机器学习 识别图片人物动作_一键学习人物识别说明
机器学习 识别图片人物动作
This article was originally written February 28, 2017.
本文最初写于2017年2月28日。
Let’s say you want to teach a computer to read handwritten digits. You might give it a bunch of rules to tell it what to do. For example, an oval is most likely a 0. Another approach you might try is “machine learning.” Give a computer a bunch of examples of each digit to study so that it can learn its own rules. This latter method has worked surprisingly well. In fact, most banks use this technology to allow ATMs or mobile phones read the amount on a check without the need for human interaction.
假设您想教一台计算机来读取手写数字。 您可能会给它一些规则来告诉它该怎么做。 例如,椭圆形很可能是0。您可以尝试的另一种方法是“机器学习”。 给计算机提供一堆有关每个数字的示例以供学习,以便它可以学习自己的规则。 后一种方法效果很好。 实际上,大多数银行都使用这种技术,使ATM或移动电话无需人工干预即可读取支票上的金额。
One limitation with current machine learning techniques, however, is that they require a lot of examples. For example, if you want to teach a computer to recognize cats, you need to first give the computer many pictures of cats so it can learn what cats looks like. These examples might not always exist or might be very expensive to obtain. What if you could teach a computer to learn a new concept, such as a “cat,” from just one or two examples? This is exactly what three researchers, Lake, Salakhutdinov, and Tenebaum, from MIT did.
但是,当前机器学习技术的局限性在于它们需要大量示例。 例如,如果要教计算机识别猫,则需要首先为计算机提供许多猫的图片,以便它可以了解猫的外观。 这些示例可能并不总是存在,或者获取起来可能非常昂贵。 如果您可以仅通过一个或两个示例来教计算机学习诸如“猫”之类的新概念,该怎么办? 这正是麻省理工学院的三个研究人员Lake,Salakhutdinov和Tenebaum所做的。
The researchers specifically focused on character recognition. They asked: can we teach a computer to recognize new characters after just seeing one example? The end result was an algorithm that was just as good as humans at learning what new characters look like. Specifically, the algorithm performed just as well as humans in character recognition and generation tasks.
研究人员专门研究了字符识别。 他们问:仅看一个例子,我们可以教一台计算机识别新字符吗? 最终结果是一种算法,与人类在学习新字符的外观方面一样出色。 具体而言,该算法在字符识别和生成任务方面的表现与人类一样好。
字符识别 (Character Recognition)
How well can you recognize a character that you’ve never seen before? To evaluate their algorithm’s performance in this test, the researchers compared their algorithm’s performance to that of humans. They first gathered a group of handwritten characters from various alphabets. The researchers then gave each participant an example of a character they had never seen before and asked the participant to find the character in a set of 20 new characters from the same alphabet. They asked their algorithm to do the same. Surprisingly, the algorithm (3.3% error rate) performed just as well as the people (avg. 4.5% error rate)!
您如何认识以前从未见过的角色? 为了评估该算法在该测试中的性能,研究人员将其算法性能与人类的性能进行了比较。 他们首先收集了来自各种字母的一组手写字符。 然后,研究人员为每个参与者提供了一个他们从未见过的字符的示例,并要求参与者从同一字母的20个新字符集中找到该字符。 他们要求他们的算法做同样的事情。 令人惊讶的是,算法(错误率3.3%)的表现与人员(平均错误率4.5%)一样好!
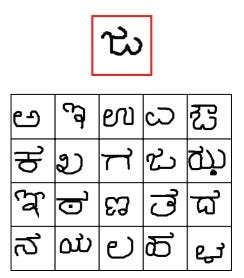
角色产生 (Character Generation)
Can you generate examples of how other people would write a character? Using the same group of handwritten characters, they gave each participant an example of a character they had never seen before, and then asked the participant to create a new example of that character. They asked their algorithm to do the same thing. To test how well the algorithm did, they showed a group of computer-generated characters and a group of human-written characters to a judge to see if the judge could differentiate between the two. The judges could only identify the computer-generated characters 52% of the time, not doing much better than random chance (50%).
您能否生成其他人如何写角色的示例? 他们使用同一组手写字符,为每个参与者提供了一个他们从未见过的字符的示例,然后要求参与者创建该字符的新示例。 他们要求他们的算法做同样的事情。 为了测试该算法的效果,他们向法官展示了一组计算机生成的字符和一组人工手写的字符,以查看法官是否可以区分两者。 裁判只能在52%的时间内识别出计算机生成的角色,没有比随机几率(50%)更好。
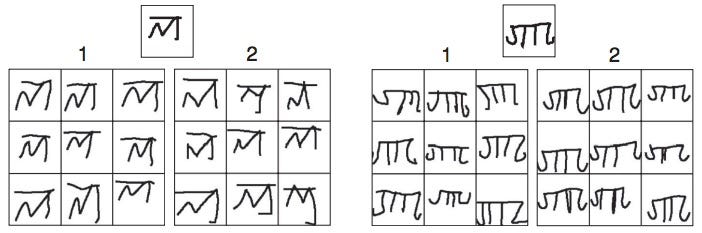
那么他们是怎么做到的呢? (So how did they do it?)
