DeepID算法实践
DeepID实践
转载请注明:http://blog.csdn.net/stdcoutzyx/article/details/45570221
好久没有写博客了,I have failed my blog. 目前人脸验证算法可以说是DeepID最强,本文使用theano对DeepID进行实现。关于deepid的介绍,可以参见我这一片博文 DeepID之三代。
当然DeepID最强指的是DeepID和联合贝叶斯两个算法,本文中只实现了DeepID神经网络,并用它作为特征提取器来应用在其他任务上。
本文所用到的代码工程在github上:DeepID_FaceClassify,如果这篇博客帮到了你,求star。咳咳,为了github工程的star数我觉得我太无耻了,哈哈。
实践流程
环境配置
本工程使用theano库,所以在实验之前,theano环境是必须要配的,theano环境配置可以参见theano document。文档已经较为全面,本文不再赘述,在下文中,均假设读者已经装好了theano。
代码概览
本文所用到的代码结构如下:
src/ ├── conv_net │ ├── deepid_class.py │ ├── deepid_generate.py │ ├── layers.py │ ├── load_data.py │ └── sample_optimization.py └── data_prepare├── vectorize_img.py├── youtube_data_split.py└── youtube_img_crop.py
正如文件名命名所指出的,代码共分为两个模块,即数据准备模块(data_prepare)和卷积神经网络模块(conv_net)。
数据准备
我觉得DeepID的强大得益于两个因素,卷积神经网络的结构和数据,数据对于DeepID或者说对任何的卷积神经网络都非常重要。
可惜的是,我去找过论文作者要过数据,可是被婉拒。所以在本文的实验中,我使用的数据并非论文中的数据。经过下面的描述你可以知道,如果你还有其他的数据,可以很轻松的用python将其处理为本文DeepID网络的输入数据。
以youtube face数据为例。它的文件夹结构如下所示,包含三级结构,第一是以人为单位,然后每个人有不同的视频,每个视频中采集出多张人脸图像。
youtube_data/ ├── people_folderA │ ├── video_folderA │ │ ├── img1.jpg │ │ ├── img2.jpg │ │ └── imgN.jpg │ └── video_folderB └── people_folderB
拿到youtube face数据以后,需要做如下两件事:
- 对图像进行预处理,原来的youtube face图像中,人脸只占中间很小的一部分,我们对其进行裁剪,使人脸的比例变大。同时,将图像缩放为(47,55)大小。
- 将数据集合划分为训练集和验证集。本文中划分训练集和验证集的方式如下:
- 对于每一个人,将其不同视频下的图像混合在一起
- 随机化
- 选择前5张作为验证集,第6-25张作为训练集。
经过划分后,得到7975张验证集和31900训练集。显然,根据这两个数字你可以算出一共有1595个类(人)。
数据准备的代码使用
注意: 数据准备模块中以youtube为前缀的的程序是专门用来处理youtube数据,因为其他数据可能图像属性和文件夹的结构不一样。如果你使用了其他数据,请阅读youtube_img_crop.py和youtube_data_split.py代码,然后重新写出适合自己数据的代码。数据预处理代码都很简单,相信在我代码的基础上,不需要改太多,就能适应另一种数据了。
youtube_img_crop.py
被用来裁剪图片,youtube face数据中图像上人脸的比例都相当小,本程序用于将图像的边缘裁减掉,然后将图像缩放为47×55(DeepID的输入图像大小)。
Usage: python youtube_img_crop.py aligned_db_folder new_folder
- aligned_db_folder: 原始文件夹
- new_folder: 结果文件夹,与原始文件夹的文件夹结构一样,只不过图像是被处理后的图像。
youtube_data_split.py
用来切分数据,将数据分为训练集和验证集。
Usage: python youtube_data_split.py src_folder test_set_file train_set_file
- src_folder: 原始文件夹,此处应该为上一步得到的新文件夹
- test_set_file: 验证集图片路径集合文件
- train_set_file: 训练集图片路径集合文件
test_set_file和train_set_file的格式如下,每一行分为两部分,第一部分是图像路径,第二部分是图像的类别标记。
youtube_47_55/Alan_Ball/2/aligned_detect_2.405.jpg,0 youtube_47_55/Alan_Ball/2/aligned_detect_2.844.jpg,0 youtube_47_55/Xiang_Liu/5/aligned_detect_5.1352.jpg,1 youtube_47_55/Xiang_Liu/1/aligned_detect_1.482.jpg,1
