Caffe 的深度学习训练全过程
本文为大数据杂谈 4 月 20 日微信社群分享内容整理。
今天的目标是使用 Caffe 完成深度学习训练的全过程。Caffe 是一款十分知名的深度学习框架,由加州大学伯克利分校的贾扬清博士于 2013 年在 Github 上发布。自那时起,Caffe 在研究界和工业界都受到了极大的关注。Caffe 的使用比较简单,代码易于扩展,运行速度得到了工业界的认可,同时还有十分成熟的社区。
对于刚开始学习深度学习的同学来说,Caffe 是一款十分十分适合的开源框架。可其他同类型的框架,它又一个最大的特点,就是代码和框架比较简单,适合深入了解分析。今天将要介绍的内容都是 Caffe 中成型很久的内容,如今绝大多数版本的 Caffe 都包含这些功能。关于 Caffe 下载和安装的内容请各位根据官方网站指导进行下载和安装,这里就不再赘述了。
一个常规的监督学习任务主要包含训练与预测两个大的步骤,这里还是以 Caffe 中自带的例子——MNIST 数据集手写数字识别为例,来介绍一下它具体的使用方法。
如果把上面提到的深度学习训练步骤分解得更细致一些,那么这个常规流程将分成这几个子步骤:
- 数据预处理(建立数据库)
- 网络结构与模型训练的配置
- 训练与在训练
- 训练日志分析
- 预测检验与分析
- 性能测试
下面就来一一介绍。
1 数据预处理
首先是训练数据和预测数据的预处理。这里的工作一般是把待分析识别的图像进行简单的预处理,然后保存到数据库中。为什么要完成这一步而不是直接从图像文件中读取数据呢?因为实际任务中训练数据的数量可能非常大,从图像文件中读取数据并进行初始化的效率是非常低的,所以很有必要把数据预先保存在数据库中,来加快训练的节奏。
以下的操作将全部在终端完成。第一步是将数据下载到本地,好在 MNIST 的数据量不算大,如果大家的网络环境好,这一步的速度会非常快。首先来到 caffe 的安装根目录——CAFFE_HOME,然后执行下面的命令:
cd data/mnist ./get_mnist.sh
程序执行完成后,文件夹下应该会多出来四个文件,这四个文件就是我们下载的数据文件。第二步我们需要调用 example 中的数据库创建程序:
cd $CAFFE_HOME ./examples/mnist/create_mnist.sh
程序执行完成后,examples/mnist 文件夹下面就会多出两个文件夹,分别保存了 MNIST 的训练和测试数据。值得一提的是,数据库的格式可以通过修改脚本的 BACKEND 变量来更换。目前数据库有两种主流选择:
- LevelDB
- LmDB
这两种数据库在存储数据和操纵上有一些不同,首先是它们的数据组织方式不同,这是 LevelDB 的内容:

这是 LMDB 的内容:

从结构可以看出 LevelDB 的文件比较多,LMDB 的文件更为紧凑。
其次是它们的读取数据的接口,某些场景需要遍历数据库完成一些原始图像的分析处理,因此了解它们的数据读取方法也十分有必要。首先是 LMDB 读取数据的代码:

其次是 LevelDB 读取的代码:
最后回到本小节的问题:为什么要采用数据库的方式存储数据而不是直接读取图像?这里可以简单测试一下用 MNIST 数据构建的这两个数据库按序读取的速度,这里用系统函数 time 进行计时,结果如下:
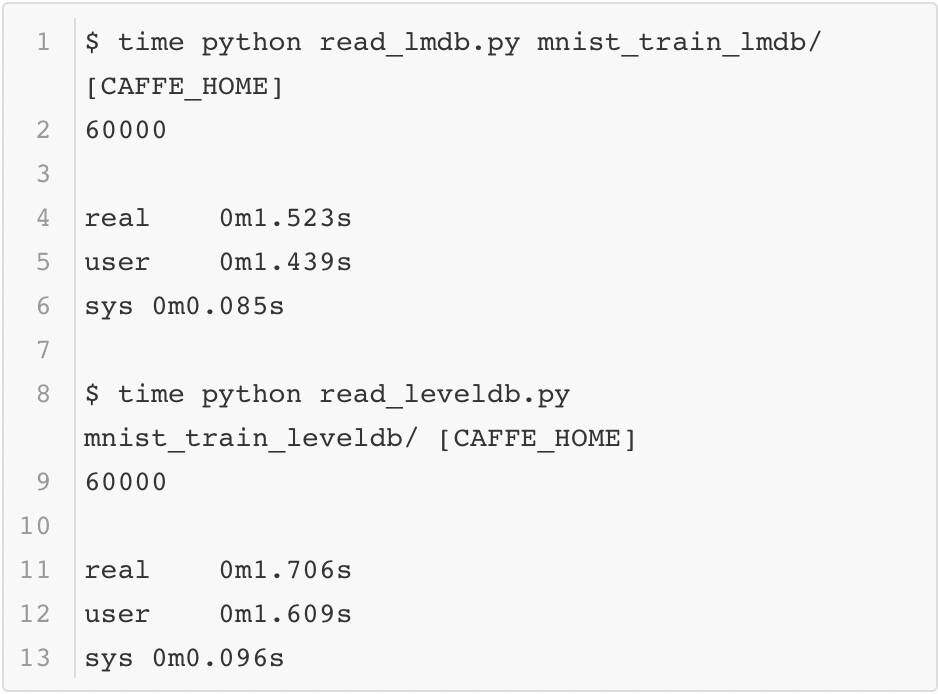
为了比较原始图像读入的速度,这里将 MNIST 的数据以 jpeg 的格式保存成图像,并测试它的读取效率(以 Caffe python 使用的 scikit image 为例),代码如下所示:
最终的时间如下所示:

