显卡 内存分配 linux,【原创】Linux环境下的图形系统和AMD R600显卡编程(4)——AMD显卡显存管理机制...
显卡使用的内存分为两部分,一部分是显卡自带的显存称为VRAM内存,另外一部分是系统主存称为GTT内存(graphics translation table和后面的GART含义相同,都是指显卡的页表,GTT 内存可以就理解为需要建立GPU页表的显存)。在嵌入式系统或者集成显卡上,显卡通常是不自带显存的,而是完全使用系统内存。通常显卡上的显存访存速度数倍于系统内存,因而许多数据如果是放在显卡自带显存上,其速度将明显高于使用系统内存的情况(比如纹理,OpenGL中分普通纹理和常驻纹理)。
某些内容是必须放在vram中的,比如最终用于显示的“帧缓存”,以及后面说的页表GART (graphics addres remapping table),另外有一些比如后面将介绍的命令环缓冲区(ring buffer)是要放在GTT 内存中的。另一方面,VRAM内存是有限的,如果VRAM内存使用完了,则必须将一些数据放入GTT内存中。
通常GTT内存是按需分配的,而且是给设备使用的,比如radeon r600显卡最多可以使用512M系统内存(Linux内核中是这样设置的),一次性分配512M连续的给设备用的内存在linux系统中是不可能成功的,而且即使可以成功,有相当多的内存是会被浪费掉的。按照按需分配的原则,使用多少就从系统内存中分配多少,这样得到的GTT内存在内存中肯定是不连续的。GPU同时需要使用VRAM内存和GTT内存,最简单的方法就是将这两片内存统一编址(这类似RISC机器上IO和MEM统一编址),VRAM是显卡自带的内存,其地址一定是连续的,但是不连续的GTT内存如果要统一编址,就必须通过页表建立映射关系了,这个页表被称为GTT或者GART,这也是这些内存被称为GTT内存的原因。
和CPU端地址类似,我们将GPU使用的地址称为“GPU虚拟地址”,经过查页表之后的地址称为“GPU物理地址”,这些地址是GPU最终用于访存的地址,由于GPU挂接在设备总线上,因此这里的“GPU物理地址”就是“总线地址”,当然落在vram 区域的内存是不用建页表的,这一片内存区域的地址我们只关心其“GPU 虚拟地址”。
R600显卡核心存管理有关的寄存器如表1示,目前并没有找到完整的描述这些寄存器的手册,表中的数据根据阅读代码获取到。
寄存器名称
偏移地址
功能
R600_CONFIG_MEMSIZE
0x5428
VRAM大小
MC_VM_FB_LOCATION
0x2180
VRAM区域在GPU虚拟地址空间的起始地址和长度
MC_VM_SYSTEM_APERTURE_LOW_ADDR
0x2190
VRAM区域在GPU虚拟地址空间的起始地址
MC_VM_SYSTEM_APERTURE_HIGH_ADDR
0x2194
VRAM区域在GPU虚拟地址空间的结束地址
VM_L2_CNTL
GPU L2 Cache控制寄存器
MC_VM_L1_TLB_MCB
GPU TLB控制寄存器
VM_CONTEXT0_PAGE_TABLE_START_ADDR
0x1594
GTT内存的起始地址
VM_CONTEXT0_PAGE_TABLE_END_ADDR
0x15B4
GTT内存的结束地址
VM_CONTEXT0_PAGE_TABLE_BASE_ADDR
