Recording︱有价值的各类AI、机器学习比赛心得、经验抄录
今年kaggle华人优胜团队很多,所以经验、心得不少,都是干货慢慢收集。
一、【干货】Kaggle 数据挖掘比赛经验分享
github:https://github.com/ChenglongChen/Kaggle_HomeDepot
1、了解数据分布
◆ 分析特征变量的分布
◇ 特征变量为连续值:如果为长尾分布并且考虑使用线性模型,可以对变量进行幂变换或者对数变换。
◇ 特征变量为离散值:观察每个离散值的频率分布,对于频次较低的特征,可以考虑统一编码为“其他”类别。
◆ 分析目标变量的分布
◇ 目标变量为连续值:查看其值域范围是否较大,如果较大,可以考虑对其进行对数变换,并以变换后的值作为新的目标变量进行建模(在这种情况下,需要对预测结果进行逆变换)。一般情况下,可以对连续变量进行Box-Cox变换。通过变换可以使得模型更好的优化,通常也会带来效果上的提升。
◇ 目标变量为离散值:如果数据分布不平衡,考虑是否需要上采样/下采样;如果目标变量在某个ID上面分布不平衡,在划分本地训练集和验证集的时候,需要考虑分层采样(Stratified Sampling)。
◆ 分析变量之间两两的分布和相关度
◇ 可以用于发现高相关和共线性的特征。
2、数据清洗
◆ 特征缺失值的处理
◇ 特征值为连续值:按不同的分布类型对缺失值进行补全:偏正态分布,使用均值代替,可以保持数据的均值;偏长尾分布,使用中值代替,避免受 outlier 的影响;
◇ 特征值为离散值:使用众数代替。
◆ 文本数据的清洗
◇ 在比赛当中,如果数据包含文本,往往需要进行大量的数据清洗工作。如去除HTML 标签,分词,拼写纠正, 同义词替换,去除停词,抽词干,数字和单位格式统一等。
3、特征工程
- 特征变换
主要针对一些长尾分布的特征,需要进行幂变换或者对数变换,使得模型(LR或者DNN)能更好的优化。需要注意的是,Random Forest 和 GBDT 等模型对单调的函数变换不敏感。其原因在于树模型在求解分裂点的时候,只考虑排序分位点。
- 特征编码
对于离散的类别特征,往往需要进行必要的特征转换/编码才能将其作为特征输入到模型中。常用的编码方式有 LabelEncoder,OneHotEncoder(sklearn里面的接口)。譬如对于”性别”这个特征(取值为男性和女性),使用这两种方式可以分别编码为{0,1}和{[1,0], [0,1]}。
对于取值较多(如几十万)的类别特征(ID特征),直接进行OneHotEncoder编码会导致特征矩阵非常巨大,影响模型效果。可以使用如下的方式进行处理:
◆ 统计每个取值在样本中出现的频率,取 Top N 的取值进行 One-hot 编码,剩下的类别分到“其他“类目下,其中 N 需要根据模型效果进行调优;
◆ 统计每个 ID 特征的一些统计量(譬如历史平均点击率,历史平均浏览率)等代替该 ID 取值作为特征,具体可以参考 Avazu 点击率预估比赛第二名的获奖方案;
◆ 参考 word2vec 的方式,将每个类别特征的取值映射到一个连续的向量,对这个向量进行初始化,跟模型一起训练。训练结束后,可以同时得到每个ID的Embedding。具体的使用方式,可以参考 Rossmann 销量预估竞赛第三名的获奖方案,https://github.com/entron/entity-embedding-rossmann。
对于 Random Forest 和 GBDT 等模型,如果类别特征存在较多的取值,可以直接使用 LabelEncoder 后的结果作为特征。
4、模型选择和验证
- 对于稀疏型特征(如文本特征,One-hot的ID类特征),我们一般使用线性模型,譬如 Linear Regression 或者
Logistic Regression。Random Forest 和 GBDT
等树模型不太适用于稀疏的特征,但可以先对特征进行降维(如PCA,SVD/LSA等),再使用这些特征。稀疏特征直接输入 DNN 会导致网络
weight 较多,不利于优化,也可以考虑先降维,或者对 ID 类特征使用 Embedding 的方式 - ◆ 对于稠密型特征,推荐使用 XGBoost 进行建模,简单易用效果好;
- ◆ 数据中既有稀疏特征,又有稠密特征,可以考虑使用线性模型对稀疏特征进行建模,将其输出与稠密特征一起再输入 XGBoost/DNN
建模,具体可以参考2.5.2节 Stacking 部分
5、模型参数常规设置
DNN或者XGBoost中学习率这个参数,一般就选 0.01 左右就 OK 了(太大可能会导致优化算法错过最优化点,太小导致优化收敛过慢)
Random Forest,一般设定树的棵数范围为 100~200 就能有不错的效果,当然也有人固定数棵数为 500,然后只调整其他的超参数
.
