postgresql索引_PostgreSQL中的索引— 8(RUM)
postgresql索引
indexing engine, the interface of access methods, and main access methods, such as: 索引引擎 ,访问方法的接口以及主要访问方法,例如: hash indexes, 哈希索引 , B-trees, B树 , GiST, GiST , SP-GiST, and SP-GiST和GIN. In this article, we will watch how gin turns into rum.GIN 。 在本文中,我们将观察杜松子酒如何变成RUM。
RUM (RUM)
Although the authors claim that gin is a powerful genie, the theme of drinks has eventually won: next-generation GIN has been called RUM.
尽管作者声称杜松子酒是一种强大的精灵,但饮料的主题最终获得了胜利:下一代GIN被称为RUM。
This access method expands the concept that underlies GIN and enables us to perform full-text search even faster. In this series of articles, this is the only method that is not included in a standard PostgreSQL delivery and is an external extension. Several installation options are available for it:
这种访问方法扩展了GIN基础的概念,并使我们能够更快地执行全文搜索。 在本系列文章中,这是标准PostgreSQL交付中未包含的唯一方法,并且是外部扩展。 有几个安装选项可供使用:
Take «yum» or «apt» package from the PGDG repository. For example, if you installed PostgreSQL from «postgresql-10» package, also install «postgresql-10-rum».
从PGDG存储库中获取«yum»或«apt»软件包。 例如,如果从«postgresql-10»软件包安装了PostgreSQL,则还要安装«postgresql-10-rum»。
Build from source code on github and install on your own (the instruction is there as well).
从github上的源代码进行构建,然后自行安装(说明也存在)。
Use as a part of Postgres Pro Enterprise (or at least read the documentation from there).
用作Postgres Pro Enterprise的一部分(或至少从那里阅读文档 )。
GIN的局限性 (Limitations of GIN)
What limitations of GIN does RUM enable us to transcend?
RUM使我们能够超越GIN的哪些限制?
First, «tsvector» data type contains not only lexemes, but also information on their positions inside the document. As we observed last time, GIN index does not store this information. For this reason, operations to search for phrases, which appeared in version 9.6, are supported by GIN index inefficiently and have to access the original data for recheck.
首先,«tsvector»数据类型不仅包含词素,还包含有关它们在文档中位置的信息。 正如我们上次观察到的,GIN索引不存储此信息。 因此,GIN索引无法有效地支持9.6版中出现的短语搜索操作,并且必须访问原始数据以进行重新检查。
Second, search systems usually return the results sorted by relevance (whatever that means). We can use ranking functions «ts_rank» and «ts_rank_cd» to this end, but they have to be computed for each row of the result, which is certainly slow.
其次,搜索系统通常返回按相关性排序的结果(无论如何)。 为此,我们可以使用排名函数《 ts_rank》和《 ts_rank_cd》,但必须为结果的每一行计算它们,这肯定很慢。
To a first approximation, RUM access method can be considered as GIN that additionally stores position information and can return the results in a needed order (like GiST can return nearest neighbors). Let's move step by step.
对于第一近似,可以将RUM访问方法视为GIN,它另外存储位置信息并可以按所需顺序返回结果(例如GiST可以返回最近的邻居)。 让我们一步一步地前进。
搜索词组 (Searching for phrases)
A full-text search query can contain special operators that take into account the distance between lexemes. For example, we can find documents in which «hand» is separated from «thigh» with two more word:
全文搜索查询可以包含考虑了词素之间的距离的特殊运算符。 例如,我们可以找到文档中的“手”与“大腿”之间有两个不同的单词:
postgres=# select to_tsvector('Clap your hands, slap your thigh') @@to_tsquery('hand <3> thigh');?column?
----------t
(1 row)Or we can indicate that the words must be located one after another:
或者我们可以指出单词必须一个接一个地定位:
postgres=# select to_tsvector('Clap your hands, slap your thigh') @@to_tsquery('hand <-> slap');?column?