vectorize_img.py
用来将图像向量化,每张图像都是47×55的,所以每张图片变成一个47×55×3的向量。
为了避免超大文件的出现,本程序自动将数据切分为小文件,每个小文件中只有1000张图片,即1000×(47×55×3)的矩阵。当然,最后一个小文件不一定是1000张。
Usage: python vectorize_img.py test_set_file train_set_file test_vector_folder train_vector_folder
- test_set_file:
*_data_split.py生成的 - train_set_file:
*_ata_split.py生成的 - test_vector_folder: 存储验证集向量文件的文件夹名称
- train_vector_folder: 存储训练集向量文件的文件夹名称
Conv_Net
走完了漫漫前路,终于可以直捣黄龙了。现在是DeepID时间。吼吼哈嘿。
在conv_net模块中,有五个程序文件
- layers.py: 卷积神经网络相关的各种层次的定义,包括逻辑斯底回归层、隐含层、卷积层、max_pooling层等
- load_data.py: 为DeepID载入数据。
- sample_optimization.py: 针对各种层次的一些测试实验。
- deepid_class.py: DeepID主程序
- deepid_generate.py: 根据DeepID训练好的参数,来将隐含层抽取出来
Conv_Net代码使用
deepid_class.py
Usage: python deepid_class.py vec_valid vec_train params_file
- vec_valid:
vectorize_img.py生成的 - vec_train:
vectorize_img.py生成的 - params_file: 用来存储训练时每次迭代的参数,可以被用来断点续跑,由于CNN程序一般需要较长时间,万一遇到停电啥的,就可以用得上了。自然,更大的用途是保存参数后用来抽取特征。
注意:
DeepID训练过程有太多的参数需要调整,为了程序使用简便,我并没有把这些参数都使用命令行传参。如果你想要改变迭代次数、学习速率、批大小等参数,请在程序的最后一行调用函数里改。
deepid_generate.py
可以使用下面的命令来抽取DeepID的隐含层,即160-d的那一层。
Usage: python deepid_generate.py dataset_folder params_file result_folder
- dataset_folder: 可以是训练集向量文件夹或者验证集向量文件夹。
- params_file:
deepid_class.py训练得到 - result_folder: 结果文件夹,其下的文件与dataset_folder中文件的文件名一一对应,但是结果文件夹中的向量的长度变为160而不是原来的7755。
效果展示
DeepID 效果
跑完deepid_class.py以后,你可以得到输出如下。输出可以分为两部分,第一部分是每次迭代以及每个小batch的训练集误差,验证集误差等。第二部分是一个汇总,将epoch train error valid error. 按照统一格式打印了出来。
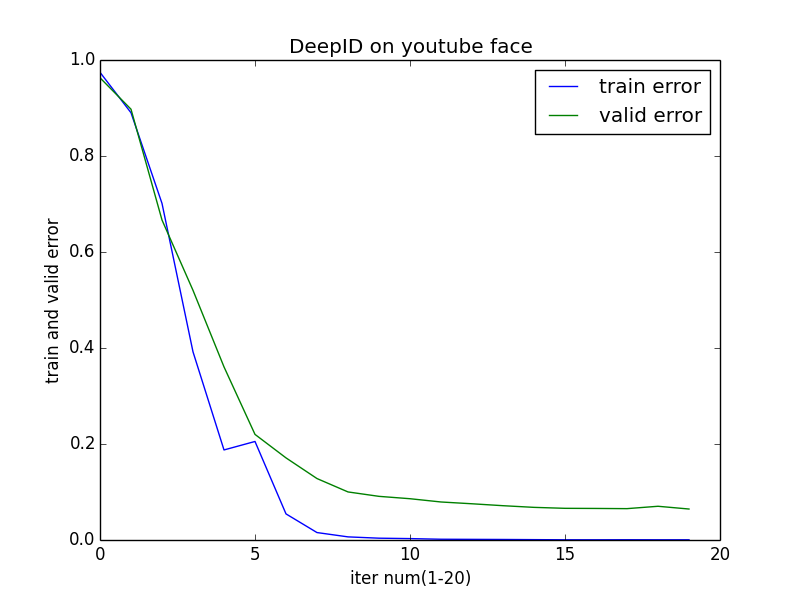
epoch 15, train_score 0.000444, valid_score 0.066000epoch 16, minibatch_index 62/63, error 0.000000 epoch 16, train_score 0.000413, valid_score 0.065733epoch 17, minibatch_index 62/63, error 0.000000 epoch 17, train_score 0.000508, valid_score 0.065333epoch 18, minibatch_index 62/63, error 0.000000 epoch 18, train_score 0.000413, valid_score 0.070267epoch 19, minibatch_index 62/63, error 0.000000 epoch 19, train_score 0.000413, valid_score 0.0645330 0.974349206349 0.962933333333 1 0.890095238095 0.897466666667 2 0.70126984127 0.666666666667 3 0.392031746032 0.520133333333 4 0.187619047619 0.360666666667 5 0.20526984127 0.22 6 0.054380952381 0.171066666667 