二、阿里天池IJCAI17大赛第四名方案全解析(附代码)
github:https://github.com/Jessicamidi/Solution-to-IJCAI17-Sales-Volume-Prediction-on-Koubei-Platform
阿里天池IJCAI17:https://tianchi.aliyun.com/competition/introduction.htm?spm=5176.100067.5678.1.amifQx&raceId=231591
- 赛题目标:通过阿里支付宝口碑平台2000个商户从2015.07.01到2016.10.31的商家数据,用户在支付宝端的支付和浏览日志,预测商家在未来14天(2016.11.01-2016.11.14)的客户流量。
- 外部数据:天气数据(提供了世界各地在机场附近检测到的气象信息,包含气温,露点,湿度,气压,能见度,风速,瞬时风速,降水量,天气状况等信息。历史气象信息的采样间隔为30分钟。测试集首日,北京首都国际机场2016年11月1日气象条件)、节假日信息(节假日信息 HOLI.csv,将日期类型简单分为三个类别,其中工作日标签为0,周末标签为1,假期标签为2。)
1、数据清洗
数据清洗包含三部分,通过规则清除,通过模型预训练清除及仅保留销量统计信息。
规则清除:原始数据中,存在单用户某小时内大量购买的现象,如userID为9594359用户在2016年1月30日在shopID为878的商家累计购买了209次。针对此类现象,对于单个用户单小时内的购买数量x,采用以下公式处理消除异常消费
模型预训练清除:商家日销量,可能存在一些难以预计的大幅波动,如促销,商家停业等。对于这些规则难以清除的异常值,采用预训练的方式清除。
2、仅保留销量统计信息
由于只需要预测商家的日销量,无需识别单个用户的行为,按照大数定理,可以只针对分时段的浏览与购买总数进行预测。因而在数据清洗后,保留的数据仅按小时统计商户总销量,在这一步剔除了用户ID,使得数据量仅为原始的约1/10.
3、常规销量预测模型
3.1 特征与标签
![]()
3.2 训练方式
采用滑窗对于2000个商家日销量的时间序列生成481143条有效训练样本,清除间断前后及异常值后保留468535条样本。
采用2次训练的方法,第一次采用最大深度为3欠拟合模型进一步清洗脏数据。采用了xgboost与sklearn的GBDT模型训练,具体参数如下:
XGBoost-Round_1: 日销量仅作log处理,预训练后样本保留量为90%。
XGBoost-Round_2: 日销量仅作log处理后,采用过去三周的中位数作无量纲,预训练后样本保留量为75%。
4、 历史均值模型
输入:过去21天的历史销量,过去三周的销量相关度矩阵。
输出:未来2周的销量及其对应在模型融合中置信度。
方法:过去21天的按工作日平均,得到按工作日平均的均值销量。通过过去三周按周统计的销量中位数及平均值,做线性拟合得到销量增量。将历史均值销量叠加销量增量即得到未来2周预测销量。
由于方法本质上寻找历史上相似的(过去三周相关度较高)销量曲线作为未来预测,本质上为均值模型与KNN方法的结合。
置信度即为融合系数,仅当三周相关系数或后两周相关系数的最小值大于0.7时有效。均值模型的融合比例最大为0.75。
5、双11销量修正模型
模型概述:需要预测的时间段(11月1日到11月14日范围内)包含双11节日。从诸多商家的销量图上能明显看到在双11当天存在较大波动,可能的原因为网商促销对实体店的冲击,双11作为光棍节对于餐饮业的促进。然而仅有约1/3的商家存在2015年双11的销量记录,需要通过这部分商家去年双11信息,预测其余商家双11销量表现。
特征描述:仅包含商家特征,包含平均View/Pay比值,平均每天开店时间,关店时间,开店总时长;首次营业日期,非节假日销量中位数,节假日销量中位数,节假日/非节假日销量比值;商家类别,人均消费,评分,评论数,门店等级。
6、模型融合
多套gradient boosting的结果间的融合
xgboost1,xgboost2, GBDT三份结果按0.47, 0.34, 0.19 比例融合。
gradient boosting与均值模型融合
将均值模型结果与步骤1 gradient boosting 的结果融合,均值模型的融合系数为通过相关度得到的置信度。
双11系数进行销量调制
双11当天销量乘以双11销量修正模型得到的销量增量,11-12, 11-13由于为周六周日,有理由相信其销量与11-11(周五)的表现存在相似性, 因而乘以0.2及0.1倍的销量增量系数。
![]()
.
