{arg0} and id = #{user.id}userMapper.findByNameAndUser("hyx", user);}如果参数设置了@Param注解或者存在多个参数,则在此处进行遍历,逐个添加到paramMap中,并为其添加通用key(param1、param2…)。
![]()
提示:如果配置了
@Param注解,或编译时开启了-parameters选项(JDK8+),那么arg0、arg1…会转换为实际的形参名。
参数映射和赋值
经过ParamNameResolver类进行参数转换后,将会得到一个Object类型(实际为原类型或ParamMap)的参数对象。
在JDBC处理的设置参数(parameterize)阶段, 会遍历之前解析好的parameterMappings,获取需要设置参数的位置及相关信息,通过对应的方法从参数对象中获取对应的参数值后,再匹配对应类型的TypeHandler进行设置(setXxxx)。
获取参数值的规则如下:
- 有类型处理器( TypeHandler)的:直接赋值,并且忽略SQL中引用名称。一般是单个基本类型、String或自定义 TypeHandler 的类型。
- 没有类型处理器的:使用
MetaObject封装后基于属性名称映射,支持嵌套对象属性访问。
跟踪代码:在经过下面一些流程后,进入到 SimpleExecutor 的 prepareStatement 方法,该方法用于预处理Statement,以及设置参数。
DefaultSqlSession.selectList()->CachingExecutor.query()->BaseExecutor.queryFromDatabase()
->SimpleExecutor.doQuery()->SimpleExecutor.prepareStatement()![]()
我们调试到 parameterize方法进行跟进,经过 RoutingStatementHandler 后,在 PreparedStatementHandler 中调用了 DefaultParameterHandler 的setParameters 方法进行参数设置。
![]()
![]()
![]()
首先从 MappedStatement 的 SqlSource 中获取解析好的 parameterMappings,该 ArrayList 保存了预处理器 SQL 需要设置的参数信息,如属性名、JDBC类型和类型处理器等。接下来进行遍历,逐个处理每个需要设置的参数。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9XBeEqKc-1626662417737)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210602133045589.png)]
跳过输出参数不需要设置,还有对foreach动态标签的特殊处理(这个我们后续会详细讲解),我们可以看到,如果有匹配的TypeHandler,则直接往下走。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RewLyBss-1626662417738)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210602133945644.png)]
调用 TypeHandler的setParameter方法,进行参数设置。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SwKyWIt5-1626662417740)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210602134211929.png)]
跟进,这里可以看到,如果参数为NULL,则必须JDBC类型,否则无法设置参数。如果参数不为NULL,则进入另一分支,设置非空参数。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ddM12PAY-1626662417741)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210602134709614.png)]
MyBatis会根据value的class类型自动匹配对应的TypeHandler进行设置,可以不设置JDBC类型。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2CaAThBa-1626662417743)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210602135114725.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5aF9s7Xt-1626662417745)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210602135151203.png)]
最后调用匹配好的类型处理器进行参数设置。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9uiIBPNR-1626662417746)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210602135447289.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NPrxczSh-1626662417748)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210602135531288.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JDIdreeW-1626662417749)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210602135545209.png)]
对于没有 TypeHandler 的参数设置,在进行参数映射时通过反射工具类MetaObject进行封装,然后用OGNL表达式获取对应的值,后续流程与上面一致。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EAlePnGw-1626662417751)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210602140351150.png)]
提示:我们可以自定义
TypeHandler,然后使用TypeHandlerRegistry注册到MyBatis。
结果集处理详解
简单结果映射流程
结果集映射概述
结果集处理主要使用下面三个类:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hBghZqze-1626662417752)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210602140815923.png)]
DefaultResultSetHandler:主要用于处理映射逻辑,将结果集行转化为Java对象,先放到ResultContext中。DefaultResultContext:主要用于控制结果集的转换(如STOP),其保存了当前解析的Java对象、解析状态等。DefaultResultHandler:主要用于存储处理后的Java对象,内部有一个List存放Object。
为什么不直接把Object直接丢给ResultHandler呢?
答:添加 ResultContext可以对结果转换进行控制,如STOP等。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-w4AysGIm-1626662417754)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210602142759454.png)]
结果集处理主流程如下,可以参照源码阅读网MyBatis源码地图进行跟踪。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-w9e9LfOE-1626662417755)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210602143238446.png)]
地址:http://www.coderead.cn/p/mybatis/map/file/%E7%BB%93%E6%9E%9C%E9%9B%86%E5%A4%84%E7%90%86.map
用户:test
密码:111222
首先,JDBC处理器(PreparedStatementHandler)执行完查询后,调用结果集处理器(DefaultResultSetHandler)处理结果。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KD1FS8SI-1626662417757)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210608220910966.png)]
然后调用handleResultSets处理多结果集的相关逻辑,一般用于存储过程返回多个结果集的情形,将多个结果集合并为单个返回。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aQe6rENe-1626662417759)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210608221347825.png)]
