QA问答系统中的深度学习技术实现
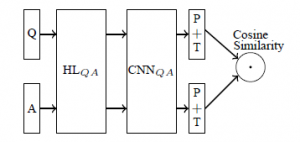
- Qp:[batch_size, sequence_len],Qp是Q之前的一个表示(在上图中没有画出)。所有句子需要截断或padding到一个固定长度(因为后面的CNN一般是处理固定长度的矩阵),例如句子包含3个字ABC,我们选择固定长度sequence_len为100,则需要将这个句子padding成ABC<a><a>…<a>(100个字),其中的<a>就是添加的专门用于padding的无意义的符号。训练时都是做mini-batch的,所以这里是一个batch_size行的矩阵,每行是一个句子。
- Q:[batch_size, sequence_len, embedding_size]。句子中的每个字都需要转换成对应的字向量,字向量的维度大小是embedding_size,这样Qp就从一个2维的矩阵变成了3维的Q
- HL层输出:[batch_size, embedding_size, hl_size]。HL层:[embedding_size, hl_size],Q中的每个句子会通过和HL层的点积进行变换,相当于将每个字的字向量从embedding_size大小变换到hl_size大小。
- CNN+P+T输出:[batch_size, num_filters_total]。CNN的filter大小是[filter_size, hl_size],列大小是hl_size,这个和字向量的大小是一样的,所以对每个句子而言,每个filter出来的结果是一个列向量(而不是矩阵),列向量再取max-pooling就变成了一个数字,每个filter输出一个数字,num_filters_total个filter出来的结果当然就是[num_filters_total]大小的向量,这样就得到了一个句子的语义表示向量。T就是在输出结果上加上Tanh激活函数。
- Cosine_Similarity:[batch_size]。最后的一层并不是通常的分类或者回归的方法,而是采用了计算两个向量(Q&A)夹角的方法,下面是网络损失函数。
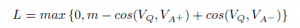 ,m是需要设定的参数margin,VQ、VA+、VA-分别是问题、正向答案、负向答案对应的语义表示向量。损失函数的意义就是:让正向答案和问题之间的向量cosine值要大于负向答案和问题的向量cosine值,大多少,就是margin这个参数来定义的。cosine值越大,两个向量越相近,所以通俗的说这个Loss就是要让正向的答案和问题愈来愈相似,让负向的答案和问题越来越不相似。
,m是需要设定的参数margin,VQ、VA+、VA-分别是问题、正向答案、负向答案对应的语义表示向量。损失函数的意义就是:让正向答案和问题之间的向量cosine值要大于负向答案和问题的向量cosine值,大多少,就是margin这个参数来定义的。cosine值越大,两个向量越相近,所以通俗的说这个Loss就是要让正向的答案和问题愈来愈相似,让负向的答案和问题越来越不相似。







Test setTop-1 AccuracyMean Reciprocal Rank
- 字向量和词向量的效果相当。所以优先使用字向量,省去了分词的麻烦,还能更好的避免未登录词的问题,何乐而不为。
- 字向量不是固定的,在训练中会更新。
- Dropout的使用对最高的准确率没有很大的影响,但是使用了Dropout的结果更稳定,准确率的波动会更小,所以建议还是要使用Dropout的。不过Dropout也不易过度使用,比如Dropout的keep_prob概率如果设置到0.25,则模型收敛得更慢,训练时间长很多,效果也有可能会更差,设置会差很多。我这版代码使用的keep_prob为0.5,同时保证准确率和训练时间。另外,Dropout只应用到了max-pooling的结果上,其他地方没有再使用了,过多的使用反而不好。
- 如何生成训练集。每个训练case需要一个问题+一个正向答案+一个负向答案,很明显问题和正向答案都是有的,负向答案的生成方法就是随机采样,这样就不需要涉及任何人工标注工作了,可以很方便的应用到大数据集上。
- HL层的效果不明显,有很微量的提升。如果HL层的大小是200,字向量是100,则HL层相当于将字向量再放大一倍,这个感觉没有多少信息可利用的,还不如直接将字向量设置成200,还省去了HL这一层的变换。
- margin的值一般都设置得比较小。这里用的是0.05
- 如果将Cosine_similarity这一层换成分类或者回归,印象中效果是不如Cosine_similarity的(具体数据忘了)
- num_filters越大并不是效果越好,基本到了一定程度就很难提升了,反而会降低训练速度。
- 同时也写了tensorflow版本代码,对比theano的,效果差不多。
- Adam和SGD两种训练方法比较,Adam训练速度貌似会更快一些,效果基本也持平吧,没有太细节的对比。不过同样的网络+SGD,theano好像训练要更快一些。
- Loss和Accuracy是比较重要的监控参数。如果写一个新的网络的话,类似的指标是很有必要的,可以在每个迭代中评估网络是否正在收敛。因为调试比较麻烦,所以通过这些参数能评估你的网络写对没,参数设置是否正确。
- 网络的参数还是比较重要的,如果一些参数设置不合理,很有可能结果千差万别,记得最初用tensorflow实现的时候,应该是dropout设置得太小,导致效果很差,很久才找到原因。所以调参和微调网络还是需要一定的技巧和经验的,做这版代码的时候就经历了一段比较痛苦的调参过程,最开始还怀疑是网络设计或是代码有问题,最后总结应该就是参数没设置好。
发表在 机器学习, 深度学习, 自然语言处理, 问答系统 | 留下评论
达观数据搜索引擎的Query自动纠错技术和架构详解发表于 2016年04月27号 由 recommender
1 背景

继续阅读 →
发表在 自然语言处理 | 一条评论
非主流自然语言处理——遗忘算法系列(四):改进TF-IDF权重公式发表于 2016年04月23号 由 老憨
一、前言
前文介绍了利用词库进行分词,本文介绍词库的另一个应用:词权重计算。
二、词权重公式
1、公式的定义
定义如下公式,用以计算词的权重:
![]()
2、公式的由来
在前文中,使用如下公式作为分词的依据:
![]()
任给一个句子或文章,通过对最佳分词方案所对应的公式进行变换,可以得到:
![]()
按前面权重公式的定义,上面的公式可以理解为:一个句子出现的概率对数等于句子中各词的权重之和。
公式两边同时取负号使权重是个正值。
三、与TF-IDF的关系
词频、逆文档频率(TF-IDF)在自然语言处理中,应用十分广泛,也是提取关键词的常用方法,公式如下:
![]()
从形式上看,该公式与我们定义的权重公式很像,而且用途也近似,那么它们之间有没有关系呢?
答案是肯定的。
我们知道,IDF是按文档为单位统计的,无论文档的长短,统一都按一篇计数,感觉这个统计的粒度还是比较粗的,有没有办法将文本的长短,这个明显相关的因素也考虑进去呢,让这个公式更加精细些?