三、第一次参加Kaggle拿银总结——特征工程(FE)
截取特征工程部分,来源:http://scarletpan.github.io/summary-of-get-a-silver-medal-in-kaggle/
在对一些基础的特征进行生成之后,我开始了漫长地测试特征的长征路,测试的思路我后来发现并不是很好,因为是通过新增加一个或几个feature,如果cv分数上去了,就增加这个feature,如果cv分数没有上去,就舍弃这个feature,也就是相当于贪心验证。这样做的弊处在于,如果之前被舍弃的feature和之后被舍弃的feature联合在一起才会有正面影响,就相当于你错过了两个比较好的feature。因此特征的选择和联合显得非常关键。
数值型feature的简单加减乘除
这个乍一看仿佛没有道理可言,但是事实上却能挖掘出几个feature之间的内在联系,比如这场比赛中提供了bathrooms和bedrooms的数量,以及价格price,合租用户可能会更关心每个卧室的价格,即bathrooms / price,也会关心是不是每个房间都会有一个卫生间bathrooms / price,这些数值型feature之间通过算数的手段建立了联系,从而挖掘出了feature内部的一些价值,分数也就相应地上去了。
高势集类别(High Categorical)进行经验贝叶斯转换成数值feature
什么是High Categorical的特征呢?一个简单的例子就是邮编,有100个城市就会有好几百个邮编,有些房子坐落在同一个邮编下面。很显然随着邮编的数量增多,如果用简单的one-hot编码显然效果不太好,因此有人就用一些统计学思想(经验贝叶斯)将这些类别数据进行一个map,得到的结果是数值数据。在这场比赛中有人分享了一篇paper里面就提到了具体的算法。详细就不仔细讲了,用了这个encoding之后,的确效果提升了很多。那么这场比赛中哪些数据可以进行这样的encoding呢,只要满足下面几点:1. 会重复,2. 根据相同的值分组会分出超过一定数量(比如100)的组。也就是说building_id, manager_id, street_address, display_address都能进行这样的encoding,而取舍就由最后的实验来决定了。
时间特征
针对于时间数据来讲,提取年、月、日、星期等可能还是不够的,有另外一些points可以去思考,用户的兴趣跟发布时间的久远是否有关系?可以构造如下的feature来进行测试: python data[“latest”] = (data[“created”]- data[“created”].min()) python data[“passed”] = (data[“created”].max()- data[“created”])
可以看到latest指的是从有数据开始到该房创建为止一共过去了多少时间,而passed则是该房记录创建为止到最后有记录的时候一共过去了多少时间。
另外针对于时间特征还可以用可视化的方式来与其他特征建立联系,比如我们观察listing_id与时间变化到底有怎样的联系,能够绘制出如下的图来:

可能简单的相除就能获得很好的结果
地理位置特征
想到地理位置,就会想到聚类,一个简单的方式将每个房子划分到同一块区域中去;除了聚类以外,算出几个中心点坐标,计算曼哈顿距离或者欧式距离可能都会有神奇的效果。
文本特征
实话说自己是看中这次比赛中有文本数据才参加的,因此在文本挖掘中做了很大的努力,比如提取关键词、情感分析、word embedding聚类之类都尝试过,但效果都不是很好, 对于文本的特征的建议还是去找出一些除了停用词以外的高频词汇,寻找与这个房屋分类问题的具体联系。
图片特征
除了最后爆料出来的magic feature(后文会提到)以外,我只用了一个房子有几个照片这个信息。讨论区中都说对于图片特征用CNN提取、简单特征提取之类的效果都不是很好。
稀疏特征集
其实就相当于一系列标签,不同标签的个数也是挺多的,本次比赛我只是简单地采用了counterEncoding的方式进行one-hot编码。值得一提的是,有些标签是可以合并的,比如cat allowed 和 dog allowed可以合并成为 pet allowed,我在这场比赛中手工地合并了一些feature数据,最终结果略微有所提升。
特征重要程度(feature importance)
在树结构的分类器比如randomforest、xgboost中最后能够对每个特征在分类上面的重要程度进行一个评估。这时候如果已经选定了一些feature进行训练了之后,查看feature importance的反馈是非常重要的,比如本场比赛制胜的关键是运用manager_id这个feature,而它的feature importance反馈结果也是非常高。通过对重要特征的重新再提取特征,能够发现很多有意思的新特征,这才是用FE打好一场比赛的关键所在。
模型融合
如果你没有idea了的话,就模型融合吧!模型融合是能够快速提高比赛成绩的捷径,现在的比赛几乎没有人不用到这个技巧,通常获胜者会对很多很多模型进行融合,并且会选择不同的模型融合的方式。这里有一篇非常好的模型融合解析 博文 ,相信每个看过它的人都会对模型融合有一个清楚的了解
本次比赛中我使用了两种模型融合方式,一种是Averaging,一种是Stacking。
先来说说Stacking,因为这场比赛一名贡献比较大的选手分享了一个叫StackNet的库,作为新手我就直接用了。首先我用我的xgboost cv集交叉预测出结果作为feature的一部分放到train data中,再对test data进行预测的结果作为feature的一部分放到test data中,再在第二层上选择了Logistic Classifer,GradientBoostingClassifer,AdaBoostClassifer,NNSoftemaxClassfier,RandomForestClassifer等进行交叉预测,第三层选取了一个randomForest作为最后的结果训练和预测。Stacking主要增多了模型的diversity,使我的成绩上升了至少0.003的量级,
然后是Averaging,之前提到过Stacking需要交叉预测,我就选取了10组随机种子分别对训练集进行10-kfold交叉预测取平均,以及每个flod训练预测的时候我都对我的xgboost选取5个随机种子取平均。也就是说,在第一层Stacking的CV集交叉预测时我总共训练了500个模型进行平均。分数的提升大约在0.002左右。
直到比赛结束看了排名靠前的选手的模型融合后,才发现自己对于模型融合只是做了一点微小的工作,提升空间还非常大。详情可以看FE部分分享的solution链接。
.
四、推荐|分分钟带你杀入Kaggle Top 1%
来源文章《推荐|分分钟带你杀入Kaggle Top 1%》
比较新奇的几个心得记录如下:
.
1、错误分析
人无完人,每个模型不可能都是完美的,它总会犯一些错误。为了解某个模型在犯什么错误,我们可以观察被模型误判的样本,总结它们的共同特征,我们就可以再训练一个效果更好的模型。这种做法有点像后面Ensemble时提到的Boosting,但是我们是人为地观察错误样本,而Boosting是交给了机器。通过错误分析->发现新特征->训练新模型->错误分析,可以不断地迭代出更好的效果,并且这种方式还可以培养我们对数据的嗅觉。
举个例子,这次比赛中,我们在错误分析时发现,某些样本的两个问句表面上很相似,但是句子最后提到的地点不一样,所以其实它们是语义不相似的,但我们的模型却把它误判为相似的。比如这个样本:
Question1: Which is the best digital marketing institution in banglore?
Question2: Which is the best digital marketing institute in Pune?
