AI Studio 飞桨 零基础入门深度学习笔记6.3-手写数字识别之数据处理
AI Studio 飞桨 零基础入门深度学习笔记6.3-手写数字识别之数据处理)
- 概述
- 前提条件
- 读入数据并划分数据集
- 扩展阅读:为什么学术界的模型总在不断精进呢?
- 训练样本乱序、生成批次数据
- 校验数据有效性
- 机器校验
- 人工校验
- 封装数据读取与处理函数
- 异步数据读取
概述
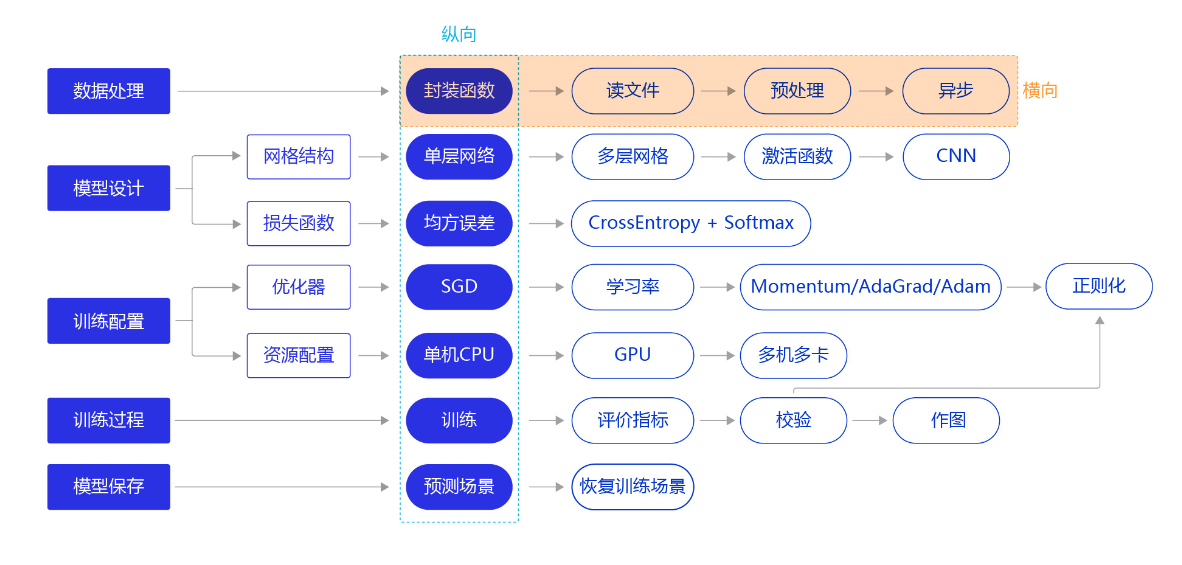
上一节我们使用“横纵式”教学法中的纵向极简方案快速完成手写数字识别任务的建模,但模型测试效果并未达成预期。我们换个思路,从横向展开,如 图1 所示,逐个环节优化,以达到最优训练效果。本节主要介绍手写数字识别模型中,数据处理的优化方法。
图1:“横纵式”教学法 — 数据处理优化
上一节,我们通过调用飞桨提供的API(paddle.dataset.mnist)加载MNIST数据集。但在工业实践中,我们面临的任务和数据环境千差万别,通常需要自己编写适合当前任务的数据处理程序,一般涉及如下五个环节:
- 读入数据
- 划分数据集
- 生成批次数据
- 训练样本集乱序
- 校验数据有效性
前提条件
在数据读取与处理前,首先要加载飞桨和数据处理库,代码如下。
# 加载飞桨和相关数据处理的库
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph.nn import Linear
import numpy as np
import os
import gzip
import json
import random
读入数据并划分数据集
在实际应用中,保存到本地的数据存储格式多种多样,如MNIST数据集以json格式存储在本地,其数据存储结构如 图2 所示。
图2:MNIST数据集的存储结构
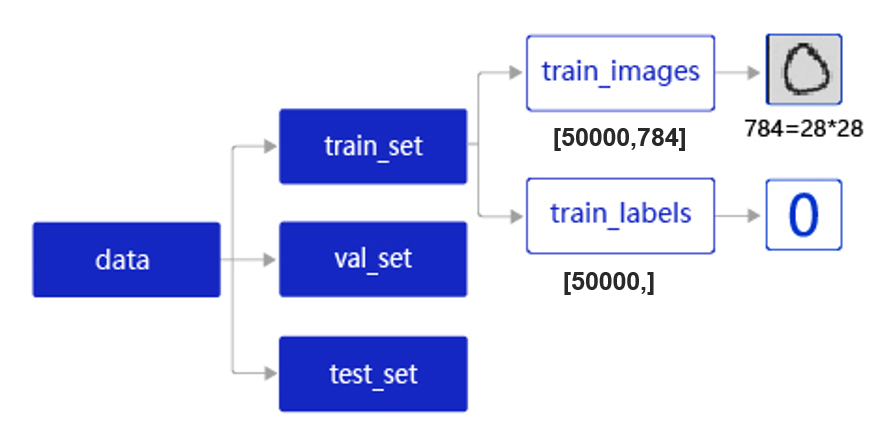
data包含三个元素的列表:train_set、val_set、 test_set,包括50000条训练样本,10000条测试样本,共60000条数据。每个样本包含手写数字图片和对应的标签。
- train_set(训练集):用于确定模型参数。
- val_set(验证集):用于调节模型超参数(如多个网络结构、正则化权重的最优选择)。
- test_set(测试集):用于估计应用效果(没有在模型中应用过的数据,更贴近模型在真实场景应用的效果)。
train_set包含两个元素的列表:train_images、train_labels。
- train_images:[50000, 784]的二维列表,包含50000张图片。每张图片用一个长度为784的向量表示,内容是28*28尺寸的像素灰度值(黑白图片)。
- train_labels:[50000, ]的列表,表示这些图片对应的分类标签,即0-9之间的一个数字。
在本地./work/目录下读取文件名称为mnist.json.gz的MNIST数据,并拆分成训练集、验证集和测试集,实现方法如下所示。
# 声明数据集文件位置
datafile = './work/mnist.json.gz'
print('loading mnist dataset from {} ......'.format(datafile))
# 加载json数据文件
data = json.load(gzip.open(datafile))
print('mnist dataset load done')
# 读取到的数据区分训练集,验证集,测试集
train_set, val_set, eval_set = data# 数据集相关参数,图片高度IMG_ROWS, 图片宽度IMG_COLS
IMG_ROWS = 28
IMG_COLS = 28# 打印数据信息
imgs, labels = train_set[0], train_set[1]
print("训练数据集数量: ", len(imgs))# 观察验证集数量
imgs, labels = val_set[0], val_set[1]
print("验证数据集数量: ", len(imgs))# 观察测试集数量
imgs, labels = val= eval_set[0], eval_set[1]
print("测试数据集数量: ", len(imgs))
loading mnist dataset from ./work/mnist.json.gz ......
