Kafka是如何实现高吞吐率的
转载:http://aoyouzi.iteye.com/blog/2322673
Kafka是分布式消息系统,需要处理海量的消息,Kafka的设计是把所有的消息都写入速度低容量大的硬盘,以此来换取更强的存储能力,但实际上,使用硬盘并没有带来过多的性能损失
kafka主要使用了以下几个方式实现了超高的吞吐率
顺序读写
kafka的消息是不断追加到文件中的,这个特性使kafka可以充分利用磁盘的顺序读写性能
顺序读写不需要硬盘磁头的寻道时间,只需很少的扇区旋转时间,所以速度远快于随机读写
Kafka官方给出了测试数据(Raid-5,7200rpm):
顺序 I/O: 600MB/s
随机 I/O: 100KB/s
零拷贝
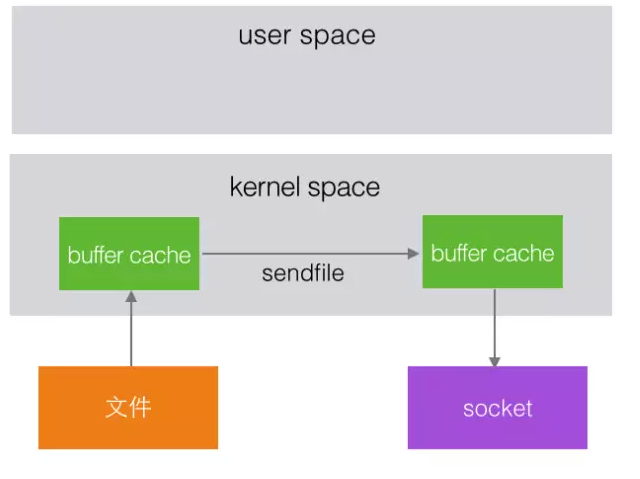
先简单了解下文件系统的操作流程,例如一个程序要把文件内容发送到网络
这个程序是工作在用户空间,文件和网络socket属于硬件资源,两者之间有一个内核空间
在操作系统内部,整个过程为:

在Linux kernel2.2 之后出现了一种叫做"零拷贝(zero-copy)"系统调用机制,就是跳过“用户缓冲区”的拷贝,建立一个磁盘空间和内存的直接映射,数据不再复制到“用户态缓冲区”
系统上下文切换减少为2次,可以提升一倍的性能
文件分段
kafka的队列topic被分为了多个区partition,每个partition又分为多个段segment,所以一个队列中的消息实际上是保存在N多个片段文件中
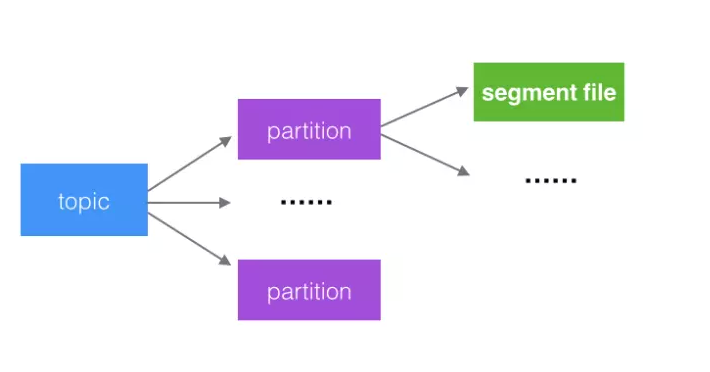
通过分段的方式,每次文件操作都是对一个小文件的操作,非常轻便,同时也增加了并行处理能力
批量发送
Kafka允许进行批量发送消息,先将消息缓存在内存中,然后一次请求批量发送出去
比如可以指定缓存的消息达到某个量的时候就发出去,或者缓存了固定的时间后就发送出去
如100条消息就发送,或者每5秒发送一次
这种策略将大大减少服务端的I/O次数
数据压缩
Kafka还支持对消息集合进行压缩,Producer可以通过GZIP或Snappy格式对消息集合进行压缩
压缩的好处就是减少传输的数据量,减轻对网络传输的压力
Producer压缩之后,在Consumer需进行解压,虽然增加了CPU的工作,但在对大数据处理上,瓶颈在网络上而不是CPU,所以这个成本很值得
Kafka是如何实现高吞吐率的相关推荐
- 批处理的高吞吐率和高延迟的解释
在很多系统中都允许用户设置单条消息处理模式或者批处理模式.例如,在storm中,用户可以通过core和Trident两种API编写,区别是前者是一个tuple一个tuple地处理,而后者是多个tupl ...
