墙上绘图机器人_一个实现日常场景甚至故事的绘图机器人
墙上绘图机器人
If you were asked to draw a picture of several people in ski gear, standing in the snow, chances are you’d start with an outline of three or four people reasonably positioned in the center of the canvas, then sketch in the skis under their feet. Though it was not specified, you might decide to add a backpack to each of the skiers to jibe with expectations of what skiers would be sporting. Finally, you’d carefully fill in the details, perhaps painting their clothes blue, scarves pink, all against a white background, rendering these people more realistic and ensuring that their surroundings match the description. Finally, to make the scene more vivid, you might even sketch in some brown stones protruding through the snow to suggest that these skiers are in the mountains.
如果您被要求在雪地上画几个滑雪者的照片,您可能会先从三四个人的轮廓开始,然后将它们合理地定位在画布的中心,然后在滑雪者的下方素描脚。 尽管未指定,但您可以决定向每个滑雪者添加一个背包,以期对滑雪者的运动有所期待。 最后,您将仔细地填写细节,也许将他们的衣服涂成蓝色,围巾变成粉红色,并且都以白色为背景,从而使这些人更加逼真并确保其周围环境与描述相符。 最后,为使场景更加生动,您甚至可以草绘一些穿过雪地的棕色石头,以表明这些滑雪者在山上。
Now there’s a bot that can do all that.
现在有一个机器人可以做到所有这些。
New AI technology being developed at Microsoft Research AI can understand a natural language description, sketch a layout of the image, synthesize the image, and then refine details based on the layout and the individual words provided. In other words, this bot can generate images from caption-like text descriptions of everyday scenes. This deliberate mechanism produced a significant boost in generated image quality compared to the earlier state-of-the-art technique for text-to-image generation for complicated everyday scenes, according to results on industry standard tests reported in “Object-driven Text-to-Image Synthesis via Adversarial Training”, to be published this month in Long Beach, California at the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019). This is a collaboration project among Pengchuan Zhang, Qiuyuan Huang and Jianfeng Gao of Microsoft Research AI, Lei Zhang of Microsoft, Xiaodong He of JD AI Research, and Wenbo Li and Siwei Lyu of the University at Albany, SUNY (while Wenbo Li worked as an intern at Microsoft Research AI).
Microsoft Research AI正在开发的新AI技术可以理解自然的语言描述,绘制图像的布局,合成图像,然后根据布局和所提供的各个单词来细化细节。 换句话说,该机器人可以从类似于字幕的日常场景文字描述中生成图像。 根据“ 对象驱动的文字广告”中报告的行业标准测试结果,与较早的用于复杂日常场景的文字到图片生成的最新技术相比,这种故意的机制大大提高了生成的图片质量。 通过对抗训练进行图像合成 ”,本月将在加利福尼亚州长滩的2019 IEEE计算机视觉和模式识别会议 (CVPR 2019)上发表。 这是Microsoft Research AI的 Zhang Pengchuan , Huang Qiuyuan Gao和Gao Jianfeng , Microsoft的 Zhang Lei ,JD AI Research的Xiaodong He以及纽约州立大学奥尔巴尼分校的Wenwen Li和Siwei Lyu之间的合作项目(李文博担任Microsoft Research AI的实习生)。
There are two main challenges intrinsic to the description-based drawing bot problem. The first is that many kinds of objects can appear in everyday scenes and the bot should be able to understand and draw all of them. Previous text-to-image generation methods use image-caption pairs that only provide a very coarse-grained supervising signal for generating individual objects, limiting their object generation quality. In this new technology, the researchers make use of the COCO dataset that contains labels and segmentation maps for 1.5 million object instances across 80 common object classes, enabling the bot to learn both concept and appearance of these objects. This fine-grained supervised signal for object generation significantly improves generation quality for these common object classes.
