GAN理论推导(知乎转载)
GAN理论推导
在知乎上看到一个对GAN推导得十分仔细的文章,写得非常好,我准备按照他的思路推导一下GAN的理论。可以理解为这篇文章转载自:https://zhuanlan.zhihu.com/p/27295635
GAN的原理
首先我们知道真实图片集的分布 P d a t a ( x ) P_{data}(x) Pdata(x),x是一个真实的图片,可以想象为一个向量,这个向量集合的分布就是 P d a t a P_{data} Pdata。我们现在有Generator生成的分布假设为 p G ( x ; θ ) p_G(x;\theta) pG(x;θ),这是一个由 θ \theta θ控制的分布, θ \theta θ是这个分布的参数(如果是高斯混合模型,那么 θ \theta θ就是每个高斯分布的平均值和方差),假设我们再真实分布中取一些数据, x 1 , x 2 , . . . , X m {x^1,x^2,...,X^m} x1,x2,...,Xm,我们想要计算一个似然 P G ( x i ; θ ) P_G(x^i;\theta) PG(xi;θ),关于似然的理解可以参考这篇博客:https://blog.csdn.net/weixin_40499753/article/details/82977623 对于这些数据,在生成模型中的似然就是 L = ∏ i = 1 m P G ( x i ; θ ) L=\prod_{i=1}^mP_G(x^i;\theta) L=∏i=1mPG(xi;θ), 我们想要最大化这个似然,等价于让generator生成那些真实图片的概率最大,这就变成了一个最大似然估计的问题了,我们需要找到一个参数 θ ∗ \theta^* θ∗来最大化这个似然。公式推导如下:
我们寻找一个 θ ∗ \theta^* θ∗来最大化这个似然,等价于最大化log似然。因为此时这m个数据是从真实分布中取得,所以也就约等于真实分布中的所有x在 P G P_G PG分布中的log似然的期望。真实分布中的所有x的期望,等价于求概率积分,可以转化为积分运算,因为减号后面的项和 θ \theta θ无关,所以添加上之后还是等价的。然后提出共有的项,括号内的反转,max变为min,就可以转化为KL散度的形式了,KL散度描述的是2个向量之间的差异。所以最大化似然,让generator最大概率的生成真实图片,也就是要找一个 θ \theta θ让 P G P_G PG更接近于 P d a t a P_{data} Pdata,那如何来找这个最合理的 θ \theta θ呢?我们可以假设 P G ( x ; θ ) P_G(x;\theta) PG(x;θ)是一个神经网络。首先随机一个向量z,通过G(z)=x这个网络生成图片x,那么如何比较两个分布是否相似呢?只要我们取一组sample z,这组z符合一个分布,那么通过网络就可以生成另外一个分布 P G P_G PG,然后来和真实分布 P d a t a P_{data} Pdata比较。
![]() 如何来找更接近的分布,这就是GAN的核心贡献了。GAN的公式为:
如何来找更接近的分布,这就是GAN的核心贡献了。GAN的公式为:这个式子的好处在于,固定G,max V(G, D)就表示 P G P_G PG和 P d a t a P_{data} Pdata之间的差异,然后要找一个最好的G,让这个最大值最小,也就是2个分布之间的差异最小。
表面上看这个的意思是,D要让这个式子尽可能的大,也就是对于x是真实分布中,D(x)要接近与1,对于x来自于生成的分布,D(x)要接近于0,然后G要让式子尽可能的小,让来自于生成分布中的x,D(x)尽可能的接近1。
现在我们先固定G,来求解最优的D:
 对于一个给定的x,得到最优的D如上图,范围在(0,1)内,把最优的D带入
对于一个给定的x,得到最优的D如上图,范围在(0,1)内,把最优的D带入可以得到:
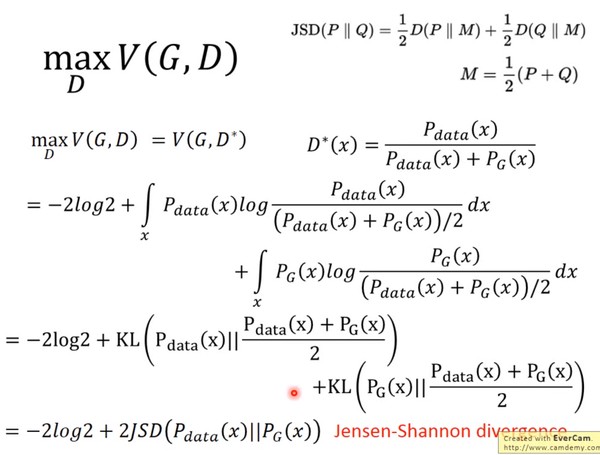 JS divergence是KL divergence的对称平滑版本,表示了两个分布之间的差异,这个推导就表明了上面所说的,固定G,
JS divergence是KL divergence的对称平滑版本,表示了两个分布之间的差异,这个推导就表明了上面所说的,固定G,表示两个分布之间的差异,最小值是-2log2,最大值为0。现在我们需要找个G,来最小化
观察上式,当
时,G是最优的。
训练
有了上面推导的基础之后,我们就可以开始训练GAN了。结合我们开头说的,两个网络交替训练,我们可以在起初有一个 G 0 G_0 G0和 D 0 D_0 D0,先训练 D 0 D_0 D0找到,然后固定 D 0 D_0 D0开始训练 G 0 G_0 G0,训练的过程都可以使用gradient descent,以此类推,训练 D 1 , G 1 , D 2 , G 2 . . . D_1,G_1,D_2,G_2... D1,G1,D2,G2...
![]() 避免上述情况的方法就是更新G的时候,不要更新G太多。
避免上述情况的方法就是更新G的时候,不要更新G太多。
知道了网络的训练顺序,我们还需要设定两个loss function,一个是D的loss,一个是G的loss。下面是整个GAN的训练具体步骤:
![]() 上述步骤在机器学习和深度学习中也是非常常见,易于理解。
上述步骤在机器学习和深度学习中也是非常常见,易于理解。
存在的问题
但是上面G的loss function还是有一点小问题,下图是两个函数的图像:
![]() l o g ( 1 − D ( x ) ) log(1-D(x)) log(1−D(x))是我们计算时G的loss function,但是我们发现,在D(x)接近于0的时候,这个函数十分平滑,梯度非常的小。这就会导致,在训练的初期,G想要骗过D,变化十分的缓慢,而上面的函数,趋势和下面的是一样的,都是递减的。但是它的优势是在D(x)接近0的时候,梯度很大,有利于训练,在D(x)越来越大之后,梯度减小,这也很符合实际,在初期应该训练速度更快,到后期速度减慢。
l o g ( 1 − D ( x ) ) log(1-D(x)) log(1−D(x))是我们计算时G的loss function,但是我们发现,在D(x)接近于0的时候,这个函数十分平滑,梯度非常的小。这就会导致,在训练的初期,G想要骗过D,变化十分的缓慢,而上面的函数,趋势和下面的是一样的,都是递减的。但是它的优势是在D(x)接近0的时候,梯度很大,有利于训练,在D(x)越来越大之后,梯度减小,这也很符合实际,在初期应该训练速度更快,到后期速度减慢。
![]()
![]() 还有可能的原因是,虽然两个分布都是高维的,但是两个分布都十分的窄,可能交集相当小,这样也会导致JS divergence算出来=log2,约等于没有交集。解决的一些方法,有添加噪声,让两个分布变得更宽,可能可以增大它们的交集,这样JS divergence就可以计算,但是随着时间变化,噪声需要逐渐变小。
还有可能的原因是,虽然两个分布都是高维的,但是两个分布都十分的窄,可能交集相当小,这样也会导致JS divergence算出来=log2,约等于没有交集。解决的一些方法,有添加噪声,让两个分布变得更宽,可能可以增大它们的交集,这样JS divergence就可以计算,但是随着时间变化,噪声需要逐渐变小。
还有一个问题叫Mode Collapse,如下图:
![]() 这个图的意思是,data的分布是一个双峰的,但是学习到的生成分布却只有单峰,我们可以看到模型学到的数据,但是却不知道它没有学到的分布。
这个图的意思是,data的分布是一个双峰的,但是学习到的生成分布却只有单峰,我们可以看到模型学到的数据,但是却不知道它没有学到的分布。
造成这个情况的原因是,KL divergence里的两个分布写反了,![]()
GAN理论推导(知乎转载)相关推荐
- GAN完整理论推导与实现,Perfect!
