前端内存优化的探索与实践
引言
标注是地图最基本的元素之一,标明了地图每个位置或线路的名称。在地图 JSAPI 中,标注的展示效果及性能也是需要重点解决的问题。
新版地图标注的设计中,引入了 SDF ( signed distance field)重构了整个标注部分的代码。新的方式需要把标注的位置偏移,避让,三角拆分等全部由前端进行计算,不仅计算量激增,内存的消耗也成了重点关注的问题之一。
![]()
例如,3D 场景下需要构建大量的顶点坐标,一万左右的带文字的标注,数据量大约会达到 8 (attributes) 5 (1个图标 + 4个字) 6(个顶点) 1E4 ,约为 250w 个顶点,使用 Float32Array 存储,需要的空间约为 2.5E6 4(byte)空间(海量地图标注 DEMO)。前端这样大量的存储消耗,需要对内存的使用十分小心谨慎。于是借此机会研究了一下前端内存相关的问题,以便在开发过程中做出更优的选择,减少内存消耗,提高程序性能。
01 前端内存使用概述
首先我们来了解一下内存的结构。
内存结构
内存分为堆(heap)和栈(stack),堆内存存储复杂的数据类型,栈内存则存储简单数据类型,方便快速写入和读取数据。在访问数据时,先从栈内寻找相应数据的存储地址,再根据获得的地址,找到堆内该变量真正存储的内容读取出来。
在前端中,被存储在栈内的数据包括小数值型,string ,boolean 和复杂类型的地址索引。
所谓小数值数据(small number), 即长度短于 32 位存储空间的 number 型数据。
一些复杂的数据类型,诸如 Array,Object 等,是被存在堆中的。如果我们要获取一个已存储的对象 A,会先从栈中找到这个变量存储的地址,再根据该地址找到堆中相应的数据。如图:
![]()
简单的数据类型由于存储在栈中,读取写入速度相对复杂类型(存在堆中)会更快些。下面的 Demo 对比了存在堆中和栈中的写入性能:
function inStack(){let number = 1E5;var a;while(number--){a = 1;}
}var obj = {};
function inHeap(){let number = 1E5;while(number--){obj.key = 1;}
}实验环境1:
mac OS/firefox v66.0.2
对比结果:
![]()
实验环境2:
mac OS/safari v11.1(13605.1.33.1.2)
对比结果:
![]()
在每个函数运行 10w 次的数据量下,可以看出在栈中的写入操作是快于堆的。
对象及数组的存储
在JS中,一个对象可以任意添加和移除属性,似乎没有限制(实际上需要不能大于 2^32 个属性)。而JS中的数组,不仅是变长的,可以随意添加删除数组元素,每个元素的数据类型也可以完全不一样,更不一般的是,这个数组还可以像普通的对象一样,在上面挂载任意属性,这都是为什么呢?
Object 存储
首先了解一下,JS是如何存储一个对象的。
JS在设计复杂类型存储的时候面临的最直观的问题就是,选择一种数据结构,需要在读取,插入和删除三个方面都有较高的性能。
数组形式的结构,读取和顺序写入的速度最快,但插入和删除的效率都非常低下;
链表结构,移除和插入的效率非常高,但是读取效率过低,也不可取;
复杂一些的树结构等等,虽然不同的树结构有不同的优点,但都绕不过建树时较复杂,导致初始化效率低下;
综上所属,JS 选择了一个初始化,查询和插入删除都能有较好,但不是最好的性能的数据结构 -- 哈希表。
哈希表
哈希表存储是一种常见的数据结构。所谓哈希映射,是把任意长度的输入通过散列算法变换成固定长度的输出。
对于一个 JS 对象,每一个属性,都按照一定的哈希映射规则,映射到不同的存储地址上。在我们寻找该属性时,也是通过这个映射方式,找到存储位置。当然,这个映射算法一定不能过于复杂,这会使映射效率低下;但也不能太简单,过于简单的映射方式,会导致无法将变量均匀的映射到一片连续的存储空间内,而造成频繁的哈希碰撞。
关于哈希的映射算法有很多著名的解决方案,此处不再展开。
哈希碰撞
所谓哈希碰撞,指的是在经过哈希映射计算后,被映射到了相同的地址,这样就形成了哈希碰撞。想要解决哈希碰撞,则需要对同样被映射过来的新变量进行处理。
众所周知,JS 的对象是可变的,属性可在任意时候(大部分情况下)添加和删除。在最开始给一个对象分配内存时,如果不想出现哈希碰撞问题,则需要分配巨大的连续存储空间。但大部分的对象所包含的属性一般都不会很长,这就导致了极大的空间浪费。
但是如果一开始分配的内存较少,随着属性数量的增加,必定会出现哈希碰撞,那如何解决哈希碰撞问题呢?