----------t
(1 row)Regular GIN index can return the documents that contain both lexemes, but we can check the distance between them only by looking into tsvector:
常规GIN索引可以返回包含两个词素的文档,但是我们只能通过查看tsvector来检查它们之间的距离:
postgres=# select to_tsvector('Clap your hands, slap your thigh');to_tsvector
--------------------------------------'clap':1 'hand':3 'slap':4 'thigh':6
(1 row)In RUM index, each lexeme does not just reference the table rows: each TID is supplied with the list of positions where the lexeme occurs in the document. This is how we can envisage the index created on the «slit-sheet» table, which is already quite familiar to us («rum_tsvector_ops» operator class is used for tsvector by default):
在RUM索引中,每个词素不仅仅引用表行:每个TID都提供了词素在文档中出现的位置列表。 这是我们可以设想的在«slit-sheet»表上创建的索引的方法,这个索引已经为我们所熟悉(默认情况下,«vector_ops»运算符类用于tsvector):
postgres=# create extension rum;postgres=# create index on ts using rum(doc_tsv);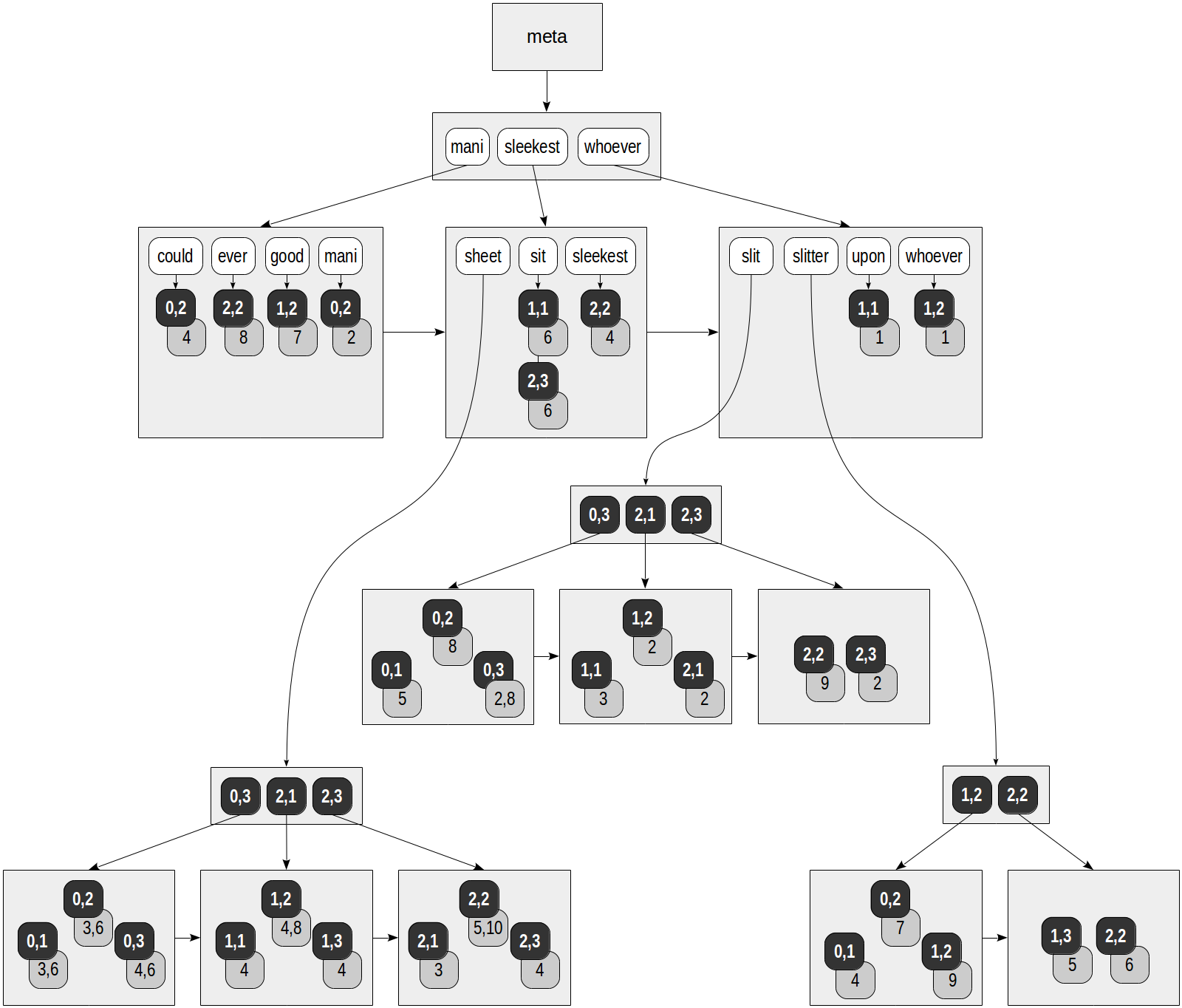
Gray squares in the figure contain the position information added:
图中的灰色方块包含添加的位置信息:
postgres=# select ctid, left(doc,20), doc_tsv from ts;ctid | left | doc_tsv
-------+----------------------+---------------------------------------------------------(0,1) | Can a sheet slitter | 'sheet':3,6 'slit':5 'slitter':4(0,2) | How many sheets coul | 'could':4 'mani':2 'sheet':3,6 'slit':8 'slitter':7(0,3) | I slit a sheet, a sh | 'sheet':4,6 'slit':2,8(1,1) | Upon a slitted sheet | 'sheet':4 'sit':6 'slit':3 'upon':1(1,2) | Whoever slit the she | 'good':7 'sheet':4,8 'slit':2 'slitter':9 'whoever':1(1,3) | I am a sheet slitter | 'sheet':4 'slitter':5(2,1) | I slit sheets. | 'sheet':3 'slit':2(2,2) | I am the sleekest sh | 'ever':8 'sheet':5,10 'sleekest':4 'slit':9 'slitter':6(2,3) | She slits the sheet | 'sheet':4 'sit':6 'slit':2
(9 rows)GIN also provides a postponed insertion when «fastupdate» parameter is specified; this functionality is removed from RUM.
当指定了“ fastupdate”参数时,GIN还提供了延迟的插入。 此功能已从RUM中删除。
To see how the index works on live data, let's use the familiar archive of pgsql-hackers mailing list.
要查看索引如何处理实时数据,让我们使用熟悉的pgsql-hackers邮件列表档案 。
fts=# alter table mail_messages add column tsv tsvector;fts=# set default_text_search_config = default;fts=# update mail_messages
set tsv = to_tsvector(body_plain);...