接着调用handleResultSet处理单个结果集,首先创建一个结果存放的容器(DefaultResultHandler)传入handlerRowValues处理每一行结果,全部行完毕后关闭当前结果集。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-91maDvwJ-1626662417761)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210608221752793.png)]
在handleRowValues中判断,如果有嵌套结果映射,则调用handleRowValuesForNestedResultMap(后面章节会详解该分支),否则调用handleRowValuesForSimpleResultMap进行简单结果映射处理。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MbSnbOsI-1626662417762)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210608222103184.png)]
简单结果映射处理流程,首先跳过rowBounds指定的行,然后循环判断,如果结果集没有被关闭且应该继续处理(由DefaultResultContext控制,如果没有被停止且小于rowBounds的限制数,则继续处理),那么调用rs.next()获取下一行结果进行处理。
结果行处理,首先是鉴别器的逻辑,可以先跳过不看。然后调用getRowValue,内部处理后,获得的就是封装好的Javabean对象(如User),最后将该对象存入resultContext中。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sMKzplZ9-1626662417764)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210608222922535.png)]
skipRows主要有两种方式
- 如果数据库驱动支持
absoluteAPI,则调用该JDBC API直接跳到指定行。- 否则循环调用N次
rs.next()。
对结果行的处理,主要经过三个步骤:创建结果对象->处理自动结果映射->处理手动结果映射,后面的章节会对这三步骤进行详细讲解。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wa8dbe1H-1626662417767)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210608224202981.png)]
创建结果对象
上文提到,结果行的处理主要经过三个步骤,首先是调用createResultObject创建结果对象。
createResultObject内部首先调用了其重载函数,创建实际对象,然后遍历resultMap的所有列映射,如果有嵌套子查询且开启了懒加载,则创建对应的代理对象。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vhiSt2Fj-1626662417768)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210608224853815.png)]
创建实际结果对象时有四种方式,从上往下选择:
1.原始类型创建如String、Integer 等 。直接匹配 TypeHandler调用JDBC API getXxxx获取结果集对象。
2.基于ResultMap中的构造参数配置映射 创建
3.返回结果为接口,或存在无参构造方法,基于ObjectFatory创建
4.基于自动映射,自动依次查找型是否与指定构造方法匹配,如果有就自动创建。
自动映射结果集
创建结果对象后,优先调用applyAutomaticMappings进行自动结果映射。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OwGk2ngb-1626662417772)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210603112414533.png)]
自动映射:对没有配置手动映射的列创建一个UnMappedColumnAutoMapping,然后遍历map进行自动映射,获取结果值,使用metaObject存入上文创建的结果对象。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-N58WbZU9-1626662417774)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/image-20210608230852922.png)]
手动映射结果集
处理完自动结果映射后,开始处理手动结果映射。MyBatis在Mapper配置文件中提供了ResultMap标签用于配置结果集映射规则。子标签constructor用于构造结果对象,id和result用于映射基本类型字段,association用于配置一对一关联,collection用于配置一对多关联。
![]()
手动映射的逻辑主要在applyPropertyMappings中。
手动映射:首先从ResultMap中获取要映射的字段,遍历获取字段值,如果value==DEFERRED则表示延迟加载(后文将会讲到),否则直接把值set进结果对象。
![]()
手动映射获取列的值比自动映射更为复杂,首先要判断是否为嵌套查询,如果是,则走getNestedQueryMappingValue(稍后会讲),如果有结果集别名,则走addPendingChildRelation(很少用)。最后。如果只是普通的结果映射,则匹配TypeHandler从结果集行获取值。
![]()
嵌套子查询
基本概念
嵌套子查询是指在查询某个对象的时候,又关联去查询其他对象。根据需要映射的成员变量是否为列表,分别使用<collection>标签和<association>标签进行嵌套查询,如果是列表,则标签的select属性指向的是一个多查询,否则为单查询。如查询博客,并同时查询博客的作者和博客的所有评论,在这个例子中,查询博客的作者就是一对一的子查询,查询博客的所有评论就是一对多的子查询。
在进行完自动映射之后,就会进行手动结果映射,如果配置了嵌套子查询,则在获取映射结果值的时候(getNestedQueryMappingValue),就会走嵌套子查询的逻辑。
![]()
提示:例如自己评论自己的博客时,两次User的查询一致,第二次走一级缓存,这是也一级缓存的作用之一:加速嵌套子查询!
流程分析
一个嵌套子查询案例的部分代码如下:
/*** 跟踪代码:嵌套子查询 + 循环查询(采用延迟加载解决)*/@Testpublic void testNestedQuery() {Blog blog = blogMapper.findByIdNestedQueryComments(1); // 直接查询blog + comments的信息 (注意comments的嵌套查询问题)System.out.println(blog);} <!-- 据ID查询博客 嵌套查询comments--><resultMap id="blogNestedQueryMap" type="org.example.model.Blog" autoMapping="true"><id column="id" property="id"/><result column="title" property="title"/><!-- <result column="body" property="body"/>--><!-- 子查询 ==> 嵌套查询comments--><collection property="comments" column="id" select="org.example.dao.CommentMapper.findByBlogIdNestedQueryBlog"/></resultMap><select id="findByIdNestedQueryComments" resultMap="blogNestedQueryMap">select * from blog where id = #{id}</select> <!-- 根据ID查询评论 嵌套查询Blog--><resultMap id="commentNestedQueryMap" type="org.example.model.Comment" autoMapping="true"><id column="id" property="id"/><result column="blog_id" property="blogId"/><result column="content" property="content"/><association property="blog" column="blog_id" select="org.example.dao.BlogMapper.findByIdNestedQueryComments"/></resultMap><select id="findByBlogIdNestedQueryBlog" resultMap="commentNestedQueryMap">SELECT * FROM comment where blog_id = #{blogId}</select>
下面是嵌套子查询执行流程图
![]()
在DefaultResultMapping.applyPropertyMappings => getPropertyMappingValue中打上断点,可以看到,在映射comments的时候,存在嵌套查询,则走嵌套查询逻辑getNestedQueryMappingValue。
![]()
嵌套查询的逻辑主要在getNestedQueryMappingValue中实现,在进行必要的参数准备后,先从一级缓存取值,如果取到了则进行延迟加载。
![]()
如果没有取到,则继续判断是否为懒加载,如果是则走懒加载逻辑,否则直接从数据库进行加载。
![]()
解决循环查询
