Python+大数据-Spark技术栈(二)SparkBaseCore
Python+大数据-Spark技术栈(二)SparkBase&Core
- 学习目标
- 掌握SparkOnYarn搭建
- 掌握RDD的基础创建及相关算子操作
- 了解PySpark的架构及角色
环境搭建-Spark on YARN
- Yarn 资源调度框架,提供如何基于RM,NM,Continer资源调度
- Yarn可以替换Standalone结构中Master和Worker来使用RM和NM来申请资源
SparkOnYarn本质
- Spark计算任务通过Yarn申请资源,SparkOnYarn
- 将pyspark文件,经过Py4J(Python for java)转换,提交到Yarn的JVM中去运行
修改配置
思考,如何搭建SparkOnYarn环境?
1-需要让Spark知道Yarn(yarn-site.xml)在哪里?
在哪个文件下面更改?spark-env.sh中增加YARN_CONF_DIR的配置目录
2-修改Yan-site.xml配置,管理内存检查,历史日志服务器等其他操作
修改配置文件
3-需要配置历史日志服务器
需要实现功能:提交到Yarn的Job可以查看19888的历史日志服务器可以跳转到18080的日志服务器上
因为19888端口无法查看具体spark的executor后driver的信息,所以搭建历史日志服务器跳转
3-需要准备SparkOnYarn的需要Jar包,配置在配置文件中
在spark-default.conf中设置spark和yarn映射的jar包文件夹(hdfs)
注意,在最终执行sparkonyarn的job的时候一定重启Hadoop集群,因为更改相关yarn配置
4-执行SparkOnYarn
这里并不能提供交互式界面,只有spark-submit(提交任务)
#基于SparkOnyarn提交任务 bin/spark-submit \ --master yarn \ /export/server/spark/examples/src/main/python/pi.py \ 10
小结
SparKOnYarn:使用Yarn提供了资源的调度和管理工作,真正执行计算的时候Spark本身
Master和Worker的结构是Spark Standalone结构 使用Master申请资源,真正申请到是Worker节点的Executor的Tasks线程
原来Master现在Yarn替换成ResourceManager,现在Yarn是Driver给ResourceManager申请资源
原来Worker现在Yarn替换为Nodemanager,最终提供资源的地方时hiNodeManager的Continer容器中的tasks
安装配置:
1-让spark知道yarn的位置
2-更改yarn的配置,这里需要开启历史日志服务器和管理内存检查
3-整合Spark的历史日志服务器和Hadoop的历史日志服务器,效果:通过8088的yarn的http://node1:8088/cluster跳转到18080的spark的historyserver上
4-SparkOnYarn需要将Spark的jars目录下的jar包传递到hdfs上,并且配置spark-default.conf让yarn知晓配置
5-测试,仅仅更换–master yarn
部署模式
#如果启动driver程序是在本地,称之为client客户端模式,现象:能够在client端看到结果
#如果在集群模式中的一台worker节点上启动driver,称之为cluser集群模式,现象:在client端看不到结果
client
首先 client客户端提交spark-submit任务,其中spark-submit指定–master资源,指定–deploy-mode模式
由启动在client端的Driver申请资源,
交由Master申请可用Worker节点的Executor中的Task线程
一旦申请到Task线程,将资源列表返回到Driver端
Driver获取到资源后执行计算,执行完计算后结果返回到Driver端
由于Drivr启动在client端的,能够直接看到结果
实验:
#基于Standalone的脚本—部署模式client
#driver申请作业的资源,会向–master集群资源管理器申请
#执行计算的过程在worker中,一个worker有很多executor(进程),一个executor下面有很多task(线程)
bin/spark-submit
–master spark://node1:7077
–deploy-mode client
–driver-memory 512m
–executor-memory 512m
/export/server/spark/examples/src/main/python/pi.py
10
cluster
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LSRjAKIC-1667918253373)(3-SparkBase-基础2.assets/image-20210910114736875.png)]
首先 client客户端提交spark-submit任务,其中spark-submit指定–master资源,指定–deploy-mode模式
由于指定cluster模式,driver启动在worker节点上
由driver申请资源,由Master返回worker可用资源列表
由Driver获取到资源执行后续计算
执行完计算的结果返回到Driver端,
由于Driver没有启动在客户端client端,在client看不到结果
如何查看数据结果?
需要在日志服务器上查看,演示
实验:
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit
–master spark://node1.itcast.cn:7077,node2.itcast.cn:7077
–deploy-mode cluster
–driver-memory 512m
–executor-memory 512m
–num-executors 1
–total-executor-cores 2
–conf “spark.pyspark.driver.python=/root/anaconda3/bin/python3”
–conf “spark.pyspark.python=/root/anaconda3/bin/python3”
${SPARK_HOME}/examples/src/main/python/pi.py
10* 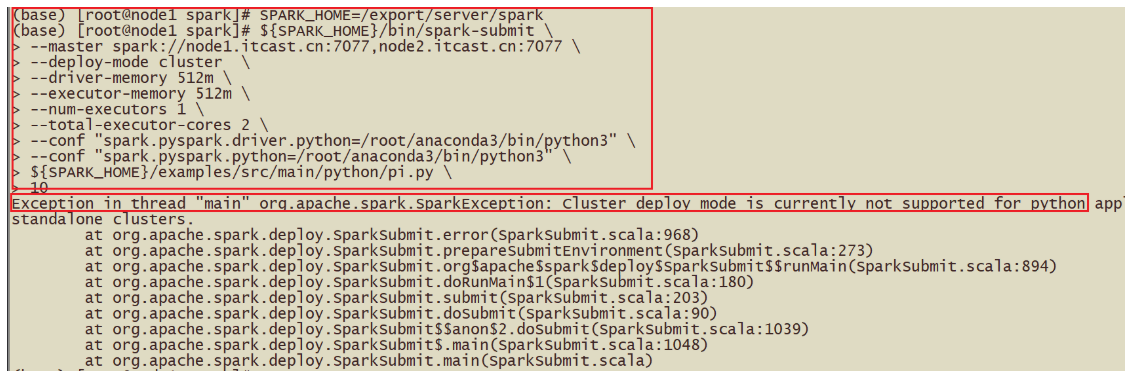
- 注意事项:

- 通过firstpyspark.py写的wordcount的代码,最终也是转化为spark-submit任务提交
- 如果是spark-shell中的代码最终也会转化为spark-submit的执行脚本
- 在Spark-Submit中可以提交driver的内存和cpu,executor的内存和cpu,–deploy-mode部署模式
Spark On Yarn两种模式
Spark on Yarn两种模式
–deploy-mode client和cluster
Yarn的回顾:Driver------AppMaster------RM-----NodeManager—Continer----Task
client模式
#deploy-mode的结构
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit
–master yarn
–deploy-mode client
–driver-memory 512m
–driver-cores 2
–executor-memory 512m
–executor-cores 1
–num-executors 2
–queue default
${SPARK_HOME}/examples/src/main/python/pi.py
10#瘦身 SPARK_HOME=/export/server/spark ${SPARK_HOME}/bin/spark-submit \ --master yarn \ --deploy-mode client \ ${SPARK_HOME}/examples/src/main/python/pi.py \ 10
原理:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QBsqHZYs-1667918253381)(3-SparkBase-基础2.assets/image-20210910151817226.png)]
1-启动Driver
2-由Driver向RM申请启动APpMaster
3-由RM指定NM启动AppMaster
4-AppMaster应用管理器申请启动Executor(资源的封装,CPU,内存)
5-由AppMaster指定启动NodeManager启动Executor
6-启动Executor进程,获取任务计算所需的资源
7-将获取的资源反向注册到Driver
由于Driver启动在Client客户端(本地),在Client端就可以看到结果3.1415
8-Driver负责Job和Stage的划分[了解]
1-执行到Action操作的时候会触发Job,不如take
2-接下来通过DAGscheduler划分Job为Stages,为每个stage创建task
3-接下来通过TaskScheduler将每个Stage的task分配到每个executor去执行
4-结果返回到Driver端,得到结果
cluster:
作业:
${SPARK_HOME}/bin/spark-submit
–master yarn
–deploy-mode cluster
–driver-memory 512m
–executor-memory 512m
–executor-cores 1
–num-executors 2
–queue default
–conf “spark.pyspark.driver.python=/root/anaconda3/bin/python3”
–conf “spark.pyspark.python=/root/anaconda3/bin/python3”
${SPARK_HOME}/examples/src/main/python/pi.py
10
#瘦身
${SPARK_HOME}/bin/spark-submit
–master yarn
–deploy-mode cluster
${SPARK_HOME}/examples/src/main/python/pi.py
10* 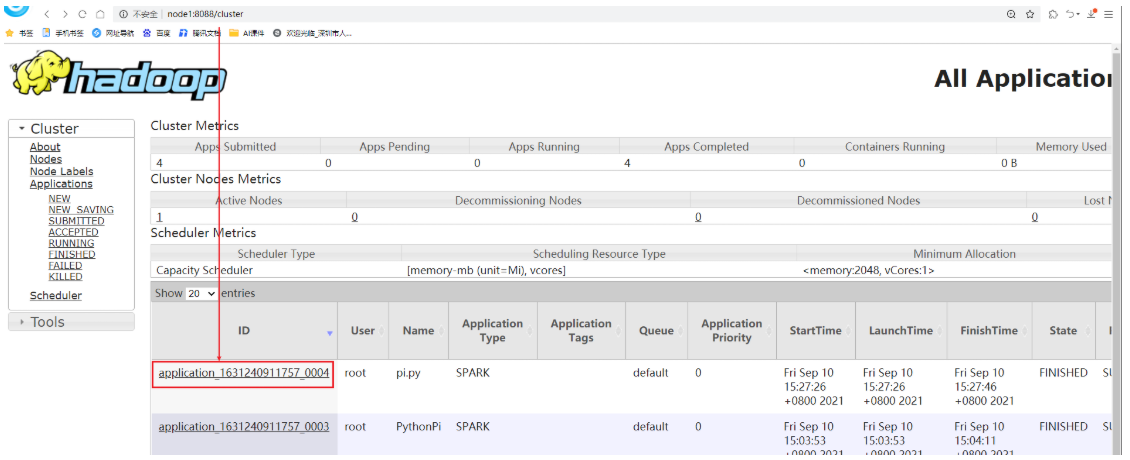* 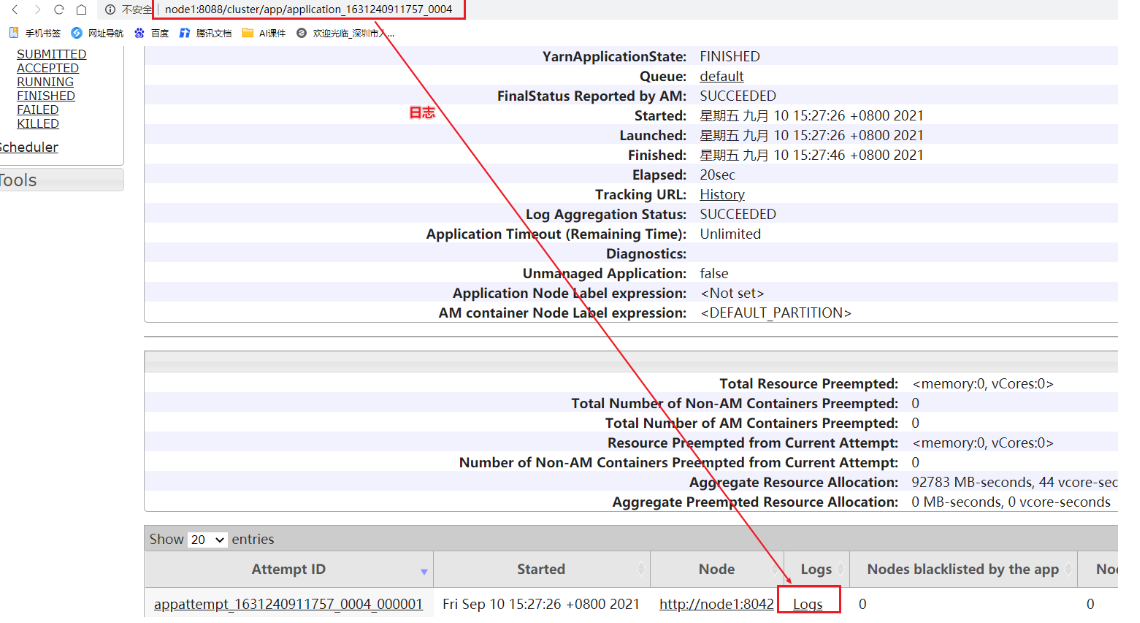* * 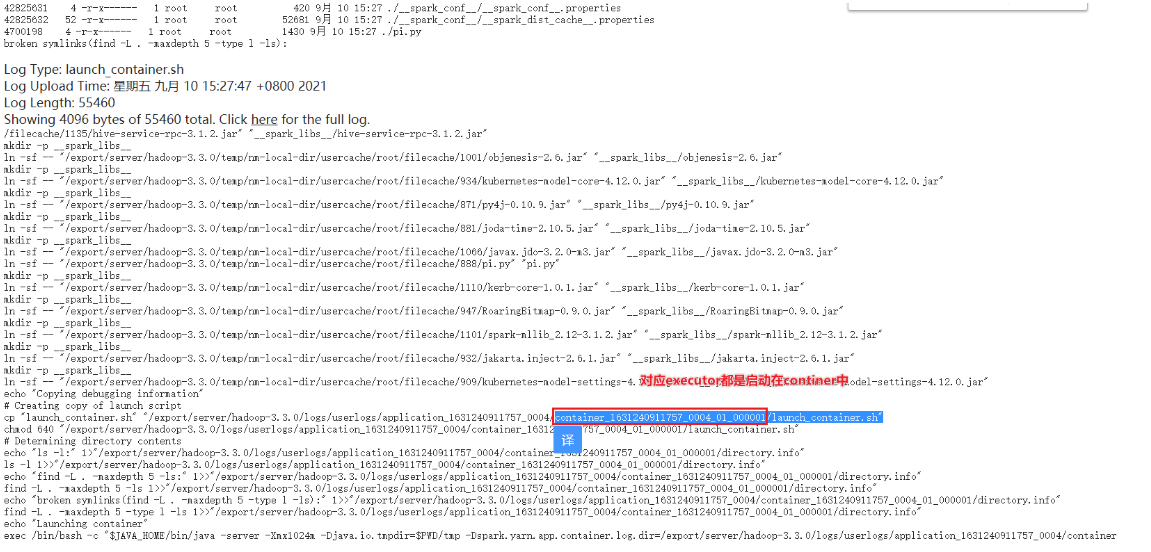* 原理:* 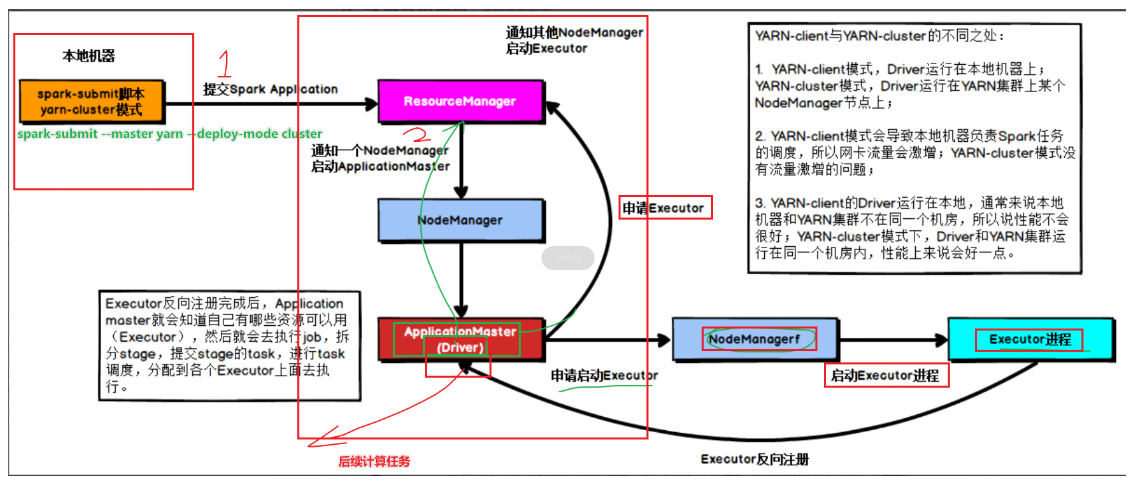* * 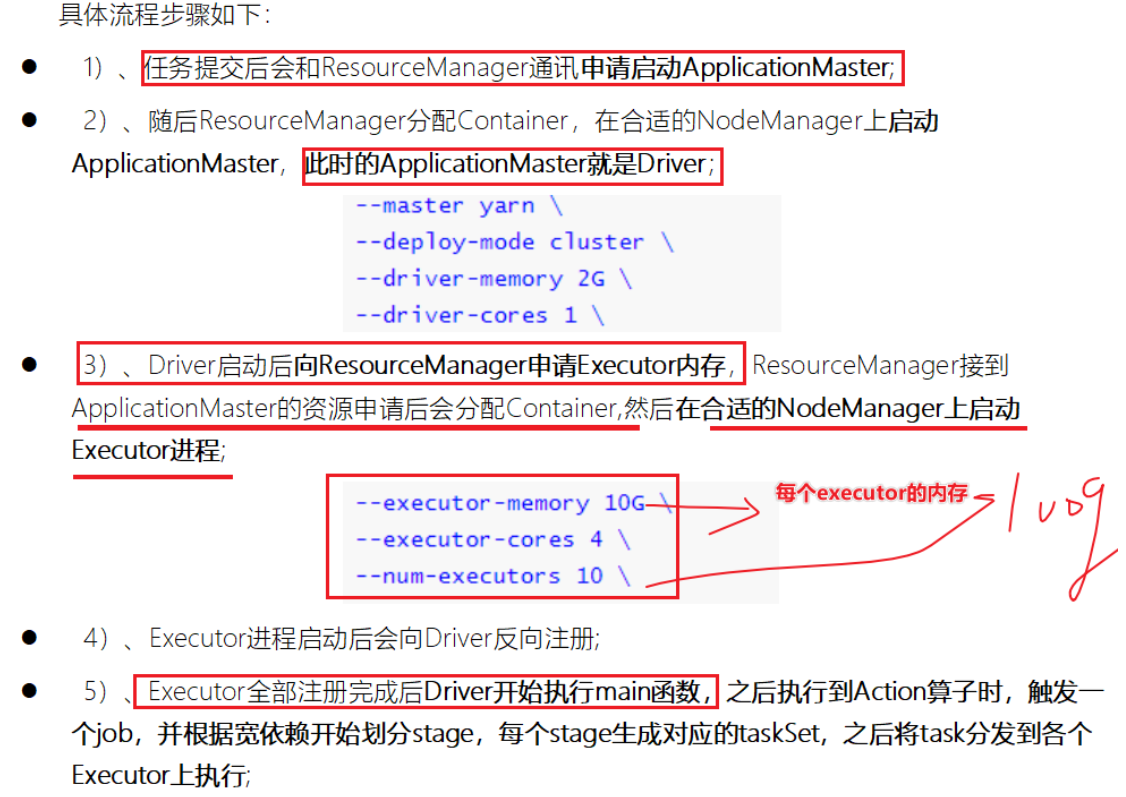

扩展阅读:两种模式详细流程
扩展阅读-Spark关键概念
扩展阅读:Spark集群角色
- Executor通过启动多个线程(task)来执行对RDD的partition进行并行计算