UPDATE 356125This is how a query that uses search for phrases is performed with GIN index:
这是通过GIN索引执行使用短语搜索的查询的方式:
fts=# create index tsv_gin on mail_messages using gin(tsv);fts=# explain (costs off, analyze)
select * from mail_messages where tsv @@ to_tsquery('hello <-> hackers');QUERY PLAN
---------------------------------------------------------------------------------Bitmap Heap Scan on mail_messages (actual time=2.490..18.088 rows=259 loops=1)Recheck Cond: (tsv @@ to_tsquery('hello <-> hackers'::text))Rows Removed by Index Recheck: 1517Heap Blocks: exact=1503-> Bitmap Index Scan on tsv_gin (actual time=2.204..2.204 rows=1776 loops=1)Index Cond: (tsv @@ to_tsquery('hello <-> hackers'::text))Planning time: 0.266 msExecution time: 18.151 ms
(8 rows)As we can see from the plan, GIN index is used, but it returns 1776 potential matches, of which 259 are left and 1517 are dropped at the recheck stage.
从计划中可以看到,使用了GIN索引,但它返回了1776个潜在匹配项,其中剩余259个匹配项,在重新检查阶段删除了1517个匹配项。
Let's delete the GIN index and build RUM.
让我们删除GIN索引并构建RUM。
fts=# drop index tsv_gin;fts=# create index tsv_rum on mail_messages using rum(tsv);The index now contains all the necessary information, and search is performed accurately:
现在,索引包含所有必要的信息,并且搜索可以准确地执行:
fts=# explain (costs off, analyze)
select * from mail_messages
where tsv @@ to_tsquery('hello <-> hackers');QUERY PLAN
--------------------------------------------------------------------------------Bitmap Heap Scan on mail_messages (actual time=2.798..3.015 rows=259 loops=1)Recheck Cond: (tsv @@ to_tsquery('hello <-> hackers'::text))Heap Blocks: exact=250-> Bitmap Index Scan on tsv_rum (actual time=2.768..2.768 rows=259 loops=1)Index Cond: (tsv @@ to_tsquery('hello <-> hackers'::text))Planning time: 0.245 msExecution time: 3.053 ms
(7 rows)按相关性排序 (Sorting by relevance)
To return documents readily in the needed order, RUM index supports ordering operators, which we discussed in GiST-related article. RUM extension defines such an operator, <=>, which returns some distance between the document («tsvector») and query («tsquery»). For example:
为了方便地按所需顺序返回文档,RUM索引支持排序运算符,我们在GiST相关文章中对此进行了讨论。 RUM扩展定义了这样的运算符<=> ,该运算符返回文档(«tsvector»)和查询(«tsquery»)之间的距离。 例如:
fts=# select to_tsvector('Can a sheet slitter slit sheets?') <=>l to_tsquery('slit');?column?
