我花了一年时间研究不确定性估算,写下了这份最全指南
让我从年初的一个flag说起:
我的新年目标:我在2018年期间绘制的每一幅图表都要包含不确定性估算
为什么立下这个flag?因为我在各种大会上听腻了人们争论每个月微件(widget)的数量是上升还是下降,或者微件方法X是否比微件方法Y更有效率。
而且我发现,对于几乎任何图表,量化不确定性都很有用,所以我也开始尝试。
然而我很快发现,我给自己挖了个深坑。几个月后:
现在已经是今年的第4个月,我要告诉你,估算不确定性的水还挺深。
我从未学过统计学,也没有通过机器学习来逆向了解过它。所以我算是半路出家,在慢慢自学统计知识。今年早些时候,我还只了解一些关于Bootstrapping算法(拔靴法)和置信区间的基本知识,但随着时间的推移,我学会了蒙特卡罗方法和逆Hessians矩阵(黑塞矩阵)等全套把戏。
这些方法很有用,我也想把这一年的经营教训分享给大家。
从数据开始
我相信没有具体例子是无法真正学到东西的,所以让我们先制造一些数据。我们将生成一个假的时间系列,其日期范围从2017-07-01至2018-07-31,比如说这个序列是一头大象重量的观测值。
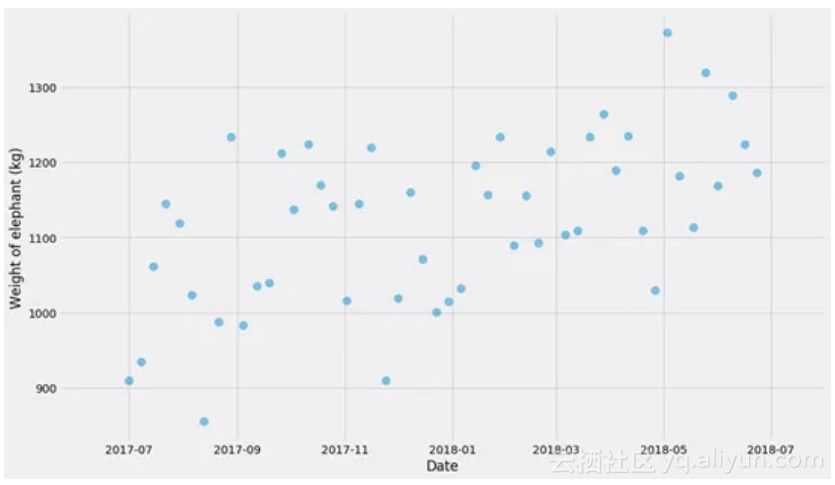
在开始之前,我们需要做图来看看发生了什么!
首先,我们不用任何花哨的模型,我们只是将其分解为几个区间(bucket)并计算每个区间的平均值。不过,让我们先停下来谈谈不确定性。
数据分布与不确定性
之前我一直搞不清“不确定性”的意思,但我认为搞清楚这一点非常重要。我们可以为多种不同的数据估算分布:
1. 数据本身。给定一定的时间范围(t ,t '),在这个时间间隔内大象体重的分布是什么?
