Uber提出基于Metropolis-Hastings算法的GAN改进思想
改进GAN除了使用更复杂的网络结构和损失函数外,还有其他简单易行的方法吗?Uber的这篇文章或许可以给你答案,将GAN与贝叶斯方法相结合,在已经训练好的GAN上增加后处理步骤即可。本文对Uber的这篇最新工作进行了简要介绍,如果对内容感兴趣还可以点击文末的原文链接阅读论文,同时文末还提供了该方法的开源代码,你可以轻松用它来提升自己的GAN模型。
更多干货内容请关注微信公众号“AI前线”(ID:ai-front)
生成对抗网络(GAN)不仅在真实感图像生成和图像恢复方面取得了令人惊叹的效果,并且由GAN生成的一幅艺术作品也售出了40万美元的价格。
在Uber,GAN有大量具有潜力的应用,包括增强机器学习模型与对抗性攻击的对抗能力,学习交通模拟器,乘车请求或随时间变化的需求模式,以及为Uber Eats生成个性化的订单建议。
GAN由两个互相对抗的部分组成,一部分是生成器,一部分是判别器。生成器学习真实数据的分布,判别器负责需要学习如何区别真实样本和生成样本(即假样本)。大多数研究都致力于改进GAN的结构和训练过程来提高其性能,例如使用更大的网络结构或使用不同的损失函数。
NeurIPS2018的贝叶斯深度学习研讨会上,Uber的一篇论文中提供了一种新的思路:调整判别器用于在完成训练后从生成器中选择更好的样本。该工作提供了一种互补的抽样方法,Google和U.C. Berkeley在判别器舍选抽样(Discriminator Rejection Sampling,DRS)的研究与此方法也具有相同的思路。
Uber这篇工作以及DRS方法的核心思想可归纳为,如何使用已经训练好的判别器的信息来从生成器中选择样本,以保证这些被选择的样本尽可能符合真实数据的分布。通常,在训练完成后判别器就没有什么用了,因为在训练过程中会将判别器学到的知识编码到生成器中。然而,生成器往往是不完美的,判别器同时也会含有一些有用的信息,所以上述使用判别器信息来提升已经训练好的GAN的方法是值得一试的。Uber的研究团队使用了Metropolis-Hastings算法对分布进行抽样,并将采用这种方法得到的模型称为Metropolis-Hastings GAN,即MH-GAN。
GAN重抽样