----------16.4493
(1 row)fts=# select to_tsvector('Can a sheet slitter slit sheets?') <=> to_tsquery('sheet');?column?
----------13.1595
(1 row)The document appeared to be more relevant to the first query than to the second one: the more often the word occurs, the less «valuable» it is.
该文档似乎与第一个查询更相关,而与第二个查询更相关:单词出现的频率越高,其“有价值”越少。
Let's again try to compare GIN and RUM on a relatively large data size: we'll select ten most relevant documents containing «hello» and «hackers».
让我们再次尝试在相对较大的数据大小上比较GIN和RUM:我们将选择十个最相关的文档,其中包含“你好”和“黑客”。
fts=# explain (costs off, analyze)
select * from mail_messages
where tsv @@ to_tsquery('hello & hackers')
order by ts_rank(tsv,to_tsquery('hello & hackers'))
limit 10;QUERY PLAN
---------------------------------------------------------------------------------------------Limit (actual time=27.076..27.078 rows=10 loops=1)-> Sort (actual time=27.075..27.076 rows=10 loops=1)Sort Key: (ts_rank(tsv, to_tsquery('hello & hackers'::text)))Sort Method: top-N heapsort Memory: 29kB-> Bitmap Heap Scan on mail_messages (actual ... rows=1776 loops=1)Recheck Cond: (tsv @@ to_tsquery('hello & hackers'::text))Heap Blocks: exact=1503-> Bitmap Index Scan on tsv_gin (actual ... rows=1776 loops=1)Index Cond: (tsv @@ to_tsquery('hello & hackers'::text))Planning time: 0.276 msExecution time: 27.121 ms
(11 rows)GIN index returns 1776 matches, which are then sorted as a separate step to select ten best hits.
GIN索引返回1776个匹配项,然后将其作为单独的步骤进行排序以选择十个最佳匹配项。
With RUM index, the query is performed using a simple index scan: no extra documents are looked through, and no separate sorting is required:
使用RUM索引,可以使用简单的索引扫描来执行查询:无需查看额外的文档,并且不需要单独的排序:
fts=# explain (costs off, analyze)
select * from mail_messages
where tsv @@ to_tsquery('hello & hackers')
order by tsv <=> to_tsquery('hello & hackers')
limit 10;QUERY PLAN
--------------------------------------------------------------------------------------------Limit (actual time=5.083..5.171 rows=10 loops=1)-> Index Scan using tsv_rum on mail_messages (actual ... rows=10 loops=1)Index Cond: (tsv @@ to_tsquery('hello & hackers'::text))Order By: (tsv <=> to_tsquery('hello & hackers'::text))Planning time: 0.244 msExecution time: 5.207 ms
(6 rows)附加信息 (Additional information)
RUM index, as well as GIN, can be built on several fields. But while GIN stores lexemes from each column independently of those from another column, RUM enables us to «associate» the main field («tsvector» in this case) with an additional one. To do this, we need to use a specialized operator class «rum_tsvector_addon_ops»:
RUM索引以及GIN可以建立在几个字段上。 但是,尽管GIN分别存储每一列的词素与另一列的词素,但RUM使我们能够将主字段(在本例中为“ tsvector”)“附加”一个附加字段。 为此,我们需要使用专门的运算符类“ rum_tsvector_addon_ops»:
fts=# create index on mail_messages using rum(tsv RUM_TSVECTOR_ADDON_OPS, sent)WITH (ATTACH='sent', TO='tsv');We can use this index to return the results sorted on the additional field:
我们可以使用此索引来返回按附加字段排序的结果:
fts=# select id, sent, sent <=> '2017-01-01 15:00:00'
from mail_messages
where tsv @@ to_tsquery('hello')
order by sent <=> '2017-01-01 15:00:00'
limit 10;id | sent | ?column?
