sql查询涵盖的时段_涵盖的主题
sql查询涵盖的时段
涵盖的主题: (Topics Covered:)
1. 什么是NLP? (1. What is NLP?)
- A changing field
不断变化的领域 - Resources
资源资源 - Tools
工具类 - Python libraries
Python库 - Example applications
应用范例 - Ethics issues
道德问题
2. 使用NMF和SVD进行主题建模 (2. Topic Modeling with NMF and SVD)
part-1part-2 (click to follow the link to article)
第1 部分,第2部分 (单击以跟随文章链接)
- Stop words, stemming, & lemmatization
停用词,词干和词形化 - Term-document matrix
术语文档矩阵 - Topic Frequency-Inverse Document Frequency (TF-IDF)
主题频率-逆文档频率(TF-IDF) - Singular Value Decomposition (SVD)
奇异值分解(SVD) - Non-negative Matrix Factorization (NMF)
非负矩阵分解(NMF) - Truncated SVD, Randomized SVD
截断SVD,随机SVD
3. 使用朴素贝叶斯,逻辑回归和ngram进行情感分类 (3. Sentiment classification with Naive Bayes, Logistic regression, and ngrams)
part -1(click to follow the link to article)
-1部分 (单击以跟随文章链接)
- Sparse matrix storage
稀疏矩阵存储 - Counters
专柜 - the fastai library
法斯特图书馆 - Naive Bayes
朴素贝叶斯 - Logistic regression
逻辑回归 - Ngrams
克 - Logistic regression with Naive Bayes features, with trigrams
具有朴素贝叶斯功能的逻辑回归,带有三字母组合
4.正则表达式(和重新访问令牌化) (4. Regex (and re-visiting tokenization))
5.语言建模和情感分类与深度学习 (5. Language modeling & sentiment classification with deep learning)
- Language model
语言模型 - Transfer learning
转移学习 - Sentiment classification
情感分类
6.使用RNN进行翻译 (6. Translation with RNNs)
- Review Embeddings
查看嵌入 - Bleu metric
蓝光指标 - Teacher Forcing
教师强迫 - Bidirectional
双向的 - Attention
注意
7.使用Transformer架构进行翻译 (7. Translation with the Transformer architecture)
- Transformer Model
变压器型号 - Multi-head attention
多头注意力 - Masking
掩蔽 - Label smoothing
标签平滑
8. NLP中的偏见与道德 (8. Bias & ethics in NLP)
- bias in word embeddings
词嵌入中的偏见 - types of bias
偏见类型 - attention economy
注意经济 - drowning in fraudulent/fake info
淹没在欺诈/虚假信息中
使用NMF和SVD进行主题建模:第2部分 (Topic Modeling with NMF and SVD : Part-2)
please find part-1 here: Topic Modeling with NMF and SVD
请在此处找到第1部分: 使用NMF和SVD进行主题建模
Let’s wrap up some loose ends from last time.
让我们从上次总结一些松散的结局。
两种文化 (The two cultures)
This “debate” captures the tension between two approaches:
这个“辩论”抓住了两种方法之间的张力:
- modeling the underlying mechanism of a phenomena
建模现象的潜在机制 - using machine learning to predict outputs (without necessarily understanding the mechanisms that create them)
使用机器学习来预测输出(不必了解创建它们的机制)
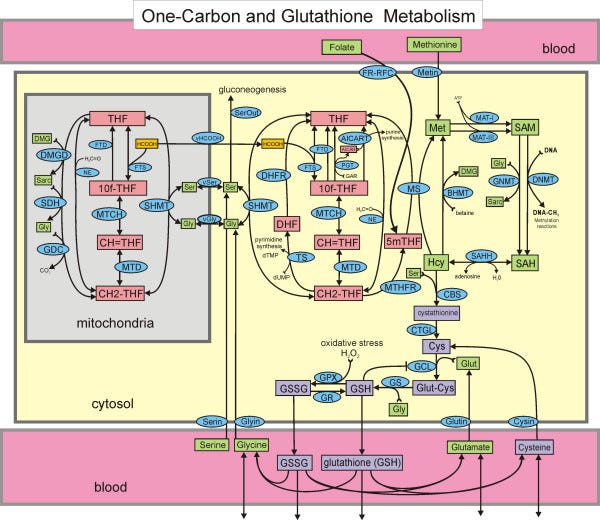
There was a research project (in 2007) that involved manually coding each of the above reactions. The scientist were determining if the final system could generate the same ouputs (in this case, levels in the blood of various substrates) as were observed in clinical studies.