mnist dataset load done
训练数据集数量: 50000
验证数据集数量: 10000
测试数据集数量: 10000
扩展阅读:为什么学术界的模型总在不断精进呢?
通常某组织发布一个新任务的训练集和测试集数据后,全世界的科学家都针对该数据集进行创新研究,随后大量针对该数据集的论文会陆续发表。论文1的A模型声称在测试集的准确率70%,论文2的B模型声称在测试集的准确率提高到72%,论文N的X模型声称在测试集的准确率提高到90% …
然而这些论文中的模型在测试集上准确率提升真实有效么?我们不妨大胆猜测一下。
假设所有论文共产生1000个模型,这些模型使用的是测试数据集来评判模型效果,并最终选出效果最优的模型。这相当于把原始的测试集当作了验证集,使得测试集失去了真实评判模型效果的能力,正如机器学习领域非常流行的一句话:“拷问数据足够久,它终究会招供”。
图3:拷问数据足够久,它总会招供
那么当我们需要将学术界研发的模型复用于工业项目时,应该如何选择呢?给读者一个小建议:当几个模型的准确率在测试集上差距不大时,尽量选择网络结构相对简单的模型。往往越精巧设计的模型和方法,越不容易在不同的数据集之间迁移。
训练样本乱序、生成批次数据
- 训练样本乱序: 先将样本按顺序进行编号,建立ID集合index_list。然后将index_list乱序,最后按乱序后的顺序读取数据。
说明:
通过大量实验发现,模型对最后出现的数据印象更加深刻。训练数据导入后,越接近模型训练结束,最后几个批次数据对模型参数的影响越大。为了避免模型记忆影响训练效果,需要进行样本乱序操作。
- 生成批次数据: 先设置合理的batch_size,再将数据转变成符合模型输入要求的np.array格式返回。同时,在返回数据时将Python生成器设置为
yield模式,以减少内存占用。
在执行如上两个操作之前,需要先将数据处理代码封装成load_data函数,方便后续调用。load_data有三种模型:train、valid、eval,分为对应返回的数据是训练集、验证集、测试集。
imgs, labels = train_set[0], train_set[1]
print("训练数据集数量: ", len(imgs))
# 获得数据集长度
imgs_length = len(imgs)
# 定义数据集每个数据的序号,根据序号读取数据
index_list = list(range(imgs_length))
# 读入数据时用到的批次大小
BATCHSIZE = 100# 随机打乱训练数据的索引序号
random.shuffle(index_list)# 定义数据生成器,返回批次数据
def data_generator():imgs_list = []labels_list = []for i in index_list:# 将数据处理成期望的格式,比如类型为float32,shape为[1, 28, 28]img = np.reshape(imgs[i], [1, IMG_ROWS, IMG_COLS]).astype('float32')label = np.reshape(labels[i], [1]).astype('float32')imgs_list.append(img) labels_list.append(label)if len(imgs_list) == BATCHSIZE:# 获得一个batchsize的数据,并返回yield np.array(imgs_list), np.array(labels_list)# 清空数据读取列表imgs_list = []labels_list = []# 如果剩余数据的数目小于BATCHSIZE,# 则剩余数据一起构成一个大小为len(imgs_list)的mini-batchif len(imgs_list) > 0:yield np.array(imgs_list), np.array(labels_list)return data_generator
训练数据集数量: 50000
# 声明数据读取函数,从训练集中读取数据
train_loader = data_generator
# 以迭代的形式读取数据
for batch_id, data in enumerate(train_loader()):image_data, label_data = dataif batch_id == 0:# 打印数据shape和类型print("打印第一个batch数据的维度:")print("图像维度: {}, 标签维度: {}".format(image_data.shape, label_data.shape))break
