ICLR2022 | GREASE LM: 图推理增强QA上的LM
本文是Christopher D. Manning和Jure Leskovec合作的一篇文章,NLPer和GNNer应该对这两个名字不陌生,一个讲了CS224N,一个讲了CS224W。
本文提出一种用图推理增强QA的LM的架构:GREASE LM。GREASE LM通过对LM和GNN进行多层次深度交互,有效捕捉导GNN的结构信息与LM的语义约束,从而提升了模型在QA任务上的性能,和处理复杂问题的能力。
研究背景
回答文本相关的问题需要从陈述的上下文(context)和它背后的知识(knowledge)来推理。
QA任务的基本范式是pre-trained LM。尽管在普通的benchmark上表现良好,但是当用于测试的example的分布与精调的数据集不相同时,模型的表现会变的挣扎。因为这种学习方式希望通过简单(偶尔是错误)的模式匹配直接走捷径获得答案,虽然能从LM中捕捉到context的情景约束和细微差别,但不能很好的表达概念之间的潜在关系。我们希望能用context提供的显性信息和内在的隐性知识来进行健壮的、结构化的推理。
Knowledge Graph(KG)由描述实体关系的三元组构成,被认为蕴含有大量的知识,在QA之类的推理任务上作用显著,因此用KG给LM扩充知识的结构化表示成为热门问题。然而,要将KG的推理优势扩展到一般的QA(问题和答案用自然语言表示,不容易转换成严格的逻辑查询),需要根据QA example提供的信息和约束找到KG中正确的知识集成。
早期LM+KG的工作通常将两种模态在浅层并且以非交互的方式融合,比如各自独立编码最后预测时再融合,或者用一个模态去加强另一个模态的输入。一般分为三种:
- 双塔结构,没有交互;
- KG支撑LM,比如用KG的编码来增强QA example的文本表示;
- 第三种是LM支撑KG,用文本表示(LM的最后一层)去增强从example提取的KG。
这三种结构信息流动最多有一个方向,这样两种模态信息交互的能力有限。如果想更好的模拟结构化的情景推理,需要实现双向的信息交互,让KG获得LM的细微语义约束,KG和LM进行深层次的融合。最近的一些工作探讨了这两种模态更深层次的集成。有的通过在结构化的KG数据上训练LM来将隐层知识编码进LM,然后用LM去生成针对QA的小KG。但是这样KG在转化成文本之后结构信息就丢掉了。QA-GNN用消息传递来联合更新LM和GNN,但是他们将LM池化作为整个架构的文本组件,限制了文本表示的更新能力。还有一些工作在预训练的时候将KG融入到LM中,但是模态的交互方向更多是将知识送到语言中。 Sun的工作与GREASE LM相似,但是它交互的bottleneck需要高精度的实体链接;并且LM和KG的参数共享限制了表达能力。
模型架构
符号定义:
MCQA(multiple choice question answering)的数据集包括上下文段落 ccc ,问题 qqq ,答案候选集 AAA ,都以文本的形式表示。本工作中,还假设有额外的知识图谱 GGG 提供背景知识。
给定QA example (c,q,A)(c,q,A)(c,q,A) 和KG GGG ,判断正确的答案 a∈Aa \in Aa∈A 。
我们将自然语言中的token序列表示为 {w1,…,wT}\{w_1,\dots,w_T \}{w1,…,wT} ,其中 TTT 表示token数量,token wtw_twt 在 lll -th layer的表示为 ht(l)h_t^{(l)}ht(l) 。KG的点集表示为 {e1,…,eJ}\{e_1,\dots,e_J\}{e1,…,eJ} ,其中 JJJ 表示节点的数量。节点 eje_jej 在 lll -th layer的表示为 ej(l)e_j^{(l)}ej(l) 。
输入表示:
先将 c,q,ac,q,ac,q,a 和分离符并起来作为模型输入 [c;q;a][c;q;a][c;q;a] ,转换成token序列 {w1,…,wT}\{w_1,\dots,w_T \}{w1,…,wT} ;然后用输入序列去检索(retrieval)出 GGG 的子图 GsubG_{sub}Gsub , GsubG_{sub}Gsub 提供跟QA example相关的知识. GsubG_{sub}Gsub 的点集表示为 {e1,…,eJ}\{e_1,\dots,e_J\}{e1,…,eJ} .
