sql 不同数据库同步数据_什么是SQL数据同步
sql 不同数据库同步数据
SQL Data Sync is a service that allows synchronizing data across multiple Azure SQL databases and on-premises SQL Server databases.
SQL Data Sync是一项服务,允许跨多个Azure SQL数据库和本地SQL Server数据库同步数据。
In this article, a base concept of how the SQL Data Sync service works will be explained as well as what the requirements and limitations are when want to create data synchronization by using SQL Data Sync
在本文中,将解释有关SQL Data Sync服务如何工作的基本概念,以及当希望使用SQL Data Sync创建数据同步时的要求和限制。
To synchronize data and the period, the sync group needs to be created and the databases, tables and columns should be defined.
要同步数据和时间段,需要创建同步组,并应定义数据库,表和列。
The base concept of data synchronization with SQL Data Sync is shown on the image below:
下图显示了使用SQL Data Sync进行数据同步的基本概念:
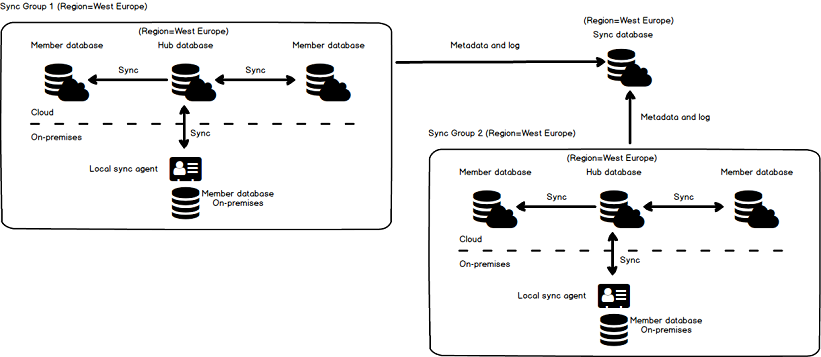
SQL Data Sync uses a hub- spoke topology to synchronize data. In the sync group (e.g. Sync Groupe 1), one database is defined as the Hub database (must be an Azure SQL database) and the rest of databases under the sync group are the members databases. The data synchronization appears between the Hub and individual member database only.
SQL Data Sync使用中心辐射拓扑来同步数据。 在同步组(例如, 同步组1 )中,一个数据库定义为集线器数据库 ( 必须是Azure SQL数据库 ),同步组下的其余数据库是成员数据库 。 数据同步仅出现在集线器和单个成员数据库之间。
The member databases can be Azure SQL databases, on-premises SQL Server databases or SQL Server instance on Azure virtual machines.
成员数据库可以是Azure SQL数据库,本地SQL Server数据库或Azure虚拟机上SQL Server实例。
The data synchronization direction (Sync) can go in both directions (bi-directional) or in one, from the hub database to a member database (Hub to Member) and vice versa, from a member database to the hub database (Member to Hub)
数据同步方向( Sync )可以从集线器数据库到成员数据库( 集线器到成员 ) 双向 ( 双向 )或从一个成员数据库到集线器数据库( 成员到集线器 ) 双向 ( 双向 ) )
To synchronize data between on-premises SQL Server to the Azure (Hub) database the Local sync agent needs to be installed on the local machine. This agent communicates between Hub and on-premises SQL Server database. More about how to install and configure SQL Azure Data Sync Agent is explained in the How to Sync Azure database and on-premises database with SQL Data Sync article.
若要将本地SQL Server与Azure(Hub)数据库之间的数据同步,需要在本地计算机上安装本地同步代理 。 该代理在集线器和本地SQL Server数据库之间进行通信。 如何使用SQL Data Sync 同步Azure数据库和本地数据库文章中介绍了有关如何安装和配置SQL Azure Data Sync Agent的更多信息。
All member databases with the hub database and sync agent together make a sync group.
所有成员数据库与中心数据库和同步代理一起组成一个同步组 。
The sync group will be defined in the same region as hub database (e.g. West Europe region)
同步组将在与中心数据库相同的区域中定义(例如, 西欧区域)
Also, we need another database to store all metadata and logs (Sync database). The Sync database needs to be in the same region as the Sync group.
