Python日记 -- 百度OCR翻译
原文:https://c12th.cn/index.php/archives/16/
前言
最近写了个 丐版 的 百度 OCR 翻译 ,其实网络上也有很多类似的源码。
该教程为 简化版 ,详细查看 技术文档 , 支持 python 版本 2.7.+ 和 3.+ 。
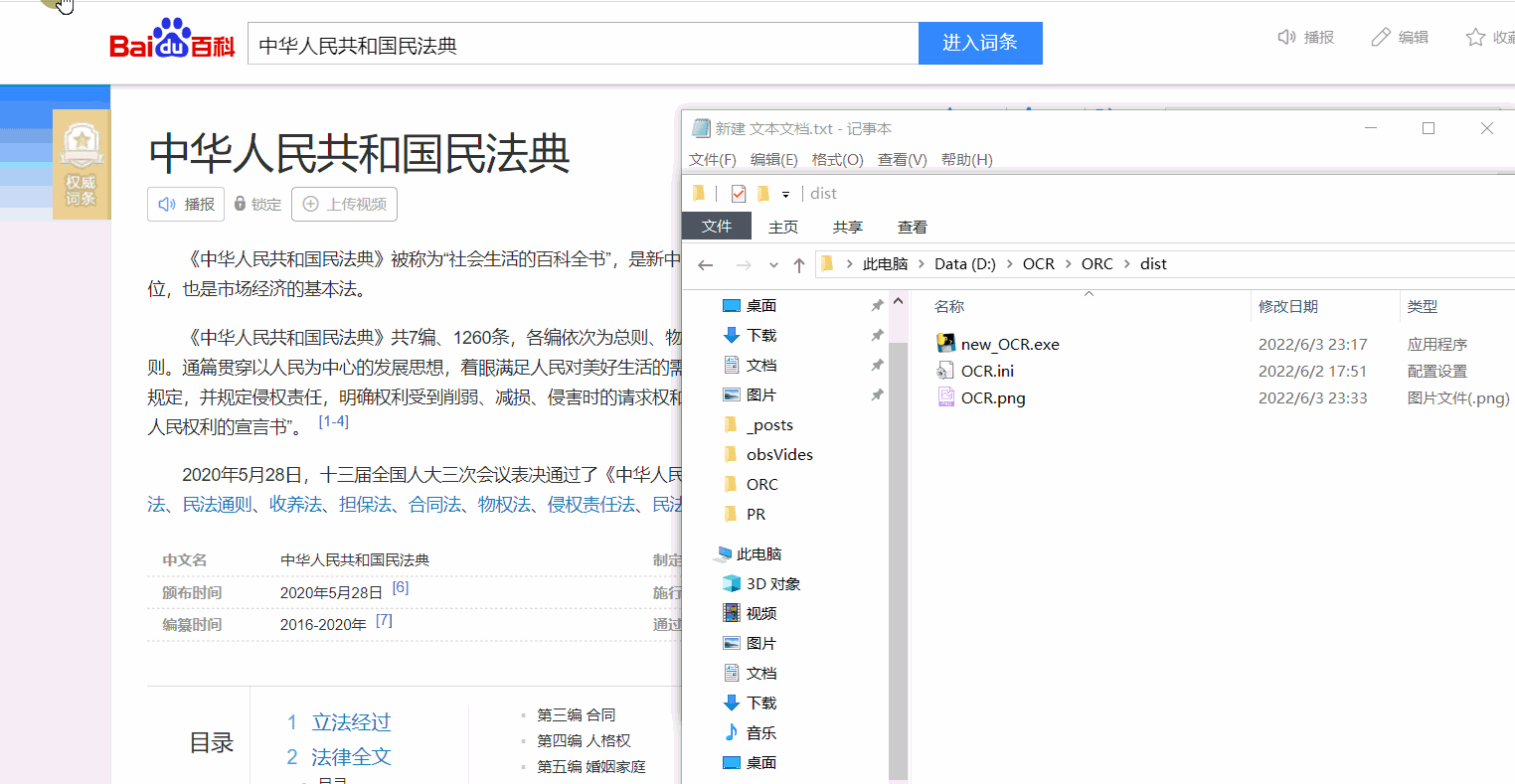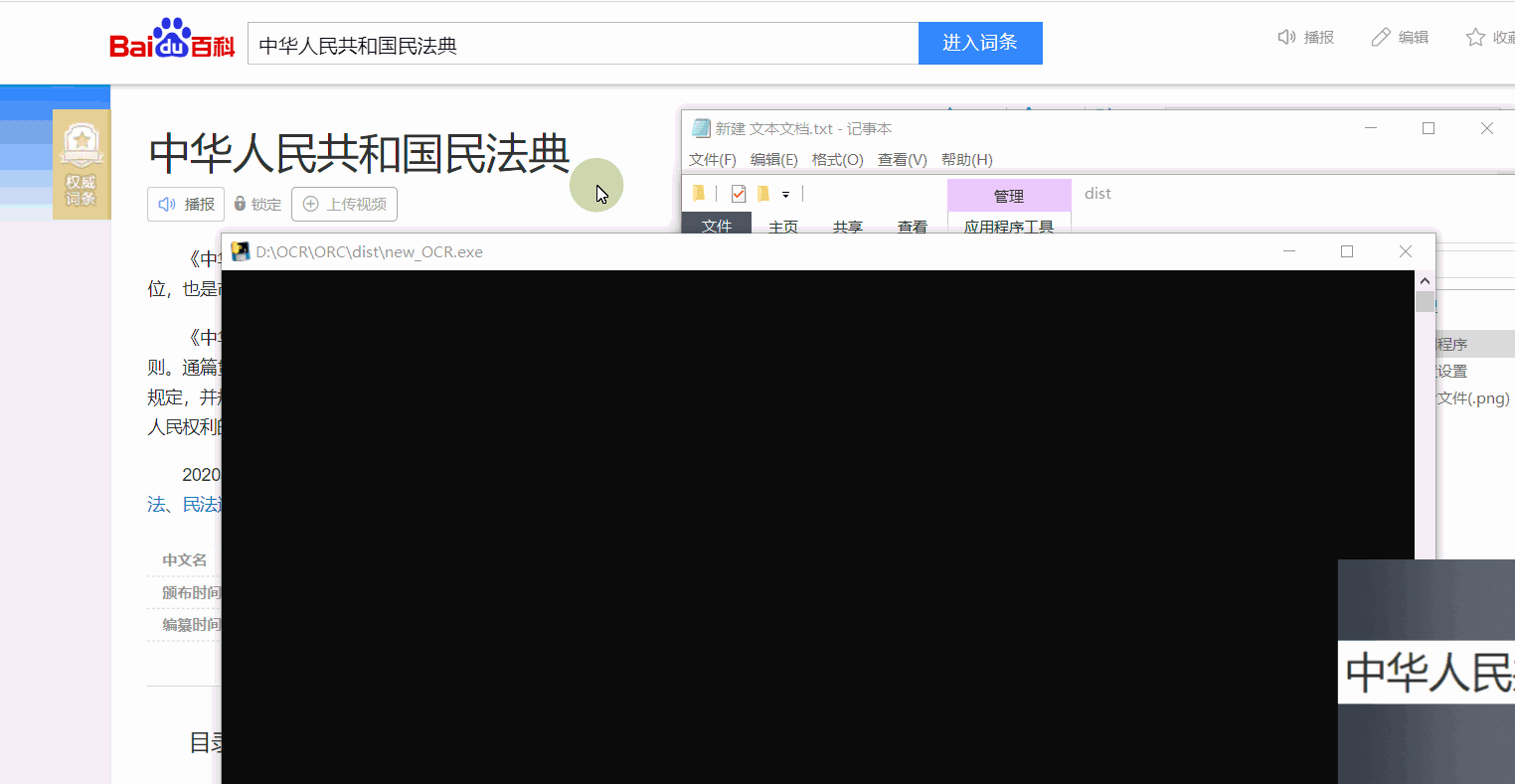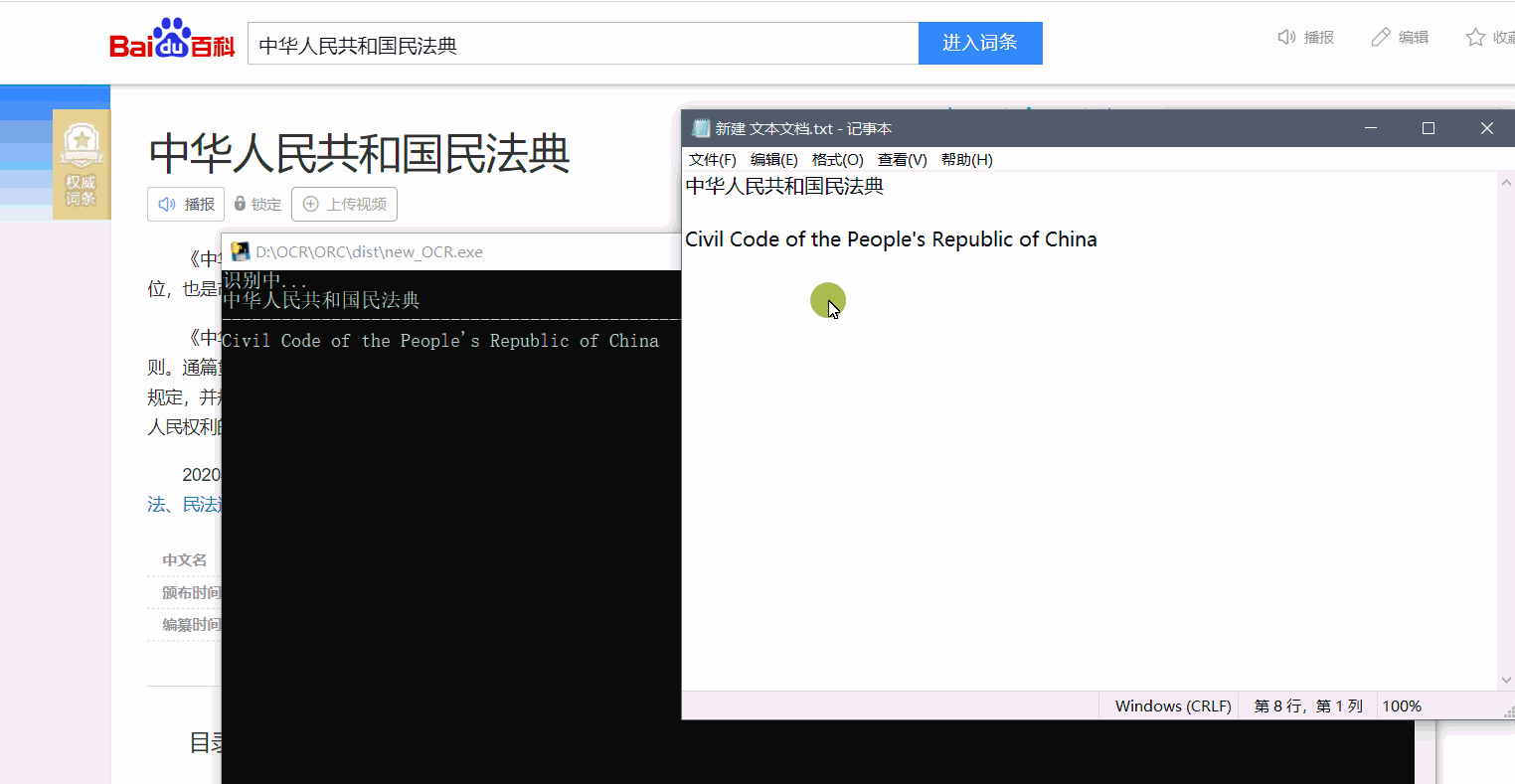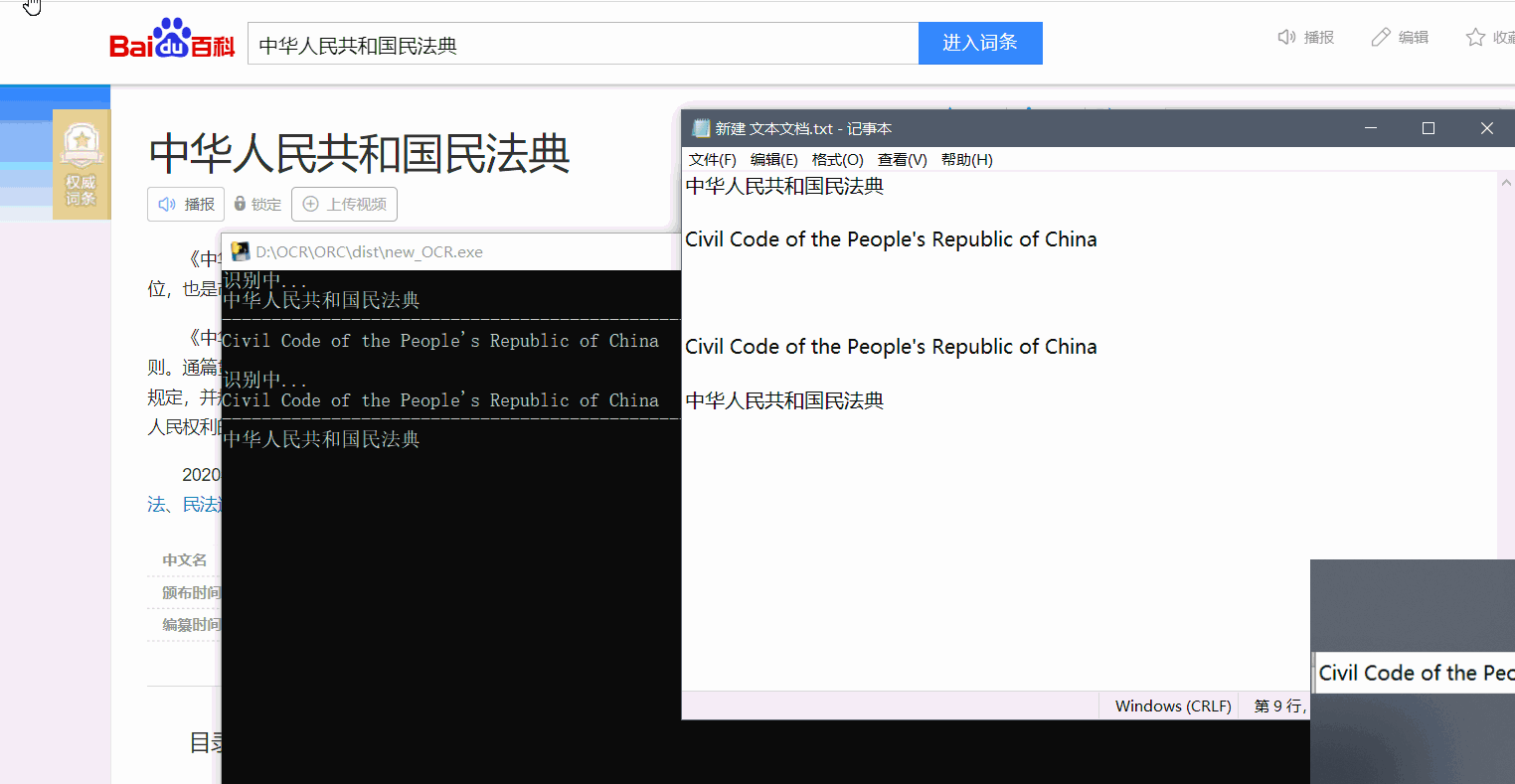
效果展示
百度OCR
准备工作
登录 / 注册 百度账号
创建 通用场景OCR ,应用归属 选择
个人,应用名称 和 应用描述 自定义填完以上信息后,点击
立即创建(注意要实名认证)此时,应用列表 会出现 刚创建好的应用 ,分别把
AppID、API Key和Secret Key记录好 等下用
核心代码
- 当前版本为 python 3.8.1 (PIL 在 python3 时,第三方库应安装 pillow)
# 截图import keyboardimport timefrom PIL import ImageGrabkeyboard.wait(hotkey='ctrl+c') # 触发按键time.sleep(0.01) # 延迟# 保存图片image = ImageGrab.grabclipboard()image.save('OCR.png') # 图片命名为'OCR.png'
- 安装 OCR Python SDK
pip install baidu-aip
- 配置 OCR
- 配置AipOcr ,把在 准备工作 获取的
AppID、API Key和Secret Key对应填入
# 配置AipOcrfrom aip import AipOcrAPP_ID = '你的 App ID'API_KEY = '你的 Api Key'SECRET_KEY = '你的 Secret Key'client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
- 接口说明
