python爬虫爬取豆瓣电影
最近买了《python编程从入门到实践》,想之后写两篇文章,一篇数据可视化,一篇python web,今天这篇就当python入门吧。
一.前期准备:
IDE准备:pycharm
导入的python库:requests用于请求,BeautifulSoup用于网页解析
二.实现步骤
1.传入url
2.解析返回的数据
3.筛选
4.遍历提取数据
三.代码实现
import requests # 导入网页请求库
from bs4 import BeautifulSoup # 导入网页解析库# 传入URL
r = requests.get("https://movie.douban.com/top250")# 解析返回的数据
soup=BeautifulSoup(r.content,"html.parser")#找到div中,class属性为item的div
movie_list=soup.find_all("div",class_="item")#遍历提取数据
for movie in movie_list:title=movie.find("span",class_="title").textrating_num=movie.find("span",class_="rating_num").textinq=movie.find("span",class_="inq").textstar = movie.find('div', class_='star')comment_num = star.find_all('span')[-1].textprint(title, rating_num, '\n', comment_num, inq, '\n')
以title变量为例,我们找到了div中,class属性为item的div,然后在此div中,筛选出class名为title的span,获取文本内容,打印(comment_num比较特殊,因为其在star的div下,没有class属性,为div中最后一个span,所以我们取出star层级中最后一个span,变为文本),以下是输出结果。
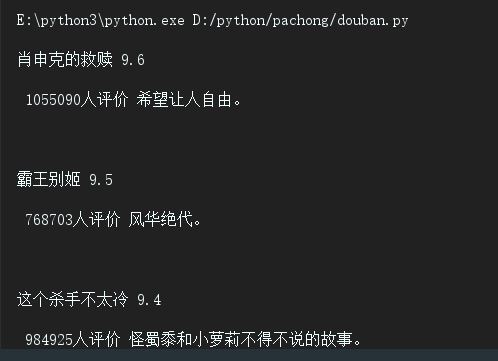
四.对获取到的数据进行整合
1.整合成列表
2.整合成json文件
3.定义为函数形式
1.整合成列表
import requests # 导入网页请求库
from bs4 import BeautifulSoup # 导入网页解析库
import pprint # 规范显示列表的插件库# 传入URL
r = requests.get("https://movie.douban.com/top250")# 解析返回的数据
soup=BeautifulSoup(r.content,"html.parser")#找到div中,class属性为item的div
movie_list=soup.find_all("div",class_="item")#创建存储结果的空列表
result_list=[]#遍历提取数据
for movie in movie_list:#创建字典dict={}dict["title"]=movie.find("span",class_="title").textdict["dictrating_num"]=movie.find("span",class_="rating_num").textdict["inq"]=movie.find("span",class_="inq").textstar = movie.find('div', class_='star')dict["comment_num"] = star.find_all('span')[-1].textresult_list.append(dict)# 显示结果
pp = pprint.PrettyPrinter(indent=4)
pp.pprint(result_list)
控制台显示的结果:
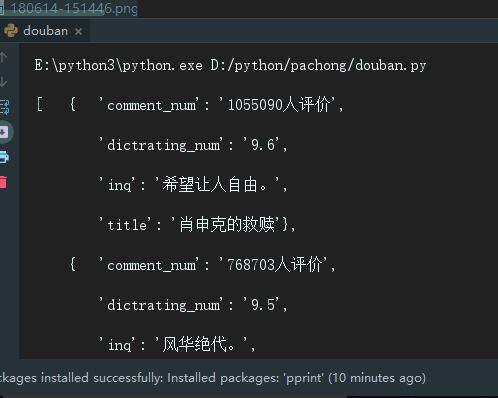
2.整合成JSON文件
import requests # 导入网页请求库
import json# 用于将列表字典(json格式)转化为相同形式字符串,以便存入文件
from bs4 import BeautifulSoup # 导入网页解析库# 传入URL
r = requests.get("https://movie.douban.com/top250")# 解析返回的数据
soup=BeautifulSoup(r.content,"html.parser")#找到div中,class属性为item的div