为了让模型可以处理这种样本,我们将两个问句的最长公共子串(Longest Common Sequence)去掉,用剩余部分训练一个新的深度学习模型,相当于告诉模型看到这种情况的时候就不要判断为相似的了。因此,在加入这个特征后,我们的效果得到了一些提升。
.
2、特征工程
总结一下,我们抽取的手工特征可以分为以下4种:
Text Mining Feature,比如句子长度;两个句子的文本相似度,如N-gram的编辑距离,Jaccard距离等;两个句子共同的名词,动词,疑问词等。
Embedding Feature,预训练好的词向量相加求出句子向量,然后求两个句子向量的距离,比如余弦相似度、欧式距离等等。
Vector Space Feature,用TF-IDF矩阵来表示句子,求相似度。
Magic Feature,是Forum上一些选手通过思考数据集构造过程而发现的Feature,这种Feature往往与Label有强相关性,可以大大提高预测效果。
.
3、深度学习的不足与传统方法的优势
通过对深度学习产生的结果进行错误分析,并且参考论坛上别人的想法,我们发现深度学习没办法学到的特征大概可以分为两类:
对于一些数据的Pattern,在Train Data中出现的频数不足以让深度学习学到对应的特征,所以我们需要通过手工提取这些特征。
由于Deep Learning对样本做了独立同分布假设(iid),一般只能学习到每个样本的特征,而学习到数据的全局特征,比如TF-IDF这一类需要统计全局词频才能获取的特征,因此也需要手工提取这些特征。
传统的机器学习模型和深度学习模型之间也存在表达形式上的不同。虽然传统模型的表现未必比深度学习好,但它们学到的Pattern可能不同,通过Ensemble来取长补短,也能带来性能上的提升。因此,同时使用传统模型也是很有必要的。
.
五、多标签图像分类
来源:开发 | Kaggle亚马逊比赛冠军专访:利用标签相关性来处理分类问题
原文链接:Planet: Understanding the Amazon from Space, 1st Place Winner’s Interview
这是一个图像多标签预测的问题,来看看作者的模型:
![]()
精细调节了11个卷积神经网络(CNN),得到每个CNN的类别标签概率。比赛中我用到了一些流行的、高性能的CNN,例如ResNets、DenseNets、Inception和SimpleNet等。
再来看看作者 的模型集成:
![]()
可以看到11个模型出来的结果,并排,然后接一个ridge层,得到每个分类的最佳得分,从而确定最终分类。
.
六、语言习得建模
来源:动态 2018 NAACL语言学习建模竞赛:英语组冠军先声教育展望自适应学习技术
今年 BEA 有两个公开任务,一个是单词复杂度识别(Complex Word Identification),一个是第二语言习得建模(Second Language Acquisition Modeling)。第二语言习得建模是指根据学生过去的答题 (第二语言学习) 历史,预测该学生能否对未来的题目作出正确应答。
先声教育 CTO采用的是:
CLUF 是一种基于深度学习的 Encoder-Decoder 模型,它由四个 encoder 构成,分别是语境编码器 Context Encoder、语言学特征编码器 Linguistic Encoder、用户信息编码器 User Encoder、题型信息编码器 Format Encoder,最后由解码器利用编码器输出的高维特征作出预测。
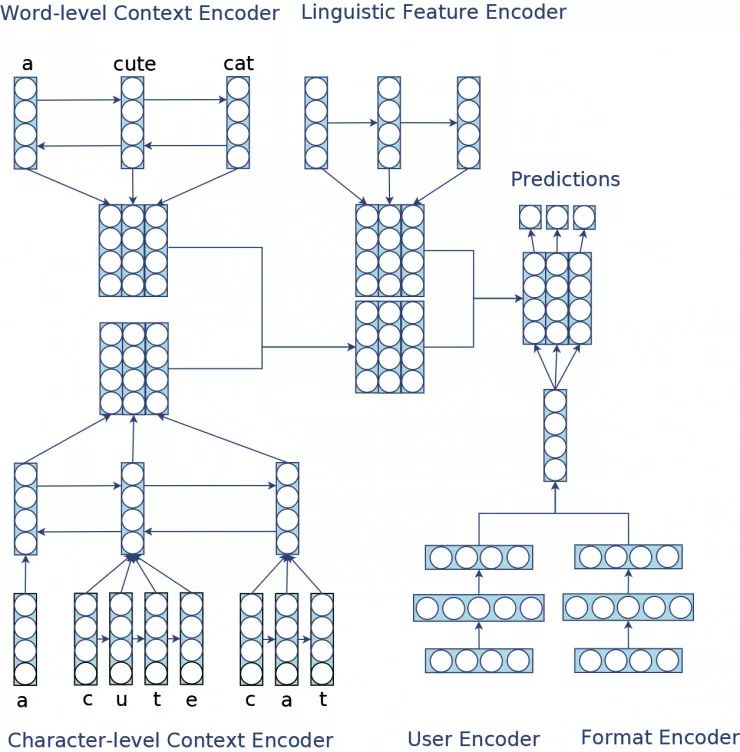
第二名采用的是:
- 纽约大学也取得了不错的成绩。他们的系统会提取用户、词汇、上下文等基于认知科学、语言学的特征,然后使用梯度提升决策树 GBDT
模型进行建模。 - 在西班牙和法语学习中取得最好分数的是来自于瑞典的 SanaLabs,他们采用了 ensemble
的方法,也就是使用多个不同的模型进行预测,然后对多个模型的预测结果进行加权组合的方法。
七、Kaggle avito方案分享-竞赛中的多源异构神经网络和迁移学习
avito是俄罗斯的二手交易网站,类似中国的咸鱼,如果有一个AI,可以给你做归因分析,指导你定价,告诉你成交概率岂不是美滋滋?