0x1547
GPU页表基地址
VM_CONTEXT0_CNTL
0x1440
GPU虚拟地址空间使能寄存器
VM_CONTEXT0_PROTECTION_FAULT_DEFAULT_ADDR
0x1554
页故障处理程序地址
RADEON_PCIE_TX_DISCARD_RD_ADDR_LO/HI
RADEON_PCIE_TX_GART_ERROR
表1
在Radeon显卡中,VRAM内存涉及到“visiable vram”和“real vram”两个说法,visiable vram是可以使用pci设备内存映射方式映射出来的内存,这部分内存可供软件访问,而显卡的vram还有一部分是不可见的,不能被软件直接访问(是GPU自身使用的?),这部分内存加上visiable ram共同构成显卡的real vram。
通过读取pci配置空间可以获取到visiable vram,比如在一个机器上读出visiable ram大小为256M,读取RADEON_CONFIG_MEMSIZE获取real vram大小为512M,于是vram长度为512M,将vram起始地址设置为0x0,那么结束地址为0x1fffffff,然后将起始地址和结束地址写入R_000004_MC_FB_LOCATION寄存器:
rv515_mc_wreg(R_000004_MC_FB_LOCATION, S_000004_MC_FB_START(rdev->vram_start >> 16) |S_000004_MC_FB_TOP(rdev->vram_end >> 16));
然后是设置GTT内存和GART。GTT的大小是由驱动自己确定的,GTT大小确定后,GART占用的内存也就确定了。参考内核源码和上面表给给出的说明应该很容易明白这个过程。
相比于CPU使用的3级页表,radeon GPU使用的页表比较简单,radeon GPU使用的是1级页表(是否可配置),页表大小为4K,那么页表项的后面12位(212=4k)为标志位。在早期的radeon GPU中,GPU使用的页表页表项是32位的,到r600 之后GPU 页表项为64位,页表项的12位标志位中只有后6位有用,定义如图1。
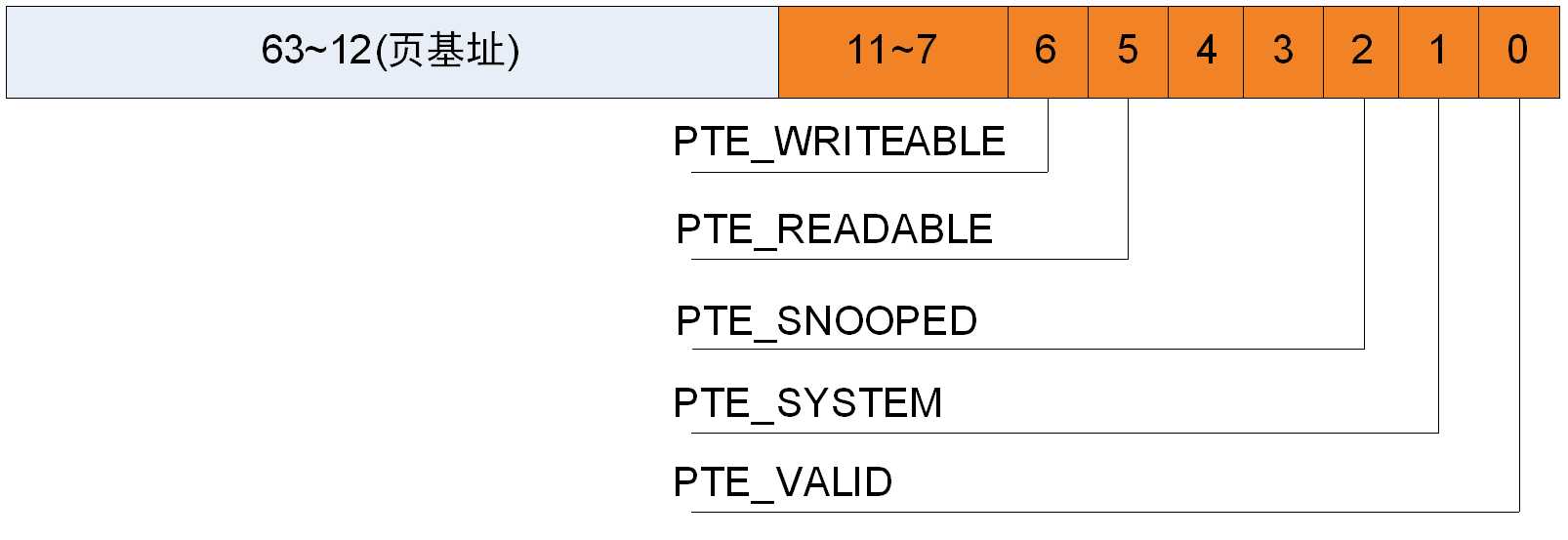
图1
GPU页表在GPU VRAM内存中,VM_CONTEXT0_PAGE_TABLE_BASE_ADDR和VM_CONTEXT0_PAGE_TABLE_END_ADDR两个寄存器表明了页表在vram中的位置。
xxxx linux内核中的代码【待修改】
上述函数有两个参数,dma\_addr是分配的系统内存经过映射后的总线地址,这个地址用于设备访问主存,也是我们上文说的“GPU物理地址”,后面一个参数index是页表项索引。
代码中ptr是页表所在的内存在CPU虚拟地址空间中的地址,r600的页表项为64位,r500及以下的页表为32位。
下面来看一片内存的分配和映射情况。在下一篇博文中将使用一个称为ring buffer分配一片内存,这片内存用于放置命令,cpu将命令放置到这一片内存中,gpu从这一片内存中拿命令对GPU进行配置。
xxx ring_init过程描述【待修改】
在GPU初始化完成后,R600显卡GPU按照图2(代码中看到的是这个样子,是否有错误?)显示的过程进行内存访问。