7 0.0154920634921 0.128 8 0.00650793650794 0.100133333333 9 0.00377777777778 0.0909333333333 10 0.00292063492063 0.086 11 0.0015873015873 0.0792 12 0.00133333333333 0.0754666666667 13 0.00111111111111 0.0714666666667 14 0.000761904761905 0.068 15 0.000444444444444 0.066 16 0.000412698412698 0.0657333333333 17 0.000507936507937 0.0653333333333 18 0.000412698412698 0.0702666666667 19 0.000412698412698 0.0645333333333
上述数据画成折线图如下:
向量抽取效果展示
运行deepid_generate.py之后, 可以得到输出如下:
loading data of vec_test/0.pklbuilding the model ...generating ...writing data to deepid_test/0.pkl loading data of vec_test/3.pklbuilding the model ...generating ...writing data to deepid_test/3.pkl loading data of vec_test/1.pklbuilding the model ...generating ...writing data to deepid_test/1.pkl loading data of vec_test/7.pklbuilding the model ...generating ...writing data to deepid_test/7.pkl
程序会对向量化文件夹内的每一个文件进行抽取操作,得到对应的160-d向量化文件。
将隐含层抽取出来后,我们可以在一些其他领域上验证该特征的有效性,比如图像检索。可以使用我的另一个github工程进行测试,这是链接.使用验证集做查询集,训练集做被查询集,来看一下检索效果如何。
为了做对比,本文在youtube face数据上做了两个人脸检索实验。
- PCA exp. 在
vectorized_img.py生成的数据上,使用PCA将特征降到160-d,然后进行人脸检索实验。 - DeepID exp. 在
deepid_generate.py生成的160-d数据上直接进行人脸检索实验。
注意: 在两个实验中,我都使用cosine相似度计算距离,之前做过很多实验,cosine距离比欧式距离要好。
人脸检索结果如下:
- 正确率如下:
| Precision | Top-1 | Top-5 | Top-10 |
|---|---|---|---|
| PCA | 95.20% | 96.75% | 97.22% |
| DeepID | 97.27% | 97.93% | 98.25% |
- 平均正确率如下:
| AP | Top-1 | Top-5 | Top-10 |
|---|---|---|---|
| PCA | 95.20% | 84.19% | 70.66% |
| DeepID | 97.27% | 89.22% | 76.64% |
Precision意味着在top-N结果中只要出现相同类别的人,就算这次查询成功,否则失败。而AP则意味着,在top-N结果中需要统计与查询图片相同类别的图片有多少张,然后除以N,是这次查询的准确率,然后再求平均。
从结果中可以看到,在相同维度下,DeepID在信息的表达上还是要强于PCA的。
参考文献
[1]. Sun Y, Wang X, Tang X. Deep learning face representation from predicting 10,000 classes[C]//Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on. IEEE, 2014: 1891-1898.
版权声明:本文为博主原创文章,未经博主允许不得转载。
- 上一篇局部敏感哈希之KSH
- 下一篇Adam:大规模分布式机器学习框架
- 顶
- 3
- 踩
- 1
- 猜你在找
- Python自动化开发基础 多线程\多进程\及主机管理 day7
- JDBC视频教程
- PDF神器-Adobe Acrobat Pro
- R语言知识体系概览
- jQuery 视频教程
- 准备好了么? 跳吧 !更多职位尽在 CSDN JOB
-
C++开发工程师深圳市互联港湾网络技术有限公司
|
8-12K/月我要跳槽
-
C++开发工程师佳都新太科技股份有公司
|
6-12K/月我要跳槽
-
C++工程师广州华工邦元信息技术有限公司
|
5-10K/月我要跳槽
-
算法研究员百猎网
|
18-35K/月我要跳槽
- 12楼 yangchao_THU 2015-08-09 11:44发表 [回复]
-

