[机器学习实战]决策树
1. 简介
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的凌乱程度,使用算法ID3, C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
决策树学习通常包括 3 个步骤:
- 特征选择
- 决策树的生成
- 决策树的修剪
1.1 决策树场景
场景一:二十个问题
有一个叫 “二十个问题” 的游戏,游戏规则很简单:参与游戏的一方在脑海中想某个事物,其他参与者向他提问,只允许提 20 个问题,问题的答案也只能用对或错回答。问问题的人通过推断分解,逐步缩小待猜测事物的范围,最后得到游戏的答案。
场景二:邮件分类
一个邮件分类系统,大致工作流程如下:
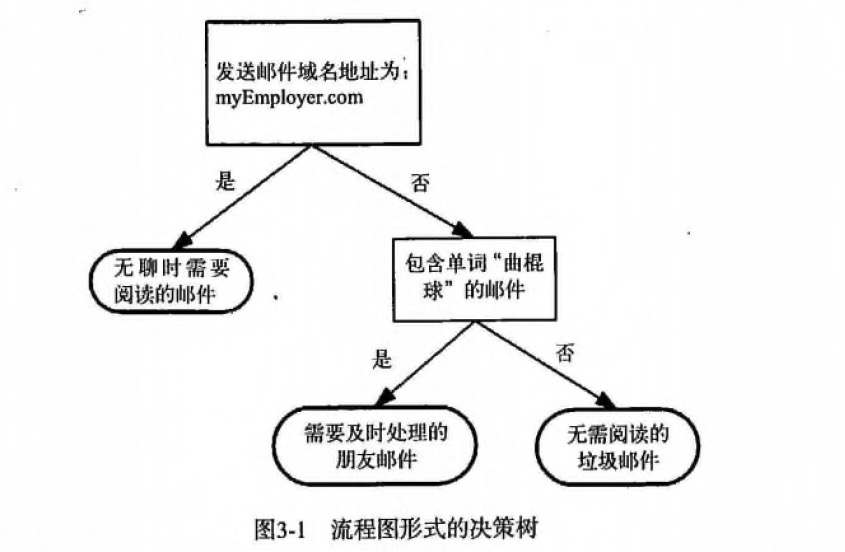
首先检测发送邮件域名地址。如果地址为 myEmployer.com, 则将其放在分类 "无聊时需要阅读的邮件"中。
如果邮件不是来自这个域名,则检测邮件内容里是否包含单词 "曲棍球" , 如果包含则将邮件归类到 "需要及时处理的朋友邮件",
如果不包含则将邮件归类到 "无需阅读的垃圾邮件" 。
1.2 定义
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点(node)和有向边(directed edge)组成。
结点有两种类型:
- 内部结点(internal node):表示一个特征或属性。
- 叶结点(leaf: node):表示一个类。
用决策树分类,从根节点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到其子结点;这时,每一个子结点对应着该特征的一个取值。如此递归地对实例进行测试并分配,直至达到叶结点。最后将实例分配到叶结点的类中。
2. 决策树原理
- 熵:
熵(entropy)指的是体系的混乱的程度,在不同的学科中也有引申出的更为具体的定义,是各领域十分重要的参量。 信息熵(香农熵):
是一种信息的度量方式,表示信息的混乱程度,也就是说:信息越有序,信息熵越低。例如:火柴有序放在火柴盒里,熵值很低,相反,熵值很高。信息增益:
在划分数据集前后信息发生的变化称为信息增益。
2.1 工作原理
我们使用 createBranch() 方法构造一个决策树,如下所示:
检测数据集中的所有数据的分类标签是否相同:If so return 类标签Else:寻找划分数据集的最好特征(划分之后信息熵最小,也就是信息增益最大的特征)划分数据集创建分支节点for 每个划分的子集调用函数 createBranch (创建分支的函数)并增加返回结果到分支节点中return 分支节点2.2 决策树开发流程
1. 收集数据:可以使用任何方法。
2. 准备数据:树构造算法只适用于标称型数据,因此数值型数据必须离散化。
3. 分析数据:可以使用任何方法,构造树完成之后,我们应该检查图形是否符合预期。
4. 训练算法:构造树的数据结构。
5. 测试算法:使用经验树计算错误率。(经验树没有搜索到较好的资料,有兴趣的同学可以来补充)
6. 使用算法:此步骤可以适用于任何监督学习算法,而使用决策树可以更好地理解数据的内在含义。2.3 决策树算法特点
- 优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。
- 缺点:可能会产生过度匹配问题。
适用数据类型:数值型和标称型。
3. 实战案例
3.1 项目概述
根据以下 2 个特征,将动物分成两类:鱼类和非鱼类。
特征:
- 不浮出水面是否可以生存
- 是否有脚蹼
3.2 开发流程
(1) 收集数据
可以使用任何方法

我们利用 createDataSet() 函数输入数据:
def createDataSet():dataSet = [[1, 1, 'yes'],[1, 1, 'yes'],[1, 0, 'no'],[0, 1, 'no'],[0, 1, 'no']]labels = ['no surfacing', 'flippers']return dataSet, labels(2) 准备数据
树构造算法只适用于标称型数据,因此数值型数据必须离散化
此处,由于我们输入的数据本身就是离散化数据,所以这一步就省略了。
(3) 分析数据
可以使用任何方法,构造树完成之后,我们应该检查图形是否符合预期

计算给定数据集的香农熵的函数
def calcShannonEnt(dataSet):# 求list的长度,表示计算参与训练的数据量numEntries = len(dataSet)# 计算分类标签label出现的次数labelCounts = {}# the the number of unique elements and their occurancefor featVec in dataSet:# 将当前实例的标签存储,即每一行数据的最后一个数据代表的是标签currentLabel = featVec[-1]# 为所有可能的分类创建字典,如果当前的键值不存在,则扩展字典并将当前键值加入字典。每个键值都记录了当前类别出现的次数。if currentLabel not in labelCounts.keys():labelCounts[currentLabel] = 0labelCounts[currentLabel] += 1# 对于 label 标签的占比,求出 label 标签的香农熵shannonEnt = 0.0for key in labelCounts:# 使用所有类标签的发生频率计算类别出现的概率。prob = float(labelCounts[key])/numEntries# 计算香农熵,以 2 为底求对数shannonEnt -= prob * log(prob, 2)return shannonEnt按照给定特征划分数据集
