基线提升至96.45%:2022 司法杯犯罪事实实体识别+数据蒸馏+主动学习
0.法研杯 LAIC2022 司法人工智能挑战赛犯罪事实实体识别
0.1比赛简介
任务介绍
本赛道由中国司法大数据研究院承办。
犯罪事实实体识别是司法NLP应用中的一项核心基础任务,能为多种下游场景所复用,是案件特征提取、类案推荐等众多NLP任务的重要基础工具。本赛题要求选手使用模型抽取出犯罪事实中相关预定义实体。
与传统的实体抽取不同,犯罪事实中的实体具有领域性强、分布不均衡等特性。
官网:http://data.court.gov.cn/pages/laic.html
数据介绍
- (1) 本赛题数据来源于危险驾驶罪的犯罪事实,分为有标注样本和无标注样本,供选手选择使用;
- (2) 数据格式:训练集数据每一行表示为一个样本,context表示犯罪事实,entities表示实体对应的标签(label)及其位置信息(span);entities_text表示每个标签label对应的实体内容;
- (3) 两条标注样本之间以换行符为分割;
- (4) 训练集:有标注训练样本:200条(分初赛、复赛两次提供,数据集包括验证集,不再单独提供验证集,由选手自己切分);无标注样本10000条;
- (5) 标注样本示例:
{"datasetid": "2552", "id": "813087", "context": "经审理查明,2014年4月12日下午,被告人郑某某酒后驾驶二轮摩托车由永定县凤城镇往仙师乡方向行驶过程中,与郑某甲驾驶的小轿车相碰刮,造成交通事故。经福建南方司法鉴定中心司法鉴定,事发时被告人郑某某血样中检出乙醇,乙醇含量为193.27mg/100ml血。经永定县公安局交通管理大队责任认定,被告人郑某某及被害人郑某甲均负事故的同等责任。案发后,被告人郑某某与被害人郑某甲已达成民事赔偿协议并已履行,被告人郑某某的行为已得到被害人郑某甲的谅解。另查明,被告人郑某某的机动车驾驶证E证已于2014年2月6日到期,且未在合理期限内办理相应续期手续。", "entities": [{"label": "11341", "span": ["25;27"]}, {"label": "11339", "span": ["29;34"]}, {"label": "11344", "span": ["54;57", "156;159", "183;186", "215;218"]}, {"label": "11345", "span": ["60;63"]}, {"label": "11342", "span": ["34;47"]}, {"label": "11348", "span": ["164;168"]}], "entities_text": {"11341": ["酒后"], "11339": ["二轮摩托车"], "11344": ["郑某甲", "郑某甲", "郑某甲", "郑某甲"], "11345": ["小轿车"], "11342": ["由永定县凤城镇往仙师乡方向"], "11348": ["同等责任"]}}
评价方式:
F1=2×准确率 (precision )×召回率 (recall )准确率 (precision )+召回率 (recall )F_1=\frac{2 \times \text { 准确率 }(\text { precision }) \times \text { 召回率 }(\text { recall })}{\text { 准确率 }(\text { precision })+\text { 召回率 }(\text { recall })}F1= 准确率 ( precision )+ 召回率 ( recall )2× 准确率 ( precision )× 召回率 ( recall )
其中:精确率(precision):识别出正确的实体数/识别出的实体数,召回率(recall):识别出正确的实体数 / 样本的实体数
相关要求及提交说明
初赛阶段采用上传预测答案的方式进行测评,复赛需上传模型,请选手严格按照以下说明规范提交:
1. 本赛题不允许通过增加额外有监督样本数量提升模型的预测效果。2. 只允许产出一个模型,复赛前需要打印模型结构进行验证。主模型不允许多个模型串行或者并行,比如bert+bert;主模型以外允许适当的结构串行,比如bert+crf。模型结构随压缩包提供。3. 模型存储空间 ≤2.0G。4. 法研基线模型请前往LAIC2022GitHub网站;请务必按照README中的相关说明组织文件,并制成ZIP压缩包上传。赛程安排
1. 初赛阶段(2022年9月21日-2022年12月09日)释放初赛数据集,开放初赛排名榜。选手所提交答案的得分超过初赛基线模型分数,自动晋级复赛。2. 复赛阶段(2022年10月31日-2022年12月09日)释放复赛数据集,开放复赛排名榜;选手于复赛结束前选择三个模型和所选模型对应的源代码等审查材料[注]进入封测评审阶段。3. 封测评审阶段(2022年12月10日-12月25日)模型将在封闭数据集上进行测试,获得模型的封测成绩。4. 技术交流会(2022年12月下旬)邀请成绩优异的选手进行模型分享,并和专家观众进行论证和讨论。5. 发布成绩(2022年12月底)公布最终成绩,参赛者的最终成绩为模型的封测成绩和复赛成绩按7:3加权取得的分数的最高分。注:请提前准备,若未在规定时间内提交,视为放弃。若选手所提供的源代码无法复现初复赛结果,或被判为成绩无效,最终解释权归中国司法大数据研究院所有。结果预览:
| 模型 | Precision | Recall | F1 |
|---|---|---|---|
| Base | 88.96 | 95.37 | 92.06 |
| Base+全量 | 93.86 (+4.9) | 99.2 (+3.83) | 96.45 (+4.39) |
| UIE Slim | 98.632 (+9.67) | 98.736 (+3.37) | 98.684(+6.62) |
![]()
#更新库
!pip install --upgrade paddlenlp
#解压数据集
!unzip -d data1 /home/aistudio/data/data174441/1666867681954.zip
Archive: /home/aistudio/data/data174441/1666867681954.zipcreating: data1/无标注数据集/inflating: data1/无标注数据集/危险驾驶罪-样本标签集-2000 inflating: data1/无标注数据集/危险驾驶罪-样本标签集-8000 creating: data1/选手数据集/inflating: data1/选手数据集/test.json inflating: data1/选手数据集/train.json inflating: data1/犯罪事实-上传答案示例.txt
0.2 数据集预览:
无标注:
{"fullText": "经审理查明,2016年6月4日0时57分许,被告人张伟饮酒后驾驶号跨界高尔夫牌小型轿车由北向南行驶至滨河东路南中环桥向西转匝道路段时,遇张某驾驶的无号牌东风-福龙马牌中型载货专项作业车逆向行驶后准备向南右转时横在滨河东路中间,二车发生相撞,造成同乘人曹某当场死亡、同乘人杨某经医院抢救无效死亡、张伟本人受伤及两车损坏的交通事故。经鉴定,从张伟送检的血样中检出乙醇成分,含量为140.97mg/100ml。从张某送检的血样中未检出乙醇成分,经交警部门依法认定,张伟、张某承担事故的同等责任,杨某、曹某无责任。2016年6月13日,张某所属的太原市高新技术产业开发区环境卫生管理中心向曹某、杨某家属进行了民事赔偿。被害人曹某的家属对被告人张伟的行为表示谅解。", "id": "dfe98005-0491-4015-94ff-a7f50185aa70"}
有标注:
{"id": "813046", "context": "经审理查明,2016年9月24日19时20分许,被告人陈某某酒后驾驶蒙L80783号比亚迪牌小型轿车由东向西行驶至内蒙古自治区鄂尔多斯市准格尔旗薛家湾镇鑫凯盛小区“金娃娃拉面馆”门前道路处时,与由西向东行驶至此处的驾驶人范某某驾驶的蒙ANB577号丰田牌小型越野客车相撞,造成两车不同程度受损的道路交通事故。被告人陈某某在该起事故中承担同等责任。经某政府1鉴定,被告人陈某某血液酒精含量检验结果为259.598mg/100ml,属醉酒状态。被告人陈某某明知他人报警而在现场等候。2016年9月29日被告人陈某某的妻子冯某某与驾驶人范某某就车损赔偿达成了私了协议书。", "entities": [{"label": "11341", "span": ["30;32"]}, {"label": "11339", "span": ["46;50"]}, {"label": "11340", "span": ["50;56"]}, {"label": "11342", "span": ["57;94"]}, {"label": "11346", "span": ["97;106"]}, {"label": "11344", "span": ["110;113", "265;268"]}, {"label": "11345", "span": ["127;133"]}, {"label": "11348", "span": ["168;172"]}, {"label": "11350", "span": ["215;219"]}], "entities_text": {"11341": ["酒后"], "11339": ["小型轿车"], "11340": ["由东向西行驶"], "11342": ["内蒙古自治区鄂尔多斯市准格尔旗薛家湾镇鑫凯盛小区“金娃娃拉面馆”门前道路处"], "11346": ["由西向东行驶至此处"], "11344": ["范某某", "范某某"], "11345": ["小型越野客车"], "11348": ["同等责任"], "11350": ["醉酒状态"]}}
实体类型:
'11339': '被告人交通工具','11340': '被告人行驶情况','11341': '被告人违规情况','11342': '行为地点','11343': '搭载人姓名','11344': '其他事件参与人','11345': '参与人交通工具','11346': '参与人行驶情况','11347': '参与人违规情况','11348': '被告人责任认定','11349': '参与人责任认定','11350': '被告人行为总结',
1.baseline——模型训练预测(UIE model)
UIE模型使用情况参考下面链接,写的很详细了要考虑了工业部署情况方案
参考链接:
UIE Slim满足工业应用场景,解决推理部署耗时问题,提升效能!
