《计算机科学概论》—第3章3.3节文本表示法
本节书摘来自华章出版社《计算机科学概论》一书中的第3章,第3.3节文本表示法,作者[美]内尔·黛尔(Nell Dale)约翰·路易斯(John Lewis),更多章节内容可以访问云栖社区“华章计算机”公众号查看。
3.3 文本表示法
一个文本文档可以被分解为段落、句子、词和最终的单个字符。要用数字形式表示文本文档,只需要表示每个可能出现的字符。文档是连续(模拟)的实体,独立的字符则是离散的元素,它们才是我们要表示并存储在计算机内存中的。
现在,我们应该区分文本表示法的基本想法和文字处理的概念。当用Microsoft Word这样的字处理程序创建文档时,可以设置各种格式,包括字体、页边距、制表位、颜色等。 许多字处理程序还允许在文档中加入自选图形、公式和其他元素。这些额外信息与文本存储在一起,以便文档能够正确地显示和打印出来。但核心问题是如何表示字符本身,因此,目前我们把重点放在表示字符的方法上。
要表示的字符数是有限的。一种表示字符的普通方法是列出所有字符,然后赋予每个字符一个二进制字符串。例如,要存储一个特定的字母,我们将保存它对应的位串。
那么需要表示哪些字符呢?在英语中,有26个字母,但必须有区别地处理大写字母和小写字母,所以实际上有52个字母。与数字(0、1到9)一样,各种标点符号也需要表示。即使是空格,也需要有自己的表示法。那么对于非英语的语言又如何呢?一旦你考虑到这一点,那么我们想表示的字符数就会迅速增长。记住,我们在本章的前面讨论过,要表示的状态数决定了需要多少位来表示一种状态。
字符集只是字符和表示它们的代码的清单。这些年来,出现了多种字符集,但只有少数的几种处于主导地位。在计算机制造商就关于使用哪种字符集达成一致后,文本数据的处理变得容易多了。在接下来的小节中,我们将介绍两种字符集,即ASCII字符集和Unicode字符集。
字符集(character set):字符和表示它们的代码的清单。
3.3.1 ASCII字符集
ASCII是美国信息交换标准代码(American Standard Code for Information Interchange)的缩写。最初,ASCII字符集用7位表示每个字符,可以表示128个不同的字符。每个字节中的第八位最初被用作校验位,协助确保数据传输正确。之后,ASCII字符集进化了,用8位表示每个字符。这个8位版本的正式名字是Latin-1扩展ASCII字符集。该扩展字符集可以表示256个字符,包括一些重点字符和几个补充的特殊符号。图3-5展示了完整的ASCII字符集。
**字符集迷宫
1960年,一篇关于ACM通信的文章报道了字符集使用的调查,描述了60个不同的字符集。仅仅IBM公司的电脑生产线中,就存在9个内容和顺序都不同的字符集。**[1]

这个图表中的代码是用十进制数表示的,但计算机存储这些代码时,将把它们转换成相应的二进制数。注意,每个ASCII字符都有自己的顺序,这是由存储它们所用的代码决定的。每个字符都有一个相对于其他字符的位置(在其他字符之前或之后)。这个属性在许多方面都很有用。例如,可以利用字符代码对一组单词按照字母顺序排序。
这个图表中的前32个ASCII字符没有简单的字符表示法,不能输出到屏幕上。这些字符是为特殊用途保留的,如回车符和制表符,处理数据的程序会用特定的方式解释它们。
3.3.2 Unicode字符集
ASCII字符集的扩展版本提供了256个字符,虽然足够表示英语,但是却无法满足国际需要。这种局限性导致了Unicode字符集的出现,这种字符集具有更强大的国际影响。
Unicode的创建者的目标是表示世界上使用的所有语言中的所有字符,包括亚洲的表意符号。此外,它还表示了许多补充的专用字符,如科学符号。
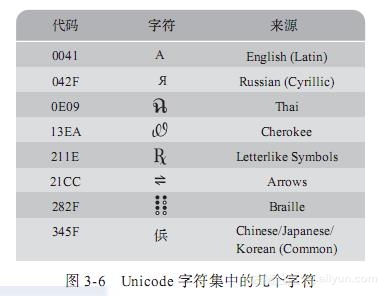
现在,Unicode字符集被许多程序设计语言和计算机系统采用。一般情况下,每个字符的编码都为16位,但也是十分灵活的,如果需要的话每个字符可以使用更多空间,以便表示额外的字符。Unicode字符集的一个方便之处就是它把ASCII字符集作为了一个子集。图3-6展示了Unicode字符集中非ASCII部分的几个字符。
