Map实现之HashMap(结构及原理)(转)
java.util包中的集合类包含 Java 中某些最常用的类。最常用的集合类是 List 和 Map。List 的具体实现包括 ArrayList 和 Vector,它们是可变大小的列表,比较适合构建、存储和操作任何类型对象元素列表。List 适用于按数值索引访问元素的情形。
Map 则提供了一个更通用的元素存储方法。Map 集合类用于存储元素对(称作“键”和“值”),其中每个键映射到一个值。从概念上而言,您可以将 List 看作是具有数值键的 Map。而实际上,除了 List 和 Map 都在定义 java.util 中外,两者并没有直接的联系。
Map接口的实现类有很多,其中HashMap就是比较重要的一个实现,本文就以HashMap为主重点介绍。
HashMap是基于哈希表的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。(除了非同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
HashMap结合了ArrayList与LinkedList两个实现的优点,,虽然HashMap并不会向List的两种实现那样在某项操作上性能较高,但是在基本操作(get 和 put)上具有稳定的性能。
首先从成员变量开始一点点的来了解HashMap和上述几个概念。
1.HashMap的成员变量:

- /**
- * 初始默认容量(必须为2的幂次方)
- */
- static final int DEFAULT_INITIAL_CAPACITY = 16;
- /**
- * 最大容量,如果被指定为一个更高的值必须为2的幂次方,并且小于1073741824.(1<<30)
- */
- static final int MAXIMUM_CAPACITY = 1 << 30;
- /**
- * 默认负载因子/负载系数
- */
- static final float DEFAULT_LOAD_FACTOR = 0.75f;
- /**
- * 内部实现表, 必要时调整大小,其长度亦为2的幂次方
- */
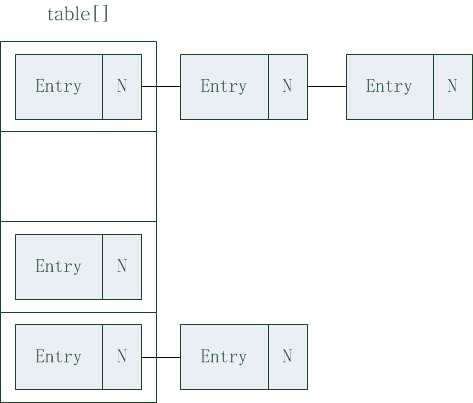
- transient Entry[] table;
- /**
- * map中添加的元素个数
- */
- transient int size;
- /**
- * 扩容临界值,当size达到此值时进行扩容 (容量乘以负载因子).
- */
- int threshold;
- /**
- * 内部实现表的负载因子
- */
- final float loadFactor;
- /**
- * 操作数,可以理解为map实例被操作的次数,包括添加,删除等等
- */
- transient volatile int modCount;
HashMap其内部实现是一个Entry数组table,而Entry就是保存相应键值的实体。table数组默认大小为16,我们也可以在初始化时指定更大的值,但指定值必须为2的幂次方。
通过对ArrayList的学习了解到ArrayList其内部实现也是数组,当被添加的元素超出数组的容纳极限时,ArrayList会对内部数组进行一次“扩容”,从而可以添加新的元素。
在HashMap中也有类似的概念,HashMap并不会像ArrayList一样直到数组都满了的情况下才去“扩容”,而是根据负载因子(load factor)来进行判断。
举例来说:HashMap实例中table数组的默认大小为16,负载因子为0.75,当添加元素个数大于等于12(16*0.75)时就会进行扩容。
所以说容量和负载因子直接影响着table数组是否扩容,什么时机扩容,进而影响这HashMap实例的性能。
当我们在初始化时可以指定HashMap实例的容量大小,当指定大小不为2的幂次方时,如下:
- Map map=new HashMap(131);
请问初始化完成HashMap内table的长度是多少? 答案为:256
其实只要打开HashMap的构造函数源代码就明白为什么了,以下为源代码:
- public HashMap(int initialCapacity, float loadFactor) {
- if (initialCapacity < 0)
- throw new IllegalArgumentException("Illegal initial capacity: "
- + initialCapacity);
- if (initialCapacity > MAXIMUM_CAPACITY)
- initialCapacity = MAXIMUM_CAPACITY;
- if (loadFactor <= 0 || Float.isNaN(loadFactor))
- throw new IllegalArgumentException("Illegal load factor: "
- + loadFactor);
- // Find a power of 2 >= initialCapacity
- int capacity = 1;
- while (capacity < initialCapacity)
- capacity <<= 1;
- this.loadFactor = loadFactor;
- threshold = (int) (capacity * loadFactor);
- table = new Entry[capacity];
- init();
- }
关键在于这两行:
- while (capacity < initialCapacity)
- capacity <<= 1;
如果initialCapacity(指定大小)大于capacity(原或初始化大小)时,就会不断循环进行位移赋值计算,相当于capacity=capacity *2.直至capacity 大于或等于我们指定的大小。如果指定的大小正好为2的N次幂时两个值便会相等,进而终止计算;如果指定大小不符合条件时,capacity 就会是刚好大于指定大小的那个2的N次幂的数。
所以,在上面我们指定大小为131,大于131并且为2的的N次幂的数就为256,所以此时就会按256来初始化table.