PaddleNLP之UIE信息抽取小样本进阶(二)[含doccano详解]
Paddlenlp之UIE模型实战实体抽取任务【打车数据、快递单】
1.1 数据处理
执行这一步前请把,data源数据数据移动到data目录下
同时注意后续数据集根据自己需求修正,可以增添数量等,数据处理程序是可以复用的
!cp -R /home/aistudio/data源数据/选手数据集/* /home/aistudio/data
#数据转化
import jsonspan={'11339': '被告人交通工具','11340': '被告人行驶情况','11341': '被告人违规情况','11342': '行为地点','11343': '搭载人姓名','11344': '其他事件参与人','11345': '参与人交通工具','11346': '参与人行驶情况','11347': '参与人违规情况','11348': '被告人责任认定','11349': '参与人责任认定','11350': '被告人行为总结',}def convert_record(source):target = {}target["id"] = int(source["id"])target["text"] = source["context"]target["relations"] = []target["entities"] = []id = 0for item in source["entities"]:for i in range(len((item['span']))):tmp = {}tmp['id'] = id id = id + 1tmp['start_offset'] = int(item['span'][i].split(';')[0])tmp['end_offset'] = int(item['span'][i].split(';')[1])tmp['label'] = span[item['label']]target["entities"].append(tmp)return targetif __name__ == '__main__':train_file = 'data/train.json'json_data = []content_len=[]for line in open(train_file, 'r',encoding='utf-8'):json_data.append(json.loads(line))content_len.append(len(json.loads(line)["context"]))ff = open('data/train_new.txt', 'w')for item in json_data:target = convert_record(item)ff.write(json.dumps(target, ensure_ascii=False ) + '\n')ff.close()print(content_len)
[272, 369, 234, 273, 335, 282, 257, 279, 201, 586, 241, 459, 205, 418, 350, 230, 329, 191, 300, 653, 497, 446, 349, 304, 269, 299, 323, 299, 615, 296, 303, 256, 571, 574, 256, 333, 317, 341, 212, 411, 433, 271, 129, 366, 303, 306, 1293, 307, 477, 125, 373, 266, 364, 354, 252, 300, 349, 249, 419, 282, 270, 195, 179, 423, 290, 281, 241, 396, 349, 328, 323, 987, 615, 244, 629, 217, 270, 257, 228, 515, 318, 264, 513, 373, 293, 275, 323, 220, 227, 463, 287, 307, 304, 328, 320, 452, 346, 311, 250, 230, 330, 240, 205, 180, 162, 289, 245, 199, 294, 286, 216, 325, 218, 334, 207, 192, 202, 164, 288, 303, 230, 219, 299, 250, 416, 401, 221, 299, 177, 335, 262, 475, 368, 306, 178, 202, 285, 235, 159, 156, 271, 269, 380, 280, 231, 222, 238, 151, 264, 215, 247, 199, 345, 359, 231, 402, 369, 245, 291, 249, 242, 282, 260, 218, 191, 268, 258, 186, 443, 298, 249, 221, 231, 204, 276, 229, 202, 271, 326, 227, 191, 191, 181, 154, 255, 225, 238, 216, 186, 152, 250, 294, 361, 234, 221, 244, 193, 176, 177, 322]
#解压数据集
# !unzip -d /home/aistudio/ /home/aistudio/PaddleNLP-model_zoo-uie.zip
#划分数据集
!python doccano.py \--doccano_file ./data/train_new.txt \--task_type ext \--save_dir ./data \--splits 0.8 0.2 0
[32m[2022-10-31 10:16:27,050] [ INFO][0m - Converting doccano data...[0m
100%|██████████████████████████████████████| 160/160 [00:00<00:00, 13598.28it/s]
[32m[2022-10-31 10:16:27,063] [ INFO][0m - Adding negative samples for first stage prompt...[0m
100%|█████████████████████████████████████| 160/160 [00:00<00:00, 180254.81it/s]
[32m[2022-10-31 10:16:27,065] [ INFO][0m - Converting doccano data...[0m
100%|████████████████████████████████████████| 40/40 [00:00<00:00, 17976.23it/s]
[32m[2022-10-31 10:16:27,067] [ INFO][0m - Adding negative samples for first stage prompt...[0m
100%|███████████████████████████████████████| 40/40 [00:00<00:00, 145257.28it/s]
[32m[2022-10-31 10:16:27,068] [ INFO][0m - Converting doccano data...[0m
0it [00:00, ?it/s]
[32m[2022-10-31 10:16:27,068] [ INFO][0m - Adding negative samples for first stage prompt...[0m
0it [00:00, ?it/s]
[32m[2022-10-31 10:16:27,086] [ INFO][0m - Save 1920 examples to ./data/train.txt.[0m
[32m[2022-10-31 10:16:27,091] [ INFO][0m - Save 480 examples to ./data/dev.txt.[0m
[32m[2022-10-31 10:16:27,091] [ INFO][0m - Save 0 examples to ./data/test.txt.[0m
[32m[2022-10-31 10:16:27,091] [ INFO][0m - Finished! It takes 0.04 seconds[0m
[0m
1.2 模型训练验证
#模型训练
!python finetune.py \--train_path "./data/train.txt" \--dev_path "./data/dev.txt" \--save_dir "./checkpoint_base" \--learning_rate 5e-6 \--batch_size 32 \--max_seq_len 512 \--num_epochs 30 \--model "uie-base" \--seed 1000 \--logging_steps 10 \--valid_steps 100 \--device "gpu"
训练结果预览:
[2022-10-31 10:25:43,181] [ INFO] - global step 510, epoch: 8, loss: 0.00172, speed: 2.33 step/s
[2022-10-31 10:25:45,959] [ INFO] - global step 520, epoch: 8, loss: 0.00171, speed: 3.60 step/s
[2022-10-31 10:25:51,260] [ INFO] - global step 530, epoch: 9, loss: 0.00169, speed: 1.89 step/s
[2022-10-31 10:25:55,512] [ INFO] - global step 540, epoch: 9, loss: 0.00167, speed: 2.35 step/s
[2022-10-31 10:25:59,746] [ INFO] - global step 550, epoch: 9, loss: 0.00166, speed: 2.36 step/s
[2022-10-31 10:26:04,010] [ INFO] - global step 560, epoch: 9, loss: 0.00164, speed: 2.35 step/s
[2022-10-31 10:26:08,215] [ INFO] - global step 570, epoch: 9, loss: 0.00162, speed: 2.38 step/s
[2022-10-31 10:26:12,343] [ INFO] - global step 580, epoch: 9, loss: 0.00160, speed: 2.42 step/s
[2022-10-31 10:26:16,597] [ INFO] - global step 590, epoch: 10, loss: 0.00159, speed: 2.35 step/s