基于描述的绘图机器人问题固有两个主要挑战。 首先是许多物体可以出现在日常场景中,并且机器人应该能够理解并绘制所有物体。 以前的文本到图像生成方法使用图像标题对,它们仅提供非常粗糙的监督信号来生成单个对象,从而限制了对象的生成质量。 在这项新技术中,研究人员利用了COCO数据集,该数据集包含跨80个常见对象类的150万个对象实例的标签和分段图,从而使该机器人可以学习这些对象的概念和外观。 用于对象生成的细粒度监督信号显着提高了这些常见对象类的生成质量。
The second challenge lies in the understanding and generation of the relationships between multiple objects in one scene. Great success has been achieved in generating images that only contain one main object for several specific domains, such as faces, birds, and common objects. However, generating more complex scenes containing multiple objects with semantically meaningful relationships across those objects remains a significant challenge in text-to-image generation technology. This new drawing bot learned to generate layout of objects from co-occurrence patterns in the COCO dataset to then generate an image conditioned on the pre-generated layout.
第二个挑战在于理解和生成一个场景中多个对象之间的关系。 在生成仅包含多个特定领域的一个主要对象的图像(例如人脸,鸟类和常见对象)方面已取得了巨大的成功。 但是,在文本到图像生成技术中,生成包含多个对象且在这些对象之间具有语义上有意义的关系的更复杂的场景仍然是一项重大挑战。 这个新的绘图机器人学会了从COCO数据集中的共现模式生成对象的布局,然后生成以预生成的布局为条件的图像。
对象驱动的注意力图像生成 (Object-driven attentive image generation)
At the core of Microsoft Research AI’s drawing bot is a technology known as the Generative Adversarial Network, or GAN. The GAN consists of two machine learning models—a generator that generates images from text descriptions, and a discriminator that uses text descriptions to judge the authenticity of generated images. The generator attempts to get fake pictures past the discriminator; the discriminator on the other hand never wants to be fooled. Working together, the discriminator pushes the generator toward perfection.
Microsoft Research AI的绘图机器人的核心是一种称为对抗性生成网络(GAN)的技术。 GAN由两个机器学习模型组成-一个从文本描述生成图像的生成器,以及一个使用文本描述判断生成图像的真实性的鉴别器。 生成器尝试使伪造的图片经过鉴别器; 另一方面,歧视者从不希望被愚弄。 鉴别器共同作用,将发生器推向完美。
The drawing bot was trained on a dataset of 100,000 images, each with salient object labels and segmentation maps and five different captions, allowing the models to conceive individual objects and semantic relations between objects. The GAN, for example, learns how a dog should look like when comparing images with and without dog descriptions.
该绘图机器人在100,000个图像的数据集上进行了训练,每个图像上都带有显着的对象标签和分割图以及五个不同的标题,从而使模型可以构思单个对象以及对象之间的语义关系。 例如,GAN可以在比较带有和不带有狗描述的图像时,了解狗的外观。

Figure 1: A complex scene with multiple objects and relationships.
图1:具有多个对象和关系的复杂场景。
GANs work well when generating images containing only one salient object, such as a human face, birds or dogs, but quality stagnates with more complex everyday scenes, such a scene described as “A woman wearing a helmet is riding a horse” (see Figure 1.) This is because such scenes contain multiple objects (woman, helmet, horse) and rich semantic relations between them (woman wear helmet, woman ride horse). The bot first must understand these concepts and place them in the image with a meaningful layout. After that, a more supervised signal capable of teaching the object generation and the layout generation is required to fulfill this language-understanding-and-image-generation task.
当生成仅包含一个显着物体(例如人脸,鸟或狗)的图像时,GAN可以很好地工作,但是高质量的图像会停滞在更复杂的日常场景中,这种场景被描述为“戴头盔的女人骑着马”(见图) 1.)这是因为这样的场景包含多个对象(女人,头盔,马)和它们之间的丰富语义关系(女人戴头盔,女人骑马)。 机器人首先必须理解这些概念,并以有意义的布局将它们放置在图像中。 此后,需要一个能够指导对象生成和布局生成的更加监督的信号来完成此语言理解和图像生成任务。
As humans draw these complicated scenes, we first decide on the main objects to draw and make a layout by placing bounding boxes for these objects on the canvas. Then we focus on each object, by repeatedly checking the corresponding words that describe this object. To capture this human trait, the researchers created what they called an Object-driven attentive GAN, or ObjGAN, to mathematically model the human behavior of object centered attention. ObjGAN does this by breaking up the input text into individual words and matching those words to specific objects in the image.