这是SEO的一种思路,如何猜query中的hot words,比如这个标题里插入几个词,Kaggle,神经网络,迁移学习,多源异构。
赛题链接 https://www.kaggle.com/c/avito-demand-prediction
综合类数据比赛:kaggle上第一次出现文本,图像,结构化数据及时间序列的比赛。
根据我的体验,在结构化数据上的特征工程是最重要的,收益最大,其次是文本,再是图像。
这里面有个原因是,结构化数据中有个强特image_top1(avito的分类结果),所以一定程度上削弱了原始图像的作用。
这也很好理解,你在咸鱼发布一个东西,描述吸引人,图片漂亮,品类是热点,就很容易卖出去。
特征工程:模型千千万,不如一个分布差异明显的特征来的实在。
其中很值得思考的问题是定位策略:
- 钻石:你大概能体会到一个品类的均价和你定价的差值能影响到他的销量,暗示你定价是否合理。
- 王者:第一名分享里小舟再进一步,想到了一个黑科技,如何刻画一个商品最合理定价?如何刻画你和最合理定价的偏差?我们在最后一部分的迁移学习里面讲解。
特征工程的常规套路:
图像:
- a.数据简单的时候,可以用ResNet等fintue。这样的代价是这个网络本身就很大了,单一的信息也不充分,只用图像和target搞学习到的怕是奇怪的东西。
- b.用pre-trained的模型抽特征,用中间层的结果或者fc前pooling出来的结果使用。或者是做一个稍微简单一点的模型。用原始的像素信息。
- c.用pre-trained的分类结果作为ID类型做embedding
- 图像也有一些meta信息,可以作为FE的部分送进网络,长宽/RGB/亮暗/模糊性/关键点坐标…
文本
- a.文本分类模型并联: Embedding(fasttext/Glove/w2v X char/subword/word level) +
LSTM/GRU/CNN - b.矩阵(tfidf/wc/pretrianed embedding) 可以加 降维(LDA/SVD/PCA)
- 当然文本也有一些meta信息,可以作为FE的部分送进网络,长/数量/用词丰富度/各词性实体统计/…
一些特殊操作
这次神经网络最大的收益是来自于这样一个操作,吸收DeepFM的思想,在类别型变量的embedding上做一次交叉element-wise的乘法(对应元素相乘),这个结果如果加起来,就是FM公式中的二次项来源,但是加起来相当于把信息压缩到一个值,我试验的时候不如连起来效果好。这样信息保留的充分一些。
八、北邮夺冠CVPR 2018 DeepGlobe比赛,他们是这样做卫星图像识别的
比赛的任务是将卫星图像中的道路部分提取出来,即将每个属于道路部分的像素点标注为道路,其他部分标注为背景(属于一个二元分割的问题)。
比赛分为三个子任务:卫星图像道路提取(84队参与)、房屋提取(26队参与)以及地表覆盖分类(38队参与)。

数据扩增-图像形态变换:
①、随机翻折:包含水平、竖直、对角线三种翻折方式,每张图片扩增为原来的8倍。
②、随机缩放:将图像随机缩放至多10%。
③、随机偏移:将图像随机上下左右偏移至多10%。
④、随机拉升:将图像随机沿竖直方向或水平方向拉升至多10%。
经过以上四种变换之后,再截取图像中心1024*1024的部分,不足的部分补0。
数据扩增-图像色彩变换:
使用OpenCV,在HSV空间对图像进行色彩变换。在OpenCV中,每个像素的HSV保存在uint8的数据类型中(0~255)。
①、H空间,随机变换(-15~15)。
②、S空间,随机变换(-15~15)。
③、V空间,随机变换(-30~30)。
模型结构D-LinkNet
使用在ImageNet数据集上与训练好的ResNet作为网络的encoder,并在中心部分添加带有shortcut的dilated-convolution层,使得整个网络识别能力更强、接收域更大、融合多尺度信息。
预测
由于卫星图像具有翻折和旋转不变性,在测试时,我们将图像进行水平、竖直、对角线三种翻折,每张图片预测8次,然后将8次的结果平均。(我们没有旋转图片是出于预测时间的考虑)
代码及PPT:https://github.com/zlkanata/DeepGlobe-Road-Extraction-Challenge
九、图像分类比赛中,你可以用如下方案举一反三
图像的可视化,方便对图像进行认知:
决定使用 t 分布随机邻域嵌入(https://lvdmaaten.github.io/tsne/)可视化技术来查看图片的分布。
t 分布随机邻域嵌入(t—SNE)是一种特别适合对高维数据集进行可视化的降维技术。这种技术可以通过「Barnes-Hut」近似算法来实现,这使得它能够被应用于大型的真实数据集。[14
]
不平衡数据的处理:
模型在样本数量较少的类别上的并不好。
针对不平衡学习的自适应样本合成方法(ADASYN):ADASYN 为样本较少的类生成合成的数据,这种方法会生成更多较难学习的数据集样本。
ADASYN 的核心思想是,根据学习的困难程度,对样本数少的类别实例使用加权分布。ADASYN
通过两种方法提高了对数据分布的学习效果:(1)减少类别的不平衡所带来的偏差。(2)自适应地将分类的决策边界转换为更困难的样本。[5]少数类过采样技术(SMOTE):SMOTE 包括对少数类的过采样和多数类的欠采样,从而得到最佳抽样结果。
我们对少数(异常)类进行过采样并对多数(正常)类进行欠采样的做法可以得到比仅仅对多数类进行欠采样更好的分类性能(在 ROC 空间中)。[6]
在此用例中,可以证明 SMOTE 算法的结果更好,因此 SMOTE 的性能优于 ADASYN 算法。
学习率的新方法——周期性学习率
实际上让我们不必再通过大量实验找到全局学习率的最优值和最佳学习计划。这种方法并不是单调地减小学习率,而是让学习率周期性地在合理的边界值之间变化。利用周期性学习率代替固定的学习率进行训练,能够有效地在不用进行调优的情况下提升分类准确率,需要的迭代次数往往也更少。[11]
其他一些新的技巧:
为快照集成(snapshot ensembling)的技术,通过训练一个单一神经网络来达到集成目的,并且沿着优化路径收敛到几个局部最小值,最终将模型参数保存下来。
十、论文 用迁移学习解释:电商网站的用户评论应如何优化排序?