def get_file_content(filePath):with open('OCR.png', "rb") as fp:return fp.read()image = get_file_content('OCR.png')# 调用通用文字识别(标准版)res_image = client.basicGeneral(image)print(res_image)
- 删减 + 筛选数据
with open('OCR.png', "rb") as fp:image = fp.read()# 调用通用文字识别(标准版)res_image = client.basicGeneral(image)# print(res_image)# 筛选数据res = res_image['words_result']for i in res:print(i['words'])
有道翻译
- 用到了 爬虫 , 网上有教程,不细说
import requests
import json
import time
import random
import hashlib# 网址
url = 'https://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'# 反爬
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36','Cookie': 'OUTFOX_SEARCH_USER_ID=1870252624@10.110.96.157; OUTFOX_SEARCH_USER_ID_NCOO=1338974472.751384; ___rl__test__cookies=1654489795853','Referer': 'https://fanyi.youdao.com/'
}# 时间戳
r = str(int(time.time()*1000))
# print(r)# 随机数
random_num = random.randint(0,9)
i = r + str(random_num)
# print(i)def data_new(e):# md5str_sign = "fanyideskweb" + e + i + "Ygy_4c=r#e#4EX^NUGUc5"md5 = hashlib.md5()md5.update(str_sign.encode())sign = md5.hexdigest()# print(sign)data_old = {'i': e,'from': 'AUTO','to': 'AUTO','smartresult': 'dict','client': 'fanyideskweb','salt': i,'sign': sign,'lts': r,'bv': 'dbf26599b4389c828cae8b896c9b0708','doctype': 'json','version': '2.1','keyfrom': 'fanyi.web','action': 'FY_BY_REALTlME'}return data_olda = input('请输入需要翻译的内容:\n')
data = data_new(a)# 请求
result = requests.post(url,headers=header,data=data).text
# print(result)# 数据筛选
dict_res = json.loads(result)
print(dict_res['translateResult'][0][0]['tgt'])
补充
拓展
- 增加 复制 和 弹窗 功能 加了些花里胡哨的东西
import pyperclipimport tkinter as tk# copypyperclip.copy(a + '\n' + b)time.sleep(0.02)# 弹窗root = tk.Tk()root.title("info")tk.Label(root, text="已复制", ).pack() # 弹窗显示root.after(1000, lambda: root.destroy()) # 停留1sroot.mainloop()
打包前 完整代码
- 演示版本为 python 3.8.1 , 如出现报错请自行解决
# 工程:test
# 创建时间:2022/6/2 11:41
# encoding:utf-8import keyboard
import time
import requests
import random
import hashlib
import json
import configparser
import pyperclip
import tkinter as tk
