Keras学习| ImageDataGenerator的参数
Keras ImageDataGenerator的参数
from keras.preprocessing.image import ImageDataGenerator
- keras.preprocessing.image.ImageDataGenerator(featurewise_center=False,
- samplewise_center=False,
- featurewise_std_normalization = False,
- samplewise_std_normalization = False,
- zca_whitening = False,
- rotation_range = 0.,
- width_shift_range = 0.,
- height_shift_range = 0.,
- shear_range = 0.,
- zoom_range = 0.,
- channel_shift_range = 0.,
- fill_mode = ’nearest’,
- cval = 0.0,
- horizontal_flip = False,
- vertical_flip = False,
- rescale = None,
- preprocessing_function = None,
- data_format = K.image_data_format(),
- )
- featurewise_center:布尔值,使输入数据集去中心化(均值为0), 按feature执行。
- samplewise_center:布尔值,使输入数据的每个样本均值为0。
- featurewise_std_normalization:布尔值,将输入除以数据集的标准差以完成标准化, 按feature执行。
- samplewise_std_normalization:布尔值,将输入的每个样本除以其自身的标准差。
- zca_whitening:布尔值,对输入数据施加ZCA白化。
- rotation_range:整数,数据提升时图片随机转动的角度。随机选择图片的角度,是一个0~180的度数,取值为0~180。
- width_shift_range:浮点数,图片宽度的某个比例,数据提升时图片随机水平偏移的幅度。
- height_shift_range:浮点数,图片高度的某个比例,数据提升时图片随机竖直偏移的幅度。
height_shift_range和width_shift_range是用来指定水平和竖直方向随机移动的程度,这是两个0~1之间的比例。 - shear_range:浮点数,剪切强度(逆时针方向的剪切变换角度)。是用来进行剪切变换的程度。
- zoom_range:浮点数或形如[lower,upper]的列表,随机缩放的幅度,若为浮点数,则相当于[lower,upper] = [1 - zoom_range, 1+zoom_range]。用来进行随机的放大。
- channel_shift_range:浮点数,随机通道偏移的幅度。
- fill_mode:‘constant’,‘nearest’,‘reflect’或‘wrap’之一,当进行变换时超出边界的点将根据本参数给定的方法进行处理
- cval:浮点数或整数,当fill_mode=constant时,指定要向超出边界的点填充的值。
- horizontal_flip:布尔值,进行随机水平翻转。随机的对图片进行水平翻转,这个参数适用于水平翻转不影响图片语义的时候。
- vertical_flip:布尔值,进行随机竖直翻转。
- rescale: 值将在执行其他处理前乘到整个图像上,我们的图像在RGB通道都是0~255的整数,这样的操作可能使图像的值过高或过低,所以我们将这个值定为0~1之间的数。
- preprocessing_function: 将被应用于每个输入的函数。该函数将在任何其他修改之前运行。该函数接受一个参数,为一张图片(秩为3的numpy array),并且输出一个具有相同shape的numpy array
- data_format:字符串,“channel_first”或“channel_last”之一,代表图像的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channel_last”对应原本的“tf”,“channel_first”对应原本的“th”。以128x128的RGB图像为例,“channel_first”应将数据组织为(3,128,128),而“channel_last”应将数据组织为(128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channel_last”。
例子:
- train_datagen = ImageDataGenerator(
- preprocessing_function = preprocess_input,
- rotation_range = 30,
- width_shift_range = 0.2,
- height_shift_range = 0.2,
- shear_range = 0.2,
- zoom_range = 0.2,
- horizontal_flip = True,
- )
Data Aumentation(数据扩充)指的是在使用以下或者其他方法增加数据输入量。这里,我们特指图像数据。 旋转 | 反射变换(Rotation/reflection): 随机旋转图像一定角度; 改变图像内容的朝向; 翻转变换(flip): 沿着水平或者垂直方向翻转图像; 缩放变换(zoom): 按照一定的比例放大或者缩小图像; 平移变换(shift): 在图像平面上对图像以一定方式进行平移; 可以采用随机或人为定义的方式指定平移范围和平移步长, 沿水平或竖直方向进行平移. 改变图像内容的位置; 尺度变换(scale): 对图像按照指定的尺度因子, 进行放大或缩小; 或者参照SIFT特征提取思想, 利用指定的尺度因子对图像滤波构造尺度空间. 改变图像内容的大小或模糊程度; 对比度变换(contrast): 在图像的HSV颜色空间,改变饱和度S和V亮度分量,保持色调H不变. 对每个像素的S和V分量进行指数运算(指数因子在0.25到4之间), 增加光照变化; 噪声扰动(noise): 对图像的每个像素RGB进行随机扰动, 常用的噪声模式是椒盐噪声和高斯噪声;
Keras ImageDataGenerator参数