2.Entry 元素
与LinkedList类似,HashMap也是采用Entry内部类来存储实际元素信息,以下是Entry的源代码(省略部分代码):
- static class Entry<K, V> implements Map.Entry<K, V> {
- final K key;
- V value;
- Entry<K, V> next;
- final int hash;
- }
Entry中包括4个成员变量,其中key为键,value为值,next指向下一个节点元素,hash为hash值。Entry通过next属性可以寻找到下一个节点的元素,进而通过遍历就可以找到相应key下存储的信息。
3.HashMap设置元素
Map通过put方法来在Map实例中关联指定值与指定键。如果该实例已经包含了一个该键的映射关系,则旧值被替换。
示例如下:
- Map map = new HashMap();
- map.put("user1", "小明");
- map.put("user2", "小强");
- map.put("user3", "小红");
- System.out.println("user1:" + map.get("user1"));
- System.out.println("user2:" + map.get("user2"));
- System.out.println("user3:" + map.get("user3"));
- map.put("user2", "小龙");
- System.out.println("user1:" + map.get("user1"));
- //打印结果
- user1:小明
- user2:小强
- user3:小红
- user1:小明
首先,创建了一个HashMap的实例map,此时map实例中的table数组会默认初始化,创建一个长度为DEFAULT_INITIAL_CAPACITY=16的空数组。
然后,调用put方法将一对键、值(key,value)保存。当已存在Map实例中已存在指定key的映射时,会将新指定的value覆盖原value。
与LIst的相关实现add方法一样,HashMap的put方法是设置元素的入口,在put的过程中会进行一系列的判断与操作,所以只有将put方法理解透彻后HashMap的内部结构与机制才会更加清晰。
HashMap进行put操作时按以下步骤执行:
1)判断key是否为空,如果为空则调用设置null的专有方法。
2)计算key的hash值。
3)通过hash与table数组的长度计算出该元素所要放置的数组下标。
4)遍历该下标下的Entry元素链,如果找到与指定key相同的Entry则直接替换该Entry的value值并返回。
5)如果未找到则添加一个新元素至该下标下的元素链前端。
以下是一张官网上对于put操作流程的描述图片,可以作为参考:
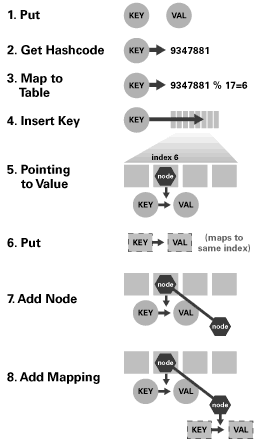
以下是put方法的源代码,其中我已经加入了相关描述便于大家理解:
- /**
- * 设置指定值
- */
- public V put(K key, V value) {
- //1.首先判断key是否为null
- if (key == null)
- //如果为null则调用putForNullKey方法
- return putForNullKey(value);
- //2.计算key的hash值
- int hash = hash(key.hashCode());
- //3.根据计算后的hash值与table数组长度计算该key应放置到table数组的那个下标位置
- int i = indexFor(hash, table.length);
- //4.遍历该下标下的所有Entry,如果key已存在则覆盖该key所在Entry的value值
- for (Entry<K, V> e = table[i]; e != null; e = e.next) {
- Object k;
- if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
- V oldValue = e.value;
- e.value = value;
- e.recordAccess(this);
- return oldValue;
- }
- }
- modCount++;
- //5.如果该key不存在则新添加Entry元素至数组指定位置,并且该Entry作为此下标元素链的头部
- addEntry(hash, key, value, i);
- return null;
- }
- this.loadFactor = DEFAULT_LOAD_FACTOR;//0.75f
- threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);//16*0.75=12
- table = new Entry[DEFAULT_INITIAL_CAPACITY];//16
- Entry<K,V> e = table[bucketIndex];
- table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
- for (Entry<K,V> e = table[i]; e != null; e = e.next) {
- Object k;
- if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
- V oldValue = e.value;
- e.value = value;
- e.recordAccess(this);
- return oldValue;
- }
- }
如果HashMap实例中已经put了该key则只需遍历找到该节点Entry,更新其value并返回,所以更新已有key的操作不会调用addEntry方法。
 HashMap采用此种存储元素的方式是结合了ArrayList与LinkedList两者的优点,虽然单纯某项操作的性能上并不比二者之一高,但这种方式的好处就是存储与获取性能平稳,并不会出现剧烈波动的情况。
HashMap采用此种存储元素的方式是结合了ArrayList与LinkedList两者的优点,虽然单纯某项操作的性能上并不比二者之一高,但这种方式的好处就是存储与获取性能平稳,并不会出现剧烈波动的情况。
- /**
- * 返回指定key的value
- */
- public V get(Object key) {
- // 1.判断可以是否为null
- if (key == null)
- return getForNullKey();
- // 2.计算key的hash值
- int hash = hash(key.hashCode());
- // 3.遍历table指定下标下的Entry链
- for (Entry<K, V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) {
- Object k;
- // 4.如果找到则返回该Entry的value
- if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
- return e.value;
- }
- // 5.未找到则返回null
- return null;
- }
6.HashMap移除元素
- Map map = new HashMap();
