python熊猫图案_熊猫Python数据分析库和SQL教会了我如何取平均数
python熊猫图案
对于主要处理数据的Python开发人员来说,很难不让自己经常陷入SQL和Python的开源数据库pandas中。 尽管这些工具使操作和转换数据变得如此容易(有时就像一行代码一样简洁),但分析人员仍然必须始终了解其数据及其代码的含义。 即使计算像汇总统计信息一样简单的内容,也容易出现严重的错误。
在本文中,我们看一下算术平均值。 尽管通常讲授一维数据,但是针对多维数据进行计算需要一个根本不同的过程。 实际上,将算术平均值当作一维数据来计算将产生严重不正确的数字,有时甚至超出预期数量级。 对我而言,这是一次令人沮丧的经历:即使算术平均值也比其他任何计算都要受到两次和三次检查。
很少有统计计算能够与最基本的简单性和解释能力相提并论:百分比,总和和平均值。 结果,它们遍地开花,从探索性数据分析到数据仪表板和管理报告。 但是其中之一(算术平均值)异常成问题。 尽管通常讲授一维数据,但是针对多维数据进行计算需要一个根本不同的过程。 实际上,将算术平均值当作一维数据来计算将产生严重不正确的数字,有时甚至超出预期数量级。 对我而言,这是一次令人沮丧的经历:即使算术平均值也比其他任何计算都要受到两次和三次检查。
回归本源
算术平均值定义为:
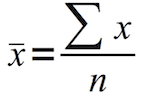
要么:
SUM(all observations) / COUNT(number of observations)
我们可以通过一个简单的摘苹果示例看到这一点:
苹果
| 名称 | num_apples |
|---|---|
| Katie | 4 |
| Alan | 8 |
| John | 10 |
| Tess | 8 |
| Jessica | 5 |
什么构成这里的观察? 由单个列(名称)定义的一个人,也称为维度或属性。
使用上面的公式,我们可以计算算术平均值:
SUM(4 + 8 + 10 + 8 + 5) / 5 = 7
在SQL中,我们将编写:
SELECT AVG ( num_apples ) FROM apples
我们只是算什么? “每个人摘苹果的平均数量”(每个人代表一个观察值)。
增加复杂性:二维数据
苹果
| 日期 | 名称 | num_apples |
|---|---|---|
| 2017-09-24 | 凯蒂 | 4 |
| 2017-09-24 | 艾伦 | 8 |
| 2017-09-24 | 约翰 | 10 |
| 2017-09-24 | 苔丝 | 8 |
| 2017-09-26 | 凯蒂 | 5 |
在此示例中,我们用凯蒂(Katie)替换了杰西卡(Jessica),但日期不同。
现在,表中的每个观察值都不是简单的 (名称)。 凯蒂(Katie)出现了两次,但由于凯蒂(Katie)在不同的两天摘了苹果,所以分别观察到。 而是,每个观察都由两个维度组成:(日期,名称)。
我们可以问与以前相同的问题:“人平均摘苹果的数量是多少?”
我们应该像以前一样期待一个数字。 我们是否应该像以前那样期望平均值等于7?
回到我们的公式:
要么:
SUM(4 + 8 + 10 + 8 + 5) / 4 = 8.75
这里发生了什么? 在表级别定义的观察单位不同于我们分析的观察单位。
对于我们的分析性问题,我们没有询问每个人摘苹果多少天。 我们只是在询问每个人平均采摘的苹果数量,最后我们应该得到一个答案,例如“平均采摘7个苹果”或“平均采摘10个苹果”。 如果凯蒂(Katie)采摘苹果的天数超过其他所有人,那应该会真正提高平均水平。 在任何随机的苹果采摘机样本中,我们可能会吸引像Katie这样的人比其他任何人更频繁地采摘苹果,这会增加人采摘苹果的平均数量。
那么我们如何用SQL编写呢? 这是行不通的:
SELECT AVG(num_apples) FROM apples
这将为我们提供与以前相同的答案:7。
我们要做的是将数据折叠到我们关注的分析级别。 我们并没有要求约会人员挑选苹果的平均数量,这是之前的查询所能提供的。 我们正在询问普通人采摘的苹果数量。 我们分析的观察水平是一个人(姓名),而不是一个约会人员(日期,姓名)。
因此我们的查询如下所示:
SELECT AVG(num_apples) FROM (
SELECT name, SUM(num_apples) AS num_apples
FROM apples
GROUP BY name
) AS t
害怕。
内部查询为我们提供了以下结果集:
苹果
| 名称 | num_apples |
|---|---|
| Katie | 9 |
| Alan | 8 |
| John | 10 |
| Tess | 8 |
现在, 这就是我们想要取的平均值! 然后,外部查询将执行以下操作:
SUM(4 + 8 + 10 + 8 + 5) / 4 = 8.75
那么我们在这里学到了什么? 我们的分析性问题要求我们将数据的维数减少到小于表定义的维数。 该表定义了对两个维度(日期,名称)的观察,但是我们的分析问题要求对一个维度(名称)进行观察。
由于折叠而导致的尺寸变化导致分母中观测值的数量发生变化,从而改变了我们的平均值。
重申一下显而易见的一点:如果不对原始数据执行此折叠操作,则我们计算出的第一个平均值将是错误的 。
为什么会发生这种情况?