KG Retrieval:
首先根据文本中的实体从 GGG 中链接出一个初始点集 VlinkedV_{linked}Vlinked 。然后将 VlinkedV_{linked}Vlinked 中任意点对之间的2-hop路径(长度为2,也就是中间只有一个点,也就是桥点)的桥点加进去形成 VretrievedV_{retrieved}Vretrieved 。然后再对 VretrievedV_{retrieved}Vretrieved 里的点计算相关分数(relevance score) : 将node name并在QA example后面,通过LM得到node name的output score,作为relavance score。我们取 VretrievedV_{retrieved}Vretrieved 中分数最高的200个点为 VsubV_{sub}Vsub ,剩下的都扔掉。最后,将所有链接两个 VsubV_{sub}Vsub 中的点的边加进去形成 GsubG_{sub}Gsub 。另外, GsubG_{sub}Gsub 里的每个点都做一个标记,标记这个点对应的实体是从哪里来的,来自上下文 ccc / 询问 qqq / 答案 aaa / 这些点的相邻节点。本文之后的KG都是表示 GsubG_{sub}Gsub .
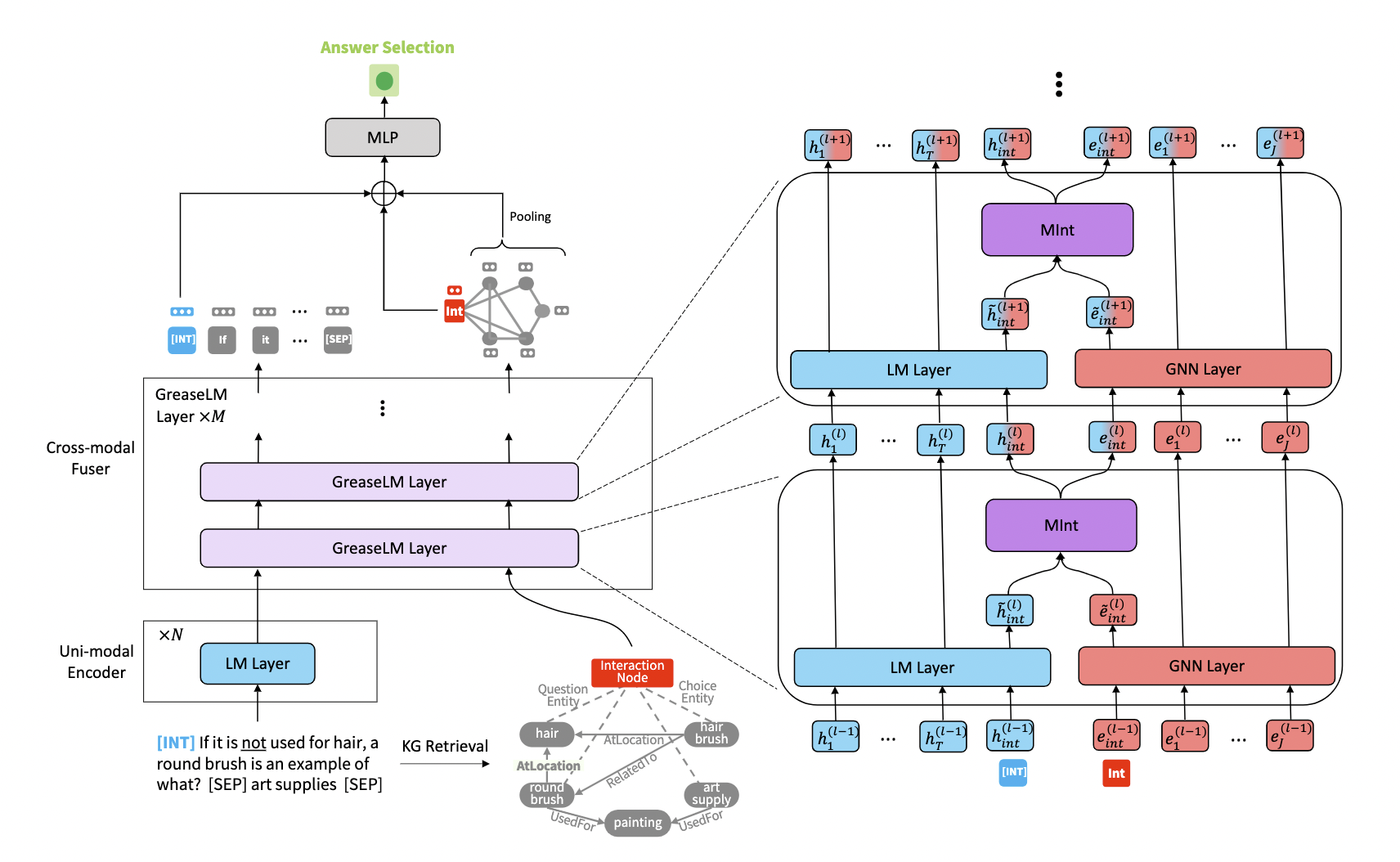
图1. GREASELM模型架构图
GREASE LM 整体架构有两个堆叠组件:
- 单模态的LM层*N:获得输入token的初始表示
- 交叉模态的GREASELM层*M:将LM层的文本表示与KG的图表示融合在一起
Language Pre-Encoding
将 {w1,…,wT}\{w_1,\dots,w_T \}{w1,…,wT} 的token、段、位置嵌入求和作为 l=0l=0l=0 时的表示 {hint(0),h1(0),…,hT(0)}\{h_{int}^{(0)},h_1^{(0)},\dots,h_T^{(0)}\}{hint(0),h1(0),…,hT(0)} 。之后就用LM-layer运算出每一层的表示。LM-layer的参数初始为预训练的结果。
{hint(l),h1(l),…,hT(l)}=LM−layer({hint(l−1),h1(l−1),…,hT(l−1)})forl=1,…,N\{h_{int}^{(l)},h_1^{(l)},\dots,h_T^{(l)}\}=LM-layer(\{h_{int}^{(l-1)},h_1^{(l-1)},\dots,h_T^{(l-1)}\}) \\ for \ \ l=1,\dots,N {hint(l),h1(l),…,hT(l)}=LM−layer({hint(l−1),h1(l−1),…,hT(l−1)})forl=1,…,N
GreaseLM layer
Interaction Bottlenecks:
首先定义用于交互的 interaction token wintw_{int}wint 和 interaction node einte_{int}eint ,作为两个模态交互的bottlenecks。将 wintw_{int}wint 添加到token序列里面,将 einte_{int}eint 链接 GsubG_{sub}Gsub 中点集 VlinkV_{link}Vlink 。(不是 GsubG_{sub}Gsub 所有点)