将指定特征的特征值等于 value 的行剩下列作为子数据集。
def splitDataSet(dataSet, index, value):"""splitDataSet(通过遍历dataSet数据集,求出index对应的colnum列的值为value的行)就是依据index列进行分类,如果index列的数据等于 value的时候,就要将 index 划分到我们创建的新的数据集中Args:dataSet 数据集 待划分的数据集index 表示每一行的index列 划分数据集的特征value 表示index列对应的value值 需要返回的特征的值。Returns:index列为value的数据集【该数据集需要排除index列】"""retDataSet = []for featVec in dataSet: # index列为value的数据集【该数据集需要排除index列】# 判断index列的值是否为valueif featVec[index] == value:# chop out index used for splitting# [:index]表示前index行,即若 index 为2,就是取 featVec 的前 index 行reducedFeatVec = featVec[:index]'''请百度查询一下: extend和append的区别list.append(object) 向列表中添加一个对象objectlist.extend(sequence) 把一个序列seq的内容添加到列表中1、使用append的时候,是将new_media看作一个对象,整体打包添加到music_media对象中。2、使用extend的时候,是将new_media看作一个序列,将这个序列和music_media序列合并,并放在其后面。result = []result.extend([1,2,3])print resultresult.append([4,5,6])print resultresult.extend([7,8,9])print result结果:[1, 2, 3][1, 2, 3, [4, 5, 6]][1, 2, 3, [4, 5, 6], 7, 8, 9]'''reducedFeatVec.extend(featVec[index+1:])# [index+1:]表示从跳过 index 的 index+1行,取接下来的数据# 收集结果值 index列为value的行【该行需要排除index列】retDataSet.append(reducedFeatVec)return retDataSet选择最好的数据集划分方式
def chooseBestFeatureToSplit(dataSet):"""chooseBestFeatureToSplit(选择最好的特征)Args:dataSet 数据集Returns:bestFeature 最优的特征列"""# 求第一行有多少列的 Feature, 最后一列是label列嘛numFeatures = len(dataSet[0]) - 1# 数据集的原始信息熵baseEntropy = calcShannonEnt(dataSet)# 最优的信息增益值, 和最优的Featurn编号bestInfoGain, bestFeature = 0.0, -1# iterate over all the featuresfor i in range(numFeatures):# create a list of all the examples of this feature# 获取对应的feature下的所有数据featList = [example[i] for example in dataSet]# get a set of unique values# 获取剔重后的集合,使用set对list数据进行去重uniqueVals = set(featList)# 创建一个临时的信息熵newEntropy = 0.0# 遍历某一列的value集合,计算该列的信息熵 # 遍历当前特征中的所有唯一属性值,对每个唯一属性值划分一次数据集,计算数据集的新熵值,并对所有唯一特征值得到的熵求和。for value in uniqueVals:subDataSet = splitDataSet(dataSet, i, value)# 计算概率prob = len(subDataSet)/float(len(dataSet))# 计算信息熵newEntropy += prob * calcShannonEnt(subDataSet)# gain[信息增益]: 划分数据集前后的信息变化, 获取信息熵最大的值# 信息增益是熵的减少或者是数据无序度的减少。最后,比较所有特征中的信息增益,返回最好特征划分的索引值。infoGain = baseEntropy - newEntropyprint 'infoGain=', infoGain, 'bestFeature=', i, baseEntropy, newEntropyif (infoGain > bestInfoGain):bestInfoGain = infoGainbestFeature = ireturn bestFeature
Q:上面的 newEntropy 为什么是根据子集计算的呢?
