【ACL 2021】Locate and Label A Two-stage Identifier for Nested Named Entity Recognition
一、Introduction
命名实体识别(NER)是自然语言处理中一项研究非常广泛的任务。传统的NER研究只处理平面实体,而忽略了嵌套实体。例如:北京大学,北京大学不仅是一个组织,同时北京也是一个地点。
嵌套实体研究现状:
( 1 )序列方法:这种预测边界,但在没有动态调整的情况下,边界信息没有得到充分利用。
( 2 )基于spanspanspan的方法:将实体识别的问题转化为了spanspanspan分类问题。假设一个句子有四个词s1,s2,s3,s4s_1,s_2,s_3,s_4s1,s2,s3,s4,枚举所有spanspanspan的可能性,然后逐一判断每个spanspanspan是不是实体。这种方法由于大量低质量的spanspanspan导致较高的计算成本。
sentences={s1,s2,s3,s4}sentences=\{s_1,s_2,s_3,s_4\} sentences={s1,s2,s3,s4}
s1,s2,s3,s4,s1s2,s2s3,s3s4,s1s2s3,s2s3s4,s1s2s3s4s_1,s_2,s_3,s_4,s_1s_2,s_2s_3,s_3s_4,s_1s_2s_3,s_2s_3s_4,s_1s_2s_3s_4 s1,s2,s3,s4,s1s2,s2s3,s3s4,s1s2s3,s2s3s4,s1s2s3s4
二、Method
- 在第一阶段,设计SpanProposalSpan ProposalSpanProposal模块,该模块包含两个组件:过滤器和回归器。过滤器作用是过滤掉低质量的spansspansspans,保留高质量的spansspansspans(SpanProposalSpan ProposalSpanProposal)。回归器通过调整跨度建议的边界来定位实体,以提高SpanProposalSpan ProposalSpanProposal的质量。
- 在第二阶段,我们使用实体分类器来标记实体类别。

2.1 Token Representation
一个句子n个词,第i个词向量是通过将它的词向量 xiwx^w_ixiw、上下文词向量xilmx^{lm}_ixilm、词性向量xposix^{pos}ixposi、字符级向量xicharx^{char}_ixichar进行拼接,然后将其输入BiLSTMBiLSTMBiLSTM获得最终词向量hi∈Rdh_i\in{\mathbb{R}}^dhi∈Rd。
2.2 Seed Span Generation
seedseedseed spansspansspans集合
一个句子长度为LLL,枚举所有的起始位置和结束位置生成seedseedseed spansspansspans,seedseedseed spansspansspans集合表示为β={b0,...,bK}\beta=\{b_0,...,b_K\}β={b0,...,bK},其中bi=(sti,edi)b_i=(st_i,ed_i)bi=(sti,edi)表示第i个seedseedseed spanspanspan,KKK表示seedseedseed spansspansspans的数量,stist_isti和edied_iedi表示spanspanspan的起始位置和结束位置。
为seedseedseed spansspansspans分配类别和回归目标
首先,计算seedseedseed spanspanspan和所有groud−truthgroud-truthgroud−truth实体的IoU(A,B)IoU(A,B)IoU(A,B)值,将seedseedseed spanspanspan和最大IoUIoUIoU值的groud−truthgroud-truthgroud−truth实体进行配对。其次,根据seedsseedsseeds spanspanspan配对的其groud−truthgroud-truthgroud−truth实体的IoUIoUIoU值将其分为正样本和负样本;具体来说,如果seedseedseed spanspanspan和配对的groud−truthgroud-truthgroud−truth实体的IoUIoUIoU值如果大于某一个阈值α\alphaα,则为正样本,否则设为负样本;对于正样本,将其groud−truthgroud-truthgroud−truth实体的类别y^\widehat{y}y 作为正样本的类别,对于负样本,将其类别置。最后,对负样本进行随机抽样,使正样本和负样本的比例是5:15:15:1。