当数据存储在数据库中时,必须指定粒度级别。 换句话说,“什么构成个人观察?”
您可以想象一个表存储这样的数据:
营业额
| 日期 | 产品_已售 |
|---|---|
| 2017-09-21 | 21 |
| 2017-09-22 | 28 |
| 2017-09-24 | 19 |
| 2017-09-25 | 21 |
| 2017-09-26 | 19 |
| 2017-09-27 | 18 |
但是您也可以想象一个表,它存储相同的数据,但是存储的粒度更大,如下所示:
营业额
| 日期 | 产品分类 | 产品_已售 |
|---|---|---|
| 2017-09-21 | 上衣 | 16 |
| 2017-09-21 | 外套 | 2 |
| 2017-09-21 | 礼帽 | 3 |
| 2017-09-22 | 上衣 | 23 |
| 2017-09-22 | 礼帽 | 5 |
| 2017-09-24 | 上衣 | 10 |
| 2017-09-24 | 外套 | 3 |
| 2017-09-24 | 礼帽 | 6 |
| 2017-09-25 | 上衣 | 21 |
| 2017-09-26 | 上衣 | 14 |
| 2017-09-26 | 礼帽 | 5 |
| 2017-09-27 | 上衣 | 14 |
| 2017-09-27 | 外套 | 4 |
在表级别定义的观察单位称为主键 。 所有数据库表中都需要一个主键,并且应用了一个约束,即每个观察值都必须是唯一的。 毕竟,如果一个观察出现两次但不是唯一的,则应该只是一个观察。
它通常遵循如下语法:
CREATE TABLE sales (
date DATE NOT NULL default '0000-00-00',
product_category VARCHAR(40) NOT NULL default '',
products_sold INT
PRIMARY KEY (date, product_category) <------
)
请注意,我们选择记录的有关数据的粒度级别实际上是表定义的一部分。 主键在我们的数据中定义了“单一观察”。 并且这是我们开始存储任何数据之前所必需的。
现在,仅因为我们在该粒度级别记录数据并不意味着我们需要在该粒度级别进行分析 。 我们需要分析数据的粒度级别始终取决于我们要回答哪种问题。
这里的关键要点是,主键在表级别定义了一个观察值 ,并且可以包括一个或两个或20个维度。 但是我们的分析可能不会这么细化地定义观察(例如,我们可能只关心每天的销售额),因此我们必须折叠数据并重新定义观察以进行分析。
形式化模式
因此,我们知道,对于我们提出的任何分析问题,我们都需要重新定义构成单个观察值的内容,而与主键碰巧无关。 如果我们仅取平均值而不会使我们的数据崩溃,那么我们将在分母中得到太多观察值(即,由主键定义的数量),因此平均值太低 。
要进行审查,请使用与上述相同的数据:
营业额
| 日期 | 产品分类 | 产品_已售 |
|---|---|---|
| 2017-09-21 | 上衣 | 16 |
| 2017-09-21 | 外套 | 2 |
| 2017-09-21 | 礼帽 | 3 |
| 2017-09-22 | 上衣 | 23 |
| 2017-09-22 | 礼帽 | 5 |
| 2017-09-24 | 上衣 | 10 |
| 2017-09-24 | 外套 | 3 |
| 2017-09-24 | 礼帽 | 6 |
| 2017-09-25 | 上衣 | 21 |
| 2017-09-26 | 上衣 | 14 |
| 2017-09-26 | 礼帽 | 5 |
| 2017-09-27 | 上衣 | 14 |
| 2017-09-27 | 外套 | 4 |
“每天平均售出多少产品?”