电子商务网站的用户评论数量不断增加,如何估计评论的有用性并将其恰当地推荐给消费者。
- 难点:样本比较少(评价较少)的或有OOV(out-of-vocabulary)问题的领域
- 解决:
- 1、样本小的问题,我们主要利用基于特征迁移的迁移学习的技术来从其他领域里学习一些知识去帮助我们所感兴趣的领域
- 2、提出了一种基于卷积神经网络(CNN)的模型,它利用了基字和字符层面的表示来克服OOV问题(字向量)
常规评论排序:
过去大量的评论排序都是基于时间,点赞次数等。现在有些网站开始尝试基于评论的有用性来进行排序。
大多依赖使用专家经验和语义特征。例如,LIWC,INQUIRER和GALC等语义特征(Yang et al.,2015; Martin and Pu,2010),基于aspect的(Yang et al.,2016)和基于argument特征(Liu et al.,2017a)
问题:需要大量的标记样本去更好的训练模型、解决不了OOV问题
模型:TextCNN+Adversarial Learning
- TextCNN主要分这几步: 查找词嵌入(word embedding),给输入的文本的每个词映射到一个词嵌入。
把评论文本句子中的每个词拆解成字符然后再组合一起输入到一个卷积层(convolutional
layer)和一个最大池化层(max-pooling layer)去学习出一个定长的字符嵌入(character embedding)。
最后合并生成的词嵌入和字符嵌入,一起作为输入到卷积神经网络。 - specific shared的框架
什么时候迁移学习最有效
我们这里发现我们的方法对于某些数据小的领域提升比较大(如上图),于是我们做了个实验去分析目标领域的数据大小对于迁移的有效性的影响。同样的,我们用Electronics(数据最多)作为源领域,outdoor作为目标领域。我们改变目标领域数据大小(从10%到100%),然后观察不同的比例数据下迁移的有效性。效果如下图所示:
很明显仅使用10%或者30%目标领域数据的情况下,迁移带来的提升越明显,说明我们的迁移学习的方法对于训练数据越少的目标领域帮助越大。
在全量的目标数据上(100%),我们的方法反而出现了略微的效果的降低。这个说明如果目标领域数据足够的话,其实仅用目标领域数据就可以训练一个不错的模型,这个时候迁移学习带来的收益比较微小。
十一:如何从数据挖掘比赛中脱颖而出?快来 get 阿里妈妈广告算法赛亚军套路吧!(内附代码和数据链接)
- 原文:如何从数据挖掘比赛中脱颖而出?快来 get 阿里妈妈广告算法赛亚军套路吧!(内附代码和数据链接)
- github:https://github.com/YouChouNoBB/ijcai-18-top2-single-mole-solution
本赛题为搜索广告转化预估问题,一条样本包含广告点击相关的用户(user)、广告商品(ad)、检索词(query)、上下文内容(context)、商店(shop)等信息的条件下预测广告产生购买行为的概率(pCVR),形式化定义为:pCVR=P(conversion=1 | query, user, ad, context, shop)。可以将问题抽象为二分类问题,重点对用户,商品,检索词,上下文,商店进行特征刻画,来训练模型。
数据特征:通过数据分析我们发现,训练数据的前 7 天转化率维持在 1% 左右,但是在 6 号转化率偏低,在预测当天 7 号的上午转化率超过 4%,所以这是一个对特定促销日进行预测的问题。重点需要刻画用户,商品,店铺,检索词等关键信息在预测日前面 7 天的行为,预测日前一天的行为,预测日当天的行为。
- 缺失值填充:id 类特征使用众值填充,数值特征均值填充
- 模型设计:3 种数据划分方式训练模型,主模型使用 7 号上午的数据作为训练样本,对 31-5 号,6 号,7
号的数据提取特征。全局数据模型使用全部带标签的样本作为训练样本,使用全部数据提取特征。时间信息模型使用 31-6 号的数据作为训练样本,对
31-6 数据提取特征。训练的时间信息模型对 7
号全天的样本进行预测,将预测结果(携带了时间信息)作为新的特征添加到前面的模型中,来弥补前面模型对时间刻画的缺失。
![]()
- 特征工程
特征工程是模型提分的关键,我们从简单到复杂建立了基础特征群,转化率特征群,排名特征群,比例特征群,类特征群,竞争特征群,业务特征群等多种特征群,对用户及行为进行了细致的刻画。
![]()
- 模型特征: 选择了 LightGBM 模型,因为数据量少,训练快,可以在线下快速迭代。在实际业务中,使用的更多的模型可能是
LR,FFM,DNN
之类的模型,实际业务的数据是海量的,这些模型更能学习到稳定鲁棒的参数,并且预估速度更快。由于正负样本比例悬殊,如果考虑训练效率的话,其实也可以对负样本进行采样后训练,比如
LR 模型训练之后通过对截距项的修正,依然可以保持预估的数据符合实际分布。
十二:IJCAI 2018 广告算法大赛落下帷幕,Top 3 方案出炉
IJCAI-18 阿里妈妈搜索广告转化预测比赛近日落下帷幕
相关内容开源在github:https://github.com/luoda888/2018-IJCAI-top3