movie_list=soup.find_all("div",class_="item")#创建存储结果的空列表
result_list=[]#遍历提取数据
for movie in movie_list:#创建字典dict={}dict["title"]=movie.find("span",class_="title").textdict["dictrating_num"]=movie.find("span",class_="rating_num").textdict["inq"]=movie.find("span",class_="inq").textstar = movie.find('div', class_='star')dict["comment_num"] = star.find_all('span')[-1].textresult_list.append(dict)# 显示结果
# 将result_list这个json格式的python对象转化为字符串
s = json.dumps(result_list, indent = 4, ensure_ascii=False)
# 将字符串写入文件
with open('movies.json', 'w', encoding = 'utf-8') as f:f.write(s)结果:
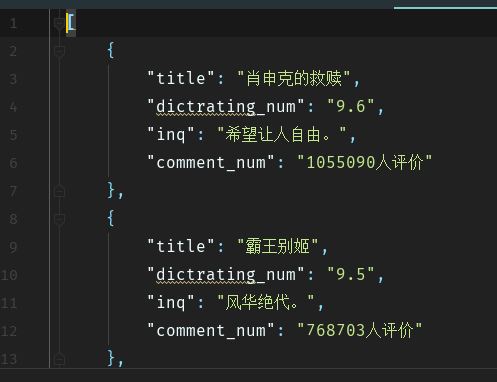
3.定义成函数
import requests # 导入网页请求库
import json# 用于将列表字典(json格式)转化为相同形式字符串,以便存入文件
from bs4 import BeautifulSoup # 导入网页解析库# 用于发送请求,获得网页源代码以供解析
def start_requests(url):r = requests.get(url)return r.content# 解析返回的数据
def parse(text):soup=BeautifulSoup(text,"html.parser")movie_list=soup.find_all("div",class_="item")result_list=[]for movie in movie_list:#创建字典dict={}dict["title"]=movie.find("span",class_="title").textdict["dictrating_num"]=movie.find("span",class_="rating_num").textdict["inq"]=movie.find("span",class_="inq").textstar = movie.find('div', class_='star')dict["comment_num"] = star.find_all('span')[-1].textresult_list.append(dict)return result_list#将数据写入json文件
def write_json(result):s = json.dumps(result, indent = 4, ensure_ascii=False)with open('movies1.json', 'w', encoding = 'utf-8') as f:f.write(s)# 主运行函数,调用其他函数
def main():url = 'https://movie.douban.com/top250'text = start_requests(url)result = parse(text)write_json(result)if __name__ == '__main__':main()
结果:
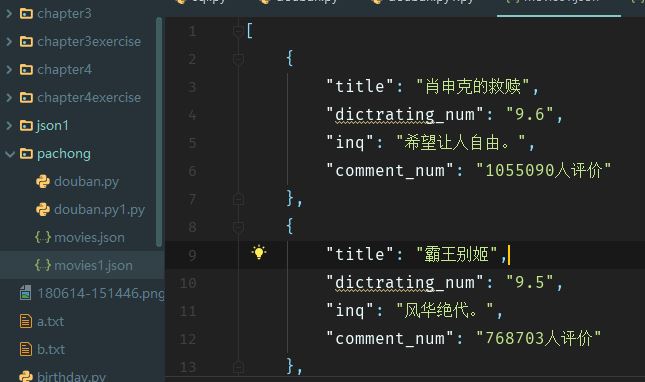
觉得有用的话就给颗小吧~
python爬虫爬取豆瓣电影相关推荐
- Python爬虫 爬取豆瓣电影TOP250
Python爬虫 爬取豆瓣电影TOP250 最近在b站上学习了一下python的爬虫,实践爬取豆瓣的电影top250,现在对这两天的学习进行一下总结 主要分为三步: 爬取豆瓣top250的网页,并通过 ...
- python爬虫爬取豆瓣电影排行榜并通过pandas保存到Excel文件当中
我们的需求是利用python爬虫爬取豆瓣电影排行榜数据,并将数据通过pandas保存到Excel文件当中(步骤详细) 我们用到的第三方库如下所示: import requests import pan ...
