Python大数据:jieba分词,词频统计
实验目的
- 学习如何读取一个文件
- 学习如何使用DataFrame
- 学习jieba中文分词组件及停用词处理原理
- 了解Jupyter Notebook
概念
中文分词
在自然语言处理过程中,为了能更好地处理句子,往往需要把句子拆开分成一个一个的词语,这样能更好的分析句子的特性,这个过程叫就叫做分词。由于中文句子不像英文那样天然自带分隔,并且存在各种各样的词组,从而使中文分词具有一定的难度。
不过,中文分词并不追求完美,而是通过关键字识别技术,抽取句子中最关键的部分,从而达到理解句子的目的。
工具
Jupyter Notebook
Jupyter Notebook是一个交互式的笔记本工具,重点有两点
- “交互式” 让你随时随时运行并暂存结果,
- “笔记本” 记录你的研究过程
想象一下,在这之前你是如何使用Python的?
- 用一切可能的文本编辑工具编写代码
- 然后运行python xxx.py调试
- 当你写了一个9W条数据的处理程序之后,跑到一半报个错,又得重头开始
- 画图基本靠脑补
有了JN之后,你可以:
- 直接在网页上编写代码
- 按Shift + Enter立即执行当前Cell的代码段
- Cell执行后的变量仍然生存,可以在下一个Cell继续使用,所以,我用第一个Cell加载9W条数据,第二个Cell开始预处理,第三个Cell进行运算等等
- 直接在网页上画出图片,即时调整参数Shift+Enter预览,麻麻再也不用担心我写错代码,美滋滋 ~~~
jieba
jieba模块安装请参见官方说明
jieba 是一个python实现的中文分词组件,在中文分词界非常出名,支持简、繁体中文,高级用户还可以加入自定义词典以提高分词的准确率。
它支持三种分词模式
- 精确模式:试图将句子最精确地切开,适合文本分析;
- 全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
另外它还自带有关键词摘取算法。
- 基于 TF-IDF 算法的关键词抽取
- 基于 TextRank 算法的关键词抽取
pandas
pandas 是基于NumPy 的大数据处理工具,基本数据结构有(二维表)DataFrame,(一维数组)Series。
本次实验中,我们主要使用pandas的DataFrame,加载、保存csv数据源,处理数组进行去重、统计。
数据
实验数据为百度随意打开的新闻,请读者自行按下表格式准备
| id | title | content |
|---|---|---|
| 1 | 文章标题 | 文章内容 |
| 2 | 文章标题 | 文章内容 |
| 3 | 文章标题 | 文章内容 |

思路(伪代码)
- 读取数据源
- 加载停用词库
- 循环对每一篇文章进行分词
- 普通分词,需要手工进行停用词过滤
- TF-IDF关键词抽取,需要使用停用词库
- textrank关键词抽取,只取指定词性的关键词
- 对结果进行词频统计
- 输出结果到csv文件
实验代码
第一行将代码标记为utf-8编码,避免出现处理非ascii字符时的错误
# -*- coding: UTF-8 -*-
载入需要用到的模块,as是给模块取个别名,输入的时候不用输那么长的单词。
嗯,反正你别问我为什么不给jieba取别名
import numpy as np
import pandas as pd
import jieba
import jieba.analyse
import codecs
默认情况下,pd显示的文本长度为50,超出部分显示为省略号,我们修改一下,以方便观察数据(文章内容)
#设置pd的显示长度
pd.set_option('max_colwidth',500)
读取我们的实验数据,将所有列设置为string,编码指定utf-8,第一行为列头
#载入数据
rows=pd.read_csv('datas1.csv', header=0,encoding='utf-8',dtype=str)
我们直接在下一个Cell中输入变量rows,观察载入的结果
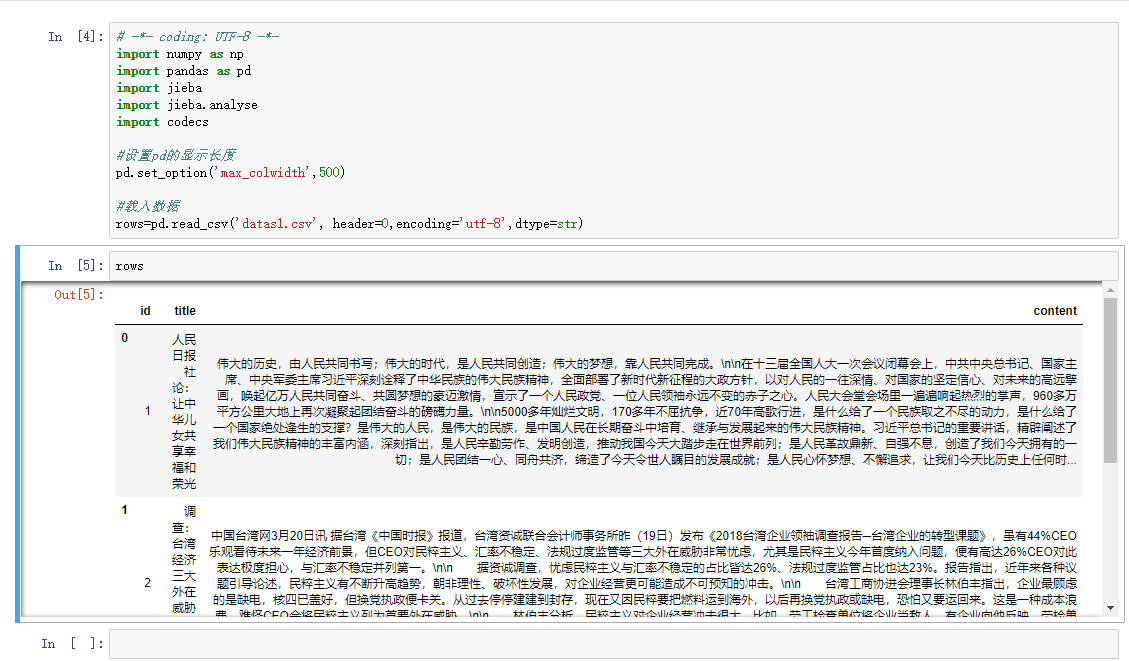
对于普通分词,我们需要将停用词载入到一个数组中,在分词后逐一比较关键词是否为停用词
stopwords = [line.strip() for line in codecs.open('stoped.txt', 'r', 'utf-8').readlines()] 对于TF-IDF,我们只需要告诉组件停用词库,它将自己载入词库并使用它
#载入停用词
jieba.analyse.set_stop_words('stoped.txt')
接下来我们就要对所有文章进行分词了,先声明一个数组,用于保存分词后的关键字,此数组每行保存一个关键字对象。
关键字对象有两个属性:
- word: 关键字本身
- count : 永远为1,用于后面统计词频
# 保存全局分词,用于词频统计
segments = []