GAN的训练过程通常被理解为两种条件之间的博弈,生成器需要尽可能让判别器产生误判的概率最大化,而判别器则需要尽可能的对真1z实数据和生成数据进行良好的区分。图1展示了这个过程,生成器使得函数值向极小值方向移动(橙色线条),而判别器则向极大值方向移动(紫色线条)。训练结束后,向生成器输入不同的随机噪声可以得到很方便得到生成样本。如果可以训练一个完美的生成器,那么生成器最终的概率密度函数pG应与真实数据的概率密度函数相同。然而,许多现有的GAN无法很好地收敛到真实数据的分布,因此从这种不完美的生成器中抽样会产生看起来不像原始训练数据的样本。
这种pG的不完美让我们想到另一种分布情况:判别器对生成器隐含的概率密度。这种分布被称为pD,并且它往往都很接近真实的数据分布pG。这是因为训练判别器是一种比训练生成器更简单的任务,因此判别器很有可能包含可以用于校正生成器的信息。如果我们有一个完美的判别器D和一个不完美的生成器G,使用pD而不是pG作为生成的概率密度函数等价于使用一个新的生成器G’,并且这个G’是可以完美地模拟真实数据分布的,如图一所示:
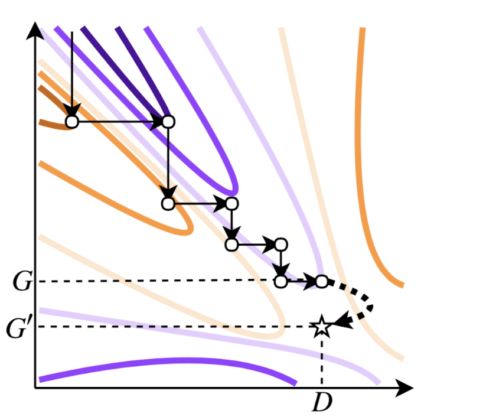
图1:等高线图展示了GAN训练中的对抗过程,联合函数的值在极小化和极大化之间交替进行。橙色线条表示生成器G的优化过程,紫色线条表示判别器D的优化。假设GAN的训练过程结束于图中(D,G)这一点,此时的G未处于最优点,但对于这个G来说D是最优的。此时,通过从pD的分布中抽样,可以得到一个能够完美对数据分布建模的新的生成器G'。
即使pD的分布可能与数据更匹配,但若想利用其得到样本数据并不像直接使用生成器那样直接。幸运的是,我们可以使用抽样算法从分布中产生样本,一种是舍选抽样法(Rejection Sampling,也被称为Acceptance-Rejection Sampling),一种是马尔科夫链蒙特卡洛法(Markov Chain Monte Carlo,MCMC)。这两种方法都可以作为一种后处理方法来提高生成器的输出;之前的判别器舍选抽样法(Discrimitor Rejection Sampling,DRS)借鉴了舍选抽样法的思路,而MH-GAN则采用了Metropolis-Hastings MCMC方法。
舍选抽样