嗯,此数据集中有6天的时间,总共售出126种产品。 平均每天售出21种产品。
它不是9.7 ,这是您从以下查询中得到的:
SELECT AVG(products_sold) FROM sales
我们需要像这样折叠数据:
SELECT AVG(quantity) FROM (
SELECT date, SUM(products_sold) AS quantity
FROM sales
GROUP BY date
) AS t
给我们21.我们可以在这里感觉到它的重要性:9.7根本不接近21。
在上面注释该查询:
SELECT AVG(quantity) FROM (
SELECT date, SUM(products_sold) AS quantity
FROM sales
GROUP BY date // [COLLAPSING KEY]
) AS t
在这里,我将折叠键定义为“与我们的分析相关的观察单位”。 它与主键无关,它忽略了我们不关心的任何列,例如(product_category)。 崩溃的密钥说:“我们只想使用这种级别的粒度,因此通过将所有粒度加起来将其汇总到下面。
在这种情况下,我们将分析的观察单位明确定义为(日期),它将组成分母中的行数。 如果我们不这样做,谁知道分母会有多少观察(行)? (答案:但是我们在主键级别看到的很多。)
不幸的是,崩溃的关键还不是故事的结局。
如果我们要获取组的平均值怎么办? 例如,“按类别销售的平均产品数量是多少?”
与小组合作
“按类别销售的平均产品数量是多少?”
似乎是一个无害的问题。 可能出什么问题了?
SELECT product_category, AVG(products_sold)
FROM sales
GROUP BY product_category
没有。 确实有效。 那是正确的答案。 我们得到:
营业额
| 产品分类 | AVG(产品已售) |
|---|---|
| T-Shirts | 12.83 |
| Jackets | 3 |
| Hats | 4.75 |
夹克的健全性检查:我们有三天卖夹克,而我们总共卖出4 + 3 + 2 = 9,所以平均为3。
我立刻想到:“三个什么 ?” 答:“平均卖出三件夹克。” 问题:“平均是多少?” 答:“平均一天,我们卖三件夹克。”
好的,现在我们看到我们最初的问题还不够精确,它没有提及几天!
我们真正回答的问题是:“对于每种产品类别,每天平均售出多少产品?”
平均问题的剖析,英文
由于任何SQL查询的目标都是最终实现以简单英语提出的问题的直接声明式翻译,因此我们首先需要以英语理解问题的各个部分。
让我们分解一下:“对于每个产品类别,每天平均售出多少产品?”
分为三个部分:
组:我们想要每个产品类别(product_category)的平均值观察:我们的分母应该是天数(日期)度量:分子是我们求和的度量变量(products_sold)
对于每个组,我们需要一个平均值,该平均值是每天售出的产品总数除以该组中的天数 。
我们的目标是将这些英语组件直接转换为SQL。
从英语到SQL
以下是一些交易数据:
交易次数
| 日期 | 产品 | 州 | 购买者 | 数量 |
|---|---|---|---|---|
| 2016-12-23 | 真空 | 纽约州 | 布莱恩·金 | 1个 |
| 2016-12-23 | 订书机 | 纽约州 | 布莱恩·金 | 3 |
| 2016-12-23 | 打印机墨水 | 纽约州 | 布莱恩·金 | 2 |
| 2016-12-23 | 订书机 | 纽约州 | 特雷弗·坎贝尔 | 1个 |
| 2016-12-23 | 真空 | 嘛 | 劳伦·米尔斯 | 1个 |
| 2016-12-23 | 打印机墨水 | 嘛 | 约翰·史密斯 | 5 |
| 2016-12-24 | 真空 | 嘛 | 劳伦·米尔斯 | 1个 |
| 2016-12-24 | 键盘 | 纽约州 | 布莱恩·金 | 2 |
| 2016-12-25 | 键盘 | 嘛 | 汤姆·刘易斯 | 4 |
| 2016-12-26 | 订书机 | 纽约州 | 约翰·杜 | 1个 |
“对于每个州和产品,每天平均售出多少产品?”