答案也是肯定的。
文章是由词铺排而成,长短不同,所包含的词的个数也就有多有少。
我们可以考虑在统计文档个数时,为每个文档引入包含多少个词这样一个权重,以区别长短不同的文档,沿着这个思路,改写一下IDF公式:
![]()
我们用所有文档中的词做成词库,那么上式中:
![]()
综合上面的推导过程,我们知道,本文所定义的词权重公式,本质上是tf-idf为长短文档引入权重的加强版,而该公式的应用也极为简单,只需要从词库中读取该词词频、词库总词频即可。
时间复杂度最快可达O(1)级,比如词库以Hash表存储。
关于TF-IDF更完整的介绍及主流用法,建议参看阮一峰老师的博文《TF-IDF与余弦相似性的应用(一):自动提取关键词》。
四、公式应用
词权重用途很广,几乎词袋类算法中,都可以考虑使用。常见的应用有:
1、关键词抽取、自动标签生成
作法都很简单,分词后排除停用词,然后按权重值排序,取排在前面的若干个词即可。
2、文本摘要
完整的文本摘要功能实现很复杂也很困难,这里所指,仅是简单应用:由前面推导过程中可知,句子的权重等于分词结果各词的权重之和,从而获得句子的权重排序。
3、相似度计算
相似度计算,我们将在下一篇文中单独介绍。
五、演示程序
在演示程序显示词库结果时,是按本文所介绍的权重公式排序的。
演示程序与词库生成的相同:
下载地址:遗忘算法(词库生成、分词、词权重)演示程序.rar
特别感谢:王斌老师指出,本文公式实质上是TF-ICF。
六、联系方式: 1、QQ:老憨 244589712
2、邮箱:gzdmcaoyc@163.com
发表在 自然语言处理 | 标签为 TF-IDF, 自然语言处理, 遗忘算法 | 留下评论
非主流自然语言处理——遗忘算法系列(三):分词发表于 2016年04月23号 由 老憨
一、前言
前面介绍了词库的自动生成的方法,本文介绍如何利用前文所生成的词库进行分词。
二、分词的原理
分词的原理,可以参看吴军老师《数学之美》中的相关章节,这里摘取Google黑板报版本中的部分:
![]()
从上文中,可以知道分词的任务目标:给出一个句子S,找到一种分词方案,使下面公式中的P(S)最大:
![]()
不过,联合概率求起来很困难,这种情况我们通常作马尔可夫假设,以简化问题,即:任意一个词wi的出现概率只同它前面的词 wi-1 有关。
关于这个问题,吴军老师讲的深入浅出,整段摘录如下:
![]()
另外,如果我们假设一个词与其他词都不相关,即相互独立时,此时公式最简,如下:
![]()
这个假设分词无关的公式,也是本文所介绍的分词算法所使用的。
三、算法分析
问:假设分词结果中各词相互无关是否可行?
答:可行,前提是使用遗忘算法系列(二)中所述方法生成的词库,理由如下:
分析ICTCLAS广受好评的分词系统的免费版源码,可以发现,在这套由张华平、刘群两位博士所开发分词系统的算法中假设了:分词结果中词只与其前面的一个词有关。
回忆我们词库生成的过程可以知道,如果相邻的两个词紧密相关,那么这两个词会连为一个粗粒度的词被加入词库中,如:除“清华”、“大学”会是单独的词外,“清华大学”也会是一个词,分词过程中具体选用那种,则由它们的概率来决定。
也就是说,我们在生成词库的同时,已经隐含的完成了相关性训练。
关于ICTCLAS源码分析的文章,可以参看吕震宇博文:《天书般的ICTCLAS分词系统代码》。
问:如何实现分词?
答:基于前文生成的词库,我们可以假设分词结果相互无关,分词过程就比较简单,使用下面的步骤可以O(N)级时间,单遍扫描完成分词:
逐字扫描句子,从词库中查出限定字长内,以该字结尾的所有词,分别计算其中的词与该词之前各词的概率乘积,取结果值最大的词,分别缓存下当前字所在位置的最大概率积,以及对应的分词结果。
重复上面的步骤,直到句子扫描完毕,最后一字位置所得到即为整句分词结果。
3、算法特点
3.1、无监督学习;
3.2、O(N)级时间复杂度;
3.3、词库自维护,程序可无需人工参与的情况下,自行发现并添加新词、调整词频、清理错词、移除生僻词,保持词典大小适当;
3.4、领域自适应:领域变化时,词条、词频自适应的随之调整;
3.5、支持多语种混合分词。
四、演示程序下载
演示程序与词库生成的相同:
下载地址:遗忘算法(词库生成、分词、词权重)演示程序.rar
五、联系方式:
1、QQ:老憨 244589712
2、邮箱:gzdmcaoyc@163.com
发表在 自然语言处理 | 标签为 无监督分词, 自然语言处理, 自适应词典, 跨语种, 遗忘算法 | 13 条评论
非主流自然语言处理——遗忘算法系列(二):大规模语料词库生成发表于 2016年04月23号 由 老憨
一、前言
本文介绍利用牛顿冷却模拟遗忘降噪,从大规模文本中无监督生成词库的方法。
二、词库生成
算法分析,先来考虑以下几个问题
问:目标是从文本中抽取词语,是否可以考虑使用遗忘的方法呢?
答:可以,词语具备以相对稳定周期重复再现的特征,所以可以考虑使用遗忘的方法。这意味着,我们只需要找一种适当的方法,将句子划分成若干子串,这些子串即为“候选词”。在遗忘的作用下,如果“候选词”会周期性重现,那么它就会被保留在词库中,相反如果只是偶尔或随机出现,则会逐渐被遗忘掉。
问:那用什么方法来把句子划分成子串比较合适呢?
答:考察句中任意相邻的两个字,相邻两字有两种可能:要么同属于一个共同的词,要么是两个词的边界。我们都会有这样一种感觉,属于同一个词的相邻两字的“关系”肯定比属于不同词的相邻两字的“关系”要强烈一些。
数学中并不缺少刻划“关系”的模型,这里我们选择公式简单并且参数容易统计的一种:如果两个字共现的概率大于它们随机排列在一起的概率,那么我们认为这两个字有关,反之则无关。
如果相邻两字无关,就可以将两字中间断开。逐字扫描句子,如果相邻两字满足下面的公式,则将两字断开,如此可将句子切成若干子串,从而获得“候选词”集,判断公式如下图所示:
![]()
公式中所需的参数可以通过统计获得:遍历一次语料,即可获得公式中所需的“单字的频数”、“相邻两字共现的频数”,以及“所有单字的频数总和”。
问:如何计算遗忘剩余量?
答:使用牛顿冷却公式,各参数在遗忘算法中的含义,如下图所示:
牛顿冷却公式的详情说明,可以参考阮一峰老师的博文《基于用户投票的排名算法(四):牛顿冷却定律》。
![]()
问:参数中时间是用现实时间吗,遗忘系数取多少合适呢?
