python爬虫豆瓣电影按电影类型,豆瓣电影---按分类爬取
全部代码以及分析见GitHub:https://github.com/dta0502/douban-movie
我突然想看下有什么电影可以看。由于我偏爱剧情类电影,因此我用Python爬虫来爬取剧情类型的电影。
一、单个页面分析及爬取
1、页面分析
首先选择想要看的分类,如下图所示:
通过chrome的“检查”观察发现真实的URL为
https://movie.douban.com/j/new_search_subjects?sort=S&range=0,10&tags=%E7%94%B5%E8%A7%86%E5%89%A7&start=0&genres=%E5%89%A7%E6%83%85&countries=%E7%BE%8E%E5%9B%BD
sort:按热度排序为T、按时间排序为R、按评分排序为S
tags:类型
countries:地区
geners:形式(电影、电视剧…)
start:“加载更多”
如下图所示:
![]()
“加载更多”分析
1) 首先要能看网页发回来的JSON数据,步骤如下:
打开chrome的“检查”工具
切换到network界面
选择XHR
在页面上点击“加载更多”后会看到浏览器发出去的请求
Preview界面可以看到接受到的JSON数据
全部过程如下图所示:
![]()
下面是上述过程的URL:
![]()
2) 现在我们可以来看下点击“加载更多”这个过程的URL的变化
下图是点击加载更多加载出来的JSON数据:
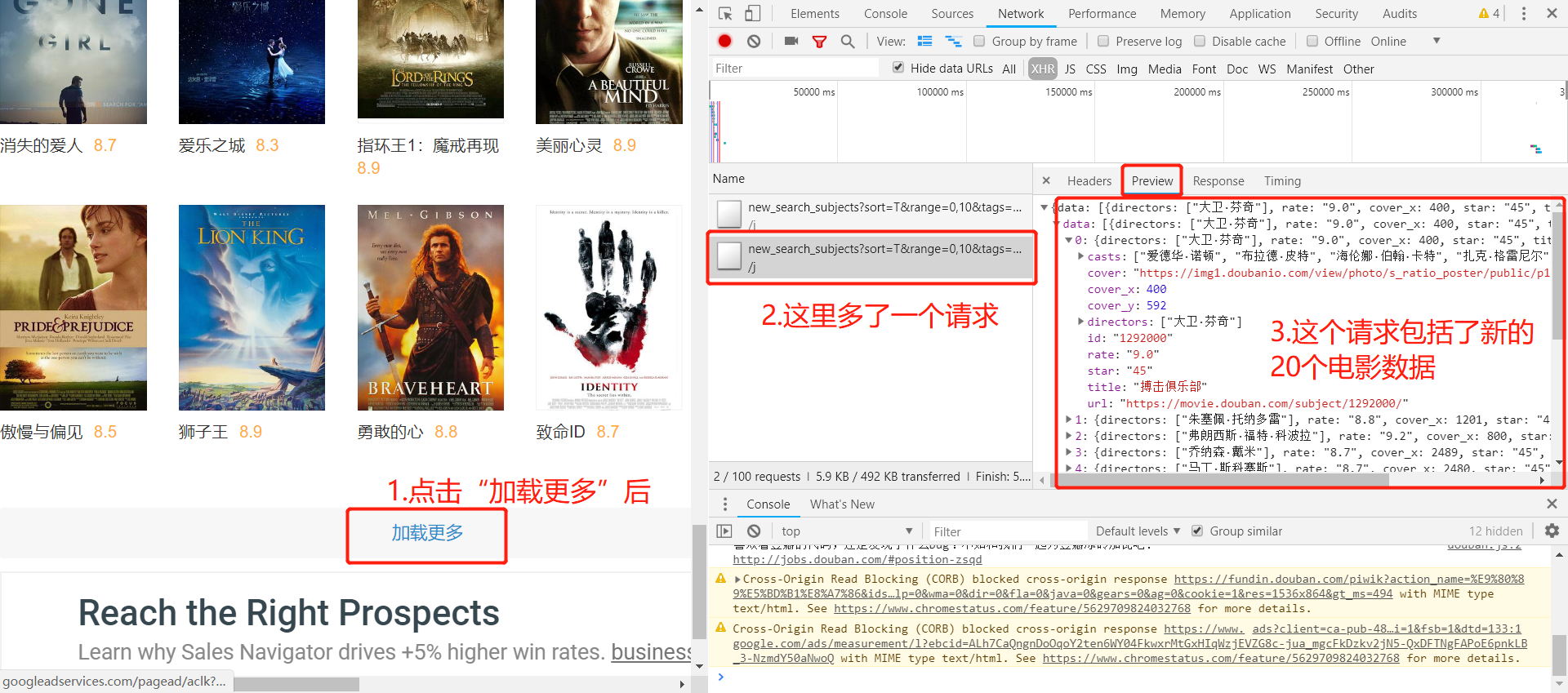
下图是上述过程的URL:
![]()
这里可以发现,每次点击“加载更多”,每次会增加显示20个电影,真实URL中的start这个参数从0-20-40…变化,发送回来最新加载出来的20个电影的JSON数据,了解了这些以后,下面就可以用代码实现抓取了。
2、Python爬取(baseline model)
导入库
import requests
from lxml import etree
import json
import pandas as pd
页面爬取
url = "https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=%E7%94%B5%E5%BD%B1&start=20&genres=%E5%89%A7%E6%83%85&countries=%E7%BE%8E%E5%9B%BD"
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"}
data = requests.get(url,headers = headers).text
JSON数据转换为Python中的字典
Python中json.loads和json.dumps对比:
json.dumps 将Python中的字典转换为字符串
json.loads 将字符串转换为Python中的字典
dicts = json.loads(data)
dicts
字典格式转换为Pandas DataFrame格式
df = pd.DataFrame(dicts["data"])
df.head()
删除DataFrame中不需要的列。
df.drop("cover_x",axis = 1,inplace = True)
df.drop("cover_y",axis = 1,inplace = True)