有一个研究项目(2007年)涉及对上述每个React进行手动编码。 科学家正在确定最终系统是否可以产生与临床研究中观察到的相同的输出量(在这种情况下,是各种底物血液中的水平)。
The equation for each reaction could be quite complex:
每个React的方程式可能非常复杂:

This is an example of modeling the underlying mechanism, and is very different from a machine learning approach.Source: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2391141/
这是对基础机制进行建模的示例,与机器学习方法有很大不同。 资料来源: https : //www.ncbi.nlm.nih.gov/pmc/articles/PMC2391141/
每个州最受欢迎的单词 (The most popular word in each state)

A time to remove stop words
删除停用词的时间
因式分解与矩阵分解相似 (Factorization is analgous to matrix decomposition)
带整数 (With Integers)
Multiplication:
乘法:
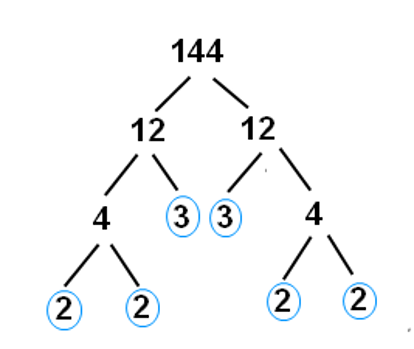
Factorization is the “opposite” of multiplication:Here, the factors have the nice property of being prime.Prime factorization is much harder than multiplication (which is good, because it’s the heart of encryption).
因子分解是乘法的“对立”:在这里,因子具有素数的优良特性。素因分解比乘法难得多(这很好,因为它是加密的核心)。
与矩阵 (With Matrices)
Matrix decompositions are a way of taking matrices apart (the “opposite” of matrix multiplication).Similarly, we use matrix decompositions to come up with matrices with nice properties.Taking matrices apart is harder than putting them together.
矩阵分解是将矩阵分开(矩阵乘法的“对面”)的一种方法。类似地,我们使用矩阵分解来得出具有良好属性的矩阵。将矩阵分开比将它们放在一起要困难。
One application:
一个应用程序 :

What are the nice properties that matrices in an SVD decomposition have?
SVD分解中的矩阵有哪些好的属性?
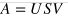
一些线性代数复习 (Some Linear Algebra Review)
矩阵向量乘法 (Matrix-vector multiplication)
takes a linear combination of the columns of A, using coefficients xhttp://matrixmultiplication.xyz/
使用系数x http://matrixmultiplication.xyz/对A列进行线性组合
矩阵矩阵乘法 (Matrix-matrix multiplication)
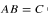
each column of C is a linear combination of columns of A, where the coefficients come from the corresponding column of C
C的每一列都是A的列的线性组合,其中系数来自C的对应列
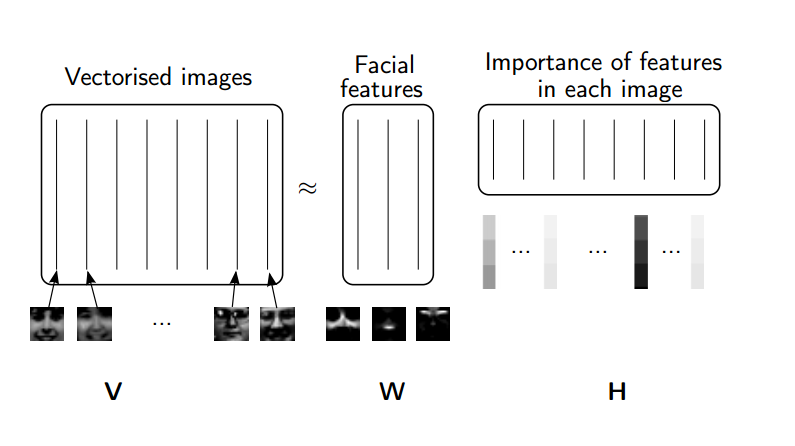
(来源: NMF教程 ) 矩阵作为变换 ((source: NMF Tutorial)Matrices as Transformations)
The 3Blue 1Brown Essence of Linear Algebra videos are fantastic. They give a much more visual & geometric perspective on linear algreba than how it is typically taught. These videos are a great resource if you are a linear algebra beginner, or feel uncomfortable or rusty with the material.
线性代数的3Blue 1Brown 本质视频非常棒。 他们对线性algreba的视觉和几何透视比通常讲授的要多得多。 如果您是线性代数初学者,或者对材料感到不舒服或生锈,这些视频将是一个很好的资源。
Even if you are a linear algrebra pro, I still recommend these videos for a new perspective, and they are very well made.
即使您是线性algrebra专业人士,我仍然建议您以新角度观看这些视频,而且它们的制作精良。
In [2]:
在[2]中:
from IPython.display import YouTubeVideoYouTubeVideo("kYB8IZa5AuE")Excel中的英国文学SVD和NMF (British Literature SVD & NMF in Excel)
Data was downloaded from here
数据从这里下载
The code below was used to create the matrices which are displayed in the SVD and NMF of British Literature excel workbook. The data is intended to be viewed in Excel, I’ve just included the code here for thoroughness.
