定位排查工作流的计算结果数据量不符合预期的方法
近期有发现一些用户在咨询,为什么数据从数据源出来后,经过了一些计算,结果不符合预期了。最常见的是说,为什么我的数据在Mysql里有xx条,怎么到MaxCompute里算了下结果变了。因为这是两个不同的系统,我们又没办法拿两边的记录直接做个full outer join看看少的是哪些数据。本文拿2个实际的例子,做了简化方便理解,给出排查过程,希望能给大家带来一些思路。
问题1
场景模拟
这是一个常见的场景,为什么我数据同步过来后,就直接用SQL做了count,结果就不对了。
先在mysql里创建一张用户表,并插入一些数据:
create table myuser(uid int,name varchar(30),regTime DATETIME );
insert into myuser(uid,name,regTime) values (1,'Lilei','2017-01-22 01:02:03');
insert into myuser(uid,name,regTime) values (2,'HanMM','2017-01-22 22:22:22');然后在MaxCompute里配置了个接受的表:
create table ods_user(uid bigint,name string,regTime datetime) partitioned by(ds string);然后配置了一个同步任务和SQL任务用于统计结果数据条数如图:
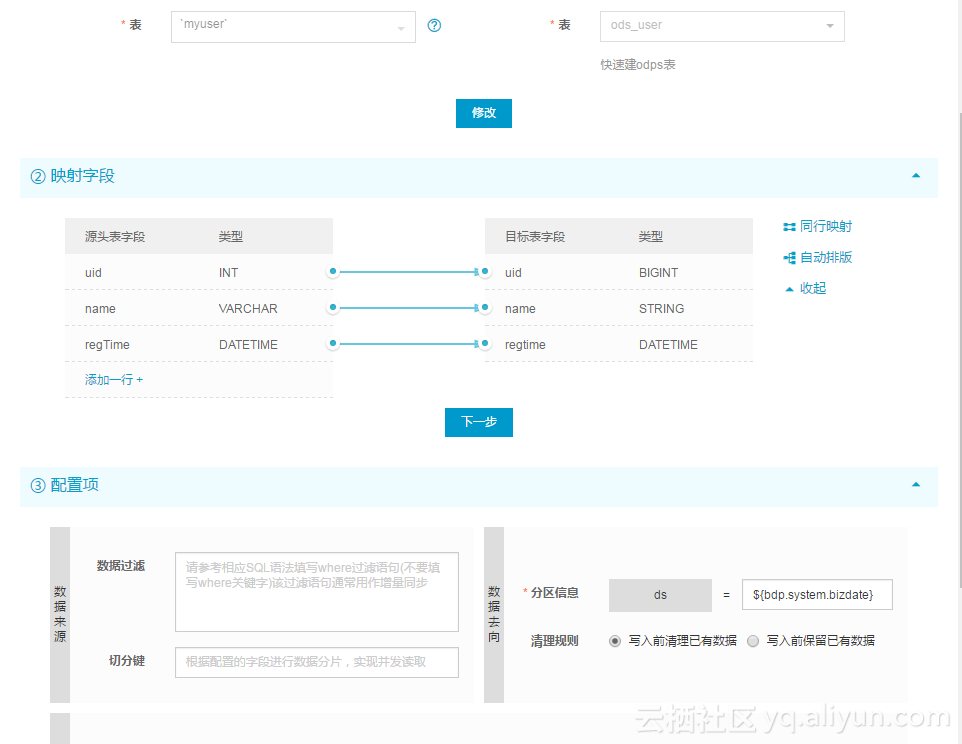
CREATE TABLE IF NOT EXISTS dws_usercnt (cnt BIGINT
)
PARTITIONED BY (ds STRING);INSERT OVERWRITE TABLE dws_usercnt PARTITION (ds='${bdp.system.bizdate}')
SELECT COUNT(*) AS cnt
FROM ods_user;最后做成工作流
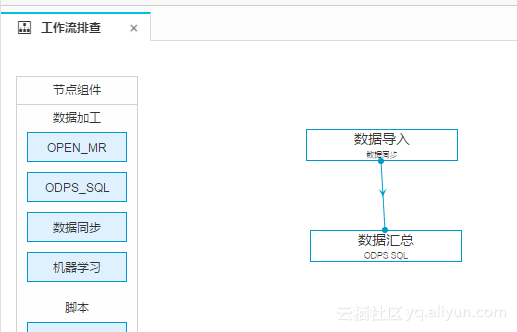
任务上线后,跑了第一天,结果还是对的。
odps@ >read dws_usercnt;
+------------+------------+
| cnt | ds |
+------------+------------+
| 2 | 20170122 |
+------------+------------+但是第二天插入几条新的数据后,为什么统计结果就不对了呢:
odps@ >read dws_usercnt;
+------------+------------+
| cnt | ds |
+------------+------------+
| 2 | 20170122 |
| 6 | 20170123 |
+------------+------------+预期的是第二天的数据是4。
排查解决
我们需要先理清楚数据的走向。这个例子的思路很简单,数据从Mysql同步到MaxCompute的表里,然后针对结果表做了汇总。走向图为myuser(MySql)=>ods_user(MaxCompute)=>dws_usercnt(MaxCompute)。