[2022-10-31 10:26:20,881] [ INFO] - global step 600, epoch: 10, loss: 0.00157, speed: 2.33 step/s
[2022-10-31 10:26:26,571] [ INFO] - Evaluation precision: 0.90678, recall: 0.89727, F1: 0.90200
[2022-10-31 10:26:26,571] [ INFO] - best F1 performence has been updated: 0.87898 --> 0.90200
best模型已保存
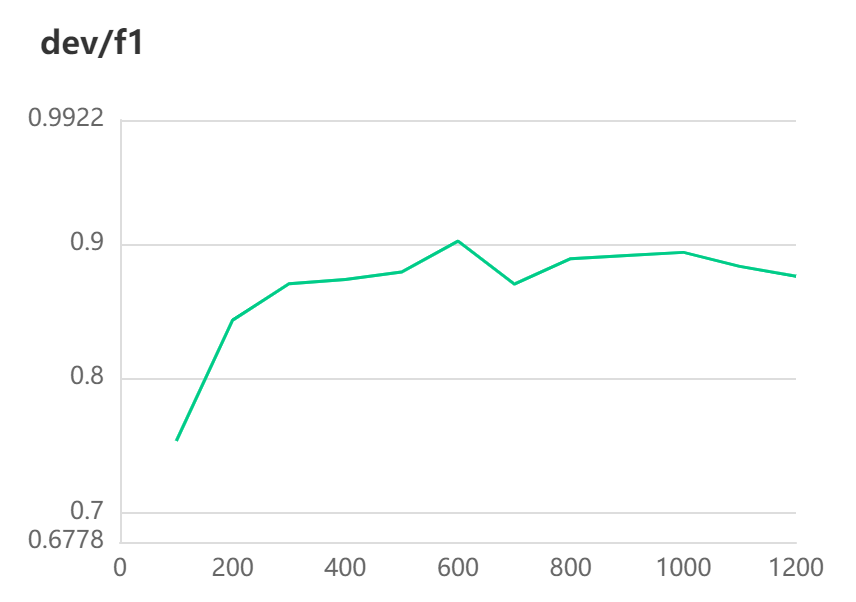
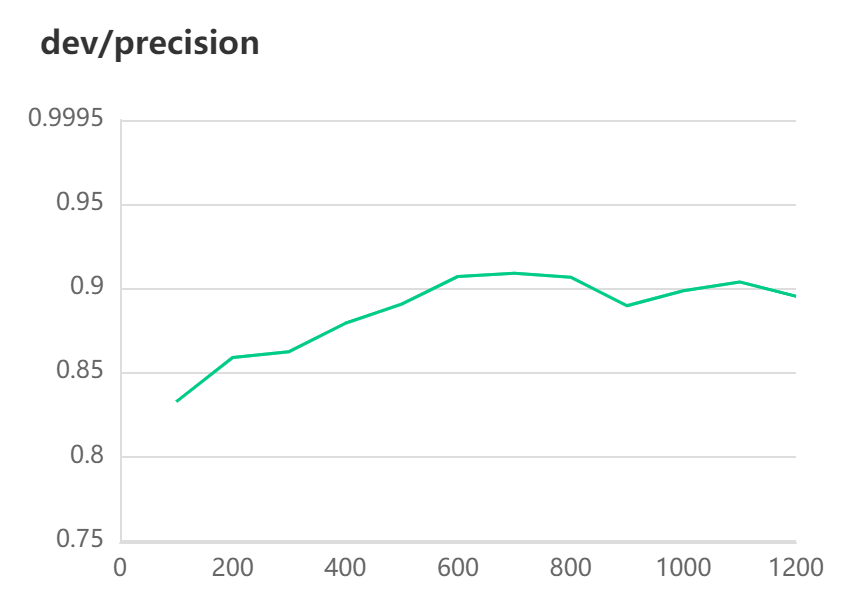
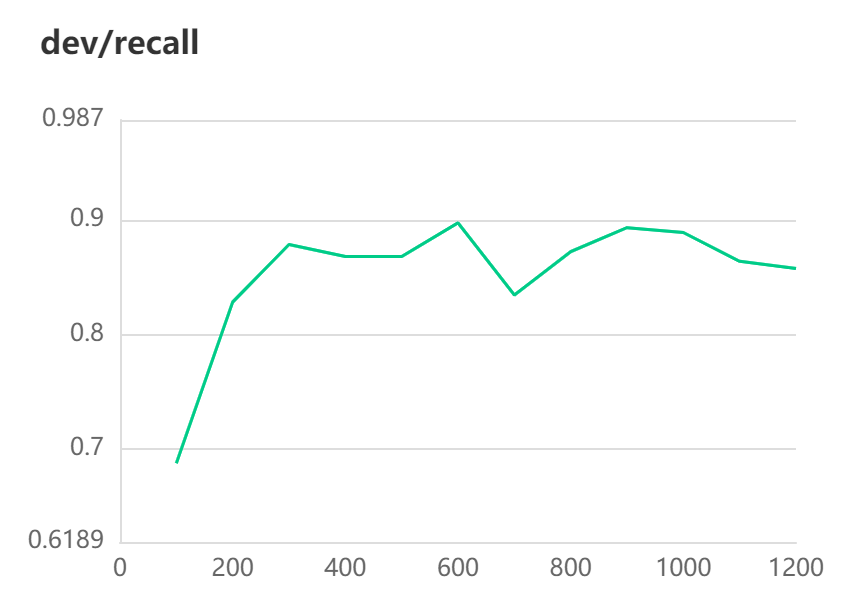
#模型评估
!python evaluate.py \--model_path ./checkpoint_base/model_best \--test_path ./data/dev.txt \--batch_size 16 \--max_seq_len 512
[32m[2022-10-31 10:31:23,136] [ INFO][0m - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint_base/model_best'.[0m
W1031 10:31:23.161486 2428 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2
W1031 10:31:23.164036 2428 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[32m[2022-10-31 10:31:33,982] [ INFO][0m - -----------------------------[0m
[32m[2022-10-31 10:31:33,983] [ INFO][0m - Class Name: all_classes[0m
[32m[2022-10-31 10:31:33,983] [ INFO][0m - Evaluation Precision: 0.90678 | Recall: 0.89727 | F1: 0.90200[0m
[0m
!python evaluate.py \--model_path ./checkpoint_base/model_best \--test_path ./data/dev.txt \--debug
[32m[2022-10-31 10:31:38,318] [ INFO][0m - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint_base/model_best'.[0m
W1031 10:31:38.342159 2476 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2
W1031 10:31:38.344569 2476 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[32m[2022-10-31 10:31:43,857] [ INFO][0m - -----------------------------[0m
[32m[2022-10-31 10:31:43,857] [ INFO][0m - Class Name: 被告人交通工具[0m
[32m[2022-10-31 10:31:43,857] [ INFO][0m - Evaluation Precision: 0.97500 | Recall: 0.95122 | F1: 0.96296[0m
[32m[2022-10-31 10:31:44,297] [ INFO][0m - -----------------------------[0m
[32m[2022-10-31 10:31:44,297] [ INFO][0m - Class Name: 行为地点[0m
[32m[2022-10-31 10:31:44,297] [ INFO][0m - Evaluation Precision: 1.00000 | Recall: 0.94872 | F1: 0.97368[0m
[32m[2022-10-31 10:31:44,780] [ INFO][0m - -----------------------------[0m
[32m[2022-10-31 10:31:44,781] [ INFO][0m - Class Name: 其他事件参与人[0m
[32m[2022-10-31 10:31:44,781] [ INFO][0m - Evaluation Precision: 0.90604 | Recall: 0.95745 | F1: 0.93103[0m
[32m[2022-10-31 10:31:44,898] [ INFO][0m - -----------------------------[0m
[32m[2022-10-31 10:31:44,898] [ INFO][0m - Class Name: 被告人行为总结[0m
[32m[2022-10-31 10:31:44,898] [ INFO][0m - Evaluation Precision: 1.00000 | Recall: 0.70000 | F1: 0.82353[0m
[32m[2022-10-31 10:31:45,324] [ INFO][0m - -----------------------------[0m
[32m[2022-10-31 10:31:45,324] [ INFO][0m - Class Name: 被告人责任认定[0m
[32m[2022-10-31 10:31:45,325] [ INFO][0m - Evaluation Precision: 0.89474 | Recall: 0.91892 | F1: 0.90667[0m
[32m[2022-10-31 10:31:45,775] [ INFO][0m - -----------------------------[0m
[32m[2022-10-31 10:31:45,775] [ INFO][0m - Class Name: 被告人违规情况[0m
[32m[2022-10-31 10:31:45,776] [ INFO][0m - Evaluation Precision: 0.90909 | Recall: 0.87719 | F1: 0.89286[0m
[32m[2022-10-31 10:31:46,124] [ INFO][0m - -----------------------------[0m
[32m[2022-10-31 10:31:46,124] [ INFO][0m - Class Name: 被告人行驶情况[0m
[32m[2022-10-31 10:31:46,124] [ INFO][0m - Evaluation Precision: 0.94286 | Recall: 0.86842 | F1: 0.90411[0m
[32m[2022-10-31 10:31:46,574] [ INFO][0m - -----------------------------[0m
[32m[2022-10-31 10:31:46,574] [ INFO][0m - Class Name: 参与人交通工具[0m
[32m[2022-10-31 10:31:46,574] [ INFO][0m - Evaluation Precision: 0.93617 | Recall: 0.93617 | F1: 0.93617[0m
[32m[2022-10-31 10:31:46,924] [ INFO][0m - -----------------------------[0m
[32m[2022-10-31 10:31:46,924] [ INFO][0m - Class Name: 参与人行驶情况[0m
[32m[2022-10-31 10:31:46,924] [ INFO][0m - Evaluation Precision: 0.82353 | Recall: 0.77778 | F1: 0.80000[0m
[32m[2022-10-31 10:31:47,137] [ INFO][0m - -----------------------------[0m
[32m[2022-10-31 10:31:47,137] [ INFO][0m - Class Name: 参与人责任认定[0m
[32m[2022-10-31 10:31:47,137] [ INFO][0m - Evaluation Precision: 0.86667 | Recall: 0.76471 | F1: 0.81250[0m
[32m[2022-10-31 10:31:47,191] [ INFO][0m - -----------------------------[0m
[32m[2022-10-31 10:31:47,191] [ INFO][0m - Class Name: 搭载人姓名[0m
[32m[2022-10-31 10:31:47,191] [ INFO][0m - Evaluation Precision: 1.00000 | Recall: 0.85714 | F1: 0.92308[0m
[32m[2022-10-31 10:31:47,246] [ INFO][0m - -----------------------------[0m
[32m[2022-10-31 10:31:47,246] [ INFO][0m - Class Name: 参与人违规情况[0m
[32m[2022-10-31 10:31:47,246] [ INFO][0m - Evaluation Precision: 1.00000 | Recall: 0.28571 | F1: 0.44444[0m
[0m
1.3模型预测
安装FasterTokenizer:使用C++实现的高性能分词算子FasterTokenizer进行文本预处理加速。需要通过pip install faster_tokenizer安装FasterTokenizer库后方可使用。默认为False。更多使用说明可参考FasterTokenizer文档。
!pip install faster_tokenizer
# 查找重复出现的字符串
def str_all_index(str_, a):'''Parameters----------str_ : string.a : str_中的子串Returns-------index_list : list首先输入变量2个,输出list,然后中间构造每次find的起始位置start,start每次都在找到的索引+1,后面还得有终止循环的条件'''index_list=[]start=0while True:x=str_.find(a,start)if x>-1:start=x+1index_list.append(x)else:breakreturn index_list