SELECT state , product , AVG ( quantity )
FROM transactions
GROUP BY state , product
这给我们:
交易次数
| 州 | 产品 | AVG(数量) |
|---|---|---|
| NY | 真空 | 1个 |
| NY | 订书机 | 1.66 |
| NY | 打印机墨水 | 2 |
| NY | 键盘 | 2 |
| MA | 真空 | 1个 |
| MA | 打印机墨水 | 5 |
| MA | 键盘 | 4 |
在(NY,订书机)进行健全性检查时,我们应该在2天(2017-12-23和2017-12-26)内总共得到3 +1 + 1 = 5,给我们2.5 ...
las,SQL结果给了我们1.66。 该查询一定是错误的 。
这是正确的查询:
SELECT state , product , AVG ( quantity ) FROM (
SELECT state , product , DATE , SUM ( quantity ) AS quantity
FROM transactions
GROUP BY state , product , DATE
) AS t
GROUP BY state , product
给我们:
交易次数
| 州 | 产品 | AVG(数量) |
|---|---|---|
| NY | 真空 | 1个 |
| NY | 订书机 | 2.5 |
| NY | 打印机墨水 | 2 |
| NY | 键盘 | 2 |
| MA | 真空 | 1个 |
| MA | 打印机墨水 | 5 |
| MA | 键盘 | 4 |
SQL中平均问题的剖析
我们确定英语平均题分为三个部分,如果我们不遵守这一点,我们将对平均值进行错误的计算。 我们也知道,英语的组件应该转换为SQL的组件。
他们来了:
SELECT state , product ,
AVG ( quantity ) // [ MEASUREMENT VARIABLE ]
FROM (
SELECT state , product , DATE , SUM ( quantity ) AS quantity
FROM transactions
GROUP BY state , product , DATE // [ COLLAPSING KEY ]
) AS t
GROUP BY state , product // [ GROUPING KEY ]
-- [OBSERVATION KEY] = [COLLAPSING KEY] - [GROUPING KEY]
-- (date) = (state, product, date) - (state, product)
这是与上面相同的查询,只是带有注释。
请注意,折叠键不在我们的英语问题中—就像伪造主键一样,但是用于我们的分析而不是使用表中定义的键。
还要注意, 在SQL转换中,观察键是隐式的,不是显式的 。 观察键等于折叠键 (即,仅是我们分析所需的尺寸,仅此而已) 减去分组键 (在其上进行分组的尺寸)。 剩下的就是观察的关键,或者是定义我们分析的观察的关键。
我是第一个承认这个令人困惑的人,即我们平均问题的最重要部分(即定义观察的内容)在SQL中甚至不是明确的。 它是隐式的。 我称这是进行多维平均的陷阱 。
外卖如下:
折叠键定义了我们将在分析中使用的维度。 该表的主键中的所有其他内容都将被“汇总”。 我们在内部查询的GROUP BY中定义折叠键。分组键取决于我们要对数据进行分组的维度(即“针对每个组”)。 这是在外部查询的GROUP BY中定义的。折叠键-分组键=观察键 。如果未定义折叠键,则隐式使用表的主键作为折叠键。如果您不进行任何分组,则折叠键等于观察键
举例来说,如果表的主键是(日期,产品,状态,购买者),并且您想对每个状态( 组 :状态)按购买者( 观察值 :购买者)取平均值, 则必须解决折叠键 (即内部SQL查询中的内容)。
我们不想隐式使用主键,因此我们将使用折叠键。 什么折叠键? 折叠键将为( 观察键 :购买者)+( 分组键 :状态)=(购买者,状态)。 那在我们内部查询的GROUP BY中,(状态)仅在外部查询的GROUP BY中,并且隐含的观察键是(购买者)。
最后,请注意如果不使用折叠键会发生什么。 主键是(日期,产品,状态,购买者),而我们的分组键是(状态)。 如果我们根本不使用任何子查询,我们将得到一个答案,该答案将观察值定义为(日期,产品,状态,购买者)-(状态)=(日期,产品,购买者)。 这将决定我们在每个组中看到多少个观测值,从而影响我们平均值的分母。 哪有错
结语
从这一切中学到的一件事是,从分析的角度来看, 永远不要相信主键 。 它定义了记录数据的粒度(即,构成观察值的粒度),但这可能不是分析所需要的。 而如果你没有明确意识到这种差异会如何影响你的计算,你的计算很可能是不正确的。 因为无论您是否知道,主键都会影响分母。
因此,如果您不信任主键,那么最安全的方法就是始终折叠数据。 如果您不进行任何分组,那么折叠键将显式等于观察键。 如果要进行分组,那么折叠键就是观察键和分组键的总和。 但是可以肯定的是:如果您不折叠数据,则意味着您隐含地信任主键。
我了解到的第二件事是,与SQL完全无关,询问有关平均值的问题并不总是直观的。 “按证券计算的平均每日价格是多少?” 即使是简单的英语也是一个模棱两可的问题! 是每个证券每天的平均股价,还是每天证券的平均股价?