2.某些参数的不确定性。如参数k在线性关系y = k t + m里,或者某些估算器的不确定性,就像许多观测值的平均值一样。
3.预测数值的不确定性。因此,如果我们预测日期为t(可能在未来)时大象的重量是y公斤,我们想知道数量y的不确定性。
让我们从最基本的模型开始 - 只需在区间中分解问题。如果我们只是想学习一些关于分布和不确定性估计的基本概念,那么我推荐Seaborn软件包。Seaborn通常在数据帧上运行,因此我们需要进行转换:
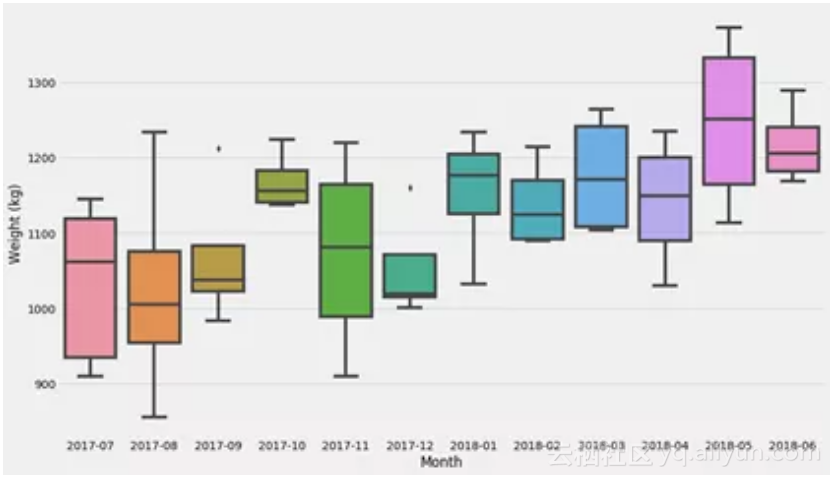
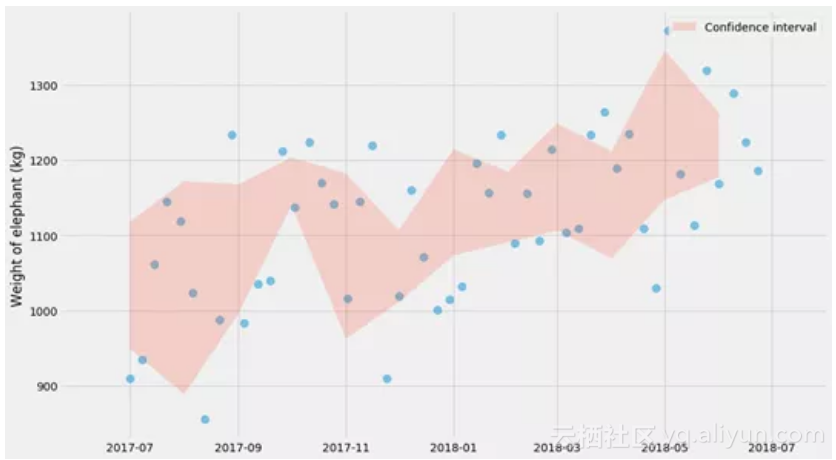
最后的图表显示了数据集的分布。现在让我们试着弄清楚一个非常常见的估算器的不确定性:均值!
计算均值的不确定性 - 正态分布
在一些宽松的假设下(我一会儿回来仔细研究它),我们可以计算均值估计量的置信区间:
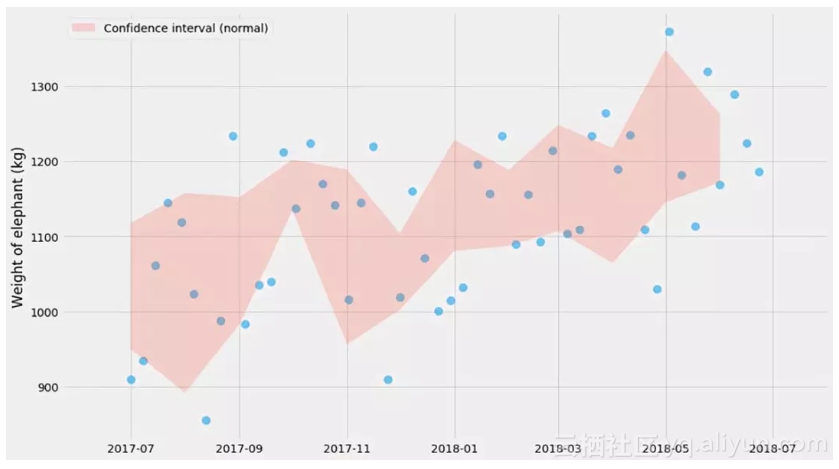
这里¯ X是平均值和σ是标准差,也就是方差的平方根。我不认为记住这个公式非常重要,但我觉得记住置信区间的大小与样本数的平方根成反比这个关系还是有点用的。例如,这在当你运行的A/B测试是有用的-如果你要检测1%的差异,那么你需要大约0.01−2=10,000个样本。(这只是经验值,不要把它用于你的医疗设备软件)。