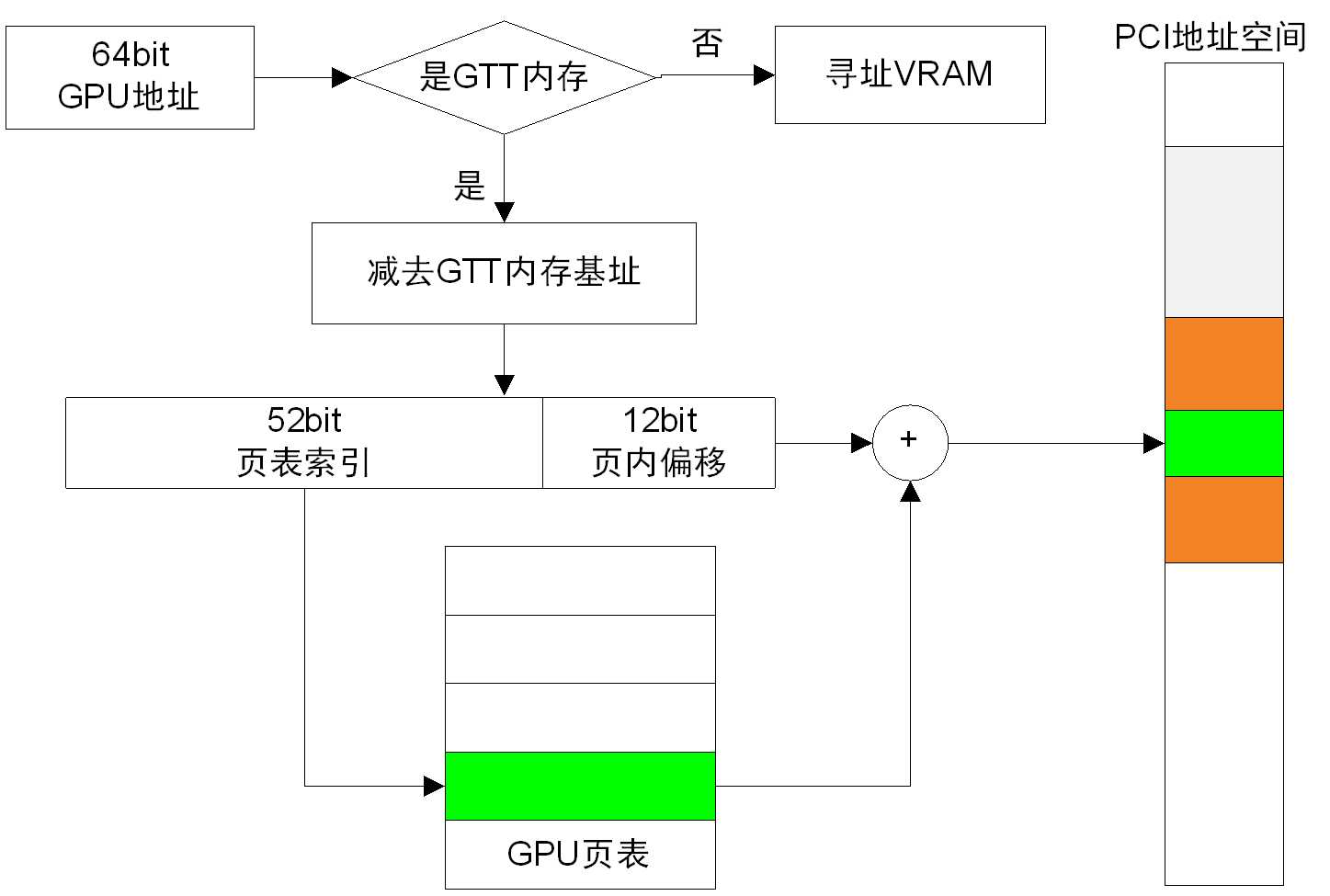
图2
如果是GTT内存,则需要查GPU页表,根据64位地址(在当前的驱动中实际上只用了32位)的前面50 位定位GPU 页表项,根据页表项内容的后12位与上0即是内存在PCI设备空间中的“页基址”,“页基址”加上原来64 位地址的后12位(页内偏移)就得到对应的总线地址。
注意到由于vram和GTT统一编址,而vram并不参与这里的页表地址转换过程,因而需要有减去GTT内存基址的过程。
在linux内核中是有一套完善的内存管理机制的,这套机制是TTM和GEM(相关参考资料)。和操作系统里面的系统内存管理一样,这套机制比较复杂,我们这里不详细描述这套机制的具体实现,而是简单描述如何在核内核外获取和使用显存。
内核使用显存
在radeon内核驱动代码radeon_device_init(drivers/gpu/drm/radeon/radeon_device.c)函数中有如下代码:
810 if (radeon_testing) {
811 radeon_test_moves(rdev);
812 }
810行是一个全局变量开关,当这个开关开启的时候,驱动会做一个拷屏操作,这段代码在drivers/gpu/drm/radeon/radeon_test.c文件中,radeon_test_moves做些数据拷贝操作,包括从vram到系统主存和系统主存到vram之间的数据拷贝,在系统启动的时候就能在屏幕上看到效果(这个是能够直接在radeon内核驱动代码中运行并且能够看到效果的命令处理过程)。在这个地方,内核已经完成了初始化工作,后续对显卡的部分编程可以放在这个地方,重新系统后就能看到效果。下面是一段使用内核API进行显存分配和操作的示例代码:
1 struct radeon_bo *vram_obj = NULL;
2 struct radeon_bo *gtt_obj = NULL;
3 uint64_t vram_addr, gtt_addr;
4 unsigned size;
5 void *vram_map, *gtt_map;
6
7 size = 1024 * 768 * 4;
8 r = radeon_bo_create(rdev, size, PAGE_SIZE, true,
9 RADEON_GEM_DOMAIN_VRAM, &vram_obj);
10 if (r) {
11 DRM_ERROR("Failed to create VRAM object\n");
12 goto out_cleanup;
13 }
14 r = radeon_bo_reserve(vram_obj, false);
15 if (unlikely(r != 0))
16 goto out_cleanup;
17 r = radeon_bo_pin(vram_obj, RADEON_GEM_DOMAIN_VRAM, &vram_addr);
18 if (r) {
19
20 DRM_ERROR("Failed to pin VRAM object\n");
21 goto out_cleanup;
22 }
23 r = radeon_bo_kmap(vram_obj, &vram_map);
24 if (r) {
25 DRM_ERROR("Failed to map VRAM object\n");