对于哈希碰撞问题,比较经典的解决方法有如下几种:
- 开放寻址法
- 再哈希法
- 拉链法
这几种方式均各有优略,由于本文不是重点讲述哈希碰撞便不再缀余。
在 JS 中,选择的是拉链法解决哈希碰撞。所谓拉链法,是将通过一定算法得到的相同映射地址的值,用链表的形式存储起来。如图所示(以倾斜的箭头表明链表动态分配,并非连续的内存空间):
![]()
映射后的地址空间存储的是一个链表的指针,一个链表的每个单元,存储着该属性的 key, value 和下一个元素的指针;
这种存储的方式的好处是,最开始不需要分配较大的存储空间,新添加的属性只要动态分配内存即可;
对于索引,添加和移除都有相对较好的性能;
通过上述介绍,也就解释了这个小节最开始提出的为何JS 的对象如此灵活的疑问。
Array 存储
JS 的数组为何也比其他语言的数组更加灵活呢?因为 JS 的 Array 的对象,就是一种特殊类型的数组!
所谓特殊类型,就是指在 Array 中,每一个属性的 key 就是这个属性的 index;而这个对象还有 .length 属性;还有 concat, slice, push, pop 等方法;
于是这就解释了:
为何 JS 的数组每个数据类型都可以不一样?
因为他就是个对象,每条数据都是一个新分配的类型连入链表中;为何 JS 的数组无需提前设置长度,是可变数组?
答案同上;为何数组可以像 Object 一样挂载任意属性?
因为他就是个对象;
等等一系列的问题。
内存攻击
当然,选择任何一种数据存储方式,都会有其不利的一面。这种哈希的拉链算法在极端情况下也会造成严重的内存消耗。
我们知道,良好的散列映射算法,可以讲数据均匀的映射到不同的地址。但如果我们掌握了这种映射规律而将不同的数据都映射到相同的地址所对应的链表中去,并且数据量足够大,将造成内存的严重损耗。读取和插入一条数据会中了链表的缺陷,从而变得异常的慢,最终拖垮内存。这就是我们所说的内存攻击。
构造一个 JSON 对象,使该对象的 key 大量命中同一个地址指向的列表,附件为 JS 代码,只包含了一个特意构造的对象(引用出处),图二为利用 Performance 查看的性能截图:
![]()
相同 size 对象的 Performance 对比图:
![]()
根据 Performance 的截图来看,仅仅是 load 一个 size 为 65535 的对象,竟然足足花费了 40 s!而相同大小的非共计数据的运行时间可忽略不计。
如果被用户利用了这个漏洞,构建更长的 JSON 数据,可以直接把服务端的内存打满,导致服务不可用。这些地方都需要开发者有意识的避免。
但从本文的来看,这个示例也很好的验证了我们上面所说的对象的存储形式。
02 视图类型(连续内存)
通过上面的介绍与实验可以知道,我们使用的数组实际上是伪数组。这种伪数组给我们的操作带来了极大的方便性,但这种实现方式也带来了另一个问题,及无法达到数组快速索引的极致,像文章开头时所说的上百万的数据量的情况下,每次新添加一条数据都需要动态分配内存空间,数据索引时都要遍历链表索引造成的性能浪费会变得异常的明显。
好在 ES6 中,JS 新提供了一种获得真正数组的方式:ArrayBuffer,TypedArray 和 DataView
ArrayBuffer
ArrayBuffer 代表分配的一段定长的连续内存块。但是我们无法直接对该内存块进行操作,只能通过 TypedArray 和 DataView 来对其操作。
TypedArrayTypeArray 是一个统称,他包含 Int8Array / Int16Array / Int32Array / Float32Array等等。
拿 Int8Array 来举例,这个对象可拆分为三个部分:Int、8、Array
首先这是一个数组,这个数据里存储的是有符号的整形数据,每条数据占 8 个比特位,及该数据里的每个元素可表示的最大数值是 2^7 = 128 , 最高位为符号位。
// TypedArray
