MapReduce1和Yarn的工作机制
Hadoop中的MapReduce的工作机制分为两种:
- MapReduce 1 也就是Hadoop 2.0之前的工作机制
- YARN
MapReduce 1
构成
MapReduce 1最主要的其实就是jobtracker和tasktracker:
- jobtracker,用来协调作业的运行。它也是一个Java程序,主类是JobTracker。
- tasktracker,用来运行作业划分后的任务。它也是一个Java程序,主类是TaskTracker。
除此之外,MapReduce 1的最顶层包括的实体还有两个:客户端、分布式文件系统。
工作原理
我们先来看一幅图:
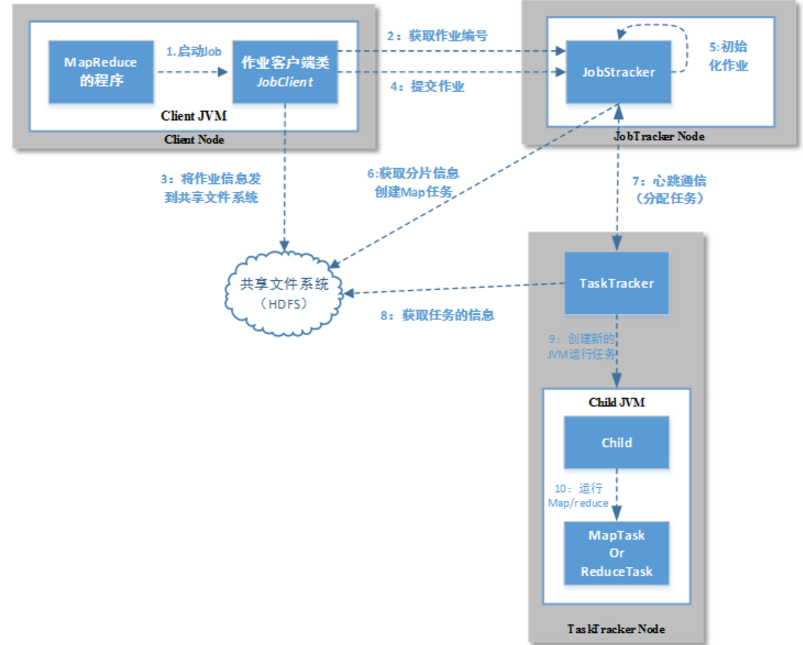
这幅图就是MapReduce 1的工作原理。
我们可以看到里面有10个步骤,分别来看看这10个步骤都干了些什么。
- 客户端启动一个job。
- 从jobtracker请求一个新的作业ID。(getNewJobId()方法)
- 检查作业的输出说明并计算作业的输入分片,然后将运行作业所需要的资源都复制到以作业ID命名的目录下。
- 提交作业,告知jobtracker作业准备执行。(submitJob()方法)
- 初始化作业。创建一个表示正在运行作业的对象,用来封装任务和记录信息。
- 获取客户端计算好的输入分片,然后为每个分片创建一个map任务。在此步骤的时候还会创建reduce任务、作业创建任务、作业清理任务。
- tasktracker运行一个简单的循环来定期发送“心跳”给jobtracker,用来充当两者之间的消息通道。
- 准备运行任务。
- 作业的JAR文件本地化。从共享文件系统把作业的JAR文件复制到tasktracker所在的文件系统。
- tasktracker为任务创建一个本地工作目录,并把JAR解压到这。
- tasktracker创建一个TaskRunner实例。
- 启动一个新的JVM来运行每个任务。
- 运行map/reduce。
这就是经典的MapReduce的工作原理。
YARN
构成
YARN比MapReduce更具一般性,实际上MapReduce只是YARN应用的一种形式。
相比经典的MapReduce来说,YARN的顶层包括更多的实体:
- 客户端。
- YARN资源管理器。负责协调集群上计算资源的分配。
- YARN节点管理器。负责启动和监视集群中机器上的计算容器。
- 应用程序master。负责协调运行MapReduce作业的任务。
- 分布式文件系统。
主要是多了一个容器的概念。每一个任务都有一个对应的容器,而且只能在该容器中运行。
工作原理
同样,我们先看一幅图:
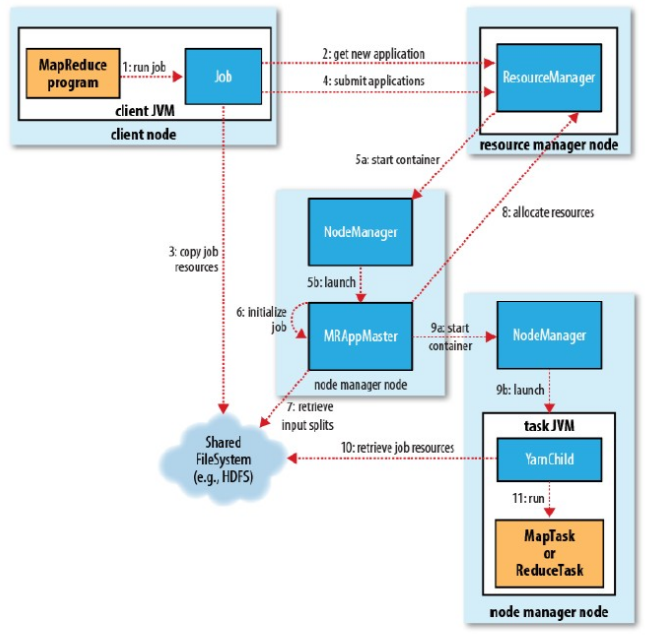
从图中可以看出YARN运行MapReduce的过程有11个步骤,我们分别来看看:
- 启动一个job。
- 从资源管理器请求一个新的作业ID。
- 检查作业的输出说明并计算作业的输入分片,然后将作业资源复制到HDFS。
- 通过调用资源管理器的submitApplication()方法提交作业。
- 将请求传递给调度器。
- 调度器分配一个容器。
- 资源管理器在节点管理器的管理下在容器中启动master进程。
- master进程对作业进行初始化。
- 获取计算出的输入分片,为每个分片创建一个map任务。并创建reduce任务。
- master为作业向资源管理器请求一个容器来运行任务。
- 调度器为任务分配容器。
- master与节点管理器通信来启动容器。
- 资源本地化。
- 运行map/reduce任务。
这样一个YARN运行的MapReduce的原理也就完整了。
转:http://axuebin.com/blog/2016/02/23/hadoop-mapreduce-yarn/?utm_source=tuicool&utm_medium=referral
MapReduce1和Yarn的工作机制相关推荐
- 【Yarn】工作机制及任务提交流程