答:a、关于时间:
可以使用现实时间,遗忘的发生与现实同步。
也可以考虑用处理语料中对象的数量来代替,这样仅当有数据处理时,才会发生遗忘。比如按处理的字数为计时单位,人阅读的速度约每秒5至7个字,当然每个人的阅读速度并不相同,这里的参数值要求并不需要特别严格。
b、遗忘系数可以参考艾宾浩斯曲线中的实验值,如下图(来自互联网)
![]()
我们取6天记忆剩余量约为25.4%这个值,按每秒阅读7个字,将其代入牛顿冷却公式可以求得遗忘系数:
![]()
注意艾宾浩斯曲线中的每组数值代入公式,所得的系数并不相同,会对词库的最大有效容量产生影响。
二、该算法生成词库的特点
3.1、无监督学习
3.2、O(N)级时间复杂度
3.3、训练、执行为同一过程,可无缝处理流式数据
3.4、未登录词、新词、登录词没有区别
3.5、领域自适应:领域变化时,词条、词频自适应的随之调整
3.6、算法中仅使用到频数这一语言的共性特征,无需对任何字符做特别处理,因此原理上跨语种。
三、词库成熟度
由于每个词都具备一个相对稳定的重现周期,不难证明,当训练语料达到一定规模后,在遗忘的作用下,每个词的词频在衰减和累加会达到平衡,也即衰减的速度与增加的速度基本一致。成熟的词库,词频的波动相对会比较小,利用这个特征,我们可以衡量词库的成熟程度。
四、源码(C#)、演示程序下载
使用内附语料(在“可直接运行的演示程序”下可以找到)生成词库效果如下:
![]()
下载地址:遗忘算法(词库生成、分词、词权重)演示程序.rar
五、联系方式:
1、QQ:老憨 244589712
2、邮箱:gzdmcaoyc@163.com
发表在 自然语言处理 | 标签为 未登录词发现, 牛顿冷却公式, 自然语言处理, 词库生成, 遗忘算法 | 4 条评论
非主流自然语言处理——遗忘算法系列(一):算法概述发表于 2016年04月19号 由 老憨
一、前言
二、遗忘算法原理
三、牛顿冷却公式
四、已经实现的功能
1.1、跨语种,算法语种无关,比如:中日韩、少数民族等语种均可支持
1.2、未登录词发现(只要符合按相对稳定周期性重现的词汇都会被收录)
1.3、领域自适应,切换不同领域的训练文本时,词条、词频自行调整
1.4、词典成熟度:可以知道当前语料训练出的词典的成熟程度
2.1、成长性分词:用的越多,切的越准
2.2、词典自维护:切词的同时动态维护词库的词条、词频、登录新词
2.2、领域自适应、跨语种(继承自词库特性)
3.1、关键词提取、自动标签
3.2、文章摘要
3.3、长、短文本相似度计算
3.4、主题词集
五、联系方式:
发表在 自然语言处理 | 标签为 牛顿冷却公式, 自然语言处理, 遗忘算法 | 留下评论
达观数据对于大规模消息数据处理的系统架构发表于 2015年12月2号 由 recommender
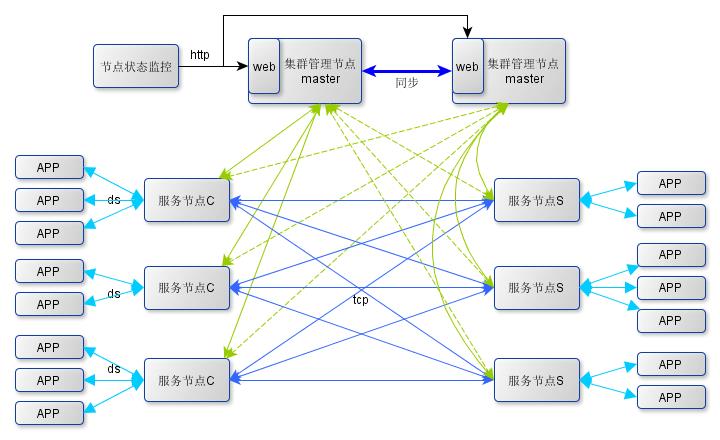 在设计达观数据的消息数据处理机制时,首先充分借鉴了ZeroMQ和ProxyIO的设计思想。ZeroMQ提供了一种底层的网络通讯框架,提供了基本的RoundRobin负载均衡算法,性能优越,而ProxyIO是雅虎的网络通讯中间件,承载了雅虎内部大量计算节点间的实时消息处理。但是ZeroMQ没有实现基于节点健康状态的最快响应算法,并且ZeroMQ和ProxyIO对节点的状态管理,连接管理,负载均衡调度等也需要各应用自己来实现。
在设计达观数据的消息数据处理机制时,首先充分借鉴了ZeroMQ和ProxyIO的设计思想。ZeroMQ提供了一种底层的网络通讯框架,提供了基本的RoundRobin负载均衡算法,性能优越,而ProxyIO是雅虎的网络通讯中间件,承载了雅虎内部大量计算节点间的实时消息处理。但是ZeroMQ没有实现基于节点健康状态的最快响应算法,并且ZeroMQ和ProxyIO对节点的状态管理,连接管理,负载均衡调度等也需要各应用自己来实现。
- 监控节点,顾名思义即提供系统监控服务的,用来给系统管理员查看集群中节点的服务状态及负载情况,系统对监控节点并无实时性及稳定性要求,在本模型中是单点系统。
- 在上图的架构中把管理节点设计成双master结构,参考zookeeper集群管理思路,多个master通过一定算法分别服务于集群中一部分节点,相对于另外的服务节点则为备份管理节点,他们通过内部通讯同步数据,每个管理节点都有一个web服务为监控节点提供服务节点的状态数据。
- 服务节点即是下文要谈的代理服务,根据服务对象不同分为应用端代理和服务端代理。集群中的服务节点根据提供服务的不同分为多个组,每个代理启动都需要注册到相应的组中,然后提供服务。

- clientHost和serverHost间使用socketapi进行tcp通讯,相同主机内部的多个进程间使用共享内存传递消息内容,client和clientproxy、server和serverproxy之间通过domain socket进行事件通知;在socket连接的一方收到对端的事件通知后,从共享内存中获取消息内容。
- clientproxy/serverproxy启动时绑定到host的一个端口响应应用api的连接,在连接到来时将该api对应的共享内存初始化,将偏移地址告诉给应用。clientproxy和serverproxy中分别维护了一个到应用api的连接句柄队列,并通过io复用技术监听这些连接上的读写事件。
- serverproxy在启动时通过socket绑定到服务器的一个端口,并以server身份注册到一个group监听该端口的连接事件,当事件到达时回调注册的事件处理函数响应事件。
- 在serverproxy内部通过不同的thread分别管理从本地应用建立的连接和从clientproxy建立的连接。thread的个数在启动proxy时由用户指定,默认是分别1个。每个clientproxy启动时会以client身份注册到一个group,并建立到同组的所有serverproxy的连接,clientproxy内部包含了连接的自管理能力及failover的处理(将在下面连接管理部分描述)。 DPIO实现了负载均衡,路由选择和透明代理的功能。


- Api与DPIO通信协议
- 共享内存存储消息格式
|
字段
|
含义
|
长度
|
|
protocol len
|
协议包的总长度
|
4bytes
|
|
protocol head len
|
协议头的长度
|
1byte
|
|
Version_protocol_id
|
协议的版本号和协议号
|
1byte
|
|
Flag
|
消息标志,标志路由模式,是否记录来源地址,有二级路由,所以这个字段一定要Eg,末位表示要记录src,倒数第二位表示按roundrobin路由,倒数第3位表示按消息头路由,xxx
|
1byte
|
|
Proxy
|
来源/目的 proxy
|
2bytes
|
|
Api
|
来源/目的 api
|
2bytes
|
|
ApiTtl
|
协议包的发送时间
|
2Bytes
|
|
ClientTtl
|
消息存活的时间,后面添加,增加路由策略,选择app_server
|
2Bytes
|
|
ClientProcessTime
|
客户端处理所用时间
|
2Bytes
|
|
ServerTtl
|
消息存活的时间,后面添加,增加路由策略,选择app_client
|
2Bytes
|
|
timeout
|
协议包的超时时间
|
2 byte
|
|
Sid
|
消息序列号
|
4bytes
|
|
protocol body len
|
Body长度
|
4bytes
|
|
protocol body
|
消息体
|
Size
|
- 请求协议包
|
字段
|
含义
|
长度
|
|
protocol head len
|
协议头的长度
|
1byte
|
|
Version_protocol_id
|
协议的版本号和协议号
|
1byte
|
|
Flag
|
消息标志,标志路由模式,是否记录来源地址,有二级路由,所以这个字段一定要Eg,末位表示要记录src,倒数第二位表示按roundrobin路由,倒数第3位表示按消息头路由,xxx
|
1byte
|
|
ApiTtl
|
协议包的发送时间
|
2bytes
|
|
Timeout
|
