分布式计算 MapReduce与yarn工作机制
一、第一代hadoop组成与结构
第一代Hadoop,由分布式存储系统HDFS和分布式计算框架MapReduce组成,其中,HDFS由一个NameNode和多个DataNode组成,MapReduce由一个JobTracker和多个TaskTracker组成,对应Hadoop版本为Hadoop 1.x和0.21.X,0.22.x。
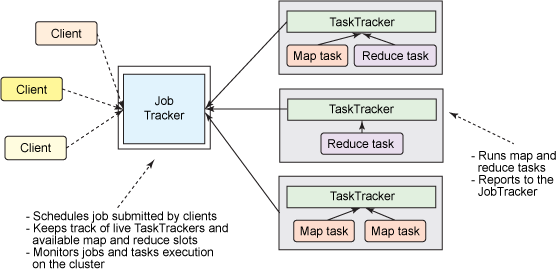
1、MapReduce角色分配
Client :作业提交发起者。
JobTracker: 初始化作业,分配作业,与TaskTracker通信,协调整个作业。
TaskTracker:保持JobTracker通信,在分配的数据片段上执行MapReduce任务。
2、MapReduce执行流程
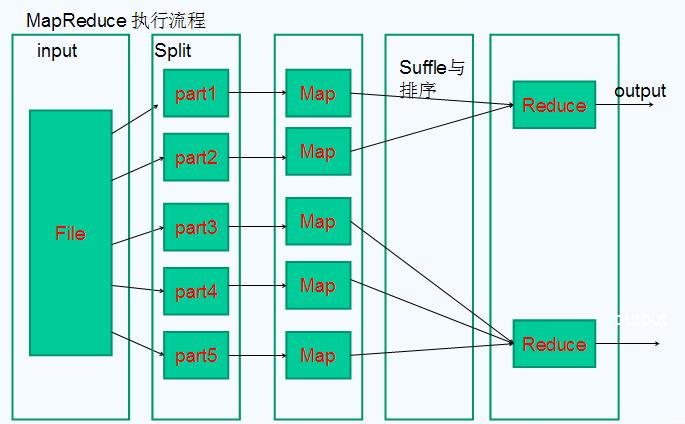
(1)提交作业
在作业提交之前,需要对作业进行配置
程序代码,主要是自己书写的MapReduce程序。
输入输出路径
其他配置,如输出压缩等。
配置完成后,通过JobClinet来提交
(2)作业的初始化
客户端提交完成后,JobTracker会将作业加入队列,然后进行调度,默认的调度方法是FIFO调试方式。
(3)任务的分配
TaskTracker和JobTracker之间的通信与任务的分配是通过心跳机制完成的。
TaskTracker会主动向JobTracker询问是否有作业要做,如果自己可以做,那么就会申请到作业任务,这个任务可以使Map也可能是Reduce任务。
(4)任务的执行
申请到任务后,TaskTracker会做如下事情:
拷贝代码到本地
拷贝任务的信息到本地
启动JVM运行任务
(5)状态与任务的更新
任务在运行过程中,首先会将自己的状态汇报给TaskTracker,然后由TaskTracker汇总告之JobTracker。
任务进度是通过计数器来实现的。
(6)作业的完成
JobTracker是在接受到最后一个任务运行完成后,才会将任务标志为成功。
此时会做删除中间结果等善后处理工作。
二、第二代hadoop组成与结构
第二代Hadoop,为克服Hadoop 1.0中HDFS和MapReduce存在的各种问题而提出的。针对Hadoop 1.0中的单NameNode制约HDFS的扩展性问题,提出了HDFS Federation,它让多个NameNode分管不同的目录进而实现访问隔离和横向扩展;针对Hadoop 1.0中的MapReduce在扩展性和多框架支持方面的不足,提出了全新的资源管理框架YARN(Yet Another Resource Negotiator),它将JobTracker中的资源管理和作业控制功能分开,分别由组件ResourceManager和ApplicationMaster实现,其中,ResourceManager负责所有应用程序的资源分配,而ApplicationMaster仅负责管理一个应用程序。对应Hadoop版本为Hadoop 0.23.x和2.x。
1、 yarn运行架构
YARN 是下一代Hadoop计算平台,如下所示:

在 YARN 架构中,一个全局ResourceManager 以主要后台进程的形式运行,它通常在一台独立机器上运行,在各种竞争的应用程序之间仲裁可用的集群资源。
ResourceManager会追踪集群中有多少可用的活动节点和资源,协调用户提交的哪些应用程序应该在何时获取这些资源。ResourceManager是惟一拥有此信息的进程,所以它可通过某种共享的、安全的、多租户的方式制定分配(或者调度)决策(例如,依据应用程序优先级、队列容量、ACLs、数据位置等)。
在用户提交一个应用程序时,一个称为ApplicationMaster的轻量型进程实例会启动来协调应用程序内的所有任务的执行。这包括监视任务,重新启动失败的任务,推测性地运行缓慢的任务,以及计算应用程序计数器值的总和。这些职责以前是分配给单个 JobTracker来完成的。ApplicationMaster和属于它的应用程序的任务,在受NodeManager控制的资源容器中运行。
NodeManager是TaskTracker的一种更加普通和高效的版本。没有固定数量的 map 和 reduce slots,NodeManager 拥有许多动态创建的资源容器。容器的大小取决于它所包含的资源量,比如内存、CPU、磁盘和网络 IO。目前,仅支持内存和 CPU (YARN-3)。一个节点上的容器数量,由节点资源总量(比如总CPU数和总内存)共同决定。