顺便说一句 – 数值1.96是怎么来的?它与不确定性估计的大小直接相关。± 1.96意味着你将覆盖概率分布的95%左右。
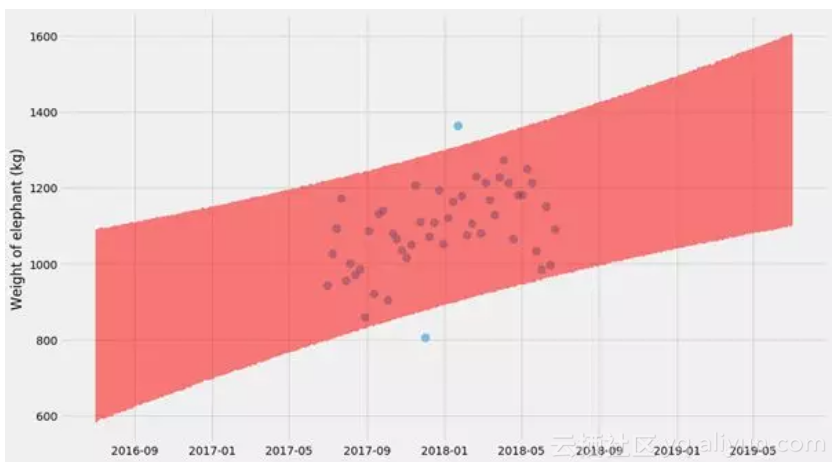
请注意,这是指均值的不确定性,这与数据分布本身不是一回事。这就是为什么你看到在红色阴影区域内的蓝色点数远少于95%。如果我们添加更多的点,红色阴影区域将变得越来越窄,而其中蓝色点数仍将具有差不多的比例。然而,理论上真正的平均值应该有95%时间处于红色阴影区域内。
我之前提到,置信区间的公式仅适用于一些宽松的假设。那些假设是什么?是正态的假设。根据中心极限定理,这对于大量的观测值也是可行的。
所有结果为0或1时的置信区间
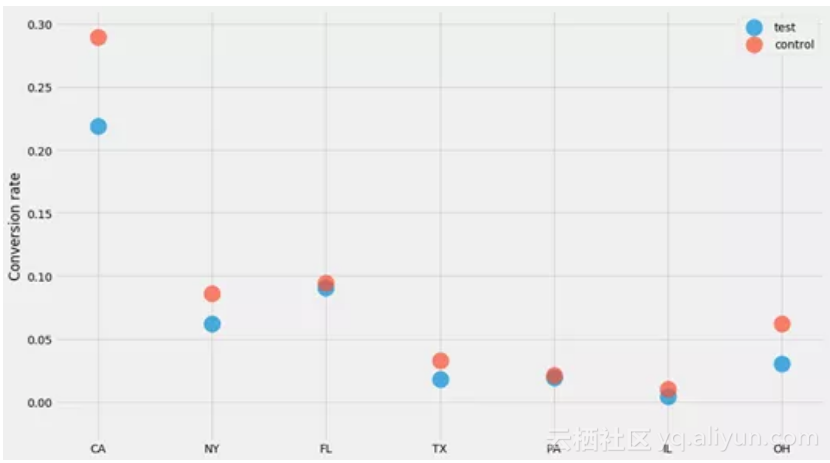
让我们看看我经常使用的一种数据集:转化。为了论证,我们假设正在进行一个有一定影响的A / B测试,并且我们正试图了解各州对转化率的影响。转化结果是0或1。生成此数据集的代码并不是非常重要,因此不要过多关注:
对于每个州和每个“组”(测试和控制),我们生成了n个用户,其中k个已转化。让我们绘制每个州的转化率,看看发生了什么!