打印第一个batch数据的维度:
图像维度: (100, 1, 28, 28), 标签维度: (100, 1)
校验数据有效性
在实际应用中,原始数据可能存在标注不准确、数据杂乱或格式不统一等情况。因此在完成数据处理流程后,还需要进行数据校验,一般有两种方式:
- 机器校验:加入一些校验和清理数据的操作。
- 人工校验:先打印数据输出结果,观察是否是设置的格式;再从训练的结果验证数据处理和读取的有效性。
机器校验
如下代码所示,如果数据集中的图片数量和标签数量不等,说明数据逻辑存在问题,可使用assert语句校验图像数量和标签数据是否一致。
imgs_length = len(imgs)assert len(imgs) == len(labels), \"length of train_imgs({}) should be the same as train_labels({})".format(len(imgs), len(label))
人工校验
人工校验是指打印数据输出结果,观察是否是预期的格式。实现数据处理和加载函数后,我们可以调用它读取一次数据,观察数据的shape和类型是否与函数中设置的一致。
# 声明数据读取函数,从训练集中读取数据
train_loader = data_generator
# 以迭代的形式读取数据
for batch_id, data in enumerate(train_loader()):image_data, label_data = dataif batch_id == 0:# 打印数据shape和类型print("打印第一个batch数据的维度,以及数据的类型:")print("图像维度: {}, 标签维度: {}, 图像数据类型: {}, 标签数据类型: {}".format(image_data.shape, label_data.shape, type(image_data), type(label_data)))break
打印第一个batch数据的维度,以及数据的类型:
图像维度: (100, 1, 28, 28), 标签维度: (100, 1), 图像数据类型: <class 'numpy.ndarray'>, 标签数据类型: <class 'numpy.ndarray'>
封装数据读取与处理函数
上文,我们从读取数据、划分数据集、到打乱训练数据、构建数据读取器以及数据校验,完成了一整套一般性的数据处理流程,下面将这些步骤放在一个函数中实现,方便在神经网络训练时直接调用。
def load_data(mode='train'):datafile = './work/mnist.json.gz'print('loading mnist dataset from {} ......'.format(datafile))# 加载json数据文件data = json.load(gzip.open(datafile))print('mnist dataset load done')# 读取到的数据区分训练集,验证集,测试集train_set, val_set, eval_set = dataif mode=='train':# 获得训练数据集imgs, labels = train_set[0], train_set[1]elif mode=='valid':# 获得验证数据集imgs, labels = val_set[0], val_set[1]elif mode=='eval':# 获得测试数据集imgs, labels = eval_set[0], eval_set[1]else:raise Exception("mode can only be one of ['train', 'valid', 'eval']")print("训练数据集数量: ", len(imgs))# 校验数据imgs_length = len(imgs)assert len(imgs) == len(labels), \"length of train_imgs({}) should be the same as train_labels({})".format(len(imgs), len(labels))# 获得数据集长度imgs_length = len(imgs)# 定义数据集每个数据的序号,根据序号读取数据index_list = list(range(imgs_length))# 读入数据时用到的批次大小BATCHSIZE = 100# 定义数据生成器def data_generator():if mode == 'train':# 训练模式下打乱数据random.shuffle(index_list)imgs_list = []labels_list = []for i in index_list:# 将数据处理成希望的格式,比如类型为float32,shape为[1, 28, 28]img = np.reshape(imgs[i], [1, IMG_ROWS, IMG_COLS]).astype('float32')label = np.reshape(labels[i], [1]).astype('float32')imgs_list.append(img) labels_list.append(label)if len(imgs_list) == BATCHSIZE:# 获得一个batchsize的数据,并返回yield np.array(imgs_list), np.array(labels_list)# 清空数据读取列表imgs_list = []labels_list = []# 如果剩余数据的数目小于BATCHSIZE,# 则剩余数据一起构成一个大小为len(imgs_list)的mini-batchif len(imgs_list) > 0:yield np.array(imgs_list), np.array(labels_list)return data_generator
下面定义一层神经网络,利用定义好的数据处理函数,完成神经网络的训练。
# 数据处理部分之后的代码,数据读取的部分调用load_data函数
# 定义网络结构,同上一节所使用的网络结构
class MNIST(fluid.dygraph.Layer):def __init__(self):super(MNIST, self).__init__()self.fc = Linear(input_dim=784, output_dim=1, act=None)def forward(self, inputs):inputs = fluid.layers.reshape(inputs, (-1, 784))outputs = self.fc(inputs)return outputs# 训练配置,并启动训练过程
with fluid.dygraph.guard():model = MNIST()model.train()#调用加载数据的函数train_loader = load_data('train')optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.001, parameter_list=model.parameters())EPOCH_NUM = 10for epoch_id in range(EPOCH_NUM):for batch_id, data in enumerate(train_loader()):#准备数据,变得更加简洁image_data, label_data = dataimage = fluid.dygraph.to_variable(image_data)label = fluid.dygraph.to_variable(label_data)#前向计算的过程predict = model(image)#计算损失,取一个批次样本损失的平均值loss = fluid.layers.square_error_cost(predict, label)avg_loss = fluid.layers.mean(loss)#每训练了200批次的数据,打印下当前Loss的情况if batch_id % 200 == 0:print("epoch: {}, batch: {}, loss is: {}".format(epoch_id, batch_id, avg_loss.numpy()))#后向传播,更新参数的过程avg_loss.backward()optimizer.minimize(avg_loss)model.clear_gradients()#保存模型参数fluid.save_dygraph(model.state_dict(), 'mnist')loading mnist dataset from ./work/mnist.json.gz ......