- Python爬虫爬取豆瓣电影评论内容,评论时间和评论人
Python爬虫爬取豆瓣电影评论内容,评论时间和评论人 我们可以看到影评比较长,需要展开才能完整显示.但是在网页源码中是没有显示完整影评的.所以我们考虑到这部分应该是异步加载的方式显示.所以打开网页的 ...
- python爬虫爬取豆瓣电影信息城市_Python爬虫入门 | 2 爬取豆瓣电影信息
这是一个适用于小白的Python爬虫免费教学课程,只有7节,让零基础的你初步了解爬虫,跟着课程内容能自己爬取资源.看着文章,打开电脑动手实践,平均45分钟就能学完一节,如果你愿意,今天内你就可以迈入爬 ...
- Python爬虫爬取豆瓣电影Top250
爬虫爬取豆瓣Top250 文章目录 爬虫爬取豆瓣Top250 完整代码 第一步获取整个网页并以html来解析 正则表达式来匹配关键词 所有信息写入列表中 存入Excel中 效果如图 本文学习自B站UP ...
- 用Python爬虫爬取豆瓣电影、读书Top250并排序
更新:已更新豆瓣电影Top250的脚本及网站 概述 经常用豆瓣读书的童鞋应该知道,豆瓣Top250用的是综合排序,除用户评分之外还考虑了很多比如是否畅销.点击量等等,这也就导致了一些近年来评分不高的畅 ...
- python爬虫爬取豆瓣电影信息城市_python爬虫,爬取豆瓣电影信息
hhhhh开心,搞了一整天,查了不少python基础资料,终于完成了第一个最简单的爬虫:爬取了豆瓣top250电影的名字.评分.评分人数以及短评. 代码实现如下:#第一个最简单的爬虫 #爬取了豆瓣to ...
- PYTHON爬虫爬取豆瓣电影的一周口碑电影排行榜
代码前准备: 1.使用Eclipse进行开发,关于eclipse搭建python的环境见:https://www.cnblogs.com/telwanggs/p/7016803.html 2.使用bs ...
- python爬虫爬取豆瓣电影排行榜,并写进csv文件,可视化数据分析
#1.爬取内容,写进csv文件 import requests import re import csv #豆瓣电影排行榜,写进csv文件 url = "https://movie.doub ...
- python爬取豆瓣电影top250的代码_Python爬虫——爬取豆瓣电影Top250代码实例
利用python爬取豆瓣电影Top250的相关信息,包括电影详情链接,图片链接,影片中文名,影片外国名,评分,评价数,概况,导演,主演,年份,地区,类别这12项内容,然后将爬取的信息写入Excel表中 ...
最新文章
- MobileNets论文阅读笔记
- 2015人脸检测研究进展
- tensorflow随笔-变量
- 如何搭建Electron开发环境
- oracle 自治事物,自治事务 - 努力创造未来! - BlogJava
- 【报告分享】2022年私域电商平台趋势报告.pdf(附下载链接)
- 【大数据】0002---MongoDB集群自动分离创建新集群
- 小米手环6NFc支持Android,小米手环6普通版和NFC版有什么区别-哪个好-哪款更值得入手...
- 计算机刷bios版本,华硕主板怎么刷BIOS版本?华硕主板在线升级BIOS详细图文教程...
- 多元统计分析最短距离法_多元统计分析方法
- 电路(第五版)邱关源 第一章总结
- 计算机无法识别荣耀9,华为荣耀9连接不上电脑端华为手机助手怎么处理?
- java 时钟_Java的指针时钟
- 微商城、小程序商城、APP商城对比
- 国内热门ERP软件有哪些推荐?
- 怎么用计算机直接截图,电脑怎么截图?使用电脑截图的多种方法
- linux没有cpufreq目录,Linux内核的cpufreq(变频)机制
- uniapp 埋点(友盟)
- LINQ To SQL與Transaction
- 深入理解搜索引擎——详解query理解