提出了四种训练集划分:
1. 全量统计特征提取第七天特征——all-to-7
2. 全量数据的抽样统计——sample
3. 单独第七天的特征提取——only7
4. 全量数据——all
特征工程:
首先执如下三步操作:
上述基础特征分列
去掉取值变化小的列
去掉缺失值过多的列
![]()
特征选择:
罗宾理同学在GitHub的开源代码,利用贪心、模拟退火算法,构造出多组特征,适用于组内模型融合。
2)利用 Std/Mean 训练集测试集分布一致的思想,进行特征选择,保证线上线下特征的一致性。
模型选择及融合
Xgboost/Lightgbm/GBDT+LR/Catboost/NN 模型
在 NN 模型里,使用对多个模型求 Average 的方法,使用的模型如下:
- DeepFM/DeepFFM (原始 ID 特征放入交叉层) 与 Lightgbm 线下差距 0.0001 (千分点)
- AFFM/AFM (对原始 ID 特征加入 Attention) 与 Lightgbm 线下差距 0.00001 (万分点)
- FNN/FFNN/NFM (将特征工程后放入网络结构) 与 Lightgbm 线下差距 0.0001 (千分点)
IJCAI 2018国际广告算法大赛迁移学习夺冠,中国包揽冠亚季军
1、第一名
DOG对方案最大的特点整体非常简洁,设计思路清晰。针对这次比赛中测试数据和训练数据分布差异的问题,这个方案采用了一些迁移学习的方法利用训练数据。没有暴力地去融合很多特征,而是针对数据特性做了很简洁的特征设计。
![]()
使用了统计特征、时差特征、排序特征和表征特征这四种。
- 统计特征就是用户点击的次数,看过的页数,搜索的小时,还有点击的品类的个数。
- 时差是用户与商品item交互的时间距离;在真实的场景中,我们只能用到用户距离上次的时间,拿不到下次的时间,在整个比赛中,这有一定程度的数据穿越,所以最终采用的是用户点击某一个品类,距离上次的时间和下次的时间。
- 排序特征是用户user与商品item的交互次数。
- 表征特征,用户对商品的哪些属性感兴趣,点击的ITEM有哪些属性,这样交互的特征越接近,购买的概率就越大。
![]()
2、第二名
强东队则试图用end2end的深度学习来解CVR预估问题
不等长多值Field特征通过padding补成等长输入到Embedding层对原始稀疏特征进行映射
![]()
十三、16岁Kaggle老兵夺冠Kaggle地标检索挑战赛!
解决方案包含两个主要的组件:第一个是创建一个高性能的全局描述子,以用奇异值向量表征数据集中的图像,第二个组件即构建一个高效的策略以匹配这些向量,从而搜索到最可能的匹配条目,并提交到排行榜。
最亮眼应该是花式提取图像特征子:
![]()
全局描述子:
- 基于区域熵的多层抽象池化(REMAP)[42.8%mAP]:这是我们全新设计的全局描述子,它聚合了来自不同卷积层的层级化深度特征,并训练表征多个互补的层级视觉抽象。我们计划在即将来到的
- CVPR Workshop 中展示 REMAP 架构的细节。 最大卷积激活值(MAC)[32.9% mAP]:MAC 描述子编码了最后层中每一个卷积核的最大局部响应。在 MAC 架构中,ResNeXt 的最后卷积层会接一个最大池化层、L2 正则化层和 PCA+白化层。
- 卷积的池化和(SPoC)[31.7% mAP]:在 SPoC 流程中,ResNeXt 的最后卷积层会接一个池化求和层、L2 正则化层和 PCA+白化层。
- 卷积的区域最大激活值(RMAC)[34.7% mAP]:在 RMAC 中,ResNeXt 的最后卷积特征图是通过在多尺度重叠区域上做最大池化而得出。基于区域的描述子是 L2 正则化、PCA+白化和另一个 L2 正则化,描述子最后会求和汇聚到一个单描述子。
最近邻搜索
在创建好描述子之后,每张图像都用 4096 维的描述子来表征。接下来,我们使用穷尽 k 最近邻搜索来找出每张图像的 top 2500 近邻和 L2 距离。在这一阶段提交每张测试图像的 top 100 近邻获得了 47.2% 的分数。
这一步使用优化 NumPy 代码来实现,耗时两小时为 120 万张图像中的每一张找出 top 2500 近邻(我们需要索引集执行最近邻,以备后续使用)。
十四:预测不了世界杯比分,就预测百威啤酒销量,送数据竞赛冠军笔记
预处理:
异常值判断:历史上某些值的平均值,比他两三个标准差偏差还要多的话,会认为异常值
预测值做Log处理
特征工程:
- 聚类方法:或者把标签当做特征加进去。
- 衍生变量:日期衍生(是否是节假日,本周的节假日有几天,距离下一个工作日有几天)、商品、门店属性、各类高级计算。新商品从第一天开始售卖,累计的销售天数。
- 高级的特征处理方式:GBDT生成特征,每棵树的权重作为一种特征,在树模型之中比较常见; Embedding的方法,如word2vec一样
使用的时序库:
时间预测模型的示意图:GAM库
模型评估:
树模型:对于离群值的鲁棒性较好;数据分布要求低;可以作为金模型,把精简之后的特征,给一些简单的模型,譬如LR