---------+---------------------+----------2298548 | 2017-01-01 15:03:22 | 2022298547 | 2017-01-01 14:53:13 | 4072298545 | 2017-01-01 13:28:12 | 55082298554 | 2017-01-01 18:30:45 | 126452298530 | 2016-12-31 20:28:48 | 666722298587 | 2017-01-02 12:39:26 | 779662298588 | 2017-01-02 12:43:22 | 782022298597 | 2017-01-02 13:48:02 | 820822298606 | 2017-01-02 15:50:50 | 894502298628 | 2017-01-02 18:55:49 | 100549
(10 rows)Here we search for matching rows being as close to the specified date as possible, no matter earlier or later. To get the results that are strictly preceding (or following) the specified date, we need to use <=| (or |=>) operator.
在这里,我们搜索匹配的行,这些行尽可能早于指定日期,而不管早晚。 要获得严格在指定日期之前(或之后)的结果,我们需要使用<=| (或|=> )运算符。
As we expect, the query is performed just by a simple index scan:
如我们所料,查询仅通过简单的索引扫描执行:
ts=# explain (costs off)
select id, sent, sent <=> '2017-01-01 15:00:00'
from mail_messages
where tsv @@ to_tsquery('hello')
order by sent <=> '2017-01-01 15:00:00'
limit 10;QUERY PLAN
---------------------------------------------------------------------------------Limit-> Index Scan using mail_messages_tsv_sent_idx on mail_messagesIndex Cond: (tsv @@ to_tsquery('hello'::text))Order By: (sent <=> '2017-01-01 15:00:00'::timestamp without time zone)
(4 rows)If we created the index without the additional information on the field association, for a similar query, we would have to sort all results of the index scan.
如果创建索引时没有字段关联的附加信息,则对于类似的查询,我们将必须对索引扫描的所有结果进行排序。
In addition to the date, we can certainly add fields of other data types to RUM index. Virtually all base types are supported. For example, an online store can quickly display goods by novelty (date), price (numeric), and popularity or discount value (integer or floating-point).
除了日期,我们当然可以将其他数据类型的字段添加到RUM索引中。 几乎所有基本类型都受支持。 例如,在线商店可以按新颖性(日期),价格(数字)以及受欢迎程度或折扣值(整数或浮点数)快速显示商品。
其他操作员类别 (Other operator classes)
To complete the picture, we should mention other operator classes available.
为了使图片更完整,我们应该提到其他可用的运算符类。
Let's start with «rum_tsvector_hash_ops» and «rum_tsvector_hash_addon_ops». They are similar to already discussed «rum_tsvector_ops» and «rum_tsvector_addon_ops», but the index stores hash code of the lexeme rather than the lexeme itself. This can reduce the index size, but of course, search becomes less accurate and requires recheck. Besides, the index no longer supports search of a partial match.
让我们从«rum_tsvector_hash_ops»和«rum_tsvector_hash_addon_ops»开始 。 它们类似于已经讨论过的《 rum_tsvector_ops》和《 rum_tsvector_addon_ops》,但是索引存储的是词素的哈希码,而不是词素本身。 这样可以减小索引的大小,但是搜索的准确性当然会降低,需要重新检查。 此外,索引不再支持部分匹配的搜索。
It is interesting to look at «rum_tsquery_ops» operator class. It enables us to solve an «inverse» problem: find queries that match the document. Why could this be needed? For example, to subscribe a user to new goods according to his/her filter or to automatically categorize new documents. Look at this simple example:
看看“ rum_tsquery_ops”运算符类很有趣。 它使我们能够解决“逆向”问题:查找与文档匹配的查询。 为什么需要这个? 例如,根据用户的过滤器为用户订阅新商品或自动对新文档进行分类。 看这个简单的例子:
fts=# create table categories(query tsquery, category text);fts=# insert into categories values(to_tsquery('vacuum | autovacuum | freeze'), 'vacuum'),(to_tsquery('xmin | xmax | snapshot | isolation'), 'mvcc'),(to_tsquery('wal | (write & ahead & log) | durability'), 'wal');fts=# create index on categories using rum(query);fts=# select array_agg(category)
from categories
where to_tsvector('Hello hackers, the attached patch greatly improves performance of tuplefreezing and also reduces size of generated write-ahead logs.'