from PIL import ImageGrab
from aip import AipOcr# 读取ini文件
aip = 'OCR.ini'
conf = configparser.ConfigParser()
conf.read(aip)# 配置AipOcr
APP_ID = conf.get('aip', 'APP_ID') # 你的 App ID
API_KEY = conf.get('aip', 'API_KEY') # 你的 Api Key
SECRET_KEY = conf.get('aip', 'SECRET_KEY') # 你的 Secret Keyclient = AipOcr(APP_ID, API_KEY, SECRET_KEY)while True:# --------------- 截图识别 --------------# 截图keyboard.wait(hotkey='ctrl+c') # 触发按键time.sleep(0.01) # 延迟# 保存图片image = ImageGrab.grabclipboard()image.save('OCR.png') # 图片命名为'OCR.png'print('识别中...')with open('OCR.png', "rb") as fp:image = fp.read()# 调用通用文字识别(标准版)res_image = client.basicGeneral(image)# print(res_image)# 筛选数据all_text = ''res = res_image['words_result']for i in res:all_text += i['words'] + '\n'a = all_textprint(a + '-' * 70)# --------------- 有道翻译 --------------# 网址url = 'https://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'# 反爬header = {'User-Agent': conf.get('config', 'User-Agent'),'Cookie': conf.get('config', 'Cookie'),'Referer': 'https://fanyi.youdao.com/'}# 