26 goto out_cleanup;
27 }
28
29 r = radeon_bo_create(rdev, size, PAGE_SIZE, true,
30 RADEON_GEM_DOMAIN_GTT, >t_obj);
31 if (r) {
32 DRM_ERROR("Failed to create GTT object\n");
33 goto out_cleanup;
34 }
35 r = radeon_bo_reserve(gtt_obj, false);
36 if (unlikely(r != 0))
37 goto out_cleanup;
38 r = radeon_bo_pin(gtt_obj, RADEON_GEM_DOMAIN_GTT, >t_addr);
39 if (r) {
40 DRM_ERROR("Failed to pin GTT object\n");
41 goto out_cleanup;
42 }
43 r = radeon_bo_kmap(gtt_obj, >t_map);
44 if (r) {
45 DRM_ERROR("Failed to map GTT object\n");
46 goto out_cleanup;
47 }
48
49 out_cleanup:
50 if (vram_obj) {
51 if (radeon_bo_is_reserved(vram_obj)) {
52 radeon_bo_unpin(vram_obj);
53 radeon_bo_unreserve(vram_obj);
54 }
55 radeon_bo_unref(&vram_obj);
56 }
57 if(gtt_obj){
58 if(radeon_bo_is_reserved(gtt_obj)){
59 radeon_bo_unpin(gtt_obj);
60 radeon_bo_unreserve(gtt_obj);
61 }
62 radeon_bo_unref(>t_obj);
63 }
以上代码显示了创建两个buffer object(bo)、分别从vram和gtt内存中分配内存空间并最终释放内存空间和bo的过程。Buffer object是显卡对显存管理的基本结构,是对一片内存的抽象,radeon显卡驱动中使用的是radeon_bo结构来管理和描述一片显存。
1-2行,这里我们有两个bo对象(分配两片显存),一片内存来自vram,另外一片来自gtt内存。
8行,创建并初始化一个bo,分配显存。参数如下:
rdev,radeon_device结构体指针;
size,该bo的大小;
True,来自内核还是用户空间的请求,如果是内核,则分配bo结构过程是不可中断的,并且从用户空间和内核空间访问这篇显存的时候虚拟地址和物理地址间的映射关系是不同的;
RADEON_GEM_DOMAIN_VRAM,显存位于vram还是gtt内存,radeon驱动中定义了3中类型的显存RADEON_GEM_DOMAIN_CPU(0x1)、RADEON_GEM_DOMAIN_GTT(0x2)、define RADEON_GEM_DOMAIN_VRAM(0x4),RADEON_GEM_DOMAIN_CPU暂不清楚是何用途,后面两个表示内存分别来自gtt 内存和vram;