- 类别标号为0 和 1 具体代表什么啊!
- 11楼 yangchao_THU 2015-08-07 14:57发表 [回复]
-
- 弱弱的问一句,youtube face 的数据集是买的吗?在哪可以下载啊
- 10楼 some_possible 2015-07-14 11:29发表 [回复]
-

-
我也下载了图像检索的程序,可是遇到了ImportError: No module named retrieval.load_data 明明是有的,为什么提示没有呢?楼主
- Re: 张雨石 2015-07-14 21:49发表 [回复]
-

- 回复some_possible:在python中设一下路径。。把当前src目录设成python的环境路径之一。。具体应该是在python的site-packages目录下写一个.pth文件,里面是代码的路径。
- 9楼 some_possible 2015-07-14 09:50发表 [回复]
-
-
您好,我跑通了您的代码,数据还是youtube的,代码没有边,按照步骤做下来。准确率0 0.968571428571 0.9896
1 0.901111111111 0.931066666667
2 0.726126984127 0.7736
3 0.440412698413 0.604266666667
4 0.186412698413 0.346666666667
5 0.0910158730159 0.177066666667
6 0.0264444444444 0.230133333333
7 0.0833650793651 0.166933333333
8 0.0176825396825 0.1268
9 0.00479365079365 0.092
10 0.00269841269841 0.0818666666667
11 0.00142857142857 0.0721333333333
12 0.000825396825397 0.0657333333333
13 0.000825396825397 0.0666666666667
14 0.000666666666667 0.0658666666667
15 0.000761904761905 0.0645333333333
16 0.284253968254 0.999333333333
17 0.99180952381 0.995866666667
18 0.956825396825 0.951066666667
19 0.841365079365 0.844
我要是想用15次的参数来提取特征,怎么做呢- Re: baidu_29874963 2015-07-16 17:25发表 [回复]
-