很多实际问题中,真实分布p(x)是很难直接抽样的的,因此,我们需要求助其他的手段来抽样。既然 p(x) 太复杂在程序中没法直接抽样,那么我们可以设定一个程序可抽样的分布 q(x) 比如高斯分布,然后按照一定的方法拒绝某些样本,达到接近 p(x) 分布的目的,其中q(x)叫做候选分布(Proposal Distribution)。
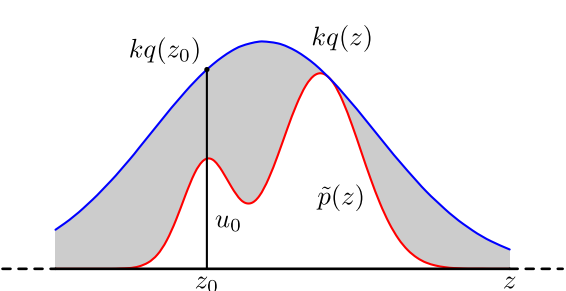
图2:舍选抽样
具体操作如下,设定一个方便抽样的函数 q(x),以及一个常量 k,使得 p(x) 总在 kq(x) 的下方。(参考上图)
x 轴方向:从 q(x) 分布抽样得到 a。
y 轴方向:从均匀分布(0, kq(a)) 中抽样得到 u。
如果刚好落到灰色区域即u \u0026gt; p(a),则拒绝,否则接受这次抽样。
重复以上过程便可得到p(x)的近似分布。该方法两大挑战分别是:
k的值通常是人为经验设置的,无法确定一个准确的值。若k值设置的过大可能导致拒绝率很高,增加无用计算;若k值过小则有可能找不到正确的p(x)分布。
合适的q(x)分布通常很难找到。
在GAN中,pD即为目标分布对应上述p(x),pG为现有的分布对应上述q(x)。所以在GAN中使用该方法的难点主要来源于k值的确定,或因k值太小而无法正确抽样,或因k值过大而在高维空间中产生大量的计算。为了解决样本浪费问题,DRS启发式地增加了一个γ调整判别器分数,使得判别器D即使是完美的情况下,从分布中产生的样本仍能够与真实样本存在差异。
更好的途径:Metropolis-Hastings
Uber的这篇工作使用了Metropolis-Hastings(MH)方法,这是马尔科夫链蒙特卡洛法一类方法中的一种。这一类方法被最初是作为舍选抽样法在高维空间中的代替而发明的,它们通过从候选分布中多点抽样得到一个尽可能复杂的概率分布,然后再对这个概率分布进行抽样。MH包含两步,第一步是从候选分布中(例如,生成器)选择K个样本,然后从K中依次选择一个样本,决定是接受当前样本还是根据接受规则保留先前选择的样本,如图3所示:
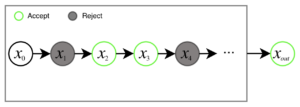
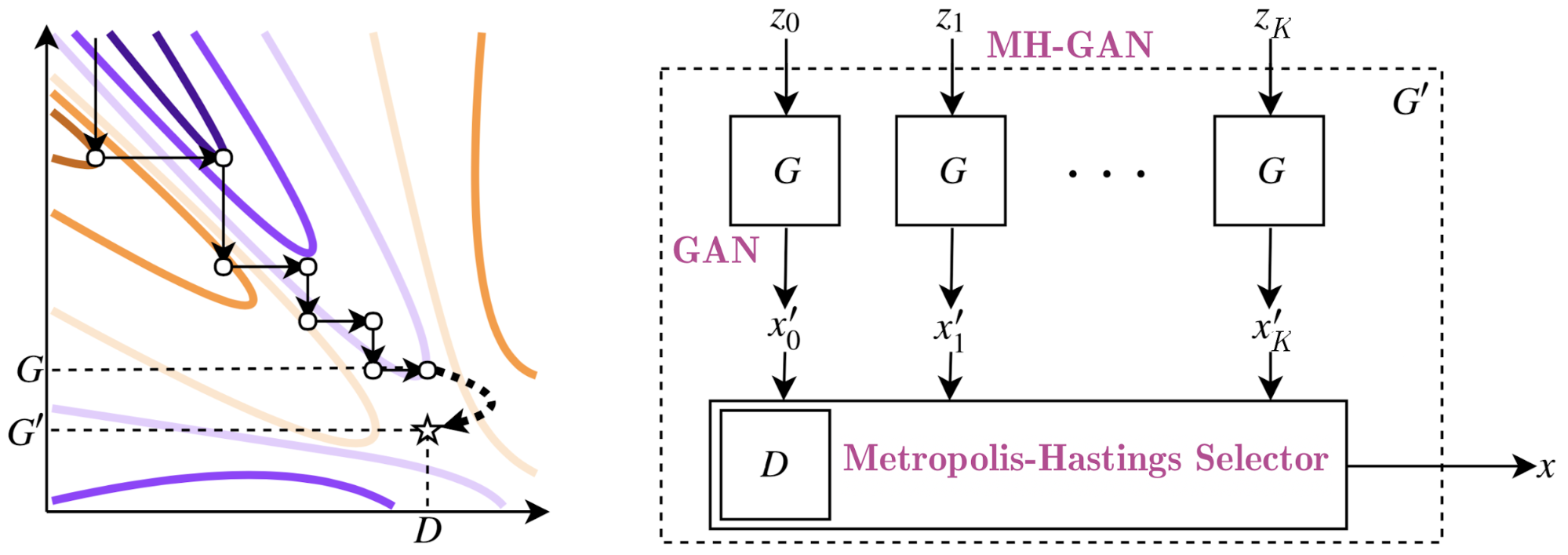
