Pluto-基于Caffe的GPU多机多卡深度学习算法产品
作者
阿里巴巴-计算平台-机器学习团队
同Caffe的关系
- 完全兼容Caffe。Pluto基于开源库Caffe扩展而来,是Caffe的超集,完全兼容Caffe的配置和数据,使用过Caffe的同学几分钟就能用Pluto跑起多机多卡版程序。
- Pluto的单机核心代码同开源社区版本保持同步,所以开源社区提供的一些新特性我们能够迅速merge到Pluto里面
新特性
我们来源于Caffe,但同时根据我们的用户需求我们提供了一些Pluto独有的新特性,帮助用户在模型训练中提高效率。
- 多机多卡,通过并行计算提高计算和收敛速度。
- 数据读取提供多lmdb支持。开源版本只能从一个lmdb读取训练数据,Pluto提供支持从多个lmdb按概率(可配置)读取数据,可以更好的支持用户训练数据的增量更新,不会因为训练数据增加而重新制作lmdb文件。
- hdf5文件prefetch支持。因为hdf5文件读取时需要全部load进内存的特点,当以hdf5文件作为数据存储格式时数据读取时间同计算时间无法进行overlap。Pluto提供文件级的prefetch支持,通过独立线程在计算时preload下一份hdf5文件,缩短训练时间。
- Sequential learning支持。Sequence learning对于语音识别和自然语言处理中存在时序关联的数据进行处理建模拥有天然的优势。Pluto中提供的Sequence learning的相关支持,包括常用的RNN/LSTM以及双向的LSTM,可以高效准确的进行自然场景图片描述(如Image Caption)和自然语言处理中的相关建模任务。
- 多种同步模式支持。用户可以配置多卡间的同步轮数间隔,默认每轮同步一次;也可以配置按时间同步,即每张卡独立的迭代一段时间后同步一次,适用于资源竞争激烈或快慢机明显的环境。
- Sparse 数据格式支持。支持sparse格式的训练数据。
性能分析
实验环境
- GPU Device: Tesla K40m with 12GiB display memory, two cards in each box
- Network: InfiniBand, GPU direct
- cuDNNv2:open
Alexnet在Imagenet数据集上的实验结果
梯度平均
在每轮计算都做一次梯度平均,可以获得同单机一模一样的收敛结果,即acc57.1%,计算和收敛加速比如下:
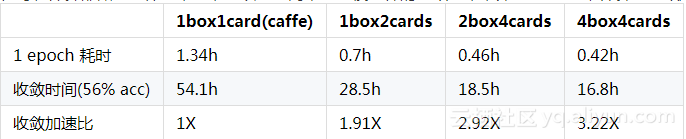
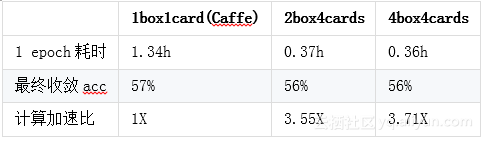
模型平均 每张卡各自计算若干轮后做一次模型平均,会 影响收敛结果 ,但是可以 提高计算加速比 ,结果如下:
收敛曲线


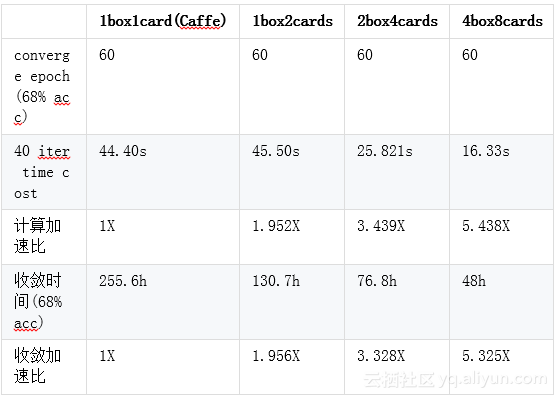
Googlenet在Imagenet数据集上的实验结果:
模型平均
收敛曲线


如何使用
- 在阿里云机器学习平台PAI上,可以选择Caffe组件使用。
- 使用文档见: https://help.aliyun.com/document_detail/49571.html?spm=5176.doc42745.6.548.Dd4AFR#Caffe
Pluto-基于Caffe的GPU多机多卡深度学习算法产品相关推荐
- 基于京东云GPU云主机搭建TensorFlow深度学习环境
TensorFlow是一个开放源代码软件库,用于进行高性能数值计算.借助其灵活的架构,用户可以轻松地将计算工作部署到多种平台(CPU.GPU.TPU)和设备(桌面设备.服务器集群.移动设备.边缘设备等 ...