- map.put("user1", "小明");
- map.put("user2", "小强");
- map.put("user3", "小红");
- map.remove("user2");
- System.out.println("user1:" + map.get("user1"));
- System.out.println("user2:" + map.get("user2"));
- System.out.println("user3:" + map.get("user3"));
- //打印结果:
- user1:小明
- user2:null
- user3:小红
当主动调用remove方法时,会根据指定的key删除该节点元素。
- /**
- * 删除指定key下内容
- */
- public V remove(Object key) {
- Entry<K, V> e = removeEntryForKey(key);
- return (e == null ? null : e.value);
- }
- /**
- * 根据指定key删除元素
- */
- final Entry<K, V> removeEntryForKey(Object key) {
- int hash = (key == null) ? 0 : hash(key.hashCode());
- int i = indexFor(hash, table.length);
- Entry<K, V> prev = table[i];
- Entry<K, V> e = prev;
- while (e != null) {
- Entry<K, V> next = e.next;
- Object k;
- if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) {
- modCount++;
- size--;
- if (prev == e)
- table[i] = next;
- else
- prev.next = next;
- e.recordRemoval(this);
- return e;
- }
- prev = e;
- e = next;
- }
- return e;
- }
remove方法调用了另一个方法removeEntryForKey,removeEntryForKey方法会循环遍历指定下标下所有Entry节点元素,如果该key存在则修改该节点前一个节点的next指向,从而达到把该Entry节点移除Entry链的目的。
- Map map = new HashMap();
- map.put("user1", "小明");
- map.put("user2", "小强");
- map.put("user3", "小红");
- Iterator iter = map.entrySet().iterator();
- while (iter.hasNext()) {
- Map.Entry entry = (Map.Entry) iter.next();
- Object key = entry.getKey();
- Object value = entry.getValue();
- System.out.println("key:" + key + ";value:" + value);
- // 然后移除元素
- if (key.toString().equals("user1")) {
- iter.remove();
- } else if (key.toString().equals("user2")) {
- entry.setValue("小海");
- }
- }
- System.out.println(map.get("user1"));
- System.out.println(map.get("user2"));
- System.out.println(map.get("user3"));
- // 打印结果:
- key:user2;value:小强
- key:user1;value:小明
- key:user3;value:小红
- null
- 小海
- 小红
此种方式操作简单,代码量少,效率较高,且可以直接操作元素,是常用的手段之一。
- Map map = new HashMap();
- map.put("user1", "小明");
- map.put("user2", "小强");
- map.put("user3", "小红");
- Iterator iter = map.keySet().iterator();
- while (iter.hasNext()) {
- Object key = iter.next();
- Object value = map.get(key);
- System.out.println("key:" + key + ";value:" + value);
- // 然后移除元素
- if (key.toString().equals("user1")) {
- iter.remove();
- }
- }
- System.out.println(map.get("user1"));
- System.out.println(map.get("user2"));
- System.out.println(map.get("user3"));
- // 打印结果:
- key:user2;value:小强
- key:user1;value:小明
- key:user3;value:小红
- null
- 小强
- 小红
此种方式先需要将所有key遍历后返回,再通过get方法来获取元素,如果单纯需要操作Map实例中的个别节点元素时效率尚可,如果需要大规模获取和修改时效率不如第一种。所以两种方式选择那种需要视情况而言,并没有绝对。
- Map map = new HashMap();
- map.put("user1", "小明");
- map.put("user2", "小强");
- map.put("user3", "小红");
- //转换成数组
- String[] names= (String[]) map.values().toArray(new String[map.size()]);
- for (String name : names){
- System.out.println(name);
- }
- //采用迭代
- Collection nameArray = map.values();
- Iterator iter = nameArray.iterator();
- while (iter.hasNext()) {
- String name=iter.next().toString();
- System.out.println(name);
- }
- // 打印结果:
- 小强
- 小明
- 小红
此种方式简单明了,适用于直接获取所有value的情况,可以直接迭代或者转换成数组,当直接显示value的情况下比较适用。
Map实现之HashMap(结构及原理)(转)相关推荐
- HashMap底层实现原理,红黑树,B+树,B树的结构原理,volatile关键字,CAS(比较与交换)实现原理
HashMap底层实现原理,红黑树,B+树,B树的结构原理,volatile关键字,CAS(比较与交换)实现原理 首先HashMap是Map的一个实现类,而Map存储形式是键值对(key,value) ...