协议包的超时时间
|
2bytes
|
|
Api
|
来源/目的 api
|
2bytes
|
|
Sid
|
消息序列号
|
4byte
|
|
Begin_offset
|
协议包的起始偏移
|
4bytes
|
|
len
|
协议包长度
|
4bytes
|
- 响应协议包
|
字段
|
含义
|
长度
|
|
protocol head len
|
协议头的长度
|
1byte
|
|
Version_protocol_id
|
协议的版本号和协议号
|
1byte
|
|
Flag
|
消息标志,标志路由模式,是否记录来源地址,有二级路由,所以这个字段一定要Eg,末位表示要记录src,倒数第二位表示按roundrobin路由,倒数第3位表示按消息头路由,xxx
|
1byte
|
|
Result
|
处理结果
|
1byte
|
|
sid
|
消息序列号
|
4bytes
|
|
begin_offset
|
协议包的起始偏移
|
4bytes
|
|
len
|
协议包长度
|
4bytes
|
- Proxy与监控中心的监控信息
- 请求协议包
|
字段
|
含义
|
长度
|
|
protocol len
|
协议包的总长度
|
4bytes
|
|
protocol head len
|
协议头的长度
|
4bytes
|
|
Version
|
协议的版本号
|
4bytes
|
|
protocol id
|
协议的协议号
|
4bytess
|
|
status_version
|
当前状态版本
|
4bytes
|
|
Proxy_identify_len
|
该proxy标识长度
|
4bytess
|
|
Proxy_identify
|
该proxy 标识
|
4bytes
|
|
protocol body
|
消息体
|
Size
|
- 应答包
|
字段
|
含义
|
长度
|
|
protocol len
|
协议包的总长度
|
4bytes
|
|
protocol head len
|
协议头的长度
|
4bytes
|
|
Version
|
协议的版本号
|
4bytes
|
|
protocol id
|
协议的协议号
|
4bytess
|
|
protocol body len
|
Body长度
|
4bytes
|
|
protocol body
|
消息体
|
Size
|



- apiclient通过调用api的接口,将消息传给
- api接受消息体,从共享内存中申请内存,填写消息头size(协议总长度)、Offset (协议版本号和协议号)、Headsize (协议头的总长度)、flag(路由策略),ApiTtl (协议包的发送时间)、timeout (协议包的超时时间)、sid(序列号),size(消息体长度)字段,封装成协议包,将协议包写入共享内存。
- api通过socket发送请求给proxy。
- app epoll thread通过检测api的可读事件,接受请求。通过解析请求内容,获取请求协议包所在的共享内存的偏移、请求协议包的长度和api连接index加入到处理队列。
- proxy client的io epoll thread通过检测对端DPIO连接的可写事件,从发送队列中获取请求包,将api的index加入到协议包的api index字段。
- proxy client的io epoll thread从共享内存中读取协议包,释放由请求包中所标识的内存空间。
- proxy server的io epoll thread通过检测对端DPIO的可读事件,接受请求。
- proxy server的io epoll thread从共享内存中申请空间,将proxy的index加入到协议包的proxy index字段。将请求内存写入到申请的空间中。
- proxy server的io epoll thread 将协议包在共享内存的偏移和协议包的长度加入的待处理队列中。
- app epoll thread从待处理队列中获取请求包,将协议包转发给相应的api进行处理。
- api通过检测DPIO的可读事件,解析请求内容。
- api通过解析请求内容,获取请求协议包在共享内存中的偏移和请求协议包的长度。从共享内存中读取请求内容,并释放相应空间。
- api将请求协议包返回给应用层进行处理。
- 应用层将应答包传给api。
- Api从共享内存中申请空间,将应答包写入到共享内存中。
- Api将应答包在共享内存中的偏移和应答包的大小写入到共享内存中。
- App epoll thread通过检测可读事件,将应答包写入到已处理队列中。
- proxy server的Io epoll thread通过检测对端的DPIO的可写事件,将已处理队列中获取应答包。
- proxy server的Io epoll thread从共享内存中读取应答包。
- Proxy client的Io epoll thread检测可读事件,读取应答包。
- Proxy client的Io epoll thread通过解析应答包,从共享内存中申请空间,将应答包写入到申请的内存中。
- Proxy client的Io epoll thread将应答包移入到已处理队列。
- App epoll thread通过检测api的可写事件,将已处理队列中获取应答包。
- App epoll thread发送应答包。
- Api通过检测可读事件,获取应答包,通过解析应到包,获取应答包在共享内存中的偏移和应到的大小,从共享内存中读取应到包。
- Api将应答包返回给应用端。(桂洪冠 陈运文)。

发表在 数据挖掘 | 标签为 数据处理, 数据通讯 | 留下评论
在微信公众号里使用LaTeX数学公式发表于 2015年11月17号 由 52nlp
发表在 随笔 | 标签为 latex公式, latex数学公式, MathJax, 微信, 微信latex, 微信公众号, 微信公众号数学公式编辑器, 微信公式编辑器, 微信数学公式 | 2 条评论
斯坦福大学深度学习与自然语言处理第四讲:词窗口分类和神经网络发表于 2015年09月14号 由 52nlp
- [UFLDL tutorial]
- [Learning Representations by Backpropogating Errors]
- 第四讲Slides [slides]
- 第四讲视频 [video]
继续阅读 →
发表在 机器学习, 深度学习, 自然语言处理 | 标签为 Deep Learning, Deep Learning公开课, Deep NLP, DL, NER, Richard Socher, softmax, word vectors, word2vec, wordnet, 二元逻辑回归, 人名识别, 公开课, 分类, 分类器, 前馈网络记录, 反向传播算法, 命名实体识别, 回归, 地名识别, 斯坦福大学, 机器学习, 梯度下降, 深度学习, 深度学习与自然语言处理, 深度学习技术, 深度学习模型, 神经元, 神经网络, 窗口向量, 窗口向量分类, 自然语义处理, 自然语言处理, 词向量, 词嵌入, 语义词典, 逻辑回归, 随机梯度下降 | 3 条评论
出门问问宣布完成由Google投资的C轮融资,累计融资7500万美金发表于 2015年09月2号 由 52nlp
继续阅读 →
- Qp:[batch_size, sequence_len],Qp是Q之前的一个表示(在上图中没有画出)。所有句子需要截断或padding到一个固定长度(因为后面的CNN一般是处理固定长度的矩阵),例如句子包含3个字ABC,我们选择固定长度sequence_len为100,则需要将这个句子padding成ABC<a><a>…<a>(100个字),其中的<a>就是添加的专门用于padding的无意义的符号。训练时都是做mini-batch的,所以这里是一个batch_size行的矩阵,每行是一个句子。
- Q:[batch_size, sequence_len, embedding_size]。句子中的每个字都需要转换成对应的字向量,字向量的维度大小是embedding_size,这样Qp就从一个2维的矩阵变成了3维的Q