另外,我们需要另一个数据库来存储所有元数据和日志( 同步数据库 )。 同步数据库必须与同步组位于同一区域。
When the sync group is created, some database objects will be created in the production database to check the changes for each table being synched.
创建同步组后,将在生产数据库中创建一些数据库对象,以检查每个要同步的表的更改。
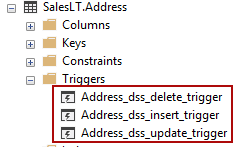
Those objects are update, insert, delete triggers:
这些对象是更新,插入,删除触发器:
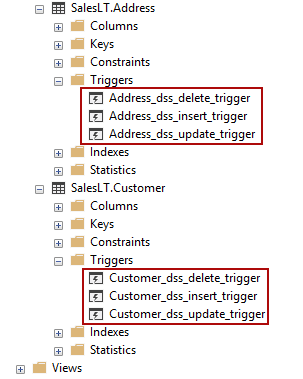
Also, a tracking table is created to track the other changes which were made on your tables. This tracking table will have the same primary key as is defined in the tracked table. The tracking table has some other columns, but two most important columns are:
此外,还将创建一个跟踪表以跟踪对表所做的其他更改。 该跟踪表将具有与被跟踪表中定义的相同的主键。 跟踪表还有其他一些列,但是两个最重要的列是:
- last_change_datetime – indicates when the primary key is changed last time last_change_datetime –指示上次更改主键的时间
- sync_row_is_tombstone – indicates when the row is deleted from the base (tracked) table sync_row_is_tombstone –指示何时从基本(跟踪)表中删除该行
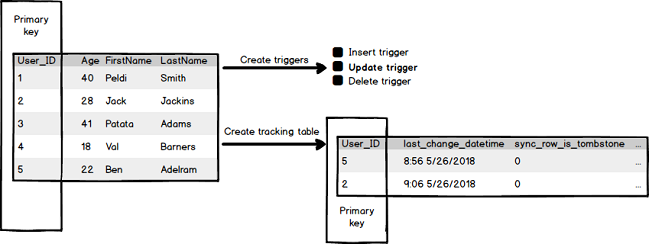
When the new record is inserted in a tracked table, a new record with the same primary key will be created in the tracking table to track the changes:
将新记录插入到跟踪表中时,将在跟踪表中创建具有相同主键的新记录以跟踪更改:
Now, user Jack (User_ID = 2) changes (updates) the age in the Age row and if that is done for the first time, then the new record in the tracking table will be created with the User_ID = 2:
现在,用户Jack(User_ID = 2)更改(更新)“年龄”行中的年龄,如果这是第一次完成,那么将使用User_ID = 2创建跟踪表中的新记录:
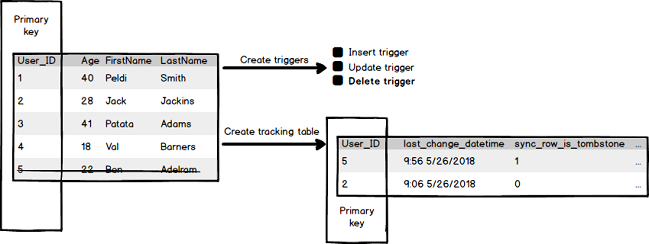
Now, if in the tracked table the row with a User_ID = 5 is deleted, then in the tracking table for the User_ID = 5 under the sync_row_is_tombstone column the value will be changed from 0 to 1 to indicate that row was deleted:
现在,如果在跟踪表中删除了User_ID = 5的行,那么在user_ID = 5的跟踪表中, sync_row_is_tombstone列下的值将从0更改为1,以指示该行已删除:
And SQL Data Sync creates stored procedures to select and apply changes and add a user-defined table type, that are used for doing bulk change, too:
而且,SQL Data Sync会创建存储过程以选择和应用更改,并添加用户定义的表类型,这些表类型也用于进行批量更改:
The hub database is sync with every member separately. Changes form the hub database will be downloaded to a member database and changes from a member database will be uploaded to the hub database.