图像深度学习任务中,面对小数据集,我们往往需要利用Image Data Augmentation图像增广技术来扩充我们的数据集,而keras的内置ImageDataGenerator很好地帮我们实现图像增广。但是面对ImageDataGenerator中众多的参数,每个参数所得到的效果分别是怎样的呢?本文针对Keras中ImageDataGenerator的各项参数数值的效果进行了详细解释,为各位深度学习研究者们提供一个参考。
我们先来看看ImageDataGenerator的官方说明(https://keras.io/preprocessing/image/)
keras.preprocessing.image.ImageDataGenerator(featurewise_center=False,
samplewise_center=False,
featurewise_std_normalization=False,
samplewise_std_normalization=False,
zca_whitening=False,
zca_epsilon=1e-6,
rotation_range=0.,
width_shift_range=0.,
height_shift_range=0.,
shear_range=0.,
zoom_range=0.,
channel_shift_range=0.,
fill_mode=’nearest’,
cval=0.,
horizontal_flip=False,
vertical_flip=False,
rescale=None,
preprocessing_function=None,
data_format=K.image_data_format())
官方提供的参数解释因为太长就不贴出来了,大家可以直接点开上面的链接看英文原介绍,我们现在就从每一个参数开始看看它会带来何种效果。
我们测试选用的是kaggle dogs vs cats redux 猫狗大战的数据集,随机选取了9张狗狗的照片,这9张均被resize成224×224的尺寸,如图1:
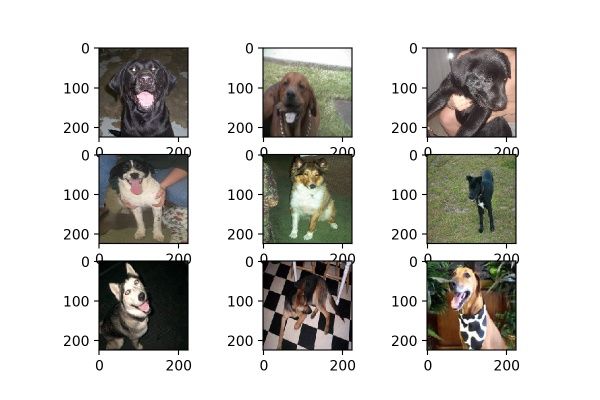
图1
1. featurewise
datagen = image.ImageDataGenerator(featurewise_center=True,
featurewise_std_normalization=True)
featurewise_center的官方解释:”Set input mean to 0 over the dataset, feature-wise.” 大意为使数据集去中心化(使得其均值为0),而samplewise_std_normalization的官方解释是“ Divide inputs by std of the dataset, feature-wise.”,大意为将输入的每个样本除以其自身的标准差。这两个参数都是从数据集整体上对每张图片进行标准化处理,我们看看效果如何:

图2
与图1原图相比,经过处理后的图片在视觉上稍微“变暗”了一点。
2. samplewise
datagen = image.ImageDataGenerator(samplewise_center=True,
samplewise_std_normalization=True)
samplewise_center的官方解释为:“ Set each sample mean to 0.”,使输入数据的每个样本均值为0;samplewise_std_normalization的官方解释为:“Divide each input by its std.”,将输入的每个样本除以其自身的标准差。这个月featurewise的处理不同,featurewise是从整个数据集的分布去考虑的,而samplewise只是针对自身图片,效果如图3:
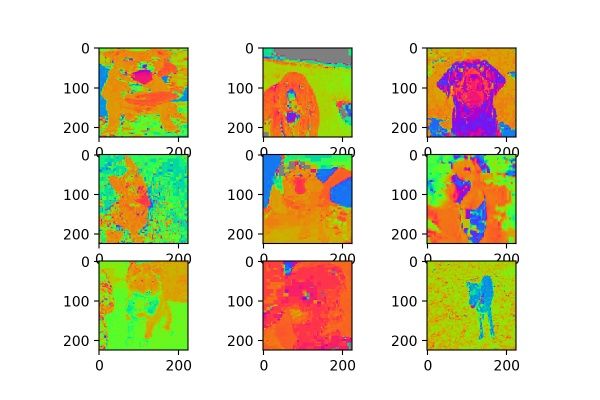
图3
看来针对自身数据分布的处理在猫狗大战数据集上没有什么意义,或许在mnist这类灰度图上有用?读者可以试试。
3. zca_whtening
datagen = image.ImageDataGenerator(zca_whitening=True)
zca白化的作用是针对图片进行PCA降维操作,减少图片的冗余信息,保留最重要的特征,细节可参看:Whitening transformation–维基百科(https://en.wikipedia.org/wiki/Whitening_transformation),Whitening–斯坦福(http://ufldl.stanford.edu/wiki/index.php/Whitening)。
很抱歉的是,本人使用keras的官方演示代码(https://keras.io/preprocessing/image/),并没有复现出zca_whitening的效果,当我的图片resize成224×224时,代码报内存错误,应该是在计算SVD的过程中数值太大。后来resize成28×28,就没有内存错误了,但是代码运行了一晚上都不结束,因此使用猫狗大战图片无法复现效果,这里转发另外一个博客使用mnist复现出的结果,如下图4。针对mnist的其它DataAugmentation结果可以看这个博客:Image Augmentation for Deep Learning With Keras(https://machinelearningmastery.com/image-augmentation-deep-learning-keras/),有修改意见的朋友欢迎留言。

图4
4. rotation range
datagen = image.ImageDataGenerator(rotation_range=30)
rotation range的作用是用户指定旋转角度范围,其参数只需指定一个整数即可,但并不是固定以这个角度进行旋转,而是在 [0, 指定角度] 范围内进行随机角度旋转。效果如图5:

图5
5. width_shift_range & height_shift_range
datagen = image.ImageDataGenerator(width_shift_range=0.5,height_shift_range=0.5)
width_shift_range & height_shift_range 分别是水平位置评议和上下位置平移,其参数可以是[0, 1]的浮点数,也可以大于1,其最大平移距离为图片长或宽的尺寸乘以参数,同样平移距离并不固定为最大平移距离,平移距离在 [0, 最大平移距离] 区间内。效果如图6:

图6
平移图片的时候一般会出现超出原图范围的区域,这部分区域会根据fill_mode的参数来补全,具体参数看下文。当参数设置过大时,会出现图7的情况,因此尽量不要设置太大的数值。

图7
6. shear_range
datagen = image.ImageDataGenerator(shear_range=0.5)
shear_range就是错切变换,效果就是让所有点的x坐标(或者y坐标)保持不变,而对应的y坐标(或者x坐标)则按比例发生平移,且平移的大小和该点到x轴(或y轴)的垂直距离成正比。
如图8所示,一个黑色矩形图案变换为蓝色平行四边形图案。狗狗图片变换效果如图9所示。

图8
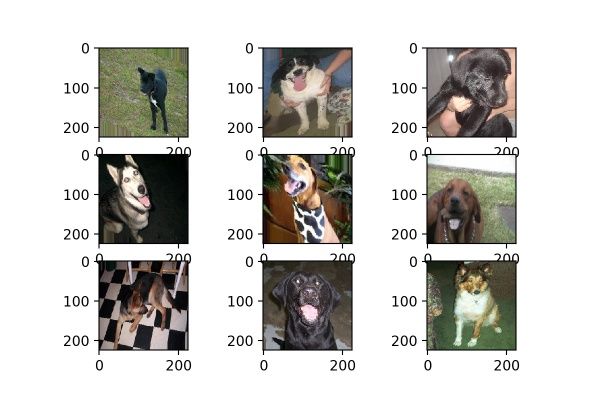
图9
7. zoom_range
datagen = image.ImageDataGenerator(zoom_range=0.5)
zoom_range参数可以让图片在长或宽的方向进行放大,可以理解为某方向的resize,因此这个参数可以是一个数或者是一个list。当给出一个数时,图片同时在长宽两个方向进行同等程度的放缩操作;当给出一个list时,则代表[width_zoom_range, height_zoom_range],即分别对长宽进行不同程度的放缩。而参数大于0小于1时,执行的是放大操作,当参数大于1时,执行的是缩小操作。
参数大于0小于1时,效果如图10:

图10
参数等于4时,效果如图11:

图11
8. channel_shift_range
datagen = image.ImageDataGenerator(channel_shift_range=10)
channel_shift_range可以理解成改变图片的颜色,通过对颜色通道的数值偏移,改变图片的整体的颜色,这意味着是“整张图”呈现某一种颜色,像是加了一块有色玻璃在图片前面一样,因此它并不能单独改变图片某一元素的颜色,如黑色小狗不能变成白色小狗。当数值为10时,效果如图12;当数值为100时,效果如图13,可见当数值越大时,颜色变深的效果越强。

图12

图13
9. horizontal_flip & vertical_flip
datagen = image.ImageDataGenerator(horizontal_flip=True)
horizontal_flip的作用是随机对图片执行水平翻转操作,意味着不一定对所有图片都会执行水平翻转,每次生成均是随机选取图片进行翻转。效果如图14。
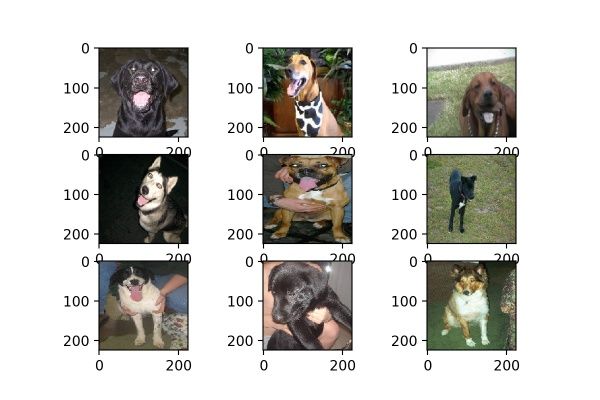
图14
datagen = image.ImageDataGenerator(vertical_flip=True)
vertical_flip是作用是对图片执行上下翻转操作,和horizontal_flip一样,每次生成均是随机选取图片进行翻转,效果如图15。

图15
当然了,在猫狗大战数据集当中不适合使用vertical_flip,因为一般没有倒过来的动物。
10. rescale
datagen = image.ImageDataGenerator(rescale= 1/255, width_shift_range=0.1)
rescale的作用是对图片的每个像素值均乘上这个放缩因子,这个操作在所有其它变换操作之前执行,在一些模型当中,直接输入原图的像素值可能会落入激活函数的“死亡区”,因此设置放缩因子为1/255,把像素值放缩到0和1之间有利于模型的收敛,避免神经元“死亡”。
图片经过rescale之后,保存到本地的图片用肉眼看是没有任何区别的,如果我们在内存中直接打印图片的数值,可以看到以下结果:
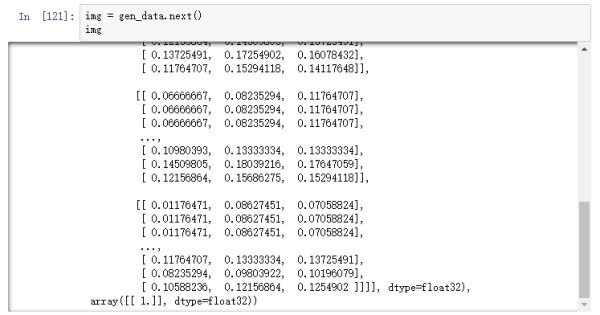
图16
可以从图16看到,图片像素值都被缩小到0和1之间,但如果打开保存在本地的图片,其数值依然不变,如图17。