目前我们通过在Mysql里查询,已经确认Mysql里就是4条记录,dws_usercnt里的结果也看到是6,那需要先定位到是ods_user里的结果是多少条,从而定位到是同步的时候出现的问题,还是同步后汇总出现的问题。
我们先看了一下ods_user,先用select count(*) from ods_user;看到为6。因为是分区表,对么个分区查一下,用select count(*) as cnt,ds from ods_user group by ds;,发现结果是
+------------+----+
| cnt | ds |
+------------+----+
| 2 | 20170122 |
| 4 | 20170123 |
+------------+----+然后配合同步任务的日志
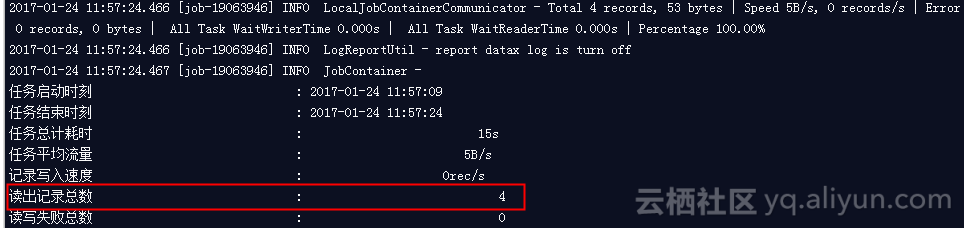
我们可以看到,我们一共同步了4条数据(如果是这里对不上的话,我们需要检查一下同步任务的where表达式对不对了)。然后最后汇总的时候,我们看下日志:
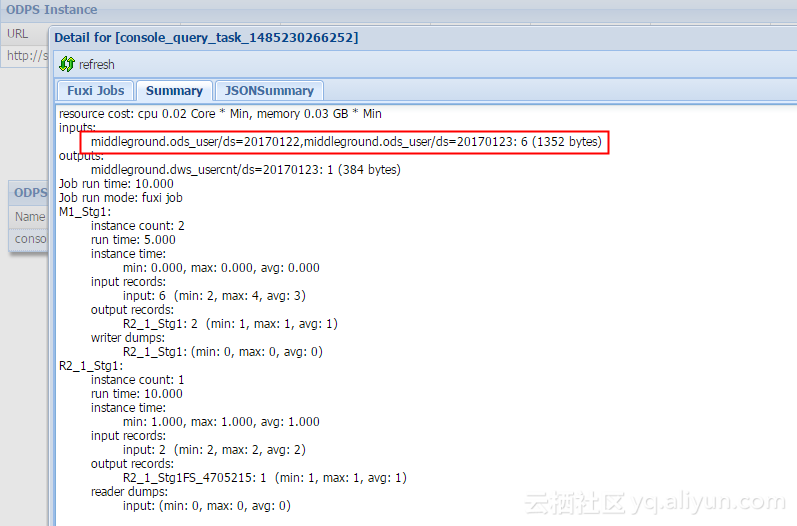
我们可以看到我们在SQL里是访问了2个分区的数据做了汇总。
所以这个问题的原因是在同步的时候,是做了每天的全量同步,但是在SQL汇总的时候,当成是增量同步了,或者是忘记写分区的过滤条件了,导致汇总是查询了全部的数据。针对这个问题的解法是先要确定这个表到底是需要增量同步,还是需要全量同步。如果是需要增量同步,那需要修改同步的时候,在配置项里配置过滤条件只同步增量数据。如果是需要每天同步全量数据,那在汇总的时候,就只需要读最后一个分区就可以了。
另外关于增量同步的配置方法,可以参考这篇文档。
问题2
场景模拟
有一些用户希望针对数据的某个属性进行分区,比如希望根据学生的年级进行分区。
我们先在Mysql里创建一张学生表,插入一些数据
create table student(id int,name varchar(30),grade varchar(1));
insert into student(id,name,grade) values(1,'Lilei',1);
insert into student(id,name,grade) values(2,'HanMM',2);
insert into student(id,name,grade) values(3,'Jim',3);同样的,在MaxCompute这边也需要配置一个ODS表和一个DWD表
create table ods_student(id bigint,name string,grade string) partitioned by(ds string) ;
create table dwd_student(id bigint,name string)partitioned by(grade string) ;然后配置一个同步任务:
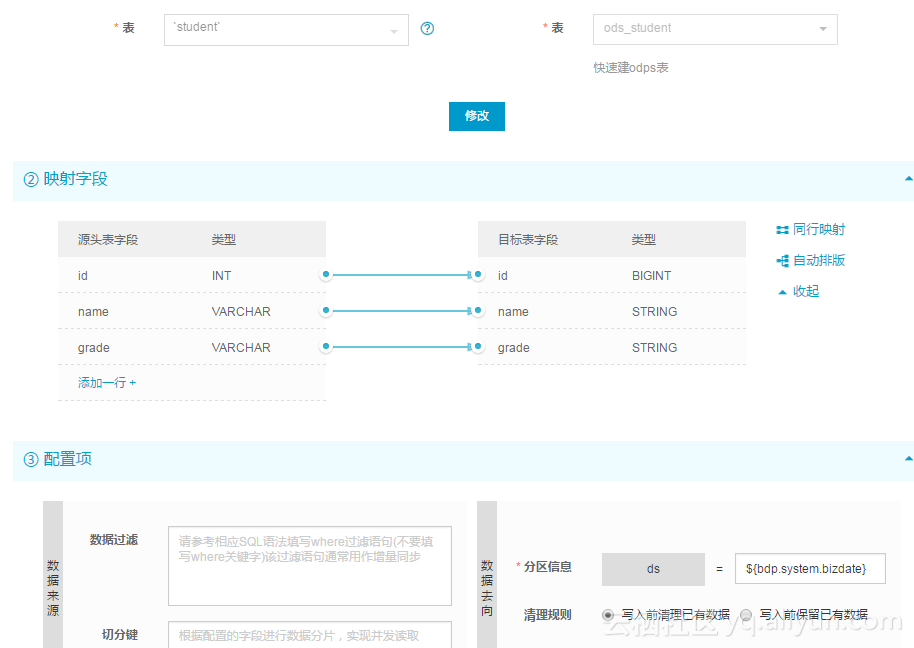
和对应的SQL任务
insert overwrite table dwd_student partition(grade )
select id,name,grade
from ods_student
where ds = '${bdp.system.bizdate}';同步后看到第一天的结果是对的。
后来这些学生都到了新年级了,3年级的学生毕业了
