SLS机器学习介绍(01):时序统计建模
文章系列链接
- SLS机器学习介绍(01):时序统计建模
- SLS机器学习介绍(02):时序聚类建模
- SLS机器学习介绍(03):时序异常检测建模
- SLS机器学习介绍(04):规则模式挖掘
- SLS机器学习最佳实战:时序异常检测和报警
背景
时序数据是业务监控中最多方法,双十一大盘、业务监控系统、系统性能平台等都可以看到他的身影。根据统计,60%+业务系统监控都是通过时序表达出来。在数量上,以在阿里云神农系统为例,一台机器有3500多个时序数据,以5秒作为采样周期1000台集群计算,每秒钟会产生70W个点。
时序数据从产生到看到一般分为几个阶段:
- 采集程序通过采样把原始的状态写入队列
- 流计算程序通过跳动窗口(分钟、15秒等)进行聚合(例如count,avg,p99)
- 写入NoSQL等存储引擎进行后期可视化与加工
这套架构非常成熟,在集团中也有非常棒的产品例如IoT、LogAgent、Logtail、TT(Hbase)、LogHub、Blink、JStorm、Kepler、TableStore、Hbase、HiTSDB等。
生成时序数据是为了对业务进行监控和报警,但这块目前非常依赖与人的经验,我们来看几个典型的问题:
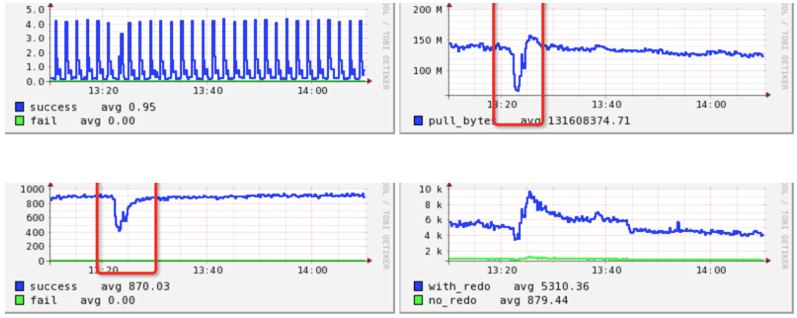
问题1:业务/交易走势异常发现
例如下图的监控中,在2分钟时间内流量大小下跌30%以上,在2分钟内后又迅速恢复:
应对这种情况有几种典型做法:
- 同环比,例如和上一周、上一天同一时刻比较,如果下降或上升一定大小(例如30%),则产生报警
- 假设系统是平滑的,与上一时刻比较,如果有比较大差距则认为是巨大变化,产生报警
- 通过统计建模估算大致走势,如果违背则认为是异常报警
这些方法有比较强的假设,并对数据的精度有较为严格的要求,在生产中容易产生误报。
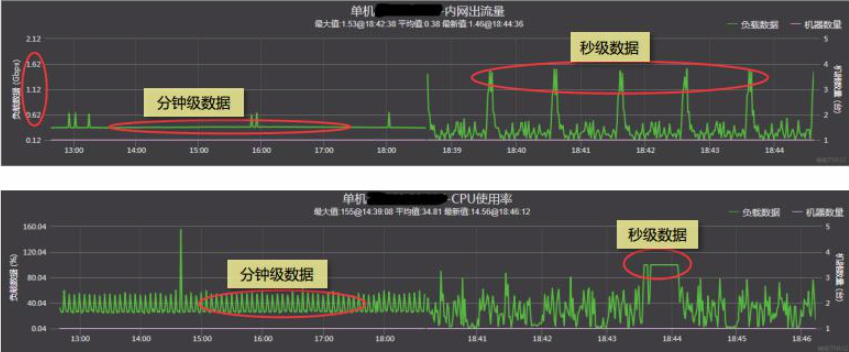
问题2:异常点发现
- 以线上业务访问为例,从肉眼很难发现隐藏在其中的局部网络流量变化
- 在分钟监控下,秒级监控中的毛刺被平均
问题3:延时是否是正常
与Pangu团队交流时发现,Latency告警是一个很依赖经验的问题,无法使用例如业务量等传统时序建模手段。主要有几大原因:
- Latency 在QPS等请求上升时,一般都是趋于稳定的
- Latency 下降并不能说系统出了问题,有可能当前没有访问
- Latency 上升可能和系统的压力、请求,机器负载相关,上升30%可能是请求多了排队引擎,并不是软件或系统Hang。
因此Latency是否正常判断,不能以单一要素维度去建模,要考虑到相关因素。
问题4:在大量实例中发现问题
案例1:在分布式系统下,我们希望所有的实例行为是否都符合预期的,是否有一些实例没有被调度到造成了浪费
案例2:在安全建模中,会对需要对同一类人(例如同一个组织)进行行为建模,其中是否有局部的人行为异常(例如流量在非工作时间段非常大)
这两个案例都会需要从几千个、几十万个实例中去发现不一样的实例。传统的人肉判断方法会显得力不从心。
我们的思考与方法