时间戳r = str(int(time.time() * 1000))# print(r)# 随机数random_num = random.randint(0, 9)i = r + str(random_num)# print(i)def data_new(e):# md5str_sign = "fanyideskweb" + e + i + "Ygy_4c=r#e#4EX^NUGUc5"md5 = hashlib.md5()md5.update(str_sign.encode())sign = md5.hexdigest()# print(sign)data_old = {'i': e,'from': 'AUTO','to': 'AUTO','smartresult': 'dict','client': 'fanyideskweb','salt': i,'sign': sign,'lts': r,'bv': conf.get('config', 'bv'),'doctype': 'json','version': '2.1','keyfrom': 'fanyi.web','action': 'FY_BY_REALTlME'}return data_olddata = data_new(a)# 请求result = requests.post(url, headers=header, data=data).text# print(result)# 数据筛选dict_res = json.loads(result)b = dict_res['translateResult'][0][0]['tgt']print(b + '\n')# copypyperclip.copy(a + '\n' + b)time.sleep(0.02)# 弹窗root = tk.Tk()root.title("info")tk.Label(root, text="已复制", ).pack() # 弹窗显示root.after(1000, lambda: root.destroy()) # 停留1sroot.mainloop()- 创建
OCR.ini文件,复制以下内容 , 把在 准备工作 获取的AppID、API Key和Secret Key对应填入
[aip]
APP_ID =
API_KEY =