由此可以看出,原始图像和数据库相比,读取数据的效率差距还是蛮大的。虽然在 Caffe 训练中数据读入是异步完成的,但是它还是不能够太慢,所以这也是在训练时选择数据库的原因。
至于这两个数据库之间的比较,这里就不再多做了。感兴趣的各位可以在一些大型的数据集上做一些实验,那样更容易看出两个数据集之间的区别。
2 网络结构与模型训练的配置
上一节完成了数据库的创建,下面就要为训练模型做准备了。一般来说 Caffe 采用读入配置文件的方式进行训练。Caffe 的配置文件一般由两部分组成:solver.prototxt 和 net.prototxt(有时会有多个 net.prototxt)。它们实际上对应了 Caffe 系统架构中两个十分关键的实体——网络结构 Net 和求解器 Solver。先来看看一般来说相对简短的 solver.prototxt 的内容,为了方便大家理解,所有配置信息都已经加入了注释:

为了方便大家理解,这里将 examples/mnist/lenet_solver.prototxt 中的内容进行重新排序,整个配置文件相当于回答了下面几个问题:
- 网络结构的文件在哪?
- 用什么计算资源训练?CPU 还是 GPU?
- 训练多久?训练和测试的比例是如何安排的,什么时候输出些给我们瞧瞧?
- 优化的学习率怎么设定?还有其他的优化参数——如动量和正则呢?
- 要时刻记得存档啊,不然大侠得从头来过了……
接下来就是 net.prototxt 了,这里忽略了每个网络层的参数配置,只把表示网络的基本结构和类型配置展示出来:
name: "LeNet"
layer {name: "mnist" type: "Data" top: "data" top: "label"
}
layer {name: "conv1" type: "Convolution" bottom: "data" top: "conv1"
}
layer {name: "pool1"type: "Pooling"bottom: "conv1"top: "pool1"
}
layer {name: "conv2"type: "Convolution"bottom: "pool1"top: "conv2"
}
layer {name: "pool2"type: "Pooling"bottom: "conv2"top: "pool2"
}
layer {name: "ip1"type: "InnerProduct"bottom: "pool2"top: "ip1"
}
layer {name: "relu1"type: "ReLU"bottom: "ip1"top: "ip1"
}
layer {name: "ip2"type: "InnerProduct"bottom: "ip1"top: "ip2"
}
layer {name: "loss"type: "SoftmaxWithLoss"bottom: "ip2"bottom: "label"top: "loss"
}
这里只展示了网络结构的基础配置,也占用了大量的篇幅。一般来说,这个文件中的内容超过 100 行都是再常见不过的事。而像大名鼎鼎的 ResNet 网络,它的文件长度通常在千行以上,更是让人难以阅读。那么问题来了,那么大的网络文件都是靠人直接编辑出来的么?不一定。有的人会比较有耐心地一点点写完,而有的人则不会愿意做这样的苦力活。实际上 Caffe 提供了一套接口,大家可以通过写代码的形式生成这个文件。这样一来,编写模型配置的工作也变得简单不少。下面展示了一段生成 LeNet 网络结构的代码:


最终生成的结果大家都熟知,这里就不给出了。
layer {name: "data"type: "Data"top: "data"top: "label"transform_param {scale: 0.00390625mirror: false}data_param {source: "123"batch_size: 128backend: LMDB}
}
layer {name: "conv1"type: "Convolution"bottom: "data"top: "conv1"convolution_param {num_output: 20kernel_size: 5stride: 1weight_filler {type: "xavier"}bias_filler {type: "constant"}}
}
layer {name: "pool1"type: "Pooling"bottom: "conv1"top: "pool1"pooling_param {pool: MAXkernel_size: 2stride: 2}
}
layer {name: "conv2"type: "Convolution"bottom: "pool1"top: "conv2"convolution_param {num_output: 50kernel_size: 5stride: 1weight_filler {type: "xavier"}bias_filler {type: "constant"}}
}
layer {name: "pool2"type: "Pooling"bottom: "conv2"top: "pool2"pooling_param {pool: MAXkernel_size: 2stride: 2}
}
layer {name: "ip1"type: "InnerProduct"bottom: "pool2"top: "ip1"inner_product_param {num_output: 500weight_filler {type: "xavier"}bias_filler {type: "constant"}}
}
layer {name: "relu1"type: "ReLU"bottom: "ip1"top: "ip1"
}
layer {name: "ip2"type: "InnerProduct"bottom: "ip1"top: "ip2"inner_product_param {num_output: 10weight_filler {type: "xavier"}bias_filler {type: "constant"}}
}
layer {name: "loss"type: "SoftmaxWithLoss"bottom: "ip2"bottom: "label"top: "loss"
}
大家可能觉得上面的代码并没有节省太多篇幅,实际上如果将上面的代码模块化做得更好些,它就会变得非常简洁。这里就不做演示了,欢迎大家自行尝试。
3 训练与再训练
准备好了数据,也确定了训练相关的配置,下面正式开始训练。训练需要启动这个脚本:

然后经过一段时间的训练,命令行产生了大量日志,训练过程也宣告完成。这时训练好的模型目录多出了这几个文件:

很显然,这几个文件保存了训练过程中的一些内容,那么它们都是做什么的呢?*caffemodel* 文件保存了 caffe 模型中的参数,*solverstate* 文件保存了训练过程中的一些中间结果。保存参数这件事情很容易想象,但是保存训练中的中间结果就有些抽象了。solverstate 里面究竟保存了什么?回答这个问题就需要找到 solverstate 的内容定义,这个定义来自 src/caffe/proto/caffe.proto 文件:

从定义中可以很清楚的看出其内容的含义。其中 history 是一个比较有意思的信息,他存储了历史的参数优化信息。这个信息有什么作用呢?由于很多算法都依赖历史更新信息,如果有一个模型训练了一半停止了下来,现在想基于之前训练的成果继续训练,那么需要历史的优化信息帮助继续训练。如果模型训练突然中断训练而历史信息又丢失了,那么模型只能从头训练。这样的深度学习框架就不具备“断点训练”的功能了,只有"重头再来"的功能。现在的大型深度学习模型都需要很长的时间训练,有的需要训练好几天,如果框架不提供断点训练的功能,一旦机器出现问题导致程序崩溃,模型就不得不重头开始训练,这会对工程师的身心造成巨大打击……所以这个存档机制极大地提高了模型训练的可靠性。
从另一个方面考虑,如果模型训练彻底结束,这些历史信息就变得无用了。caffemodel 文件需要保存下来,而 solverstate 这个文件可以被直接丢弃。因此这种分离存储的方式特别方便操作。
从刚才提到的“断点训练”可以看出,深度学习其实包含了“再训练”这个概念。一般来说“再训练”包含两种模式,其中一种就是上面提到的“断点训练”。从前面的配置文件中可以看出,训练的总迭代轮数是 10000 轮,每训练 5000 轮,模型就会被保存一次。如果模型在训练的过程中被一些不可抗力打断了(比方说机器断电了),那么大家可以从 5000 轮迭代时保存的模型和历史更新参数恢复出来,命令如下所示:

这里不妨再深入一点分析。虽然模型的历史更新信息被保存了下来,但当时的训练场景真的被完全恢复了么?似乎没有,还有一个影响训练的关键因素没有恢复——数据,这个是不容易被训练过程精确控制的。也就是说,首次训练时第 5001 轮迭代训练的数据和现在“断点训练”的数据是不一样的。但是一般来说,只要保证每个训练批次(batch)内数据的分布相近,不会有太大的差异,两种训练都可以朝着正确的方向前进,其中存在的微小差距可以忽略不计。
第二种“再训练”的方式则是有理论基础支撑的训练模式。这个模式会在之前训练的基础上,对模型结构做一定的修改,然后应用到其他的模型中。这种学习方式被称作迁移学习(Transfer Learning)。这里举一个简单的例子,在当前模型训练完成之后,模型参数将被直接赋值到一个新的模型上,然后让这个新模型重头开始训练。这个操作可以通过下面这个命令完成:

执行命令后 Caffe 会像往常一样开始训练并输出大量日志,但是在完成初始化之后,它会输出这样一条日志:

这条日志就是在告诉我们,当前的训练是在这个路径下的模型上进行"Finetune"。
4 训练日志分析
训练过程中 Caffe 产生了大量的日志,这些日志包含很多训练过程的信息,非常很值得分析。分析的内容有很多,其中之一就是分析训练过程中目标函数 loss 的变化曲线。在这个例子中,可以分析随着迭代轮数不断增加,Softmax Loss 的变化情况。首先将训练过程的日志信息保存下来,比方说日志信息被保存到 mnist.log 文件中,然后用下面的命令可以将 Iteration 和 Loss 的信息提取并保存下来:

提取后的信息可以用另一个脚本完成 Loss 曲线的绘图工作:
import matplotlib.pyplot as plt
x = []
y = []
with open('loss_data') as f:for line in f:sps = line[:-1].split()x.append(int(sps[0]))y.append(float(sps[1]))
plt.plot(x,y)
plt.show()
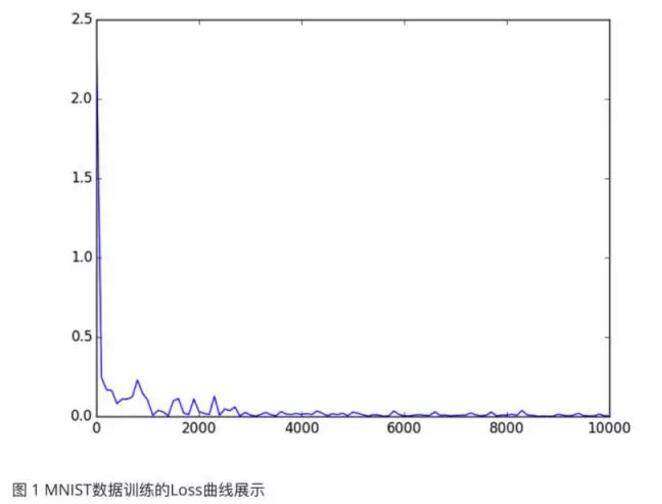
结果如图 1 所示,可见 Loss 很快就降到了很低的地方,模型的训练速度很快。这个优异的表现可以说明很多问题,但这里就不做过多地分析了。
除此之外,日志中输出的其他信息也可以被观察分析,比方说测试环节的精确度等,它们也可以通过上面的方法解析出来。由于采用的方法基本相同,这里有不去赘述了,各位可以自行尝试。
正常训练过程中,日志里只会显示每一组迭代后模型训练的整体信息,如果想要了解更多详细的信息,就要将 solver.prototxt 中的调试信息打开,这样就可以获得更多有用的信息供大家分析:
debug_info:true
调试信息打开后,每一组迭代后每一层网络的前向后向计算过程中的详细信息都可以被观测到。这里截取其中一组迭代后的日志信息展示出来:
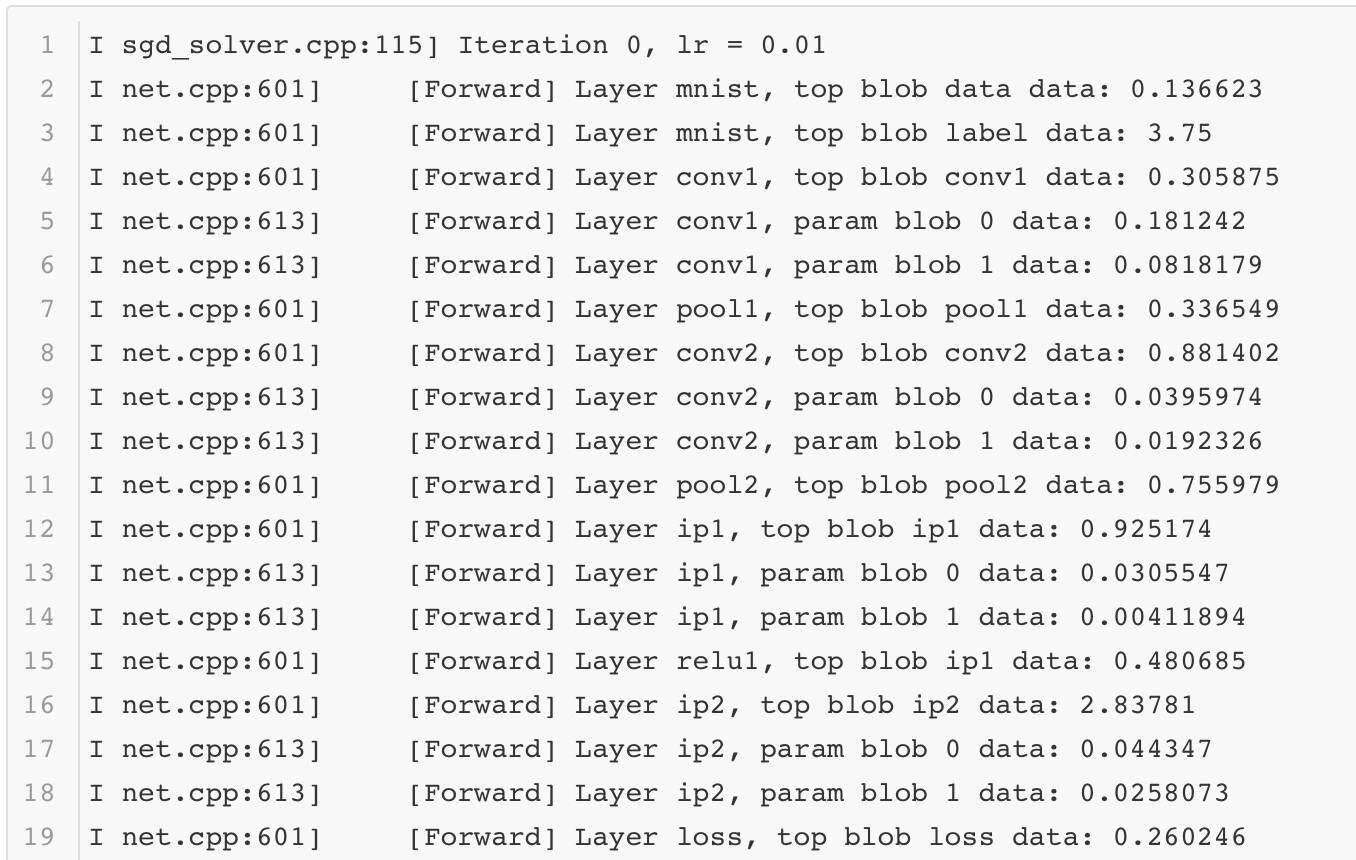