) @@ query;array_agg
--------------{vacuum,wal}
(1 row)The remaining operator classes «rum_anyarray_ops» and «rum_anyarray_addon_ops» are designed to manipulate arrays rather than «tsvector». This was already discussed for GIN last time and does not need to be repeated.
其余的运算符类“ rum_anyarray_ops”和“ rum_anyarray_addon_ops”旨在操作数组,而不是“ tsvector”。 上次已经针对GIN进行了讨论,因此无需重复。
索引和预写日志(WAL)的大小 (The sizes of the index and write-ahead log (WAL))
It is clear that since RUM stores more information than GIN, it must have larger size. We were comparing the sizes of different indexes last time; let's add RUM to this table:
显然,由于RUM比GIN存储更多的信息,因此它必须具有更大的大小。 我们上次正在比较不同索引的大小; 让我们将RUM添加到此表中:
rum | gin | gist | btree
--------+--------+--------+--------457 MB | 179 MB | 125 MB | 546 MBAs we can see, the size grew quite significantly, which is the cost of fast search.
如我们所见,大小增长非常明显,这就是快速搜索的成本。
It is worth paying attention to one more unobvious point: RUM is an extension, that is, it can be installed without any modifications to the system core. This was enabled in version 9.6 thanks to a patch by Alexander Korotkov. One of the problems that had to be solved to this end was generation of log records. A technique for logging of operations must be absolutely reliable, therefore, an extension cannot be let into this kitchen. Instead of permitting the extension to create its own types of log records, the following is in place: the code of the extension communicates its intention to modify a page, makes any changes to it, and signals the completion, and it's the system core, which compares the old and new versions of the page and generates unified log records required.
值得一提的是,RUM是一个扩展,也就是说,可以在不对系统核心进行任何修改的情况下安装RUM。 感谢Alexander Korotkov的补丁,此功能已在9.6版中启用。 为此必须解决的问题之一是日志记录的生成。 用于记录操作的技术必须绝对可靠,因此,不能在此厨房中进行扩展。 代替了允许扩展程序创建自己的日志记录类型,而是执行以下操作:扩展程序的代码传达其修改页面的意图,对其进行任何更改并发出完成信号,并且它是系统的核心,比较页面的旧版本和新版本,并生成所需的统一日志记录。
The current log generation algorithm compares pages byte by byte, detects updated fragments, and logs each of these fragments, along with its offset from the page start. This works fine when updating only several bytes or the entire page. But if we add a fragment inside a page, moving the rest of the content down (or vice versa, remove a fragment, moving the content up), significantly more bytes will change than were actually added or removed.
当前的日志生成算法逐字节比较页面,检测更新的片段,并记录这些片段中的每一个以及其与页面开始的偏移量。 仅更新几个字节或整个页面时,这可以很好地工作。 但是,如果我们在页面内添加一个片段,将其余内容向下移动(反之亦然,删除一个片段,向上移动内容),则更改的字节数将比实际添加或删除的字节多得多。
Due to this, intensively changing RUM index may generate log records of a considerably larger size than GIN (which, being not an extension, but a part of the core, manages the log on its own). The extent of this annoying effect greatly depends on an actual workload, but to get an insight into the issue, let's try to remove and add a number of rows several times, interleaving these operations with “vacuum”. We can evaluate the size of log records as follows: at the beginning and at the end, remember the position in the log using «pg_current_wal_location» function («pg_current_xlog_location» in versions earlier than ten) and then look at the difference.
因此,大量更改的RUM索引可能会生成比GIN大得多的日志记录(GIN不是扩展,而是核心的一部分,它自己管理日志)。 这种烦人的影响的程度在很大程度上取决于实际的工作量,但是为了深入了解该问题,让我们尝试多次删除并添加许多行,并将这些操作与“真空”交织在一起。 我们可以评估日志记录的大小,如下所示:在开始和结束时,请使用«pg_current_wal_location»函数(在十个以前的版本中为«pg_current_xlog_location»)记住日志中的位置,然后查看两者之间的区别。
But of course, we should consider a lot of aspects here. We need to make sure that only one user is working with the system (otherwise, «extra» records will be taken into account). Even if this is the case, we take into account not only RUM, but also updates of the table itself and of the index that supports the primary key. Values of configuration parameters also affect the size («replica» log level, without compression, was used here). But let's try anyway.