GreaseLM layer有三个组成部分:
- transformer LM encoder block
- GNN layer
- MInt layer
Language Representation:
在第 lll 层GreaseLM layer,将token embeddings {hint(N+l−1),h1(N+l−1),…,hT(N+l−1)}\{h_{int}^{(N+l-1)},h_1^{(N+l-1)},\dots,h_T^{(N+l-1)}\}{hint(N+l−1),h1(N+l−1),…,hT(N+l−1)} 输入到transformer LM encoder block继续编码:
{h~int(N+l),h~1(N+l),…,h~T(N+l)}=LM−Layer({hint(N+l−1),h1(N+l−1),…,hT(N+l−1)})forl=1,…,M\{\widetilde{h}_{int}^{(N+l)},\widetilde{h}_1^{(N+l)},\dots,\widetilde{h}_T^{(N+l)}\}=LM-Layer(\{h_{int}^{(N+l-1)},h_1^{(N+l-1)},\dots,h_T^{(N+l-1)}\})\\ for \ \ l=1,\dots,M {h
h~\widetilde{h}h
之后用于交互的bottleneck hint(N+l)h_{int}^{(N+l)}hint(N+l) 经过MInt会得到GNN的信息,那么在下一层的transformer LM encoder block的时候,hint(N+l)h_{int}^{(N+l)}hint(N+l) 会把GNN的信息传递给 h(N+l+1)h^{(N+l+1)}h(N+l+1) 。
Graph Representation:
GsubG_{sub}Gsub 中node embedding用MHGRN初始化:使用预定义的模板将KG中的知识三元组转换为句子。然后将句子送到BERT-Large LM中计算嵌入。最后,对于所有包含实体的句子,我们提取这些句子中实体的符号表示,在这些表示上进行均值池化并投影。
经过初始化,得到 {e1(0),…,eJ(0)}\{e_1^{(0)},\dots,e_J^{(0)}\}{e1(0),…,eJ(0)} ,并随机化初始bottleneck eint(0)e_{int}^{(0)}eint(0) 的embedding。
在每一层GNN,做一次消息传递。
{e~int(l),e~1(l),…,e~J(l)}=GNN({eint(l−1),e1(l−1),…,eJ(l−1)})forl=1,…,M\{\widetilde{e}_{int}^{(l)},\widetilde{e}_1^{(l)},\dots,\widetilde{e}_J^{(l)}\}=GNN(\{e_{int}^{(l-1)},e_1^{(l-1)},\dots,e_J^{(l-1)}\})\\ for \ \ l=1,\dots,M {e
具体的更新方式是GAT的一种变种,每个node根据邻居做消息传递更新表示。
e~j(l)=fn(∑es∈Nej∪{ej}αsjmsj)+ej(l−1)\widetilde{e}^{(l)}_j=f_n(\sum_{e_s \in N_{e_{j}} \cup \{e_j\}}\alpha_{sj}m_{sj})+e_j^{(l-1)} e