# 预测
import json
from paddlenlp import Taskflowdef predict(ie, result_item):result = ie(result_item['context'])[0]# print(result)sub_list = []for item in result:sub_tmp = {}sub_tmp["label"] = str(keys[values.index(str(item))])all_search=str_all_index(result_item['context'], result[item][0]["text"])txt_list=[]sub_span=[]if len(result[item])==1:for i in range(len(all_search)): txt_list.append(result[item][0]["text"]) sub_span.append([all_search[i], all_search[i] +len(result[item][0]["text"])]) else:for i in range(len(result[item])): txt_list.append(result[item][i]["text"]) sub_span.append([result[item][i]["start"], result[item][i]["end"]]) sub_tmp["text"]=txt_listsub_tmp["span"]=sub_spansub_list.append(sub_tmp)result_item["entities"] = sub_list return result_itemif __name__ == '__main__':test_file = 'data/test.json'span={'11339': '被告人交通工具','11340': '被告人行驶情况','11341': '被告人违规情况','11342': '行为地点','11343': '搭载人姓名','11344': '其他事件参与人','11345': '参与人交通工具','11346': '参与人行驶情况','11347': '参与人违规情况','11348': '被告人责任认定','11349': '参与人责任认定','11350': '被告人行为总结',}values = list(span.values())keys=list(span.keys())# idx = values.index("被告人交通工具")# print(idx)# print(keys)# key = keys[idx]# print(key)schema = span.values()# 设定抽取目标和定制化模型权重路径ie = Taskflow("information_extraction", schema=schema,batch_size=32,precision='fp32',use_faster=True, task_path='./checkpoint_base/model_best')ff = open('output/result_base.txt', 'w')for line in open(test_file, 'r',encoding='utf-8'):result_item=json.loads(line)target = predict(ie, result_item)ff.write(json.dumps(target, ensure_ascii=False) + '\n')ff.close()print("数据结果已导出")
W1031 10:33:01.569777 272 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2
W1031 10:33:01.573338 272 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[2022-10-31 10:33:04,120] [ INFO] - Converting to the inference model cost a little time.
[2022-10-31 10:33:11,405] [ INFO] - The inference model save in the path:./checkpoint_base/model_best/static/inference
[2022-10-31 10:33:12,994] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.faster_tokenizer.ErnieFasterTokenizer'> to load './checkpoint_base/model_best'.数据结果已导出
部分结果预览:
{"id": "812546", "context": "经审理查明,2016年3月12日15时50分许,被告人王某酒后驾驶无牌普通两轮摩托车由东向西行驶至本市凉州区黄羊镇二坝小学路段时,与同向行驶的被害人蒋某某驾驶的甘HB0622小轿车发生碰撞,致王某受伤、车辆受损的一般交通事故。2016年3月15日,甘肃申证司法医学鉴定所以甘申司法毒物鉴字(2016)第179号关于王某酒精含量司法鉴定检验报告书鉴定:送检的王某字样试管血液样中检测出酒精成份,含量为118.18mg/100m1。2016年4月11日,某政府以武公交凉认字第622301XXXXXXXXXX号道路交通事故责任认定书认定:王某负此次事故的全部责任,蒋某某在事故中无责任。案发后,被告人王某与受害人蒋某某就民事赔偿已某某了和解协议,双方已履行了协议。", "entities": [{"label": "11339", "text": ["普通两轮摩托车"], "span": [[35, 42]]}, {"label": "11340", "text": ["无牌", "由东向西行驶"], "span": [[33, 35], [42, 48]]}, {"label": "11341", "text": ["酒后"], "span": [[29, 31]]}, {"label": "11342", "text": ["本市凉州区黄羊镇二坝小学路段"], "span": [[49, 63]]}, {"label": "11344", "text": ["蒋某某", "蒋某某", "蒋某某"], "span": [[74, 77], [304, 307], [280, 283]]}, {"label": "11345", "text": ["小轿车"], "span": [[87, 90]]}, {"label": "11346", "text": ["同向行驶"], "span": [[66, 70]]}, {"label": "11348", "text": ["全部责任"], "span": [[275, 279]]}, {"label": "11349", "text": ["无责任"], "span": [[287, 290]]}]}
{"id": "812531", "context": "经审理查明:2015年10月4日20时21分许,被告人王某某在未取得机车动车驾驶证的情况下醉酒驾驶云F98XXX号小型普通客车沿红塔大道西向东行驶,当行驶至红塔大道32号门前处时追尾同向行驶的王某驾驶的云AKOXXX号丰田轿车,造成两车受损的道路交通事故。经鉴定,被告人王某某血液中乙醇含量为180.64mg/100ml血。经道路交通事故认定书认定,王某某承担事故的全部责任。被告人王某某在事故发生后明知对方报了警而在现场等候处理,案发后,其赔偿了王某车辆损失费共计14000元。", "entities": [{"label": "11339", "text": ["小型普通客车"], "span": [[57, 63]]}, {"label": "11340", "text": ["沿红塔大道西向东行驶"], "span": [[63, 73]]}, {"label": "11341", "text": ["未取得机车动车驾驶证", "醉酒"], "span": [[31, 41], [45, 47]]}, {"label": "11342", "text": ["红塔大道32号门前处"], "span": [[78, 88]]}, {"label": "11344", "text": ["王某", "王某"], "span": [[224, 226], [96, 98]]}, {"label": "11345", "text": ["丰田轿车"], "span": [[109, 113]]}, {"label": "11346", "text": ["同向行驶"], "span": [[91, 95]]}, {"label": "11348", "text": ["全部责任"], "span": [[183, 187]]}]}
base比赛结果
![]()
2.全量训练集训练——模型结果
2.1方法一
训练集直接复制四倍,并把训练集当验证集,潜在风险会过拟合,优点在本就小样本情况下增大数据丰富度了
#模型评估
!python evaluate.py \--model_path ./checkpoint_trainall/model_best \--test_path ./data/dev.txt \--batch_size 32 \--max_seq_len 512
[2022-10-28 15:12:00,133] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint_trainall/model_best'.
W1028 15:12:00.169660 12426 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W1028 15:12:00.174069 12426 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[2022-10-28 15:12:28,376] [ INFO] - -----------------------------
[2022-10-28 15:12:28,376] [ INFO] - Class Name: all_classes
[2022-10-28 15:12:28,376] [ INFO] - Evaluation Precision: 0.99247 | Recall: 0.99331 | F1: 0.99289
!python evaluate.py \--model_path ./checkpoint_trainall/model_best \--test_path ./data/dev.txt \--debug
[2022-10-28 15:12:32,982] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint_trainall/model_best'.