业务问题不会以数据库逻辑或程序代码的形式出现。 相反,它们是使用自然语言制定的,必须将其翻译为数据语言 。 作为数据分析人员,您必须澄清:“ 我们究竟取平均值是多少? ”在折叠,分组和观察键方面进行思考非常有帮助,尤其是在概念化分母中有多少观察值时。
这个问题不仅限于SQL,而是关系数据的任何存储,例如pandas.DataFrames或R数据表。 而且,如果您像我一样,会仔细研究一下旧代码grepping的平均值,并想知道:“我到底在这里平均什么?”
该文件最初发布在alexpetralia.com上,并经许可转载。
要了解更多信息 ,请在PyCon Cleveland 2018上参加Alex Petralia的演讲`` 分析数据:熊猫和SQL教给我的关于如何进行平均计算的知识'' 。
翻译自: https://opensource.com/article/18/4/analyzing-data-python
python熊猫图案
python熊猫图案_熊猫Python数据分析库和SQL教会了我如何取平均数相关推荐
- python熊猫图案_熊猫备忘单–适用于数据科学的Python
python熊猫图案 Pandas is arguably the most important Python package for data science. Not only does it g ...
- 用python绘制熊猫图案_利用Python进行数据分析_Pandas_绘图和可视化_Matplotlib
1 认识Figure和Subplot import matplotlib.pyplot as plt matplotlib的图像都位于Figure对象中 fg = plt.figure() 通过add ...
- 用python绘制熊猫图案_在python中绘制熊猫系列的CDF
Is there a way to do this? I cannot seem an easy way to interface pandas series with plotting a CDF. ...
- 用python绘制熊猫图案_在python中绘制大熊猫系列的CDF
我相信你正在寻找的功能是在一个系列对象的hist方法中,它将hist()函数包装在matplotlib中 以下是相关文档 In [10]: import matplotlib.pyplot as pl ...
- python 交互式流程图_使用Python创建漂亮的交互式和弦图
python 交互式流程图 Python中的数据可视化 (Data Visualization in Python) R vs Python is a constant tussle when it ...
- 熊猫分发_熊猫新手:第一部分
熊猫分发 For those just starting out in data science, the Python programming language is a pre-requisite ...
- python 网页编程_通过Python编程检索网页
python 网页编程 The internet and the World Wide Web (WWW), is probably the most prominent source of info ...
- python 时间序列预测_使用Python进行动手时间序列预测
python 时间序列预测 Time series analysis is the endeavor of extracting meaningful summary and statistical ...
- 熊猫数据集_熊猫迈向数据科学的第一步
熊猫数据集 I started learning Data Science like everyone else by creating my first model using some machi ...
最新文章
- 【错误记录】Google Play 上架报错 ( APK 大小 | 目标 API 级别 | Google Play 帮助文档 )
- 相似三角形_JAVA
- c++大文本比较_Excel – 将文本转换为数值,第二种方法会的请举左手
- MyBatis-Plus逆向工程——Generator
- 新漏洞可导致攻击者劫持Kindle
- mysql没有卸载干净服务还启动着,MySQL卸载不干净,真的让人很头大
- 视频教程-2020年软考网络规划设计师论文写作历年真题详解软考视频教程-软考
- Mysql全国省区县地区码
- .lnk 文件恢复默认打开方式
- open用法 vba_open方法读写文件
- android恢复出厂设置流程
- Python——通过while、for、if—else完成一个地铁乘车消费计算器
- 广度优先搜索——动态类迷宫问题
- MongoDB分组取每组中一条数据
- 获取当前系统时间(三种方法)
- Trac中的Ticket系统
- 华熙LIVE·五棵松再添新地标,北京市新能源汽车旗舰体验中心正式落户!
- sssdeeeeeeeeeeeee
- 关于计算机重新启动处于挂起状态的问题解决
- Squid TCP_MISS/000 的意义