作为长期参与飞天操作系统研发,我们不断地在思考这些问题的本质原因和解决方法。在日志服务(SLS)新版本中,我们把机器学习功能在产品推出,希望能替代有经验开发、运维来解决这些问题。
以下系列文章中我们会介绍以上问题的思路及方法,欢迎大家的讨论。
第一篇:时序统计建模
工业级算法设计思路
1. 通过降维减小数据维度
通常,我们的时间序列数据是多维的,多维时间序列可用于描述受监测事物的多个方面状态与情况,然而随着维度的增长,多时间序列异常异常检测的计算时间会快速增加。通过观察发现当时间序列存在与异常发生原因无关的维度时,进行一些相关性分析,去除无关维度不会对异常检测的准确性产生决定性影响。
2. 使用简单的线性判别
在时间序列的研究当中,很多时候少即是多,时间序列受随机性,趋势性影响较大,往往越多的参数,越复杂的模型意味着很难去长时间,更泛化的拟合真实的数据。而模型的复杂通常也意味着复杂度的提升,因此我们提倡在大数据算法的设计当中,可以适当的为了泛化能力以及时间效率,选择较为简单的线性方法进行粗略的异常判别,后续再使用更精确的算法对子区间进行判别。
3. 尽量设计在线的算法
目前大多数异常检测方法均为静态方法,即对历史中特定段落的时间序列进行分析并得出结果。静态的时间序列方法不能应用于实时的时间序列异常检测。然而在许多应用场景中时间序列是不断增长的,因此我们对于实时获得的时间序列中的异常的需求同样迫切。而且在线的算法也意味着效率近似于线性,是一件非常让人愉悦的事情。
4. 通过并行的思想改善耗时部分的性能
大数据的异常检测对于检测方法提出了存储能力与计算能力的新要求。单个计算结点的存储能力与计算能力无法满足这些要求,我们需要利用并行化计算的方法改善异常检测方法的检测性能。
如何设计 Master 和 Slaver 结点的算法,以及它们划分,合并的关系,将哪个部分正确的,有效的用于并行计算,是这个方向上的研究重点。
5. 做好时间与检测效果的 Trade Off
针对于大数据所设计出的算法,应该有相应的调整系数,能够平衡效率和检测效果的不同侧重。对于某些不需要高精度检测,但是实时性较强的环境,可以通过调整参数来达到相应的需求。
6. 以框架的方式设计算法
以上所提出的几点,均是这个方向上的算法的设计思路,或者说期望达到的目标,一个算法想要很好的结合这三点是很困难的。因此我们认为或许可以使用框架的方式,将各种手段或者技术进行合理的整合,比如异常序列的粗预警,细预警的分离,多维数据,多指标检测的并行分离,等等手段,都可以通过框架的方式进行有机的整合,最终形成一个良好可用的算法。
时序预测模型概况
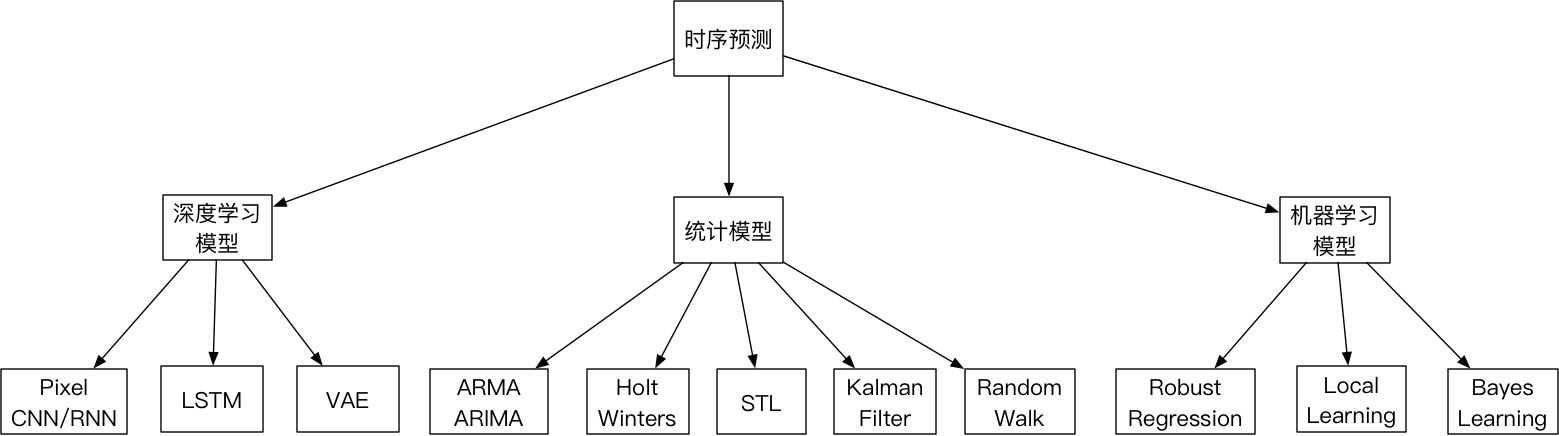
概况说明
- 统计模型预测:其中自回归和移动平均模型,主要代表算法是ARMA系列;使用二阶或三阶指数平滑算法,主要代表算法是Holt Winters;对于趋势和周期序列,主要利用序列分解策略,主要代表算法是STL;同时也有利用卡尔曼滤波和随机游走算法进行时序的预测;
- 机器学习模型预测:消除时序中的噪点,利用鲁棒性回归和相应的随机过程(泊松过程、高斯过程等)配合使用Robust Regression;局部学习算法Local Learning;还有针对历史数据进行建模,利用贝叶斯算法进行时序预测;