本文是机器之心第二个 GitHub 实现项目,上一个 GitHub 实现项目为从头开始构建卷积神经网络.在本文中,我们将从原论文出发,借助 Goodfellow 在 NIPS 2016 的演讲和台大李 ...
- GAN 的推导、证明与实现。
转自机器之心整理的,来自Goodfellow 在 NIPS 2016 的演讲和台大李弘毅的解释,完成原 GAN 的推导.证明与实现. 本文主要分四部分,第一部分描述 GAN 的直观概念,第二部分描述概 ...
- 四旋翼姿态解算——梯度下降法理论推导
转载请注明出处:http://blog.csdn.net/hongbin_xu 或 http://hongbin96.com/ 文章链接:http://blog.csdn.net/hongbin_xu ...
- NB朴素贝叶斯理论推导与三种常见模型
转自:http://www.tuicool.com/articles/zEJzIbR 朴素贝叶斯(Naive Bayes)是一种简单的分类算法,它的经典应用案例为人所熟知:文本分类(如垃圾邮件过滤). ...
- 两个高斯分布乘积的理论推导
本文主要推导高斯分布(正态分布)的乘积,以便能更清楚的明白Kalman滤波的最后矫正公式. Kalman滤波主要分为两大步骤: 1.系统状态转移估计,2.系统测量矫正: 在第2步中的主要理论依据就是两 ...
- 【理论推导】扩散模型 Diffusion Model
VAE 与 多层 VAE 回顾之前的文章 [理论推导]变分自动编码器 Variational AutoEncoder(VAE),有结论 log p ( x ) = E z ∼ q ( z ∣ x ...
- 四面埋伏(车羊问题)代码模拟+理论推导
- 背景: > 你作为选手参加一个名叫<四面埋伏>的战争游戏,获胜奖金额为100万美元.在游戏开始,你模拟一名将军处于游戏场地正中央,在你的4个方向上,有3个方向被设下埋伏,只有一个 ...
- 朴素贝叶斯理论推导与三种常见模型
朴素贝叶斯(Naive Bayes)是一种简单的分类算法,它的经典应用案例为人所熟知:文本分类(如垃圾邮件过滤).很多教材都从这些案例出发,本文就不重复这些内容了,而把重点放在理论推导(其实很浅显,别 ...
- 【转】两个高斯分布函数乘积的理论推导
[转]两个高斯分布函数乘积的理论推导 ---------------- 版权声明:本文为CSDN博主「chaosir」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明. ...
最新文章
- ce修改器传奇刷元宝_真原始传奇刷元宝方法 不封号刷元宝技巧
- 简要描述cookie和session的区别:
- stackoverflow上Java相关回答整理翻译FAQ top 100
- 两道JVM面试题,竟让我回忆起了中学时代!
- mysql 加索引不起作用_mysql加索引及索引失效的情况
- Multisim14.0 安装教程
- 前端如何查看音频的长度_Android音频可视化
- ubuntu中使用usb转串口
- echo 多行_分享laravel-echo-server广播服务搭建-Laravel
- 目前数据可视化工具软件的排名
- 三类主流影音播放器对比
- linux信号量配合共享内存应用分析(详解)
- 根据肠道微生物组重新思考健康饮食
- matlab四大取整函数fix,floor,ceil,round
- 健康指南:趴桌睡觉三大危害
- C语言uint8_t和char的区别,c – int8_t和uint8_t是char类型吗?
- 喝酒聚会神器小程序部署
- 2023最新车道线综述!近五年文章全面盘点(几何建模/机器学习/深度学习)
- 【解决方案】Ubuntu设置Matlab桌面启动快捷方式
- 小小甜菜深度学习爬坑记