update student set grade = grade+1;
delete from student where grade>3;--已经毕业的再同步一下,不对了,数据怎么还是3条。
排查解决
我们这里测试的数据比较少,可以直接select出来一看就明白了。但是真实的业务里,我们的数据可能有数以亿计,根本没办法肉眼看出来。所以还是以前的思路,我们先理清楚数据的走向。数据是从student(Mysql)=>ods_student(MaxCompute)=>dwd_student(MaxCompute)。
第二天,Mysql里的student表里数据其实是只有2条了。而ods_student表里的最新的分区也是2条。但是dwd_student里是3条。这说明ods=>dwd的过程中,数据出了问题。这个就是一个SQL问题了。我们用SQL
--里面的ds的值记得换掉
select
ods.grade,dwd.grade,ods.cnt,dwd.cnt
from
(select count(*) as cnt,grade from ods_student where ds= '${bdp.system.bizdate}' group by grade) ods
full outer join (select count(*) as cnt,grade from dwd_student group by grade) dwd
on ods.grade = dwd.grade
where coalesce(ods.cnt,0) <> coalesce(dwd.cnt,0) ;+-------+--------+------------+------------+
| grade | grade | cnt | cnt |
+-------+--------+------------+------------+
| NULL | 1 | NULL | 1 |
+-------+--------+------------+------------+
看到1年级,数据里ods表里没有1年级的数据了,但是dwd里还是有1条1年级的数据。这下就很清楚了,这条数据是第一天的数据。后来升了年级后,用Insert Overwrite覆盖写入的时候,2年级和3年级是有新数据进来的,所以数据被覆盖了。但是1年级因为没有数据进来,所以也没覆盖。我们也可以用desc partition命令看下每个分区的创建时间和修改时间来确认这个问题。
对于这种情况,其实这种分区方法有一些问题的。建议dwd表里不要做这样的分区。如果确实需要分区,也不要直接在历史分区上做覆盖写入,可以写到新的分区里,比如做2级分区,1级分区是日期字段,二级分区才是这样的业务分区字段。
本文使用的产品涉及大数据计算服务(MaxCompute),地址为https://www.aliyun.com/product/odps
配合大数据开发套件 https://data.aliyun.com/product/ide 完成的。
如果有问题,可以加入我们的钉钉群来咨询
定位排查工作流的计算结果数据量不符合预期的方法相关推荐
- snm算法_基于SNM算法的大数据量中文商品清洗方法
基于 SNM 算法的大数据量中文商品清洗方法 ∗ 张苗苗 苏 勇 [摘 要] 摘 要 SNM 算法即邻近排序算法,是英文数据清洗最常用的算法[ 1 ] . 目前为止,因为中英文语义的差异等一些原因,中 ...