由于所有结果都是0或1,并且以相同(未知)概率绘制,我们知道1和0的数量遵循二项分布。这意味着“n个用户中 k个已转化”的情形的置信区间是Beta分布。
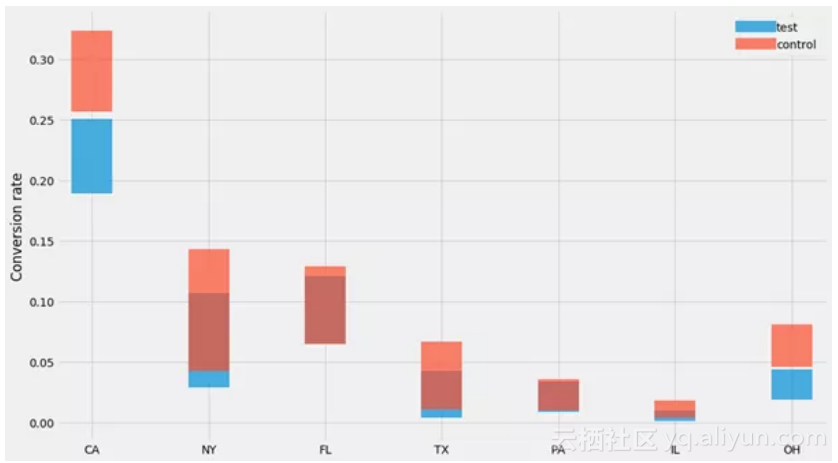
记住置信区间的公式使我获益良多,而且我觉得比起我以前用的(基于法线的)公式,我可能更倾向用它。特别需要记住的是:
代入n和k的值可以算出95%的置信区间。在这个例子里,我们看到如果我们有100个网站访问者,其中3个购买了产品,那么置信区间就是0.6%-7.1%。
让我们用我们的数据集试试:
哎哟不错噢~
Bootstrapping算法(拔靴法)
另一种有用的方法是bootstrapping算法(拔靴法),它允许你在无需记忆任何公式的情况下做同样的统计。这个算法的核心是计算均值,但是是为n次再抽样(bootstrap)计算均值,其中每个bootstrap是我们观测中的随机样本(替换)。对于每次自助抽样,我们计算平均值,然后将在97.5%和2.5%之间的均值作为置信区间:
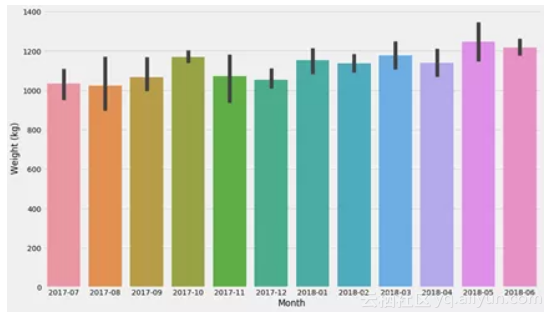
神奇吧,这些图表与之前的图表非常相似!(正如我们本该期待的那样)
Bootstrapping算法很不错,因为它可以让你回避了任何关于生成数据的概率分布的问题。虽然它可能有点慢,但它基本上是即插即用的,并且几乎适用于所有问题。
不过请注意bootstrapping也存在不可用的情形。我的理解是,当样本数量趋于无穷大时,bootstrapping会收敛到正确的估计值。但如果你使用的是小样本集,你会得到不靠谱的结果。我通常不会相信对任何少于50个样本的问题的bootstrapping再抽样,所以你最好也不要这样做。