mnist dataset load done
训练数据集数量: 50000
epoch: 0, batch: 0, loss is: [45.61764]
epoch: 0, batch: 200, loss is: [4.5475965]
epoch: 0, batch: 400, loss is: [4.1117816]
epoch: 1, batch: 0, loss is: [3.4831767]
epoch: 1, batch: 200, loss is: [4.211594]
epoch: 1, batch: 400, loss is: [4.1087213]
epoch: 2, batch: 0, loss is: [3.8220732]
epoch: 2, batch: 200, loss is: [4.435124]
epoch: 2, batch: 400, loss is: [3.1726542]
epoch: 3, batch: 0, loss is: [3.8299181]
epoch: 3, batch: 200, loss is: [3.84748]
epoch: 3, batch: 400, loss is: [3.701971]
epoch: 4, batch: 0, loss is: [3.7070477]
epoch: 4, batch: 200, loss is: [4.473604]
epoch: 4, batch: 400, loss is: [3.8212416]
epoch: 5, batch: 0, loss is: [3.9876893]
epoch: 5, batch: 200, loss is: [3.593488]
epoch: 5, batch: 400, loss is: [3.3292465]
epoch: 6, batch: 0, loss is: [3.409602]
epoch: 6, batch: 200, loss is: [3.1823404]
epoch: 6, batch: 400, loss is: [3.1249528]
epoch: 7, batch: 0, loss is: [3.0369842]
epoch: 7, batch: 200, loss is: [3.597313]
epoch: 7, batch: 400, loss is: [2.8949301]
epoch: 8, batch: 0, loss is: [4.030439]
epoch: 8, batch: 200, loss is: [2.7374206]
epoch: 8, batch: 400, loss is: [3.592334]
epoch: 9, batch: 0, loss is: [2.7048688]
epoch: 9, batch: 200, loss is: [3.9393196]
epoch: 9, batch: 400, loss is: [3.2057602]
异步数据读取
上面提到的数据读取采用的是同步数据读取方式。对于样本量较大、数据读取较慢的场景,建议采用异步数据读取方式。异步读取数据时,数据读取和模型训练并行执行,从而加快了数据读取速度,牺牲一小部分内存换取数据读取效率的提升,二者关系如 图4 所示。
图4:同步数据读取和异步数据读取示意图
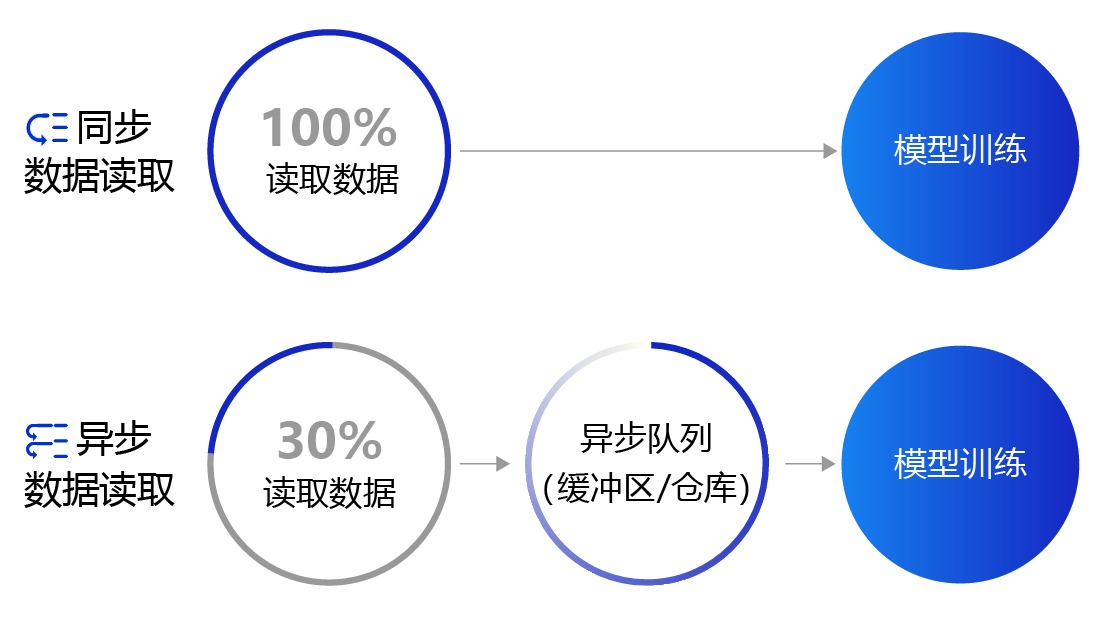
- 同步数据读取:数据读取与模型训练串行。当模型需要数据时,才运行数据读取函数获得当前批次的数据。在读取数据期间,模型一直等待数据读取结束才进行训练,数据读取速度相对较慢。
- 异步数据读取:数据读取和模型训练并行。读取到的数据不断的放入缓存区,无需等待模型训练就可以启动下一轮数据读取。当模型训练完一个批次后,不用等待数据读取过程,直接从缓存区获得下一批次数据进行训练,从而加快了数据读取速度。
- 异步队列:数据读取和模型训练交互的仓库,二者均可以从仓库中读取数据,它的存在使得两者的工作节奏可以解耦。
使用飞桨实现异步数据读取非常简单,如下所示。
# 定义数据读取后存放的位置,CPU或者GPU,这里使用CPU
# place = fluid.CUDAPlace(0) 时,数据才读取到GPU上
place = fluid.CPUPlace()
with fluid.dygraph.guard(place):# 声明数据加载函数,使用训练模式train_loader = load_data(mode='train')# 定义DataLoader对象用于加载Python生成器产生的数据data_loader = fluid.io.DataLoader.from_generator(capacity=5, return_list=True)# 设置数据生成器data_loader.set_batch_generator(train_loader, places=place)# 迭代的读取数据并打印数据的形状for i, data in enumerate(data_loader):image_data, label_data = dataprint(i, image_data.shape, label_data.shape)if i>=5:break
loading mnist dataset from ./work/mnist.json.gz ......