A :因为我们在根据一个特征计算香农熵的时候,该特征的分类值是相同,这个特征这个分类的香农熵为 0;
这就是为什么计算新的香农熵的时候使用的是子集。
(4)训练算法
构造树的数据结构
创建树的函数代码如下:
def createTree(dataSet, labels):classList = [example[-1] for example in dataSet]# 如果数据集的最后一列的第一个值出现的次数=整个集合的数量,也就说只有一个类别,就只直接返回结果就行# 第一个停止条件:所有的类标签完全相同,则直接返回该类标签。# count() 函数是统计括号中的值在list中出现的次数if classList.count(classList[0]) == len(classList):return classList[0]# 如果数据集只有1列,那么最初出现label次数最多的一类,作为结果# 第二个停止条件:使用完了所有特征,仍然不能将数据集划分成仅包含唯一类别的分组。if len(dataSet[0]) == 1:return majorityCnt(classList)# 选择最优的列,得到最优列对应的label含义bestFeat = chooseBestFeatureToSplit(dataSet)# 获取label的名称bestFeatLabel = labels[bestFeat]# 初始化myTreemyTree = {bestFeatLabel: {}}# 注:labels列表是可变对象,在PYTHON函数中作为参数时传址引用,能够被全局修改# 所以这行代码导致函数外的同名变量被删除了元素,造成例句无法执行,提示'no surfacing' is not in listdel(labels[bestFeat])# 取出最优列,然后它的branch做分类featValues = [example[bestFeat] for example in dataSet]uniqueVals = set(featValues)for value in uniqueVals:# 求出剩余的标签labelsubLabels = labels[:]# 遍历当前选择特征包含的所有属性值,在每个数据集划分上递归调用函数createTree()myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)# print 'myTree', value, myTreereturn myTree(5)测试算法
使用决策树执行分类
代码如下:
def classify(inputTree, featLabels, testVec):"""classify(给输入的节点,进行分类)Args:inputTree 决策树模型featLabels Feature标签对应的名称testVec 测试输入的数据Returns:classLabel 分类的结果值,需要映射label才能知道名称"""# 获取tree的根节点对于的key值firstStr = inputTree.keys()[0]# 通过key得到根节点对应的valuesecondDict = inputTree[firstStr]# 判断根节点名称获取根节点在label中的先后顺序,这样就知道输入的testVec怎么开始对照树来做分类featIndex = featLabels.index(firstStr)# 测试数据,找到根节点对应的label位置,也就知道从输入的数据的第几位来开始分类key = testVec[featIndex]valueOfFeat = secondDict[key]print '+++', firstStr, 'xxx', secondDict, '---', key, '>>>', valueOfFeat# 判断分枝是否结束: 判断valueOfFeat是否是dict类型if isinstance(valueOfFeat, dict):classLabel = classify(valueOfFeat, featLabels, testVec)else:classLabel = valueOfFeatreturn classLabel(6)使用算法
此步骤可以适用于任何监督学习算法,而使用决策树可以更好地理解数据的内在含义。
构造决策树是很耗时的任务,即使很小的数据集也要花费几秒。如果用创建好的决策树解决分类问题就可以很快完成。
因此为了节省计算时间,最好能每次执行分类时调用已经构造好的决策树,为了解决这个问题,需要使用Python模块pickle序列化对象。序列化对象可以在磁盘上保存对象,并在需要的时候读取出来。任何对象都可以执行序列化,包括字典对象。
下面代码是使用pickle模块存储决策树:
def storeTree(inputTree, filename):impory picklefw = open(filename, 'w')pickle.dump(inputTree, fw)fw.close()def grabTree(filename):import picklefr = open(filename)return pickle.load(fr)通过上面的代码我们可以把分类器存储在硬盘上,而不用每次对数据分类时重新学习一遍,这也是决策树的优点之一。++K-近邻算法就无法持久化分类器++。
[1] 决策树维基百科: https://zh.wikipedia.org/wiki/%E5%86%B3%E7%AD%96%E6%A0%91
[2]《机器学习实战》 -- Peter Harrington
[3]《机器学习》 -- 周志华
[机器学习实战]决策树相关推荐
- 机器学习实战-决策树-22
机器学习实战-决策树-叶子分类 import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplo ...