当人类绘制这些复杂的场景时,我们首先通过在画布上放置这些对象的边界框来确定要绘制的主要对象并进行布局。 然后,我们通过重复检查描述该对象的相应单词来关注每个对象。 为了捕捉这种人类特征,研究人员创建了他们所谓的“对象驱动的专注GAN”或“ ObjGAN”,以数学方式模拟了以对象为中心的注意力的人类行为。 ObjGAN通过将输入文本分解为单个单词并将这些单词与图像中的特定对象进行匹配来实现。
Humans typically check two aspects to refine the drawing: the realism of individual objects and the quality of image patches. ObjGAN mimics this behavior as well by introducing two discriminators—one object-wise discriminator and one patch-wise discriminator. The object-wise discriminator is trying to determine whether the generated object is realistic or not and whether the object is consistent with the sentence description. The patch-wise discriminator is trying to determine whether this patch is realistic or not and whether this patch is consistent with the sentence description.
人们通常会检查两个方面来完善绘图:单个对象的真实感和图像斑块的质量。 ObjGAN还通过引入两个鉴别符(一个是面向对象的鉴别符和一个是基于补丁的鉴别符)来模仿此行为。 逐个对象的鉴别器试图确定所生成的对象是否现实,以及该对象是否与句子描述一致。 逐块鉴别器试图确定此补丁是否现实,以及该补丁是否与句子描述一致。
相关工作:故事可视化 (Related work: Story visualization)
State-of-the-art text-to-image generation models can generate realistic bird images based on a single-sentence description. However, text-to-image generation can go far beyond synthesis of a single image based on one sentence. In “StoryGAN: A Sequential Conditional GAN for Story Visualization”, Jianfeng Gao of Microsoft Research, along with Zhe Gan, Jingjing Liu and Yu Cheng of Microsoft Dynamics 365 AI Research, Yitong Li, David Carlson and Lawrence Carin of Duke University, Yelong Shen of Tencent AI Research and Yuexin Wu of Carnegie Mellon University go a step further and propose a new task, called Story Visualization. Given a multi-sentence paragraph, a full story can be visualized, generating a sequence of images, one for each sentence. This is a challenging task, as the drawing bot is not only required to imagine a scenario that fits the story, model the interactions between different characters appearing in the story, but it also must be able to maintain global consistency across dynamic scenes and characters. This challenge has not been addressed by any single image or video generation methods.
最新的文本到图像生成模型可以基于单句描述生成逼真的鸟图像。 但是,文本到图像的生成远远超出了基于一个句子合成单个图像的范围。 在“ StoryGAN:用于故事可视化的顺序条件GAN ”中,Microsoft Research的高剑锋 ,以及Microsoft Dynamics 365 AI Research的Gan Zhe,Liu Jingjing和Yu Cheng,杜克大学的Yiyi Li,David Carlson和Lawrence Carin,沉业龙腾讯AI Research的研究人员和卡内基梅隆大学的Wu Yuexin Wu进一步提出了一项新的任务,即故事可视化。 给定一个多句段,可以使整个故事可视化,生成一系列图像,每个句子一个。 这是一项艰巨的任务,因为绘图机器人不仅需要想象一个适合故事的场景,为故事中出现的不同角色之间的交互建模,而且还必须能够在动态场景和角色之间保持全局一致性。 任何单一的图像或视频生成方法都没有解决这一挑战。
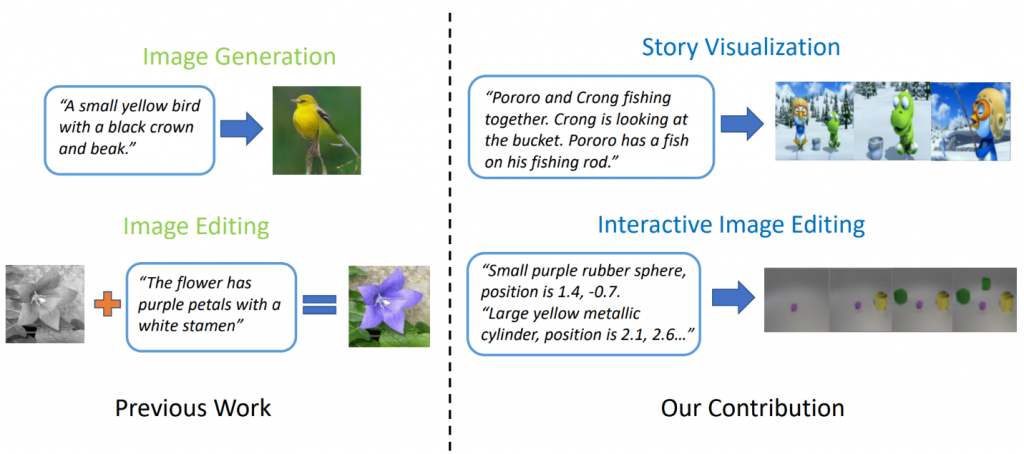
Figure 2: Story visualization vs. simple image generation.