SECRET_KEY = [config]
User-Agent = Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36Cookie = OUTFOX_SEARCH_USER_ID=1870252624@10.110.96.157; OUTFOX_SEARCH_USER_ID_NCOO=1338974472.751384; ___rl__test__cookies=1654489795853bv = dbf26599b4389c828cae8b896c9b0708
- 最后自行打包 (不打包在pycharm里也能用)
pyinstaller -F 文件名.py# pyinstaller -F 文件名.pyw
打包后 使用教程
代码已打包上传到 github 和 gitee 上
- 打开
new_OCR\dist\OCR.ini文件,把在 准备工作 获取的AppID、API Key和Secret Key对应填入 , 运行exe文件 即可
[aip]
APP_ID =
API_KEY =
SECRET_KEY =
- 如出现闪退 / 想换成自己的 , 请 / 可 更换以下内容
[config]
User-Agent = Cookie = bv =
- 方法如下
F12 打开 开发者工具 ,选择 Network , 然后选择 XHR
在 翻译框 输入任意 文字 ,页面 会出现 translate_ (如有多个选最新)
点击 translate_ ,在 Headers 页面可以找到
User-Agent和Cookie,在 Payload 页面可以找到bv(火狐浏览器的bv在请求页面)把找到的内容 替换 ini 文件内容 ,重新运行 即可
如 不清楚文字描述 可按 如图 1 所示 步骤 即可

图 1
最后
代码已在 github 和 gitee 上开源
这个百度 OCR 只能翻译第一行的内容,多行无法翻译
个人版的调用次数已经够用了,不建议多对一,建议一对一
Python日记 -- 百度OCR翻译相关推荐
- Python调用百度通用翻译api
Python调用百度通用翻译api 首先 首先 首先需要先去百度翻译api官网注册成为开发者,然后申领一下通用翻译的appid和密钥. 附上代码,默认为源语言自动识别,效果感觉不是太好,目标语言默认为 ...
