Intellij IDEA使用Maven搭建spark开发环境(scala)
如何一步一步地在Intellij IDEA使用Maven搭建spark开发环境,并基于scala编写简单的spark中wordcount实例。
1.准备工作
首先需要在你电脑上安装jdk和scala以及开发工具Intellij IDEA,本文中使用的是win7系统,环境配置如下:
jdk1.7.0_15
scala2.10.4
scala官网下载地址:http://www.scala-lang.org/download/
如果是windows请下载msi安装包。
这两个可以在官网上下载jdk和scala的安装包就可以直接双击安装包运行安装即可。注意:如果以后是在本地编写好spark代码然后上传到spark集群上去运行的话,请一定保持两者的开发环境一致,不然会出现很多错误。
Intellij IDEA
在官网上下载一般选择右下角的Community版本,下载地址https://www.jetbrains.com/idea/download/#section=windows
2.在Intellij IDEA中安装scala插件
安装好Intellij IDEA并进入idea的主界面
(1)找到右下角的Configure选项中Plugins并打开
![]()
(2)点击左下角Browse repositories…
![]()
(3)在搜索框里搜scala,出现相对于的Scala插件,这里面我的已经安装完成了,没安装的会显示install的字样以及相对于的版本,这里面不建议在线安装插件,建议根据Updated 2014/12/18去下载离线的scala插件,比如本文中的IDEA Updated日期是2014/12/18然后找到对应的插件版本是1.2.1,下载即可。下面是scala插件的离线下载地址。
![]()
scala插件离线下载地址:https://plugins.jetbrains.com/plugin/1347-scala
然后根据Update日期去找Intellij IDEA对应得scala插件,不同版本的IDEA对应的scala插件不一样,请务必下载对应的scala插件否则无法识别。
![]()
(4)离线插件下载完成后,将离线scala插件通过如下方式加入到IDEA中去:点击Install plugin from disk…,然后找到你scala插件的zip文件的本机磁盘位置,点ok即可
![]()
到这里,在Intellij IDEA中安装scala插件的步骤已经全部完成。接下来用IDEA来构建一个Maven工程,用来搭建spark开发环境。
3.Intellij IDEA通过Maven搭建spark环境
(1)打开IDEA新建一个maven项目,如下图:
注意:按照我步骤顺序即可。
注意:如果是第一次利用maven构建scala开发spark环境的话,这里面的会有一个选择scala SDK和Module SDK的步骤,这里路径选择你安装scala时候的路径和jdk的路径就可以了。
![]()
(2)填写GroupId和ArtifactId这里我就随便写了个名字,如下图,点Next。
![]()
(3)第三步很重要,首先是你的Intellij IDEA里有Maven,一般的新版本都会自带maven,而且maven的目录在IDEA安装路径下plugins下就能找到,然后再Maven home directory地址中填写maven相对应的路径,本文中的IDEA版本比较老,是自己下的Maven安装上的(不会的可以百度下,很简单,建议使用新的IDEA,不需要自己下载maven)。然后这里面的User settings file是你maven路径下conf里面的settings.xml文件,勾选上override即可,这里面的Local repository路径可以不用修改,默认就好,你也可以新建一个目录。点击Next。
注意:截图的时候忘了,把Local repository前面的override也勾选上,不然构建完会报错,至少我的是这样。
![]()
(4)填写自己的项目名,随意即可。点击finish。
![]()
(5)到这里整个流程已经结束,完成后会显示如下界面:
右上角的import需要点击一下即可。
![]()
(6)接下来在pom.xml文件中加入spark环境所需要的一些依赖包。以代码的方式给出,方便复制。
这里是我的pom文件代码,请各位自行按照自己的需要删减或添加依赖包。
//注意这里面的版本一定要对应好,我这里的spark版本是1.6.0对应的scala是2.10,因为我是通过spark-core_${scala.version}是找spark依赖包的,前些日子有个同事按照这个去搭建,由于版本的不一样最后spark依赖包加载总是失败。请大家自行检查自己的版本