- 阿里P8架构师谈:深入探讨HashMap的底层结构、原理、扩容机制
摘要 HashMap是Java程序员使用频率最高的用于映射(键值对)处理的数据类型. 随着JDK(Java Developmet Kit)版本的更新,JDK1.8对HashMap底层的实现进行了优化, ...
- Java HashMap的工作原理 及各种Map区别
2019独角兽企业重金招聘Python工程师标准>>> 一.Java HashMap的工作原理 jdk1.7下HashMap数据结构:数组加链表,链表长度没有8的限制: jdk1.8 ...
- hashmap实现原理_Java中HashMap底层实现原理(JDK1.8)源码分析
在JDK1.6,JDK1.7中,HashMap采用位桶+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里.但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依 ...
- Java数据结构和算法:HashMap的实现原理
HashMap源码理解 Java集合之HashMap HashMap原理及实现学习总结 HashMap源码分析 HashMap原理及实现学习总结 1. HashMap概述 HashMap是基于哈希表的 ...
- Java面试绕不开的问题: Java中HashMap底层实现原理(JDK1.8)源码分析
这几天学习了HashMap的底层实现,但是发现好几个版本的,代码不一,而且看了Android包的HashMap和JDK中的HashMap的也不是一样,原来他们没有指定JDK版本,很多文章都是旧版本JD ...
- HashMap底层实现原理/HashMap与HashTable区别/HashMap与HashSet区别
Hash算法 Hash,一般翻译做"散列",也有直接音译为"哈希"的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的 ...
- esp8266接收到的数据如何存放到数组中_Java中HashMap的实现原理
最近面试中被问及Java中HashMap的原理,瞬间无言以对,因此痛定思痛觉得研究一番. 一.Java中的hashCode和equals 1.关于hashCode hashCode的存在主要是用于查找 ...
- HashMap底层实现原理/HashMap与HashTable区别/HashMap与HashSet区别(转)
HashMap底层实现原理/HashMap与HashTable区别/HashMap与HashSet区别 文章来源:http://www.cnblogs.com/beatIteWeNerverGiveU ...
- Java HashMap的实现原理详解
HashMap是Java Map类型的集合类中最常使用的,本文基于Java1.8,对于HashMap的实现原理做一下详细讲解. (Java1.8源码:http://docs.oracle.com/ja ...
最新文章
- HTML5 学习笔记(一)- video
- 《精通Unix下C语言编程与项目实践》目录
- vbs字符串正则_VBscript中的正则表达式
- 好看的一本历史小说《大秦帝国》啊
- Additive属性动画
- windows环境下的zookeeper安装
- python gui插件_Python进阶量化交易专栏场外篇17- GUI控件在回测工具上的添加
- Linux CentOS服务启动
- 一个案例、6个步骤全程详解A/B测试,看这篇就够了!
- WPS如何并排放置两张图片_Animate如何制作文字动图动画
- backlog配置_Nginx backlog配置概述
- linux7 vnc 黑屏,51CTO博客-专业IT技术博客创作平台-技术成就梦想
- 数据血缘关系图 工具_QCSPCChart SPC控制图工具,QCSPCChart SPC精湛而轻松
- sd卡计算机无法读取数据,怎么强制格式化sd卡-内存卡突然无法读取、数据损坏……整个人都是崩溃的!...
- labview温度采集系统(数据保存到excel)
- 基于PHP的校园竞赛信息网站 毕业设计-附源码221230
- 终于申请自己的博客了
- 树形动态规划(树状DP)小结
- 《Tux福音》中英对照注释版
- 用Python做个美少女大战小怪兽