- 也就是执行我们对RDD定义的例如map、flatMap、reduce等算子操作。
- Driver:启动SparkCOntext的地方称之为Driver,Driver需要向CLusterManager申请资源,同时获取到资源后会划分Stage提交Job
- Master:l 主要负责资源的调度和分配,并进行集群的监控等职责;
- worker:一个是用自己的内存存储RDD的某个或某些partition;另一个是启动其他进程和线程(Executor),对RDD上的partition进行并行的处理和计算
- Executor:一个Worker****(NodeManager)****上可以运行多个Executor,Executor通过启动多个线程(task)来执行对RDD的partition进行并行计算
- 每个Task线程都会拉取RDD的每个分区执行计算,可以执行并行计算
扩展阅读:Spark-shell和Spark-submit
bin/spark-shell --master spark://node1:7077 --driver-memory 512m --executor-memory 1g
# SparkOnYarn组织参数
–driver-memory MEM 默认1g,Memory for driver (e.g. 1000M, 2G) (Default: 1024M). Driver端的内存
–driver-cores NUM 默认1个,Number of cores used by the driver, only in cluster mode(Default: 1).
–num-executors NUM 默认为2个,启动多少个executors
–executor-cores NUM 默认1个,Number of cores used by each executor,每个executou需要多少cpucores
–executor-memory 默认1G,Memory per executor (e.g. 1000M, 2G) (Default: 1G) ,每个executour的内存
–queue QUEUE_NAME The YARN queue to submit to (Default: “default”).
bin/spark-submit --master yarn \
–deploy-mode cluster \
–driver-memory 1g \
–driver-cores 2 \
–executor-cores 4 \
–executor-memory 512m \
–num-executors 10 \
path/XXXXX.py \
10
扩展阅读:命令参数
–driver-memory MEM 默认1g,Memory for driver (e.g. 1000M, 2G) (Default: 1024M). Driver端的内存
–driver-cores NUM 默认1个,Number of cores used by the driver, only in cluster mode(Default: 1).
–num-executors NUM 默认为2个,启动多少个executors
–executor-cores NUM 默认1个,Number of cores used by each executor,每个executou需要多少cpucores
–executor-memory 默认1G,Memory per executor (e.g. 1000M, 2G) (Default: 1G) ,每个executour的内存
–queue QUEUE_NAME The YARN queue to submit to (Default: “default”).
MAIN函数代码执行
- Driver端负责申请资源包括关闭资源,负责任务的Stage的切分
- Executor执行任务的计算
- 一个Spark的Application有很多Job
- 一个Job下面有很多Stage
- 一个Stage有很多taskset
- 一个Taskset有很多task任务构成的额
- 一个rdd分task分区任务都需要executor的task线程执行计算
再续 Spark 应用
[了解]PySpark角色分析
- Spark的任务执行的流程
- 面试的时候按照Spark完整的流程执行即可
- Py4J–Python For Java–可以在Python中调用Java的方法
- 因为Python作为顶层的语言,作为API完成Spark计算任务,底层实质上还是Scala语言调用的
- 底层有Python的SparkContext转化为Scala版本的SparkContext
- ****为了能在Executor端运行用户定义的Python函数或Lambda表达****式,则需要为每个Task单独启一个Python进程,通过socket通信方式将Python函数或Lambda表达式发给Python进程执行。
[了解]PySpark架构
RDD详解
为什么需要RDD?
- 首先Spark的提出为了解决MR的计算问题,诸如说迭代式计算,比如:机器学习或图计算
- 希望能够提出一套基于内存的迭代式数据结构,引入RDD弹性分布式数据集,如下图
- 为什么RDD是可以容错?
- RDD依靠于依赖关系dependency relationship
- reduceByKeyRDD-----mapRDD-----flatMapRDD
- 另外缓存,广播变量,检查点机制等很多机制解决容错问题
- 为什么RDD可以执行内存中计算?
- RDD本身设计就是基于内存中迭代式计算
- RDD是抽象的数据结构
什么是RDD?