图3:MH在马尔科夫链中选择K个样本,然后根据接受规则对每个样本作出选择。这个马尔科夫链最终会输出最终接受的样本。对于MH-GAN而言,K个样本由G生成,马尔科夫链的输出由改进后的MH-GAN'的G'产生
MH-GAN最大的特点是接受概率可以仅由概率密度比值pD/pG计算得到,而GAN'的判别器的输出恰巧可以计算这个比值!假设xk为初始样本,新的样本x'可以通过与当前样本xk的概率d计算而被接受。
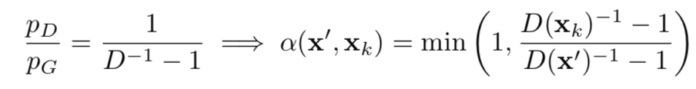
其中,D是判别器分数,由以下公式得到
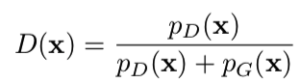
K是一个超参数,对其调整可以在速度和置信度之间做出权衡。对于一个完美的判别器K趋近于无穷,即D的分布完美的接近了真实数据分布。
MH-GAN更多细节
1.独立抽样
噪声样本被独立地输入生成器,经过K次生成得到可以符合MH选择器条件的状态链。独立的链被用于从MH-GAN的生成器G’中获取多样本。
2.初始化
对于MH算法,由于初始点的不确定性,大部分情况下算法会经过一段长时的预烧期才能开始有效的优化过程,即在开始接受第一个数据点之前会拒绝很大一部分数量的数据点。为了避免这种情况,本文对如何初始化状态链的方法进行了详细的介绍。在清理和初始化每一条状态链时,可以使用真实数据的采样结果对状态链进行优化。在遍历了整个状态链之后,如果没有一个数据被接受,MH-GAN会从生成样本中重新开始抽样,从而确保真实数据中的样本不被输出。值得注意的是,MH-GAN不需要真实的样本进行初始化,只需要它所对应的判别器分数即可。
3.校准
实际上,得到完美的D是不可能的,但是通过校准步骤可以达到相对完美的程度。另外,完美判别器的假设也不一定就真如它看起来那么好用。因为判别器仅对生成器和最初的真实数据进行评价,它只需要对来自生成器和真实数据分布的达到精确判别就可以。在一般的GAN训练中,一般不需要严格的要求判别器D的值达到一个确定的边界。但是MH算法需要从概率密度比方面对这个值进行良好的校准,从而得到正确的接受比。MH-GAN使用10%的训练数据作为随机测试集,使用保序回归的方法对判别器D进行调整。
1D和2D高斯结果