- 机器学习实战 —— 决策树(完整代码)
声明: 此笔记是学习<机器学习实战> -- Peter Harrington 上的实例并结合西瓜书上的理论知识来完成,使用Python3 ,会与书上一些地方不一样. 机器学习实战-- 决策 ...
- [机器学习数据挖掘]机器学习实战决策树plotTree函数完全解析
[机器学习&数据挖掘]机器学习实战决策树plotTree函数完全解析 http://www.cnblogs.com/fantasy01/p/4595902.html点击打开链接 import ...
- 机器学习实战--决策树ID3的构建、画图与实例:预测隐形眼镜类型
声明 本文参考了<机器学习实战>书中代码,结合该书讲解,并加之自己的理解和阐述 机器学习实战系列博文 机器学习实战--k近邻算法改进约会网站的配对效果 机器学习实战--决策树的构建.画图与 ...
- python神经网络算法pdf_Python与机器学习实战 决策树、集成学习、支持向量机与神经网络算法详解及编程实现.pdf...
作 者 :何宇健 出版发行 : 北京:电子工业出版社 , 2017.06 ISBN号 :978-7-121-31720-0 页 数 : 315 原书定价 : 69.00 主题词 : 软件工具-程序设计 ...
- 机器学习实战——决策树:matplotlib绘图
书籍:<机器学习实战>中文版 IDE:PyCharm Edu 4.02 环境:Adaconda3 python3.6 第一个例子: import matplotlib.pyplot as ...
- 机器学习实战决策树画图理解
机器学习实战第二章决策树难点 第二章决策树用matplotlib画图的理解 决策树matplotlib画图代码 第二章决策树用matplotlib画图的理解 作为一个小白呢,确实对于我们来说第二章画图 ...
- 机器学习实战——决策树(代码)
最近在学习Peter Harrington的<机器学习实战>,代码与书中的略有不同,但可以顺利运行. from math import log import operator# 计算熵 d ...
- 机器学习实战-决策树(二)Python实现
转载请注明作者和出处: http://blog.csdn.net/c406495762 运行平台: Windows Python版本: Python3.x IDE: Sublime text3 一 前 ...
最新文章
- 大型技术网站的技术( 高并发、大数据、高可用、分布式....)(一)
- UPYUN的云CDN技术架构演进之路
- UM功能实现和配置技巧(上)--语音邮件、传真功能
- 云原生存储系列文章(一):云原生应用的基石
- linux编译ace,Linux下编译ACE
- 利用计算机窃听,observer模拟监听器的实现
- 使用javascript在客户端获取URL参数值的函数
- java 查看虚拟机状态_深入理解java虚拟机学习笔记(四)虚拟机性能监控与故障处理工具...
- 建自己的小屋真辛苦啊?!·##¥
- day17【前台】支付案例
- AVR系列之TWI功能测试
- TF-tf.keras.layers.Dropout
- HTML DOM nodeName nodeValue
- 小D课堂 - 新版本微服务springcloud+Docker教程_6-04 自定义Zuul过滤器实现登录
- java 万年历接口_农历计算,农历查询API接口,万年历农历查询,农历+禁忌查询 |在线免费 API...
- HTML5制作对联网页,经典的JS对联广告代码
- 百度有趣的面试智力题
- Postgresql模糊查询插件pg_bigm安装
- php博客平台 开源,PHP开源博客Blog - PHP开源网(PHP-OPEN.ORG)
- 剑英陪你玩转图形学(五)focus