df.head()
二、一次性爬取多个url
根据上面的分析,现在已经完成了爬取单页面20本电影的功能,下面实现下一次性抓取500本电影数据。
import requests
from lxml import etree
import json
import pandas as pd
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"}
下面采用了一个循环,循环改变URL中的start数值(0-20-40…-480),单次循环爬取20本电影的数据,转换为Pandas DataFrame格式,然后和之前得到的数据进行拼接。
for i in range(0,481,20):
url = "https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=%E7%94%B5%E5%BD%B1&start={页面}&genres=%E5%89%A7%E6%83%85&countries=%E7%BE%8E%E5%9B%BD".format(页面 = i)
data = requests.get(url,headers = headers).text
dicts = json.loads(data)
df = pd.DataFrame(dicts["data"])
if i == 0:
total_df = df
else:
total_df = pd.concat([total_df,df],axis = 0)
下面把包含500本电影数据的DataFrame变量写入csv文件。
total_df.to_csv('movie-0.csv', sep = ',', header = True, index = False)
第一个参数是说把dataframe写入到movie-0.csv文件中,参数sep表示字段之间用’,’分隔,header表示是否需要头部,index表示是否需要行号。
全部代码以及分析见GitHub:https://github.com/dta0502/douban-movie
python爬虫豆瓣电影按电影类型,豆瓣电影---按分类爬取相关推荐
- Python爬虫学习第三章-4.3-使用xpath解析爬取全国城市名称
Python爬虫学习第三章-4.3-使用xpath解析爬取全国城市名称 这一节主要是使用xpath解析爬取全国城市名称 这里使用的网址是:空气质量历史数据查询 这一个案例体现的点主要是xpat ...
- 【爬虫+数据可视化毕业设计:英雄联盟数据爬取及可视化分析,python爬虫可视化/数据分析/大数据/大数据屏/数据挖掘/数据爬取,程序开发-哔哩哔哩】
[爬虫+数据可视化毕业设计:英雄联盟数据爬取及可视化分析,python爬虫可视化/数据分析/大数据/大数据屏/数据挖掘/数据爬取,程序开发-哔哩哔哩] https://b23.tv/TIoy6hj
- 【【数据可视化毕业设计:差旅数据可视化分析,python爬虫可视化/数据分析/大数据/大数据屏/数据挖掘/数据爬取,程序开发-哔哩哔哩】-哔哩哔哩】 https://b23.tv/iTt30QG
[[数据可视化毕业设计:差旅数据可视化分析,python爬虫可视化/数据分析/大数据/大数据屏/数据挖掘/数据爬取,程序开发-哔哩哔哩]-哔哩哔哩] https://b23.tv/iTt30QG ht ...