需要说明的是:ApplicationMaster可在容器内运行任何类型的任务。例如,MapReduce ApplicationMaster请求一个容器来启动map或reduce 任务,而 Giraph ApplicationMaster请求一个容器来运行Giraph任务。
我们还可以实现一个自定义的 ApplicationMaster 来运行特定的任务,进而发明出一种全新的分布式应用程序框架,改变大数据格局。
在YARN中,MapReduce降级为一个分布式应用程序的一个角色(但仍是一个非常流行且有用的角色),现在称为 MRv2。MRv2 是经典MapReduce引擎(称为 MRv1)的重现,运行在YARN之上。
2、YARN可运行任何分布式应用程序
ResourceManager、NodeManager 和容器都不关心应用程序或任务的类型。所有特定于应用程序框架的代码都会转移到ApplicationMaster,以便任何分布式框架都可以受 YARN 支持。
得益于这个一般性的方法,Hadoop YARN集群可以运行许多不同分布式计算模型,例如:MapReduce、Giraph、Storm、Spark、Tez/Impala、MPI等。
3、YARN中提交应用程序
下面讨论在应用程序提交到YARN集群时,ResourceManager、ApplicationMaster、NodeManagers和容器如何相互交互。下图显示了一个例子。
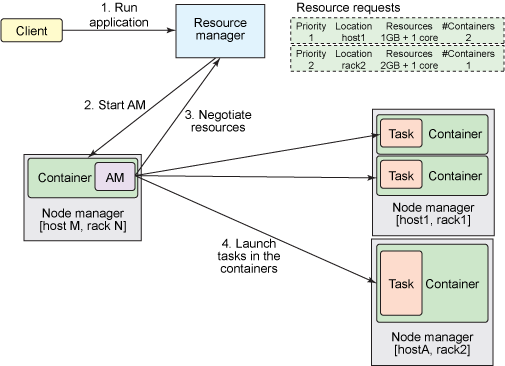
假设用户采用与MRv1中相同的方式键入hadoop jar命令,将应用程序提交到 ResourceManager。ResourceManager维护在集群上运行的应用程序列表,以及每个活动的 NodeManager上的可用资源列表。
ResourceManager 需要确定哪个应用程序接下来应该获得一部分集群资源。该决策受到许多限制,比如队列容量、ACL 和公平性。ResourceManager 使用一个可插拔的 Scheduler。Scheduler 仅执行调度;它管理谁在何时获取集群资源(以容器的形式),但不会对应用程序内的任务执行任何监视,所以它不会尝试重新启动失败的任务。
在 ResourceManager接受一个新应用程序提交时,Scheduler制定的第一个决策是选择将用来运行ApplicationMaster的容器。在 ApplicationMaster启动后,它将负责此应用程序的整个生命周期。首先也是最重要的是,它将资源请求发送到 ResourceManager,请求运行应用程序的任务所需的容器。
资源请求是对一些容器的请求,用以满足一些资源需求,比如:
一定量的资源,目前使用MB内存和CPU份额来表示
一个首选的位置,由主机名、机架名称指定
此应用程序中的一个优先级,而不是跨多个应用程序
如果可能的话,ResourceManager 会分配一个满足ApplicationMaster在资源请求中所请求的容器(表达为容器 ID和主机名)。该容器允许应用程序使用特定主机上给定的资源量。分配一个容器后,ApplicationMaster会要求NodeManager(管理分配容器的主机)使用这些资源来启动一个特定于应用程序的任务。此任务可以是在任何框架中编写的任何进程(比如一个 MapReduce 任务或一个Giraph任务)。
NodeManager 不会监视任务;它仅监视容器中的资源使用情况,例如,如果一个容器消耗的内存比最初分配的更多,它会结束该容器。
ApplicationMaster会竭尽全力协调容器,启动所有需要的任务来完成它的应用程序。它还监视应用程序及其任务的进度,在新请求的容器中重新启动失败的任务,以及向提交应用程序的客户端报告进度。
应用程序完成后,ApplicationMaster 会关闭自己并释放自己的容器。
尽管ResourceManager不会对应用程序内的任务执行任何监视,但它会检查 ApplicationMaster的健康状况。如果 ApplicationMaster失败,ResourceManager 可在一个新容器中重新启动它。我们可以认为ResourceManager负责管理ApplicationMaster,而 ApplicationMasters负责管理任务。
分布式计算 MapReduce与yarn工作机制相关推荐
- Hadoop之Yarn工作机制详解
Hadoop之Yarn工作机制详解 目录 Yarn概述 Yarn基本架构 Yarn工作机制 作业提交全过程详解 1. Yarn概述 Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于 ...