- Kafka为何可以实现高吞吐?
Kafka之所以可以实现高吞吐,主要依赖于以下5点: Zero Copy(零拷贝)技术 Page Cache(页缓存)+磁盘顺序写 分区分段+索引 批量读写 批量压缩 首先说一下零拷贝技术: Zero ...
- Kafka的高吞吐率是怎么实现的
一.Producer端消息优化 Kafka支持使用异步批量的方式发送消息.当Producer生产一条消息时,并不会立刻发送到Broker,而是先放入到消息缓冲区,等到缓冲区满或者消息个数达到限制后,再 ...
- WEB站点之 吞吐率、吞吐量、TPS、性能测试
一.吞吐率 我们一般使用单位时间内服务器处理的请求数来描述其并发处理能力.称之为吞吐率(Throughput),单位是 "req/s".吞吐率特指Web服务器单位时间内处理的请求数 ...
- 数字系统重要指标-吞吐率和时延
数字系统重要指标-吞吐率 吞吐率被定义为数字电路单位时间内传输数据的量或单位时间完成的工作量.传输的数据越多或做的工作越多,则吞吐率越高.吞吐率有时候和性能.带宽可以互换使用.对于CPU来说,吞吐率定 ...
- 吞吐率、吞吐量、TPS、性能测试,纸上不谈兵
https://ruby-china.org/topics/26221 一.吞吐率 我们一般使用单位时间内服务器处理的请求数来描述其并发处理能力.称之为吞吐率(Throughput),单位是 &quo ...
- 高吞吐消息中间件Kafka集群环境搭建(3台kafka,3台zookeeper)
高吞吐消息中间件Kafka集群环境搭建(3台kafka,3台zookeeper) 一.集群搭建要求 1.搭建设计 2.分配六台Linux,用于安装拥有三个节点的Kafka集群和三个节点的Zookeep ...
- Kafka高吞吐原理及如何保证不丢失不重复消费
原文:Kafka如何保证不丢失不重复消费 - 知乎 一.如何保证百万级写入速度: 目录 1.页缓存技术 + 磁盘顺序写 2.零拷贝技术 3.最后的总结 "这篇文章来聊一下Kafka的一些架构 ...
- 高吞吐、低延迟 Java 应用的 GC 优化实践
2019独角兽企业重金招聘Python工程师标准>>> 背景 高性能应用构成了现代网络的支柱.LinkedIn 内部有许多高吞吐量服务来满足每秒成千上万的用户请求.为了获得最佳的用户 ...
最新文章
- 如何用Linux的at命令安排一个任务
- flux服务器推消息,在Spring WebFlux响应式处理程序中发送JMS消息:它是否阻塞?
- OpenCV中利用cvConvertScale()对图像数据作线性变换
- 测试CPU品牌和当前工作频率
- 【开发管理类软件必备知识视频教程之二】登录窗体后台注意事项
- Metasploit渗透某高校域服务器
- 机器人中的轨迹规划(Trajectory Planning )
- Intellij IDEA社区版集成Maven插件
- BCNF/3NF的判断方法
- python入门教程(非常详细)-菜鸟学Python入门教程大盘点|7个多月的心血总结
- oracle 触发器代码,Oracle触发器实例代码
- mp c2011sp文件服务器,理光Ricoh MP C2011SP驱动
- windows批量部署
- Kotlin Flow 背压和线程切换竟然如此相似
- Mac电脑升级13系统后,git clone 代码报错,mac升级后git ssh用不了
- mac下sourcetree设置代理
- 搭建Window10 VNC远程访问ubuntu20.04
- ubuntu删除虚拟网卡
- 推荐一款手机Python编程软件
- BP神经网络学习及matlab实现