如果想要对网络的表现做更多地了解,那么分析这些内容必不可少。
5 预测检验与分析
模型完成训练后,就要对它的训练表现做验证,看看它在其他测试数据集上的正确性。Caffe 提供了另外一个功能用于输出测试的结果。以下就是它的脚本:

脚本的输出结果如下所示:

除了完成测试的验证,有时大家还需要知道模型更多的运算细节,这就需要深入模型内部去观察模型产生的中间结果。使用 Caffe 提供的借口,每一层网络输出的中间结果都可以用可视化的方法显示出来,供大家观测、分析模型每一层的作用。其中的代码如下所示:
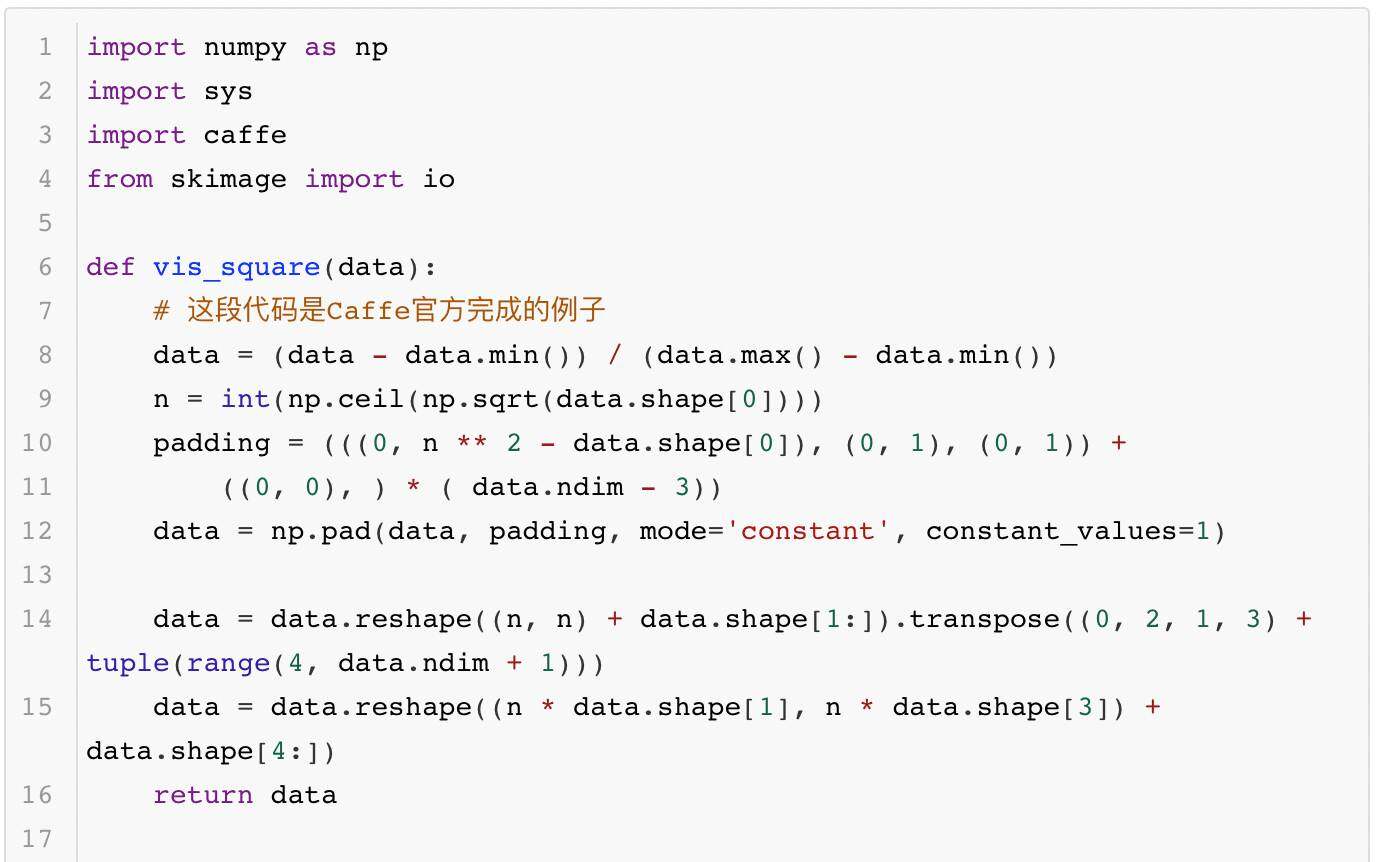

执行上面的代码就可以生成如图 2 到图 5 这几张图像,它们各代表一个模型层的输出图像:




这一组图展示了卷积神经网络是如何把一个数字转变成特征编码的。这样的方法虽然可以很好地看到模型内部的表现,比方说 conv1 的结果图中有的提取了数字的边界,有的明确了前景像素所在的位置,这个现象和第 3 章中举例的卷积效果有几分相似。但是到了 conv2 的结果图中,模型的输出就变得让人有些看不懂了。实际上想要真正看懂这些图像想表达的内容确实有些困难的。
6 性能测试
除了在测试数据上的准确率,模型的运行时间也非常值得关心。如果模型的运行时间太长,甚至到了不可用的程度,那么即使它精度很高也没有实际意义。测试时间的脚本如下所示:

Caffe 会正常的完成前向后向的计算,并记录其中的时间。以下是使一次测试结果的时间记录:
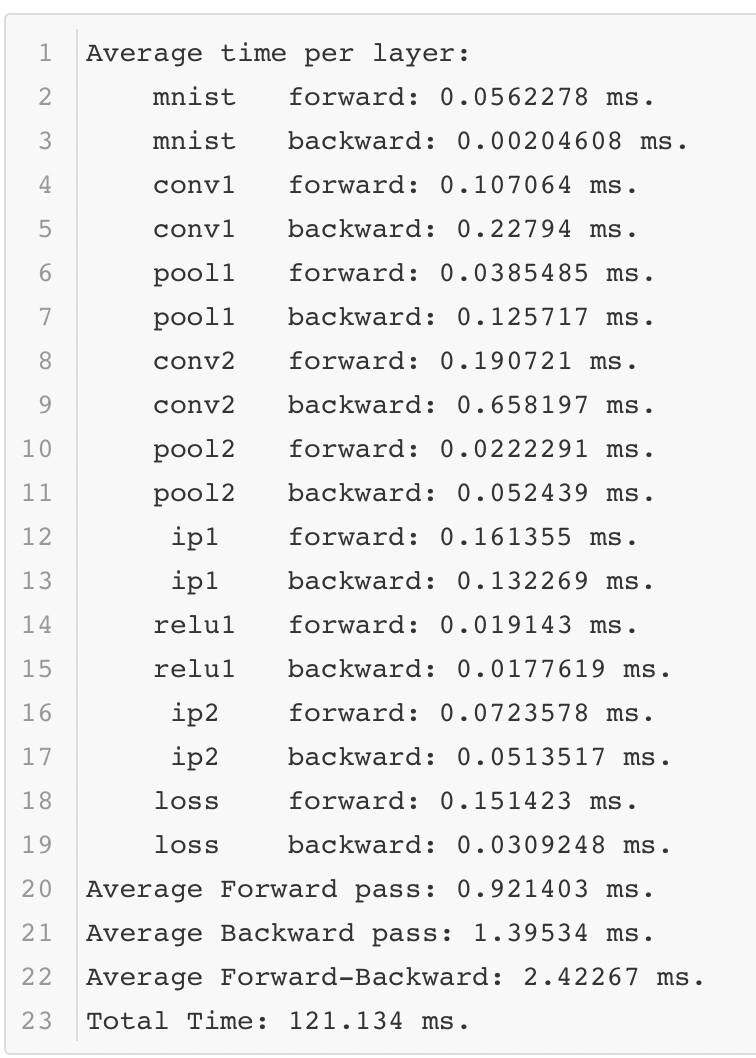
可以看出在性能测试的过程中,Lenet 模型只需要不到 1 毫秒的时间就可以完成前向计算,这个速度还是很快的。当然这是在一个相对不错的 GPU 上运行的,那么如果在一个条件差的 GPU 上运行,结果如何呢?
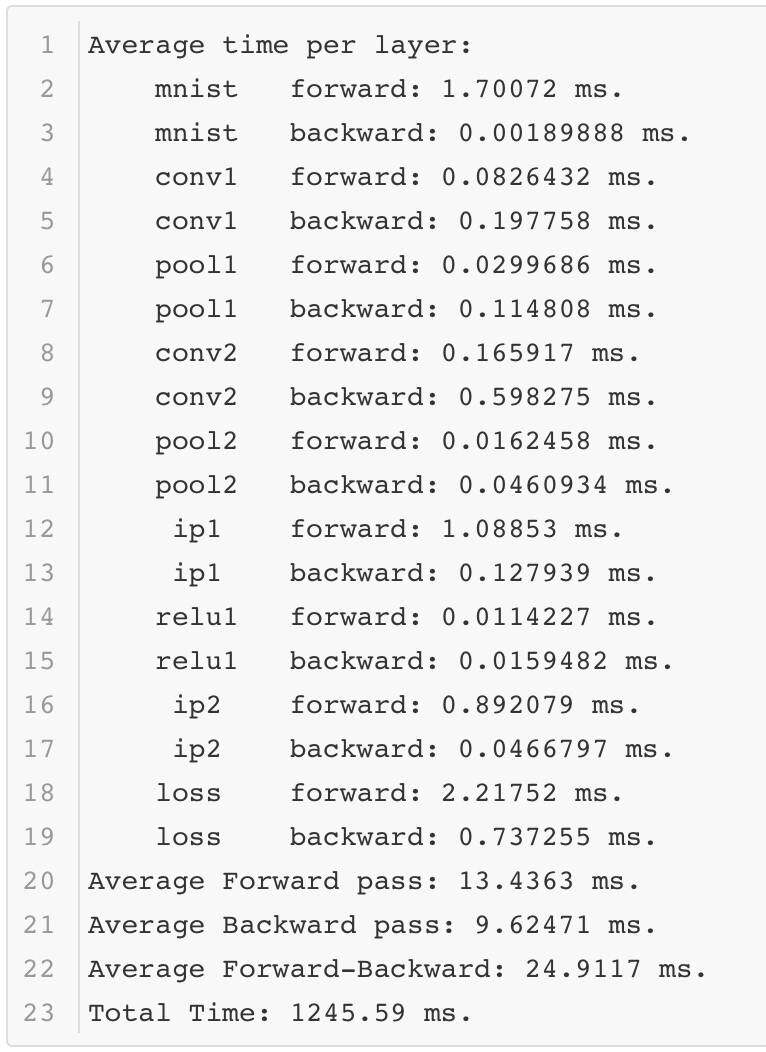
可以看到不同的环境对于模型运行的时间影响很大。
以上就是模型训练的一个完整过程。现在相信大家对深度学习模型的训练和使用有了基本的了解。实际上看到这里大家甚至可以扔下书去亲自实践不同模型的效果,开始深度学习的实战之旅。
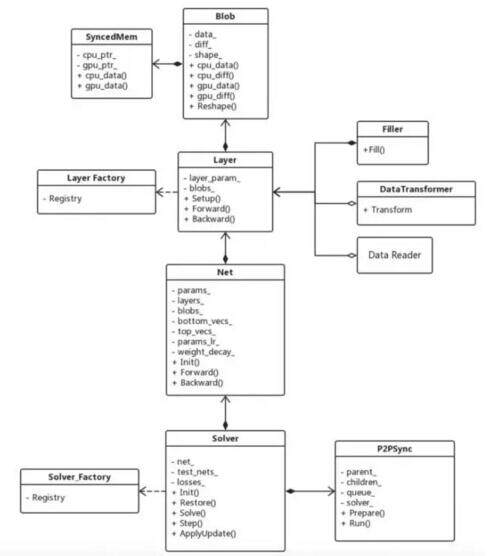
最后放一张 Caffe 源代码的架构图,以方便大家研究 Caffe 源码。
(点击放大图像)
答疑环节
Q1. Caffe 和其他深度学习框度 (如 MxNet, Tensorflow 等) 比有什么优缺点?
冯超:Caffe 作为“老一代”的深度学习框架,从架构上来说有一个很大的不同之处,那就是它不是采用符号运算的方式进行设计的,这样带来了一些优点和缺点。
优点是 Caffe 在计算过程中,在内存使用和运算速度方面都有一定的优势,内存使用较小,速度也比较有保证,相对而言,基于符号计算的框架在这两方面会稍弱一些。
缺点是 Caffe 模型灵活性较弱。对于一些新出现的网络模型结构,Caffe 适配起来需要一些技巧,需要一定的经验,而 MXNet,TensorFlow 这样的模型就简单很多。
所以一般来说,MXNet、Tensorflow 更适合实验环境,Caffe 比较适合工业界线上使用。其他方面,现在 Caffe 的社区相比 Tensorflow 可能要弱些,但依然是非常主流的开源框架。
Q2. 如何看待 facebook 新发布的 caffe2 深度学习框架?它比现有的 caffe 有什么样的改进?跟现在的 TensorFlow 相比如何?
冯超:caffe2 最近比较热,之前我没有多看过,这两天集中看了看,大概有以下一些感受:
有了 Caffe2 和 Caffe 相比变化大么?prototxt 和 caffemodel 海斗可以用,基本上算向下兼容,Caffe 的一些知识技能还可以用。