Given how well the algorithm does with just one example, the natural question that arises is, how did they do it?
考虑到该算法仅用一个示例的性能如何,出现的自然问题是,它们是如何做到的?
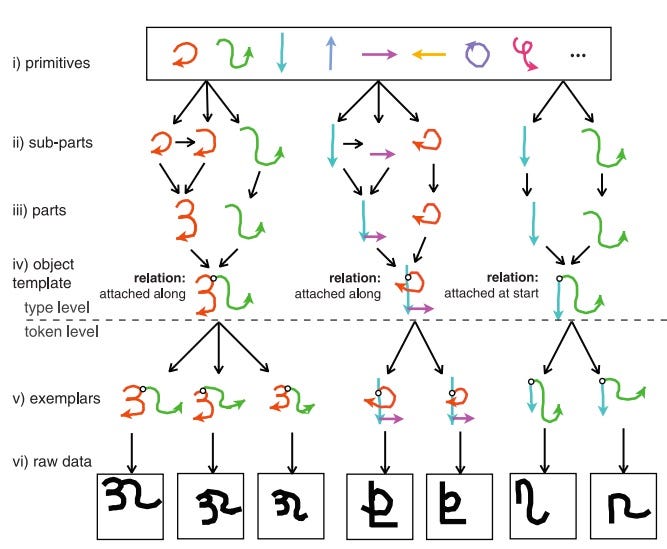
The core intuition behind the algorithm is realizing that a character can be seen as a series of strokes put together. The researchers taught the algorithm how to decompose an image of a character into a sequence of strokes that may have been used to write the character. The algorithm could then use this stroke-based representation as a base from which to generate new examples (e.g. Taking into account other ways a stroke might be written) or see which characters could be mapped to the same stroke-pattern.
该算法背后的核心直觉是认识到一个字符可以看作一系列笔画组合在一起。 研究人员教导了该算法如何将角色的图像分解为可能用于书写角色的一系列笔画。 然后,算法可以使用基于笔画的表示作为基础,从中生成新示例(例如,考虑到笔画的其他编写方式)或查看可以将哪些字符映射到相同的笔画样式。
To teach the computer how to map from character to strokes, the researchers used a method called Bayesian program learning. They broke up the task of going from character to stroke into parts and modeled each part as a probability distribution (how likely is it that there are three strokes given that the character looks like this… Etc.). Before running the algorithm, they gave the computer characters from 30 alphabets to teach the computer what the probability distributions should look like. While it still needed some data to learn the initial probabilities, now, instead of needing a thousand examples of a new character, now it only needs one!
为了教计算机如何从字符到笔划进行映射,研究人员使用了一种称为贝叶斯程序学习的方法。 他们分解了从角色到笔画的各个部分的工作,并将每个部分建模为概率分布(假设角色看起来像这样,那么有三笔画的可能性是……)。 在运行算法之前,他们给了30个字母的计算机字符,以告诉计算机概率分布应该是什么样。 虽然它仍然需要一些数据来学习初始概率,但是现在,不需要一千个新角色的示例,现在只需要一个!
未来步骤 (Future steps)
Despite the impressive advances, there is still much work to be done. People see more than just strokes when they look at a character; they may also notice features such as parallel lines or symmetry. Furthermore, optional features can cause a lot of difficulty. Consider the character “7”. An algorithm might model it as a one-stroke character the first time it sees it. However, once it sees a “7” with a dash in it, it may consider it to be a different character because that requires two strokes, and it’s never seen a “7” with a dash in it. A human, however, might be able to infer that a “7” with a dash is the same as a “7” without a dash, whether through the context or other factors.