如果有这么一种极端情况,查询博客的同时查询所有评论,查询评论时又去查询所属的博客,那么会不会出现循环查询呢?上面案例就是这种情形,实际上,MyBatis通过延迟加载和循环占位符解决了这种循环查询的问题。
![]()
什么是延迟加载呢?首先,在BaseExecutor中有一个queryStack,初始值为0,表示查询栈的深度,即当前是第几层子查询。在开始主查询时(queryFromDataBase->doQuery),queryStack加为1,同时在一级缓存中设置一个key为CacheKey,值为缓存占位符(EXECUTION_PLACEHOLDER)的临时缓存。
![]()
当进行子查询时,会优先判断一级缓存是否已存在要查询的对象,如果存在,则表示出现了循环,那么启用延迟加载,如果不是,则从数据库进行查询(可能会配置懒加载,后面讲)。当主查询执行完毕,清空临时缓存,重新设置真正的缓存值,同时queryStack减为0,这时遍历延迟加载列表,逐一进行加载,即从缓存中拿出真正的值进行填充。
![]()
简单来说,就是利用一级缓存和缓存占位符判断,如果出现了循环查询,则跳过查询,放到主查询执行完毕后统一从缓存拿值进行填充。填充的过程很简单,就是从一级缓存拿值set罢了。
![]()
扩展:一级缓存不能关闭的原因之一
- 优化嵌套子查询重复查询的性能。
- 结合延迟加载机制、缓存占位符、queryStack等来解决循环子查询问题。
子查询懒加载
基本概念
嵌套子查询在某些时候确实非常方便,但必须注意,嵌套子查询可能会导致"N+1"问题:
你执行了一个单独的 SQL 语句来获取结果的一个列表(就是“+1”)。
对列表返回的每条记录,你执行一个 select 查询语句来为每条记录加载详细信息(就是“N”)。
这个问题可能会导致成百上千的 SQL 语句被执行。有时候,我们不希望产生这样的后果。MyBatis 能够对这样的查询进行懒加载,因此可以将大量语句同时运行的开销分散开来。
懒加载就是在必要的时候才进行加载。如查询博客和博客的所有评论,先只把博客加载出来,当在查看评论时,才去数据库加载相关数据。
注意:
- 如果你加载记录列表之后立刻就遍历列表以获取嵌套的数据,就会触发所有的延迟加载查询,性能可能会变得很糟糕。
- 除get外,Configuration的lazyLoadTriggerMethods(Set<String>)中定义下列方法也会触发延迟加载:equals、clone、hashCode、toString。
触发条件
开启全局懒加载属性
lazyLoadingEnabled,以及可选择设置是否所有方法都触发懒加载。
在ResultMap的手动映射配置中配置了嵌套子查询,并设置了延迟加载属性。
调用该属性的set方法,将会移除懒加载属性。
关闭当前会话后仍可以触发懒加载。
![]()
- 使用java原生序列化并指定configuration构造器,反序列化后仍可以触发延迟加载。
![]()
定义configuration构造器如下,并进行指定。
public class ConfigurationFactory {private static Configuration configuration;static {SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(ConfigurationFactory.class.getResourceAsStream("/mybatis-config.xml"));configuration = factory.getConfiguration();}public static Configuration getConfiguration() {return configuration;}
}![]()
注意:在序列化后,对象不能进行远程传输,否则懒加载失效。
代理流程
懒加载原理:通过对JavaBean进行动态代理,当调用equals、clone、hashCode和toString方法时,会判断是否需要从数据库进行加载。
![]()
这个代理是什么时候进行的呢?下面是懒加载代理流程图。
![]()
在DefaultResultSetHandler.createResultObject时,判断存在子查询,则创建代理对象。
![]()
![]()
创建EnhancedResultObjectProxyImpl,传给下一层使用。
![]()
使用javassist的create方法创建代理对象,并设置上一步创建的EnhancedResultObjectProxyImpl。
![]()
懒加载流程
当被替换为代理对象后,当调用相关的方法时,就会触发懒加载。
为了防止Debug时调用toString触发懒加载,可关闭aggressiveLazyLoading全局属性,并在获取configuration后设置懒加载触发方法列表为空configuration.setLazyLoadTriggerMethods,可以观察到懒加载代理后的对象结构如下。
![]()
在原来的 Blog 对象加了个EnhancedResultObjectProxyImpl类型成员变量 handler ,该类实现了MathodHandler接口,用来处理方法代理逻辑。如果是writeReplace方法,则会进行一些序列化相关的处理,否则处理懒加载逻辑。
![]()
其内部 ResultLoaderMap 用于存储待加载的属性,当该属性触发加载或一些其他条件(如set后)导致懒加载失效,则会从ResultLoaderMap移除该属性。
![]()
LoadPair用于准备加载环境,
![]()
![]()
最后ResultLoader从数据库加载数据。
![]()
序列化(扩展)
一个简单的序列化与反序列化的测试案例如下,并且可以在Blog对象内部加上writeReplace和readResolve方法在序列化和反序列化的时候对对象做一些修改。
public class Blog implements Serializable {private Integer id;private String title;private String body;private User author;private List<Comment> comments;private Map<String, String> labels;// 省略getter/setter和toStringprotected final Object writeReplace() throws ObjectStreamException {if (title == null) {title = "Serializable-writeReplace";}return this;}protected final Object readResolve() throws ObjectStreamException {if (title == null || title.equals("Serializable-writeReplace")) {title = "Serializable-readResolve";}return this;}
}
/*** 序列化测试*/@Testpublic void testSerializable() throws IOException, ClassNotFoundException {Blog blog = new Blog();blog.setId(1);// 序列化byte[] bytes = writeObject(blog);// 反序列化Blog blogAfter = (Blog)readObject(bytes);System.out.println(blogAfter);// Blog{id=1, title='Serializable-readResolve', author=null, body='null', comments=null, labels=null}}/*** 序列化** @param obj* @return* @throws IOException*/public static byte[] writeObject(Object obj) throws IOException {ByteArrayOutputStream out = new ByteArrayOutputStream();ObjectOutputStream outputStream = new ObjectOutputStream(out);outputStream.writeObject(obj);return out.toByteArray();}/*** 反序列化** @param bytes* @return* @throws IOException* @throws ClassNotFoundException*/public static Object readObject(byte[] bytes) throws IOException, ClassNotFoundException {ByteArrayInputStream in = new ByteArrayInputStream(bytes);ObjectInputStream inputStream = new ObjectInputStream(in);return inputStream.readObject();}
联合查询和嵌套映射
基本概念
联合查询是指使用 join 关键字进行多表关联查询,查询结果带有多个表的数据,可能无法直接映射到简单的 VO 对象,这时候就需要进行嵌套映射。嵌套映射又分为两种,一种是一对一的嵌套映射。如查询Blog及所属的User,返回结果集如下所示,这时将行中的id、title映射到Blog对象,将user_id和user_name映射到Blog的成员变量user。
![]()
还有一种是一对多的嵌套映射,如查询博客及博客下的所有评论,返回数据格式如下图所示,这时将行中的id、title映射到Blog对象,将comment_id和comment_body映射到Blog的成员变量List<Comment>。
![]()
mybatis是如何知道哪一列映射到哪个对象的呢?