var typedArray = new Int8Array(10);typedArray[0] = 8;
typedArray[1] = 127;
typedArray[2] = 128;
typedArray[3] = 256;console.log("typedArray"," -- ", typedArray );
//Int8Array(10) [8, 127, -128, 0, 0, 0, 0, 0, 0, 0]``` 其他类型也都以此类推,可以存储的数据越长,所占的内存空间也就越大。这也要求在使用 TypedArray 时,对你的数据非常了解,在满足条件的情况下尽量使用占较少内存的类型。DataViewDataView 相对 TypedArray 来说更加的灵活。每一个 TypedArray 数组的元素都是定长的数据类型,如 Int8Array 只能存储 Int8 类型;但是 DataView 却可以在传递一个 ArrayBuffer 后,动态分配每一个元素的长度,即存不同长度及类型的数据。
// DataView
var arrayBuffer = new ArrayBuffer(8 * 10);
var dataView = new DataView(arrayBuffer);
dataView.setInt8(0, 2);
dataView.setFloat32(8, 65535);
// 从偏移位置开始获取不同数据
dataView.getInt8(0);
// 2
dataView.getFloat32(8);
// 65535
TypedArray 与 DataView 性能对比DataView 在提供了更加灵活的数据存储的同时,最大限度的节省了内存,但也牺牲了一部分性能,同样的 DataView 和 TypedArray 性能对比如下:// 普通数组
function arrayFunc(){
var length = 2E6;
var array = [];
var index = 0;while(length--){array[index] = 10;index ++;
}}
// dataView
function dataViewFunc(){
var length = 2E6;
var arrayBuffer = new ArrayBuffer(length);
var dataView = new DataView(arrayBuffer);
var index = 0;while(length--){dataView.setInt8(index, 10);index ++;
}}
// typedArray
function typedArrayFunc(){
var length = 2E6;
var typedArray = new Int8Array(length);
var index = 0;while(length--){typedArray[index++] = 10;
}}
实验环境1:
mac OS/safari v11.1(13605.1.33.1.2)
对比结果:实验环境2:mac OS/firefox v66.0.2对比结果:在 Safari 和 firefox 下,DataView 的性能还不如普通数组快。所以在条件允许的情况下,开发者还是尽量使用 TypedArray 来达到更好的性能效果。当然,这种对比并不是一成不变的。比如,谷歌的 V8 引擎已经在最近的升级版本中,解决了 DataView 在操作时的性能问题。DataView 最大的性能问题在于将 JS 转成 C++ 过程的性能浪费。而谷歌将该部分使用 CSA( CodeStubAssembler)语言重写后,可以直接操作 TurboFan(V8 引擎)来避免转换时带来的性能损耗。实验环境3:
mac OS / chrome v73.0.3683.86