但是,当然,我们应该在这里考虑很多方面。 我们需要确保只有一个用户正在使用该系统(否则,将考虑“额外”记录)。 即使是这种情况,我们不仅要考虑RUM,还要考虑表本身以及支持主键的索引的更新。 配置参数的值也会影响大小(此处使用了“副本”日志级别,未压缩)。 但是我们还是尝试一下。
fts=# select pg_current_wal_location() as start_lsn \gsetfts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv)select parent_id, sent, subject, author, body_plain, tsvfrom mail_messages where id % 100 = 0;INSERT 0 3576fts=# delete from mail_messages where id % 100 = 99;DELETE 3590fts=# vacuum mail_messages;fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv)select parent_id, sent, subject, author, body_plain, tsvfrom mail_messages where id % 100 = 1;INSERT 0 3605fts=# delete from mail_messages where id % 100 = 98;DELETE 3637fts=# vacuum mail_messages;fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv)select parent_id, sent, subject, author, body_plain, tsv from mail_messageswhere id % 100 = 2;INSERT 0 3625fts=# delete from mail_messages where id % 100 = 97;DELETE 3668fts=# vacuum mail_messages;fts=# select pg_current_wal_location() as end_lsn \gset
fts=# select pg_size_pretty(:'end_lsn'::pg_lsn - :'start_lsn'::pg_lsn);pg_size_pretty
----------------3114 MB
(1 row)So, we get around 3 GB. But if we repeat the same experiment with GIN index, this will make only around 700 MB.
因此,我们得到了大约3 GB。 但是,如果我们对GIN索引重复相同的实验,则只会占用700 MB左右的空间。
Therefore, it is desirable to have a different algorithm, which will find the minimal number of insert and delete operations that can transform one state of the page into another one. «diff» utility works in a similar way. Oleg Ivanov has already implemented such an algorithm, and his patch is being discussed. In the above example, this patch enables us to reduce the size of log records by 1.5 times, to 1900 MB, at the cost of a small slowdown.
因此,希望有一种不同的算法,该算法将找到可以将页面的一种状态转换为另一种状态的最小数量的插入和删除操作。 «diff»实用程序的工作方式与此类似。 Oleg Ivanov已经实现了这样的算法,并且他的补丁正在讨论中。 在上面的示例中,此补丁使我们能够将日志记录的大小减少1.5倍,达到1900 MB,但代价是速度有所降低。
物产 (Properties)
As usual, let's look at the properties of RUM access method, paying attention to the differences from GIN (queries have already been provided).
像往常一样,让我们看一下RUM访问方法的属性,注意与GIN的区别( 已经提供了查询)。
The following are the properties of the access method:
以下是访问方法的属性:
amname | name | pg_indexam_has_property
--------+---------------+-------------------------rum | can_order | frum | can_unique | frum | can_multi_col | trum | can_exclude | t -- f for ginThe following index-layer properties are available:
以下索引层属性可用:
name | pg_index_has_property
---------------+-----------------------clusterable | findex_scan | t -- f for ginbitmap_scan | tbackward_scan | fNote that, unlike GIN, RUM supports index scan — otherwise, it would not have been possible to return exactly the required number of results in queries with «limit» clause. There is no need for the counterpart of «gin_fuzzy_search_limit» parameter accordingly. And as a consequence, the index can be used to support exclusion constraints.
请注意,与GIN不同,RUM支持索引扫描-否则,将不可能在带有«limit»子句的查询中精确返回所需数目的结果。 不需要相应地使用«gin_fuzzy_search_limit»参数。 因此,该索引可用于支持排除约束。
The following are column-layer properties:
以下是列层属性:
name | pg_index_column_has_property
--------------------+------------------------------asc | fdesc | fnulls_first | fnulls_last | forderable | fdistance_orderable | t -- f for ginreturnable | fsearch_array | fsearch_nulls | fThe difference here is that RUM supports ordering operators. However, this is true not for all operator classes: for example, this is false for «tsquery_ops».
此处的区别在于RUM支持排序运算符。 但是,并非对所有运算符类都是如此:例如,对于“ tsquery_ops”而言,它为false。
Read on.继续阅读 。
翻译自: https://habr.com/en/company/postgrespro/blog/452116/
postgresql索引
postgresql索引_PostgreSQL中的索引— 8(RUM)相关推荐
- postgresql索引_PostgreSQL中的索引— 10(Bloom)
postgresql索引 indexing engine and the interface of access methods, as well as 索引引擎和访问方法的接口,以及hash ind ...