本文以mr程序为例,解释yarn的工作机制及任务提交流程: 0. mr程序提交任务到客户端所在节点: 1.节点上的YarnRunner向ResourceManager申请一个Application: ...
- Yarn基本架构和工作机制
Yarn基本架构和工作机制 概念 Yarn基本架构 ResourceManager (RM)作用 NodeManager (NM)作用 ApplicationMaster (AM)作用 contain ...
- Yarn在MapReduce中的工作机制
目录 前言: 1.YARN概述 2.mapreduce&yarn的工作机制 总结: 目录 前言: 在了解Yarn在MR中的作用的时候需要先了解Yarn是什么. 1.YARN概述 Yarn是一个 ...
- MapRdeuceYarn的工作机制(YarnChild是什么)
MapRdeuce&Yarn的工作机制 一幅图解决你所有的困惑 那天在集群中跑一个MapReduce的程序时,在机器上jps了一下发现了每台机器中有好多个YarnChild.困惑什么时Yarn ...
- mapreduceyarn的工作机制----吸星大法
1.mapreduce&yarn的工作机制----吸星大法 mapreduce与yarn的工作机制详解 1.客户端首先向yarn发送程序(mapreducer)运行的申请 2.resource ...
- Hadoop之Yarn工作机制详解
Hadoop之Yarn工作机制详解 目录 Yarn概述 Yarn基本架构 Yarn工作机制 作业提交全过程详解 1. Yarn概述 Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于 ...
- Yarn01:诞生背景、架构和工作机制介绍
写在前面的总结: Yarn只响应job的提交及为job的运行分配资源,yarn不参与job的具体运行机制和流程. mapReduce程序中有一个进程MrAppMaster来负责程序的具体运行流程控制. ...
- namenode和datanode工作机制_Hadoop的namenode的管理机制,工作机制和datanode的工作原理...
HDFS前言: 1) 设计思想 分而治之:将大文件.大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析: 2)在大数据系统中作用: 为各类分布式运算框架(如:mapr ...
- 探秘HDFS —— 发展历史、核心概念、架构、工作机制 (上)| 博文精选
戳蓝字"CSDN云计算"关注我们哦! 作者 | Mr-Bruce 转自 | CSDN博客 责编 | 阿秃 几周前,笔者做了一个与HDFS有关的技术分享,以知识普及为目的,主要分享 ...
最新文章
- 在C#中使用 CancellationToken 处理异步任务
- android 反编译 添加 res,Android apk反编译记录
- 跨平台开发实践之Flutter
- uni-app框架介绍
- SpringBoot拦截器和过滤器的一起使用
- 深度步态识别综述(二)
- 软件项目的项目经理不懂技术,能做好项目经理么?
- 网络安全诉讼风险:首席信息安全官最关心的4个问题
- 极路由添加静态路由表_如何将静态TCP / IP路由添加到Windows路由表
- 基于Java+SpringBoot+Thymeleaf+Mysql新冠疫苗预约系统设计与实现
- UBUNTU使用RTL8811CU网卡(包含树莓派)
- 点击图片显示图片放大的弹窗
- 你怎么看待互联网创业的国外问卷调查?
- 镁客网每周硬科技领域投融资汇总(2.24-3.2),地平线机器人晋升估值最高的AI芯片独角兽...
- 贾跃亭微博发新车V9图片 计划明年量产预售
- 【面试专栏】第五篇:Java基础:集合篇-LinkedHashMap、ConcurrentHashMap、TreeMap
- 【Leetcode】leetcode 发布题解后无法编辑(已解决)
- Windows 定位某文件位置并选择文件、定位某个注册表项位置
- RFID智能仓储管理解决方案-RFID无人仓储管理-新导智能
- crontab巨坑问题