- RDD弹性分布式数据集
- 弹性:可以基于内存存储也可以在磁盘中存储
- 分布式:分布式存储(分区)和分布式计算
- 数据集:数据的集合
RDD 定义
- RDD是不可变,可分区,可并行计算的集合
- 在pycharm中按两次shift可以查看源码,rdd.py
- RDD提供了五大属性
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Q8I7Y1iO-1667918253397)(H:\黑马\Python+大数据\第八阶段各项资料分别打包版本\笔记\3-SparkBase-基础2.assets\image-20210910181857233.png)]
RDD的5大特性
- RDD五大特性:
- 1-RDD是有一些列分区构成的,a list of partitions
- 2-计算函数
- 3-依赖关系,reduceByKey依赖于map依赖于flatMap
- 4-(可选项)key-value的分区,对于key-value类型的数据默认分区是Hash分区,可以变更range分区等
- 5-(可选项)位置优先性,移动计算不要移动存储
- 2-
- 3-
- 4-
- 5-最终图解
- RDD五大属性总结
- 1-分区列表
- 2-计算函数
- 3-依赖关系
- 4-key-value的分区器
- 5-位置优先性
RDD特点—不需要记忆
- 分区
- 只读
- 依赖
- 缓存
- checkpoint
WordCount中RDD
RDD的创建
PySpark中RDD的创建两种方式
并行化方式创建RDD
rdd1=sc.paralleise([1,2,3,4,5])
通过文件创建RDD
rdd2=sc.textFile(“hdfs://node1:9820/pydata”)
代码:
# -*- coding: utf-8 -*- # Program function:创建RDD的两种方式 ''' 第一种方式:使用并行化集合,本质上就是将本地集合作为参数传递到sc.pa 第二种方式:使用sc.textFile方式读取外部文件系统,包括hdfs和本地文件系统 1-准备SparkContext的入口,申请资源 2-使用rdd创建的第一种方法 3-使用rdd创建的第二种方法 4-关闭SparkContext ''' from pyspark import SparkConf, SparkContextif __name__ == '__main__': print("=========createRDD==============") # 1 - 准备SparkContext的入口,申请资源 conf = SparkConf().setAppName("createRDD").setMaster("local[5]") sc = SparkContext(conf=conf) # 2 - 使用rdd创建的第一种方法 collection_rdd = sc.parallelize([1, 2, 3, 4, 5, 6]) print(collection_rdd.collect()) # [1, 2, 3, 4, 5, 6] # 2-1 如何使用api获取rdd的分区个数 print("rdd numpartitions:{}".format(collection_rdd.getNumPartitions())) # 5 # 3 - 使用rdd创建的第二种方法 file_rdd = sc.textFile("/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/words.txt") print(file_rdd.collect()) print("rdd numpartitions:{}".format(file_rdd.getNumPartitions())) # 2 # 4 - 关闭SparkContext sc.stop()
小文件读取
通过外部数据创建RDD
http://spark.apache.org/docs/latest/api/python/reference/pyspark.html#rdd-apis
-- coding: utf-8 --
Program function:创建RDD的两种方式
‘’’
1-准备SparkContext的入口,申请资源
2-读取外部的文件使用sc.textFile和sc.wholeTextFile方式
3-关闭SparkContext
‘’’
from pyspark import SparkConf, SparkContextif name == ‘main’:
print(“=createRDD======”)1 - 准备SparkContext的入口,申请资源
conf = SparkConf().setAppName(“createRDD”).setMaster(“local[5]”)
sc = SparkContext(conf=conf)2 - 读取外部的文件使用sc.textFile和sc.wholeTextFile方式\
file_rdd = sc.textFile(“/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/ratings100”)
wholefile_rdd = sc.wholeTextFiles(“/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/ratings100”)
print(“file_rdd numpartitions:{}”.format(file_rdd.getNumPartitions()))#file_rdd numpartitions:100
print(“wholefile_rdd numpartitions:{}”.format(wholefile_rdd.getNumPartitions()))#wholefile_rdd numpartitions:2
print(wholefile_rdd.take(1))# 路径,具体的值如何获取wholefile_rdd得到具体的值
print(type(wholefile_rdd))#<class ‘pyspark.rdd.RDD’>
print(wholefile_rdd.map(lambda x: x[1]).take(1))3 - 关闭SparkContext
sc.stop()
* 如何查看rdd的分区?getNumPartitions()
扩展阅读:RDD分区数如何确定
-- coding: utf-8 --
Program function:创建RDD的两种方式
‘’’
第一种方式:使用并行化集合,本质上就是将本地集合作为参数传递到sc.pa
第二种方式:使用sc.textFile方式读取外部文件系统,包括hdfs和本地文件系统
1-准备SparkContext的入口,申请资源
2-使用rdd创建的第一种方法
3-使用rdd创建的第二种方法
4-关闭SparkContext
‘’’
from pyspark import SparkConf, SparkContextif name == ‘main’:
print(“=createRDD======”)1 - 准备SparkContext的入口,申请资源
conf = SparkConf().setAppName(“createRDD”).setMaster(“local[*]”)
conf.set(“spark.default.parallelism”,10)#重写默认的并行度,10
sc = SparkContext(conf=conf)
2 - 使用rdd创建的第一种方法,
collection_rdd = sc.parallelize([1, 2, 3, 4, 5, 6],5)
2-1 如何使用api获取rdd的分区个数
print(“rdd numpartitions:{}”.format(collection_rdd.getNumPartitions())) #2
总结:sparkconf设置的local5,sc.parallesise直接使用分区个数是5
如果设置spark.default.parallelism,默认并行度,sc.parallesise直接使用分区个数是10
优先级最高的是函数内部的第二个参数 3
2-2 如何打印每个分区的内容
print(“per partition content:”,collection_rdd.glom().collect())
3 - 使用rdd创建的第二种方法
minPartitions最小的分区个数,最终有多少的分区个数,以实际打印为主
file_rdd = sc.textFile(“/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/words.txt”,10)
print(“rdd numpartitions:{}”.format(file_rdd.getNumPartitions()))
print(" file_rdd per partition content:",file_rdd.glom().collect())如果sc.textFile读取的是文件夹中多个文件,这里的分区个数是以文件个数为主的,自己写的分区不起作用
file_rdd = sc.textFile(“/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/ratings100”, 3)
4 - 关闭SparkContext
sc.stop()
* 首先明确,分区的个数,这里一切以看到的为主,特别在sc.textFile* * * 重要两个API* 分区个数getNumberPartitions * 分区内元素glom().collect()
RDD的操作
函数分类
- *Transformation操作只是建立计算关系,而Action 操作才是实际的执行者*。
- Transformation算子
- 转换算子
- 操作之间不算的转换,如果想看到结果通过action算子触发
- Action算子
- 行动算子
- 触发Job的执行,能够看到结果信息
Transformation函数
值类型valueType
map
flatMap
filter
mapValue
双值类型DoubleValueType
- intersection
- union
- difference
- distinct
Key-Value值类型
- reduceByKey
- groupByKey
- sortByKey
- combineByKey是底层API
- foldBykey
- aggreateBykey
Action函数
- collect
- saveAsTextFile
- first
- take
- takeSample
- top
基础练习[Wordcount快速演示]
Transformer算子
单value类型代码
-- coding: utf-8 --
Program function:完成单Value类型RDD的转换算子的演示
from pyspark import SparkConf,SparkContext
import re
‘’’
分区内:一个rdd可以分为很多分区,每个分区里面都是有大量元素,每个分区都需要线程执行
分区间:有一些操作分区间做一些累加
‘’’
if name == ‘main’:1-创建SparkContext申请资源
conf = SparkConf().setAppName(“mini”).setMaster(“local[*]”)
sc = SparkContext.getOrCreate(conf=conf)
sc.setLogLevel(“WARN”)#一般在工作中不这么写,直接复制log4j文件2-map操作
rdd1 = sc.parallelize([1, 2, 3, 4, 5, 6])
rdd__map = rdd1.map(lambda x: x * 2)
print(rdd__map.glom().collect())#[2, 4, 6, 8, 10, 12],#[[2, 4, 6], [8, 10, 12]]3-filter操作
print(rdd1.glom().collect())
print(rdd1.filter(lambda x: x > 3).glom().collect())4-flatMap
rdd2 = sc.parallelize([" hello you", “hello me “])
print(rdd2.flatMap(lambda word: re.split(”\s+”, word.strip())).collect())5-groupBY
x = sc.parallelize([1, 2, 3])
y = x.groupBy(lambda x: ‘A’ if (x % 2 == 1) else ‘B’)
print(y.mapValues(list).collect())#[(‘A’, [1, 3]), (‘B’, [2])]6-mapValue
x1 = sc.parallelize([(“a”, [“apple”, “banana”, “lemon”]), (“b”, [“grapes”])])
def f(x): return len(x)
print(x1.mapValues(f).collect())
双value类型的代码
-- coding: utf-8 --
Program function:完成单Value类型RDD的转换算子的演示
from pyspark import SparkConf, SparkContext
import re‘’’
分区内:一个rdd可以分为很多分区,每个分区里面都是有大量元素,每个分区都需要线程执行
分区间:有一些操作分区间做一些累加
‘’’
if name == ‘main’:1-创建SparkContext申请资源
conf = SparkConf().setAppName(“mini2”).setMaster(“local[*]”)
sc = SparkContext.getOrCreate(conf=conf)
sc.setLogLevel(“WARN”) # 一般在工作中不这么写,直接复制log4j文件2-对两个RDD求并集
rdd1 = sc.parallelize([1, 2, 3, 4, 5])
rdd2 = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8])
Union_RDD = rdd1.union(rdd2)
print(Union_RDD.collect())
print(rdd1.intersection(rdd2).collect())
print(rdd2.subtract(rdd1).collect())Return a new RDD containing the distinct elements in this RDD.