- 这是在ResultMap中配置的,并且可以进行
前缀匹配:columnPrefix在匹配时会添加该前缀与列名匹配限定不为空的列:notNullColumn可以指定一个或多个列,以逗号分隔,如果全部为空,则会忽略改行数据。- 注意:在嵌套映射的场景下,autoMapping=false,自动映射默认关闭。
- 提示:可以在ResultMap中指定id列,则在进行嵌套映射时,优先使用id列进行结果行分组。如果没有指定id列,则使用所有的result配置创建RowKey。例如,上面一对多映射中,将id一致的记录视为同一个Blog对象。
流程分析
下面是 MyBatis 处理嵌套映射的流程图,可以看到嵌套映射时首先会创建一个RowKey,去暂存区读数据,如果不存在则创建对象(Blog),并进行自动映射和手动映射,然后进行复合属性填充。复合属性填充依旧先创建RowKey,流程与前类似。
在读取暂存区的时候,如果根据RowKey找到对象,则表示该对象在之前已经创建过了,直接进入复合属性填充即可。
![]()
下面进行源码跟踪验证,代码和配置摘要如下:
/*** 跟踪代码:嵌套结果映射+循环映射*/@Testpublic void testNestedMapping() {Blog blog = blogMapper.findByIdNestedMappingComments(1); // blog嵌套映射comments,comment内部又映射到当前blogSystem.out.println(blog);} <resultMap id="blogNestedMappingMap" type="org.example.model.Blog" autoMapping="true"><id column="id" property="id"/><result column="title" property="title"/><!-- <result column="body" property="body"/>--><collection property="comments" ofType="org.example.model.Comment" columnPrefix="comment_"><id column="id" property="id"/><result column="blog_id" property="blogId"/><result column="content" property="content"/><association property="blog" resultMap="blogNestedMappingMap"/></collection></resultMap><!-- 据ID查询博客 嵌套映射comments--><select id="findByIdNestedMappingComments" resultMap="blogNestedMappingMap">SELECT blog.id, blog.title, blog.body, comment.id comment_id, comment.blog_id comment_blog_id, comment.content comment_contentFROM blogLEFT JOIN comment ON blog.id = comment.blog_idWHERE blog.id = #{id}</select>
在 DefaultResultSetHandler 的 handleRowValues 打上断点,开始进行跟踪。如果存在嵌套结果集映射,则调用 handleRowValuesForNestedResultMap 处理嵌套结果映射,否则进行之前讲解的简单结果映射。
![]()
处理嵌套结果映射时,对照流程图可以看到,首先创建Rowkey,尝试从暂存区nestedResultObjects读取未映射完成的对象partialObject(如暂未映射comments的Blog对象)。把该对象传给getRowValue继续进行映射,映射完成后继续把该对象保存起来(storeObject)。
![]()
在getRowValue中(嵌套映射的重载形式),如果 partialObject != null,也就是根据RowKey查找到了对象,则直接进行嵌套属性映射(一般在一对多映射的子属性第二次及以上映射)。
如果在暂存区没有找到映射的对象,则先创建对象,进行自动映射和手动映射后再进行嵌套属性映射。
![]()
在applyNestedResultMappings中映射嵌套属性时,又回到了流程图中创建RowKey的逻辑,不过这次的Key是combinedKey。
![]()
解决循环映射
在上面源码跟踪的最后一步,发现又回到了创建RowKey的起始位置。观察上面案例,blogNestedMappingMap中映射comments时,coments内部又引用了blogNestedMappingMap进行blog的映射,这样会不会产生循环映射呢?
MyBatis使用ancestorObjects暂存区解决的循环映射的问题,在进行嵌套属性映射前,以当前resultMapId为key,当前对象为value存入ancestorObjects容器,在嵌套属性映射完成后,再从容器中删除。
![]()
而在 applyNestedResultMappings 中,获取嵌套映射MapnestedResultMap后,先去ancestorObjects中查找,是否与父对象的映射一致,如果是则直接进行linkObjects,不必要再进行combinedKey的创建及后续的getRowValue了。
![]()
MetaObject(补充)
MetaObject是MyBatis底层的一个反射工具类,主要结构和功能如下:
![]()
- MetaObject基本使用
// 1. 查找属性:忽略大小写,支持驼峰,支持子属性// 2. 获取属性值:// 2.1 基于点获取子属性 "user.name"// 2.2 基于索引获取列表值 "users[1].id"// 2.1 基于key获取map值 "user[map]"// 3. 设置属性// 3.1 可设置子属性值// 3.2 支持自动创建子属性(必须带有空参构造方法,且不能是集合)@Testpublic void testMetaObject() {// 装饰BlogBlog blog = new Blog();Configuration configuration = new Configuration();MetaObject metaObject = configuration.newMetaObject(blog);// 数组不能直接创建,需要我们手动创建ArrayList<Comment> comments = new ArrayList<>();comments.add(new Comment());// 设置属性metaObject.setValue("id", 666);metaObject.setValue("author.id", 1);metaObject.setValue("comments", comments);metaObject.setValue("comments[0].content", "不错的博客!");metaObject.setValue("labels", new HashMap<>());metaObject.setValue("labels[red]", "红");// 获取属性System.out.println(metaObject.getValue("id")); // 666System.out.println(metaObject.getValue("author.id")); // 1System.out.println(metaObject.getValue("comments")); // [Comment{user=null, content='不错的博客!'}]System.out.println(metaObject.getValue("comments[0].content")); // 不错的博客!System.out.println(metaObject.getValue("labels")); // {red=红}System.out.println(metaObject.getValue("labels[red]")); // 红// 使用BeanWrapper获取属性BeanWrapper beanWrapper = new BeanWrapper(metaObject, blog);beanWrapper.get(new PropertyTokenizer("comments")); // 获取到 comments 集合 beanWrapper.get(new PropertyTokenizer("comments[0]")); // 获取到 comments[0] ,可以通过索引获取beanWrapper.get(new PropertyTokenizer("comments[0].content")); // 获取到 comments[0] ,不支持获取子属性}- MetaObject源码分析
MetaObject获取属性的流程图如下,在上述案例打上断点跟踪调试看看吧!
![]()
从MetaObject的getValue方法进入后,首先使用PropertyTokenizer类进行分词,再判断是否有子属性。
- 如果有:使用 IndexedName 获取新的 MetaObject对象,传入 children 表达式进行递归。
- 如果没有:则递归结束,调用
BeanWrapper类的 get 方法获取当前对象的指定属性。
![]()
递归完成后如下图所示,简化为使用username从User对象中取值。
![]()
提示:在递归过程中,
metaObjectForProperty(prop.getIndexedName())方法内部需要获取cmments[0]、user等对象构建新的MetaObject,可能多次调用objectWrapper.get(prop),要注意区分!
在BeanWrapper类中,可获取当前对象的属性值,这里没有index,走下面的逻辑。
![]()
再往下就是JDK反射的一些包装了,这里不详细展开讲解,可自行跟踪理解。
![]()
![]()
如果在BeanWrapper中有index,如comments[0],则会先调用MetaObject.getValue获取 collection 对象(传入prop.getName())。
![]()
![]()
获取到集合对象后,根据不同的集合类型,用 index 从集合中拿数据返回。
![]()
![]()
- PropertyTokenizer类
PropertyTokenizer 对输入的表达式(comments[0].user.username)进行分词,拆分为name(comments)、indexedName(comments[0])、index(0)和children(user.username),并实现了迭代器接口,可进行迭代操作,迭代时传入children进行递归。
public PropertyTokenizer next() {return new PropertyTokenizer(children);}动态SQL
基本概念
动态SQL就是每次执行SQL时,基于预先编写的脚本和参数动态的构建可执行SQL语句。
![]()
常用的动态SQL脚本标签有如下几类,具体用法可参考官方文档。
| 类型 | 标签 |
|---|---|
| 逻辑判断 |
<if>
|
| 选择判断 |
<choose>、<when>、<otherwise>
|
| 遍历 |
<foreach>
|
| 字符修剪 |
<trim>、<where>、<set>
|
提示:动态SQL脚本标签是可以相互嵌套的!
