Python爬虫:爬取网站视频
python爬取百思不得姐网站视频:http://www.budejie.com/video/
新建一个py文件,代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
|
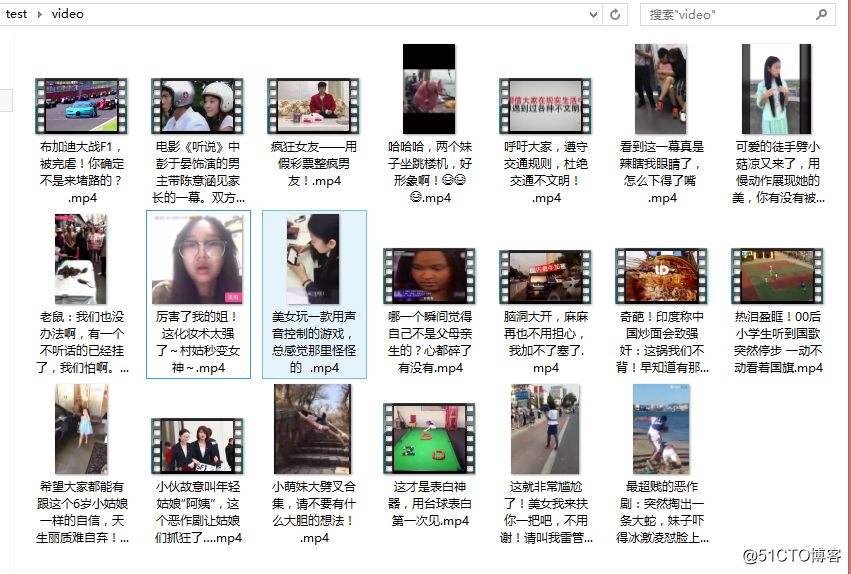
在 py 文件下新建一个 video 文件夹,执行后结果如下:
在 video 文件夹可以看到下载好的视频
注意报错:
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-9: ordinal not in range(128)
解决:
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
Python爬虫:爬取网站视频相关推荐
- python如何爬取网站所有目录_用python爬虫爬取网站的章节目录及其网址
认识爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引.模拟 ...
- Python爬虫爬取Twitter视频、文章、图片
Python爬虫爬取Twitter视频.文章.图片 Twitter的Python爬虫 https://github.com/bisguzar/twitter-scraper 2.2k星标 (2020. ...
- 使用python爬虫爬取bilibili视频
可以使用 Python 爬虫框架如 Scrapy 来爬取 Bilibili 的视频.首先需要了解 Bilibili 网站的构造,包括数据是如何呈现的,然后构建请求来获取所需的数据.同时需要考虑反爬虫措 ...
- Python爬虫爬取网站小漫画
python爬取小漫画 最近在google冲浪的时候发现一个很有意思的漫画网站,可以看韩国的小漫画,但是只可以看很少的一部分,后面的需要付费观看,于是就想着怎么才能免费看到这个网站的所有漫画. 于是我 ...
- Python爬虫 爬取网站全部图片实战
一.获得图片地址 和 图片名称 1.进入网址之后 按F12 打开开发人员工具点击elemnts 2.点击下图的小箭头 选择主图中的任意一个图片 那我们这里点击第一个 图片 3.显示控制台 为了验 ...
- python 爬虫 爬取快手视频 批量解析 建议收藏
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2020/12/8 20:30 # @Author : huni # @File : 快 ...
- Python爬虫-爬取爆米花视频下载至本地
打开爆米花的网站,然后打开其中一个视频: 打开F12,然后刷新,可以看到: 这个URL为视频的真实地址: http://59.56.28.122/vm48002.baomihua.com/d1b3a2 ...
- python网络爬虫爬取视频_Python网络爬虫——爬取小视频网站源视频!自己偷偷看哦!...
学习前提1.了解python基础语法 2.了解re.selenium.BeautifulSoup.os.requests等python第三方库 1.引入库 爬取网站视频需要引入的第三方库: impor ...
- Python网络爬虫——爬取小视频网站源视频!自己偷偷看哦!
学习前提 1.了解python基础语法 2.了解re.selenium.BeautifulSoup.os.requests等python第三方库 1.引入库 PS:如有需要Python学习资料的小伙伴 ...
- python如何爬取网页视频_快就完事了!10分钟用python爬取网站视频和图片
原标题:快就完事了!10分钟用python爬取网站视频和图片 话不多说,直接开讲!教你如何用Python爬虫爬取各大网站视频和图片. 638855753 网站分析: 我们点视频按钮,可以看到的链接是: ...
最新文章
- Spring.NET实用技巧3——NHibernate分布式事务(上)
- 用友BIP|YonBuilder+APICloud 双平台,“1+1>N”的低代码战略
- NO.10章 图(遍历、最短路、生成树、拓扑、关键路径)
- 嗨淘V12刷任务点赞系统源码手动派单版本
- 老实人做不得?教练微信工作群内“说错话”遭公司索赔46万元
- Rocket - decode - 最小项与最大项
- 数据挖掘:特征提取——PCA与LDA
- 数据库版本管理工具Flyway应用
- 学习图(最短路径)算法
- C++调用SSD caffe模型进行物体检测-Opencv3.4.3
- win10连接校园网(wifi)开热点手机连接显示“已连接但无法访问互联网”解决办法
- cidaemon.exe
- 织梦dedecms TAG标签调用汇总(史上最全)
- 深度优先搜索(DFS) 总结(算法+剪枝+优化总结)
- ++a与a++、--a与a--
- Combining Deep Learning with Information Retrieval to Localize Buggy Files for Bug Reports
- android布局空格以及首行缩进表示符
- java到大数据学习路线
- matlab标量数据,可视化标量三维体数据的方法
- [Dest0g3 520迎新赛] Web部分wp