集线器数据库分别与每个成员同步。 对中心数据库所做的更改将下载到成员数据库,而对成员数据库所做的更改将上传到中心数据库。
In case of conflicts, there are the Hub wins and Member wins options for resolving of conflicts:
在发生冲突的情况下,有解决冲突的中心赢和会员赢的选项:
- Hub wins option always overwrites changes in a member database Hub wins选项始终会覆盖成员数据库中的更改
- Member wins options always overwrites changes in the hub database. In case when in the sync group there are more members, the last value depends on which member syncs first 成员获胜选项始终会覆盖中心数据库中的更改。 如果在同步组中有更多成员,则最后一个值取决于哪个成员首先同步
要求 (Requirements)
Every table that should be synchronized must contain a primary key column
每个应该同步的表必须包含一个主键列
In case there is a need to change the primary key value, delete that column and then recreate it with the new primary key value
如果需要更改主键值,请删除该列,然后使用新的主键值重新创建它
Snapshot isolation need to be enabled:
需要启用快照隔离 :
ALTER DATABASE Database
SET ALLOW_SNAPSHOT_ISOLATION ON ALTER DATABASE Database
SET READ_COMMITTED_SNAPSHOT ON
Otherwise the following exception may appear when try to sync database:
否则,尝试同步数据库时可能会出现以下异常:
局限性 (Limitations)
- identity column that is not a column with a 标识列不是具有primary key, cannot be used in the tables that should be synchronized 主键的列,不能在应同步的表中使用
- The datetime data type cannot be used for a primary key datetime数据类型不能用于主键
- Maximum tables in one sync group is 500 一个同步组中的最大表数为500
- Maximum columns that one table can have in one sync group is 1000 一张表在一个同步组中最多可以有1000列
- Minimal sync interval is 5 minutes 最小同步间隔为5分钟
- SQL Data Sync doesn’t support Azure Active Directory authentication SQL Data Sync不支持Azure Active Directory身份验证
More about SQL Data Sync requirements and limitations can be found on the Sync data across multiple cloud and on-premises databases with SQL Data Sync page.
有关SQL Data Sync要求和限制的更多信息,请参见“ 使用SQL Data Sync”页面跨多个云和本地数据库同步数据 。
权限 (Permissions)
The SQL Data Sync synchronization operations require the following permissions:
SQL数据同步同步操作需要以下权限:
Create table permissions for creating metadata tables (scope_info_dss, scope_config_dss, schema_dss, and provision_marker_dss) and tracking tables (table name_dss_tracking):
创建表权限以创建元数据表(scope_info_dss,scope_config_dss,schema_dss和Provision_marker_dss)和跟踪表(表name_dss_tracking):

Alter table permissions to create Insert, Update, Delete triggers on tables that need to be synchronized:
更改表权限以在需要同步的表上创建插入,更新,删除触发器:
- Create procedure permissions to create the procedures that SQL Data Sync uses 创建过程权限以创建SQL Data Sync使用的过程
- Select permissions for scope_info_dss, scope_config_dss, schema_dss, and provision_marker_dss tables 选择scope_info_dss,scope_config_dss,schema_dss和Provision_marker_dss表的权限
- Insert Permission s for scope_info_dss, scope_config_dss, schema_dss, and provision_marker_dss tables 为scope_info_dss,scope_config_dss,schema_dss和Provision_marker_dss表插入Permissions
- Select permissions for table that should be synchronized 选择应同步的表的权限
- Select, Insert, Update, and Delete permissions are required for tables that should be updated during synchronization process and for metadata tables 选择,插入,更新和删除权限对于在同步过程中应更新的表和元数据表是必需的
- Executed permissions for the stored procedures that SQL Data Sync uses to read and write to metadata tables and tables that should be synchronized SQL Data Sync用于读取和写入元数据表以及应同步的表的存储过程的执行权限
翻译自: https://www.sqlshack.com/what-is-sql-data-sync/
sql 不同数据库同步数据
sql 不同数据库同步数据_什么是SQL数据同步相关推荐
- sql server数据库备份单个表的结构和数据生成脚本
1.使用场景:sql server数据库备份单个表的结构和数据,在我们要修改正式系统的数据的一天或者多条某些数据时候,要执行update语句操作,安全稳健考虑,最好先做好所修改的表的结构和数据备份! ...