- 深度学习模型预测:利用递归神经网络RNN,以及RNN的变形LSTM模型,进行时序预测;同时还有利用VAE(Variance Auto Encoder)算法将时序数据利用编码器的方式去噪声,并利用网络的强大拟合能力对其中数据缺失等问题得以解决;改进WaveNet模型使用CNN的形式去模拟部分RNN的策略较好的利用曲线的局部特征进行预测;
本文重点
- 指标趋势预测:通过分析指标历史数据,判断未来一段时间指标趋势及预测值,常见有 Holt-Winters、时序数据分解(STL)、ARMA 系列算法。该算法技术可用于异常检测、容量预测、容量规划等场景。
- 主要阐述算法基本模型和使用方法。
模型实战
时间序列一般具有如下比较明显的特征:
- 趋势性:数据呈现某种持续向上或向下的趋势或者规律
- 季节性:数据呈现季节性,数据按照一定的规则进行往复出现
- 随机性:一些采集过程中的噪声或一些不规则的波动
时间序列预测法用于短期、中期和长期预测。时间序列的本质特性是承认动态数据之间的相关性或依赖关系,这种相关性表征了系统的“动态”或“记忆”。如果这种相关性可用数学模型描述,则可有系统的过去及现在的取值预测其未来取值。
模型构建流程

数据预处理
- 平滑滤波
- 周期估计
模型原理介绍
1. 数据预处理操作
1.1 指数平滑模型原理
一般常用的指数平滑法为一次指数平滑、二次指数平滑、三次指数平滑。在平滑之前,首先需要有初始值,通常,如果数据项小于20,则初始取值第1、2、3期的平均值;如果数据项大于20,则可以把第1期的值作为初始值,记为$S_0$。
- 一次指数平滑模型,适用于水平型的数据
$$ S_{t}^{1} = \alpha * x_{t-1} + (1 - \alpha) * S_{t-1}^{1} $$
其中,$S_{t}^{1}$为t时刻的平滑值,$S_{t-1}^{1}$为t-1时刻的平滑值,$x_{t-1}$为t-1时刻的实际值,$\alpha$为常数值。
预测未来时刻的公式为:
$$ S_{t+1}^{1} = \alpha * x_{t} + (1 - \alpha) * S_{t}^{1} $$
$\alpha$选择的经验:当数据波动不大时,选择较小的值;当数据波动较大时,选择较大的值。
- 二次指数平滑模型,适用于斜坡型时序数据,该算法保留了平滑信息和趋势信息,基本思路就是对平滑之后的数据在平滑一次
$$ S_{t}^{1} = \alpha * x_{t-1} + (1 - \alpha) * S_{t-1}^{1} $$
$$ S_{t}^{2} = \alpha * S_{t}^{1} + (1 - \alpha) * S_{t-1}^{2} $$
其中,$S_{t}^{1}$为t时刻第一期的平滑值,$S_{t}^{2}$为t时刻第二期的平滑值,$x_t$是t时刻的实际值,$\alpha$为常数值。
预测未来T时刻的计算公式为:
$$ x_{t+T} = A_T + B_{T}*T $$
其中
$$ A_T = 2 * S_{t}^{1} - S_{t}^{2} $$