print(Union_RDD.distinct().collect())
print(Union_RDD.distinct().glom().collect())* key-Value算子* ```python# -*- coding: utf-8 -*- # Program function:完成单Value类型RDD的转换算子的演示from pyspark import SparkConf, SparkContext import re''' 分区内:一个rdd可以分为很多分区,每个分区里面都是有大量元素,每个分区都需要线程执行 分区间:有一些操作分区间做一些累加 ''' if __name__ == '__main__':# 1-创建SparkContext申请资源conf = SparkConf().setAppName("mini2").setMaster("local[*]")sc = SparkContext.getOrCreate(conf=conf)sc.setLogLevel("WARN") # 一般在工作中不这么写,直接复制log4j文件# 2-key和value类型算子# groupByKeyrdd1 = sc.parallelize([("a", 1), ("b", 2)])rdd2 = sc.parallelize([("c", 1), ("b", 3)])rdd3 = rdd1.union(rdd2)key1 = rdd3.groupByKey()print("groupByKey:",key1.collect())#groupByKey:# [('b', <pyspark.resultiterable.ResultIterable object at 0x7f001c469c40>),# ('c', <pyspark.resultiterable.ResultIterable object at 0x7f001c469310>),# ('a', <pyspark.resultiterable.ResultIterable object at 0x7f001c469a00>)]print(key1.mapValues(list).collect())#需要通过mapValue获取groupByKey的值print(key1.mapValues(tuple).collect())# reduceByKeykey2 = rdd3.reduceByKey(lambda x, y: x + y)print(key2.collect())# sortByKeyprint(key2.map(lambda x: (x[1], x[0])).sortByKey(False).collect())#[(5, 'b'), (1, 'c'), (1, 'a')]# countByKeyprint(rdd3.countByValue())#defaultdict(<class 'int'>, {('a', 1): 1, ('b', 2): 1, ('c', 1): 1, ('b', 3): 1})
Action算子
部分操作
-- coding: utf-8 --
Program function:完成单Value类型RDD的转换算子的演示
from pyspark import SparkConf, SparkContext
import re‘’’
分区内:一个rdd可以分为很多分区,每个分区里面都是有大量元素,每个分区都需要线程执行
分区间:有一些操作分区间做一些累加
‘’’
if name == ‘main’:1-创建SparkContext申请资源
conf = SparkConf().setAppName(“mini2”).setMaster(“local[*]”)
sc = SparkContext.getOrCreate(conf=conf)
sc.setLogLevel(“WARN”) # 一般在工作中不这么写,直接复制log4j文件2-key和value类型算子
groupByKey
rdd1 = sc.parallelize([(“a”, 1), (“b”, 2)])
rdd2 = sc.parallelize([(“c”, 1), (“b”, 3)])print(rdd1.first())
print(rdd1.take(2))
print(rdd1.top(2))
print(rdd1.collect())rdd3 = sc.parallelize([1, 2, 3, 4, 5])
from operator import add
from operator import mulprint(rdd3.reduce(add))
print(rdd3.reduce(mul))rdd4 = sc.parallelize(range(0, 10))
能否保证每次抽样结果是一致的,使用seed随机数种子
print(rdd4.takeSample(True, 3, 123))
print(rdd4.takeSample(True, 3, 123))
print(rdd4.takeSample(True, 3, 123))
print(rdd4.takeSample(True, 3, 34))* 其他补充算子* ```python# -*- coding: utf-8 -*- # Program function:完成单Value类型RDD的转换算子的演示from pyspark import SparkConf, SparkContext import re''' 分区内:一个rdd可以分为很多分区,每个分区里面都是有大量元素,每个分区都需要线程执行 分区间:有一些操作分区间做一些累加 '''def f(iterator): # 【1,2,3】 【4,5】for x in iterator: # for x in 【1,2,3】 x=1,2,3 print 1.2.3print(x)def f1(iterator): # 【1,2,3】 【4,5】 sum(1+2+3) sum(4+5)yield sum(iterator)if __name__ == '__main__':# 1-创建SparkContext申请资源conf = SparkConf().setAppName("mini2").setMaster("local[*]")sc = SparkContext.getOrCreate(conf=conf)sc.setLogLevel("WARN") # 一般在工作中不这么写,直接复制log4j文件# 2-foreach-Applies a function to all elements of this RDD.rdd1 = sc.parallelize([("a", 1), ("b", 2)])print(rdd1.glom().collect())# def f(x):print(x)rdd1.foreach(lambda x: print(x))# 3-foreachPartition--Applies a function to each partition of this RDD.# 从性能角度分析,按照分区并行比元素更加高效rdd1.foreachPartition(f)# 4-map---按照元素进行转换rdd2 = sc.parallelize([1, 2, 3, 4])print(rdd2.map(lambda x: x * 2).collect())# 5-mapPartiton-----按照分区进行转换# Return a new RDD by applying a function to each partition of this RDD.print(rdd2.mapPartitions(f1).collect()) # [3, 7]
重要函数
基本函数
- 基础的transformation
- 和action操作
分区操作函数
- mapPartition
- foreachPartition
重分区函数
-- coding: utf-8 --
Program function:完成单Value类型RDD的转换算子的演示
from pyspark import SparkConf, SparkContext
import re
‘’’
分区内:一个rdd可以分为很多分区,每个分区里面都是有大量元素,每个分区都需要线程执行
分区间:有一些操作分区间做一些累加
alt+6 可以调出来所有TODO,
TODO是Python提供了预留功能的地方
‘’’
if name == ‘main’:
#TODO: 1-创建SparkContext申请资源
conf = SparkConf().setAppName(“mini2”).setMaster(“local[*]”)
sc = SparkContext.getOrCreate(conf=conf)
sc.setLogLevel(“WARN”) # 一般在工作中不这么写,直接复制log4j文件
#TODO: 2-执行重分区函数–repartition
rdd1 = sc.parallelize([1, 2, 3, 4, 5, 6], 3)
print(“partitions num:”,rdd1.getNumPartitions())
print(rdd1.glom().collect())#[[1, 2], [3, 4], [5, 6]]
print(“repartition result:”)
#TODO: repartition可以增加分区也可以减少分区,但是都会产生shuflle,如果减少分区的化建议使用coalesc避免发生shuffle
rdd__repartition1 = rdd1.repartition(5)
print(“increase partition”,rdd__repartition1.glom().collect())#[[], [1, 2], [5, 6], [3, 4], []]
rdd__repartition2 = rdd1.repartition(2)
print(“decrease partition”,rdd__repartition2.glom().collect())#decrease partition [[1, 2, 5, 6], [3, 4]]