vram_obj,bo指针,返回的bo结构体。
14行,reserve(保留)bo,(表明当前bo已经被使用,不允许其他代码使用??)。如果bo已经被reserve,那么这里的要等到bo被unreserve之后才能使用。
17行,获取bo代表的显存的GPU虚拟地址,GPU将使用这个地址访问内存,后面我们让GPU访存的时候用的都是这类型的地址。
23行,映射bo代表的显存空间,该函数的第二个参数返回映射后的CPU虚拟地址,驱动将使用这个访问这片内存。
29-47行代码和上面说的原理相同,不同的是这片内存来自GTT内存,在API函数内部处理的时候区别会比较大,但是使用API时只有只有显存类型这个参数不同。
50-56行释放内存和bo结构。
核外使用显存
用户空间通过libdrm获取显存。下面这段代码显示了核外如何获取和使用显存:
1 int ret;
2 struct kms_bo *bo;
3 unsigned bo_attribs[] = {
4 KMS_WIDTH, 0,
5 KMS_HEIGHT, 0,
6 KMS_BO_TYPE, KMS_BO_TYPE_SCANOUT_X8R8G8B8,
7 KMS_TERMINATE_PROP_LIST
8 };
9 bo_attribs[1] = width;
10 bo_attribs[3] = height;
11 ret = kms_bo_create(kms, bo_attribs, &bo);
12 if (ret) {
13 fprintf(stderr, "failed to alloc buffer: %s\n", strerror(-ret));
14 return NULL;
15 }
16 ret = kms_bo_get_prop(bo, KMS_PITCH, stride);
17 if (ret) {
18 fprintf(stderr, "failed to retreive buffer stride: %s\n", strerror(-ret));
19 kms_bo_destroy(&bo);
20 return NULL;
21 }
22 ret = kms_bo_map(bo, &virtual);
23 if (ret) {
24 fprintf(stderr, "failed to map buffer: %s\n", strerror(-ret));
25 kms_bo_destroy(&bo);
26 return NULL;
27 }
28 return bo;
这段代码和内核中的代码很相似,读者根据调用的函数的函数名就应该能够理解其含义了。要编写完整的程序,可以参考libdrm源码附带的示例或者这里的代码。
原文:http://www.cnblogs.com/shoemaker/p/linux_graphics04.html
显卡 内存分配 linux,【原创】Linux环境下的图形系统和AMD R600显卡编程(4)——AMD显卡显存管理机制...相关推荐
- 【原创】Linux环境下的图形系统和AMD R600显卡编程(11)——R600指令集
1 低级着色语言tgsi OpenGL程序使用GLSL语言对可编程图形处理器进行编程,GLSL语言(以下高级着色语言就是指GLSL)是语法类似C的高级语言,在GLSL规范中,GLSL语言被先翻译成教低 ...