- HL层输出:[batch_size, embedding_size, hl_size]。HL层:[embedding_size, hl_size],Q中的每个句子会通过和HL层的点积进行变换,相当于将每个字的字向量从embedding_size大小变换到hl_size大小。
- CNN+P+T输出:[batch_size, num_filters_total]。CNN的filter大小是[filter_size, hl_size],列大小是hl_size,这个和字向量的大小是一样的,所以对每个句子而言,每个filter出来的结果是一个列向量(而不是矩阵),列向量再取max-pooling就变成了一个数字,每个filter输出一个数字,num_filters_total个filter出来的结果当然就是[num_filters_total]大小的向量,这样就得到了一个句子的语义表示向量。T就是在输出结果上加上Tanh激活函数。
- Cosine_Similarity:[batch_size]。最后的一层并不是通常的分类或者回归的方法,而是采用了计算两个向量(Q&A)夹角的方法,下面是网络损失函数。,m是需要设定的参数margin,VQ、VA+、VA-分别是问题、正向答案、负向答案对应的语义表示向量。损失函数的意义就是:让正向答案和问题之间的向量cosine值要大于负向答案和问题的向量cosine值,大多少,就是margin这个参数来定义的。cosine值越大,两个向量越相近,所以通俗的说这个Loss就是要让正向的答案和问题愈来愈相似,让负向的答案和问题越来越不相似。
Test setTop-1 AccuracyMean Reciprocal Rank
- 字向量和词向量的效果相当。所以优先使用字向量,省去了分词的麻烦,还能更好的避免未登录词的问题,何乐而不为。
- 字向量不是固定的,在训练中会更新。
- Dropout的使用对最高的准确率没有很大的影响,但是使用了Dropout的结果更稳定,准确率的波动会更小,所以建议还是要使用Dropout的。不过Dropout也不易过度使用,比如Dropout的keep_prob概率如果设置到0.25,则模型收敛得更慢,训练时间长很多,效果也有可能会更差,设置会差很多。我这版代码使用的keep_prob为0.5,同时保证准确率和训练时间。另外,Dropout只应用到了max-pooling的结果上,其他地方没有再使用了,过多的使用反而不好。
- 如何生成训练集。每个训练case需要一个问题+一个正向答案+一个负向答案,很明显问题和正向答案都是有的,负向答案的生成方法就是随机采样,这样就不需要涉及任何人工标注工作了,可以很方便的应用到大数据集上。
- HL层的效果不明显,有很微量的提升。如果HL层的大小是200,字向量是100,则HL层相当于将字向量再放大一倍,这个感觉没有多少信息可利用的,还不如直接将字向量设置成200,还省去了HL这一层的变换。
- margin的值一般都设置得比较小。这里用的是0.05
- 如果将Cosine_similarity这一层换成分类或者回归,印象中效果是不如Cosine_similarity的(具体数据忘了)
- num_filters越大并不是效果越好,基本到了一定程度就很难提升了,反而会降低训练速度。
- 同时也写了tensorflow版本代码,对比theano的,效果差不多。
- Adam和SGD两种训练方法比较,Adam训练速度貌似会更快一些,效果基本也持平吧,没有太细节的对比。不过同样的网络+SGD,theano好像训练要更快一些。
- Loss和Accuracy是比较重要的监控参数。如果写一个新的网络的话,类似的指标是很有必要的,可以在每个迭代中评估网络是否正在收敛。因为调试比较麻烦,所以通过这些参数能评估你的网络写对没,参数设置是否正确。
- 网络的参数还是比较重要的,如果一些参数设置不合理,很有可能结果千差万别,记得最初用tensorflow实现的时候,应该是dropout设置得太小,导致效果很差,很久才找到原因。所以调参和微调网络还是需要一定的技巧和经验的,做这版代码的时候就经历了一段比较痛苦的调参过程,最开始还怀疑是网络设计或是代码有问题,最后总结应该就是参数没设置好。
发表在 机器学习, 深度学习, 自然语言处理, 问答系统 | 留下评论
达观数据搜索引擎的Query自动纠错技术和架构详解发表于 2016年04月27号 由 recommender
1 背景
继续阅读 →
发表在 自然语言处理 | 一条评论
非主流自然语言处理——遗忘算法系列(四):改进TF-IDF权重公式发表于 2016年04月23号 由 老憨
一、前言
前文介绍了利用词库进行分词,本文介绍词库的另一个应用:词权重计算。
二、词权重公式
1、公式的定义
定义如下公式,用以计算词的权重:
![]()
2、公式的由来
在前文中,使用如下公式作为分词的依据:
![]()
任给一个句子或文章,通过对最佳分词方案所对应的公式进行变换,可以得到:
![]()
按前面权重公式的定义,上面的公式可以理解为:一个句子出现的概率对数等于句子中各词的权重之和。
公式两边同时取负号使权重是个正值。
三、与TF-IDF的关系
词频、逆文档频率(TF-IDF)在自然语言处理中,应用十分广泛,也是提取关键词的常用方法,公式如下:
![]()
从形式上看,该公式与我们定义的权重公式很像,而且用途也近似,那么它们之间有没有关系呢?
答案是肯定的。
我们知道,IDF是按文档为单位统计的,无论文档的长短,统一都按一篇计数,感觉这个统计的粒度还是比较粗的,有没有办法将文本的长短,这个明显相关的因素也考虑进去呢,让这个公式更加精细些?
答案也是肯定的。
文章是由词铺排而成,长短不同,所包含的词的个数也就有多有少。
我们可以考虑在统计文档个数时,为每个文档引入包含多少个词这样一个权重,以区别长短不同的文档,沿着这个思路,改写一下IDF公式:
![]()
我们用所有文档中的词做成词库,那么上式中:
![]()
综合上面的推导过程,我们知道,本文所定义的词权重公式,本质上是tf-idf为长短文档引入权重的加强版,而该公式的应用也极为简单,只需要从词库中读取该词词频、词库总词频即可。
时间复杂度最快可达O(1)级,比如词库以Hash表存储。
关于TF-IDF更完整的介绍及主流用法,建议参看阮一峰老师的博文《TF-IDF与余弦相似性的应用(一):自动提取关键词》。
四、公式应用
词权重用途很广,几乎词袋类算法中,都可以考虑使用。常见的应用有:
1、关键词抽取、自动标签生成
作法都很简单,分词后排除停用词,然后按权重值排序,取排在前面的若干个词即可。
2、文本摘要
完整的文本摘要功能实现很复杂也很困难,这里所指,仅是简单应用:由前面推导过程中可知,句子的权重等于分词结果各词的权重之和,从而获得句子的权重排序。
3、相似度计算
相似度计算,我们将在下一篇文中单独介绍。
五、演示程序
在演示程序显示词库结果时,是按本文所介绍的权重公式排序的。
演示程序与词库生成的相同:
下载地址:遗忘算法(词库生成、分词、词权重)演示程序.rar
特别感谢:王斌老师指出,本文公式实质上是TF-ICF。
六、联系方式: 1、QQ:老憨 244589712
2、邮箱:gzdmcaoyc@163.com
发表在 自然语言处理 | 标签为 TF-IDF, 自然语言处理, 遗忘算法 | 留下评论
非主流自然语言处理——遗忘算法系列(三):分词发表于 2016年04月23号 由 老憨
一、前言
前面介绍了词库的自动生成的方法,本文介绍如何利用前文所生成的词库进行分词。
二、分词的原理
分词的原理,可以参看吴军老师《数学之美》中的相关章节,这里摘取Google黑板报版本中的部分:
![]()
从上文中,可以知道分词的任务目标:给出一个句子S,找到一种分词方案,使下面公式中的P(S)最大:
![]()
不过,联合概率求起来很困难,这种情况我们通常作马尔可夫假设,以简化问题,即:任意一个词wi的出现概率只同它前面的词 wi-1 有关。
关于这个问题,吴军老师讲的深入浅出,整段摘录如下:
![]()
另外,如果我们假设一个词与其他词都不相关,即相互独立时,此时公式最简,如下:
![]()
这个假设分词无关的公式,也是本文所介绍的分词算法所使用的。
三、算法分析
问:假设分词结果中各词相互无关是否可行?