边注,Seaborn的 barplot实际上使用bootstrapping来绘制置信区间:
seaborn.barplot(data=d, x='Month', y='Weight (kg)')
同样,Seaborn非常适合进行探索性分析,其中一些图表可以用于基本的统计。
回归
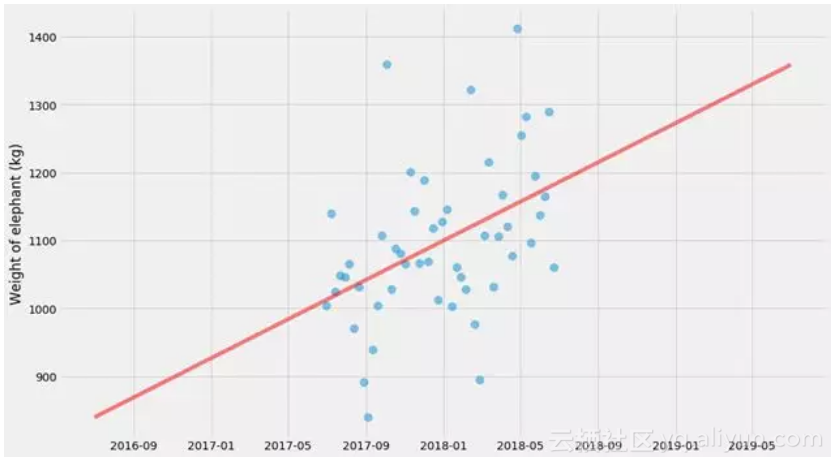
让我们提高一个档次。我们将在这一群点上做一个线形回归。
我将以我认为最普遍的方式来做这件事。我们将定义一个模型(在这种情况下是一条直线),一个损失函数(与该直线的平方偏差),然后使用通用求解器(scipy.optimize.minimize)对其进行优化。
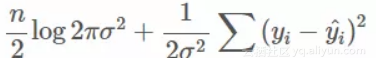
具有不确定性的线性回归,使用最大似然方法
我们只拟合k和m,但这里没有不确定性估计。有几件事我们可以估计不确定性,但让我们从预测值的不确定性开始。
我们可以通过在拟合k和m的同时在直线周围拟合正态分布来做到这一点。我将使用最大似然方法来做到这一点。如果你不熟悉这种方法,不要害怕!如果统计学存在方法能够很容易实现(它是基本概率理论)并且很有用,那就是这种方法。
实际上,最小化平方损失(我们刚刚在前面的片段中做过)实际上是最大可能性的特殊情况!最小化平方损失与最大化所有数据概率的对数是一回事。这通常称为“对数似然”。
所以我们已经有一个表达式来减少平方损失。如果我们使方差为未知变量σ2,我们可以同时拟合它!我们现在要尽量减少的数量变成了
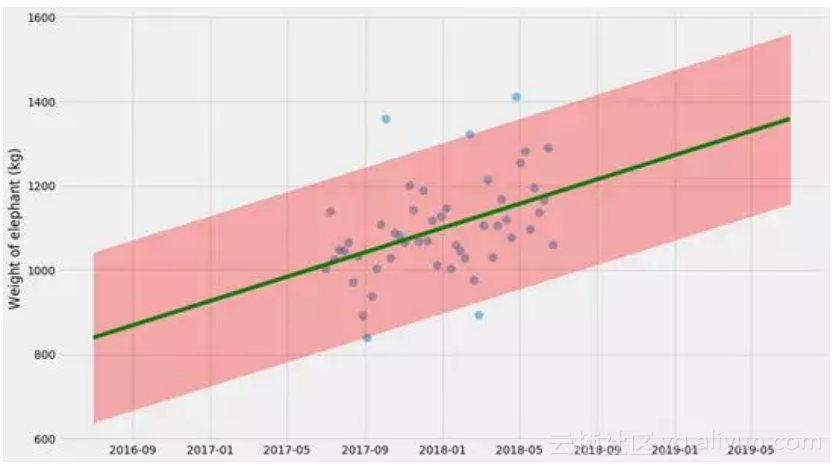
在这里 ^yi=kxi+m是我们模型的预测值。让我们尝试拟合它!