- sql 生成csv数据_创建包含SQL Server数据的动态生成的CSV文件
sql 生成csv数据 介绍 ( Introduction ) A few months back, I presented a paper at SQL Saturday 327 in Johann ...
- 向mysql数据库发送指令_常用的MySQL数据库命令大全
飞信2017V5.6.8860.0 官方正式版 类型:聊天其它大小:69.1M语言:中文 评分:9.6 标签: 立即下载 常用的MySQL命令大全 一.连接MySQL 格式: mysql -h主机地址 ...
- mysql binlog 大数据_后起之秀 | MySQL Binlog增量同步工具go-mysql-transfer实现详解
一. 概述 工作需要研究了下阿里开源的MySQL Binlog增量订阅消费组件canal,其功能强大.运行稳定,但是有些方面不是太符合需求,主要有如下三点: 需要自己编写客户端来消费canal解析到的 ...
- sql 删除数据_从零开始学SQL:是什么、如何安装、基本语法、表格(创建、删除、更新)、数据(插入、删除、更新)...
一.学习知识的黄金圈思维 用黄金圈思维分析自己学习SQL,能增加自己的效率和坚持下去的动力. 二.SQL基础知识 1.数据库概念: database ,按照数据结构来组织.存储和管理数据的仓库. 2. ...
- fn_dblog_如何使用fn_dblog和fn_dump_dblog直接在SQL Server数据库中连续读取事务日志文件数据
fn_dblog 大纲 (Outline) In this article, we'll discuss how to read SQL Server transaction logs. This a ...
- sql 获取数据库字段信息_使用DBATools获取SQL数据库详细信息
sql 获取数据库字段信息 In the series of articles on DBATools, (see TOC at the bottom) we are exploring useful ...
- sql 查询数据库索引重建_不良的数据库索引– SQL查询性能的杀手–建议
sql 查询数据库索引重建 previous article, we explained what clustered and nonclustered indexes were, and showe ...
- php 导出mysql 数据库表结构图_导入和导出数据表的图文介绍(phpMyAdmin的使用教程5)...
导入和导出数据表的图文介绍(phpMyAdmin的使用教程5) 导入和导出数据是互逆的两个操作,导入数据是通过扩展名为.sql的文件导入到数据库中,导出数据是将数据表结构,表记录储存为.sql的文件, ...
最新文章
- sql中去掉换行符和回车符
- DbVisualizer 数据库连接工具:添加数据库驱动方法。dbvis搜索不到驱动文件夹下的驱动解决方法
- 总结 | 如何测试你自己的 RubyGem
- 如何查看S/4HANA指定时间段批量生产订单的状态
- 贝叶斯分类器_Sklearn 中的朴素贝叶斯分类器
- caffe,deeplab,对Interp(差值)层的理解
- docker 安装mysql_安装docker并使用docker安装mysql
- 软件项目需求调研报告模板下载_软件项目需求分析报告模板
- 彻底清理c盘空间,本人亲测有效--WinDirStat
- Please refer to dump files (if any exist) [date].dump, [date]-jvmRun[N].dump and [date].dumpstream.
- 如何读取或转换PCD点云文件
- 中国生物农药市场投资前景及“十四五”规划建议报告2022-2028年
- 数据挖掘知识点整理(期末复习版)
- FileExistsError: [WinError 183] 当文件已存在时,无法创建该文件。附文件重命名代码
- TrustZone 基本信息介绍大全
- 零点城市社交电商 2.1.7.4 独立版 全开源 含前后端VUE文件 全插件
- 《数字图像处理》题库5:计算题 ②
- Python 机器学习实战 —— 监督学习(下)
- OpenStack-T中使用密钥对登录虚拟机实例
- 2022美赛E题(森林的碳封存)——赛题解读解题思路