W1028 15:12:33.009744 12550 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W1028 15:12:33.013761 12550 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[2022-10-28 15:12:38,972] [ INFO] - -----------------------------
[2022-10-28 15:12:38,972] [ INFO] - Class Name: 其他事件参与人
[2022-10-28 15:12:38,972] [ INFO] - Evaluation Precision: 0.99441 | Recall: 0.99164 | F1: 0.99303
[2022-10-28 15:12:40,929] [ INFO] - -----------------------------
[2022-10-28 15:12:40,930] [ INFO] - Class Name: 参与人交通工具
[2022-10-28 15:12:40,930] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2022-10-28 15:12:41,595] [ INFO] - -----------------------------
[2022-10-28 15:12:41,596] [ INFO] - Class Name: 被告人行为总结
[2022-10-28 15:12:41,596] [ INFO] - Evaluation Precision: 0.96970 | Recall: 0.96970 | F1: 0.96970
[2022-10-28 15:12:43,396] [ INFO] - -----------------------------
[2022-10-28 15:12:43,396] [ INFO] - Class Name: 被告人违规情况
[2022-10-28 15:12:43,396] [ INFO] - Evaluation Precision: 1.00000 | Recall: 0.99254 | F1: 0.99625
[2022-10-28 15:12:44,706] [ INFO] - -----------------------------
[2022-10-28 15:12:44,706] [ INFO] - Class Name: 参与人行驶情况
[2022-10-28 15:12:44,706] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2022-10-28 15:12:46,449] [ INFO] - -----------------------------
[2022-10-28 15:12:46,450] [ INFO] - Class Name: 被告人责任认定
[2022-10-28 15:12:46,450] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2022-10-28 15:12:48,303] [ INFO] - -----------------------------
[2022-10-28 15:12:48,303] [ INFO] - Class Name: 行为地点
[2022-10-28 15:12:48,303] [ INFO] - Evaluation Precision: 0.98000 | Recall: 0.98000 | F1: 0.98000
[2022-10-28 15:12:49,221] [ INFO] - -----------------------------
[2022-10-28 15:12:49,221] [ INFO] - Class Name: 参与人责任认定
[2022-10-28 15:12:49,221] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2022-10-28 15:12:49,480] [ INFO] - -----------------------------
[2022-10-28 15:12:49,480] [ INFO] - Class Name: 搭载人姓名
[2022-10-28 15:12:49,480] [ INFO] - Evaluation Precision: 0.97727 | Recall: 1.00000 | F1: 0.98851
[2022-10-28 15:12:51,429] [ INFO] - -----------------------------
[2022-10-28 15:12:51,430] [ INFO] - Class Name: 被告人交通工具
[2022-10-28 15:12:51,430] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2022-10-28 15:12:52,680] [ INFO] - -----------------------------
[2022-10-28 15:12:52,681] [ INFO] - Class Name: 被告人行驶情况
[2022-10-28 15:12:52,681] [ INFO] - Evaluation Precision: 0.98684 | Recall: 0.98684 | F1: 0.98684
[2022-10-28 15:12:52,795] [ INFO] - -----------------------------
[2022-10-28 15:12:52,795] [ INFO] - Class Name: 参与人违规情况
[2022-10-28 15:12:52,795] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
# 预测
import json
from paddlenlp import Taskflowdef predict(ie, result_item):result = ie(result_item['context'])[0]# print(result)sub_list = []for item in result:sub_tmp = {}sub_tmp["label"] = str(keys[values.index(str(item))])all_search=str_all_index(result_item['context'], result[item][0]["text"])txt_list=[]sub_span=[]if len(result[item])==1:for i in range(len(all_search)): txt_list.append(result[item][0]["text"]) sub_span.append([all_search[i], all_search[i] +len(result[item][0]["text"])]) else:for i in range(len(result[item])): txt_list.append(result[item][i]["text"]) sub_span.append([result[item][i]["start"], result[item][i]["end"]]) sub_tmp["text"]=txt_listsub_tmp["span"]=sub_spansub_list.append(sub_tmp)result_item["entities"] = sub_list return result_itemif __name__ == '__main__':test_file = 'data/test.json'span={'11339': '被告人交通工具','11340': '被告人行驶情况','11341': '被告人违规情况','11342': '行为地点','11343': '搭载人姓名','11344': '其他事件参与人','11345': '参与人交通工具','11346': '参与人行驶情况','11347': '参与人违规情况','11348': '被告人责任认定','11349': '参与人责任认定','11350': '被告人行为总结',}values = list(span.values())keys=list(span.keys())# idx = values.index("被告人交通工具")# print(idx)# print(keys)# key = keys[idx]# print(key)schema = span.values()# 设定抽取目标和定制化模型权重路径ie = Taskflow("information_extraction", schema=schema,batch_size=32,precision='fp32',use_faster=True, task_path='./checkpoint_train_double/model_best')ff = open('output/result_train_double.txt', 'w')for line in open(test_file, 'r',encoding='utf-8'):result_item=json.loads(line)target = predict(ie, result_item)ff.write(json.dumps(target, ensure_ascii=False) + '\n')ff.close()print("数据结果已导出")
[2022-10-31 11:09:12,610] [ INFO] - Converting to the inference model cost a little time.
[2022-10-31 11:09:19,869] [ INFO] - The inference model save in the path:./checkpoint_train_double/model_best/static/inference
[2022-10-31 11:09:21,317] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.faster_tokenizer.ErnieFasterTokenizer'> to load './checkpoint_train_double/model_best'.数据结果已导出
2.2 方法二
在源数据集上扩大几倍,在进行随机分割,一定程度减少数据面导致的过拟合
#划分数据集
!python doccano.py \--doccano_file ./data/train_double.txt \--task_type ext \--save_dir ./data \--splits 0.8 0.2 0
[2022-10-31 10:39:35,840] [ INFO] - Converting doccano data...
100%|██████████████████████████████████████| 640/640 [00:00<00:00, 13311.16it/s]
[2022-10-31 10:39:35,889] [ INFO] - Adding negative samples for first stage prompt...
100%|█████████████████████████████████████| 640/640 [00:00<00:00, 170014.22it/s]
[2022-10-31 10:39:35,895] [ INFO] - Converting doccano data...
100%|██████████████████████████████████████| 160/160 [00:00<00:00, 15252.71it/s]
[2022-10-31 10:39:35,906] [ INFO] - Adding negative samples for first stage prompt...
100%|█████████████████████████████████████| 160/160 [00:00<00:00, 180158.02it/s]
[2022-10-31 10:39:35,907] [ INFO] - Converting doccano data...
0it [00:00, ?it/s]
[2022-10-31 10:39:35,908] [ INFO] - Adding negative samples for first stage prompt...
0it [00:00, ?it/s]
[2022-10-31 10:39:35,987] [ INFO] - Save 7680 examples to ./data/train.txt.
[2022-10-31 10:39:36,006] [ INFO] - Save 1920 examples to ./data/dev.txt.
[2022-10-31 10:39:36,006] [ INFO] - Save 0 examples to ./data/test.txt.