下面的代码用于创建在英国文学excel工作簿的SVD和NMF中显示的矩阵。 数据打算在Excel中查看,为了完整起见,这里仅包含代码。
初始化,创建文档术语矩阵 (Initializing, create document-term matrix)
In [2]:
在[2]中:
import numpy as npfrom sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizerfrom sklearn import decompositionfrom glob import globimport osIn [3]:
在[3]中:
np.set_printoptions(suppress=True)In [46]:
在[46]中:
filenames = []for folder in ["british-fiction-corpus"]: #, "french-plays", "hugo-les-misérables"]: filenames.extend(glob("data/literature/" + folder + "/*.txt"))In [47]:
在[47]中:
len(filenames)Out[47]:
出[47]:
27In [134]:
在[134]中:
vectorizer = TfidfVectorizer(input='filename', stop_words='english')dtm = vectorizer.fit_transform(filenames).toarray()vocab = np.array(vectorizer.get_feature_names())dtm.shape, len(vocab)Out[134]:
出[134]:
((27, 55035), 55035)In [135]:
在[135]中:
[f.split("/")[3] for f in filenames]Out[135]:
出[135]:
['Sterne_Tristram.txt', 'Austen_Pride.txt', 'Thackeray_Pendennis.txt', 'ABronte_Agnes.txt', 'Austen_Sense.txt', 'Thackeray_Vanity.txt', 'Trollope_Barchester.txt', 'Fielding_Tom.txt', 'Dickens_Bleak.txt', 'Eliot_Mill.txt', 'EBronte_Wuthering.txt', 'Eliot_Middlemarch.txt', 'Fielding_Joseph.txt', 'ABronte_Tenant.txt', 'Austen_Emma.txt', 'Trollope_Prime.txt', 'CBronte_Villette.txt', 'CBronte_Jane.txt', 'Richardson_Clarissa.txt', 'CBronte_Professor.txt', 'Dickens_Hard.txt', 'Eliot_Adam.txt', 'Dickens_David.txt', 'Trollope_Phineas.txt', 'Richardson_Pamela.txt', 'Sterne_Sentimental.txt', 'Thackeray_Barry.txt']NMF (NMF)
In [136]:
在[136]中:
clf = decomposition.NMF(n_components=10, random_state=1)W1 = clf.fit_transform(dtm)H1 = clf.components_In [137]:
在[137]中:
num_top_words=8def show_topics(a): top_words = lambda t: [vocab[i] for i in np.argsort(t)[:-num_top_words-1:-1]] topic_words = ([top_words(t) for t in a])return [' '.join(t) for t in topic_words]In [138]:
在[138]中:
def get_all_topic_words(H): top_indices = lambda t: {i for i in np.argsort(t)[:-num_top_words-1:-1]} topic_indices = [top_indices(t) for t in H]return sorted(set.union(*topic_indices))In [139]:
在[139]中:
ind = get_all_topic_words(H1)In [140]:
在[140]中:
vocab[ind]Out[140]:
出[140]:
array(['adams', 'allworthy', 'bounderby', 'brandon', 'catherine', 'cathy', 'corporal', 'crawley', 'darcy', 'dashwood', 'did', 'earnshaw', 'edgar', 'elinor', 'emma', 'father', 'ferrars', 'finn', 'glegg', 'good', 'gradgrind', 'hareton', 'heathcliff', 'jennings', 'jones', 'joseph', 'know', 'lady', 'laura', 'like', 'linton', 'little', 'll', 'lopez', 'louisa', 'lyndon', 'maggie', 'man', 'marianne', 'miss', 'mr', 'mrs', 'old', 'osborne', 'pendennis', 'philip', 'phineas', 'quoth', 'said', 'sissy', 'sophia', 'sparsit', 'stephen', 'thought', 'time', 'tis', 'toby', 'tom', 'trim', 'tulliver', 'uncle', 'wakem', 'wharton', 'willoughby'], dtype='<U31')In [141]:
在[141]中:
show_topics(H1)Out[141]:
出[141]:
['mr said mrs miss emma darcy little know', 'said little like did time know thought good', 'adams jones said lady allworthy sophia joseph mr', 'elinor marianne dashwood jennings willoughby mrs brandon ferrars', 'maggie tulliver said tom glegg philip mr wakem', 'heathcliff linton hareton catherine earnshaw cathy edgar ll', 'toby said uncle father corporal quoth tis trim', 'phineas said mr lopez finn man wharton laura', 'said crawley lyndon pendennis old little osborne lady', 'bounderby gradgrind sparsit said mr sissy louisa stephen']In [142]:
在[142]中:
W1.shape, H1[:, ind].shapeOut[142]:
出[142]:
((27, 10), (10, 64))导出为CSV (Export to CSVs)
In [72]:
在[72]中:
from IPython.display import FileLink, FileLinksIn [119]:
在[119]中:
np.savetxt("britlit_W.csv", W1, delimiter=",", fmt='%.14f')FileLink('britlit_W.csv')Out[119]:
出[119]:
britlit_W.csv
britlit_W.csv
In [120]:
在[120]中:
np.savetxt("britlit_H.csv", H1[:,ind], delimiter=",", fmt='%.14f')FileLink('britlit_H.csv')Out[120]:
出[120]:
britlit_H.csv
britlit_H.csv
In [131]:
在[131]中:
np.savetxt("britlit_raw.csv", dtm[:,ind], delimiter=",", fmt='%.14f')FileLink('britlit_raw.csv')Out[131]:
出[131]:
britlit_raw.csv
britlit_raw.csv
In [121]:
在[121]中:
[str(word) for word in vocab[ind]]Out[121]:
出[121]:
['adams', 'allworthy', 'bounderby', 'brandon', 'catherine', 'cathy', 'corporal', 'crawley', 'darcy', 'dashwood', 'did', 'earnshaw', 'edgar', 'elinor', 'emma', 'father', 'ferrars', 'finn', 'glegg', 'good', 'gradgrind', 'hareton', 'heathcliff', 'jennings', 'jones', 'joseph', 'know', 'lady', 'laura', 'like', 'linton', 'little', 'll', 'lopez', 'louisa', 'lyndon', 'maggie', 'man', 'marianne', 'miss', 'mr', 'mrs', 'old', 'osborne', 'pendennis', 'philip', 'phineas', 'quoth', 'said', 'sissy', 'sophia', 'sparsit', 'stephen', 'thought', 'time', 'tis', 'toby', 'tom', 'trim', 'tulliver', 'uncle', 'wakem', 'wharton', 'willoughby']SVD (SVD)
In [143]:
在[143]中:
U, s, V = decomposition.randomized_svd(dtm, 10)In [144]:
在[144]中:
ind = get_all_topic_words(V)In [145]:
在[145]中:
len(ind)Out[145]:
出[145]:
52In [146]:
在[146]中:
vocab[ind]Out[146]:
出[146]:
array(['adams', 'allworthy', 'bounderby', 'bretton', 'catherine', 'crimsworth', 'darcy', 'dashwood', 'did', 'elinor', 'elton', 'emma', 'finn', 'fleur', 'glegg', 'good', 'gradgrind', 'hareton', 'hath', 'heathcliff', 'hunsden', 'jennings', 'jones', 'joseph', 'knightley', 'know', 'lady', 'linton', 'little', 'lopez', 'louisa', 'lydgate', 'madame', 'maggie', 'man', 'marianne', 'miss', 'monsieur', 'mr', 'mrs', 'pelet', 'philip', 'phineas', 'said', 'sissy', 'sophia', 'sparsit', 'toby', 'tom', 'tulliver', 'uncle', 'weston'], dtype='<U31')In [147]:
在[147]中:
show_topics(H1)Out[147]:
出[147]:
['mr said mrs miss emma darcy little know', 'said little like did time know thought good', 'adams jones said lady allworthy sophia joseph mr', 'elinor marianne dashwood jennings willoughby mrs brandon ferrars', 'maggie tulliver said tom glegg philip mr wakem', 'heathcliff linton hareton catherine earnshaw cathy edgar ll', 'toby said uncle father corporal quoth tis trim', 'phineas said mr lopez finn man wharton laura', 'said crawley lyndon pendennis old little osborne lady', 'bounderby gradgrind sparsit said mr sissy louisa stephen']In [148]:
在[148]中:
np.savetxt("britlit_U.csv", U, delimiter=",", fmt='%.14f')FileLink('britlit_U.csv')Out[148]:
出[148]:
britlit_U.csv
britlit_U.csv
In [149]:
在[149]中:
np.savetxt("britlit_V.csv", V[:,ind], delimiter=",", fmt='%.14f')FileLink('britlit_V.csv')Out[149]:
出[149]:
britlit_V.csv
britlit_V.csv
In [150]:
在[150]中:
np.savetxt("britlit_raw_svd.csv", dtm[:,ind], delimiter=",", fmt='%.14f')FileLink('britlit_raw_svd.csv')Out[150]:
出[150]:
britlit_raw_svd.csv
britlit_raw_svd.csv
In [151]:
在[151]中:
np.savetxt("britlit_S.csv", np.diag(s), delimiter=",", fmt='%.14f')FileLink('britlit_S.csv')Out[151]:
出[151]:
britlit_S.csv
britlit_S.csv
In [152]:
在[152]中:
[str(word) for word in vocab[ind]]Out[152]:
出[152]:
['adams', 'allworthy', 'bounderby', 'bretton', 'catherine', 'crimsworth', 'darcy', 'dashwood', 'did', 'elinor', 'elton', 'emma', 'finn', 'fleur', 'glegg', 'good', 'gradgrind', 'hareton', 'hath', 'heathcliff', 'hunsden', 'jennings', 'jones', 'joseph', 'knightley', 'know', 'lady', 'linton', 'little', 'lopez', 'louisa', 'lydgate', 'madame', 'maggie', 'man', 'marianne', 'miss', 'monsieur', 'mr', 'mrs', 'pelet', 'philip', 'phineas', 'said', 'sissy', 'sophia', 'sparsit', 'toby', 'tom', 'tulliver', 'uncle', 'weston']随机SVD可加快速度 (Randomized SVD offers a speed up)
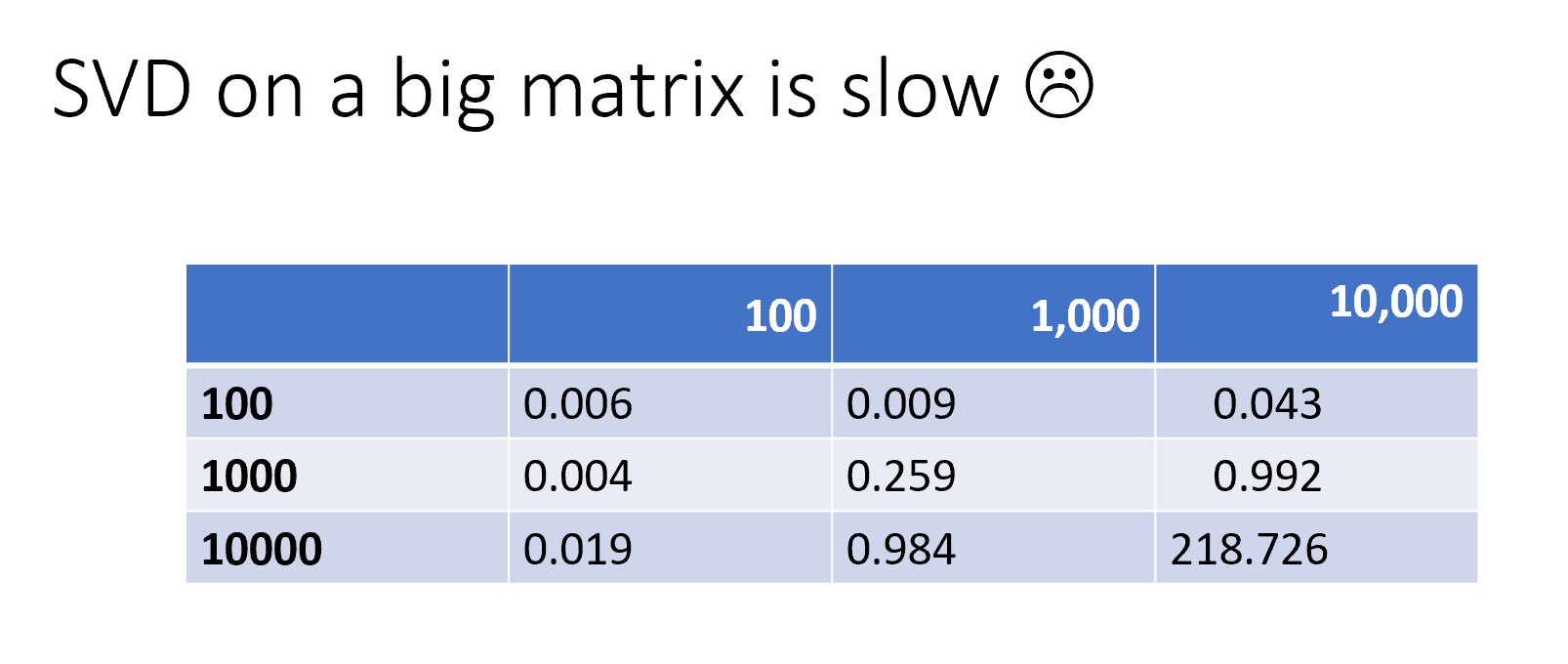
One way to address this is to use randomized SVD. In the below chart, the error is the difference between A — U S V, that is, what you’ve failed to capture in your decomposition:
解决此问题的一种方法是使用随机SVD。 在下图中,错误是A — U S V之间的差,即您在分解中未能捕获的内容:
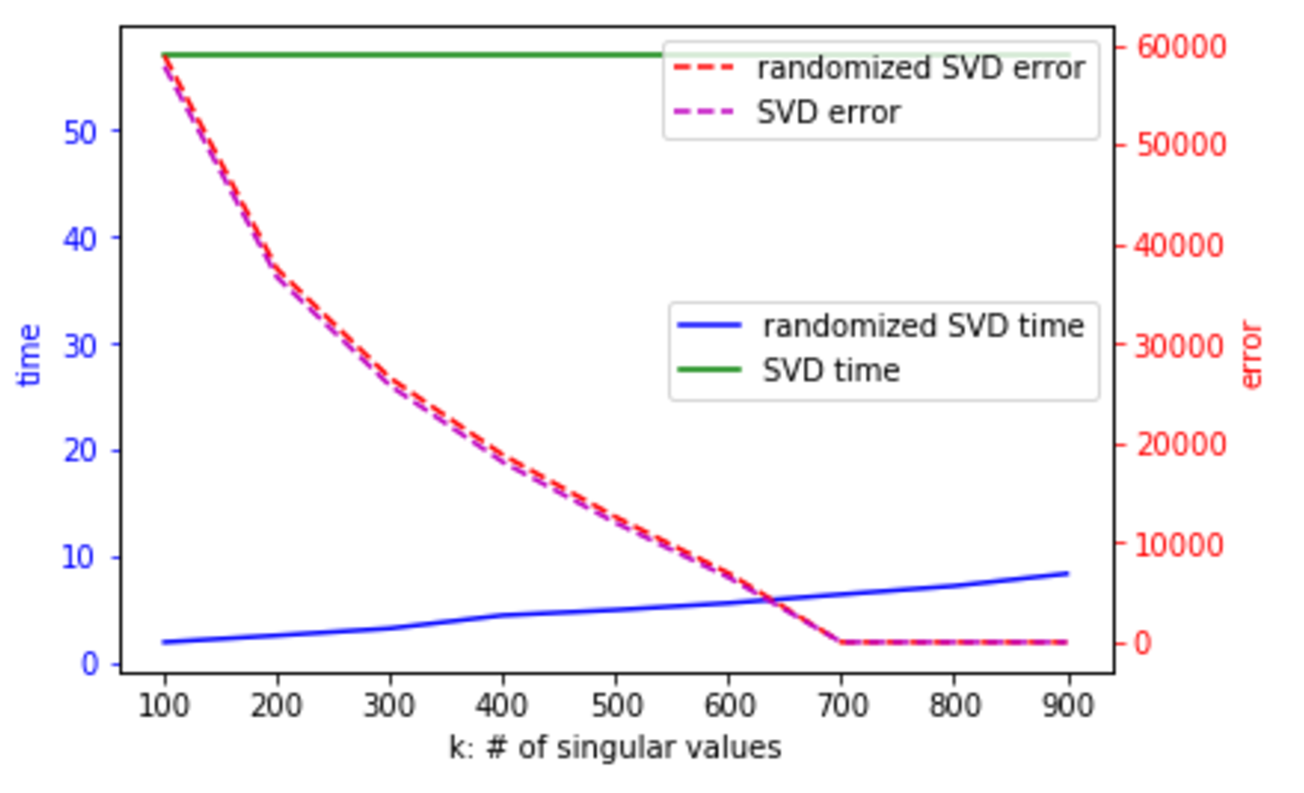
For more on randomized SVD, check out my PyBay 2017 talk.For significantly more on randomized SVD, check out the Computational Linear Algebra course.
有关随机SVD的更多信息,请查看我的PyBay 2017演讲 。有关随机SVD的更多信息,请查看计算线性代数课程 。
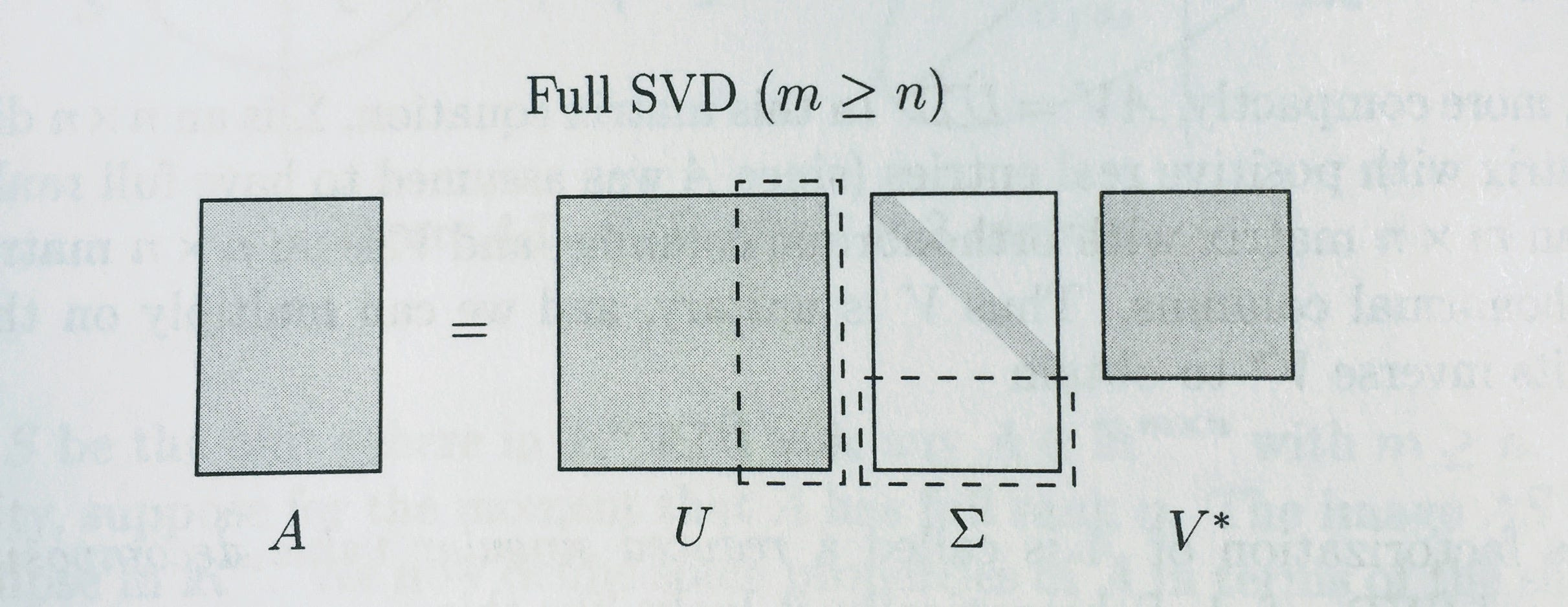
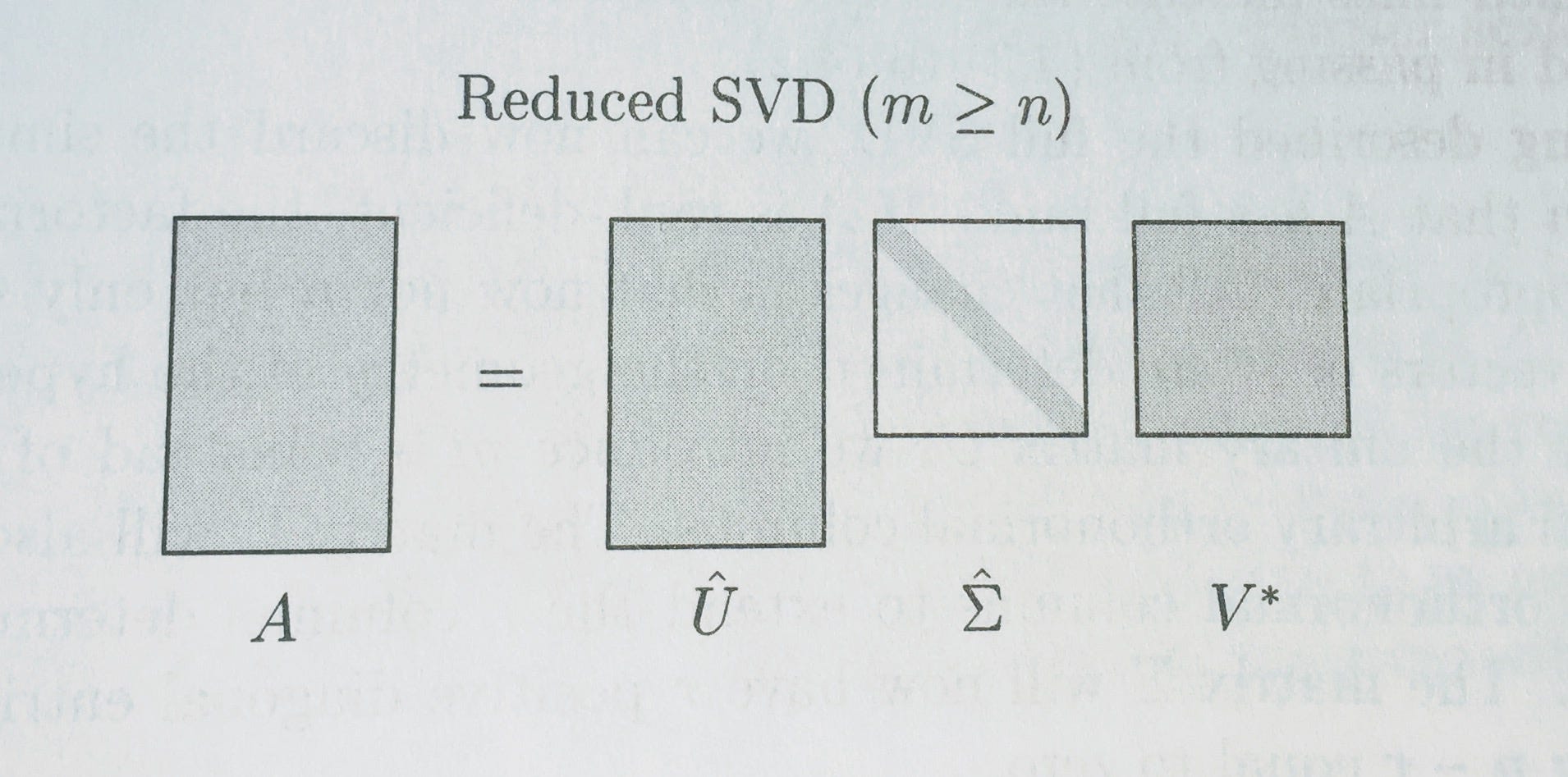
完整与精简SVD (Full vs Reduced SVD)
Remember how we were calling np.linalg.svd(vectors, full_matrices=False)? We set full_matrices=False to calculate the reduced SVD. For the full SVD, both U and V are square matrices, where the extra columns in U form an orthonormal basis (but zero out when multiplied by extra rows of zeros in S).