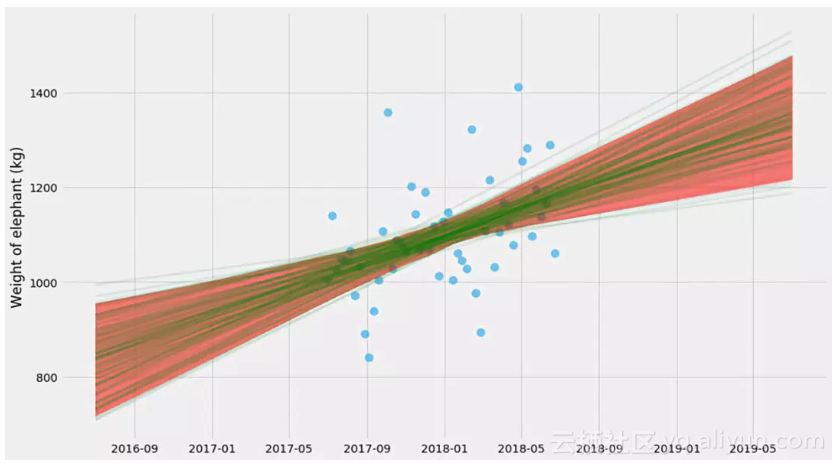
这里的不确定性估计实际上不是100%,因为它没有考虑k,m和σ本身的不确定性。这是一个不错的近似,但要做到正确,我们需要同时做这些事情。所以我们这样做吧。
再次启用Bootstrapping!
所以让我们把它提升到一个新的水平,并尝试估计k和m和σ的不确定性估计! 我认为这将显示bootstrapping基本上是如何切割 - 你可以将它插入几乎任何东西,以估计不确定性。
对于每个bootstrap估计,我将绘制一条线。我们也可以采用所有这些线并计算置信区间:
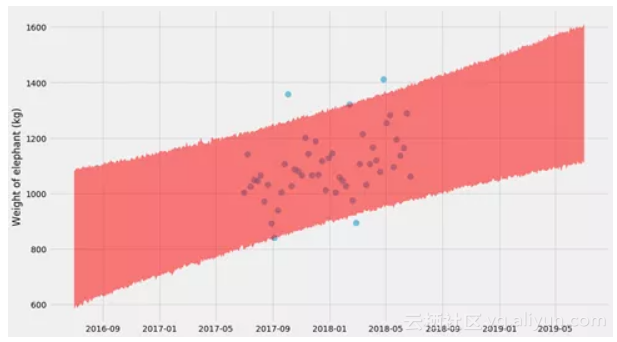
哇,这里发生了什么?这种不确定性与之前的情节非常不同。这看起来很混乱,直到你意识到他们展示了两个非常不同的东西:
● 第一个图找到k和m的一个解,并显示预测的不确定性。所以,如果你被问到下个月大象体重的范围是什么,你可以从图表中得到它。
● 第二个图找到了k和m的许多解,并显示了kx + m的不确定性。因此,这回答了一个不同的问题 - 大象体重随时间变化的趋势是什么,趋势的不确定性是什么?
事实证明,我们可以将这两种方法结合起来,并通过拟合绘制bootstrapping样本并同时拟合k,m和σ使其更加复杂。然后,对于每个估算,我们可以预测新值y。我们这样做:
哎呦,又不错!它现在变得很像回事了 - 如果仔细观察,你会看到一个双曲线形状!
这里的技巧是,对于(k,m,σ)的每个bootstrap估计,我们还需要绘制随机预测。正如您在代码中看到的,我们实际上是将随机正态变量添加到y的预测值。这也是为什么这个形状最终变成一个大波浪形的原因。
不幸的是,bootstrapping对于这个问题来说相当缓慢 - 对于每个bootstrap,我们需要拟合一个模型。让我们看看另一个选项:
马尔可夫链蒙特卡罗方法
现在它会变得有点狂野了~~
我将切换到一些贝叶斯方法,我们通过绘制样本来估计k,m和σ。它类似于bootstrapping,但MCMC有更好的理论基础(我们使用贝叶斯规则从“后验分布”中抽样),并且它通常要快几个数量级。
为此,我们将使用一个名为emcee的库,我发现它很好用。 它所需要的只是一个Log—likelihood函数,我们之前已经定义过了! 我们只需要用它的负数。
让我们绘制k和m的采样值!