图2:故事可视化与简单图像生成。
The researchers came up with a new story-to-image-sequence generation model, StoryGAN, based on the sequential conditional GAN framework. This model is unique in that it consists of a deep Context Encoder that dynamically tracks the story flow, and two discriminators at the story and image levels to enhance the image quality and the consistency of the generated sequences. StoryGAN also can be naturally extended for interactive image editing, where an input image can be edited sequentially based on the text instructions. In this case, a sequence of user instructions will serve as the “story” input. Accordingly, the researchers modified existing datasets to create the CLEVR-SV and Pororo-SV datasets, as shown in the Figure 2.
研究人员根据顺序条件GAN框架提出了一个新的故事到图像序列生成模型StoryGAN。 该模型的独特之处在于它包括一个动态跟踪故事流程的深层上下文编码器,以及故事和图像级别的两个鉴别器,以增强图像质量和所生成序列的一致性。 StoryGAN还可以自然扩展为交互式图像编辑,其中可以根据文本指令顺序编辑输入图像。 在这种情况下,一系列用户指令将用作“故事”输入。 因此,研究人员修改了现有数据集以创建CLEVR-SV和Pororo-SV数据集,如图2所示。
实际应用–真实故事 (Practical applications – a real story)
Text-to-image generation technology could find practical applications acting as a sort of sketch assistant to painters and interior designers, or as a tool for voice-activated photo editing. With more computing power, the researchers imagine the technology generating animated films based on screenplays, augmenting the work that animated filmmakers do by removing some of the manual labor involved.
文本到图像生成技术可以找到实际的应用程序,充当画家和室内设计师的素描助手,或者用作声控照片编辑的工具。 研究人员可以想象,凭借更高的计算能力,该技术可以根据电影剧本生成动画电影,从而消除了一些体力劳动,从而使动画电影制片人的工作更加丰富。
For now, the generated images are still far away from photo realistic. Individual objects almost always reveal flaws, such as blurred faces and or buses with distorted shapes. These flaws are a clear indication that a computer, not a human, created the images. Nevertheless, the quality of the ObjGAN images is significantly better than previous best-in-class GAN images and serve as a milestone on the road toward a generic, human-like intelligence that augments human capabilities.
目前,生成的图像距离照片逼真还很远。 单个对象几乎总会显示出瑕疵,例如模糊的面Kong和/或形状失真的公共汽车。 这些缺陷清楚地表明,是由计算机而非人创造的图像。 尽管如此,ObjGAN图像的质量明显优于以前的同类最佳GAN图像,并且是通向增强人类能力的类人通用智能道路上的里程碑。
For AIs and humans to share the same world, each must have a way to interact with the other. Language and vision are the two most important modalities for humans and machines to interact with each other. Text-to-image generation is one important task that advances language-vision multi-modal intelligence research.
为了使AI和人类共享同一个世界,彼此之间必须有一种相互交流的方式。 语言和视觉是人机交互的两个最重要的方式。 文本到图像的生成是推进语言视觉多模式智能研究的一项重要任务。
The researchers who created this exciting work look forward to sharing these findings with attendees at CVPR in Long Beach and hearing what you think. In the meantime, please feel free to check out their open-source code for ObjGAN and StoryGANon GitHub
创造了这项令人兴奋的工作的研究人员期待与长滩CVPR的与会者分享这些发现,并听听您的想法。 同时,请随时在GitHub上查看其针对ObjGAN和StoryGAN的开源代码
翻译自: https://habr.com/en/company/microsoft/blog/457200/
墙上绘图机器人
墙上绘图机器人_一个实现日常场景甚至故事的绘图机器人相关推荐
- 中科佑铭机器人_一个月连开四个班!犀灵机器人口碑炸裂,值得信赖!