mnist dataset load done
训练数据集数量: 50000
0 [100, 1, 28, 28] [100, 1]
1 [100, 1, 28, 28] [100, 1]
2 [100, 1, 28, 28] [100, 1]
3 [100, 1, 28, 28] [100, 1]
4 [100, 1, 28, 28] [100, 1]
5 [100, 1, 28, 28] [100, 1]
与同步数据读取相比,异步数据读取仅增加了三行代码,如下所示。
place = fluid.CPUPlace()# 设置读取的数据是放在CPU还是GPU上。data_loader = fluid.io.DataLoader.from_generator(capacity=5, return_list=True) # 创建一个DataLoader对象用于加载Python生成器产生的数据。数据会由Python线程预先读取,并异步送入一个队列中。data_loader.set_batch_generator(train_loader, place) # 用创建的DataLoader对象设置一个数据生成器set_batch_generator,输入的参数是一个Python数据生成器train_loader和服务器资源类型place(标明CPU还是GPU)
fluid.io.DataLoader.from_generator参数名称和含义如下:
- feed_list:仅在PaddlePaddle静态图中使用,动态图中设置为“None”,本教程默认使用动态图的建模方式;
- capacity:表示在DataLoader中维护的队列容量,如果读取数据的速度很快,建议设置为更大的值;
- use_double_buffer:是一个布尔型的参数,设置为“True”时,Dataloader会预先异步读取下一个batch的数据并放到缓存区;
- iterable:表示创建的Dataloader对象是否是可迭代的,一般设置为“True”;
- return_list:在动态图模式下需要设置为“True”。
异步数据读取并训练的完整案例代码如下所示。
with fluid.dygraph.guard():model = MNIST()model.train()#调用加载数据的函数train_loader = load_data('train')# 创建异步数据读取器place = fluid.CPUPlace()data_loader = fluid.io.DataLoader.from_generator(capacity=5, return_list=True)data_loader.set_batch_generator(train_loader, places=place)optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.001, parameter_list=model.parameters())EPOCH_NUM = 3for epoch_id in range(EPOCH_NUM):for batch_id, data in enumerate(data_loader):image_data, label_data = dataimage = fluid.dygraph.to_variable(image_data)label = fluid.dygraph.to_variable(label_data)predict = model(image)loss = fluid.layers.square_error_cost(predict, label)avg_loss = fluid.layers.mean(loss)if batch_id % 200 == 0:print("epoch: {}, batch: {}, loss is: {}".format(epoch_id, batch_id, avg_loss.numpy()))avg_loss.backward()optimizer.minimize(avg_loss)model.clear_gradients()fluid.save_dygraph(model.state_dict(), 'mnist')
loading mnist dataset from ./work/mnist.json.gz ......