- Python基于百度OCR的疫情防控截图自动分析检查
通过腾讯文档收集人员信息,下载后,使用Python基于百度OCR对填报的疫情防控截图信息进行识别和统计分析,5分钟搞定每天人工1小时的检查工作量,提高效率,还提高准确率. 前言 疫情期间,各地.各单位 ...
- python调用百度OCR识别证件+操作excel表格
python调用百度OCR识别证件+操作excel表格 如果要操作文件的话最好让程序知道文件存不存在,因为做了GUI界面,报错不会直接弹出来,异常捕获就用得比较频繁 因为面向对象没学好,GUI是用工具 ...
- Python调用百度OCR实现图片文字识别
百度AI提供了一天50000次的免费文字识别额度,可以愉快的免费使用!下面直接上方法: 首先在百度AI创建一个应用,按照下图创建即可,创建后会获得如下: 创建后会获得如下信息: APP_ID = '* ...
- 用Python编写百度ocr图像识别程序
涉及的知识点:Python.调用百度API.PyQt5 运行环境:Mac+Python3.7+PyQt5 程序截图: 实现步骤: 第一步:获得自己的百度OCR的AK和SK 1.利用百度 AI 开发平台 ...
- 有这个OCR程序,不用再买VIP了,Python 调用百度OCR API
最近学习,很多东西都是视频,截图后,又想做成文档保存起来. 刚开始不多,打一下字就很快解决了. 随着时间的推移,现在越来越多的图了,管理起来确实不方便,打字有时也不能很快的解决. 所以就弄了个OCR. ...
- Python使用百度OCR接口进行验证码图像识别
上次从pytesseract软件及其python库入门了OCR的图像识别, 包括图像的读取.格式转换和图像处理,也进行了验证码的识别实验,包括验证码获取.登录验证以及不同图像处理的识别效果测试,具体内 ...
- python使用百度OCR图片验证码
在爬取网站的时候都遇到过验证码,有什么方法可以让程序帮我们识别验证码呢?其实网上已有很多打码平台,但是这些都是需要money,像阿里云平台的,以前大概是每分钱1次,现在价格有点小贵,但对于仅仅爬取点数 ...
- python使用百度OCR接口识别图片文字
调用百度的OCR接口进行识别 一.百度AI开放平台地址,进入创建 通用文字识别 应用(前提要先注册百度智能云账号) https://ai.baidu.com/tech/ocr?track=cp:ain ...
- Python 调用百度通用翻译接口
缘起 以为该类型的代码在CSDN上比比皆是,最后还是自己按照百度开发文档自己写了一个 库导入 import httpx from random import randint import hashli ...
最新文章
- ExtJS中xtype 概览
- 浅谈博客园的初使用体验
- 聊天机器人突然火了,能解决那方面的需求吗?
- Boost:基于Boost的阻塞TCP回显服务器
- [Vue CLI 3] 源码系列之useTaobaoRegistry
- 为什么python打开pygame秒关闭后在运行_当我运行Python程序时,pygame窗口打开片刻,然后退出 - python...
- CV 加持的工业检测,从算法选型到模型部署
- 睡前小故事之MySQL起源
- UE4 异步资源加载
- 用FlexGrid做开发,轻松处理百万级表格数据
- day17 10.jdbc的crud操作
- vue2.x 父组件监听子组件事件并传回信息
- ue4 设置运行分辨率
- 160个CrackMe001
- docker swarm 部署 sentry9.1.2
- Python导包的几种方法,自定义包的生成以及导入详解
- 解决Chrome浏览器登录web系统一直报“验证码错误问题“
- 综述 | 一文读懂自然语言处理NLP(附学习资料)
- JavaEE 微信境外支付
- 添加https证书信任