答:可行,前提是使用遗忘算法系列(二)中所述方法生成的词库,理由如下:
分析ICTCLAS广受好评的分词系统的免费版源码,可以发现,在这套由张华平、刘群两位博士所开发分词系统的算法中假设了:分词结果中词只与其前面的一个词有关。
回忆我们词库生成的过程可以知道,如果相邻的两个词紧密相关,那么这两个词会连为一个粗粒度的词被加入词库中,如:除“清华”、“大学”会是单独的词外,“清华大学”也会是一个词,分词过程中具体选用那种,则由它们的概率来决定。
也就是说,我们在生成词库的同时,已经隐含的完成了相关性训练。
关于ICTCLAS源码分析的文章,可以参看吕震宇博文:《天书般的ICTCLAS分词系统代码》。
问:如何实现分词?
答:基于前文生成的词库,我们可以假设分词结果相互无关,分词过程就比较简单,使用下面的步骤可以O(N)级时间,单遍扫描完成分词:
逐字扫描句子,从词库中查出限定字长内,以该字结尾的所有词,分别计算其中的词与该词之前各词的概率乘积,取结果值最大的词,分别缓存下当前字所在位置的最大概率积,以及对应的分词结果。
重复上面的步骤,直到句子扫描完毕,最后一字位置所得到即为整句分词结果。
3、算法特点
3.1、无监督学习;
3.2、O(N)级时间复杂度;
3.3、词库自维护,程序可无需人工参与的情况下,自行发现并添加新词、调整词频、清理错词、移除生僻词,保持词典大小适当;
3.4、领域自适应:领域变化时,词条、词频自适应的随之调整;
3.5、支持多语种混合分词。
四、演示程序下载
演示程序与词库生成的相同:
下载地址:遗忘算法(词库生成、分词、词权重)演示程序.rar
五、联系方式:
1、QQ:老憨 244589712
2、邮箱:gzdmcaoyc@163.com
发表在 自然语言处理 | 标签为 无监督分词, 自然语言处理, 自适应词典, 跨语种, 遗忘算法 | 13 条评论
非主流自然语言处理——遗忘算法系列(二):大规模语料词库生成发表于 2016年04月23号 由 老憨
一、前言
本文介绍利用牛顿冷却模拟遗忘降噪,从大规模文本中无监督生成词库的方法。
二、词库生成
算法分析,先来考虑以下几个问题
问:目标是从文本中抽取词语,是否可以考虑使用遗忘的方法呢?
答:可以,词语具备以相对稳定周期重复再现的特征,所以可以考虑使用遗忘的方法。这意味着,我们只需要找一种适当的方法,将句子划分成若干子串,这些子串即为“候选词”。在遗忘的作用下,如果“候选词”会周期性重现,那么它就会被保留在词库中,相反如果只是偶尔或随机出现,则会逐渐被遗忘掉。
问:那用什么方法来把句子划分成子串比较合适呢?
答:考察句中任意相邻的两个字,相邻两字有两种可能:要么同属于一个共同的词,要么是两个词的边界。我们都会有这样一种感觉,属于同一个词的相邻两字的“关系”肯定比属于不同词的相邻两字的“关系”要强烈一些。
数学中并不缺少刻划“关系”的模型,这里我们选择公式简单并且参数容易统计的一种:如果两个字共现的概率大于它们随机排列在一起的概率,那么我们认为这两个字有关,反之则无关。
如果相邻两字无关,就可以将两字中间断开。逐字扫描句子,如果相邻两字满足下面的公式,则将两字断开,如此可将句子切成若干子串,从而获得“候选词”集,判断公式如下图所示:
![]()
公式中所需的参数可以通过统计获得:遍历一次语料,即可获得公式中所需的“单字的频数”、“相邻两字共现的频数”,以及“所有单字的频数总和”。
问:如何计算遗忘剩余量?
答:使用牛顿冷却公式,各参数在遗忘算法中的含义,如下图所示:
牛顿冷却公式的详情说明,可以参考阮一峰老师的博文《基于用户投票的排名算法(四):牛顿冷却定律》。
![]()
问:参数中时间是用现实时间吗,遗忘系数取多少合适呢?
答:a、关于时间:
可以使用现实时间,遗忘的发生与现实同步。
也可以考虑用处理语料中对象的数量来代替,这样仅当有数据处理时,才会发生遗忘。比如按处理的字数为计时单位,人阅读的速度约每秒5至7个字,当然每个人的阅读速度并不相同,这里的参数值要求并不需要特别严格。
b、遗忘系数可以参考艾宾浩斯曲线中的实验值,如下图(来自互联网)
![]()
我们取6天记忆剩余量约为25.4%这个值,按每秒阅读7个字,将其代入牛顿冷却公式可以求得遗忘系数:
![]()
注意艾宾浩斯曲线中的每组数值代入公式,所得的系数并不相同,会对词库的最大有效容量产生影响。
二、该算法生成词库的特点
3.1、无监督学习
3.2、O(N)级时间复杂度
3.3、训练、执行为同一过程,可无缝处理流式数据
3.4、未登录词、新词、登录词没有区别
3.5、领域自适应:领域变化时,词条、词频自适应的随之调整
3.6、算法中仅使用到频数这一语言的共性特征,无需对任何字符做特别处理,因此原理上跨语种。
三、词库成熟度
由于每个词都具备一个相对稳定的重现周期,不难证明,当训练语料达到一定规模后,在遗忘的作用下,每个词的词频在衰减和累加会达到平衡,也即衰减的速度与增加的速度基本一致。成熟的词库,词频的波动相对会比较小,利用这个特征,我们可以衡量词库的成熟程度。
四、源码(C#)、演示程序下载
使用内附语料(在“可直接运行的演示程序”下可以找到)生成词库效果如下:
![]()
下载地址:遗忘算法(词库生成、分词、词权重)演示程序.rar
五、联系方式:
1、QQ:老憨 244589712
2、邮箱:gzdmcaoyc@163.com
发表在 自然语言处理 | 标签为 未登录词发现, 牛顿冷却公式, 自然语言处理, 词库生成, 遗忘算法 | 4 条评论
非主流自然语言处理——遗忘算法系列(一):算法概述发表于 2016年04月19号 由 老憨
一、前言
二、遗忘算法原理
三、牛顿冷却公式
四、已经实现的功能
1.1、跨语种,算法语种无关,比如:中日韩、少数民族等语种均可支持
1.2、未登录词发现(只要符合按相对稳定周期性重现的词汇都会被收录)
1.3、领域自适应,切换不同领域的训练文本时,词条、词频自行调整
1.4、词典成熟度:可以知道当前语料训练出的词典的成熟程度
2.1、成长性分词:用的越多,切的越准
2.2、词典自维护:切词的同时动态维护词库的词条、词频、登录新词
2.2、领域自适应、跨语种(继承自词库特性)
3.1、关键词提取、自动标签
3.2、文章摘要
3.3、长、短文本相似度计算
3.4、主题词集
五、联系方式:
发表在 自然语言处理 | 标签为 牛顿冷却公式, 自然语言处理, 遗忘算法 | 留下评论
达观数据对于大规模消息数据处理的系统架构发表于 2015年12月2号 由 recommender
在设计达观数据的消息数据处理机制时,首先充分借鉴了ZeroMQ和ProxyIO的设计思想。ZeroMQ提供了一种底层的网络通讯框架,提供了基本的RoundRobin负载均衡算法,性能优越,而ProxyIO是雅虎的网络通讯中间件,承载了雅虎内部大量计算节点间的实时消息处理。但是ZeroMQ没有实现基于节点健康状态的最快响应算法,并且ZeroMQ和ProxyIO对节点的状态管理,连接管理,负载均衡调度等也需要各应用自己来实现。
- 监控节点,顾名思义即提供系统监控服务的,用来给系统管理员查看集群中节点的服务状态及负载情况,系统对监控节点并无实时性及稳定性要求,在本模型中是单点系统。
- 在上图的架构中把管理节点设计成双master结构,参考zookeeper集群管理思路,多个master通过一定算法分别服务于集群中一部分节点,相对于另外的服务节点则为备份管理节点,他们通过内部通讯同步数据,每个管理节点都有一个web服务为监控节点提供服务节点的状态数据。
- 服务节点即是下文要谈的代理服务,根据服务对象不同分为应用端代理和服务端代理。集群中的服务节点根据提供服务的不同分为多个组,每个代理启动都需要注册到相应的组中,然后提供服务。