普通分词及停用词判断
for index, row in rows.iterrows():content = row[2]#TextRank 关键词抽取,只获取固定词性words = jieba.cut(content)splitedStr = ''for word in words:#停用词判断,如果当前的关键词不在停用词库中才进行记录if word not in stopwords:# 记录全局分词segments.append({'word':word, 'count':1})splitedStr += word + ' '
Text Rank 关键词抽取
for index, row in rows.iterrows():content = row[2]#TextRank 关键词抽取,只获取固定词性words = jieba.analyse.textrank(content, topK=20,withWeight=False,allowPOS=('ns', 'n', 'vn', 'v'))splitedStr = ''for word in words:# 记录全局分词segments.append({'word':word, 'count':1})splitedStr += word + ' '
观察分词后的关键字,发现全是utf-8编码后的文字,暂时不管,我们先将这个数组转换为DataFrame对象,调用groupby方法和sum方法进行统计汇总。
# 将结果数组转为df序列
dfSg = pd.DataFrame(segments)# 词频统计
dfWord = dfSg.groupby('word')['count'].sum()
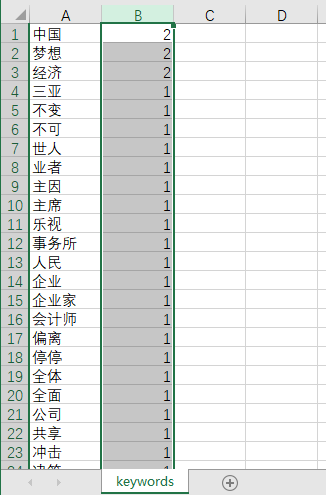
输出结果
#导出csv
dfWord.to_csv('keywords.csv',encoding='utf-8')
完整代码
# -*- coding: UTF-8 -*-
import numpy as np
import pandas as pd
import jieba
import jieba.analyse
import codecs#设置pd的显示长度
pd.set_option('max_colwidth',500)#载入数据
rows=pd.read_csv('datas1.csv', header=0,encoding='utf-8',dtype=str)segments = []
for index, row in rows.iterrows():content = row[2]#TextRank 关键词抽取,只获取固定词性words = jieba.analyse.textrank(content, topK=50,withWeight=False,allowPOS=('ns', 'n', 'vn', 'v'))splitedStr = ''for word in words:# 记录全局分词segments.append({'word':word, 'count':1})splitedStr += word + ' '
dfSg = pd.DataFrame(segments)# 词频统计
dfWord = dfSg.groupby('word')['count'].sum()
#导出csv
dfWord.to_csv('keywords.csv',encoding='utf-8')
总结
分词算法
本次实验,我们学习了如何使用jieba模块进行中文分词与关键字提取,结果各有千秋:
- 普通分词:需要手工过滤停用词、无意义词、电话号码、符号等,但能较为全面的保留所有关键字。
- TF-IDF:停用词过滤有限,也需要手工处理部分数字、符号;它通过词频抽取关键字,对同一篇文章的词频统计不具有统计意义,多用于宏观上的观测。
- Text Rank: 大概效果同TF-IDF,通过限定词性过滤无关字符,能得到较为工整的关键字结果。
结论
总之,我们应根据我们的目标去选择适当的分词方法。
- 对某一篇文章进行关键字Map,我们选择普通分词,并自行过滤关键词,或添加自定义词库。
- 对采集的一批样本进行关键字分析,我们可以选择TF-IDF,对所有的关键字进行词频统计,并绘制出关键字云图。
- 如果我们要分析一批样本中用户的分类,用户的行为,用户的目的,我们可以选择TextRank抽取指定词性的关键字进行统计分析。
引用
jieba 开源仓库 https://github.com/fxsjy/jieba
下期预告
Python大数据:商品评论的情感倾向分析
Python大数据:jieba分词,词频统计相关推荐
- 大数据技术——MapReduce词频统计
注:参考林子雨老师教程,具体请见 MapReduce编程实践(Hadoop3.1.3)_厦大数据库实验室博客 一.实验目的 1.理解Hadoop中MapReduce模块的处理逻辑。 2.熟悉MapRe ...