#TODO: 3-减少分区–coalese
print(rdd1.coalesce(2).glom().collect())#[[1, 2], [3, 4, 5, 6]]
print(rdd1.coalesce(5).glom().collect())#[[1, 2], [3, 4], [5, 6]]
print(rdd1.coalesce(5,True).glom().collect())#[[], [1, 2], [5, 6], [3, 4], []]结论:repartition默认调用的是coalese的shuffle为True的方法
TODO: 4-PartitonBy,可以调整分区,还可以调整分区器(一种hash分区器(一般打散数据),一种range分区器(排序拍好的))
此类专门针对RDD中数据类型为KeyValue对提供函数
rdd五大特性中有第四个特点key-value分区器,默认是hashpartitioner分区器
rdd__map = rdd1.map(lambda x: (x, x))
print(“partitions length:”,rdd__map.getNumPartitions())#partitions length: 3
print(rdd__map.partitionBy(2).glom().collect())聚合函数* * 代码:* ```python# -*- coding: utf-8 -*- # Program function:完成单Value类型RDD的转换算子的演示 from pyspark import SparkConf, SparkContext import re''' 分区内:一个rdd可以分为很多分区,每个分区里面都是有大量元素,每个分区都需要线程执行 分区间:有一些操作分区间做一些累加 alt+6 可以调出来所有TODO, TODO是Python提供了预留功能的地方 ''' def addNum(x,y):return x+y if __name__ == '__main__':# TODO: 1-创建SparkContext申请资源conf = SparkConf().setAppName("mini2").setMaster("local[*]")sc = SparkContext.getOrCreate(conf=conf)sc.setLogLevel("WARN") # 一般在工作中不这么写,直接复制log4j文件# TODO: 2-使用reduce进行聚合计算rdd1 = sc.parallelize([1, 2, 3, 4, 5, 6], 3)from operator import add# 直接得到返回值-21print(rdd1.reduce(add))# TODO: 3-使用fold进行聚合计算# 第一个参数zeroValue是初始值,会参与分区的计算# 第二个参数是执行运算的operationprint(rdd1.fold(0, add)) # 21print(rdd1.getNumPartitions()) # 3print(rdd1.glom().collect())print("fold result:", rdd1.fold(10, add))# TODO: 3-使用aggreate进行聚合计算# seqOp分区内的操作, combOp分区间的操作print(rdd1.aggregate(0, add, add)) # 21print(rdd1.glom().collect())print("aggregate result:", rdd1.aggregate(1, add, add)) # aggregate result: 25# 结论:fold是aggregate的简化版本,fold分区内和分区间的函数是一致的print("aggregate result:", rdd1.aggregate(1, addNum, addNum)) # aggregate result: 25
byKey类的聚合函数
groupByKey----如何获取value的数据?------答案:result.mapValue(list).collect
reduceByKey
foldBykey
aggregateByKey
CombineByKey:这是一个更为底层实现的bykey 聚合算子,可以实现更多复杂功能
案例1:
# -*- coding: utf-8 -*-# Program function:完成单Value类型RDD的转换算子的演示from pyspark import SparkConf, SparkContext import re''' 分区内:一个rdd可以分为很多分区,每个分区里面都是有大量元素,每个分区都需要线程执行 分区间:有一些操作分区间做一些累加 alt+6 可以调出来所有TODO, TODO是Python提供了预留功能的地方 '''''' 对初始值进行操作 ''' def createCombiner(value): #('a',[1])return [value]# 这里的x=createCombiner得到的[value]结果def mergeValue(x,y): #这里相同a的value=y=1x.append(y)#('a', [1, 1]),('b', [1])return xdef mergeCombiners(a,b):a.extend(b)return aif name == ‘main’:
TODO: 1-创建SparkContext申请资源
conf = SparkConf().setAppName(“mini2”).setMaster(“local[*]”)
sc = SparkContext.getOrCreate(conf=conf)
sc.setLogLevel(“WARN”) # 一般在工作中不这么写,直接复制log4j文件TODO: 2-基础数据处理
from operator import add
rdd = sc.parallelize([(“a”, 1), (“b”, 1), (“a”, 1)])
[(a:[1,1]),(b,[1,1])]
print(sorted(rdd.groupByKey().mapValues(list).collect()))
使用自定义集聚合函数组合每个键的元素的通用功能。
-
createCombiner, which turns a V into a C (e.g., creates a one-element list)对初始值进行操作
-
mergeValue, to merge a V into a C (e.g., adds it to the end ofa list)对分区内的元素进行合并
-
mergeCombiners, to combine two C’s into a single one (e.g., merges the lists)对分区间的元素进行合并
by_key_result = rdd.combineByKey(createCombiner, mergeValue, mergeCombiners)
print(sorted(by_key_result.collect()))#[(‘a’, [1, 1]), (‘b’, [1])]* 案例2* ```python-- coding: utf-8 --
Program function:完成单Value类型RDD的转换算子的演示
from pyspark import SparkConf, SparkContext
import re‘’’
分区内:一个rdd可以分为很多分区,每个分区里面都是有大量元素,每个分区都需要线程执行
分区间:有一些操作分区间做一些累加
alt+6 可以调出来所有TODO,
TODO是Python提供了预留功能的地方
‘’’‘’’
对初始值进行操作
[value,1],value指的是当前学生成绩,1代表的是未来算一下一个学生考了几次考试
(“Fred”, 88)---------->[88,1]
‘’’def createCombiner(value): #
return [value, 1]‘’’
x代表的是 [value,1]值,x=[88,1]
y代表的相同key的value,比如(“Fred”, 95)的95,执行分区内的累加
‘’’def mergeValue(x, y):
return [x[0] + y, x[1] + 1]‘’’
a = a[0] value,a[1] 几次考试
‘’’def mergeCombiners(a, b):
return [a[0] + b[0], a[1] + b[1]]if name == ‘main’:
TODO: 1-创建SparkContext申请资源
conf = SparkConf().setAppName(“mini2”).setMaster(“local[*]”)
sc = SparkContext.getOrCreate(conf=conf)
sc.setLogLevel(“WARN”) # 一般在工作中不这么写,直接复制log4j文件TODO: 2-基础数据处理
from operator import add
这里需要实现需求:求解一个学生的平均成绩
x = sc.parallelize([(“Fred”, 88), (“Fred”, 95), (“Fred”, 91), (“Wilma”, 93), (“Wilma”, 95), (“Wilma”, 98)], 3)
print(x.glom().collect())第一个分区(“Fred”, 88), (“Fred”, 95)
第二个分区(“Fred”, 91), (“Wilma”, 93),
第三个分区(“Wilma”, 95), (“Wilma”, 98)
reduceByKey
reduce_by_key_rdd = x.reduceByKey(lambda x, y: x + y)
print(“reduceBykey:”, reduce_by_key_rdd.collect()) # [(‘Fred’, 274), (‘Wilma’, 286)]如何求解平均成绩?