- 脑机接口的深度学习算法
脑机接口的深度学习算法 脑电图控制是一种利用脑信号去控制电子设备和电路的非侵入式技术.目前,脑机接口系统提供了两种信号类型--原始信号和逻辑状态信号(用于开关设备).本文对脑机接口系统的性能进行了探讨 ...
- 学术篇 | 多模态fNIRS脑电分类——基于脑机接口的深度学习算法
近年来,脑机接口(BCI)系统的发展受到神经科学家的广泛关注,脑机接口可以作为一种沟通手段,并为运动障碍患者的运动功能恢复.脑机接口(BCI)设计的一个重要部分是正确地对脑信号进行分类,这些信号过去是 ...
- TensorFlow和Caffe、MXNet、Keras等其他深度学习框架的对比
2019独角兽企业重金招聘Python工程师标准>>> TensorFlow和Caffe.MXNet.Keras等其他深度学习框架的对比 博客分类: 深度学习 Google 近日发布 ...
- 基于web端和C++的两种深度学习模型部署方式
深度学习Author:louwillMachine Learning Lab 本文对深度学习两种模型部署方式进行总结和梳理.一种是基于web服务端的模型部署,一种是基... 深度学习 Author:l ...
- 基于微软开源深度学习算法,用 Python 实现图像和视频修复
作者 | 李秋键 编辑 | 夕颜 出品 | AI科技大本营(ID:rgznai100) 图像修复是计算机视觉领域的一个重要任务,在数字艺术品修复.公安刑侦面部修复等种种实际场景中被广泛应用.图像 ...
- AMD将推出7纳米GPU Vega,专为深度学习和机器学习打造
内容来源:ATYUN AI平台 AMD今天在Computex上为其下一代7纳米GPU Vega草拟了高级的数据中心计划.综合了AMD在个人电脑上花费一个半小时的展示,显然7纳米Vega终于瞄准了高性能 ...
- 基于PyTorch、易上手,细粒度图像识别深度学习工具库Hawkeye开源
转载自丨机器之心 鉴于当前领域内尚缺乏该方面的深度学习开源工具库,南京理工大学魏秀参教授团队用时近一年时间,开发.打磨.完成了 Hawkeye--细粒度图像识别深度学习开源工具库,供相关领域研究人员和 ...
- 【ncnn】基于ncnn的iOS端深度学习算法部署及应用
ncnn 是一个为手机端极致优化的高性能神经网络前向计算框架.ncnn 从设计之初深刻考虑手机端的部署和使用.无第三方依赖,跨平台,手机端 cpu 的速度快于目前所有已知的开源框架.基于 ncnn,开 ...
最新文章
- 第一次走绿道,从长岭陂到梅林水库
- 五十六、 白话讲解商业智能 BI、数据仓库 DW、数据挖掘 DM
- marc数据个人心得
- OD的hit跟踪和run跟踪
- MySQL(二)数据的检索和过滤
- [codevs1039]数的划分
- 处理git clone命令的非标准SSH端口连接
- Hibernate 查询数据
- Scrum立会报告+燃尽图(十月二十二日总第十三次)
- PHP设置脚本最大执行时间的三种方法
- SoapUI中文乱码
- WindRiver编译小结
- Idea一不小心把Main menu头部菜单关闭还原的解决办法
- linux 命令 cups,linux cups 打印机命令说明
- 游戏出海Get,TikTok联手Zynga推出一款基于HTML5打造的手机游戏
- 西安邮电大学计算机学院军训,高考状元染网瘾无法自拔 5次考上大学3次退学
- torch.mul、matmul、mm、bmm的区别
- 质量运营在美团点评智能支付业务测试中的初步实践
- 世界上前11名最贵跑车
- 求职季之你必须要懂的原生JS(中)