为了保持一致,Unicode字符集被设计为ASCII的超集。也就是说,Unicode字符集中的前256个字符与扩展ASCII字符集中的完全一样,表示这些字符的代码也一样。因此,即使底层系统采用的是Unicode字符集,采用ASCII值的程序也不会受到
影响。
3.3.3 文本压缩
字母信息(文本)是一种基本数据类型。因此,找到存储这种信息以及有效地在两台计算机之间传递它们的方法是很重要的。下面的小节将分析三种文本压缩类型:
- 关键字编码
- 行程长度编码
- 赫夫曼编码
在本章后面的小节中我们还会谈到,这些文本压缩方法的基本思想也适用于其他类型的数据。
关键字编码
想想你在英语中使用“the”“and”“which”“that”和“what”的频率。如果这些单词占用更少的空间(即用更少的字符表示),文档就会减小。即使每个单词节省的空间都很少,但因它们在典型的文档中太常用,所以节省出的总空间还是很可观的。
一种相当直接的文本压缩方法是关键字编码,它用单个字符代替了常用的单词。要解压这种文档,需要采用压缩的逆过程,即用相应的完整单词替换单个字符。
关键字编码(keyword encoding):用单个字符代替常用的单词。
例如,假设我们用下列图表对几个单词编码:
单 词 符 号 单 词 符 号
as ^ must &
the ~ well %
and + these #
that $

让我们对下列段落编码:
The human body is composed of many independent systems, such as the circulatory system, the respiratory system, and the reproductive system. Not only must all systems work independently, but they must interact and cooperate as well. Overall health is a function of the well-being of separate systems, as well as how these separate systems work in concert.
编码后的段落如下:
The human body is composed of many independent systems, such ^ ~ circulatory system, ~
respiratory system, + ~ reproductive system. Not only & each system work independently, but they & interact + cooperate ^ %. Overall health is a function of ~ %-being of separate systems, ^ % ^ how # separate systems work in concert.
原始段落总共有352个字符,包括空格和标点。编码后的段落包括317个字符,节省了35个字符。这个例子的压缩率是317/352,或约为0.9。
关键字编码有几点局限性。首先,用来对关键字编码的字符不能出现在原始文本中。例如,如果原始段落中包括“$”,那么生成的编码就会有歧义。我们不知道“$”表示的是单词“that”还是真正的美元符号。这限制了能够编码的单词数和要编码的文本的特性。
**昂贵的一晚
如果你曾入住假日酒店、假日快捷酒店或者皇冠假日酒店并在2002年10月24日到10月26日之间结账离开,那么你就很可能是被多收100倍价钱的26?000人中的一个,有些地方收费达到了每晚6500到21?000美元,小数点的删除导致了信用卡处理的错误。**
此外,示例中的单词“The”没有被编码为字符“~”,因为“The”与“the”不是同一个单词。记住,在计算机上存储的字母的大写版本和小写版本是不同的字符。如果想对“The”编码,就必须使用另一个符号,或者采用更加复杂的替换模式。
最后,不要对“a”和“I”这样的单词编码,因为那不过是用一个字符替换另一个字符。单词越长,每个单词的压缩率就越高。遗憾的是,常用的单词通常都比较短。另一方面,有些文档使用某些单词比使用其他单词频繁,这是由文档的主题决定的。例如,在我们的示例中,如果对单词“system”编码,将节省很多空间,但在通常情况下,并不值得对它编码。