NejN_{e_{j}}Nej 表示 eje_jej 的邻域,msjm_{sj}msj 表示邻点 ese_ses 传递给 eje_jej 的信息, αsj\alpha_{sj}αsj 是用来缩放 msjm_{sj}msj 的注意力权重, fnf_nfn 是一个两层的MLP。
msjm_{sj}msj 具体计算方式如下:
rsj=fr(r~sj,us,uj)msh=fm(es(l−1),us,rsj)r_{sj}=f_r(\widetilde{r}_{sj},u_s,u_j) \\ m_{sh}=f_m(e_s^{(l-1)},u_s,r_{sj}) \\ rsj=fr(r
usu_sus ,uju_juj 是node type embedding(KG Retrieval最后加的类型标记),r~sj\widetilde{r}_{sj}r
αsj\alpha_{sj}αsj 具体计算方式如下:
qs=fq(es(l−1),us)kj=fk(ej(l−1),uj,rsj)γsj=qsTkjDαsj=exp(γsj)∑es∈Nej∪{ej}exp(γsj)q_s=f_q(e_s^{(l-1)},u_s) \\ k_j=f_k(e_j^{(l-1)},u_j,r_{sj}) \\ \gamma_{sj}=\frac{q_s^Tk_j}{\sqrt{D}} \\ \alpha_{sj}=\frac{exp(\gamma_{sj})}{\sum_{e_s \in N_{e_{j}} \cup \{e_j\}}exp(\gamma_{sj})} qs=fq(es(l−1),us)kj=fk(ej(l−1),uj,rsj)γsj=D
fqf_qfq 和 fkf_kfk 都是线性变化。
同理,einte_{int}eint 在获得LM传递过来的信息之后,在下一层的GNN中,会将信息传递给其他的node。
Modality Interaction:
在通过LM layer和GNN layer更新过各自的embedding之后,用 modality interaction layer (MInt) 来让两个模态的信息通过 token wintw_{int}wint 和 node einte_{int}eint 这两个bottleneck进行融合。作者直接将 h~int(l)\widetilde{h}_{int}^{(l)}h
[hint(l);eint(l)]=MInt([h~int(l);e~int(l)])[h_{int}^{(l)};e_{int}^{(l)}]=MInt([\widetilde{h}_{int}^{(l)};\widetilde{e}_{int}^{(l)}]) [hint(l);eint(l)]=MInt([h
MInt为一个两层的MLP,但是也可以用别的融合操作来替换。除了用于交互的 wintw_{int}wint 和 einte_{int}eint,其他embedding都保持不变: w(l)=w~(l)forw∈{w1,…,wT},e(l)=e~(l)fore∈{e1,…,eJ}w^{(l)}=\widetilde{w}^{(l)}\ for \ w \in \{w_1,\dots,w_T\},\ e^{(l)}=\widetilde{e}^{(l)}\ for \ e \in \{e_1,\dots,e_J\}w(l)=w
Learning & Inference:
对于MCQA任务,给定问题 qqq ,从候选集 AAA 中选择一个答案 aaa ,aaa 正确的概率为 p(a∣q,c)∝exp(MLP(hintN+M,eintM,g))p(a|q,c) \propto exp(MLP(h_{int}^{N+M},e_int^{M},g))p(a∣q,c)∝exp(MLP(hintN+M,eintM,g)) ,ggg 为将 hintN+Mh_{int}^{N+M}hintN+M 作为query、对 {ejM∣ej∈e1,…,eJ}\{e_j^{M}|e_j \in {e_1,\dots,e_J}\}{ejM∣ej∈e1,…,eJ} 的基于注意力的池化。采用交叉熵作为loss,选择 argmaxa∈Ap(a∣q,c)arg \ max_{a \in A} \ p(a|q,c)argmaxa∈Ap(a∣q,c) 作为最合理的答案。
实验结果
MCQA数据集
| 数据集 | 内容 | LM | KG | GREASE LM相比于LM的性能提升 | GREASE LM相比于LM+KG的性能提升 |
|---|---|---|---|---|---|
| CommonsenseQA | 常识 | RoBERTa-Large | ConceptNet | 5.5% | 0.9% |
| OpenbookQA | 基本的科学知识 | AristoRoBERTa | ConceptNet | 6.6% | 1.8% |
| MedQA-USMLE | 生物医学和临床知识 | SapBERT | 自建的知识图谱+DrugBank | 1.3% | 0.5% |
表格中LM和KG表示Grease LM采用的LM和KG
Dataset Result

表1. 数据集示例

表2. CommonsenseQA Result

表3. OpenbookQA Result
表2和表3中Grease LM都要比QA-GNN优秀,说明这样持续的融合比不持续融合的性能更强。

表4. 与大模型在OpenBookQA上比较
在表5中,Grease LM实现了第3高,相比于参数接近的模型,性能是最高的。
定量分析
作者希望知道模型在更复杂的推理上的表现,但是没有一个明确的方法取衡量命题的推理复杂性。于是作者用3个特性来表述:介词短语的数量(视为显性约束的数量,虽然有时选择正确的answer的过程中会用不上这种约束);否定词(e.g.,no,never)的出现;模糊词(e.g.,sometimes,maybe)的出现。

表5. 复杂推理的表现
如表5所示,在否定项和模糊项上,Grease LM都显著优于RoBERTa-Large和QA-GNN,说明Grease LM对于细微语意约束捕捉的更好。没有介词短语的时候,QA-GNN强于Grease LM;但是当问题复杂度的上升——介词短语逐渐增加后,Grease LM的表现会好于QA-GNN。QA-GNN的融合方式是将LM对于context的最终表示初始化为GNN的一个node,这种末端融合在一定程度上有效提高了性能,但是这样会在LM与KG交互之前,将整个context压缩成一个向量,严重限制了能被捕捉到的交互信息。
另外一个发现是即便没有介词短语,GREASELM和QA-GNN都比RoBERTa-Large好,可能是因为这些问题不需要推理,但是需要一些特定的常识,这些常识在RoBERTa-Large预训练的时候可能没有学到。
定性分析

图2. 图注意力权重的变化