Uber在论文中使用了一些小例子对MH-GAN和DRS方法进行了比较,其中真实数据来源于四个单变量的高斯模型的混合结果。通过pG的概率密度图可以看出普通的GAN存在的通病,它们的生成结果都缺失了一种模式(如图4所示)。但是,不使用γ校正DRS和MH-GAN则能良好的还原混合模型,而使用γ进行调整的DRS不能还原原始分布。然而,与使用γ进行调整的DRS方法相比,不使用γ的DRS方法在第一次接受之前抽样的数量增加了一个数量级。
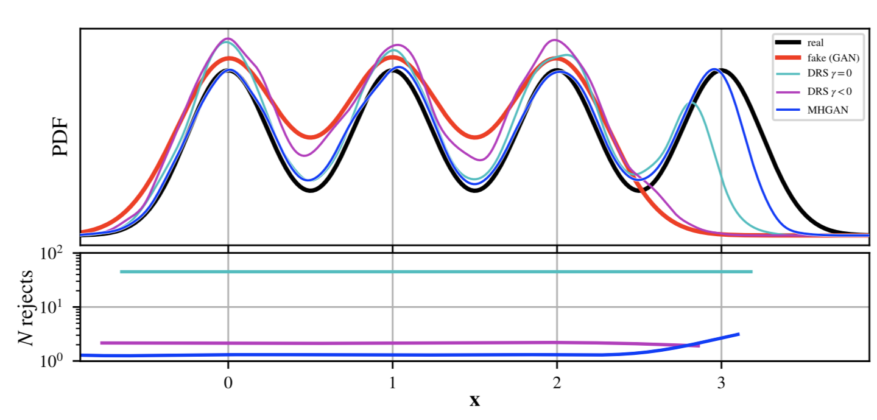
图4:图中真实数据来自于四个高斯模型组成的GMM,可以看出生成器的概率密度分布确实了一个模式。MH-GAN和不使用γ的DRS能够产生该模式,尽管在第一次接受之前后者需要大量的抽样数据。
大部分文献都喜欢用5*5的2D高斯模型作为一个简单的例子进行简单演示,Uber也使用了这样的2D模型对基础GAN、DRS、MH-GAN在不同训练阶段下的情况进行了比较,如图5所示。所有的方法都采用了一个4层全连接卷积神经网络,使用线性整流函数(ReLU)作为激活函数,以及一个100维的隐层和一个维度为2的噪声向量。从视觉效果上来讲,相较于基础GAN的DRS取得了明显的提升,但是它的结果还是更接近基础GAN而不是真实数据。MH-GAN可以模拟出所有25种模式并且从视觉效果上来讲更接近于真实数据。定量角度讲,MH-GAN相较于其他方法具有更小的 JS散度。
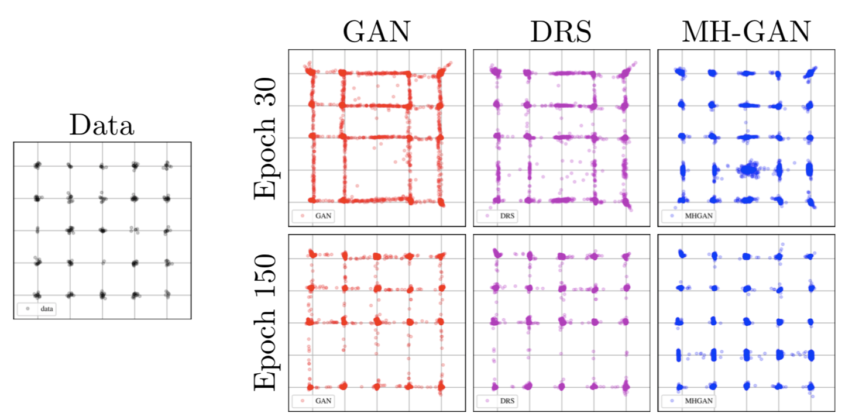
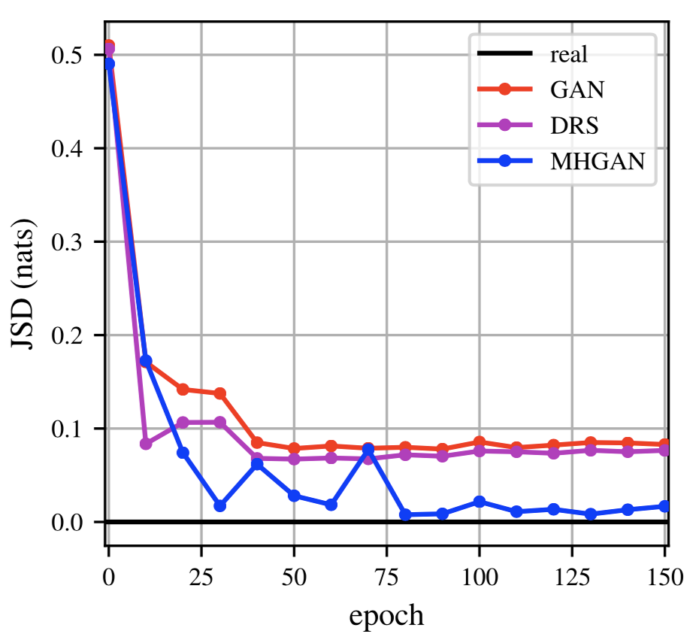
图5:上图是25种高斯模型的2D分布情况。相较于基础GAN,尽管DRS的样本点更集中于模式周围,但它缺失的一些模式上看起来与前者很相似,而MH-GAN则与真实数据更为相似。下图展示MH-GAN具有更小的JS散度。
在CIFAR-10和CelebA上的结果
这部分内容主要展示了MH-GAN在真实数据上的效果,分别测试了选取使用了梯度惩罚的DCGAN和WGAN作为基础GAN的结果。在图6的表格中展示了校准后的MH-GAN的感知分数(Inception Socre)。
感知分数会完全忽略真实数据而只是用生成的图像进行评价,它需要将生成图像传入在ImageNet上预训练好的感知分类器中,感知分数会对输入图像属于某个详细类的置信度和预测类别的多样性进行测量。尽管感知分数存在缺陷,但它仍被广泛用于与其他工作进行比较。