解析流程
要想执行XML配置中的动态SQL语句,需要将其先构建为抽象语法树(AST),然后执行脚本表达式进行解析,解析后才得到可真正执行的SQL(BoundSql)。
![]()
抽象语法树表现为一个SQL源(SqlSource),继承结构如上图所示。如果XML中配置的是一个动态SQL,则会转换为DynamicSqlSource,如果是非动态SQL,则转换为RawSqlSource,特殊的,也可以使用第三方脚本语言进行XML到SQL源的转换,转换后的结果是ProviderSqlSource。
DynamicSqlSource
**动态SQL源(DynamicSqlSource)**在创建时仅初始化configuration和rootSqlNode(语法树的根节点),但在每次getBoundSql时都执行下列一些步骤:
- 创建
DynamicContext用于协助语法树的执行。 - 执行语法树,并保存拼接好的SQL到context中。
- 对拼接好的SQL进行解析,如 #{} 替换为 ? 等操作,最后生成一个
StaticSqlSource。 - 从StaticSqlSource中获取boundSql。
- 设置additionParamter,方便在参数映射阶段,如果是foreach标签生成的参数,则从其中取值。
- 返回boundSql。
![]()
RawSqlSource
**非动态SQL源(RawSqlSource)**在创建时进行SQL解析,即把 #{} 替换为 ? 等操作,并生成StaticSqlSource,在每次 getBoundSql 时,直接从 StaticSqlSource 获取可执行SQL即可,无需进行一系列的语法树执行和SQL解析过程,性能更高。
![]()
StaticSqlSource
StaticSqlSource出于设计需要,用于存储解析好的SQL语句,无太大的实际意义。
![]()
BoundSql
BoundSql 包含了一个SQL执行所必需的信息,保存在MappedStatement中,一般作为执行器执行的参数之一。
- sql:预编译SQL语句。如 select * form blog where id = ? 。
- parameterMappings:参数映射配置集合,保存参数设置所需的相关信息,如property、jdbcType、numericScale、typeHandler等。
- parameterObject和metaParameters:传入的参数值及其MetaObject形式。
- additionalParameters:从List从解析出的用于in(?,?)映射的一些参数值。
![]()
构建SqlSource
从上文可知,要执行动态SQL,必须经过两步,第一步是从XML中带标签的SQL构建出语法树,也就是SqlSource。这一步的工作主要是通过XMLScriptBuilder来完成的,准备如下动态SQL案例,在parseScriptNode方法打上断点,进行代码跟踪。
<select id="find" resultMap="blogMap">select * from blog<where><if test="id != null">id = #{id}</if><if test="title != null">title = #{title}</if></where></select>
parseScriptNode的过程主要就是解析动态SQL标签的过程,解析完动态SQL标签后,根据解析结果判断,如果是动态SQL,则创建一个DynamicSqlSource,否则创建RawSqlSource。
![]()
重点是XMLScriptBuilder是如何解析动态SQL标签的,下面是一个执行流程图。
![]()
继续跟入parseDynamicTags进行对比验证。可以看到先解析select * from blog这一段为StaticTextSqlNode,再解析<where>标签节点,从nodeHandlerMap获取对应的节点处理器进行解析。
![]()
nodeHandlerMap初始化如下,当解析<where>元素节点时,获取的是WhereHandler,
![]()
而WhereHandler是NodeHandler的子类之一,handleNode时,又回到了parseDynamicTags进行递归调用,处理子标签,当回归时在外层加上where节点返回。
![]()
经过有限次的递归操作后,最后由XML配置的带标签SQL生成了一个动态SQL源,rootSqlNode属性保存的语法树结构如下。
![]()
执行SqlSource
经过XMLScriptBuilder将XML配置中的带标签SQL转换为SqlSource后,如果SQL语句是一个动态SQL,则会解析为 DynamicSqlSource,我们每次在getBoundSql时都会经行一系列的执行和解析,上文已有提到。但执行语法树的部分我们只是简单略过,下面我们将会详细讲解。
首先来介绍下sqlNode语法树,MyBatis为了方便处理标签中定义的逻辑,遇到元素标签时,通过NodeHandler生成对应的SqlNode加入到语法树,我们只需要从根节点依次执行即可。
与NodeHandler对应,SqlNode有如下一些类型,执行时处理方式各不相同。
![]()
- MixedSqlNode:用来包装其它节点。
- if/trim/foreach分别用来选择/分割/遍历文本
- staticTextSqlNode称为静态文本,纯粹SQL文本,无任何表达式和子标签,解析时会被附加到SQL后。
- textSqlNode是表达式文本,如select * from ${table_name},进行一些字符串替换。
执行语法树需要一个统筹的DynamicContext,负责数据的保存和执行顺序控制。DynamicContext沿着根节点,依次往下执行,执行的过程,就是一个递归的过程。
![]()
注意:语法树只有一个根节点,且每个节点只有一个子节点,通过Mixed节点进行包装实现的。
if节点解析
动态SQL中最常见的标签就是IF标签,IF标签的执行流程如下。首先判断表达式,如果结果为true,则执行子节点的,否则不执行。
通常,子节点是一个静态文本节点,而静态文本节点执行就是把保存的文本加入到DynamicContext。
![]()
案例如下,跟踪代码查看
@Testpublic void ifTest() {User user = new User();user.setId(1);// 创建动态SQL上下文DynamicContext context = new DynamicContext(configuration, user);// 添加静态文本节点new StaticTextSqlNode("select * from user where 1=1").apply(context);// 添加if节点IfSqlNode ifSqlNode = new IfSqlNode(new StaticTextSqlNode("and id = #{id}"), "id != null");ifSqlNode.apply(context);System.out.println(context.getSql()); // select * from user where 1=1 and id = #{id}}
![]()
![]()
![]()
where节点解析详解
where节点用于解决where 1=1问题,它会在子句存在的时候加上where关键字,并去除拼接后的SQL中不必要的AND/OR前缀。
案例如下,跟踪代码查看:
@Testpublic void whereTest() {User user = new User();user.setId(1); // 切换是否注释来查看执行结果user.setUsername("黄原鑫");// 创建动态SQL上下文DynamicContext context = new DynamicContext(configuration, user);// 添加静态文本节点 无where 1=1new StaticTextSqlNode("select * from user ").apply(context);// 添加where节点IfSqlNode ifSqlNode1 = new IfSqlNode(new StaticTextSqlNode(" and id = #{id} "), "id != null");IfSqlNode ifSqlNode2 = new IfSqlNode(new StaticTextSqlNode(" or username = #{username} "), "username != null");MixedSqlNode mixedSqlNode = new MixedSqlNode(Arrays.asList(ifSqlNode1, ifSqlNode2));WhereSqlNode whereSqlNode = new WhereSqlNode(configuration, mixedSqlNode);whereSqlNode.apply(context);System.out.println(context.getSql()); // select * from user WHERE id = #{id} or username = #{username}}WhereSqlNode在实现上直接继承了TrimSqlNode,并进行了前缀的初始化。
![]()
我们跟踪代码可以看到,直接进入了TrimSqlNode的代码,由于要对拼接后的SQL进行修剪,因此TrimSqlNode先将拼接结果放在一个临时的上下文FilteredDynamicContext中。
![]()
![]()
所有子节点都解析完成后,再在applyAll中解决前缀和后缀问题,最后添加到真正的上下文中。
![]()
foreach节点解析详解
foreachSqlNode用于处理in(?,?)语法的参数映射,执行流程图如下所示。
![]()
准备案例如下:
@Testpublic void foreachTest() {HashMap<Object, Object> parameter = new HashMap<>();parameter.put("ids", Arrays.asList(1, 2, 3, 4));session.selectList("org.example.dao.BlogMapper.findByIds", parameter); // select * from blog where id in ( ? , ? , ? , ? )}@Testpublic void foreachTest() {List<Integer> list = Arrays.asList(1, 2, 3, 4);List<Blog> blogList = blogMapper.findByIds(list);System.out.println(blogList);}
<select id="findByIds" resultMap="blogMap">select * from blogwhere id in<foreach collection="ids" open="(" item="id" separator="," close=")">#{id}</foreach></select>
在DynamicSqlsource.getBoundSql中打上条件断点查看。
![]()
循环处理所有节点
![]()
我们可以直接把断点打在ForEachSqlNode.apply中,对比流程图进行验证。
![]()
![]()
转换后的参数映射如图所示,新增了一些_frch_id_开头的映射配置。
![]()
OGNL表达式(扩展)
对象导航图语言(OGNL)是一种开源的JAVA表达式语言,可以方便的存取对象属性和调用方法。下面是一个OGNL表达式的案例:
@Testpublic void ognlTest() {ExpressionEvaluator evaluator = new ExpressionEvaluator();Comment comment = new Comment();comment.setId(10);comment.setBlog(new Blog());comment.setContent("这文章也的也太好了!");ArrayList<Comment> comments = new ArrayList<>();comments.add(comment);Blog blog = new Blog();blog.setId(1);blog.setAuthor(new User());blog.setComments(comments);// 1. 访问属性boolean b1 = evaluator.evaluateBoolean("id != null && author.username == null", blog);System.out.println(b1); //true// 2. 访问集合属性boolean b2 = evaluator.evaluateBoolean("comments[0].id > 0", blog);System.out.println(b2);// 3. 调用无参方法boolean b3 = evaluator.evaluateBoolean("isHasComment == true && isHasComment() == true", blog);System.out.println(b3);// 4. 调用带参方法boolean b4 = evaluator.evaluateBoolean("findCommentContent(0).equals(\"这文章也的也太好了!\")", blog);System.out.println(b4);// 5. 遍历集合Iterable<?> iterable = evaluator.evaluateIterable("comments", blog);for (Object obj : iterable) {System.out.println(obj);}// 6. 注意:防止出现空指针异常!evaluator.evaluateBoolean("body.length() > 0", blog); // java.lang.NullPointerException: target is null for method length}
为什么OGNL表达式这么强大了,MyBatis还需要开发MetaObject工具类?
答:MetaObject不需要解析表达式,直接使用反射调用,性能更高。
Configuration配置体系
配置元素概览
Configuration 是整个MyBatis的配置体系集中管理中心,前面所学Executor、StatementHandler、Cache、MappedStatement…等绝大部分组件都是由它直接或间接的创建和管理。此外影响这些组件行为的属性配置也是由它进行保存和维护。如cacheEnabled、lazyLoadingEnabled … 等。
Configuration 配置信息来源于xml和注解,每个文件和注解都是由若干个配置元素组成,并呈现嵌套关系,总体关系如下图所示:
![]()
为什么要抽出
@Option注解呢?
答:让CURD标签的配置看起来不要那么乱,并且可以给四个标签进行复用。
主要作用
Configuration 配置来源有三项:
Mybatis-config.xml:启动文件,全局配置、全局组件都是来源于此。
Mapper.xml: SQL映射(MappedStatement)/结果集映射(ResultMapper)都来源于此。
@Annotation:SQL映射与结果集映射的另一种表达形式。
总结一下Configuration主要作用如下:
- 存储全局配置信息,其来源于settings。
- 初始化并维护全局基础组件。包括typeAliases、typeHandlers、plugins、environments和cache(二级缓存空间)等。
- 初始化并维护MappedStatement
- 组件构造器,并基于插件进行增强。包括newExecutor、newStatementHandler、newResultSetHandler和newParameterHandler等。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OvBfO0oN-1626662417918)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/%E4%BC%81%E4%B8%9A%E5%BE%AE%E4%BF%A1%E6%88%AA%E5%9B%BE_16244589404958(2)].png)
为什么要在Configuration中进行上述四个组件的创建?