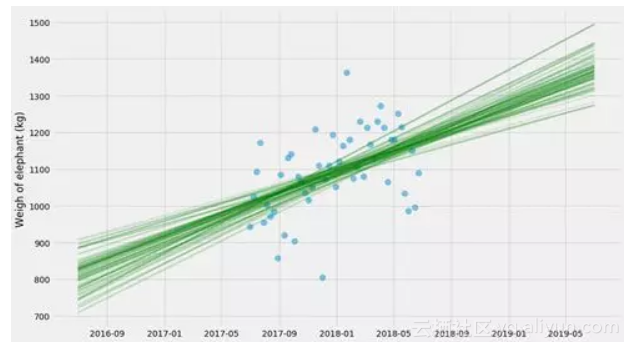
这些方法还有一些内容 - 采样有点挑剔,需要一些人工参与才能正常工作。我不想在这里深入解释所有细节,而且我自己就是一个门外汉。但它通常比booststrapping快几个数量级,并且它还可以更好地处理数据更少的情况。
我们最终得到了k,m,σ后验分布的样本。我们可以看看这些未知数的概率分布:
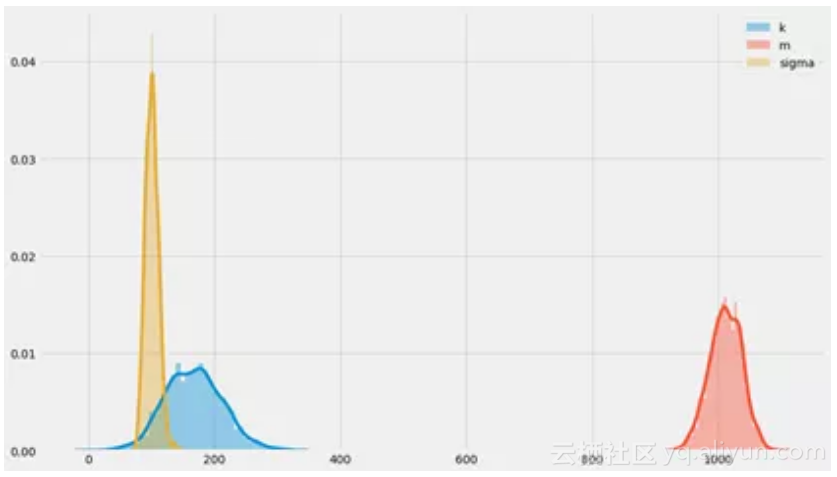
你可以看到围绕k = 200,m = 1000,σ= 100时的分布中心,我们原本也是如此构建它们的!这看起来挺令人放心的~
最后,我们可以使用与boostraps相同的方法绘制预测的完全不确定性:
这些贝叶斯方法并没有在这里结束。特别是有几个库可以解决这些问题。事实证明,如果您以更结构化的方式表达问题(而不仅仅是负对数似然函数),您可以将采样比例调整为大问题(如数千个未知参数)。对于Python来说,有PyMC3和PyStan,以及稍微更小众一点的Edward和Pyro。
结语
似乎我把你们带进了一个深坑 - 但这些方法其实可以走得更远。事实上,强迫自己估计我做的任何事情的不确定性是一个很好的体验,可以逼着自己学习很多的统计知识。
根据数据做出决策很难!但如果我们对量化不确定性更加严格,我们可能会做出更好的决策。现在要做到这一点并不容易,但我真的希望我们能够使用更便捷的工具,从而看到这些方法的普及。
我花了一年时间研究不确定性估算,写下了这份最全指南相关推荐
- Siteground和Bluehost对比,我花了7天时间研究出了结果
Siteground主机和Bluehost主机,哪个更好?哪个更适合外贸建站?读完这篇,你就有答案! 说实话......我花了太多的时间来做决定.在决定买什么相机.加入什么健身房.甚至选择什么衣服时, ...
- 我花了一年时间来学机器学习
我花了一年时间来学机器学习 为了把大家从越来越多的技术水文中拯救出来,"大公司技术博客"将良心推送国内外大公司的优质干货文,如Facebook, Google, Medium, G ...
- 我花了18年时间才能和你坐在一起喝咖啡
我的白领朋友们,如果我是一个初中没毕业就来沪打工的民工,你会和我坐在starbucks一起喝咖啡吗?不会,肯定不会. 比较我们的成长历程,你会发现为了一些在你看来垂手可得的东西,我却需要付出巨大的努力 ...