使用自定义集聚合函数组合每个键的元素的通用功能。
-
createCombiner, which turns a V into a C (e.g., creates a one-element list)对初始值进行操作
-
mergeValue, to merge a V into a C (e.g., adds it to the end ofa list)对分区内的元素进行合并
-
mergeCombiners, to combine two C’s into a single one (e.g., merges the lists)对分区间的元素进行合并
combine_by_key_rdd = x.combineByKey(createCombiner, mergeValue, mergeCombiners)
print(combine_by_key_rdd.collect()) # [(‘Fred’, [274, 3]), (‘Wilma’, [286, 3])]接下来平均值如何实现–(‘Fred’, [274, 3])—x[0]=Fred x[1]= [274, 3],x[1][0]=274,x[1][1]=3
print(combine_by_key_rdd.map(lambda x: (x[0], int(x[1][0] / x[1][1]))).collect())
* * 面试题:* [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0jT58qk8-1667918253411)(3-SparkBase-基础2.assets/image-20210911160023982.png)]* 关联函数
SparkCore案例
PySpark实现SouGou统计分析
jieba分词:
pip install jieba 从哪里下载pypi
三种分词模式
精确模式,试图将句子最精确地切开,适合文本分析;默认的方式
全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
-- coding: utf-8 --
Program function:测试结巴分词
import jieba
import rejieba.cut
方法接受四个输入参数:
需要分词的字符串;
cut_all 参数用来控制是否采用全模式;
HMM 参数用来控制是否使用 HMM 模型;
use_paddle 参数用来控制是否使用paddle模式下的分词模式,paddle模式采用延迟加载方式,通过enable_paddle接口安装paddlepaddle-tiny,并且import相关代码;
str = “我来到北京清华大学”
print(list(jieba.cut(str))) # [‘我’, ‘来到’, ‘北京’, ‘清华大学’],默认的是精确模式
print(list(jieba.cut(str, cut_all=True))) # [‘我’, ‘来到’, ‘北京’, ‘清华’, ‘清华大学’, ‘华大’, ‘大学’] 完全模式准备的测试数据
str1 = “00:00:00 2982199073774412 [360安全卫士] 8 3 download.it.com.cn/softweb/software/firewall/antivirus/20067/17938.html”
print(re.split(“\s+”, str1)[2]) # [360安全卫士]
print(re.sub(“[|]”, “”, re.split(“\s+”, str1)[2])) #360安全卫士
print(list(jieba.cut(re.sub(“[|]”, “”, re.split(“\s+”, str1)[2])))) # [360安全卫士] —>[‘360’, ‘安全卫士’]* 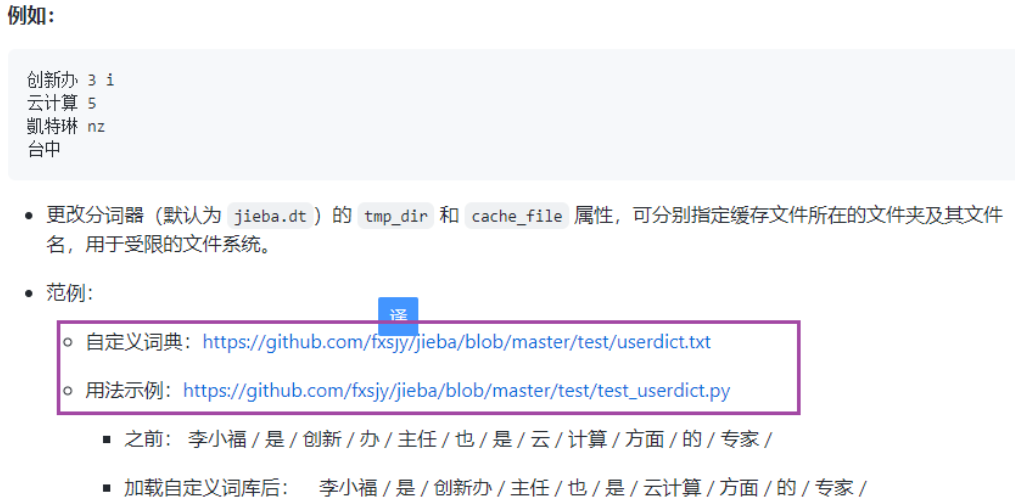* 数据认知:数据集来自于搜狗实验室,日志数据* ***\*日志\****库设计为包括约1个月(2008年6月)Sogou搜索引擎部分**网页查询需求**及**用户点击情况的网页查询日志**数据集合。* 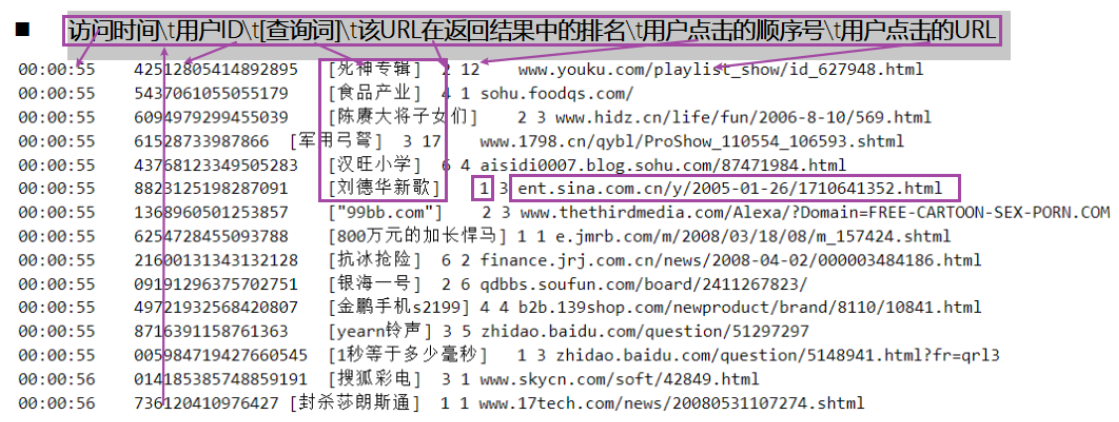* * 需求* 1-首先需要将数据读取处理,形成结构化字段进行相关的分析* 2-如何对搜索词进行分词,使用jieba或hanlp* jieba是中文分词最好用的工具* 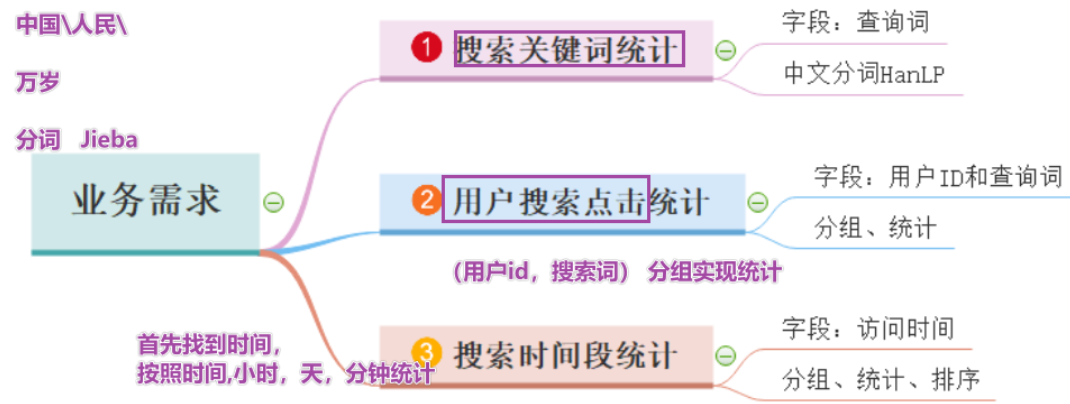* 步骤* 1-读取数据* 2-完成需求1:搜狗关键词统计* 3-完成需求2:用户搜索点击统计* 4-完成需求3:搜索时间段统计* 5-停止sparkcontext* 代码* ```python-- coding: utf-8 --
Program function:搜狗分词之后的统计
‘’’
- 1-读取数据
- 2-完成需求1:搜狗关键词统计
- 3-完成需求2:用户搜索点击统计
- 4-完成需求3:搜索时间段统计
- 5-停止sparkcontext
‘’’
from pyspark import SparkConf, SparkContext
import re
import jiebaif name == ‘main’:
准备环境变量
conf = SparkConf().setAppName(“sougou”).setMaster(“local[*]”)
sc = SparkContext.getOrCreate(conf=conf)
sc.setLogLevel(“WARN”)TODO*1 - 读取数据
sougouFileRDD = sc.textFile(“/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/sougou/SogouQ.reduced”)
print(“sougou count is:”, sougouFileRDD.count())#sougou count is: 1724264
00:00:00 2982199073774412 [360安全卫士] 8 3 download.it.com.cn/softweb/software/firewall/antivirus/20067/17938.html
resultRDD=sougouFileRDD
.filter(lambda line:(len(line.strip())>0) and (len(re.split(“\s+”,line.strip()))==6))
.map(lambda line:(
re.split(“\s+”, line)[0],
re.split(“\s+”, line)[1],
re.sub(“[|]”, “”, re.split(“\s+”, line)[2]),
re.split(“\s+”, line)[3],
re.split(“\s+”, line)[4],
re.split(“\s+”, line)[5]
))print(resultRDD.take(2))
#(‘00:00:00’, ‘2982199073774412’, ‘360安全卫士’, ‘8’, ‘3’, ‘download.it.com.cn/softweb/software/firewall/antivirus/20067/17938.html’)
#(‘00:00:00’, ‘07594220010824798’, ‘哄抢救灾物资’, ‘1’, ‘1’, ‘news.21cn.com/social/daqian/2008/05/29/4777194_1.shtml’)TODO*2 - 完成需求1:搜狗关键词统计
print(“=完成需求1:搜狗关键词统计======”)
recordRDD = resultRDD.flatMap(lambda record: jieba.cut(record[2]))print(recordRDD.take(5))