尽管取得了令人瞩目的进步,但仍有许多工作要做。 人们在看角色时看到的不仅是笔画。 他们可能还会注意到平行线或对称等特征。 此外,可选功能可能会导致很多困难。 考虑字符“ 7”。 一种算法可能会在第一次看到它时将其建模为单笔画字符。 但是,一旦看到带有破折号的“ 7”,它可能会认为它是一个不同的字符,因为这需要两次击键,而且从未看到带有破折号的“ 7”。 然而,无论是通过上下文还是其他因素,人类都可以推断带破折号的“ 7”与不带破折号的“ 7”相同。
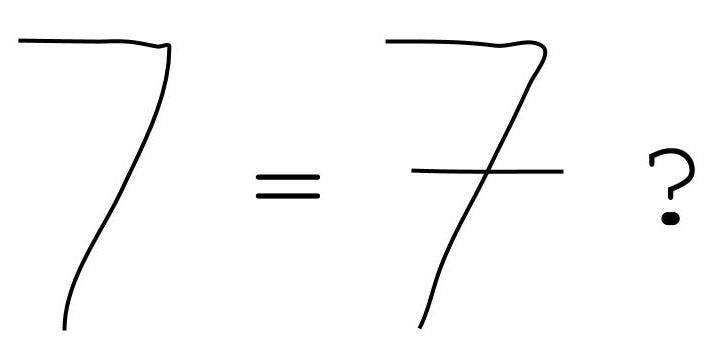
This algorithm is also very specific toward recognizing characters. It would be interesting to see if we could develop similar “one-shot learning” algorithms in other areas. For example, what if a self-driving car could learn to recognize and obey a new sign after watching another car react to it once?
该算法在识别字符方面也非常具体。 有趣的是,我们是否可以在其他领域开发类似的“一次性学习”算法。 例如,如果无人驾驶汽车在观看另一辆汽车对此作出React后能够学会识别并遵守新的标志,该怎么办?
One key insight from this paper makes me think that this indeed can be possible. The researchers intentionally told the algorithm to think of characters as a series of strokes being put together rather than a grid of 0s and 1s. This representation is closer to how humans think about characters and using this human-based representation greatly increased how quickly the computer learned. A lot of artificial intelligence techniques have been based on how humans make decisions, but it may prove useful to study more of how humans learn and represent information as well.
本文的一个主要见解使我认为这确实是可能的。 研究人员有意告诉该算法将字符视为一系列笔画,而不是由0和1组成的网格。 这种表示方式更接近于人类如何思考字符,并且使用这种基于人类的表示方式大大提高了计算机的学习速度。 许多人工智能技术都是基于人类如何做出决策的,但是研究更多关于人类如何学习和表示信息的方法可能被证明是有用的。
While there is still a lot of work to be done, this paper represents a significant step forward in machine learning world.
尽管仍有许多工作要做,但本文代表了机器学习领域的重要一步。
Sources
资料来源
Original paper: http://web.mit.edu/cocosci/papers/science-2015-lake-1332-8.pdf.
原始论文: http : //web.mit.edu/cocosci/papers/science-2015-lake-1332-8.pdf。
For more information on automatic reading of handwritten digits, see http://yann.lecun.com/exdb/mnist/.
有关自动读取手写数字的更多信息,请参见http://yann.lecun.com/exdb/mnist/。
- The middle three images are from Lake, Salakhutdinov, and Tenebaum’s paper (cited above).中间的三个图像来自Lake,Salakhutdinov和Tenebaum的论文(上文引用)。
翻译自: https://medium.com/@eugene.c.tang/one-shot-learning-character-recognition-explained-54186327622d
机器学习 识别图片人物动作
http://www.taodudu.cc/news/show-2691726.html
相关文章:
- opencv 图像人物识别
- ps 自动生成html代码,ps怎么生成html网页文件 PS生成html网页文件的具体教程
- 网页版在线使用PS网站源码
- PS网页版在线使用PS网站源码
- 用Ps制作网页展示总结
- 在线网页版ps
- 常用的在线PS网站
- ps的切片用来转换html,Photoshop切片导出HTML+CSS
- PS文件的存储
- PS制作登录界面
- PS之如何直接提取其他窗口或网页颜色
- PS网页设计_新手建站入门视频教程
- 【期末大作业】公益网站ps平面设计
- ps制作html网页的跳转,PS图片转页面CSS+HTML的步骤
- ps 自动生成html代码,详解使用PS中直接生成html网页保存样式的步骤
- PS网页设计
- 前端网页版ps,你用过了吗?
- 免费网页版PS,太好用了
- PS网页设计教程XXII——在PS中创建单页复古网页布局
- PS网页设计教程XVII——在Photoshop中设计创意组合网页
- PS网页设计教程XXI——在Photoshop中创建一个光质感网页设计
- 如何修改PDF中图片的大小尺寸
- el-upload限制文件大小(图片尺寸)
- 加载大尺寸图片不清晰,加载原图(ImageLoader,Glide)
- vba 读取图片尺寸
- png图片尺寸大小调整
- php获取判断图片大小,php 获取图片尺寸的方法
- matlab 保存图片大小尺寸_改变figure大小存储图片(matlab)
- C#图片处理:生成大尺寸图片,以边框颜色填充
- python如何获取图片的尺寸大小_Python获取图片的大小/尺寸
机器学习 识别图片人物动作_一键学习人物识别说明相关推荐
- python人脸识别训练模型生产_深度学习-人脸识别DFACE模型pytorch训练(二)
首先介绍一下MTCNN的网络结构,MTCNN有三种网络,训练网络的时候需要通过三部分分别进行,每一层网络都依赖前一层网络产生训练数据供当前训练网络,这样也推动了两个网络之间的最小损耗. Pnet Rn ...