-
回复some_possible: 你的问题解决了吗?我也遇到和你一样的问题,
0 0.970920634921 0.9716
1 0.898984126984 0.8704
2 0.742476190476 0.721466666667
3 0.472317460317 0.4532
4 0.20673015873 0.262266666667
5 0.0977777777778 0.176533333333
6 0.0564761904762 0.1552
7 0.0119365079365 0.1172
8 0.0716825396825 0.109733333333
9 0.00434920634921 0.092
10 0.00222222222222 0.0945333333333
11 0.000761904761905 0.0738666666667
12 0.000698412698413 0.0713333333333
13 0.000380952380952 0.0705333333333
14 0.00111111111111 0.0713333333333
15 0.000412698412698 0.0710666666667
16 0.00139682539683 0.0744
17 0.859904761905 0.997866666667
18 0.996222222222 0.9944
19 0.970952380952 0.961333333333在16次epoch之后效果又回升了,你可以用你15次的参数获取特征了吗?
- Re: 张雨石 2015-07-14 21:51发表 [回复]
-
- 回复some_possible:为什么你的15次之后的效果又回升了?
- 8楼 暗-小汐 2015-06-17 23:13发表 [回复]
-

-
github上的主要代码为什么又给删了呢~
- Re: 张雨石 2015-07-18 22:06发表 [回复]
-
- 回复暗-小汐:已经放回去了
- 7楼 eagelangel 2015-06-06 08:06发表 [回复]
-

- 博主,您好!因为git上的主程序已经被删除了,能否将DeepID_FaceClassify的完整代码发一份给我,Email:lsm8610@sina.com。谢谢啦!
- 6楼 runauto 2015-05-27 14:21发表 [回复]
-

-
楼主,采用pca就能达到这么高的结果,那还需要deepID干嘛呢?楼主在其他的数据集上做过测试没有,如LFW。
- Re: 张雨石 2015-05-27 16:25发表 [回复]
-
-
回复runauto:yeah, 你是对的,我并未在其他数据集上做过。因为deepid和其他的一些CNN-based model都是对数据要求很高,可以说数据也是决定其效果好的一部分,很遗憾,我手上并未有那么多的数据。所以没有继续深入下去。
- Re: vzvzx 2015-06-02 19:43发表 [回复]
-

-
回复张雨石:lfw我跑了一下只有8%(PCA直接就有24%),应该是过拟合了吧。训练集不够。deepid实现的还只是一部分?还有很多木有实现,按特征点分块,特征整合什么的。
- Re: yangchao_THU 2015-08-09 11:46发表 [回复]
-
-
回复vzvzx:你好,能一起具体聊聊关于DeepID在lfw上跑的情况吗??
我的QQ763927065
- 5楼 NakatsuShizuru_ 2015-05-27 01:55发表 [回复]
-

-
您好,我在执行deepid_class的过程中遇到了gcc编译问题,请问下该如何解决呢?
环境是ubuntu 12.04 + gcc 4.64 + theano 0.7
字数有点多只好上图片了
http://i.imgur.com/ejQjfzT.png
谢谢!
- 4楼 caxieyou 2015-05-22 15:44发表 [回复]
-

-
问一下,你的文件预处理部分,有没有把人脸分成60个patch的这一步处理?因为paper里似乎是这么干的
thx
- 3楼 Nick-Zhuo 2015-05-12 16:40发表 [回复]
-