还记得我们如何调用np.linalg.svd(vectors, full_matrices=False)吗? 我们设置full_matrices=False来计算简化的SVD。 对于完整的SVD,U和V均为平方矩阵,其中U中的额外列构成正交基(但与S中的额外零行相乘则为零)。
Diagrams from Trefethen:
来自Trefethen的图表:
结束 (End)
学分: (Credits:)
https://www.fast.ai/
https://www.fast.ai/
翻译自: https://medium.com/ai-in-plain-english/topics-covered-7feba459180f
sql查询涵盖的时段
相关文章:
- 一起来学C++:C++中的代码重用
- 【实例】Python tkinter 实例 桌面便签
- 相对路径和绝对路径
- Matlab GUI编程技巧(十):ui figure函数创建可视化图窗
- Flutter Container 组件
- 欧拉回路
- nyoj42一笔画问题 【欧拉回路】
- 达梦数据库一些疑难杂症的解决
- python生成统计图_用python Linux(无GUI)中生成统计图
- 第一性原理计算软件FLEUR: The Jülich FLAPW code family
- Tableau数据合并
- STATA学习笔记:数据合并
- 数据分析--数据合并
- 一文搞定pandas的数据合并
- pandas如何合并列表_Pandas数据合并与拼接的5种方法
- mysql如何重复数据合并_mysql合并重复数据
- c# datatable数据合并方法
- 【Python数据分析】之数据合并的concat函数与merge函数
- 一文搞定Pandas中的数据合并
- MySQL将多条数据合并成一条
- R语言数据合并
- Python数据分析之数据预处理(数据清洗、数据合并、数据重塑、数据转换)学习笔记
- SAS:数据合并简介
- python DataFrame数据合并 merge()、concat()方法
- 【python数据分析】pandas数据合并
- 图解pandas的数据合并merge
- 这或许是全网最全 Python dataframe 数据合并方法汇总
- GeoJson数据合并
- matlab函数merge_MATLAB数据合并方法
- Java实现多条相同数据合并为一条数据
sql查询涵盖的时段_涵盖的主题相关推荐
- sql 查询超时已过期_监视来自SQL Server代理作业的查询超时过期消息
sql 查询超时已过期 SQL Server provides you with a good solution to automate a lot of your administrative ta ...
- sql 查询数据库索引重建_不良的数据库索引– SQL查询性能的杀手–建议
sql 查询数据库索引重建 previous article, we explained what clustered and nonclustered indexes were, and showe ...
- sql查询前50条_您必须知道的前50条SQL查询
sql查询前50条 In this article, we'll go over the most common SQL queries that you should know to be able ...
- 用sql查询姓名和身份证_查询,更新和身份
在本系列的第一篇文章中,我讨论了RDBMS作为Java™对象存储解决方案的失败. 正如我所解释的那样,在当今的面向对象的世界中,像db4o这样的对象数据库可以为面向对象的开发人员提供更多的功能,而不仅 ...
- sql 查询上个月的数据_数据分析-SQL 进阶篇 多表查询
知识点 一.表的加法 Union:删除表中的重复值 union al:包含表中所有内容,包括重复值 二.表的联结 联结:join 联结分为以下五种: 交叉联结(cross join)又称为笛卡尔积:将 ...
- sql查询mysql参数配置_查询参数配置
示例 请求示例 http(s)://rds.aliyuncs.com/?Action=DescribeParameters &DBInstanceId=rm-uf6wjk5xxxxxxx &a ...
- python查询sqlserver视图_基于odoo11上的SQL查询构建一个新的视图或模型
我正在研究一个奥多模块.在 我希望我的模块是一个"报告"大多数购买的产品(按客户).在 我已经在Odoo上创建了一个视图,但是现在,我需要按客户"过滤"这些视图 ...
- 怎么让sql查询的字段可以不出现在group分组里_在工作中常用到的SQL
这篇文章来记录一下我曾经忘掉的group查询.join查询等一些比较实用/常用的SQL 本文主打通俗易懂,不涵盖任何优化(适合新手观看) 一.回顾group 查询 group查询就是分组查询,为什么要 ...
- oracle function 写查询语句_五个 SQL 查询性能测试题,只有 40% 及格率,你敢来挑战吗?...
作者 | 董旭阳TonyDong,CSDN 博客专家 责编 | 唐小引 头图 | CSDN 下载自东方 IC 出品 | CSDN 博客 下面是 5 个关于索引和 SQL 查询性能的测试题:其中 4 个 ...
最新文章
- aaaaaaaaaaa
- [deviceone开发]-do_Dialog的基本使用示例
- 我的Linux随笔目录
- aMCMC for Horseshoe: algorithms
- 1、MySQL 8.0.20最新版本在Linux上安装
- Java GC日志查看和分析
- 实例34:python
- Matlab绘图添加直角坐标轴
- 计算机机房的安全等级分,计算机机房安全等级的划分标准是什么
- Java8新特性之Lambda
- Ubuntu18.04 下联想电脑 无法连接WIFI问题解决
- SpringCache实战遇坑
- linux操作系统命令及流程图,计算机操作系统与简单命令
- 大三狗重新复习算法之递推
- c语言中实现字符串的大小的比较_C语言 | 函数实现比大小
- Java网络爬虫全面教程
- 俱乐部2006年的首次活动-ASP.NET Webpart 开发交流会暨2005回顾
- [转]机器视觉代码大全
- 二维插值-MATLAB
- 黑暗背景(所有暗主题cobalt,dracula...)Rstudio查看对象窗口viewer没有滚动条,白亮背景就有(所有白主题chrome,cloud)。R版本[64-bit] R-3.6.0