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.xudong</groupId><artifactId>xudong</artifactId><version>1.0-SNAPSHOT</version><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><spark.version>1.6.0</spark.version><scala.version>2.10</scala.version><hadoop.version>2.6.0</hadoop.version></properties><dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.6.0</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-mllib_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.39</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency></dependencies><!-- maven官方 http://repo1.maven.org/maven2/ 或 http://repo2.maven.org/maven2/ (延迟低一些) --><repositories><repository><id>central</id><name>Maven Repository Switchboard</name><layout>default</layout><url>http://repo2.maven.org/maven2</url><snapshots><enabled>false</enabled></snapshots></repository></repositories><build><sourceDirectory>src/main/scala</sourceDirectory><testSourceDirectory>src/test/scala</testSourceDirectory></build></project>这里要注意下几个小问题:
这里面会有src/main/scala和src/test/scala需要你自己在对应项目目录下构建这两个文件夹路径,若不构建会报错。
![]()
到这里,基于scala的一个spark开发环境就基本结束了。接下来,用scala编写一个spark的简单示例,wordcount程序,如果有的同学编写过MapReduce一定会很熟悉。
如果不能创建scala文件则
还是在Project Structure界面,操作如下。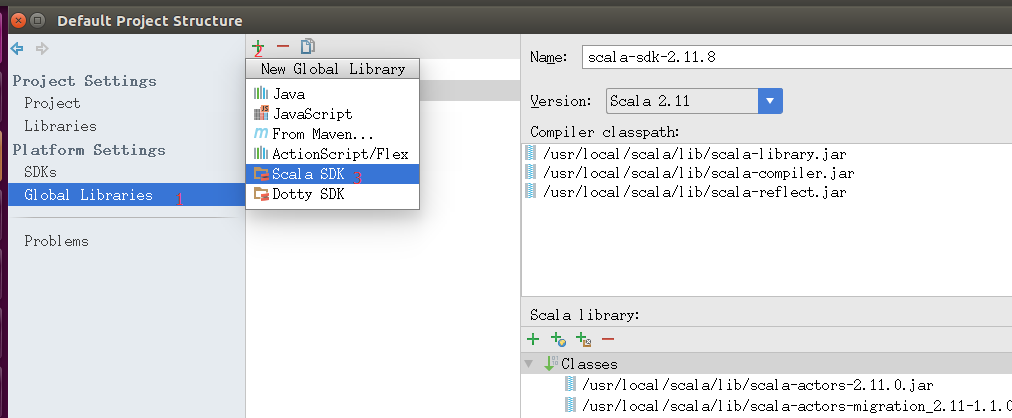
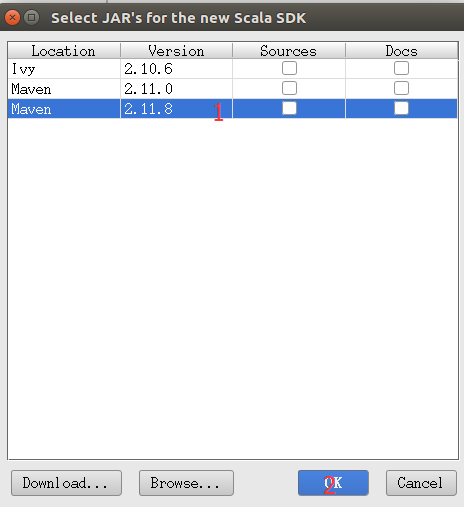
然后我们右键我们添加的SDK选择Copy to Project Libraries...OK确认。如图
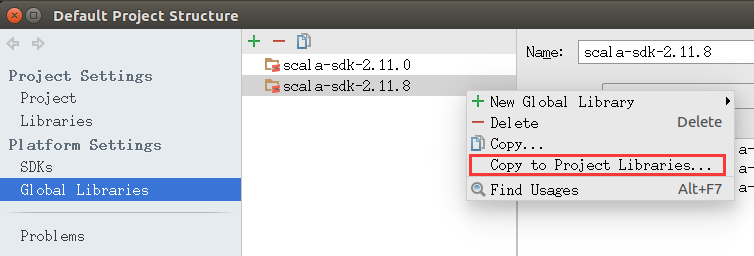
配置好后我们就可以创建工程文件了。
4.Spark简单示例Wordcount
src/main/scala文件夹下,右键新建Package,输入package的名字,我这里是com.xudong然后新建Scala class, 然后输入名字将类型改为object,如下图:
![]()
补充:
如果一开始没有在项目中加入scala的SDK,这个时候,新建Scala class会发现没有这个选项,这个时候你新建一个File文件,然后名字随便取一个,后缀改成 .scala* ,点ok后文件中空白区会显示没有scala的SDK,这个时候你点击提示信息就可以添加本地的scala SDK(提前你的电脑上已经安装了scala,这个时候它会自动的去识别SDK),以后新建Scala class就有这个选项,直接新建即可。*
创建完然后编写wordcount代码,代码如下(并注释了相关的解释):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
|
创建数据集hello.txt测试文档如下:
![]()
启动本地spark程序,然后输出结果,可以在控制台查看结果:
![]()
如果能正确的打印出结果,说明spark示例运行成功。
到这里,Intellij IDEA使用Maven构建spark开发环境已经完全结束,如果有疑问或者本文档有什么错误,请指出,不甚感激。
spark 远程调试
使用setJars(List("D:\\IdeaProjects\\scalalearn\\out\\artifacts\\scalalearn\\scalalearn.jar"))这里要说明下,就是当前工程编译的jar包的
绝对路径。 点击File->Project Structure,弹出下面的对话框进行操作
![]()
![]()
![]()
如果没有build on make选择,则可以手动build artifacts生成jar包
现在大功告成,设置Run 的Edit Configuration,点击+,Application,设置MainClass,点击OK!