- Yarn在MapReduce中的工作机制
目录 前言: 1.YARN概述 2.mapreduce&yarn的工作机制 总结: 目录 前言: 在了解Yarn在MR中的作用的时候需要先了解Yarn是什么. 1.YARN概述 Yarn是一个 ...
- Yarn基本架构和工作机制
Yarn基本架构和工作机制 概念 Yarn基本架构 ResourceManager (RM)作用 NodeManager (NM)作用 ApplicationMaster (AM)作用 contain ...
- hadoop--Yarn资源调度器的基础架构、工作机制 与 作业提交全过程
目录 一.Yarn资源调度器 Yarn 基础架构 二.YARN工作机制 三.作业提交全过程 1. HDFS.YARN.MapReduce三者关系 2. 作业提交过程(YARN) 3. 作业提交过程(H ...
- 【Hadoop快速入门】Hdfs、MapReduce、Yarn
1. Hahoop概述 1.1 Hodoop是什么 1) Hadoop是一个有Apache基金会所开发的分布式系统基础架构 2) 主要解决海量数据的存储和海量数据的分析计算问题 3) 广义上来说,Ha ...
- Yarn01:诞生背景、架构和工作机制介绍
写在前面的总结: Yarn只响应job的提交及为job的运行分配资源,yarn不参与job的具体运行机制和流程. mapReduce程序中有一个进程MrAppMaster来负责程序的具体运行流程控制. ...
- MapReduce1和Yarn的工作机制
Hadoop中的MapReduce的工作机制分为两种: MapReduce 1 也就是Hadoop 2.0之前的工作机制 YARN MapReduce 1 构成 MapReduce 1最主要的其实就是 ...
- 【MapReduce】MapReduce工作机制
一个mapreduce作业,一般分为两阶段执行:map阶段和reduce阶段,下面分别对这两阶段进行介绍. Map阶段 Map阶段又分为五部分:读取文件阶段,MapTask阶段,collect阶段,溢 ...
- 第6章-MapReduce的工作机制-笔记
为什么80%的码农都做不了架构师?>>> 作业的提交 可以只用一行代码来运行一个MapReduce作业: JobClient.runJob(conf). 作业的调度 Hadoo ...
最新文章
- Axios的基本使用
- VTK:PolyData之MultiBlockMergeFilter
- OnInit 和 Page_Init 事件有什么不同
- (18) Node.js npm包管理工具
- 月球软着陆matlab程序,matlab变量优化 卫星软着陆问题
- zend studio【快捷键】
- 高等代数第3版下 [丘维声 著] 2015年版_一文搞懂代数几何发展史(一)
- 【FPGA+BP神经网络】基于FPGA的简易BP神经网络verilog设计
- C++ Concurrency in Action, 2nd Edition 免积分下载
- 强化学习(十一) Prioritized Replay DQN
- 威联通Docker安装为知笔记方法
- 《惢客创业日记》2020.11.15-17(周日)谁有谁的四十不惑?
- java发送get请求400解决
- 解读数据处理白皮书、共话核心软件创新,软博会又一主题论坛拉开帷幕!
- 华中科技大学计算机徐永兵,华中科技大学计算机学院导师及科研方向.doc
- MySQL数据库 各种指令操作大杂烩(DML增删改、DQL查询、SQL...)
- 【文史】百家讲坛讲稿txt下载
- 上课记录笔记 项目1 文字大乱斗 v0.1
- 实验六 MPEG音频编码
- UCenter 基本原理
热门文章
- android 添加随意拖动的桌面悬浮窗口,android 添加随意拖动的桌面悬浮窗口
- java jdbc 详解_JDBC概述及详解各个对象
- 在微型计算机系统中,打印机一般是通过( ,2013湖南省计算机等级考试试题 二级C试题最新考试试题库...
- java ssh 那一层应该捕获异常_java ssh异常(大神来看看啊)
- c语言中的所有关键字,C语言中的32个关键字
- python 个人所得税问题_Python实现的个人所得税计算器
- 苹果app商品定价_【知乎问答】苹果 App Store 新推出的 1 元或 3 元定价对开发者有什么影响?...
- mysql考勤系统设计函数_Mysql实战之员工考勤系统数据库建立
- java http头 字符串转日期_springboot~DTO字符字段与日期字段的转换问题
- 2014 网选 5007 Post Robot(暴力或者AC_自动机(有点小题大作了))