$$ B_T = \frac{1}{1-\alpha}(S_{t}^{1} - S_{t}^{2}) $$
- 三次指数平滑(Holt-Winters)该方法适用于含有趋势性和季节性的时序数据
$$ S_{t}^{1} = \alpha * x_{t-1} + (1 - \alpha) * S_{t-1}^{1} $$
$$ S_{t}^{2} = \alpha * S_{t}^{1} + (1 - \alpha) * S_{t-1}^{2} $$
$$ S_{t}^{3} = \alpha * S_{t}^{2} + (1 - \alpha) * S_{t-1}^{3} $$
其中,$S_{t}^{1}$为t时刻第一期的平滑值,$S_{t}^{2}$为t时刻第二期的平滑值,$S_{t}^{3}$为t时刻第三期的平滑值,$x_t$是t时刻的实际值,$\alpha$为常数值。
预测未来T时刻的计算公式为:
$$ x_{t+T} = A_T + B_T * T + C_T * T^2 $$
其中
$$ A_T = 3 * S_{t}^{1} - 3 * S_{t}^{2} + S_{t}^{3} $$
$$ B_T = \frac{\alpha}{2 * (1 - \alpha)^2}[(6 - 5 \alpha) * S_{t}^{1} - 2(5-4\alpha)S_{t}^{2} + (4 - 3 \alpha) S_{t}^{3}] $$
$$ C_T = \frac{\alpha^2}{2(1-\alpha)^2}[S_{t}^{1} - 2S_{t}^{2}+S_{t}^{3}] $$
下图为平台提供的各种滤波操作的结果示意图
- 默认使用Holt-Winters指数平滑函数进行平滑
* | select ts_smooth_simple(stamp, val) from log limit 100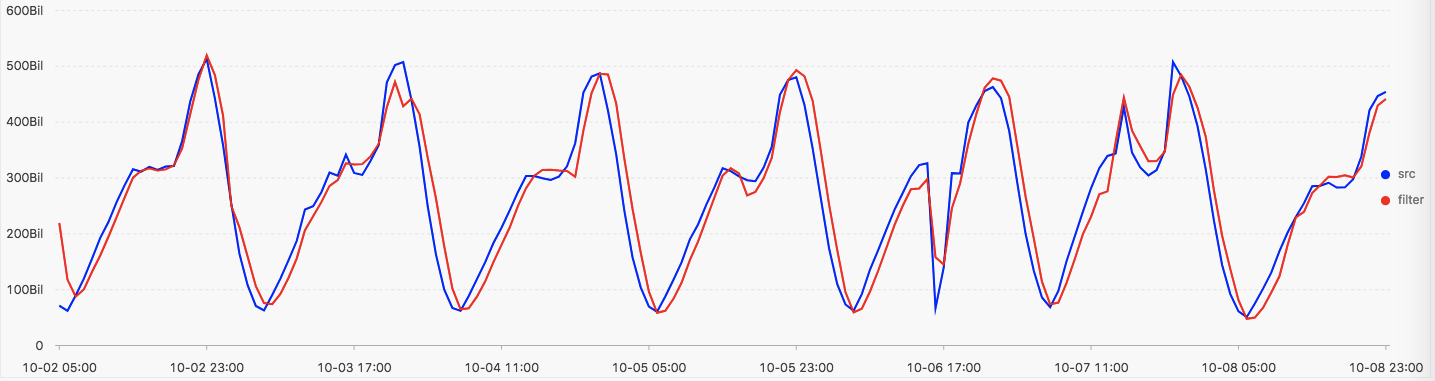
- 使用滑动窗口平滑函数进行平滑
* | select ts_smooth_fir(stamp, val, 'rectangle', 5, 1, 'avg') from log limit 100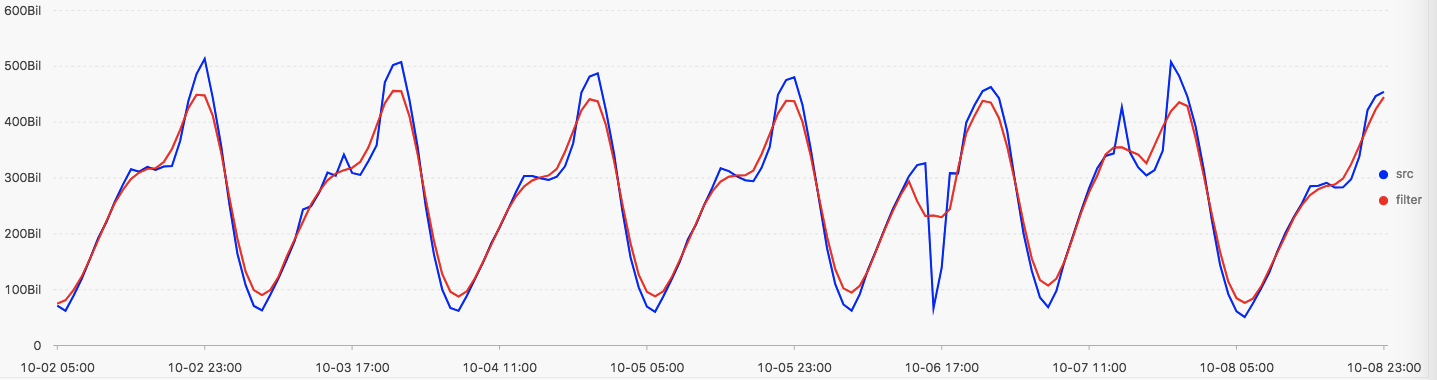
1.2 时序数据差分
问题假设:任何一个时间序列,可以分解为如下加法形式
$$ X_t = m_t + s_t + Y_t $$
其中,$m_t$表示缓慢变化的函数,$s_t$是已知周期为d的函数,称为周期项,$Y_t$是平稳随机噪声项。在估计和抽取时间序列中的确定性成分$m_t$和$s_t$时,使残差量$Y_t$是一个平稳过程,进而求得关于${Y_t}$的合适的数学模型,分析它的性质,并连同$m_t$和$s_t$可达到对${X_t}$预报和控制的目的。
1.2.1 趋势项估计和提取
不含有季节项成分模型
$$ X_t = m_t + Y_t $$
不失一般性,假设$E(Y_t) = 0$。
- 对趋势项$m_t$进行最小二乘法进行估计
$$ m_t = \alpha_0 + \alpha_1 * t + \alpha_2 * t^2 $$