答:为了创建标准化的组件,统一进行装饰,以及嵌入插件的逻辑。
组件解析过程
无论是xml 还是注解这些配置元素最终都要被转换成JAVA配置属性或对象组件来承载。其对应关系如下:
- 全局配置(mybatis-config.xml)由Configuration对像属性承载。
- sql映射<select|insert…> 或@Select等由MappedStatement对象承载。
- 缓存<cache…>或@CacheNamespace由Cache对象承载。
- 结果集映射由ResultMap对象承载。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-St9tzVIF-1626662417919)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/%E4%BC%81%E4%B8%9A%E5%BE%AE%E4%BF%A1%E6%88%AA%E5%9B%BE_16244594891799(1)].png)
MyBatis在SqlSessionFactoryBuilder.bulid(is)时对mybatis-config.xml进行解析,继而解析Mapper映射文件和Mapper注解配置。解析流程图如下。
可以使用daoyou/daoyou登录网站(http://www.coderead.cn/p/mybatis/map/file/%E5%88%9D%E5%A7%8B%E5%8C%96.map)进行查看。
![]()
配置文件解析需要我们分开讨论,首先来分析XML解析过程。xml配置解析其底层使用dom4j先解析成一棵节点树,然后根据不同的节点类型与去匹配不同的解析器。最终解析成特定组件。
解析器的基类是BaseBuilder,其内部包含全局的configuration 对象,这么做的用意是所有要解析的组件最后都要集中归属至configuration。
接下来了解一下每个解析器的作用:
- XMLConfigBuilder :解析mybatis-config.xml文件,会直接创建一个configuration对象,用于解析全局配置 。
- XMLMapperBuilder :解析XxxxMapper.xml文件,内容包含 等
- MapperBuilderAssistant:XxxxMapper.xml解析辅助。在一个XxxxMapper.xml中Cache是对Statement共享的,共享组件的分配即由该解析实现。
- XMLStatementBuilder:SQL映射解析 即<select|update|insert|delete> 元素解析成MapperStatement。
- SqlSourceBuilder:Sql数据源解析,将声明的SQL解析可执行的SQL。
- XMLScriptBuilder:解析动态SQL数据源当中所设置SqlNode脚本集。
我们先在SqlSessionFactoryBuilder.build()中打上断点进行跟踪。
// TODO SqlSessionFactoryBuilder.build()流程截图
MapperStatement注解的解析过程
注解解析底层实现是通过反射获取Mapper接口当中注解元素实现。有两种方式一种是直接指定接口名,一种是指定包名然后自动扫描包下所有的接口类。这些逻辑均由Mapper注册器(MapperRegistry)实现。其接收一个接口类参数,并基于该参数创建针对该接口的动态代理工厂,然后解析内部方法注解生成每个MapperStatement 最后添加至Configuration 完成解析。流程图如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9mpya1NS-1626662417921)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/%E4%BC%81%E4%B8%9A%E5%BE%AE%E4%BF%A1%E6%88%AA%E5%9B%BE_16244606695085(1)].png)
MappeedStatement XML解析过程
整体解析流程是从XmlConfigBuilder开始,然后逐步向内解析,直到解析完所有节点。我们通过一个MappedStatement 解析过程即可了解到期整体解析流程。
- XmlConfigBuilder 接收一个mybatis-config.xml 输入流,然后创建一个空Configuration对象。
- XmlConfigBuilder 解析全局配置。
- XmlConfigBuilder mapperElements解析,通过Resource或url 指定mapper.xml文件。
- XmlMapperBuilder 解析缓存、结果集配置等公共配置。
- XmlStatementBuilder解析Sql映射<select|insert|upate|delete>。
- XMLScriptBuilder 解析生成SQL数据源,包括动态脚本。
- XmlStatementBuilder构建Statement。
- MapperBuilderAssistant设置缓存并添加至Configuration。
- XmlStatementBuilder解析Sql映射<select|insert|upate|delete>。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MU9GVF5x-1626662417923)(https://hyx-images.oss-cn-shenzhen.aliyuncs.com/typora-img/%E4%BC%81%E4%B8%9A%E5%BE%AE%E4%BF%A1%E6%88%AA%E5%9B%BE_16244612864194(1)].png)
插件机制
插件概述
插件机制是为了对MyBatis现有体系进行扩展 而提供的入口。底层通过动态代理实现。可供代理拦截的接口有四个:
- Executor (update, query, flushStatements, commit, rollback, getTransaction, close, isClosed)
- ParameterHandler (getParameterObject, setParameters)
- ResultSetHandler (handleResultSets, handleOutputParameters)
- StatementHandler (prepare, parameterize, batch, update, query)
这四个接口已经涵盖从发起接口调用到SQl声明、参数处理、结果集处理的全部流程。接口中任何一个方法都可以进行拦截改变方法原有属性和行为。不过这是一个非常危险的行为,稍不注意就会破坏MyBatis核心逻辑还不自知。所以在在使用插件之前一定要非常清晰MyBatis内部机制。
![]()
插件的使用
创建一个插件在MyBatis当中是一件非常简单的事情 ,只需实现 Interceptor 接口,并指定想要拦截的方法签名。
@Intercepts({@Signature(type= Executor.class,method = "update",args = {MappedStatement.class,Object.class})})
public class ExamplePlugin implements Interceptor {// 当执行目标方法时会被方法拦截public Object intercept(Invocation invocation) throws Throwable {long begin = System.currentTimeMillis();try {return invocation.proceed();// 继续执行原逻辑;} finally {System.out.println("执行时间:"+(System.currentTimeMillis() - begin));}}/**生成代理对象(也可自定义生成代理对象,这样就无需配置@Intercepts注解。另外需要自行判断是否为拦截目标接口)*/public Object plugin(Object target) {return Plugin.wrap(target,this);// 调用通用插件代理生成}
}
然后在config.xml 中添加插件配置,就可以通过插件监控SQL在执行过修改过程当中,所耗费的时间。
<plugins><plugin interceptor="org.mybatis.example.ExamplePlugin"/>
</plugins>
注意:只有从外部类调用拦截目标时拦截才会生效,如果在内部调用代理逻辑不会生效。
如在Executor中有两个Query 方法,第一个会调用第二个query。如果你拦截的是第二个Query 则不会成功。
自动分页插件
MyBatis 插件拦截实现类似Spring AOP 但其实现要简单很多。代理很轻量清晰,连注释都显得多余。接下来通过一个自动分页插件全面掌握插件的用法。自动分页是指查询时,指定页码和大小 等参数,插件就自动进行分页查询,并返回总数量。这个插件设计需要满足以下目特性:
易用性:不需要额外配置,参数中带上 Page 即可。Page尽可能简单
不对使用场景作假设:不限制用户使用方式,如接口调用,还是会话调。又或是对Executor 以及StatementHandler的选择等。不能影响缓存业务
友好性:当不符合分页情况下,作出友好的用户提示。如在修改操作中付入分页参数。或用户本身已在查询语句已自带分页语句 ,这种情况应作出提示。
接下来要解决的问题,是插件的入口写在哪里?去拦截的目标有哪些?