- snm算法_基于SNM算法的大数据量中文地址清洗方法-计算机工程与应用.PDF
基于SNM算法的大数据量中文地址清洗方法-计算机工程与应用 108 2014 ,50(5 ) Computer Engineering and Applications 计算机工程与应用 基于SNM ...
- 大数据量,海量数据 处理方法总结(转)
最近有点忙,稍微空闲下来,发篇总结贴. 大数据量的问题是很多面试笔试中经常出现的问题,比如baidu google 腾讯 这样的一些涉及到海量数据的公司经常会问到. 下面的方法是我对海量数据的处理方法 ...
- [转载]大数据量,海量数据 处理方法总结 作者phylips@bmy
转自:http://i.yoho.cn/473260/logview/1816730.html 大数据量的问题是很多面试笔试中经常出现的问题,比如baidu google 腾讯 这样的一些涉及到海量数 ...
- ERA5-Land hourly data数据直接计算出来数据量偏大,monthly单位等
1. ERA5-Land hourly 单位及相关数据说明 我在计算长江流域年总降水的时候发现用ERA5-Land hourly data from 1950 to present计算出来的平均降水都 ...
- python网络爬虫系列(七)——selenium的介绍 selenium定位获取标签对象并提取数据 selenium的其它使用方法
一.selenium的介绍 知识点: 了解 selenium的工作原理 了解 selenium以及chromedriver的安装 掌握 标签对象click点击以及send_keys输入 1. sele ...
- 训练数据量中关于batch_size,iteration和epoch的概念
batch_size 机器学习使用训练数据进行学习,针对训练数据计算损失函数的值,找出使该值尽可能小的参数.但当训练数据量非常大,这种情况下以全部数据为对象计算损失函数是不现实的.因此,我们从全部数据 ...
- 图像像素与数据量之间的关系
像素是图片中的点,一个点是一种颜色,所以点越小图片越逼真,因此相同像素的图片在很小的尺寸下看着更清晰. 计算图片数据量很简单:图片像素*每像素的字节数/8, 这个计算结果的单位是字节. 不同的图片格式 ...
- 3DGIS第二章 大数据量场景加速绘制基本原理与方法
对于仅有几百个多边形和几十兆的低分辨率纹理简单场景,在现阶段一般配置的计算机上也很容易达到实时仿真的目标.然而,随着场景规模的增大,大规模虚拟场景中往往包含上万个多边形,甚至多达几百万个多边形和几百兆 ...
最新文章
- vCenter连接esxi 5.0报“Datacenter.QueryConnectionInfo” 失败
- python三维图旋转_SciPyTutorial-图像的矩阵旋转变换
- 传智播客韩顺平老师2011ssh实战项目校内网的数据库设计32张表全解
- 编写python脚本完成图片拼接
- 深入了解一下PYTHON中关于SOCKETSERVER的模块-B
- 盘点程序员必备的专业术语,值得看一看
- [蓝桥杯]最大连续子序列和
- 【分块】区间众数(金牌导航 分块-1)
- mySQL 插入,更新和删除数据
- Audio -- Music Playback 框图
- 【Tensorflow踩过的坑儿】pb转pbtxt
- Pytorch GAN实战 MINIST手写数字识别分布解析
- python通过文件头识别音频格式
- 在线旅游网站技术讲解
- GEE实现夜光遥感数据分析
- Soul如何让年轻人的“灵魂”心甘情愿的买单?
- 聚类算法及其模型评估指标【Tsai Tsai】
- 【其它】颜色的知识--亮度、色相、饱和度、对比度
- [渝粤教育] 无锡商业职业技术学院 导游业务 参考 资料
- Mendix与JEECG对比