最小化$\sum_{t} (x_t - m_t)^2$以确定$\alpha_0, \alpha_1, \alpha_2$
1.2.2 趋势项和周期项估计和提取
- 用差分方法产生平稳的数据,使用差分法可消除趋势,介绍下差分算子和延迟算子
- 一阶差分算子定义为
$$ \bigtriangledown X_t = X_t - X_{t-1} = (1-B)X_t $$
其中,B是延迟算子,定义为
$$ BX_t = X_{t-1} $$
- 二阶差分算子定义为
$$ \bigtriangledown^2 X_t = \bigtriangledown(\bigtriangledown X_t) = (1-2B+B^2)X_t = X_t - 2 X_{t-1} + X_{t-2} $$
- 消除时序中的周期和趋势,再进行预测
时序模型符合如下形式
$$ X_t = m_t + s_t + Y_t $$
其中,$E(Y_t) = 0, s_t = s_{t+d}, t \in T$
- 首先定义d步差分算子
$$ \bigtriangledown_dX_t = X_t - X_{t-d} = (1 - B^d)X_t $$
将d步差分算子,作用于时序模型,得到如下表达式
$$ \bigtriangledown_dX_t = \bigtriangledown_d(m_t + s_t + Y_t) $$
利用序列的周期为d,则有如下表达式
$$ \bigtriangledown_dX_t = m_t - m_{t-d} + Y_t - Y_{t-d} $$
利用d步差分算子,使经d步差分后数据不含有季节项,使得差分后的结果进行求解使得残差量满足平稳性。
1.3 时序数据平稳性
时间序列分析的一些主要方法都是假定数据样本是来自平稳(随机)序列,这是进行分析和确立平稳时间序列线性线性模型的前提。检验数据的平稳性,实质上是检验原来产生数据样本的随机序列的平稳性。从本质上讲,时间序列模型是通过历史规律来预测未来的,即挖掘出的历史数据的一些性质在将来保持不变,这样对模型的预测才有意义,而平稳性就是用来刻画时间序列的统计性质关于时间平移的不变性。
由平稳序列的定义知,必须检验一下两个内容:
- 均值和方差是否为常数;
- 其自协方差函数是否只与时间间隔相关,而与间隔端点的位置无关;
数据平稳性检验的参数检验方法:
首先根据平稳序列具有不随时间变化的均值函数和方差函数,其自相关(系数)函数仅是时间间隔的一元函数的性质,构造检验统计量;其次确定检验统计量的分布;进一步由所给数据计算相应统计量的值;最后查表作出结论,接受或者拒绝该数据是否是平稳随机序列。
2. 时序建模原理
2.1 自回归移动平均模型
线性回归模型
$$ Y_t = \beta_1 x_{t_1} + \beta_2 x_{t_2} + \beta_3 x_{t_3} + ... + \beta_r x_{t_r} + \epsilon_t $$
其中,$t=1,2,3,...,N, \epsilon_t ~ N(0, \sigma_{2}^{2})$