2.3 Span Proposal Module
Span Proposal Filter
对于每一个seedseedseed spanspanspan bi=(sti,edi)b_i=(st_i,ed_i)bi=(sti,edi),通过concatconcatconcat内边界词,再通过MLPMLPMLP获得spanspanspan表示。接着,计算seedseedseed spanspanspan bi=(sti,edi)b_i=(st_i,ed_i)bi=(sti,edi)属于SpanProposalSpan ProposalSpanProposal的概率pifilterp^{filter}_ipifilter,计算公式如下:
hip=MaxPooling(hsti,hsti+1,...,hedi)h^p_i=MaxPooling(h_{st_i},h_{st_i+1},...,h_{ed_i}) hip=MaxPooling(hsti,hsti+1,...,hedi)
hifilter=[hip;hsti;hedi]h^{filter}_i=[h^p_i;h_{st_i};h_{ed_i}] hifilter=[hip;hsti;hedi]
pifilter=Sigmoid(MLP(hfilter))p^{filter}_i=Sigmoid(MLP(h^{filter})) pifilter=Sigmoid(MLP(hfilter))Boundary 回归器
尽管SpanProposalFilterSpan Proposal FilterSpanProposalFilter中的seedseedseed spanspanspan和groud−truthgroud-truthgroud−truth有较高的重合度,但是仍然不能准确定位实体,因此设计了另一个边界框回归器,通过调整左右 边界来定位实体。边界回归不仅需要spanspanspan本身的信息,还需要外部边界词的信息。通过拼接spanspanspan表示、边界词表示获得最终表示hiregh^{reg}_ihireg,然后计算左右边界的偏移,计算公式如下:
hireg=[hip;hsti−1;hedi−1]h^{reg}_i=[h^p_i;h_{st_i-1};h_{ed_i-1}] hireg=[hip;hsti−1;hedi−1]
ti=W2⋅GELU(W1hireg+b1)+b2t_i=W_2\cdot GELU(W_1h^{reg}_i+b_1)+b_2 ti=W2⋅GELU(W1hireg+b1)+b2
2.4 Entity Classifier Module
利用边界框回归器调整SpanProposalSpan ProposalSpanProposal的起始位置和结束位置,计算公式如下:
sti~=max(0,sti+∣til+12∣)\widetilde{st_i}=max(0,st_i+|t^l_i+\frac{1}{2}|) sti=max(0,sti+∣til+21∣)
sti~=max(L−1,edi+∣tir+12∣)\widetilde{st_i}=max(L-1,ed_i+|t^r_i+\frac{1}{2}|) sti=max(L−1,edi+∣tir+21∣)
通过拼接内部新边界词向量并进行最大池化获得新的spanspanspan向量,然后拼接新的spanspanspan向量、起始位置向量、结束位置向量,再通过MLPMLPMLP预测最终的类别,计算公式如下:
hip=MaxPooling(hsti,(hsti+1,...,hedi)h^p_i=MaxPooling(h_{st_i},(h_{st_i}+1,...,h_{ed_i}) hip=MaxPooling(hsti,(hsti+1,...,hedi)
hicls=[hip;hsti;hedi]h^{cls}_i=[{h}^p_i;h_{st_i};h_{ed_i}] hicls=[hip;hsti;hedi]
pi=Softmax(MLP(hicls))p_i=Softmax(MLP(h^{cls}_i)) pi=Softmax(MLP(hicls))
2.5 损失函数
span proposal 过滤器损失函数,计算如下:
Lfilter=−∑iwiⅡy^≠0(1−pifilter)γlog(pifilter)+wiⅡy^=0(pifilter)γlog(1−pifilter)L_{filter}=-\sum_{i}w_iⅡ_{\widehat{y}\neq0}(1-p^{filter}_i)^{\gamma}log(p^{filter}_i)+w_iⅡ_{\widehat{y}=0}(p^{filter}_i)^{\gamma}log(1-p^{filter}_i) Lfilter=−i∑wiⅡy=0(1−pifilter)γlog(pifilter)+wiⅡy=0(pifilter)γlog(1−pifilter)边界回归器损失函数,计算如下:
Lreg(t^,t)=Lf1+LolpL_{reg}(\widehat{t},t)=L_{f1}+L_{olp} Lreg(t,t)=Lf1+Lolp
Lf1(t^,t)=∑i∑j∈{l,r}smoothL1(t^ij,tij)L_{f1}(\widehat{t},t)=\sum_i\sum_{j\in\{l,r\}}smoothL1(\widehat{t}^j_i,t^j_i) Lf1(t,t)=i∑j∈{l,r}∑smoothL1(tij,tij)
Lolp=∑i(1−min(di)−max(ei)max(di)−min(ei))L_olp=\sum_i(1-\frac{min(d_i)-max(e_i)}{max(d_i)-min(e_i)}) Lolp=i∑(1−max(di)−min(ei)min(di)−max(ei))实体分类器损失函数,计算如下:
L=λ1Lfilter+λ2Lreg+λ3LclsL=\lambda_1{L_{filter}}+\lambda_2{L_{reg}}+\lambda_3{L_{cls}} L=λ1Lfilter+λ2Lreg+λ3Lcls
2.6 Entity Decoding
经过上述步骤,得到每个SpanProposalSpan ProposalSpanProposal的分类概率,边界偏移回归结果,将SpanProposalSpan ProposalSpanProposal中分类概率最大值作为其置信度,分类概率最大的labellabellabel作为其labellabellabel。然后采用Soft−NMSSoft-NMSSoft−NMS算法,去掉小于阈值的SpanProposalSpan ProposalSpanProposal。
三、Motivation
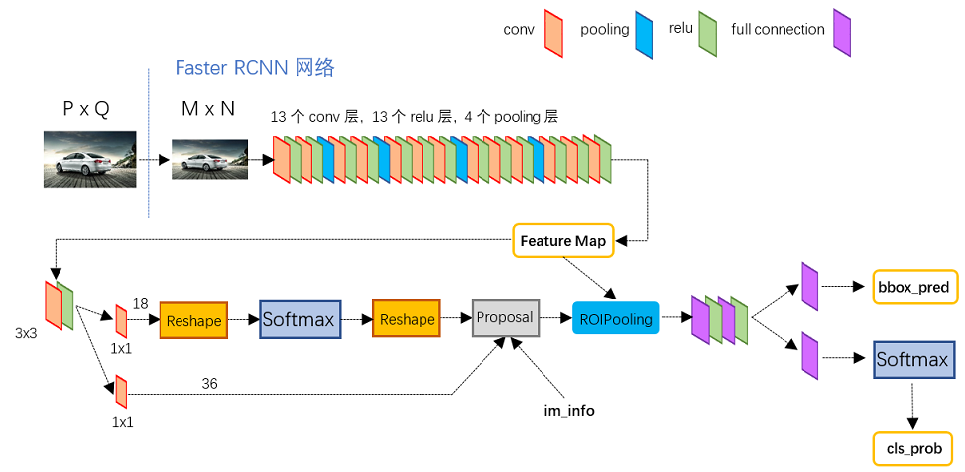
动机:作者的想法来自于两阶段目标检测方法。
![]()
FasterRCNNFaster RCNNFasterRCNN:输入图片->通过卷积神经网络产生特征图->在特征图上每一个点都放置了锚点->每个锚点都产生9个框[枚举所有可能性]
Two−stageIdentifierTwo-stage IdentifierTwo−stageIdentifier:输入文本->枚举所有的spanspanspanFasterRCNNFaster RCNNFasterRCNN:有两个分支,一个分类分支是用来区分框中是否有目标,另一个回归分支用来预测边界框和真实框的偏移量。
Two−stageIdentifierTwo-stage IdentifierTwo−stageIdentifier:有两个模块,一个SpanProposalSpan ProposalSpanProposal模块是用来区分是否是高质量的,另一个回归模块是用来预测spanspanspan起始和结束位置和真实起始和结束位置的偏移量。FasterRCNNFaster RCNNFasterRCNN:将有目标的ProposalProposalProposal通过回归模块的偏移量修正ProposalProposalProposal位置。
Two−stageIdentifierTwo-stage IdentifierTwo−stageIdentifier:将高质量的spanspanspan通过回归模块的偏移量修正spanspanspan位置。FasterRCNNFaster RCNNFasterRCNN:将修正过后的新的ProposalProposalProposal通过CNN预测其分类。
Two−stageIdentifierTwo-stage IdentifierTwo−stageIdentifier:将通修正过后的新的spanspanspan通过MLP预测其分类。
四、Experiment Settings
DatasetDatasetDataset
ACE 2004 and ACE 2005:嵌套数据集,包含7个实体类型,训练集、验证集、测试集比例为8:1:1。
KPB17:嵌套数据集,,包含7个实体类型,包含5个实体类型。
GENIA:生物学嵌套数据集。