- python分词统计词频_python jieba分词并统计词频后输出结果到Excel和txt文档方法
前两天,班上同学写论文,需要将很多篇论文题目按照中文的习惯分词并统计每个词出现的频率. 让我帮她实现这个功能,我在网上查了之后发现jieba这个库还挺不错的. 运行环境: 安装python2.7.13 ...
- Hadoop的改进实验(中文分词词频统计及英文词频统计)(1/4)
声明: 1)本文由我bitpeach原创撰写,转载时请注明出处,侵权必究. 2)本小实验工作环境为Windows系统下的百度云(联网),和Ubuntu系统的hadoop1-2-1(自己提前配好).如不 ...
- [转载] Python大数据文本分析及应用
参考链接: 使用Python的SQL 3(处理大数据) 实践课题报告: 大数据文本分析与应用 学 校:xxx 学 院:大数据与智能工程学院 专 业:信息工程(数据科学与大数据技术) 年 级:2017级 ...
- Python大数据综合应用 :零基础入门机器学习、深度学习算法原理与案例
机器学习.深度学习算法原理与案例实现暨Python大数据综合应用高级研修班 一.课程简介 课程强调动手操作:内容以代码落地为主,以理论讲解为根,以公式推导为辅.共4天8节,讲解机器学习和深度学习的模型 ...
- python-中文分词词频统计
本文主要内容是进行一次中文词频统计.涉及内容包括多种模式下的分词比较和分词词性功能展示. 本次使用的是python的jieba库.该库可在命令提示符下,直接输入pip install jieba进 ...
- Python+大数据-Spark技术栈(二)SparkBaseCore
Python+大数据-Spark技术栈(二)SparkBase&Core 学习目标 掌握SparkOnYarn搭建 掌握RDD的基础创建及相关算子操作 了解PySpark的架构及角色 环境搭建 ...
- Hadoop的改进实验(中文分词词频统计及英文词频统计)(4/4)
声明: 1)本文由我bitpeach原创撰写,转载时请注明出处,侵权必究. 2)本小实验工作环境为Windows系统下的百度云(联网),和Ubuntu系统的hadoop1-2-1(自己提前配好).如不 ...
- NLP算法-基于 Jieba 的词频统计
基于 Jieba 的词频统计 什么是词频统计 基于Jieba的词频统计 1.分词器 2.分词后的统计 测试说明 demo 什么是词频统计 在一份给定的文件里,词频(term frequency,TF) ...
最新文章
- 还在用分页?太Low !试试 MyBatis 流式查询,真心强大!
- sql中的三元运算符
- OpenCV极线epipolar lines的实例(附完整代码)
- android判断银行卡号格式不正确的是什么意思,android银行卡号验证算法详解
- 分布式事物(2PC,3PC,CAP,柔性与刚性事物,LCN)
- ssh excel 导入 mysql_ssh poi解析excel并将数据存入数据库
- 持续畅销20年的《C#高级编程》出第11版了!
- angular 权限 php,PHP,Angular,HTACCESS-仅允许来自源域的请求
- js实现表单checkbox的单选,全选
- Springboot2 搭建 高性能Websocket服务器
- 启动不起来_电脑启动不起来该怎么办
- 【linux基础】linux更改python默认版本
- Java线程并发与安全性问题详解
- 原型工具MockingBot 墨刀
- GitHub中的神奇开源,汇聚天涯神贴讨论房价涨跌,买房好帮手!
- ubuntu无法关机,卡在黑屏界面
- C#实现简单点餐系统
- 【小程序】promise在小程序中的运用
- Order By 排序
- word2016 明明设置了默认粘贴为“仅保留文本”,可是每次粘贴的时候还是带源格式怎么办?