回归模型表示了因变量的观测值$y_t$对自变量$(x_{t_1},x_{t_2},x_{t_3},...,x_{t_r})$的相关性,这种模型在数学上处理了很多方法,如最小二乘参数估计,处理含有异常值的稳健回归方法(如M估计),处理多元非参数非线性回归的投影寻踪回归(projection pursuit regresion,PPR)。
- ARMA(p,q)混合自回归移动平均过程
$$ Y_t = c + \phi_1 Y_{t-1} + \phi_2 Y_{t-2} + ... + \phi_p Y_{t-p} + \epsilon_t + \theta_1 \epsilon_{t-1} + \theta_2 \epsilon_{t-2} + ... + \theta_q \epsilon_{t-q} $$
上述模型描述了p阶自回归模型,q阶移动平均模式。经过证明,ARMA(p, q)过程的平稳性完全取决于回归参数$(\phi_1, \phi_2, \phi_3, ..., \phi_p)$,而与移动平均参数$(\theta_1, \theta_2, ..., \theta_q)$无关。
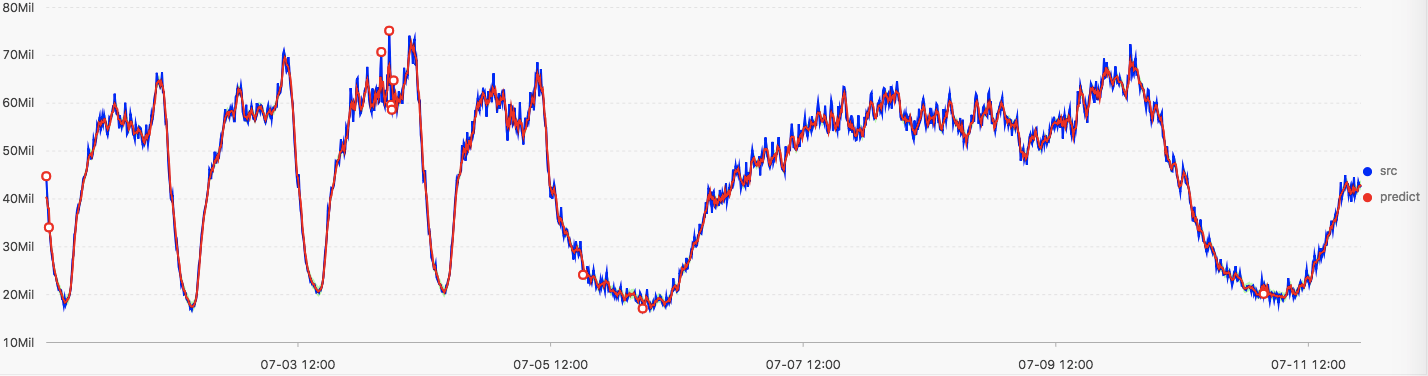
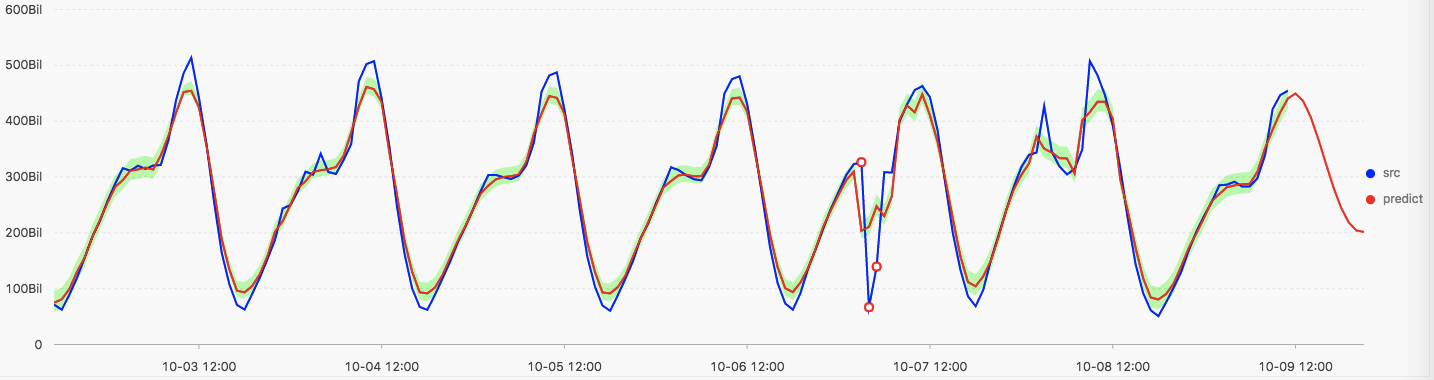
* | select ts_predicate_simple(stamp, val, 10, 1, 'avg') from log limit 500这张图显示原始序列和使用ARMA模型序列预测和异常点检测结果示意图
- 蓝色曲线表示原始序列曲线
- 红色曲线表示ARMA模型预测的序列曲线
- 绿色区域表示在置信度为0.85的条件下预测序列的区间
- 红色的空心点表示判定为异常的点(具体的算法说明后续文章说明)
2.2 STL序列分解模型
STL(Seasonal-Trend Decomposition Procedure Based on Loess)为时序分解中一种常见算法,将某时刻数据分解为趋势分量、周期分量、残差分量,具体公式如下:
$$ Y_t = T_t + S_t + R_t, t = 1,2,3,...,N $$
STL分解算法的具体流程
outer loop:计算鲁棒性回归参数inner loop:Step 1: 去趋势Step 2: 周期子序列平滑Step 3: 周期子序列的低通滤波Step 4: 去除平滑周期子序列趋势Step 5: 去周期Step 6: 趋势平滑平台实验结果
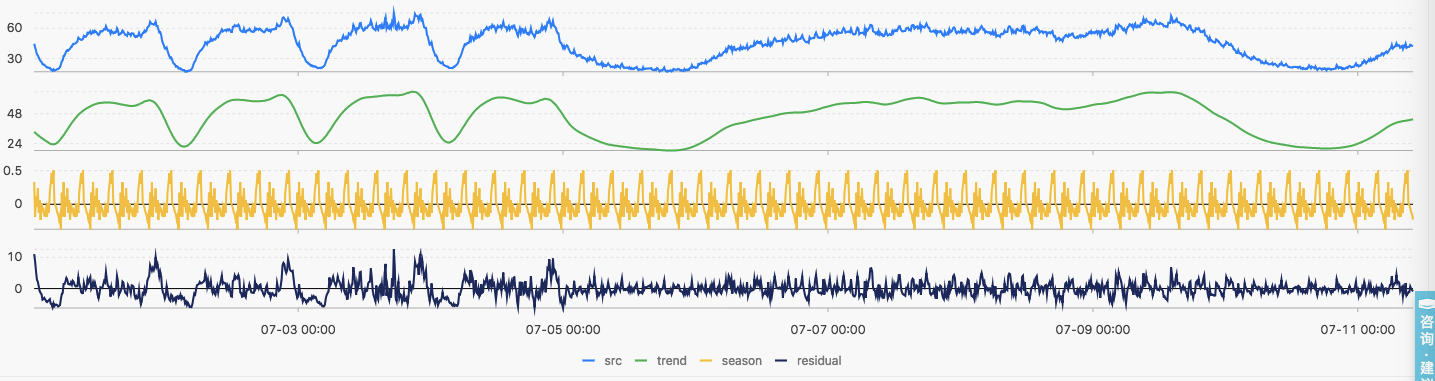
* | select ts_decompose(stamp, val, 1, 'avg') from log limit 2000下图展示利用本平台提供的算法对时序数据的分解结果
- 第一张图展示的是原始时序数据结果
- 第二张图展示的是序列分解出来的趋势序列结果
- 第三张图展示的是序列分解出来的周期序列的结果
- 第四张图展示的是序列分解出来的残差序列的结果
模型选择
给定任意一组参数,均可得到一个模型,但是如何衡量模型的好坏?如何在众多模型中选择一个最好的模型?