sougouResult1=recordRDD
.map(lambda word:(word,1))
.reduceByKey(lambda x,y:x+y)
.sortBy(lambda x:x[1],False)print(sougouResult1.take(5))
TODO*3 - 完成需求2:用户搜索点击统计
print(“=完成需求2:用户搜索点击统计======”)
根据用户id和搜索的内容作为分组字段进行统计
sougouClick = resultRDD.map(lambda record: (record[1], record[2]))
sougouResult2=sougouClick
.map(lambda tuple:(tuple,1))
.reduceByKey(lambda x,y:x+y) #key,value打印一下最大的次数和最小的次数和平均次数
print(“max count is:”,sougouResult2.map(lambda x: x[1]).max())
print(“min count is:”,sougouResult2.map(lambda x: x[1]).min())
print(“mean count is:”,sougouResult2.map(lambda x: x[1]).mean())如果对所有的结果排序
print(sougouResult2.sortBy(lambda x: x[1], False).take(5))
TODO*4 - 完成需求3:搜索时间段统计
print(“=完成需求3:搜索时间段-小时-统计======”)
#00:00:00
hourRDD = resultRDD.map(lambda x: str(x[0])[0:2])
sougouResult3=hourRDD
.map(lambda word:(word,1))
.reduceByKey(lambda x,y:x+y)
.sortBy(lambda x:x[1],False)
print(“搜索时间段-小时-统计”,sougouResult3.take(5))TODO*5 - 停止sparkcontext
sc.stop()
- 总结
- 重点关注在如何对数据进行清洗,如何按照需求进行统计
- 今日作业:
- 1-rdd的创建的两种方法,必须练习
- 2-rdd的练习将基础的案例先掌握。map。flatMap。reduceByKey
- 3-sougou的案例需要联系2-3遍
- 练习流程:
- 首先先要将代码跑起来
- 然后在理解代码,这一段代码做什么用的
- 在敲代码,需要写注释之后敲代码
Python+大数据-Spark技术栈(二)SparkBaseCore相关推荐
- 深圳地铁客流大数据 Spark 技术栈
写在前面 学以致用,本项目通过对深圳市开放数据之轨道交通客流情况进行分析,了解深漂的我们每天在上下班都经历了些什么- 本系列项目以Spark技术栈为主, 花絮 SHOW DATABASES;CREAT ...
- 大数据工程师技术栈探讨
1.前言 随着国务院印发十四五规划关于数字经济规划和数字信息化建设的推进(如下图1所示).大量的数字化的产品将产生海量的数据,因此近些年大数据技术越来越被大家重视起来. 图1 国务院十四五数字经济规 ...
- TiDB 在大型互联网的深度实践及应用--大数据平台技术栈08
回顾:大数据平台技术栈 (ps:可点击查看),今天就来说说其中的TiDB! 作者介绍 吕磊,摩拜单车高级 DBA 一.业务场景 摩拜单车 2017 年开始将 TiDB 尝试应用到实际业务当中,根据业务 ...
- 大数据|Spark技术在京东智能供应链预测的应用案例深度剖析(一)
大数据|Spark技术在京东智能供应链预测的应用案例深度剖析(一) 2017-03-27 11:58 浏览次数:148 1. 背景 前段时间京东公开了面向第二个十二年的战略规划,表示京东将全面走向技 ...
- Python +大数据-Hadoop生态-Linux(二)-集群搭建和安装
Python +大数据-Hadoop生态-Linux(二)-集群搭建和安装 今日课程学习目标 1.掌握Linux用户.权限管理 2.掌握Linux常用系统命令 3.掌握服务器集群环境搭建 4.了解sh ...
- K8S 从懵圈到熟练--大数据平台技术栈18
回顾:大数据平台技术栈 (ps:可点击查看),今天就来说说其中的K8S! 来自:阿里技术公众号 阿里妹导读:排查完全陌生的问题.不熟悉的系统组件,对许多工程师来说是无与伦比的工作乐趣,当然也是一大挑战 ...
- RocketMQ实战--大数据平台技术栈06
回顾:大数据平台技术栈 (ps:可点击查看),今天就来说说其中的RocketMQ! 作者丨张丰哲 www.jianshu.com/p/3afd610a8f7d 阿里巴巴有2大核心的分布式技术,一个是O ...
- 谈谈对 Canal( 增量数据订阅与消费 )的理解--大数据平台技术栈系列(3)
之前说了,大数据平台技术栈 (可点击查看),今天就来说说其中的Cannal 来源:朱小厮, blog.csdn.net/u013256816/article/details/52475190 概述 c ...
- 大数据常见技术栈简介
1.Hadoop Hadoop是一个由Apache基金会所开发的分布式系统基础架构.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速运算和存储.Hadoop实现了一个 ...
最新文章
- python使用matplotlib可视化3D曲面图、曲面图表示一个指定的因变量y与两个自变量x和z之间的函数关系
- apache启服务命令_apache_cgi绕过disable_functions
- Windows Mobile中实现统计图形的绘制(C#版,柱状图)
- Mysql在Windows上离线安装与配置
- 方法:如何获取操作系统所有分区(逻辑驱动器)
- Python中的并行处理(Pool.map()、Pool.starmap()、Pool.apply()、)
- mysql最左_Mysql最左原则
- amazeui学习笔记二(进阶开发2)--Web组件简介Web Component
- kubernetes集群应用部署实例
- zabbix如何实现微信报警
- 【POJ 3074】Sudoku【剪枝】
- 图片放大后很模糊怎么办?
- 利用计算机画统计图.doc,信息技术应用利用计算机画统计图.pptx
- 学校计算机机房网络设备,[学校计算机机房的维护]学校计算机机房硬件设备清单...
- 以太坊Ropsten测试网合并意味着什么?
- 华为荣耀8青春版计算机在哪里,华为荣耀8青春版比荣耀8青春在哪里?
- linux系统如何下游戏,海岛纪元干货 在Linux系统下如何畅玩游戏攻略
- Beyond Compare4
- python命令窗口代码如何调整大小_可调整窗口大小命令pythonmay
- from vision import VisionDataset报错
热门文章
- c++贪吃蛇游戏-详细解释-非单纯贴代码
- 计算机基础教育高峰论坛,黑龙江外国语学院参加计算机基础教育高峰论坛
- php 正则匹配utf8中文
- USACO 5.1 Starry Night(模拟)
- 调研分析-全球与中国保险丝接线端子市场现状及未来发展趋势
- 不够聪明的蓝牙锁,赶紧修复这几个缺陷!
- 调用png格式图片时“libpng warning: iCCP: known incorrect sRGB profile”警告
- DropDownList中SelectedIndexChanged事件失效的解决方法
- 爱思考全面讲解CISP、CISSP、CISP-PTE之间都有什么区别
- Miss Status Handling Registers (MSHR) 计算机体系结构