一.凭什么工业机器人工程师能成为现代制造业的新宠 7月,一个艳阳高照的季节 热浪滚滚的天气一度点燃了人们对机器人学习的热情 在佛山 中国(广东)机器人集成创新中心犀灵机器人培训学院 一群怀报理想的青年 ...
- 电报群组导航机器人_优必选周剑:All in 机器人,你不感性一点、轴一点怎么行?...
一个机械爱好者是怎么成为中国人形机器人之父的? 说起机器人,科幻电影和小说里刻画的精彩场面,常被人津津乐道.8 年前,周剑创立优必选的初衷,就是奔着理想中的机器人去的.热播美剧<西部世界> ...
- coji小机器人_让孩子学做程序员 Coji编程机器人体验
原标题:让孩子学做程序员 Coji编程机器人体验 玩具机器人可能每个孩子小时候的梦想,不过对于90后小编来说,小时候见过的所谓"机器人"好像最多也就是那种可遥控移动或放音乐的电子玩 ...
- 饿了吗上的扫地机器人_啥!饿了么的智能外卖机器人“万小饿”宛如扫地机器人+保温桶?...
那究竟"万小饿"是怎么送外卖的呢? 首先得搞清楚一点,就是"万小饿"并不是把外卖直接从商家送到买家手里,而是外卖小哥先把外卖送到某栋大楼,然后把外卖交给&quo ...
- 乐迪智能陪伴机器人_【团品】AI未来人工智能陪伴机器人(爆款复团)
每日一团 今日AI未来人工智能陪伴机器人复团啦 一款儿童智能陪护机器人 基于超脑技术 搭载类人脑TYOS系统 可以做到像人类一样思考学习 买一个让它更好的陪伴孩子健康成长 智能机器人内含 语音聊天,中 ...
- 草履虫纳米机器人_《Nature》:草履虫大小的微型机器人:由激光驱动,未来可用于显微外科手术!...
原标题:<Nature>:草履虫大小的微型机器人:由激光驱动,未来可用于显微外科手术! 江苏激光联盟导读: 据悉,<Nature>报道了美国康奈尔大学的最新研究成果,该校研究人 ...
- 第一个被赋予公明身份的机器人_索菲亚成为首位被授予公民身份的机器人
原标题:索菲亚成为首位被授予公民身份的机器人 图片来源:视觉中国 近日,汉森公司打造的机器人索菲亚被授予了沙特阿拉伯的公民身份.机器人索菲亚由位于香港的汉森机器人公司打造.人工智能系统使索菲亚可以辨别 ...
- Leetcode:62题 不同路径(一个机器人位于一个 m x n 网格的左上角 。 机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角)
题目: 一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为"Start" ). 机器人每次只能向下或者向右移动一步.机器人试图达到网格的右下角(在下图中标记为&q ...
- 非标自动化转行机器人_怎样将非标自动化经验应用到机器人自动化- 智造家
所谓的"机器人自动化"是指以多关节工业机器人为中心实现工业自动化生产的模式.它与传统的非标自动化生产设备相比有其独特的特点,了解这些特点,发挥机器人的优势是非标自动化工程师的一直想 ...
最新文章
- 讲故事,学内存--Oracle
- mybatis 调用 oracle 存储过程 select into 无记录时NO_DATA_FOUND异常处理分析
- mysql的增_MySQL-----增
- 1063. Set Similarity (25)
- Ubuntu16.04安装Xtion驱动并测试使用
- C++子类父类构造函数的关系
- java爬虫怎么确定url连接_Java爬虫之抓取一个网站上的全部链接
- 基于Netty的百万级推送服务设计要点
- 揭秘阿里机器翻译团队:拿下5项全球冠军,每天帮商家翻译7.5亿次
- (转)Android--sharepreference总结
- 8-1-Filter过滤器
- C++嵌入Python,以及两者混用
- SecureCRT自动化脚本编写
- 3.27 期货每日早盘操作建议
- Unity Shader UV动画之高光材质加上透明材质与UV动画
- 百度地图离线开发2.0
- 内存按字节 (Byte)编址,地址从A0000H到DFFFFH,共有多少个字节呢?
- 表单提交成功后重置表单
- 手机电子邮件用outlook登录
- win10的IE闪退及“启用或关闭windows功能”里没有IE选项