- 博主好文章,好代码
- 2楼 Deep_Learner 2015-05-12 09:49发表 [回复]
-

- PCA的结果有点高了啊,在youtube数据库上。
- 1楼 zdcs 2015-05-10 17:59发表 [回复] [引用] [举报]
-

-
我在theano0.7上出现这个错误TypeError: ('An update must have the same type as the original shared variable (shared_var=W, shared_var.type=CudaNdarrayType(float32, matrix), update_val=Elemwise{sub,no_inplace}.0, update_val.type=TensorType(float64, matrix)).', 'If the difference is related to the broadcast pattern, you can call the tensor.unbroadcast(var, axis_to_unbroadcast[, ...]) function to remove broadcastable dimensions.')
\- Re: 张雨石 2015-05-11 18:43发表 [回复]
-
- 回复zdcs:我把theano的链接给错了,我用的是theano0.6, 你用0.6版本的吧。
DeepID算法实践相关推荐
- 人脸验证 DeepID 算法实践
人脸验证 DeepID 算法实践 4,610 次阅读 - 文章 作者:雨石 出处:雨石的博客 目前人脸验证算法可以说是DeepID最强,本文使用theano对DeepID进行实现.关于deepid的 ...
- 深度学习算法实践(基于Theano和TensorFlow)
深度学习算法实践(基于Theano和TensorFlow) 闫涛 周琦 著 ISBN:9787121337932 包装:平装 开本:16开 用纸:胶版纸 正文语种:中文 出版社:电子工业出版社 出版时 ...
- SDCC 2015算法专场札记:知名互联网公司的算法实践
SDCC 2015算法专场札记:知名互联网公司的算法实践 发表于4小时前|526次阅读| 来源作者投稿|0 条评论| 作者张俊林 SDCC算法架构大数据京东腾讯 摘要:11月21日,为期三天的SDCC ...
- 实时通信服务中的语音解混响算法实践
导读: 随着音视频通信会议越来越普及,与会各方在不同环境中遇到了越来越明显且差异的混响场景,譬如大会议室场景.玻璃会议室场景和小房间且隔音材料不佳场景等.为了保证更好的听音可懂度和舒适度,通信中的语音 ...
- 阿里妈妈品牌广告中的 NLP 算法实践
导读:本次分享的主题为阿里妈妈品牌广告中的 NLP 算法实践,主要内容包括: 1. 品牌广告业务模式与技术架构的简要介绍 2. NLP 算法在品牌搜索广告中的实践,以两个具体的算法问题展开:品牌意图识 ...
- 阿里妈妈流量反作弊算法实践
阿里妈妈是阿里巴巴集团旗下商业数字营销平台.依托阿里巴巴集团核心的商业数据和超级媒体矩阵,为数百万的广告主每年提供上千亿金额的广告服务. 2020年中国互联网广告市场规模达5292亿元,根据秒针< ...
- 机器学习经典算法实践_服务机器学习算法的系统设计-不同环境下管道的最佳实践
机器学习经典算法实践 "Eureka"! While working on a persistently difficult-to-solve problem, you disco ...
- asp.net从入门到精通配套课件_MATLAB从入门到算法实践第八期本周六直播
推荐Matlab算法经典课程,此课程已经经过7次升级和打磨,累计超过3000多人学习,想从零基础入门和想提高Matlab编程水平的同学推荐加入学习. 讲师介绍 董辰辉 Matlab 畅销书主编.上市公 ...
- C#经典算法实践,回顾往生,更是致敬《算法导论》
该文章的最新版本已迁移至个人博客[比特飞],单击链接 C#经典算法实践,回顾往生,更是致敬<算法导论> | .Net中文网 访问. 概述 本系列博文将会向大家介绍本人在钻研<算法导论 ...
最新文章
- 定档12月22日!《黑客帝国4》王者归来,再掀矩阵革命
- 百万级PHP网站架构工具箱
- 第四范式@2020 WAIC世界人工智能大会
- java客户端作为kafka消费者测试
- 写java代码时的注意事项_从方法返回Java 8的可选项时的注意事项
- Python操作excel(.xlsx)封装类MyPyExcel V2.0
- 深度解析艾瑞咨询《2017年度中国商业智能行业研究报告》
- js正则匹配小数点后2位_正则实践与详解
- 注册flash.ocx inno setup (转)
- flutter 修改app名字和图标(安卓)
- paypal android app,PayPal
- 我背透了这些前端八股文
- 什么是次世代游戏建模?角色和场景建模,哪个比较容易
- Github+Typora+PicGo+Jsdelivr 实现白P图床
- 解决Win7无法登陆OneDrive并报错0x8004de40问题(亲测解决)
- 云计算------容器部署情感分析
- python控制画笔尺寸_Python turtle库的画笔控制说明
- shell下删除文件末尾的空行
- luogu1830 轰炸III
- 怎么检查计算机启动程序,如何查看电脑开机启动项