[2022-10-31 10:39:36,006] [ INFO] - Finished! It takes 0.17 seconds
!python finetune.py \--train_path "./data/train.txt" \--dev_path "./data/dev.txt" \--save_dir "./checkpoint_train_double" \--learning_rate 5e-6 \--batch_size 32 \--max_seq_len 512 \--num_epochs 20 \--model "uie-base" \--seed 1000 \--logging_steps 10 \--valid_steps 100 \--device "gpu"
[2022-10-31 11:02:25,276] [ INFO] - global step 2010, epoch: 8, loss: 0.00076, speed: 2.36 step/s
[2022-10-31 11:02:29,618] [ INFO] - global step 2020, epoch: 8, loss: 0.00075, speed: 2.30 step/s
[2022-10-31 11:02:33,167] [ INFO] - global step 2030, epoch: 8, loss: 0.00075, speed: 2.82 step/s
[2022-10-31 11:02:37,961] [ INFO] - global step 2040, epoch: 9, loss: 0.00075, speed: 2.09 step/s
[2022-10-31 11:02:42,213] [ INFO] - global step 2050, epoch: 9, loss: 0.00074, speed: 2.35 step/s
[2022-10-31 11:02:46,600] [ INFO] - global step 2060, epoch: 9, loss: 0.00074, speed: 2.28 step/s
[2022-10-31 11:02:50,923] [ INFO] - global step 2070, epoch: 9, loss: 0.00074, speed: 2.31 step/s
[2022-10-31 11:02:55,188] [ INFO] - global step 2080, epoch: 9, loss: 0.00074, speed: 2.34 step/s
[2022-10-31 11:02:59,528] [ INFO] - global step 2090, epoch: 9, loss: 0.00073, speed: 2.30 step/s
[2022-10-31 11:03:03,827] [ INFO] - global step 2100, epoch: 9, loss: 0.00073, speed: 2.33 step/s
[2022-10-31 11:03:27,192] [ INFO] - Evaluation precision: 0.98632, recall: 0.98736, F1: 0.98684
[2022-10-31 11:03:27,193] [ INFO] - best F1 performence has been updated: 0.98193 --> 0.98684
best模型已保存
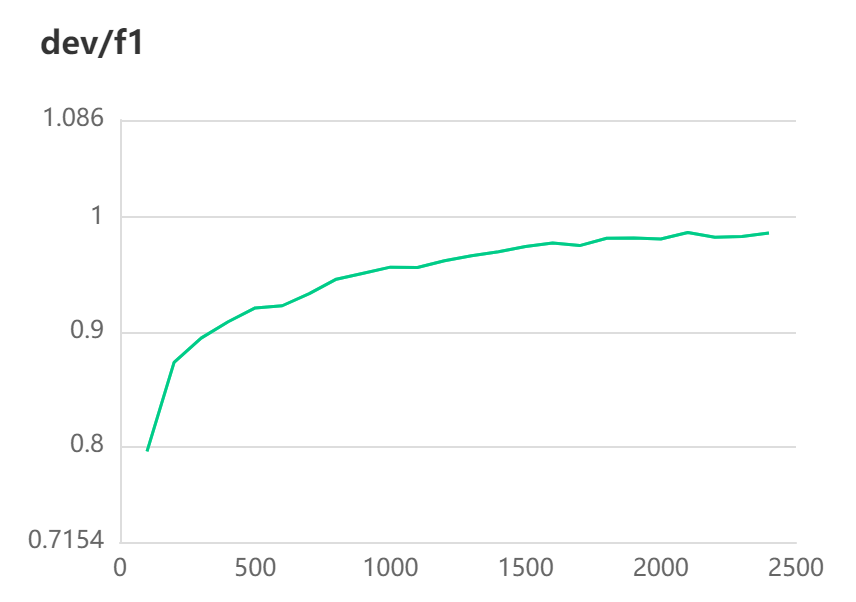
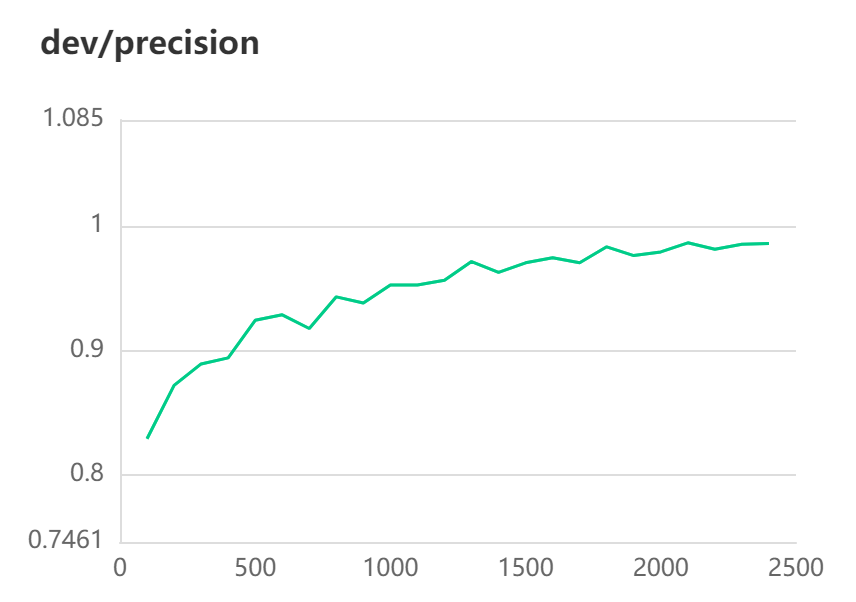
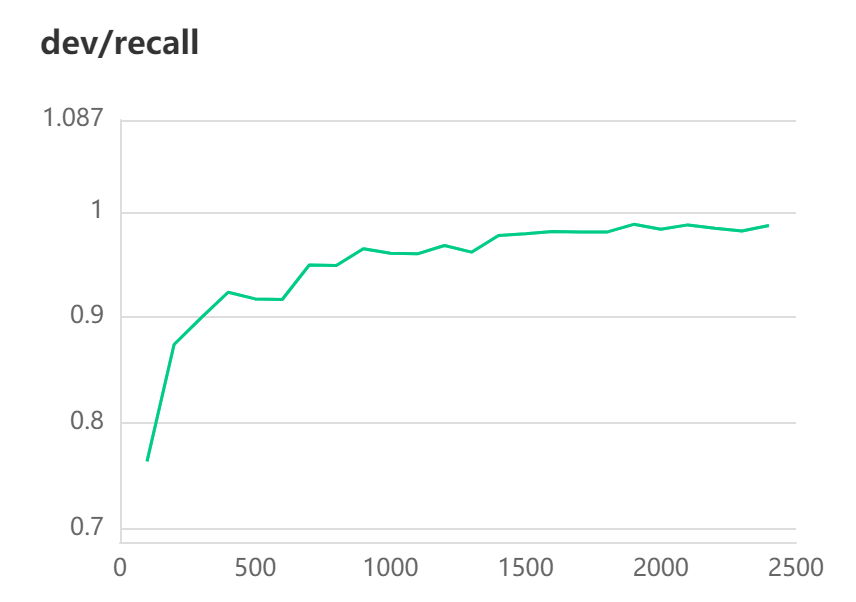
#模型评估
!python evaluate.py \--model_path ./checkpoint_train_double/model_best \--test_path ./data/dev.txt \--batch_size 32 \--max_seq_len 512
[2022-10-31 11:07:48,631] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint_train_double/model_best'.
W1031 11:07:48.656033 9462 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2
W1031 11:07:48.658501 9462 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[2022-10-31 11:08:16,539] [ INFO] - -----------------------------
[2022-10-31 11:08:16,539] [ INFO] - Class Name: all_classes
[2022-10-31 11:08:16,539] [ INFO] - Evaluation Precision: 0.98632 | Recall: 0.98736 | F1: 0.98684
!python evaluate.py \--model_path ./checkpoint_train_double/model_best \--test_path ./data/dev.txt \--debug
[2022-10-31 11:08:21,179] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint_train_double/model_best'.
W1031 11:08:21.203691 9508 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2
W1031 11:08:21.206113 9508 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[2022-10-31 11:08:28,023] [ INFO] - -----------------------------
[2022-10-31 11:08:28,023] [ INFO] - Class Name: 被告人违规情况
[2022-10-31 11:08:28,023] [ INFO] - Evaluation Precision: 0.99519 | Recall: 0.99519 | F1: 0.99519
[2022-10-31 11:08:29,860] [ INFO] - -----------------------------
[2022-10-31 11:08:29,860] [ INFO] - Class Name: 被告人交通工具
[2022-10-31 11:08:29,861] [ INFO] - Evaluation Precision: 0.98171 | Recall: 0.98773 | F1: 0.98471
[2022-10-31 11:08:31,223] [ INFO] - -----------------------------
[2022-10-31 11:08:31,223] [ INFO] - Class Name: 被告人行驶情况
[2022-10-31 11:08:31,223] [ INFO] - Evaluation Precision: 0.98675 | Recall: 0.99333 | F1: 0.99003
[2022-10-31 11:08:33,019] [ INFO] - -----------------------------
[2022-10-31 11:08:33,019] [ INFO] - Class Name: 行为地点
[2022-10-31 11:08:33,019] [ INFO] - Evaluation Precision: 0.97576 | Recall: 0.98171 | F1: 0.97872
[2022-10-31 11:08:34,941] [ INFO] - -----------------------------
[2022-10-31 11:08:34,942] [ INFO] - Class Name: 其他事件参与人
[2022-10-31 11:08:34,942] [ INFO] - Evaluation Precision: 0.98720 | Recall: 0.98540 | F1: 0.98630
[2022-10-31 11:08:36,671] [ INFO] - -----------------------------
[2022-10-31 11:08:36,671] [ INFO] - Class Name: 参与人交通工具
[2022-10-31 11:08:36,671] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2022-10-31 11:08:37,950] [ INFO] - -----------------------------
[2022-10-31 11:08:37,950] [ INFO] - Class Name: 参与人行驶情况
[2022-10-31 11:08:37,950] [ INFO] - Evaluation Precision: 0.99206 | Recall: 0.97656 | F1: 0.98425
[2022-10-31 11:08:39,599] [ INFO] - -----------------------------
[2022-10-31 11:08:39,600] [ INFO] - Class Name: 被告人责任认定
[2022-10-31 11:08:39,600] [ INFO] - Evaluation Precision: 0.97931 | Recall: 1.00000 | F1: 0.98955
[2022-10-31 11:08:40,349] [ INFO] - -----------------------------
[2022-10-31 11:08:40,349] [ INFO] - Class Name: 参与人责任认定
[2022-10-31 11:08:40,349] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2022-10-31 11:08:41,018] [ INFO] - -----------------------------
[2022-10-31 11:08:41,018] [ INFO] - Class Name: 被告人行为总结
[2022-10-31 11:08:41,018] [ INFO] - Evaluation Precision: 0.98077 | Recall: 0.89474 | F1: 0.93578
[2022-10-31 11:08:41,299] [ INFO] - -----------------------------
[2022-10-31 11:08:41,299] [ INFO] - Class Name: 搭载人姓名
[2022-10-31 11:08:41,299] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2022-10-31 11:08:41,370] [ INFO] - -----------------------------
[2022-10-31 11:08:41,370] [ INFO] - Class Name: 参与人违规情况
[2022-10-31 11:08:41,370] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
2.3最终结果
![]()
3.UIE Slim 数据蒸馏
上面方法只关注了标注数据集,下面通过训练好的UIE定制模型预测无监督数据的标签。
%cd /home/aistudio/data_distill
!python data_distill.py \--data_path /home/aistudio/data \--save_dir student_data \--task_type entity_extraction \--synthetic_ratio 10 \--model_path /home/aistudio/checkpoint_train_double/model_best
/home/aistudio/data_distill
[2022-10-31 11:16:03,982] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load '/home/aistudio/checkpoint_train_double/model_best'.