- clientHost和serverHost间使用socketapi进行tcp通讯,相同主机内部的多个进程间使用共享内存传递消息内容,client和clientproxy、server和serverproxy之间通过domain socket进行事件通知;在socket连接的一方收到对端的事件通知后,从共享内存中获取消息内容。
- clientproxy/serverproxy启动时绑定到host的一个端口响应应用api的连接,在连接到来时将该api对应的共享内存初始化,将偏移地址告诉给应用。clientproxy和serverproxy中分别维护了一个到应用api的连接句柄队列,并通过io复用技术监听这些连接上的读写事件。
- serverproxy在启动时通过socket绑定到服务器的一个端口,并以server身份注册到一个group监听该端口的连接事件,当事件到达时回调注册的事件处理函数响应事件。
- 在serverproxy内部通过不同的thread分别管理从本地应用建立的连接和从clientproxy建立的连接。thread的个数在启动proxy时由用户指定,默认是分别1个。每个clientproxy启动时会以client身份注册到一个group,并建立到同组的所有serverproxy的连接,clientproxy内部包含了连接的自管理能力及failover的处理(将在下面连接管理部分描述)。 DPIO实现了负载均衡,路由选择和透明代理的功能。
- Api与DPIO通信协议
- 共享内存存储消息格式
|
字段
|
含义
|
长度
|
|
protocol len
|
协议包的总长度
|
4bytes
|
|
protocol head len
|
协议头的长度
|
1byte
|
|
Version_protocol_id
|
协议的版本号和协议号
|
1byte
|
|
Flag
|
消息标志,标志路由模式,是否记录来源地址,有二级路由,所以这个字段一定要Eg,末位表示要记录src,倒数第二位表示按roundrobin路由,倒数第3位表示按消息头路由,xxx
|
1byte
|
|
Proxy
|
来源/目的 proxy
|
2bytes
|
|
Api
|
来源/目的 api
|
2bytes
|
|
ApiTtl
|
协议包的发送时间
|
2Bytes
|
|
ClientTtl
|
消息存活的时间,后面添加,增加路由策略,选择app_server
|
2Bytes
|
|
ClientProcessTime
|
客户端处理所用时间
|
2Bytes
|
|
ServerTtl
|
消息存活的时间,后面添加,增加路由策略,选择app_client
|
2Bytes
|
|
timeout
|
协议包的超时时间
|
2 byte
|
|
Sid
|
消息序列号
|
4bytes
|
|
protocol body len
|
Body长度
|
4bytes
|
|
protocol body
|
消息体
|
Size
|
- 请求协议包
|
字段
|
含义
|
长度
|
|
protocol head len
|
协议头的长度
|
1byte
|
|
Version_protocol_id
|
协议的版本号和协议号
|
1byte
|
|
Flag
|
消息标志,标志路由模式,是否记录来源地址,有二级路由,所以这个字段一定要Eg,末位表示要记录src,倒数第二位表示按roundrobin路由,倒数第3位表示按消息头路由,xxx
|
1byte
|
|
ApiTtl
|
协议包的发送时间
|
2bytes
|
|
Timeout
|
协议包的超时时间
|
2bytes
|
|
Api
|
来源/目的 api
|
2bytes
|
|
Sid
|
消息序列号
|
4byte
|
|
Begin_offset
|
协议包的起始偏移
|
4bytes
|
|
len
|
协议包长度
|
4bytes
|
- 响应协议包
|
字段
|
含义
|
长度
|
|
protocol head len
|
协议头的长度
|
1byte
|
|
Version_protocol_id
|
协议的版本号和协议号
|
1byte
|
|
Flag
|
消息标志,标志路由模式,是否记录来源地址,有二级路由,所以这个字段一定要Eg,末位表示要记录src,倒数第二位表示按roundrobin路由,倒数第3位表示按消息头路由,xxx
|
1byte
|
|
Result
|
处理结果
|
1byte
|
|
sid
|
消息序列号
|
4bytes
|
|
begin_offset
|
协议包的起始偏移
|
4bytes
|
|
len
|
协议包长度
|
4bytes
|
- Proxy与监控中心的监控信息
- 请求协议包
|
字段
|
含义
|
长度
|
|
protocol len
|
协议包的总长度
|
4bytes
|
|
protocol head len
|
协议头的长度
|
4bytes
|
|
Version
|
协议的版本号
|
4bytes
|
|
protocol id
|
协议的协议号
|
4bytess
|
|
status_version
|
当前状态版本
|
4bytes
|
|
Proxy_identify_len
|
该proxy标识长度
|
4bytess
|
|
Proxy_identify
|
该proxy 标识
|
4bytes
|
|
protocol body
|
消息体
|
Size
|
- 应答包
|
字段
|
含义
|
长度
|
|
protocol len
|
协议包的总长度
|
4bytes
|
|
protocol head len
|
协议头的长度
|
4bytes
|
|
Version
|
协议的版本号
|
4bytes
|
|
protocol id
|
协议的协议号
|
4bytess
|
|
protocol body len
|
Body长度
|
4bytes
|
|
protocol body
|
消息体
|
Size
|
- apiclient通过调用api的接口,将消息传给
- api接受消息体,从共享内存中申请内存,填写消息头size(协议总长度)、Offset (协议版本号和协议号)、Headsize (协议头的总长度)、flag(路由策略),ApiTtl (协议包的发送时间)、timeout (协议包的超时时间)、sid(序列号),size(消息体长度)字段,封装成协议包,将协议包写入共享内存。
- api通过socket发送请求给proxy。
- app epoll thread通过检测api的可读事件,接受请求。通过解析请求内容,获取请求协议包所在的共享内存的偏移、请求协议包的长度和api连接index加入到处理队列。
- proxy client的io epoll thread通过检测对端DPIO连接的可写事件,从发送队列中获取请求包,将api的index加入到协议包的api index字段。
- proxy client的io epoll thread从共享内存中读取协议包,释放由请求包中所标识的内存空间。
- proxy server的io epoll thread通过检测对端DPIO的可读事件,接受请求。
- proxy server的io epoll thread从共享内存中申请空间,将proxy的index加入到协议包的proxy index字段。将请求内存写入到申请的空间中。
- proxy server的io epoll thread 将协议包在共享内存的偏移和协议包的长度加入的待处理队列中。
- app epoll thread从待处理队列中获取请求包,将协议包转发给相应的api进行处理。
- api通过检测DPIO的可读事件,解析请求内容。