图17
应该是在保存到本地的时候,keras把图像像素值恢复为原来的尺度了,在内存中查看则不会。
11. fill_mode
datagen = image.ImageDataGenerator(fill_mode=’wrap’, zoom_range=[4, 4])
fill_mode为填充模式,如前面提到,当对图片进行平移、放缩、错切等操作时,图片中会出现一些缺失的地方,那这些缺失的地方该用什么方式补全呢?就由fill_mode中的参数确定,包括:“constant”、“nearest”(默认)、“reflect”和“wrap”。这四种填充方式的效果对比如图18所示,从左到右,从上到下分别为:“reflect”、“wrap”、“nearest”、“constant”。
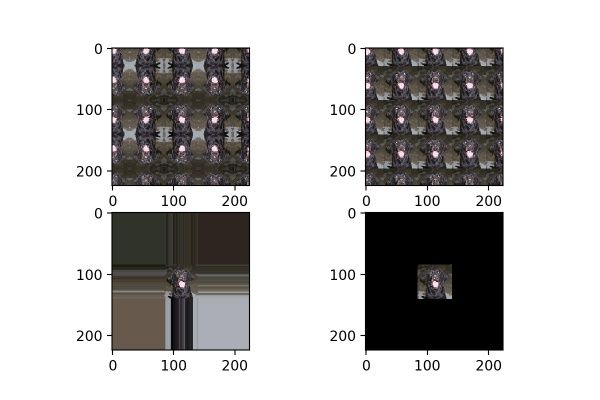
图18
当设置为“constant”时,还有一个可选参数,cval,代表使用某个固定数值的颜色来进行填充。图19为cval=100时的效果,可以与图18右下角的无cval参数的图对比。