EvaluationMetricsEvaluation MetricsEvaluationMetrics:当实体边界和实体标签同时正确,则视为正确。
annotationannotationannotation
{"tokens": ["2004-12-20T15:37:00", "Microscopic", "microcap", "Everlast", ",", "mainly", "a", "maker", "of", "boxing", "equipment", ",", "has", "soared", "over", "the", "last", "several", "days", "thanks", "to", "a", "licensing", "deal", "with", "Jacques", "Moret", "allowing", "Moret", "to", "buy", "out", "their", "women", "'s", "apparel", "license", "for", "$", "30", "million", ",", "on", "top", "of", "a", "$", "12.5", "million", "payment", "now", "."], "pos": ["JJ", "JJ", "NN", "NNP", ",", "RB", "DT", "NN", "IN", "NN", "NN", ",", "VBZ", "VBN", "IN", "DT", "JJ", "JJ", "NNS", "NNS", "TO", "DT", "NN", "NN", "IN", "NNP", "NNP", "VBG", "NNP", "TO", "VB", "RP", "PRP$", "NNS", "POS", "NN", "NN", "IN", "$", "CD", "CD", ",", "IN", "NN", "IN", "DT", "$", "CD", "CD", "NN", "RB", "."], "entities": [{"type": "ORG", "start": 1, "end": 4}, {"type": "ORG", "start": 5, "end": 11}, {"type": "ORG", "start": 25, "end": 27}, {"type": "ORG", "start": 28, "end": 29}, {"type": "ORG", "start": 32, "end": 33}, {"type": "PER", "start": 33, "end": 34}], "ltokens": ["Everlast", "'s", "Rally", "Just", "Might", "Live", "up", "to", "the", "Name", "."], "rtokens": ["In", "other", "words", ",", "a", "competitor", "has", "decided", "that", "one", "segment", "of", "the", "company", "'s", "business", "is", "potentially", "worth", "$", "42.5", "million", "."],"org_id": "MARKETVIEW_20041220.1537" }
五、Results and Comparisons
![]()
六、Code
【ACL 2021】Locate and Label A Two-stage Identifier for Nested Named Entity Recognition相关推荐
- 论文阅读笔记(三)【ACL 2021】Locate and Label: A Two-stage Identifier for Nested Named Entity
论文标题: Locate and Label: A Two-stage Identifier for Nested Named Entity Recognition 论文链接: https://arx ...
- 【论文分享】BERTifying the Hidden Markov Model for Multi-Source Weakly Supervised Named Entity Recognition
[ACL 2021]BERTifying 多源弱监督命名实体识别的隐马尔可夫模型 主要内容: ① 在有多源标签库需要使用的情况下,提出了一种条件隐马尔科夫模型,按token-wise转换和发射概率用于 ...