关键指标
- 平均绝对差值(Mean Absolute Difference/Error,MAD/MAE)
$$ M = \frac{1}{n}\sum_{i=1}^{n}|Actual - Forecast| $$
- 平均绝对百分偏差(Mean Absolute Percentage Error/Deviation,MAPE/MAPD)
$$ M = \frac{1}{n}\sum_{t=1}^{n}|\frac{Actual_t - Forecast_t}{Actual_t}| $$
- 平均平方误差(Mean Squared Difference/Error,MSD/MSE)
$$ M = \frac{1}{n}\sum_{i=1}^{n}(Actual - Forecast)^2 $$
- 绝对误差和(Sum of Absolute Difference/Error,SAD/SAE)
$$ M = \sum_{i=1}^{n}|Actual - Forecast| $$
AIC/BIC信息量准则
AIC/BIC是评估统计模型的复杂度,衡量统计模型拟合的良好程度,一般情况下:
- AIC可以表示为:
$$ AIC = 2ln(L) + 2K $$
其中K是参数的数量,L是似然函数。假设条件:模型的误差服从独立正太分布,让n为观测数量,RSS为残差平方和,那么AIC的具体计算过程为:$AIC = 2ln(RSS/n) + 2K$,其中增加自由参数的数目提高了拟合的优良性,AIC鼓励数据拟合的优良性,但尽量避免出现过拟合的情况,所以有效的模型应该是AIC值最小的一个。
- BIC可以表示为:
$$ BIC = 2ln(L) + Klog(n) $$
其中K是参数的数量,L是似然函数。
- AIC和BIC的公司前半部分是一样的,后半部分是惩罚项,当$n >= 8$时,$kln(n) >= 2K$,所以,BIC相比AIC在大数据量时对模型参数惩罚得更多,导致BIC更倾向于选择参数少的简单模型。
时序预测
1. 基于条件期望的预测
根据t时刻观测到的一组变量$X_t$预测变量$Y_{t+1}$的值。令$Y_{t+1|t}^{*}$表示根据$X_t$作出的对$Y_{t+1}$的预测。为了评价这个预测有用性,我们需要给出一个损失函数来表示当我们的预测偏离一个特定的量时我们的关心程度。通过假定一个二次损失函数,可以得到一个便利结果。二次损失函数的含义是选择合适的$Y_{t+1|t}^{*}$,使得$E(Y_{t+1} - Y_{t+1|t}^{*})^2$最小。
2. 基于线性投影的预测
假设待预测的$Y_{t+1|t}^{*}$限定为$X_t$的线性函数
$$ Y_{t+1|t}^{*} = \alpha^{'} X_t $$
假设要求解出一个$\alpha$值,使得预测误差$(Y_{t+1} - \alpha^{'}X_t)$无关,即下式成立:
$$ E[(Y_{t+1} - \alpha^{'} X_t) X_t] = 0 $$
则预测$\alpha^{'}X_t$称为$Y_{t+1}$关于$X_t$的线性投影。
3. 线性投影和普通最小二乘回归
一个将$y_{t+1}$于$x_t$联系起来的线性回归模型如下:
$$ y_{t+1} = \beta^{'}x_t + \mu_t $$
给定一个关于y和x的T个观测值的样本,样本残差平方和定义为
$$ \sum_{t=1}^{T}(y_{t+1} - \beta^{'}x_t)^2 $$
预测的置信区间
- 如何理解置信区间?
参数95%的置信度在区间A的含义是:采样100次,计算95%置信度的置信区间,有95次计算所得的区间包含真实值。
真实值不变,变的是置信区间。
通常情况下,95%被作为常用的置信度,原理就在于$3\sigma$控制,此时已经有很高的置信度了。
随着置信度的上升,置信区间的跨度也就越大,对参数估计的精度必定降低。
点估计就一个值,精度高,但置信度则低。
- 以ARMA(p,q)序列的预测
- 预测未来K步长度
$$ if K >= 1, \hat{x}_t(k) = \hat{x}_t(k) $$
$$ if K <= 0, \hat{x}_t(k) = x_{t+k} $$
- 预测方差
$$ Var[e_t(l)] =(1 + G_{1}^{2} + G_{2}^{2} + ... + G_{l-1}^{2}) * \sigma_{\epsilon}^{2} $$
- 95%置信区间
$$ [ \hat{x}_{t}(l) \mp z_{(1-\frac{\alpha}{2})} * (1 + G_{1}^{2} + G_{2}^{2} + ... + G_{l-1}^{2}) ^ {\frac{1}{2}} * \sigma_{\epsilon}] $$
- 实例说明
已知模型:
$$ x_t = 0.8 * x_{t-1} + \epsilon_t - 0.6 * \epsilon_{t-1}, \sigma_{\epsilon}^{2} = 0.0025 $$
且$x_{100} = 0.3, \epsilon_{100} = 0.01$
预测未来3期序列值的95%的置信区间。
估计值的计算:
$$ \hat{x}_{100}(1) = 0.8 * x_{100} - 0.6 * \epsilon_{100} = 0.234 $$
$$ \hat{x}_{100}(2) = 0.8 * \hat{x}_{100}(1) = 0.1872 $$
$$ \hat{x}_{100}(3) = 0.8 * \hat{x}_{100}(2) = 0.14976 $$
预测方差的计算:
$$ G_{0} = 1, G_{1} = \phi_{1} * G_{0} - \theta_1 = 0.2, G_{2} = \phi_{1} * G_{1} = 0.16 $$
$$ Var[e_{100}(1)] = G_{0}^{2} \sigma_{\epsilon}^{2} = 0.0025 $$
$$ Var[e_{100}(2)] = (G_{0}^{2} + G_{1}^{2}) \sigma_{\epsilon}^{2} = 0.0026 $$
$$ Var[e_{100}(3)] = (G_{0}^{2} + G_{1}^{2} + G_{2}^{2}) \sigma_{\epsilon}^{2} = 0.002664 $$