- 零基础入门python爬虫之《青春有你2》选手信息爬取
零基础入门python爬虫之<青春有你2>选手信息爬取 完成<青春有你2>选手图片爬取,生成选手图片的绝对路径并输出,统计爬取的图片总数量.使用工具:requests模块.Be ...
- Python爬虫入门实例五之淘宝商品信息定向爬取(优化版)
文章目录 写在前面 一.爬取原页面 二.编程思路 1.功能描述 2.程序的结构设计 三.编程过程 1.解决翻页问题 2.编写getHTMLText()函数 3.编写parsePage()函数 (1). ...
- python爬虫——用selenium和phantomjs对新浪微博PC端进行爬取(二)
.,.上一篇文章里我选择爬取简单的微博移动端,由于移动端构造简单,一般都优先爬取移动端,且因为是静态页面,我们可以直接使用xpath或者正则表达式搞定,但pc端结构就复杂得多,不能使用前面的方法.这篇 ...
- 【python爬虫】对喜马拉雅上一个专辑的音频进行爬取并保存到本地
>>>内容基本框架: 1.爬虫目的 2.爬取过程 3.代码实现 4.爬取结果 >>>实验环境: python3.6版本,pycharm,电脑可上网. [一 爬虫目 ...
- python爬虫教程(五):解析库bs4及爬取实例
大家好,今天分享的是解析库中的bs4,本文章的目的是让你知道如何使用bs4,并且附带爬取实例. 目录 一.bs4简介 二.安装及初始印象 1.安装 2.解析器 3.初始印象 三.选择元素的方法 1.方 ...
- python爬虫之Scrapy介绍八——Scrapy-分布式(以爬取京东读书为示例)
Scrapy-分布式(scrapy-redis)介绍 1 Scrapy-分布式介绍 1.1 Scrapy-redis工作原理 1.2 Scrapy-redis 安装和基本使用 1.2.1 安装 1.2 ...
- python爬虫你们最爱的YY小姐姐,这不爬取下来看看?
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理 ( 想要学习Python?Python学习交流群:1039649593,满足你的需 ...
最新文章
- HAProxy客户端IP地址的透传
- Python 使用sys.exc_info自己捕获异常详细信息
- Yii2 定时任务创建(Console 任务)
- 微信大更新,可以“远程控制”他人微信了!
- C语言 大小写字符转换
- centos7安装单节点mysql(源码包安装)
- chrome友好显示json字符串
- Fliptile (dfs+二进制压缩)
- GZIP pre-compression
- 微软将终止支持 Win7;今日头条不与微信竞争;诺基亚芬兰裁员 | 极客头条
- 大数据时代 银行信息安全如何防护?
- centos 并发请求数_彻底理解 jmeter 的线程数与并发数之间的关系
- 苹果被指乏力上游另寻“新欢”
- 滨州智能dcs系统推荐_dcs系统厂家推荐
- 重构分析21: 被拒绝的遗赠(Refused Bequest)
- 在GNU/Linux下将CD音乐转为mp3
- 火车票分段分批放票的时间
- 驳《驳〈论OIer谈恋爱的必要性〉》
- GVARUSL-京都篇
- SSM整合(搭建一个Web脚手架)
热门文章
- 撩妹用计算机,撩妹必备:iPhone计算器魔法技巧简单几步获取妹子手机号 _手机资讯...
- java代码验证大数据算法在竞猜足球预测分析中准确率
- 通用的测试用例编写大全(登录测试/web测试等)
- 在IEEE的哪里下载论文的补充材料
- 大数据学完能干什么,大数据就业方向有哪些
- org.xml.sax.SAXParseException: 文档根元素 java-control-panel 必须匹配 DOCT
- JavaScript教程 -- 廖雪峰
- 项目目标管理——里程碑
- 开环式霍尔电流传感器和闭环式霍尔电流传感器
- 山东省特种设备作业考试系统_山东省特种设备作业人员考试系统用户-使用手册.doc...