- python识别图片文字_如何利用Python识别图片中的文字
一.前言 不知道大家有没有遇到过这样的问题,就是在某个软件或者某个网页里面有一篇文章,你非常喜欢,但是不能复制.或者像百度文档一样,只能复制一部分,这个时候我们就会选择截图保存.但是当我们想用到里面的 ...
- python识别图片文字_使用百度文字识别API进行图片中文字的识别
今天,为了满足我女朋友作业的需求,我使用Python制作了一个图片转文字的小应用. (当然,下面导入模块的问题我就不多说了,是非常简单的) 一. 申请百度通用文字识别接口. 1.先在百度AI开放平台注 ...
- 易语言python识别图片验证码_图片识别-打码平台-打码网站-识别验证码-图鉴网络科技有限公司...
Android脚本 Import "Cjson.lua" Import "ttddm.lua" Import "ShanHai.lua" / ...
- 按键精灵 识别图片形状_精灵形状的2D世界建筑物简介
按键精灵 识别图片形状 Sprite Shape gives you the freedom to create rich free-form 2D environments straight in ...
- python图片提取文字软件_python识别图片文字_图片文字识别软件,快速提取文字...
图文识别是一种可以使你转换不同文档的技术,比如将扫描纸质文档,PDF文件或者数码相机拍摄的图片转换成可以编辑的文档. 假设你获得了一个纸质文件-比如,杂志.彩页或者你合作伙伴发给你的PDF合同.很明显 ...
- python识别图片指定位置文字_python批量识别图片指定区域文字内容
Python批量识别图片指定区域文字内容,供大家参考,具体内容如下 简介 对于一张图片,需求识别指定区域的内容 1.截取原始图上的指定图片当做模板 2.根据模板相似度去再原始图片上识别准确坐标 3.根 ...
- python 制定识别图片的某些区域_python批量识别图片指定区域文字内容
Python批量识别图片指定区域文字内容,供大家参考,具体内容如下 简介 对于一张图片,需求识别指定区域的内容 1.截取原始图上的指定图片当做模板 2.根据模板相似度去再原始图片上识别准确坐标 3.根 ...
- 如何识别截图文字?进来学习照片识别文字怎么弄
前阵时间,同事天天加班加点的赶工作,我一看打卡时间,好家伙一个星期里每天数他最早来,最后一个走.不过,我自己倒是很好奇为啥临近假期了,其他同事基本工作都收尾了坐等放假,就他一个忙得废寝忘食.原来,他手 ...
- python dlib opencv人脸识别准确度_Dlib+OpenCV深度学习人脸识别的方法示例
前言 人脸识别在LWF(Labeled Faces in the Wild)数据集上人脸识别率现在已经99.7%以上,这个识别率确实非常高了,但是真实的环境中的准确率有多少呢?我没有这方面的数据,但是 ...
最新文章
- php面向对象编程快速入门,PHP面向对象编程的快速入门
- 软件测试用python一般用来做什么-月薪20K的软件测试岗,为什么要求我会Python?...
- gulp+browserSync自动刷新页面
- boost::range模块实现格式化相关的测试程序
- 左边替换 oracle,sqlsever替换右边第4个字符
- python 公司年会抽奖_用Python做个年会抽奖小程序吧
- 自动取款机如何使用无卡取款_云南铝管自动抛光机如何使用_利琦抛光机械
- 开源分布式数据库 TiKV 入选 CNCF 云原生项目!
- mysql装了一半卡住了_mysql安装问题:安装到configuration overview卡住了
- 针对医疗数据进行命名实体识别
- GD32VF103(riscv)与STM32F103性能对比
- Delcam PowerInspect 5040 sp1/
- 驱动人生8新版助力电脑性能起飞
- h5制作导出html,Hype这款H5制作软件的导出功能的详细介绍
- Android相框合成图片抠图
- groovy+grails+gradle开发
- 英文事件抽取论文整理
- python selenium学习之新浪微博
- 使用Python在Markdown插入图片并自动获取链接
- 这19款最好用的免费安全工具,使用不当或许面临牢狱之灾。