mnist dataset load done
训练数据集数量: 50000
epoch: 0, batch: 0, loss is: [44.275467]
epoch: 0, batch: 200, loss is: [3.2244885]
epoch: 0, batch: 400, loss is: [4.147104]
epoch: 1, batch: 0, loss is: [3.8324347]
epoch: 1, batch: 200, loss is: [3.3452053]
epoch: 1, batch: 400, loss is: [3.5833535]
epoch: 2, batch: 0, loss is: [3.2671225]
epoch: 2, batch: 200, loss is: [3.7591367]
epoch: 2, batch: 400, loss is: [3.359116]
从异步数据读取的训练结果来看,损失函数下降与同步数据读取训练结果一致。注意,异步读取数据只在数据量规模巨大时会带来显著的性能提升,对于多数场景采用同步数据读取的方式已经足够。
AI Studio 飞桨 零基础入门深度学习笔记6.3-手写数字识别之数据处理相关推荐
- AI Studio 飞桨 零基础入门深度学习笔记1-深度学习的定义
AI Studio 飞桨 零基础入门深度学习-笔记 人工智能.机器学习.深度学习的关系 机器学习 机器学习的实现 机器学习的方法论 案例:牛顿第二定律 确定模型参数 模型结构介绍 深度学习 神经网络的 ...
- AI Studio 飞桨 零基础入门深度学习笔记4-飞桨开源深度学习平台介绍
AI Studio 飞桨 零基础入门深度学习笔记4-飞桨开源深度学习平台介绍 深度学习框架 深度学习框架优势 深度学习框架设计思路 飞桨开源深度学习平台 飞桨开源深度学习平台全景 框架和全流程工具 模 ...
- AI Studio 飞桨 零基础入门深度学习笔记2-基于Python编写完成房价预测任务的神经网络模型
AI Studio 飞桨 零基础入门深度学习笔记2-基于Python编写完成房价预测任务的神经网络模型 波士顿房价预测任务 线性回归模型 线性回归模型的神经网络结构 构建波士顿房价预测任务的神经网络模 ...
- 深度学习(4)手写数字识别实战
深度学习(4)手写数字识别实战 Step0. 数据及模型准备 1. X and Y(数据准备) 2. out=relu{relu{relu[X@W1+b1]@W2+b2}@W3+b3}out=relu ...
- 深度学习(3)手写数字识别问题
深度学习(3)手写数字识别问题 1. 问题归类 2. 数据集 3. Image 4. Input and Output 5. Regression VS Classification 6. Compu ...
- 深度学习 卷积神经网络-Pytorch手写数字识别
深度学习 卷积神经网络-Pytorch手写数字识别 一.前言 二.代码实现 2.1 引入依赖库 2.2 加载数据 2.3 数据分割 2.4 构造数据 2.5 迭代训练 三.测试数据 四.参考资料 一. ...
- 利用python卷积神经网络手写数字识别_Keras深度学习:卷积神经网络手写数字识别...
引言:最近在闭关学习中,由于多久没有写博客了,今天给大家带来学习的一些内容,还在学习神经网络的同学,跑一跑下面的代码,给你一些自信吧!Nice 奥里给! 正文:首先该impor的库就不多说了,不会的就 ...
- 【二】零基础入门深度学习:用一个案例掌握深度学习方法
(给机器学习算法与Python学习加星标,提升AI技能) 作者 | 毕然 百度深度学习技术平台部主任架构师 内容来源 | 百度飞桨深度学习集训营 本文转自飞桨PaddlePaddle 导读 从本课程 ...
- 【一】零基础入门深度学习:用numpy实现神经网络训练
(给机器学习算法与Python学习加星标,提升AI技能) 作者 | 毕然 百度深度学习技术平台部主任架构师 内容来源 | 百度飞桨深度学习集训营 本文转自飞桨PaddlePaddle 本课程是百度官方 ...
最新文章
- SpringBoot conditional注解和自定义conditional注解使用
- “httpd未被被识别的服务”的解决办法
- 如何成为月入过万的斜杠青年
- 记一次腾讯霸面---前端
- java的函数传值_java 函数形参传值和传引用的区别[转]
- django前后端结合_简单4步用FLASK/Django部署你的Pyecharts项目
- nginx重新安装 引起的问题
- ASP.NET MVC+EF框架+EasyUI实现权限管理系列(13)-权限设计
- Inndb和Memory
- [javascript]图解+注释版 Ext.extend()
- 强行杀windows服务
- qq空间网页设计_网页设计中负空间的有效利用
- linux lefse分析,科学网-linux本地化进行lefse分析-林国鹏的博文
- (一)泛函分析(江泽坚)习题解答
- 【算法设计与分析】(6)算24点问题(回溯法)
- 两码一号(九):业务监控
- 群晖NAS Git Server项目源代码管理 配置搭建
- ubuntu20.04上安装和使用frp内网穿透的方法
- 关联性——灰色关联分析
- 高德地图添加安全密钥