对比结果: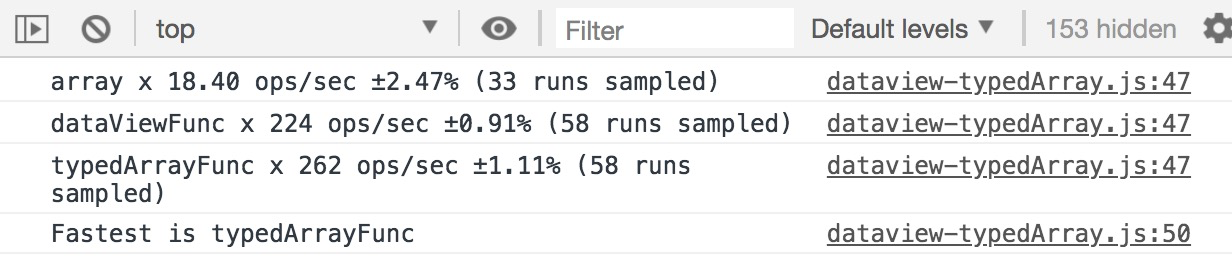可见在 chrome 的优化下,DataView 与 TypedArray 性能差距已经不大了,在需求需要变长数据保存的情况下,DataView 会比 TypedArray 节省更多内存。具体性能对比:
https://v8.dev/blog/dataview# 03 共享内存(多线程通讯)共享内存介绍说到内存还不得不提的一部分内容则是共享内存机制。JS 的所有任务都是运行在主线程内的,通过上面的视图,我们可以获得一定性能上的提升。但是当程序变得过于复杂时,我们希望通过 webworker 来开启新的独立线程,完成独立计算。开启新的线程伴随而来的问题就是通讯问题。webworker 的 postMessage 可以帮助我们完成通信,但是这种通信机制是将数据从一部分内存空间复制到主线程的内存下。这个赋值过程就会造成性能的消耗。而共享内存,顾名思义,可以让我们在不同的线程间,共享一块内存,这些现成都可以对内存进行操作,也可以读取这块内存。省去了赋值数据的过程,不言而喻,整个性能会有较大幅度的提升。使用原始的 postMessage 方法进行数据传输main.js
// main
var worker = new Worker('./worker.js');
worker.onmessage = function getMessageFromWorker(e){
// 被改造后的数据,与原数据对比,表明数据是被克隆了一份
console.log("e.data"," -- ", e.data );
// [2, 3, 4]// msg 依旧是原本的 msg,没有任何改变
console.log("msg"," -- ", msg );
// [1, 2, 3]};
var msg = [1, 2, 3];
worker.postMessage(msg);
worker.js
// worker
onmessage = function(e){
var newData = increaseData(e.data);
postMessage(newData);};
function increaseData(data){
for(let i = 0; i < data.length; i++){data[i] += 1;
}return data;}
由上述代码可知,每一个消息内的数据在不同的线程中,都是被克隆一份以后再传输的。数据量越大,数据传输速度越慢。使用 sharedBufferArray 的消息传递main.jsvar worker = new Worker('./sharedArrayBufferWorker.js');
worker.onmessage = function(e){
// 传回到主线程已经被计算过的数据
console.log("e.data"," -- ", e.data );
// SharedArrayBuffer(3) {}
// 和传统的 postMessage 方式对比,发现主线程的原始数据发生了改变
console.log("int8Array-outer"," -- ", int8Array );
// Int8Array(3) [2, 3, 4]};
var sharedArrayBuffer = new SharedArrayBuffer(3);
var int8Array = new Int8Array(sharedArrayBuffer);
int8Array[0] = 1;
int8Array[1] = 2;
int8Array[2] = 3;
worker.postMessage(sharedArrayBuffer);
worker.js
onmessage = function(e){
var arrayData = increaseData(e.data);
postMessage(arrayData);};
function increaseData(arrayData){
var int8Array = new Int8Array(arrayData);