基本上校准后的MH-GAN比其他方法都可以取得更好的效果,但是在整个训练过程中这种优势并不是一直存在的。对于这种情况的一个解释是,对于某一轮的迭代,判别器的分数与理想的判别器分数存在巨大差异,从而导致了接受概率缺乏准确性。
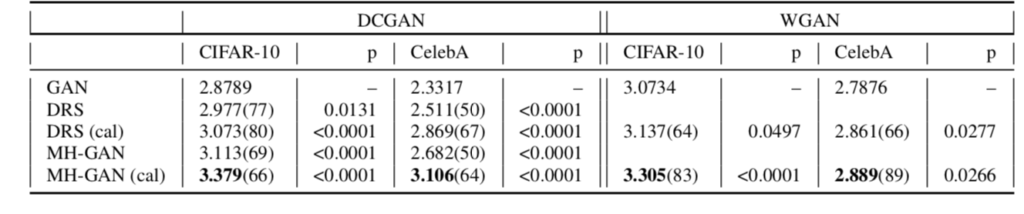
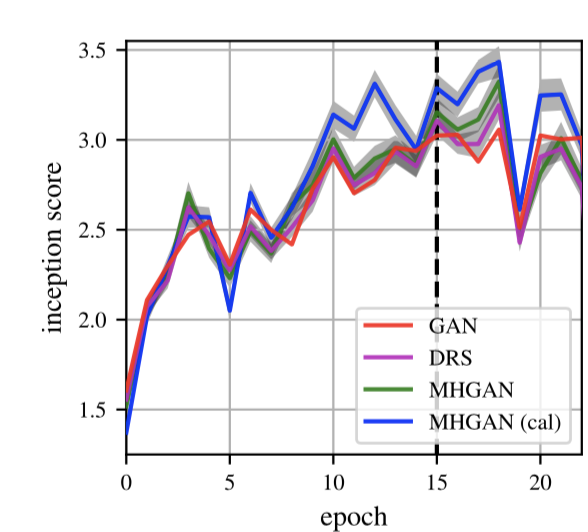
图6:在CIFAR-10和CelebA上的感知分数,值越高表示效果越好。表格中的数据是第六十次迭代后的结果。
未来工作
MH-GAN是一种提升GAN生成器的简单方法,该方法使用Metropolis-Hastings算法作为一个后处理步骤。在模拟数据和真实数据上MH-GAN都表现除了超越基础GAN的效果,与最近提出的DRS方法相比MH-GAN也更具有优势。目前该方法仅在较小的数据库和网络上进行了验证,下一步Uber计划将该方法用于更大的数据库和更先进的网络。将MH-GAN方法扩展到大规模数据库和GAN的途径是非常简单粗暴的,因为仅需要额外提供判别器分数和生成器产生的样本就可以!
此外,使用MCMC算法提升GAN的思想也可以扩展到其他更高效的算法上,例如汉密尔顿蒙特卡洛方法。如果想获取关于MH-GAN的更多细节和图表可以阅读论文:Metropolis-Hastings Generative Adversarial Network,如果想复现该工作,Uber提供了该方法基于Pytorch的开源代码。
阅读英文原文:https://eng.uber.com/mh-gan/
Uber提出基于Metropolis-Hastings算法的GAN改进思想相关推荐
- Metropolis–Hastings算法
1蒙特卡洛方法 蒙特卡罗方法也称统计模拟方法,是一种以概率统计理论为指导的数值计算方法.蒙特卡洛方法的基本思想是,当所求解问题是某种随机事件出现的概率,或者是某个随机变量的期望值时,通过某种" ...
- MCMC中的Metropolis–Hastings算法与吉布斯采样
Metropolis–Hastings算法是一种具体的MCMC方法,而吉布斯采样(Gibbs Sampling)是Metropolis–Hastings算法的一种特殊形式.二者在机器学习中具有重要作用 ...