Caffe2 的操作方式?从官方文档中看,Caffe2 的 python 接口有了很大的进步。给出的示例主要是用 python 代码描述网络结构(和 tf 很像,也有 checkpoint 等概念)-> 生成内存版的网络模型 -> 构建 net 和相关环境 -> 执行代码,所以除了前面的 python 接口,后面的流程和 caffe1 很像。
内部架构上的变化?Caffe2 借鉴了 Tensorflow 的一些概念,将过去的 Net 拆成两部分:数据和网络图。数据部分是 Workspace,和 tf 的 session 很像,另外一部分是网络图 net。另外,Caffe2 内部也将 Layer 改成了 Op。
现在就上手 Caffe2?几乎有点早,目前官方给出的内容还比较少,大家也不必太心急。
最后说说 Caffe2 官方给出的一些亮点功能:跨平台。这一次的 Caffe2 可以在各种不同的平台上部署运行,这算是一个亮点。
Q3. caffee 和 pytorch 都是 facebook 在推,那这两个框架有什么不同呢?
冯超:基本上实验环境下主要用 pytorch, 线上环境用 Caffe。
Q4. caffe 有没有提供一些 preTraining 的一些模型 方便更快地调用网络呢?
冯超:Caffe 有自己的Model zoo,详情可以上去看一看。
Q5. caffe 在移动端实践的实际案例吗?
冯超:就我身边有限的了解,一些公司做移动端尝试还是使用了 Tensorflow,并没有用 Caffe。
作者介绍
冯超,毕业于中国科学院大学,现就职于猿辅导公司,从事视觉与深度学习的应用研究工作。自 2016 年起在知乎开设了自己的专栏——《无痛的机器学习》,发表一些机器学习和深度学习的文章,收到了不错的反响。
感谢杜小芳对本文的审校。
给 InfoQ 中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号:InfoQChina)关注我们。
Caffe 的深度学习训练全过程相关推荐
- Caffe的深度学习训练全过程
转载自:http://www.infoq.com/cn/articles/whole-process-of-caffe-depth-learning-training 今天的目标是使用Caffe完成深 ...
- 2021-04-17 安装Ubuntu18.0.4 的深度学习训练服务器
序言: 过去安装系统,总是从互联网看看别人如何装,照猫画虎就稀里糊涂地装上了.但是并不知道版本之间的关系,以至于下次安装依然临时拍脑决定,这样安装的坏处是,以后运行时可能遇到莫名的错误.如今安装服务器 ...
- MLPerf结果证实至强® 可有效助力深度学习训练
MLPerf结果证实至强® 可有效助力深度学习训练 · 核心与视觉计算事业部副总裁Wei Li通过博客回顾了英特尔这几年为提升深度学习性能所做的努力. · 目前根据英特尔® 至强® 可扩展处理器的ML ...
- 最全深度学习训练过程可视化工具(附github源码)
点击上方"AI遇见机器学习",选择"星标"公众号 重磅干货,第一时间送达 Datawhale干货 作者:Edison_G,来源:计算机视觉研究院 编辑丨极市平台 ...
- 今日上午,清华大学发布中国首个高校自研深度学习训练框架—计图Jittor