在图2中,作者检验了Grease LM和QA-GNN各自GNN中node之间的注意力权重,来分析Grease LM的推理步骤是否比QA-GNN更有效。对于从 CommonsenseQA IH-dev拿出的这个例子,GreaseLM做出了正确预测:airplane,而QA-GNN的预测:motor vehicle 是错误的。
对于GreaseLM,从第一层到中间层,“bug”的权重逐渐增加,但是从中间层到最后层,权重下降了,符合“unlikey”的直觉。与此同时,“windshield”的权重从始至终都在增加。凭借着“windshield”与“airplane”之间的链接,“bug”与“car”的负链接,选择了正确的答案。
对于QA-GNN,“bug”的权重始终都在增加,可能是因为“bug”在context中反复出现,转化成GNN的node之后被很好的表示,但是没有像GreaseLM那样被LM重新表述。
泛化性
以上说明了GreaseLM在一般常识推理领域的表现,下面用MedQA-USMLE来评估泛化性。

表6. MedQA-USMLE Result
可以看出GreaseLM要比SapBERT,QA-GNN都要好。说明GreaseLM是一种对于多个领域/KG都适用的LM增广。

表9和表10. LM泛化性结果
为了评估GreaseLM的提升是否与用于使用的LM无关,作者用RoBERTA-BASE在CommonsenseQA上替换了RoBERTA-LARGE,用BioBERT和PubmedBERT在MedQA-USMLE上替换SapBERT。结果表明,将GreaseLM作为KG和LM的模态交互,可以改进多个LM的性能。
消融实验

表8. 消融实验结果
首先,当没有模态融合时,正确率从78.5%掉到76.5%,相当于QA-GNN。隔层融合也会降低性能,可能是因为影响了学习的连续性,当我们用预训练的LM权重来初始化模型的时候,会产生这样的特性。并且共享MInt的参数比不共享要好,可能因为在数据集不大的时候共享参数避免了过拟合。
对于GreaseLM的层数,当M=5时性能最好,但是M=4或者M=6的时候效果也差不多,说明模型对这个参数不敏感。
对于图的连接性,将 einte_{int}eint 链接到所有的节点相比于只链接到 VlinkV_{link}Vlink 会产生性能的下降,可能是因为是因为整个子图有200个点,全链接会导致过载。只连接到输入中的实体节点时,这些实体节点可以作为一个过滤器过滤掉不重要的信息。
对于KG node embedding的初始化,用随机权重会导致性能直接从78.5%降到60.8%,用标准的KG embedding(TranE)性能会恢复到77.7%。BERT-based始终是最好的。
ICLR2022 | GREASE LM: 图推理增强QA上的LM相关推荐
- 模型增强 | 利用 NLG 增强 QA 任务性能
作者 | 许明 整理 | NewBeeNLP 上周打算把UniLM在toolkit4nlp[1]的基础上实现一下,又刷了一遍UniLM论文[2],发现作者提到用UniLM做问题生成,来增强QA任务的性 ...
- 论文浅尝 | ExCAR: 一个事件图知识增强的可解释因果推理框架
笔记整理:朱珈徵,天津大学硕士 链接:https://aclanthology.org/2021.acl-long.183.pdf 动机 因果推理旨在理解因果之间的一般因果相关性,对于各种人工智能应用 ...