深度学习:google的wide and deep models,deep models那层要求输入是密集型的,稀疏是不能直接做输入的,所以要做转换,有的用Embedding等来做转换
超参数的调整
- 1.启发式调优 用经验。比较简单的是用启发式的调优,先固定一个比较大的learning rate去调树的数量、树的深度、叶子节点分页需要的条件之类的。
- 2.网格搜索 把所有想要尝试的参数写下来。网格搜索自动把所有的组合尝试一遍,帮你找到最优的组合,把最优的结果返回给你。
- 3.贝叶斯优化 把超参数搜索的过程看成高斯过程,库会自动尝试不同参数,然后寻找下一个最可能出现比较低的loss的尝试,搜索空间的计算量比网格搜索小很多。
Recording︱有价值的各类AI、机器学习比赛心得、经验抄录相关推荐
- 时雨月五| AI机器学习实战の电磁导航智能车中神经网络应用的问题与思考
"不愤不启,不悱不发.举一隅不以三隅反,则不复也". – <论语·述而> 再次将论语中的这句"不愤不启,不悱不发"引用在这里,说明学生的学习的活动部 ...
- Ai关于目标检测类算法比赛的经验总结
内容来源于 宅码,作者Ai. 附一张作者签名--艾宏峰! 导读: 本文为作者自己参加的三个目标检测类算法比赛的经验总结,分为五个部分:数据研究和准备.参数调节.模型验证以及模型融合,作者还给出了一些关 ...
- 2019机器学习比赛_2019顶尖的机器学习课程
2019机器学习比赛 With strong roots in statistics, Machine Learning is becoming one of the most interesting ...
- AI机器学习实战の电磁智能车篇
简 介: 本文在这里向大家介绍我们在RT106x的小车上部署实施AI的方法,以及一个base line的电磁导引神经网络模型,希望能抛砖引玉,激发同学们开动脑筋,将AI在电磁智能车上的应用发扬光大. ...
- 从零开始机器学习比赛经验(bird分享)
视频地址:https://pan.baidu.com/s/1b25yNG 机器学习比赛入门条件 1.过的去的code能力:Leetcode平台 leetcode平台可以帮助我们提高基本的算法实现能力, ...
- AI:一个20年程序猿的学习资料大全—人工智能之AI/机器学习/深度学习/计算机视觉/Matlab大赛——只有你不想要的,没有你找不到的
AI:一个20年程序猿的学习资料大全-人工智能之AI/机器学习/深度学习/计算机视觉/Matlab大赛--只有你不想要的,没有你找不到的 目录 (有偿提供,替朋友转载,扫描下方二维码提问,或者向博主扫 ...
- Azure人工智能认知服务(AI·机器学习)
最近CSDN开展了<0元试用微软 Azure人工智能认知服务,精美礼品大放送>,当前目前活动还在继续,热心的我已经第一时间报名参与,只不过今天才有时间实际的试用. 目前我在试用了 语音转文 ...
- 五位专家跟你讲讲为啥Python更适合做AI/机器学习
摘要: 为什么Python会在这股深度学习浪潮中成为编程语言的头牌?听听大牛如何解释吧! 原文地址:http://click.aliyun.com/m/43988/ 1.Python网络编程框架Twi ...
- python和lisp学哪个好_五位专家跟你讲讲为啥Python更适合做AI/机器学习
摘要: 为什么Python会在这股深度学习浪潮中成为编程语言的头牌?听听大牛如何解释吧! 1.Python网络编程框架Twisted的创始人Glyph Lefkowitz(glyph): 编程是一项社 ...
- csp-j 2022 比赛心得
csp-j 2022 比赛心得 昨天在长沙打了 csp−jcsp-jcsp−j 202220222022 普及组第二轮,深有感触,用一个字形容就是:差!!! 本次考试,我认为我还有许多缺陷需要改正,也 ...
最新文章
- Redis Server Memory Optimization
- oracle中12523,【Oracle】静态监听导致的ORA-12523错误
- 对视觉任务更友好的Transformer,北航团队开源Visformer!
- Spring整合Activiti工作流
- 使用这些思路与技巧,我读懂了多个优秀的开源项目
- Camtasia 2020软件的媒体库介绍
- Asp.net对http request 处理的全过程!
- 经典游戏扫雷详解--你也可以写出扫雷和玩好扫雷
- buck电路的matlab仿真,buck电路simulink仿真
- 如何从零开始刷力扣算法题--2020年12月中旬
- 2017计算机办公自动化试题,【2017年整理】计算机办公自动化试题.doc
- 供应链:WMS库内管理设计
- linux小记 查看dd进度,linux小记:查看dd进度
- 阿里云域名配置以及https证书(ssl证书)配置
- 迭代模型(Iterative Model)
- 本地Ping不通华为云服务问题解决
- iOS更新之DFU模式和恢复模式
- useCallback包裹函数,但是使用到的外部变量一直是最开始的值
- Inversion Lemma
- SpringBoot使用分布式锁