for(let i = 0; i < int8Array.length; i++){int8Array[i] += 1;
}return arrayData;}
通过共享内存传递的数据,在 worker 中改变了数据以后,主线程的原始数据也被改变了。性能对比实验环境1:mac OS/chrome v73.0.3683.86, 10w 条数据对比结果: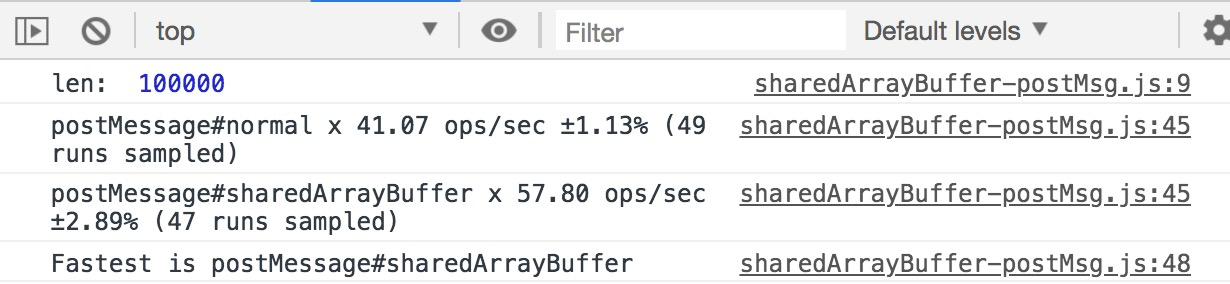实验环境2:mac OS/chrome v73.0.3683.86,100w 条数据对比结果:从对比图中来看,10w 数量级的数据量,sharedArrayBuffer 并没有太明显的优势,但在百万数据量时,差异变得异常的明显了。SharedArrayBuffer 不仅可以在 webworker 中使用,在 wasm 中,也能使用共享内存进行通信。在这项技术使我们的性能得到大幅度的提升时,也没有让数据传输成为性能瓶颈。但比较可惜的一点是,SharedArrayBuffer 的兼容性比较差,只有 chrome 68 以上支持,firefox 在最新版本中虽然支持,但需要用户主动开启;在 safari 中甚至还不支持该对象。# 04 内存检测及垃圾回收机制为了保证内存相关问题的完整性,不能拉下内存检测及垃圾回收机制。不过这两个内容都有非常多介绍的文章,这里不再详细介绍。内存检测介绍了前端内存及相关性能及使用优化后。最重要的一个环节就是如何检测我们的内存占用了。chrome 中通常都是使用控制台的 Memory 来进行内存检测及分析。使用内存检测的方式参见:https://developers.google.com/web/tools/chrome-devtools/memory-problems/heap-snapshots?hl=zh-cn垃圾回收机制JS 语言并不像诸如 C++ 一样需要手动分配内存和释放内存,而是有自己一套动态 GC 策略的。通常的垃圾回收机制有很多种。前端用到的方式为标记清除法,可以解决循环引用的问题:
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Memory_Management#垃圾回收# 05 结束语在了解了前端内存相关机制后,创建任意数据类型时,我们可以在贴近场景的情况下去选择更合适的方式保有数据。例如:在数据量不是很大的情况下,选择操作更加灵活的普通数组;在大数据量下,选择一次性分配连续内存块的类型数组或者 DataView;不同线程间通讯,数据量较大时采用 sharedBufferArray 共享数组;使用 Memory来检测是否存在内存问题,了解了垃圾回收机制,减少不必要的 GC 触发的 CPU 消耗。再结合我们的地图标注改版来说,为了节省内存动态分配造成的消耗,量级巨大的数据均采用的 TypedArray 来存储。另外,大部分的数据处理,也都在 worker 内进行。为了减少 GC,将大量的循环内变量声明全部改成外部一次性的声明等等,这些都对我们的性能提升有了很大的帮助。最后,这些性能测试的最终结果并非一成不变(如上面 chrome 做的优化),但原理基本相同。所以,如果在不同的时期和不同的平台上想要得到相对准确的性能分析,还是自己手动写测试用例来得靠谱。原文链接
本文为云栖社区原创内容,未经允许不得转载。
前端内存优化的探索与实践相关推荐
- 爱奇艺知识播放体验优化的探索和实践
前 言 德鲁克说:未来社会最大的改变一定是会发生在知识领域. 知识付费商业形式在2014年甚至更早之前就已经开始有了,只是当时还没有内容创业的概念,没有被完全重视.到了2016年,移动互联网的成熟.短 ...
- 干货 | 携程桌面应用的前端内存优化与监控
作者简介 吕萌萌,携程资深前端开发工程师,关注前端性能优化与前端框架建设. 一.背景 桌面应用的前端场景不同于传统前端,具有使用者停留时间长,功能复杂且高度聚集在单一页面等特征,因此带来了不同的技术挑 ...