- api通过解析请求内容,获取请求协议包在共享内存中的偏移和请求协议包的长度。从共享内存中读取请求内容,并释放相应空间。
- api将请求协议包返回给应用层进行处理。
- 应用层将应答包传给api。
- Api从共享内存中申请空间,将应答包写入到共享内存中。
- Api将应答包在共享内存中的偏移和应答包的大小写入到共享内存中。
- App epoll thread通过检测可读事件,将应答包写入到已处理队列中。
- proxy server的Io epoll thread通过检测对端的DPIO的可写事件,将已处理队列中获取应答包。
- proxy server的Io epoll thread从共享内存中读取应答包。
- Proxy client的Io epoll thread检测可读事件,读取应答包。
- Proxy client的Io epoll thread通过解析应答包,从共享内存中申请空间,将应答包写入到申请的内存中。
- Proxy client的Io epoll thread将应答包移入到已处理队列。
- App epoll thread通过检测api的可写事件,将已处理队列中获取应答包。
- App epoll thread发送应答包。
- Api通过检测可读事件,获取应答包,通过解析应到包,获取应答包在共享内存中的偏移和应到的大小,从共享内存中读取应到包。
- Api将应答包返回给应用端。(桂洪冠 陈运文)。
发表在 数据挖掘 | 标签为 数据处理, 数据通讯 | 留下评论
在微信公众号里使用LaTeX数学公式发表于 2015年11月17号 由 52nlp
发表在 随笔 | 标签为 latex公式, latex数学公式, MathJax, 微信, 微信latex, 微信公众号, 微信公众号数学公式编辑器, 微信公式编辑器, 微信数学公式 | 2 条评论
斯坦福大学深度学习与自然语言处理第四讲:词窗口分类和神经网络发表于 2015年09月14号 由 52nlp
- [UFLDL tutorial]
- [Learning Representations by Backpropogating Errors]
- 第四讲Slides [slides]
- 第四讲视频 [video]
继续阅读 →
发表在 机器学习, 深度学习, 自然语言处理 | 标签为 Deep Learning, Deep Learning公开课, Deep NLP, DL, NER, Richard Socher, softmax, word vectors, word2vec, wordnet, 二元逻辑回归, 人名识别, 公开课, 分类, 分类器, 前馈网络记录, 反向传播算法, 命名实体识别, 回归, 地名识别, 斯坦福大学, 机器学习, 梯度下降, 深度学习, 深度学习与自然语言处理, 深度学习技术, 深度学习模型, 神经元, 神经网络, 窗口向量, 窗口向量分类, 自然语义处理, 自然语言处理, 词向量, 词嵌入, 语义词典, 逻辑回归, 随机梯度下降 | 3 条评论
出门问问宣布完成由Google投资的C轮融资,累计融资7500万美金发表于 2015年09月2号 由 52nlp
继续阅读 →
QA问答系统中的深度学习技术实现相关推荐
- 从原理到应用落地,一文读懂推荐系统中的深度学习技术
作者丨gongyouliu.zandy 来源丨大数据与人工智能(ID:ai-big-data) 2016年DeepMind开发的AlphaGo在围棋对决中战胜了韩国九段选手李世石,一时成为轰动全球的重 ...
- 机器学习中的数学 人工智能深度学习技术丛书
作者:孙博 著 出版社:中国水利水电出版社 品牌:智博尚书 出版时间:2019-11-01 机器学习中的数学 人工智能深度学习技术丛书 ISBN:9787517077190
- 深度学习技术在脑机接口中的应用
大家好! Rose给大家分享一下深度学习技术在脑机接口中的应用. 什么是脑机接口? 脑机接口(BCI)是一种系统,可将受试者(人类或动物)的大脑活动模式提取并转换为用于交互式应用程序的消息或命令.脑活 ...
- 深度学习技术在社会化推荐场景中的总结(附数据集)
前言 不知道大家有没有感觉,在日常生活中用到推荐一词的时候经常是用在社交场景中的.到一个地方旅游让朋友推荐一下旅游景点,学习某一项技术的时候让朋友推荐一些有什么书可以看.在众多推荐系统的方向中,我觉得 ...
- 保健中的深度学习nlp技术用于决策
介绍 (Introduction) The ubiquitous adoption of electronic health records in hospitals and other health ...
- 一文探讨可解释深度学习技术在医疗图像诊断中的应用
2020-10-20 14:39:24 机器之心分析师网络 作者:仵冀颖 编辑:Joni 本文依托于综述性文章,首先回顾了可解释性方法的主要分类以及可解释深度学习在医疗图像诊断领域中应用的主要方法.然 ...
- 搜索推荐-《搜素与推荐中的深度学习匹配(Deep Match)技术》
本书介绍 匹配是搜索和推荐中的关键技术,即衡量文档与查询(Query)的相关性或用户对项目的兴趣.机器学习算法已经被用来解决该问题,该问题基于输入表示和带标签的数据来学习一个匹配函数,也称为" ...
- 深度学习技术在自动驾驶中的应用
在过去的十年里,自动驾驶汽车技术取得了越来越快的进步,主要得益于深度学习和人工智能领域的进步.作者就自动驾驶中使用的深度学习技术的现状以及基于人工智能的自驱动结构.卷积和递归神经网络.深度强化学习范式 ...
- 【深度学习】PyTorch深度学习技术生态
PyTorch Author:louwill Machine Learning Lab 随着近几年的大力发展,PyTorch逐渐成为主流的深度学习框架.相应的PyTorch技术生态也逐渐丰富和完善.本 ...
- 《Python自然语言处理-雅兰·萨纳卡(Jalaj Thanaki)》学习笔记:09 NLU和NLG问题中的深度学习
09 NLU和NLG问题中的深度学习 9.1 人工智能概览 9.1.1 人工智能的基础 9.1.2 人工智能的阶段 9.1.3 人工智能的种类 9.1.4 人工智能的目标和应用 9.2 NLU和NLG ...
最新文章
- 阿里云云服务器硬盘分区及挂载
- 20080509 - System.ExecutionEngineException 在 DefaultDomain 中发生
- IBM收购以色列应用发现公司EZSource
- modelsim 安装后运行,出现fatal License Error
- 弹性文件服务解密 -- 块存储、文件存储、对象存储的区别
- 华为正加大全球招聘 包括芯片工程师、软件开发员和AI研究员
- [VC++]最小化图标至托盘中
- python中文相似度_python比较两个文本的相似性
- redis watchdog_干货:Redis分布式锁的原理以及如何续期
- 7、重建二叉树(Python)
- 制造主数据集成开发心得
- shfileoperation C#无法读源文件或磁盘XP系统1026错误
- Unable to detect adb version, exit value: 0xc000007b
- ElasticSearch安装IK分词器并使用IK分词器和Kibana进行自定义词汇
- “互联网+”拯救了星巴克
- 基于sklearn的贝叶斯文本分类
- 英文会议口头报告(整理)
- 回音消除、噪音抑制的原理
- 强力推荐mac快速查看应用快捷键工具:键指如飞FlyKey
- 如何下载外文期刊文献,怎么下载又快又省力!