[2022-10-31 11:32:49,023] [ INFO] - Save 7040 examples to student_data/train_data.json.
[2022-10-31 11:32:49,027] [ INFO] - Save 160 examples to student_data/dev_data.json.
[2022-10-31 11:32:49,027] [ INFO] - Save 0 examples to student_data/test_data.json.
!python train.py \--task_type entity_extraction \--train_path student_data/train_data.json \--dev_path student_data/dev_data.json \--label_maps_path student_data/label_maps.json \--num_epochs 20 \--encoder ernie-3.0-xbase-zh\--device "gpu"\--valid_steps 200\--logging_steps 10\--save_dir './checkpoint_base_v1'\--batch_size 32
!python train.py \--task_type entity_extraction \--train_path student_data/train_data.json \--dev_path student_data/dev_data.json \--label_maps_path student_data/label_maps.json \--num_epochs 30 \--encoder ernie-3.0-base-zh\--device "gpu"\--valid_steps 200\--logging_steps 10\--save_dir './checkpoint_base_v1'\--batch_size 32
[2022-10-31 12:11:09,409] [ INFO] - global step 5920, epoch: 27, loss: 0.75421, speed: 2.87 step/s
[2022-10-31 12:11:12,909] [ INFO] - global step 5930, epoch: 27, loss: 0.75070, speed: 2.86 step/s
[2022-10-31 12:11:15,089] [ INFO] - global step 5940, epoch: 27, loss: 0.70207, speed: 4.59 step/s
[2022-10-31 12:11:19,017] [ INFO] - global step 5950, epoch: 28, loss: 0.77438, speed: 2.55 step/s
[2022-10-31 12:11:22,481] [ INFO] - global step 5960, epoch: 28, loss: 0.76086, speed: 2.89 step/s
[2022-10-31 12:11:25,946] [ INFO] - global step 5970, epoch: 28, loss: 0.77486, speed: 2.89 step/s
[2022-10-31 12:11:29,317] [ INFO] - global step 5980, epoch: 28, loss: 0.72513, speed: 2.97 step/s
[2022-10-31 12:11:32,698] [ INFO] - global step 5990, epoch: 28, loss: 0.73776, speed: 2.96 step/s
[2022-10-31 12:11:36,087] [ INFO] - global step 6000, epoch: 28, loss: 0.75467, speed: 2.95 step/s
[2022-10-31 12:11:38,912] [ INFO] - Evaluation precision: {'entity_f1': 0.93753, 'entity_precision': 0.98605, 'entity_recall': 0.89357}
[2022-10-31 12:11:38,912] [ INFO] - best F1 performence has been updated: 0.93728 --> 0.93753
best_model已保存
# 预测
import json
from paddlenlp import Taskflowdef predict(ie, result_item):result = ie(result_item['context'])[0]# print(result)sub_list = []for item in result:sub_tmp = {}sub_tmp["label"] = str(keys[values.index(str(item))])all_search=str_all_index(result_item['context'], result[item][0]["text"])txt_list=[]sub_span=[]if len(result[item])==1:for i in range(len(all_search)): txt_list.append(result[item][0]["text"]) sub_span.append([all_search[i], all_search[i] +len(result[item][0]["text"])]) else:for i in range(len(result[item])): txt_list.append(result[item][i]["text"]) sub_span.append([result[item][i]["start"], result[item][i]["end"]]) sub_tmp["text"]=txt_listsub_tmp["span"]=sub_spansub_list.append(sub_tmp)result_item["entities"] = sub_list return result_itemif __name__ == '__main__':test_file = '/home/aistudio/data/test.json'span={'11339': '被告人交通工具','11340': '被告人行驶情况','11341': '被告人违规情况','11342': '行为地点','11343': '搭载人姓名','11344': '其他事件参与人','11345': '参与人交通工具','11346': '参与人行驶情况','11347': '参与人违规情况','11348': '被告人责任认定','11349': '参与人责任认定','11350': '被告人行为总结',}values = list(span.values())keys=list(span.keys())# idx = values.index("被告人交通工具")# print(idx)# print(keys)# key = keys[idx]# print(key)# schema = span.values()# 设定抽取目标和定制化模型权重路径# ie = Taskflow("information_extraction", schema=schema,batch_size=32,precision='fp32',use_faster=True, task_path='./checkpoint_train_double/model_best')ie = Taskflow("information_extraction", model="uie-data-distill-gp", task_path="/home/aistudio/data_distill/checkpoint_base_v1/model_best",batch_size=32) # Schema 在闭域信息抽取中是固定的ff = open('/home/aistudio/output/result_distill.txt', 'w')for line in open(test_file, 'r',encoding='utf-8'):result_item=json.loads(line)target = predict(ie, result_item)ff.write(json.dumps(target, ensure_ascii=False) + '\n')ff.close()print("数据结果已导出")
[2022-10-31 12:18:15,492] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load '/home/aistudio/data_distill/checkpoint_base_v1/model_best'.数据结果已导出
4.主动学习方案:
参考项目:主动学习(Active Learning)综述以及在文本分类和序列标注应用
1.主动学习简介
主动学习是指对需要标记的数据进行优先排序的过程,这样可以确定哪些数据对训练监督模型产生最大的影响。
主动学习是一种学习算法可以交互式查询用户(teacher 或 oracle),用真实标签标注新数据点的策略。主动学习的过程也被称为优化实验设计。
主动学习的动机在于认识到并非所有标有标签的样本都同等重要。
主动学习是一种策略/算法,是对现有模型的增强。而不是新模型架构。主动学习背后的关键思想是,如果允许机器学习算法选择它学习的数据,这样就可以用更少的训练标签实现更高的准确性。——Active Learning Literature Survey, Burr Settles。通过为专家的标记工作进行优先级排序可以大大减少训练模型所需的标记数据量。降低成本,同时提高准确性。
主动学习不是一次为所有的数据收集所有的标签,而是对模型理解最困难的数据进行优先级排序,并仅对那些数据要求标注标签。然后模型对少量已标记的数据进行训练,训练完成后再次要求对最不确定数据进行更多的标记。
通过对不确定的样本进行优先排序,模型可以让专家(人工)集中精力提供最有用的信息。这有助于模型更快地学习,并让专家跳过对模型没有太大帮助的数据。这样在某些情况下,可以大大减少需要从专家那里收集的标签数量,并且仍然可以得到一个很好的模型。这样可以为机器学习项目节省时间和金钱!