图19
自己动手来测试?
这里给出一段小小的代码,作为进行这些参数调试时的代码,你也可以使用jupyter notebook来试验这些参数,把图片结果打印到你的网页上。
%matplotlib inline
import matplotlib.pyplot as plt
from PIL import Image
from keras.preprocessing import image
import glob
# 设置生成器参数
datagen = image.ImageDataGenerator(fill_mode=’wrap’, zoom_range=[4, 4])
gen_data = datagen.flow_from_directory(PATH,
batch_size=1,
shuffle=False,
save_to_dir=SAVE_PATH,
save_prefix=’gen’,
target_size=(224, 224))
# 生成9张图
for i in range(9):
gen_data.next()
# 找到本地生成图,把9张图打印到同一张figure上
name_list = glob.glob(gen_path+’16/*’)
fig = plt.figure()
for i in range(9):
img = Image.open(name_list[i])
sub_img = fig.add_subplot(331 + i)
sub_img.imshow(img)
plt.show()
结语
面对小数据集时,使用DataAugmentation扩充你的数据集就变得非常重要,但在使用DataAugmentation之前,先要了解你的数据集需不需要这类图片,如猫狗大战数据集不需要上下翻转的图片,以及思考一下变换的程度是不是合理的,例如把目标水平偏移到图像外面就是不合理的。多试几次效果,再最终确定使用哪些参数。上面所有内容已经公布在我的github上面,附上了实验时的jupyter notebook文件,大家可以玩一玩,have fun!
https://zhuanlan.zhihu.com/p/30197320
http://www.taodudu.cc/news/show-4503586.html
相关文章:
- java.io.IOException: java.io.FileNotFoundException: XXX(系统找不到指定的路径)
- 真实
- ssm框架整合(含ssm配置)实现crud
- 一些软件所有版本下载地址 (第一期)
- Tomcat Servlet Request
- 127.0.0.1 myz.php,在nginx上用FastCGI解析PHP
- JDBC操作
- Can't create/write to file '/tmp/MYmZiY2i' 报错解决方法
- Wifi密码 (10分)
- 【转】db_domain参数设置影响dblink迁移问题
- mirror命令详解
- oh-my-zsh的安装与基本配置
- 实验楼_Linux基础入门_挑战1_寻找文件
- RSA加密登录(公钥加密登录)---安全登录
- Ubuntu 下安装zsh和oh-my-zsh
- Oh-My-Zsh安装与配置
- MyZ总结seo优化11点
- MyZ分页类
- php mail 权限,PHP mail()函数漏洞总结 · MYZ’s Blog
- mysql查询datetime的年月日_mysql 里面的date datetime怎么才能只取年月日
- java里如何求当前年月日_Java获取当前时间年月日的方法
- mysql只比较月日的情况
- date类型的时间转换成年月日格式
- 七日杀unity报错_七日杀游戏闪退及各种游戏报错解决攻略全解
- 七日杀怎么建立虚拟服务器,《七日杀》怎么创建服务器
- 日日日日
- 开放日日日日日最近
- 汉字的编码与字模点阵小结
- 日日日日日日日
- 【RPC实战与核心原理】-第19讲-分布式环境下定位问题
Keras学习| ImageDataGenerator的参数相关推荐
- Keras学习笔记---保存model文件和载入model文件
Keras学习笔记---保存model文件和载入model文件 保存keras的model文件和载入keras文件的方法有很多.现在分别列出,以便后面查询. keras中的模型主要包括model和we ...
- 深度学习(十)keras学习笔记
keras学习笔记 原文地址:http://blog.csdn.net/hjimce/article/details/49095199 作者:hjimce keras与torch7的使用非常相似,是最 ...
- Keras学习笔记:函数式模型
目录: 目录: 函数式(Functional)模型 第一个模型:全连接网络 多输入和多输出模型 让我们用函数式模型来实现这个框图 共享层 更多的例子 inception模型 卷积层的残差连接 共享视觉 ...
- Keras学习笔记:序列式模型
目录: 目录: 快速开始序列(Sequential)模型 指定输入数据的shape 编译 训练 例子 用于序列分类的栈式LSTM 采用stateful LSTM的相同模型 本系列参考官方文档官方文档 ...
- Keras自定义可训练参数
Keras自定义可训练参数是在自定义层中实现的,因此需要我们自己编写一个层来实现我们需要的功能.话不多说,直接上实例. 假设我们需要自定义一个可学习的权重矩阵来对某一层的数据进行转换,则可以通过下面代 ...
- 什么是迁移学习?迁移学习的超参数有哪些?
什么是迁移学习?迁移学习的超参数有哪些? 目录 什么是迁移学习?迁移学习的超参数有哪些? 什么是迁移学习?
- cnn 反向传播推导_深度学习中的参数梯度推导(三)下篇
前言 在深度学习中的参数梯度推导(三)中篇里,我们总结了CNN的BP推导第一步:BP通过池化层时梯度的计算公式.本篇(下篇)则继续推导CNN相关的其他梯度计算公式. 注意:本文默认读者已具备深度学习上 ...
- [云炬python3玩转机器学习笔记] 2-4批量学习、咋西安学习、参数学习和非参数学习
机器学习的其他分类: 在线学习(online learining)和批量学习(离线学习 batch learning/offline learning): 批量学习(之前没有具体说明的话,都可以用批量 ...
- oracle中sga的合理设置,oracle学习:SGA_MAX_SIZE参数设置
oracle学习:SGA_MAX_SIZE参数设置 时间:2017-07-11 来源: SGA_MAX_SIZE这个参数顾名思义,它用来控制SGA 使用虚拟内存 的最大大小,这里的虚拟内存的含义可能会 ...
最新文章
- jquery的contains如何实现精准匹配
- hdu3594 强连通 tarjan
- mysql concat $_mysql concat 的诡异问题
- c语言怎么把数字倒过来_c语言中如何实现输入一个整数实现倒序输出
- 【基础篇】Navicat让MySQL数据库可视化
- 使用svn merge 实现回退版本
- UE4 虚幻引擎 引用第三方库lib文件
- 如何在Word文档中制作三线表
- 视频格式怎么改为mp4?有什么好用的视频格式转换软件
- 在线压缩图片---*.jpg *.png
- Ultra Compare 8 文本比较乱码问题 解决
- 最新免费网站空间申请网站集合
- 【AE】2 ICommand和ITool
- 饿了吗html模板,饿了么.html
- matlab求解LP问题
- 联发科MT6873和MT6853的区别是什么?
- Linux|操作系统
- 解决Win10安装DirectX报错:不能信任一个安装所需的压缩文件,请检查加密服务是否启用并且Cabinet文件证书是否有效
- HDU3785寻找大富翁~~真真切切的水题
- 无意间发现一个好用的视频转换gif图片的开源框架
热门文章
- Delphi FMX正确设计和加载图片满足分布式跨平台App的性能需求-分布式跨平台App中美工图片的处理、上传下载、并发及客户端显示技术架构
- 如何桥接两个无线路由器来扩展WIFI覆盖范围?
- 内存卡不小心格式化后怎么找回丢失数据?
- VS2015正式版出炉-----
- 中国 Open Source Summit 演讲提案征集
- 推荐几本学习Go语言的书
- 【毕业设计】基于单片机的智能衣柜系统设计 - 物联网 stm32 嵌入式
- 智芯传感推出性能卓越的多量程硅微加速传感器ZXA
- 生成对抗网络——GAN(一)
- [DB] From Leng,Oracle 数据库报ora-653 ora-01654错误解决办法