- 论文阅读笔记(五)【ACL 2021】Answering Ambiguous Questions through Generative Evidence Fusion and Round-Trip P
通过生成性证据融合和往返预测回答模糊问题 关键词: 生成性证据融合: 往返预测: 模糊问题 摘要 一般的开放域QA问题: 在开放域问答中,问题很可能是模棱两可的,因为用户在制定问题时可能不知道相关主题 ...
- 论文阅读笔记(四)【ACL 2021】FEW-NERD: A Few-shot Named Entity Recognition Dataset
摘要 过去的难点: 过去的都是粗粒度的: Few-NERD: 一个大规模的人类注释的小样本NERD数据集,它具有8种粗粒度和66种细粒度实体类型的层次结构.Few-NERD由来自维基百科的188238 ...
- 【AAAI 2021】全部接受论文列表(五)
来源:AINLPer微信公众号(点击了解一下吧) 编辑: ShuYini 校稿: ShuYini 时间: 2021-01-14 马上春节了,疫情又卷土而来,希望大家注意防护,爱护自己的身体 AAAI ...
- 【AAAI 2021】全部接受论文列表(二)
来源:AINLPer微信公众号(点击了解一下吧) 编辑: ShuYini 校稿: ShuYini 时间: 2021-01-14 马上春节了,疫情又卷土而来,希望大家注意防护,爱护自己的身体 AAAI ...
- 用代码,打造创意新世界!【Innovation 2021】网易应用创新开发者大赛正式开赛!
创新,是每个时代永恒不变的主题. 从「无」到「有」是创新.在对未知世界的探索中突破常规,创造了新的事物. 从「有」向「优」是创新.以 1 为始,迈进到 1.1 的改善优化,形成了新的进步. 从「优」至 ...
- 【AAAI 2021】自监督目标检测知识蒸馏:Distilling Localization for Self-Supervised Representation Learning
[AAAI 2021]自监督目标检测知识蒸馏:Distilling Localization for Self-Supervised Representation Learning 论文地址: 代码地 ...
- 【sketchup 2021】草图大师的高级工具使用2【材质贴图应用的基础功能和高级使用与实战演练(给地砖调整尺寸、转贴贴图圆柱为例、投影贴图百叶窗为例】
文章目录 不透明度.填充材质 材质贴图应用 基础功能 高级技巧 别针 蓝色别针[平行四边形别针] 红色别针[移动别针] 黄色别针[梯形别针] 绿色别针[旋转缩放别针] 别针位置调整 重设 镜像设置 旋 ...
最新文章
- golang ssh 远程登录执行命令
- TouTiao开源项目 分析笔记7 加载数据的过程
- collections deque队列及其他队列
- java点滴(6)之java引用
- google Guava包的ListenableFuture解析
- 不能用 + 拼接字符串? 这次我要吊打面试官!
- SpringBoot不支持webapp的解决办法
- 俄罗斯方块剖析之一总体计划
- php用什么电脑,我要学php了买一台什么配置的电脑最好?
- 错误记录( 六)tomcat 配置图片虚拟路径不起作用
- sql server 视图_SQL Server –具有引用视图的开发实践
- MATLAB中的max函数的用法及含义
- 在SQL-SERVER2000中对同一个数据库多张表进行查询时怎样避免笛卡儿乘积???...
- 评委移动端WebApp打分注意事项
- c++直方图匹配终极版,支持任意通道数(opencv版本)
- html光标效果,css鼠标光标样式
- 工作之外的闲暇时光(玩魔方)
- vmware virtual machine must be running in order to be migrated
- 罗技 k380快捷键
- 程序员抛弃大厂涌进工厂!南洋理工海归:这里上班比整天盯着电脑有意思的多!...