4.1 active learning的基本思想
主动学习的模型如下:
A=(C,Q,S,L,U),
其中 C 为一组或者一个分类器,L是用于训练已标注的样本。Q 是查询函数,用于从未标注样本池U中查询信息量大的信息,S是督导者,可以为U中样本标注正确的标签。学习者通过少量初始标记样本L开始学习,通过一定的查询函数Q选择出一个或一批最有用的样本,并向督导者询问标签,然后利用获得的新知识来训练分类器和进行下一轮查询。主动学习是一个循环的过程,直至达到某一停止准则为止。
这个准则可以是迭代次数,也可以是准确率等指标达到设定值
![]()
在各种主动学习方法中,查询函数的设计最常用的策略是:不确定性准则(uncertainty)和差异性准则(diversity)。 不确定性越大代表信息熵越大,包含的信息越丰富;而差异性越大代表选择的样本能够更全面地代表整个数据集。
对于不确定性,我们可以借助信息熵的概念来进行理解。我们知道信息熵是衡量信息量的概念,也是衡量不确定性的概念。信息熵越大,就代表不确定性越大,包含的信息量也就越丰富。事实上,有些基于不确定性的主动学习查询函数就是使用了信息熵来设计的,比如熵值装袋查询(Entropy query-by-bagging)。所以,不确定性策略就是要想方设法地找出不确定性高的样本,因为这些样本所包含的丰富信息量,对我们训练模型来说就是有用的。
那么差异性怎么来理解呢?之前说到或查询函数每次迭代中查询一个或者一批样本。我们当然希望所查询的样本提供的信息是全面的,各个样本提供的信息不重复不冗余,即样本之间具有一定的差异性。在每轮迭代抽取单个信息量最大的样本加入训练集的情况下,每一轮迭代中模型都被重新训练,以新获得的知识去参与对样本不确定性的评估可以有效地避免数据冗余。但是如果每次迭代查询一批样本,那么就应该想办法来保证样本的差异性,避免数据冗余。
![]()
从上图也可以看出来,在相同数目的标注数据中,主动学习算法比监督学习算法的分类误差要低。这里注意横轴是标注数据的数目,对于主动学习而言,相同的标注数据下,主动学习的样本数>监督学习,这个对比主要是为了说明两者对于训练样本的使用效率不同:主动学习训练使用的样本都是经过算法筛选出来对于模型训练有帮助的数据,所以效率高。但是如果是相同样本的数量下去对比两者的误差,那肯定是监督学习占优,这是毋庸置疑的。
4.2active learning与半监督学习的不同
很多人认为主动学习也属于半监督学习的范畴了,但实际上是不一样的,半监督学习和直推学习(transductive learning)以及主动学习,都属于利用未标记数据的学习技术,但基本思想还是有区别的。
如上所述,主动学习的“主动”,指的是主动提出标注请求,也就是说,还是需要一个外在的能够对其请求进行标注的实体(通常就是相关领域人员),即主动学习是交互进行的。
而半监督学习,特指的是学习算法不需要人工的干预,基于自身对未标记数据加以利用。
4.3.主动学习基础策略(小试牛刀)
常见主动学习策略
在未标记的数据集上使用主动学习的步骤是:
- 首先需要做的是需要手动标记该数据的一个非常小的子样本。
- 一旦有少量的标记数据,就需要对其进行训练。该模型当然不会很棒,但是将帮助我们了解参数空间的哪些领域需要首标记。
- 训练模型后,该模型用于预测每个剩余的未标记数据点的类别。
- 根据模型的预测,在每个未标记的数据点上选择分数
- 一旦选择了对标签进行优先排序的最佳方法,这个过程就可以进行迭代重复:在基于优先级分数进行标记的新标签数据集上训练新模型。一旦在数据子集上训练完新模型,未标记的数据点就可以在模型中运行并更新优先级分值,继续标记。
- 通过这种方式,随着模型变得越来越好,我们可以不断优化标签策略。
![]()
参考项目:主动学习(Active Learning)综述以及在文本分类和序列标注应用
5.总结
| 模型 | Precision | Recall | F1 |
|---|---|---|---|
| Base | 88.96 | 95.37 | 92.06 |
| Base+全量 | 93.86 (+4.9) | 99.2 (+3.83) | 96.45 (+4.39) |
| UIE Slim | 98.632 (+9.67) | 98.736 (+3.37) | 98.684(+6.62) |
简单归纳一下:增加标注量是关键
数据标注占比很重要,未利用的1w数据需要利用起来,而且小样本数据下数据覆盖面需要用一定方法维持,目前得分高的应该都是额外增加标注量了
提升预测速度,UIE数据蒸馏方案推荐使用(GlobalPointer),并可以在这个基础上优化,用mini等更小的模型
主动学习用起来,筛选出困难样本,争取达到30%标注量实现全样本效果!通过多轮迭代实现在这个任务的智能标注
最后感谢肝王@javaroom之前提供的baseline的数据预处理过程和提交数据转换,剩了编写处理时间。
参考项目:主动学习(Active Learning)综述以及在文本分类和序列标注应用
UIE模型使用情况参考下面链接,写的很详细了要考虑了工业部署情况方案
参考链接:
UIE Slim满足工业应用场景,解决推理部署耗时问题,提升效能!
PaddleNLP之UIE信息抽取小样本进阶(二)[含doccano详解]
Paddlenlp之UIE模型实战实体抽取任务【打车数据、快递单】
此文章为搬运
原项目链接
基线提升至96.45%:2022 司法杯犯罪事实实体识别+数据蒸馏+主动学习相关推荐
- 【Paddle打比赛】基于PaddleNLP法研杯2022 -犯罪事实实体识别
一.第五届中国法研杯 LAIC2022 司法人工智能挑战赛 [犯罪事实实体识别] 比赛地址: http://data.court.gov.cn/pages/laic.html 1.任务介绍 本赛道由中 ...
- 【ICDE 2022】阿里发布稀疏模型训练框架HybridBackend,单位成本下训练吞吐提升至5倍
目录 一 HybridBackend是什么 二 项目背景 三 面临挑战 1 变化的硬件资源瓶颈 2 算子细碎化(fragmentation) 四 HybridBackend的系统架构 1 ...
- 阿里开源新一代人机对话模型 ESIM:准确率打破世界纪录,提升至 94.1%!
近日,阿里 AI 开源了新一代人机对话模型 Enhanced Sequential Inference Model(ESIM).ESIM 是一种专为自然语言推断而生的加强版 LSTM,据阿里介绍,该算 ...
- 360数科第三季度财报:输出积木式技术样板,科技业务占比提升至28%
11月20日,360数科发布2020年第三季度未经审计的财务业绩.数据显示,360数科的科技业务占比提升至28%. 在数字科技驱动下,截至第三季度末,360数科连接近100家金融机构,累计为1871万 ...
- 【2022羊城杯WriteUp By EDISEC】
2022羊城杯WriteUp By EDISEC Web little_db Safepop rce_me step_by_step-v3 ComeAndLogin simple_json Misc ...
- 冠军出炉!2022『猛犸杯』国际组学数据创新大赛圆满收官
2022 MICOS 2月26日,由中国生物信息学学会(筹).广东省科技基础条件平台中心指导,深圳国家基因库.鹏城实验室.深圳华大生命科学研究院主办的2022『猛犸杯』国际组学数据创新大赛(2022 ...
- Java应用全链路启动速度提升至15s,阿里云SAE能力再升级
简介:Java 作为一门面向对象编程语言,在性能方面的卓越表现独树一帜.但在高性能的背后,Java 的启动性能差也令人印象深刻,大家印象中的 Java 笨重.缓慢的印象也大多来源于此,高性能和快启动速 ...
- 2022长安杯复盘——lucid凡
2022长安杯案情背景:某地警方接到受害人报案称其在某虚拟币交易网站遭遇诈骗,该网站号称使用"USTD币"购买所谓的"HT币",受害人充值后不但 "H ...
- 2022美亚杯第八届中国电子数据取证大赛-个人赛write up详解,软件就用弘连和美亚,尽量写的细致一点。建议入门看,仅为了解题,没有专业精神。专业选手去看后面推荐的两篇解析,都是大佬。
建议新手看我的博客,比较简单粗暴,解题率较低,仅仅是为了比赛,入门的同学可以看看.我的水平还很糟糕,之后会努力学习,所以这篇博客也会不断修改完善.博客还有很多不当之处,如有发现不当之处请私信我,我会做 ...
最新文章
- [bzoj1042][HAOI2008]硬币购物
- java 算法笔试题_【干货】经典算法面试题代码实现-Java版
- 找到数组中第k小的值(利用快排的划分函数)
- 树莓派研发笔记三——搭建服务器和实践任务
- uva 11374(Dijkstra) HappyNewYear!!!
- CentOS7下RabbitMq安装和开机自启动配置
- 小D课堂 - 零基础入门SpringBoot2.X到实战_第9节 SpringBoot2.x整合Redis实战_37、分布式缓存Redis介绍...
- Turboc C 编译出错信息的中文翻译 - C/C++ / C语言。
- 免费开源字体_7种华丽的免费开源字体以及何时使用它们
- JS遍历map集合以及map对象
- OTL音频功率放大器
- 通达信c语言编程,通达信编程实例100个;
- 解决ROS中运行launch文件报错ERROR: cannot launch node of type[xxx/xxx]:xxx的问题
- 2022-2028年中国现代服务行业企业投资项目指引及机会战略分析报告
- Node 框架之sails
- 微信小程序获取手机号登录流程
- 韩国WA15-6819B高性能DSP数字功放芯片
- css百分比定位和百分比尺寸
- 【终端快捷键】Linux terminal 终端常用快捷键
- 1031 查验身份证 (15 分)