在百度狂推PaddlePaddle框架,以及旷视计划本月25日发布自研深度学习训练框架MegEngine之际,清华大学突然发布首个中国高校自研深度学习框架Jittor,中文名为计图. 官网链接 htt ...
- 的训练过程_最全深度学习训练过程可视化工具(附github源码)
点击上方"AI遇见机器学习",选择"星标"公众号 重磅干货,第一时间送达 Datawhale干货 作者:Edison_G,来源:计算机视觉研究院编辑丨极市平台. ...
- 基于AI的计算机视觉识别在Java项目中的使用(三) —— 搭建基于Docker的深度学习训练环境
深度学习在哪里? 我们已然生活在数字时代,一天24小时我们被数字包围.我们生活中的方方面面都在使用数字来表达.传递.存储.我们无时无刻不在接收数字信息,而又无时无刻不在生产数字信息. 在数字世界中,可 ...
- Darknet 轻量级深度学习训练框架
Darkent是个轻量级深度学习训练框架,用c和cuda编写,支持GPU加速.你可以理解为darknet和tensorflow, pytorch, caffe, mxnet一样,是用于跑模型的底层 y ...
- 不止GPU!这些硬件也影响着深度学习训练速度
有志于投身人工智能研究的青年,在关注计算机专业选择时,也不妨先了解一下影响深度学习训练速度的种种因素. 本文实验数据来源:知乎@Justin ho 工程师之于计算机就相当于赛车手对待跑车一样,必须十分 ...
- Centos集成GTX-1080Ti显卡搭建深度学习环境全过程
Centos集成GTX-1080Ti显卡搭建深度学习环境全过程 在一个由N多台普通的不能再普通的机器攒凑起来的机箱中,搭载了最强核心--NVIDIA GeForce GTX 1080 Ti.我们的深度 ...
最新文章
- Windows恶意软件API调用特征分析
- NSArray利用Cocoa框架进行汉字排序
- java之面向对象知识体系_JAVA基础知识总结5(面向对象特征之一:继承)
- 全球及中国增强现实产业战略布局及运营前景决策分析报告2021-2027年
- 035-OpenStack 关闭安全组
- Vue自定义指令原来这么简单
- c 调用matlab文件路径,C/C++下调用matlab函数操作说明
- jmeter提取mysql返回值_jmeter连接数据库和提取数据库返回值
- php能开发管理系统吗,PHP《个人管理系统》希望大家一起来开发
- SQL STUFF用法很有趣的语法
- css 列表属性详细总结
- python实现对解析之后的DOM进行层次化处理升序输出
- matlab z统计量,z统计量(z统计量与t统计量)
- linux 检测screen,linux screen编程,自动监控并向screen发送命令
- java怎么使用mfc,调用mfc方法
- python的selenium的带https安全隐私问题解决方案
- C++和java的区别和联系
- Linux 的父进程和子进程的执行情况(附有案例代码)
- 【递推】HDU -2018 母牛的故事斐波那契兔子数列
- 用理想低通滤波器在频率域实现低通滤波、高通滤波。