置信区间的计算
| t | lower | upper |
|---|---|---|
| 101 | 0.136 | 0.332 |
| 102 | 0.087 | 0.287 |
| 103 | -0.049 | 0.251 |
硬广时间
日志进阶
阿里云日志服务针对日志提供了完整的解决方案,以下相关功能是日志进阶的必备良药:
- 机器学习语法与函数:https://help.aliyun.com/document_detail/93024.html
- 日志上下文查询:https://help.aliyun.com/document_detail/48148.html
- 快速查询:https://help.aliyun.com/document_detail/88985.html
- 实时分析:https://help.aliyun.com/document_detail/53608.html
- 快速分析:https://help.aliyun.com/document_detail/66275.html
- 基于日志设置告警:https://help.aliyun.com/document_detail/48162.html
- 配置大盘:https://help.aliyun.com/document_detail/69313.html
更多日志进阶内容可以参考:日志服务学习路径。
联系我们
问题咨询请加钉钉群:11775223
参考文献
- 确定性时间序列模型及ARIMA模型的应用
- [智能运维:从0搭建大规模分布式AIOps系统]
- [随机过程与应用 (田铮、秦超英)]
- [时间序列分析 (詹姆斯·D·汉密尔顿)]
- Triple Exponential Smoothin
- STL Decomposition
- STR: A Seasonal-Trend Decomposition Procedure Based on Regression
- 如何理解95%置信区间
- 平稳时间序列分析 第三章
- Holt-Winters Forecasting for Dummies - Part II
- Holt-Winters Forecasting for Dummies - Part III
SLS机器学习介绍(01):时序统计建模相关推荐
- SLS机器学习介绍(02):时序聚类建模
文章系列链接 SLS机器学习介绍(01):时序统计建模 SLS机器学习介绍(02):时序聚类建模 SLS机器学习介绍(03):时序异常检测建模 SLS机器学习介绍(04):规则模式挖掘 前言 第一篇文 ...
- SLS机器学习介绍(05):时间序列预测
00系列文章目录 0.1 算法原理目录 SLS机器学习介绍(01):时序统计建模 SLS机器学习介绍(02):时序聚类建模 SLS机器学习介绍(03):时序异常检测建模 SLS机器学习介绍(04):规 ...
- 机器学习、数据挖掘、统计建模的技术担当,20款免费预测分析软件
本文推荐一些免费的预测分析软件,它们主要用于分析统计使用,机器学习和数据挖掘来寻找关于客户行为,市场趋势和原始数据集中其他领域的线索的相关性和模式.其中一些预测建模解决方案可通过许可,免费获得开源或社 ...
- 你真的了解机器学习、人工智能、统计建模吗?
2019独角兽企业重金招聘Python工程师标准>>> 一.机器学习 机器学习是以数据为基础,它专注于为回归和分类算法.其底层随机机制往往是次要的.不被重视的.当然,许多机器学习技术 ...
- SLS机器学习最佳实战:批量时序异常检测
0.文章系列链接 SLS机器学习介绍(01):时序统计建模 SLS机器学习介绍(02):时序聚类建模 SLS机器学习介绍(03):时序异常检测建模 SLS机器学习介绍(04):规则模式挖掘 SLS机器 ...
- SLS机器学习最佳实战:日志聚类+异常告警
0.文章系列链接 SLS机器学习介绍(01):时序统计建模 SLS机器学习介绍(02):时序聚类建模 SLS机器学习介绍(03):时序异常检测建模 SLS机器学习介绍(04):规则模式挖掘 SLS机器 ...
- 【李宏毅机器学习】01:机器学习介绍 Introduction
李宏毅机器学习01:机器学习介绍 Introduction 文章目录 李宏毅机器学习01:机器学习介绍 Introduction 一.机器学习步骤 二.机器学习框架 三.机器学习学习地图 (一)Lea ...
- 李宏毅机器学习01机器学习介绍
机器学习介绍 机器学习与人工智慧 人工智慧(AI).Artificial Intelligence是我们想要达成的目标,而机器学习是想要达成目标的手段,希望机器通过学习方式,他跟人一样聪明. 深度学习 ...
- 机器学习与统计建模 —— 差异和联系
相同点 1.相同的目标:从数据中学习,核心都是探讨如何从数据中提取人们需要的信息或规律. 2.相同含义的常见术语: 不同点 1.不同的学派: 机器学习(Machine Learning, ML)是一门 ...
最新文章
- 关于rtsp的时间戳问题
- 带有BERT模型代码的BILSTM+BERT+CRF
- Python字符串常用操作
- 神经网络优化中的Weight Averaging
- MySQL使用distinct去掉查询结果重复的记录
- C语言中要改变循环语句的流程可以使用的语句有哪些
- 利用python求解节点介数和边介数
- python爬虫循环表格xpath_python爬虫数据解析之xpath
- 【译】 WebSocket 协议第十章——安全性考虑(Security Considerations)
- Docker配置国内加速器加速镜像下载的方法
- 【解决】Ubuntu安装NVIDIA驱动(咨询NVIDIA工程师的解决方案)
- 一粒云盘发布v3.5版本
- 802.11n无线网卡驱动linux,Ubuntu 无线网卡驱动安装教程
- Java excel添加水印
- 开源数据库postgreSQL13在麒麟v10sp1源码安装
- GoogleStyle编程代码规范
- 佳沛奇异果猕猴桃扫盲
- 微信撤回信息怎么用Python找回来?
- 你好你好你好你好你好你好
- gem 安装oxidized-web报错:checking for -licui18n... no处理