- 深入探索 Android 内存优化(炼狱级别)
前言 成为一名优秀的Android开发,需要一份完备的知识体系,在这里,让我们一起成长为自己所想的那样~. 本篇是 Android 内存优化的进阶篇,难度可以说达到了炼狱级别,建议对内存优化不是非常熟 ...
- 有赞 Flink 实时任务资源优化探索与实践
简介:目前有赞实时计算平台对于 Flink 任务资源优化探索已经走出第一步. 作者|沈磊 随着 Flink K8s 化以及实时集群迁移完成,有赞越来越多的 Flink 实时任务运行在 K8s 集群上, ...
- 实践App内存优化:如何有序地做内存分析与优化
由于项目里之前线上版本出现过一定比例的OOM,虽然比例并不大,但是还是暴露了一定的问题,所以打算对我们App分为几个步骤进行内存分析和优化,当然内存的优化是个长期的过程,不是一两个版本的事,每个版本都 ...
- 深入探索Android内存优化(炼狱级别)
本文由 jsonchao投稿 微信:bcce5360 前言 成为一名优秀的Android开发,需要一份完备的知识体系,在这里,让我们一起成长为自己所想的那样~. 本篇是 Android 内存优化的进阶 ...
- 内存优化 · 基础论 · 初识 Android 内存优化
[小木箱成长营]内存优化系列文章: 内存优化 · 工具论 · 常见的 Android 内存优化工具和框架 内存优化 · 方法论 · 揭开内存优化神秘面纱 内存优化 · 实战论 · 内存优化实践与应用 ...
- 深入探索Android内存优化
前言 成为一名优秀的Android开发,需要一份完备的知识体系,在这里,让我们一起成长为自己所想的那样~. 本篇是Android内存优化的进阶篇,难度会比较大,建议对内存优化不是非常熟悉的前仔细看看在 ...
- 高品质互动在线课堂:前端开发优化实践
互联网教育行业风起云涌,而高品质在线授课平台是每个互联网教育公司的核心和基石.本文是tutorabc前端负责人和君在LiveVideoStackCon 2017上的分享整理,主要介绍了在线授课系统Tu ...
最新文章
- 定义ComboBox(下拉列表)组件垂直滚动条的样式。
- 配置中心框架IConfCenter
- Nginx大规模并发原理
- winform判断线程有没有完成_并发编程系列1:线程池的架构实现、大小配置、及四种线程池使用...
- Java ObjectInputStream readShort()方法(带示例)
- [论文阅读][Point-Plane ICP]Object Modeling by Registration of Multiple Range Images
- Java-final最终修饰符
- WPF-StackPanel面板
- win10安装tomcat7的安装与配置【详细教程】
- 小智双核浏览器下载安装配置教程
- 数学建模神经网络模型,数学建模神经网络算法
- Python 多进程与数据库连接池配合同时取出数据进行处理
- 室内定位技术应用现状
- exlsx表格教程_e某cel表格~的各种基本操作.doc 文档全文预览
- 解决谷歌浏览器下载缓慢问题
- 如何进入BIOS模式,BIOS进不去解决方案
- 初探自动化测试(爬虫)框架nightmarenightwatch
- c语言中“|”和“||”区别
- Nacos 与其他注册中心对比
- 看一遍你也会做!用英伟达 DIGITS 进行图像分割(上)
热门文章
- c语言函数的使用步骤,c语言打开文件函数使用方法
- 小程序 字号设置 slider滚动改变大小_SteerMouse for mac(鼠标设置工具) v5.4.3
- signature=8405d26e250ad07c44560263cb1d4fc0,Systems for analyzing microtissue arrays
- linux set权限,Linux 特殊权限set_uid(示例代码)
- 【LeetCode笔记】338. 比特位计数(Java、位运算、动态规划)
- python套用word模板_如何使用Python批量创建Word模板
- mfc绘制bezier b样条三种曲线_生存曲线(二):SPSS和Origin绘图教程及相关问题
- 封条格式用word怎么打_标书密封条格式全word.doc
- 成都女孩弃港大全额奖学金,将去北大读马克思,“我对党史和马克思很有感情”!...
- 双胞胎一个上北大一个上清华,秘诀6个字!还有女生收到清华通知书说“考砸了”……...