- Symbolic Graph Reasoning Meets Convolutions 符号图推理与卷积结合的方式
文章发表在32nd Conference on Neural Information Processing Systems (NIPS 2018), Montréal, Canada 摘要 我们探索了 ...
- 清华「计图」现在支持国产芯片了!动态图推理比PyTorch快了270倍
明敏 发自 凹非寺 量子位 报道 | 公众号 QbitAI 清华自研的深度学习框架计图(Jittor)在动态图推理速度上又一次完胜PyTorch. 最近,计图团队完成了在寒武纪芯片MLU270上的移植 ...
- 图神经网络的图网络学习(上)
图神经网络的图网络学习(上) 原文:Learning the Network of Graphs for Graph Neural Networks 摘要 图神经网络 (GNN) 在许多使用图结构数据 ...
- 【图神经网络实战】深入浅出地学习图神经网络GNN(上)
文章目录 一.图神经网络应用领域 1.1 芯片设计 1.2 场景分析与问题推理 1.3 推荐系统 1.4 欺诈检测与风控相关 1.5 知识图谱 1.6 道路交通的流量预测 1.7 自动驾驶(无人机等场 ...
- 【深度学习,NLP,LM】Alpaca-Lora ,Colab上部署与调用
[深度学习,NLP,LM]Alpaca-Lora ,Colab上部署与调用 前言 安装环境 运行generate代码 前言 Alpaca-Lora Huggingface项目 Tloen/Alpaca ...
- 论文解读 | 利用自适应图推理的光流学习方法
此篇论文已被 AAAI 2022 收录,论文链接请见"阅读原文". 研究动机 光流可以表达视频两帧图像之间的像素级对应关系,它是视频理解和分析领域中的一项基本任务.尽管基于深度学习 ...
- 一小时讲懂图神经网络在分子上的应用
介绍:图神经网络在分子上的应用是当前的研究热点.这个课件主要目标是用一小时给领域初学者讲清楚基础知识和背景,当前的研究热点,以及重要的工作.更重要的是,该课件内附很多领域内数据.公开赛.算法的链接,以 ...
最新文章
- 滴滴哆啦A梦源码解析
- 百度健康打通医药电商服务
- 五大IT巨头 成立专利联盟
- 20非常有用的Java程序片段(3)
- Pug+Stylus+Bootstrap入门
- Delphi 打印杨辉三角
- Sql Server 2005 PIVOT的行列转换应用实例
- 壕!腾讯再公布股权激励:2.97万员工 人均49万港元
- Java面试那些事--可能会问的那些问题(中高级篇)
- Kafka 安装部署、集群启动、命令行操作 与 可视化工具 Kafka Tool
- 【水果识别】基于matlab GUI苹果质量检测及分级系统【含Matlab源码 519期】
- 固高运动控制卡学习8 --高速硬件捕获
- Sakai3白皮书(中文版)
- Java2048游戏源代码
- php文件上传管理系统,介绍14款实用的开源的PHP在线文档管理系统
- win8.1产品安装临时密钥
- xp此计算机无法连接到,XP系统无法连接到网络怎么办
- 字符串拼接用逗号隔开的四种方法
- 对标西湖大学?中国芯片首富捐资200亿办高校!地址选在了这里
- 音诺恒RK3568高性能智能商显安卓广告机主板解决方案
热门文章
- 对称加密,非对称加密详解
- 五大内存分区,堆与栈的区别
- linux sftp拷贝文件夹,Linux下sftp命令传输文件的例子
- [kafka]kafka术语白话
- python神经网络预测股价_用Python预测股票价格变化
- 解决phpStudy端口占用的问题
- 华为magic ui就是鸿蒙系统,Magic UI系统是什么?Magic UI和EMUI的区别
- 为Redmine的项目加上起止时间
- tif文件转为shp文件_从Tif文件转为shp文件(ArcMap,代码)、gdal打包问题
- SpringCloud项目No qualifying bean of type ‘×××Mapper‘ available:的错误解决