- 花了六年时间,我才和你坐在一起画拓扑
我亲爱的同事们,客户们,如果我是一个刚毕业的小白,又或是一个没有经验的工程师,你们会让我来规划一个集团的网络吗? 不会,肯定不会. 我花了六年时间,现在终于有信心规划一个有上万人企业的网络,终于有能力 ...
- 我们花了八年时间,证明不内卷也可以活得更好 | 厂长来了
NewBranding 牛/白/丁 欢迎来到「牛白丁·厂长来了 」Vol.6,在这里,你将听到来自华创资本和我们的朋友们,一起聊那些跟创业.投资.科技.消费.互联网......相关与不相关的人和事,回 ...
- 【无浪】花了两周时间纯手打打出来的Java记事本
最近的大作业是记事本,两周的大块时间和碎片时间都花在这上面了,数据结构已经落下了,要恶补了. 注意这个记事本在没有联网的时候会在关于记事本类中的一个JLabel标签里停下,该标签使用了HTML连向一张 ...
- 如何花更少的时间学习更多的知识
花时间学习不见得就是真正的学习. 因为你的学习方法一开始就是错的话,那么花再多的时间在学习上也是无济于事. 所以你得看看这篇文章,如何花少量的时间却仍然学习到更多的知识.上帝给了我们每个人同样的时间, ...
- 其实跑步花不了多少时间
其实走路也花不了多少时间 其实喝水也花不了多少时间 但是 这个东西对于你的健康的意义 十分的重要 要增强时间管理的意识和能力
- 最感叹的莫过于一见如故,最悲伤的莫过于再见陌路。最深的孤独,是你明知道自己的渴望,却得对它装聋作哑。最美的你不是生如夏花,而是在时间的长河里,波澜不惊。...
最感叹的莫过于一见如故,最悲伤的莫过于再见陌路.最深的孤独,是你明知道自己的渴望,却得对它装聋作哑.最美的你不是生如夏花,而是在时间的长河里,波澜不惊. 转载于:https://www.cnblogs ...
最新文章
- 第22条:理解NSCopying 协议
- RPM打包原理、示例、详解及备查
- Atomikos 中文说明文档【转】
- 文件html怎么另存为wps,WPS文字中另存为功能详解(wps文字怎么保存到指定文件夹)...
- bootstrap算法_决策树算法之随机森林
- 僵尸进程和孤儿进程 转载
- 信号与系统 chapter10 系统的初值问题与系数匹配法
- 美团互助关停:聚焦主业发展 将全额返还会员分摊
- RMQ(求区间最值问题)
- python下使用pymongo操作mongodb
- opencv识别圆的代码(转)
- 面向对象 之重写重载
- SQL SERVER 2008 “阻止保存要求重新创建表的更改”
- 看完浪曦相关视频后的感受
- 支付宝和微信支付用户付款码条码规则
- 犹太民族与基督的真相!
- 小班安全使用计算机教案,幼儿园小班安全教案(精选5篇)
- Citrix PVS架构和工作原理
- contiki学习笔记(六)contiki程序加载器和多线程库
- HTML+JavaScript简单搜索功能实现
热门文章
- 如何避免在Block里用self造成循环引用
- 使用PLupload在同一页面中进行多个不同类型上传解决方案和一次多文件上传的注意事项...
- SQL高级查询——50句查询(含答案) ---参考别人的,感觉很好就记录下来留着自己看。...
- Linq 中的 left join
- Smart ORM v0.3发布(完全面向对象的轻量级ORM工具)
- 从你月入2000元开始规划你的人生...
- 洛谷 P1306 斐波那契公约数
- python运算学习之Numpy ------ 数组操作:连接数组、拆分数组 、广播机制、结构化数组、文件贮存与读写、np.where、数组去重...
- html5录音支持pc和Android、ios部分浏览器,微信也是支持的,JavaScript getUserMedia
- 如何观察JS的事件队列的执行划分