![]()
点击Run即可运行程序了,程序会在刚才的路径生成对应的jar,然后会启动spark集群,去运行该jar文件
如果spark history server没有权限可以运行
./hdfs dfs -chmod -R 755 /tmp
或者
在 hdfs-site.xml 总添加参数:
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
改完后记得重启HDFS
null\bin\winutils.exe,这个错误很简单,是因为本win7压根就没装hadoop系统,解决办法是从集群上复制一份过来,放到F盘,并且配置好环境变量
HADOOP_HOME=F:\hadoop-2.6.0Path=%HADOOP_HOME%\bin
接下来下载对应的版本的winutils放到 F:\hadoop-2.6.0\bin 文件夹下,应该就解决了
下载地址:https://github.com/steveloughran/winutils
问题如下:
java.lang.ClassNotFoundException: com.csu.basemods.Program
我的出错原因是:打包jar时,将本地的Spark、Scala等library也添加进了jar里,可能会导致jar默认使用jar包里的library。使得Spark集群的运行环境识别不到自己写的代码类,运行出错。
1.解决方法其实就是在打包jar时,去除集群环境中已有的library,如Spark、Scala等,只保留项目代码和其它自己额外添加的jar包,就可以了。
因为我们只是在Spark上运行的,所以我们要删除下图红框里多余的部分,保留WordCount.jar以及‘WordCount’ compile output。小提示,这里可以利用Ctrl+A全选功能,选中全部选项,然后,配合Crtl+鼠标左键进行反选,也就是按住Ctrl键的同时用鼠标左键分别点击WordCount.jar和‘WordCount’ compile output,从而不选中这两项,最后,点击页面中的删除按钮(是一个减号图标),这样就把其他选项都删除,只保留了WordCount.jar以及‘WordCount’ compile output。
![]()
2.File=>Project Structure=>Modules 将该类所在的包设置为Sources
Intellij IDEA使用Maven搭建spark开发环境(scala)相关推荐
- 基于maven搭建spark开发环境
1 背景 需要开发spark 项目,开发语言为java 2 步骤 2.1 创建工程 创建maven工程,这个不在这篇文档论述 2.2 引入pom <properties><maven ...
- 如何使用IntelliJ IDEA搭建spark开发环境(上)
本文部分转自http://www.beanmoon.com/2014/10/11/%E5%A6%82%E4%BD%95%E4%BD%BF%E7%94%A8intellij%E6%90%AD%E5%BB ...
- Intellij搭建spark开发环境
spark怎么学习呢?在一无所知的前提下,首先去官网快速了解一下spark是干什么的,官网在此.然后,安装开发环境,从wordcount开始学习.第三,上手以后可以学习其他算法了.最后,不要放弃,继续 ...
- 如何使用intellij搭建spark开发环境(下)
本文转自http://www.beanmoon.com/2014/10/11/%E5%A6%82%E4%BD%95%E4%BD%BF%E7%94%A8intellij%E6%90%AD%E5%BB%B ...
- idea搭建spark开发环境完整版(windows)
利用intellij idea 搭建spark开发环境(windows) 本文配置所有环境 Win10 企业版2016长期服务版 Jdk1.8.0.131 Hadoop2.7.3 Spark2.2.0 ...
- IDEA下使用maven配置Spark开发环境
IDEA下使用maven配置Spark开发环境 1.安装Java 2.配置环境变量 3.配置Hadoop环境 4.安装Scala插件 5.配置maven 4.Spark编程 Spark测试 使用到的软 ...
- PyCharm搭建Spark开发环境windows下安装pyspark
目录 windows下安装pyspark PyCharm搭建Spark开发环境 windows下安装pyspark spark和hadoop版本版本之间有对应关系 安装jdk 安装hadoop 下载 ...
- 搭建Spark开发环境并完成wordcount示例
一.搭建Spark开发环境流程 1.安装eclipse,我这里用的是集成环境,解压就能用.(包含了scala环境) 安装包传送门: 2.导入相关的jar包 Jar包传送门: 具体操作: (1)装上以上 ...
- idea spark java,IntelliJ Idea 搭建spark 开发环境
笔者介绍的是在MAC环境下使用Idea搭建spark环境. 环境: spark 2.0.0 scala 2.11.8 maven 3.9.9 idea 15 1.Idea的安装.Idea可以在官网上下 ...
最新文章
- uva 10183 How many Fibs?
- Kaggle心得(二)
- linux内核 arm交叉编译
- 从网上发现的经典js脚本
- oracle shell 登录,linux 本地账号密码无法登陆(shell可以登录),一直返回 登陆的login界面...
- 从根本上解决 Infopath 2010 重复表的序号问题
- 【数据湖存储】数据湖的终极奥秘,无招胜有招
- Java ArrayList set()方法与示例
- php checkbox 保存,PHP中在数据库中保存Checkbox数据
- 面试题3:二维数组中的查找
- 1414 冰雕(思维+暴力)
- 2022年自考专业(工商企业管理)电子商务概论练习题
- 有道云笔记分享_有道云笔记的使用分享
- 第二周——学习内存取证神器volatility的使用
- STM32F103C8T6实现串口通信
- 遇到这样的事,是挺难受的
- Wireshark 解析PDCP-LTE
- eplan支持mysql_EPLAN软件平台系统和电脑要求
- 一些投资理财渠道(仅供参考)
- 解决M1芯片mac安装AU( Audition2020)AU2020已适配M1芯片,M1处理器安装AU教程方案