![]()
参数处理器 和结果集处理器显然不合适,而Executor.query() 又需要额外考虑 一、二级缓存逻辑。最后还是选定StatementHandler. 并拦截其prepare 方法。
@Intercepts(@Signature(type = StatementHandler.class,method = "prepare", args = {Connection.class,Integer.class}))
首先设定一个Page类,其包含total、size、index 3个属性,在Mapper接口中声明该参数即表示需要执行自动分页逻辑。
public class Page {private long total;private long size;private long index;// 省略getter/setter
}
接下来,插件具体实现步骤如下:
1) 检测是否满足分页条件
分页条件是 :
- 是否为查询方法
- 查询参数中是否带上Page参数。
在intercept 方法中可直接获得拦截目标StatementHandler ,通过它又可以获得BoundSql 里面就包含了SQL 和参数。遍历参数即可获得Page。
// 带上分页参数
StatementHandler target = (StatementHandler) invocation.getTarget();
// SQL包 sql、参数、参数映射
BoundSql boundSql = target.getBoundSql();
Object parameterObject = boundSql.getParameterObject();
Page page = null;
if (parameterObject instanceof Page) {page = (Page) parameterObject;
} else if (parameterObject instanceof Map) {page = (Page) ((Map) parameterObject).values().stream().filter(v -> v instanceof Page).findFirst().orElse(null);
}2) 查询总行数
实现逻辑是 将原查询SQL作为子查询进行包装成子查询,然后用原有参数,还是能过原来的参数处理器进行赋值。关于执行是采用JDBC 原生API实现。MyBatis执行器,从而绕开了一二级缓存。
private int selectCount(Invocation invocation) throws SQLException {int count = 0;StatementHandler target = (StatementHandler) invocation.getTarget();// SQL包 sql、参数、参数映射String countSql = String.format("select count(*) from (%s) as _page", target.getBoundSql().getSql());// JDBCConnection connection = (Connection) invocation.getArgs()[0];PreparedStatement preparedStatement = connection.prepareStatement(countSql);target.getParameterHandler().setParameters(preparedStatement);ResultSet resultSet = preparedStatement.executeQuery();if (resultSet.next()) {count = resultSet.getInt(1);}resultSet.close();preparedStatement.close();return count;
}3) 修改原SQL
最后一项就是修改原来的SQL,前面我是可以拿到BoundSql 的,但它没有提供修改SQL的方法,这里可以采用反射强行为SQL属性赋值。也可以采用MyBatis提供的工具类SystemMetaObject 来 赋值
if (page != null){page.setTotal(selectCount(invocation));String newSql = boundSql.getSql() + " limit " + page.getSize() + " offset " + page.getOffset();SystemMetaObject.forObject(boundSql).setValue("sql", newSql);
}return invocation.proceed();
插件代理机制
为什么MyBatis能对这四个类进行拦截呢?因为这个四个类统一由Configuration来创建的,使用了简单工厂模式,所以在创建时有机会对其进行改造。
![]()
Configuration 中有一个InterceptorChain保存了所有配置的拦截器,当创建四大对象之后就会调用拦截链,对目标对象进行拦截代理。
![]()
拦截处理十分简单,就是遍历所有的拦截器,调用其plugin方法。
![]()
而plugin方法的默认实现就是调用默认的插件代理对目标进行包装(或者使用静态代理方式)。
![]()
包装的过程就是获取所有的接口,然后创建JDK代理对象,使用Plugin作为InvocationHandler,则当代理对象执行的时候,就会调用Plugin的invoke方法。
![]()
如果是拦截方法,则调用插件的intercept方法,执行拦截逻辑。否则直接放行。
![]()
其它
日志体系
MyBatis学习笔记-源码分析篇相关推荐
- C++Primer Plus (第六版)阅读笔记 + 源码分析【目录汇总】
C++Primer Plus (第六版)阅读笔记 + 源码分析[第一章:预备知识] C++Primer Plus (第六版)阅读笔记 + 源码分析[第二章:开始学习C++] C++Primer Plu ...
- LIVE555再学习 -- testOnDemandRTSPServer 源码分析
一.简介 先看一下官网上的介绍: testOnDemandRTSPServercreates a RTSP server that can stream, via RTP unicast, from ...
- 一箭双雕 刷完阿里P8架构师spring学习笔记+源码剖析,涨薪8K
关于Spring的叙述: 我之前死磕spring的时候,刷各种资料看的我是一头雾水的,后面从阿里的P8架构师那里拿到这两份资料,从源码到案例详细的讲述了spring的各个细节,是我学Spring的启蒙 ...
- LIVE555再学习 -- testH264VideoStreamer 源码分析
上一篇文章我们已经讲了一部分: testH264VideoStreamer 重复从 H.264 基本流视频文件(名为"test.264")中读取,并使用 RTP 多播进行流式传输. ...
- 开启mybatis日志_Mybatis源码分析之Cache二级缓存原理 (五)
一:Cache类的介绍 讲解缓存之前我们需要先了解一下Cache接口以及实现MyBatis定义了一个org.apache.ibatis.cache.Cache接口作为其Cache提供者的SPI(Ser ...
- View事件分发机制(源码分析篇)
01.Android中事件分发顺序 1.1 事件分发的对象是谁 事件分发的对象是事件.注意,事件分发是向下传递的,也就是父到子的顺序. 当用户触摸屏幕时(View或ViewGroup派生的控件),将产 ...
- LIVE555再学习 -- testRTSPClient 源码分析
现在开讲 testRTSPClient.在官网这这样一段介绍,参看:RTSP client 翻译下来就是: testRTSPClient 是一个命令行程序,显示如何打开和接收由 RTSP URL 指定 ...
- LIVE555再学习 -- OpenRTSP 源码分析
看了很多东西,感觉有点杂.源码分析部分也看了,讲的也就那样.现在有点不知道从哪讲起了. 参看:nkmnkm的专栏-流媒体 参看:smilestone322的专栏-live555 一.源码组成 包括上述 ...
- Java学习集合源码分析
集合源码分析 1.集合存在的原因 可以用数组来表示集合,那为什么还需要集合? 1)数组的缺陷 在创建数组时,必须指定长度,一旦指定便不能改变 数组保存必须是同一个类型的数据 数组的增加和删除不方便 ...
最新文章
- golang 数组与切片
- how is my real odata request hijacked by Mock server
- cf1555A. PizzaForces
- Android Studio类中实现Serializable自动生成serialVersionUID
- MFC SendMessage与PostMessage区别
- 开源视频处理工具Shotcut的用法: 剪切、合并、增加背景音乐、添加字幕、 插入视频、图片转视频并加背景音乐、制作电子相册
- 大数据hadoop学习【9】-----通过JAVA语言编程,实现对Hbase数据库表及数据的相关操作
- 【MySQL 实战】02. 一条SQL 更新语句是如何具体执行的呢?
- 服务器如何与智能家居通讯协议,智能家居通信协议优缺点比较
- BugkuCTF 秋名山老司机wp
- 机器学习-周志华总结
- ADV7441驱动EDID配置及声音问题
- firefox插件推荐
- 160个CrackMe 077 firework2
- 【编程题】【Scratch三级】2019.09 打气球游戏
- prezi中文输入法使用教程
- 皮球从某给定高度自由落下,触地后反弹到原高度的一半,再落下,再反弹,……,如此反复。问皮球在第n次落地时,在空中一共经过多少距离?第n次反弹的高度是多少?
- 【PHP】Windows下最直接最简单查看PHP版本的方法
- 6.s081 lab 4
- 第15讲 布尔函数标准型及化简