- R语言实现MCMC中的Metropolis–Hastings算法与吉布斯采样
创建测试数据 第一步,我们创建一些测试数据,用来拟合我们的模型.我们假设预测变量和因变量之间存在线性关系,所以我们用线性模型并添加一些噪音. trueA <- 5trueB <- 0tru ...
- 【信号去噪】基于蚁群算法优化小波阈值实现信号去噪附matlab代码
1 简介 基于硬阈函数和软阈函数的小波去噪算法处理的信号分别存在着偏差和方差过大的缺点,为有效解决这一问题,提出基于蚁群算法优化小波变换去噪算法.并采用常用的信号用matlab对去噪效果进行了仿真.仿 ...
- 乔治亚理工提出基于GAN的强化学习算法用于推荐系统
Generative Adversarial User Model for Reinforcement Learning Based Recommendation System Xinshi Chen ...
- 基于GEMM实现的CNN底层算法被改?Google提出全新间接卷积算法
作者 | Marat Dukhan from Google Research 译者 | 凯隐 责编 | Jane 出品 | AI科技大本营(ID: rgznai100) [导读]本文介绍的内容主要聚焦 ...
- mh采样算法推导_科学网—MCMC中的Metropolis Hastings抽样法 - 张金龙的博文
Metropolis Hastings抽样法示例 jinlongzhang01@gmail.com Metropolis Hasting(下面简称MH)是蒙特卡罗马尔科夫链中一种重要的抽样方法.本文简 ...
- 亮风台提出基于图形匹配的可变形表面跟踪新算法 | ICCV 2019
ICCV 2019接收论文结果已经公布,来自全世界各地院校.研究机构.企业等,共有1077篇计算机视觉相关领域新成果入选.AR公司亮风台基于图形匹配的可变形表面跟踪算法被选为大会论文.新算法提出了一种 ...
- Uber提出损失变化分配方法LCA,揭秘神经网络“黑盒”
作者 | Janice Lan,Rosanne Liu等 译者 | 清儿爸 责编 | 夕颜 出品 | AI科技大本营(ID: rgznai100) [导读]神经网络(Neural networks,N ...
最新文章
- UNIX 网络协议的深度分析
- 创客更新装备 动态规划
- 【POJ - 3177】Redundant Paths(边双连通分量,去重边)
- unittest里discover用法_unittest框架核心要素及应用
- Homebrew更换源
- 如何学习前端开发,有哪些前端教程,前端学习路线图?
- 【Swift 4.0】扩展 WCDB 支持 SQL 语句
- xpath提取目录下所有标签内的内容,递归 //text()
- 金特会谈:有骨气的人,才会被人尊重
- go语言学习:go类型系统
- java 使用Spire.Doc实现Word文档插入图片
- 使用C#达到微信QQ自动快速发送信息的效果(刷屏)
- 如何用python计算excel两行之间的差值_excel表格求两列数据差值-怎样在EXCEL表格中求两列数的差?...
- D和弦的音阶在尤克里里上应该怎么按?
- Coding哥,魅族让你用洪荒之力来夺宝了!
- JS: exec()方法
- BZOJ 1565 [NOI2009]植物大战僵尸
- 4.0 第三十三章 XML
- [C#] Asp.Net 簡易Email寄送 使用Gmail
- vue中h5项目怎么使用weui
热门文章
- C++简易计算器的实现
- symbian与uiq开发教程[完整版]
- 《EffcativeSTL》
- 计算机丢失quartz.dll什么意思,计算机中丢失quartz.dll解决方法
- 程序员 业余赚钱的六种有效途径
- 开源软件和开源社区的反思
- item_get_app - 根据ID取商品详情原数据
- 论文笔记 | Determinants of Cross-Border Mergers and Acquisitions
- python cnn 实例_在Keras中CNN联合LSTM进行分类实例
- ncut matlab,matlab call Ncut: Matrix is too large to convert to linear index.