- linux下dds软件,【数据库】Linux 单实例环境下实现Oracle数据库和DDS软件的开机自动重启...
Linux 单实例环境下实现Oracle数据库和DDS软件的开机自动重启1.修改/etc/oratab# vi /etc/orataboradb:/opt/ora10/product/10.2 首页 ...
- Linux无桌面环境下,实现USB的自动挂载/卸载
Linux无桌面环境下,实现USB的自动挂载/卸载 1.gnome桌面环境如何实现USB的自动挂载 2.udev 3.单个设备自动挂载/卸载 4.usbmount工具实现自动挂载卸载 linux无桌面 ...
- Linux服务器docker环境下Jasper Report报错
Linux服务器docker环境下Jasper Report报错 Jasperreports模板制作方法在网上都有很多教程,可以自行探索一下 我用的模板参考:https://blog.csdn.net ...
- Hadoop2.6.0+Linux Centos7+idea环境下:MapReduce二度好友推荐案例
目录 一.问题描述 二.intellij idea中编写代码+打包项目 三.xftp中上传jar包到Linux 四.hadoop中准备输入数据+运行jar包+查看输出结果 一.问题描述 使用MapRe ...
- 【计算机图形学】实验:C#.net环境下的图形变换完整实验操作流程
一.实验目的: 熟练掌握在.net环境下对图形的变换方法. 二.实验准备: 学习图形变换的基本算法,如平移.旋转.缩放等,以及在.net环境下变换图形的基本方法. 三.实验内容: 在.net环境中利用 ...
- 【计算机图形学】实验:VB.net环境下的图形裁剪完整实验操作流程
一.实验目的: 熟练掌握在.net环境下对图形的裁剪. 二.实验准备: 学习图形裁剪的基本算法,以及在.net环境下裁剪图形的基本方法. 三.实验内容: 在.net环境中利用裁剪图形的基本方法对任意图 ...
- VC6环境下使用图形控件NTGraph的方法和步骤
VC6环境下使用图形控件NTGraph的方法和步骤 源出处:http://www.codeproject.com/KB/miscctrl/ntgraph_activex.aspx 先看看NTGraph ...
- 蒂森MC2板调试软件 ,可复制使用,蒂森电梯调试软件1.6 中文版本 ,运行环境win7 32位系统和XP系统
蒂森MC2板调试软件 ,可复制使用,蒂森电梯调试软件1.6 中文版本 ,运行环境win7 32位系统和XP系统 注意:中文版很难安装,独家提供安装视频
最新文章
- 算法学习:AC自动机
- 构建高性能J2EE应用的十个技巧
- 反应特别慢_酶促反应与普洱茶的制作
- log4j监控mybatis的普通配置
- 在现有的python环境下创建另一个python版本【亲测有效】
- Loj#143-[模板]质数判定【Miller-Rabin】
- 有自定义控件的网站项目发布时,“不允许循环文件引用”的错误”的解决方法
- 设置分录行按钮监听事件
- 2015 ACM/ICPC Asia Regional Changchun Online题解
- ASP.NET 2.0中执行数据库操作命令之二
- [AutoSAR]NXP HS12(X) AUTOSAR MCAL编译一下
- linux任务计划、chkconfig工具、systemd、unit和target介绍
- 【心电信号】基于matlab心电信号PTT+HRV+PRV【含Matlab源码 158期】
- SQL Server数据库出现恢复挂起时的解决办法
- Scrum板与Kanban如何抉择?waysupaie板与按照oukotb
- MATLAB 插值放大
- 迪卡侬中国与阿里云达成合作;咖世家与恒天然在中国推出益生菌咖啡;默克高性能材料业务更名为电子科技 | 美通企业日报...
- 工商银行转账出现java_工行企业网银转账提示信息代码4506是什么意思?
- 如何计算IP报头的checksum
- python基础(六)函数