- postgresql索引_PostgreSQL中的索引— 6(SP-GiST)
postgresql索引 indexing engine, 索引引擎 , the interface of access methods, and three methods: 访问方法的接口以及三种 ...
- MySQL普通索引与唯一索引__mysql中唯一索引和普通索引的用途及区别
MySQL普通索引与唯一索引 索引作用: 提高查询效率,一般加在经常查询或者排序的字段上. 普通索引: 允许字段值重复 唯一索引: 保证数据记录唯一性 如何选择: 查询过程: 对普通索引来说,找到满足 ...
- 6.ES中什么是索引(ES中的索引指的是库)的分片和备份(副本)?ES中的关键词有哪些? 嘻哈的简写笔记——Elastic Search
1.ES中什么是索引(ES中的索引指的是库)的分片和备份(副本)? 分片是对索引的切分存储:备份是对分片的备份: ES的服务中,可以创建多个索引(ES中的索引指的是库):每一个索引默认被分成5片存储: ...
- postgresql 锁_PostgreSQL中的锁:3.其他锁
postgresql 锁 object-level locks (specifically, relation-level locks), as well as 对象级别的锁 (特别是关系级别的锁), ...
- php普通索引和唯一索引,MySQL中普通索引和唯一索引的区别详解
本篇文章介绍了MySQL中普通索引和唯一索引的区别,讲解很详细,希望对学习MySQL的朋友有帮助! 需要注意的是: redo log中的数据,可能还没有 flush 到磁盘,磁盘中的 Page 1 和 ...
- mysql添加临时索引_mysql 中添加索引的三种方法
在mysql中有多种索引,有普通索引,全文索引,唯一索引,多列索引,小伙伴们可以通过不同的应用场景来进行索引的新建,在此列出三种新建索引的方法 mysql 中添加索引的三种方法 1.1 新建表中添加索 ...
- oracle中常见索引,Oracle中的索引详解(整理)
一. ROWID的概念 存储了row在数据文件中的具体位置:64位 编码的数据,A-Z, a-z, 0-9, +, 和 /, row在数据块中的存储方式 SELECT ROWID, last_name ...
- oracle加强制索引,Oracle中建立索引并强制优化器使用
当WHERE子句对某一列使用函数时,除非利用这个简单的技术强制索引,否则Oracle优化器不能在查询中使用索引. 通常情况下,如果在WHERE子句中不使用诸如UPPER.REPLACE 或SUBSTR ...
最新文章
- 从 idea打包工程到dos下命令运行
- Android编程获取网络连接状态(3G/Wifi)及调用网络配置界面
- STL 之 list 容器详解
- Oracle 作业学习总结
- 图文详解 Kubernetes,刺激…
- 28和lba48命令格式区别_编译Sass(命令行)
- vb升级工作笔记001---VB.NET升级到VB.NET 随时更新
- 5g网络架构_【5G网络架构】系列之五:5G核心网向to B演进
- 20190917:(leetcode习题)将有序数组转换为二叉搜索树
- python batch_size_Python config.batch_size方法代码示例
- eclipse如何安装java decompiler反编译插件
- 微信开发者工具在C盘下User Data有啥用,能删掉吗?占用空间超大
- JAVA调用WebService的三种方法
- weAdmin(layuiAdmin)
- 吉首大学2019年程序设计竞赛 A-SARS病毒(递推推公式)
- eleme 分页组件更新
- d3d11初窥(Introduction to 3D Game Programming with DirectX 11下载)
- 阿里云直播服务拉流地址播放不出来
- 解释耳语协议和 Status.im
- 客户端与服务器的理解
热门文章
- Sketch 快速创建调色板技巧(PS 同样适用)
- 面试官,怎样实现 Router 框架?
- Lind.DDD敏捷领域驱动框架~Lind.DDD各层介绍
- Java multiplechoice,雅思听力八大题型之Multiple Choice题型篇
- android studio开发的时候出现design editor is unavailable until after a successful project sync问题的解决方法
- CCRenderTexture画点出现十字架歪解
- 深入剖析串口通信数据格式
- 吴裕雄--天生自然 诗经:长恨歌
- ASEMI整流桥大全,整流桥知识型号大全
- PCDViewer 3.2 Linux 版(Ubuntu)