关键字编码的一种扩展是用特殊字符替换文本中的特定模式。被编码的模式通常不是完整的单词,而是单词的一部分,如通用的前缀和后缀“ex”“ing”和“tion”。这种方法的一个优点是被编码的模式通常比整个单词出现的频率更高,但缺点同前,即被编码的通常是比较短的模式,对每个单词来说,替换它们节省的空间比较少。
行程长度编码
在某些情况下,一个字符可能在一个长序列中反复出现。在英语文本中,这种重复不常见,但在大的数据流(如DNA序列)中,这种情况则经常出现。一种名为行程长度编码的文本压缩技术利用了这种情况。行程长度编码有时又称为迭代编码。
在行程长度编码中,重复字符的序列将被替换为标志字符,后面加重复字符和说明字符重复次数的数字。例如,下面的字符串由7个A构成:
AAAAAAA
如果用*作为标志字符,这个字符串可以被编码为:
*A7
行程长度编码(run-length encoding):把一系列重复字符替换为它们重复出现的次数。
标志字符说明这三个字符的序列应该被解码为相应的重复字符串,其他文本则按照常规处理。因此,下面的编码字符串
n5x9ccch6 some other text k8eee
将被解码为如下的原始文本:
nnnnnxxxxxxxxxccchhhhhh some other text kkkkkkkkeee
原始文本包括51个字符,编码串包括35个字符,所以这个示例的压缩率为35/51,或约为0.68。
注意,这个例子中有三个重复的c和三个重复的e都没有编码。因为需要用三个字符对这样的重复序列编码,所以对长度为2或3的字符串进行编码是不值得的。事实上,如果对长度为2的重复字符串编码,反而会使结果串更长。
因为我们用一个字符记录重复的次数,所以看来不能对重复次数大于9的序列编码。但是,在某些字符集中,一个字符是由多个位表示的。例如,字符“5”在ASCII字符集中表示为53,这是一个八位的二进制字符串00110101。因此,我们将次数字符解释为一个二进制数,而不是解释为一个ASCII数字。这样一来,能够编码的重复字符的重复次数可以是0到255的任何数,甚至可以是4到259的任何数,因为长度为2或3的序列不会被
编码。
赫夫曼编码
另一种文本压缩技术是赫夫曼编码,以它的创建者David Huffman博士的名字命名。文本中很少使用字母“X”,那么为什么要让它占用的位数与常用空格字符一样呢?赫夫曼编码使用不同长度的位串表示每个字符,从而解决了这个问题。也就是说,一些字符由5位编码表示,一些字符由6位编码表示,还有一些字符由7位编码表示,等等。这种方法与字符集的概念相反,在字符集中,每个字符都由定长(如8位或16位)的位串表示。
这种方法的基本思想是用较少的位表示经常出现的字符,而将较长的位串留给不经常出现的字符,这样表示的文档的整体大小将比较小。
赫夫曼编码(Huffman encoding):用变长的二进制串表示字符,使常用的字符具有较短的编码。
例如,假设用下列赫夫曼编码来表示一些字符:

那么单词DOORBELL的二进制编码如下:
1011110110111101001100100
如果使用定长位串(如8位)表示每个字符,那么原始字符串的二进制形式应该是8个字符×8位= 64位。而这个字符串的赫夫曼编码的长度是25位,从而压缩率为25/64,或约为0.39。
那么解码过程是怎样的呢?在使用字符集时,只要把二进制串分割成8位或16位的片段,然后查看每个片段表示的字符即可。在赫夫曼编码中,由于编码是变长的,我们不知道每个字符对应多少位编码,所以看似很难将一个字符串解码。其实,创建编码的方式已经消除了这种潜在的困惑。
赫夫曼编码的一个重要特征是用于表示一个字符的位串不会是表示另一个字符的位串的前缀。因此,在从左到右扫描一个位串时,每当发现一个位串对应于一个字符,那么这个位串就一定表示这个字符,该位串不可能是更长位串的前缀。
例如,如果下列位串是用上面的表创建的:
1010110001111011
那么它只会被解码为单词BOARD,没有其他的可能性。
那么,赫夫曼编码是如何创建的呢?虽然创建赫夫曼编码的详细过程不属于本书的介绍范围,但是我们可以讨论一下要点。由于赫夫曼编码用最短的位串表示最常用的字符,所以首先需要列出要编码的字符的出现频率。出现频率可以是字符在某个特定文档中出现的次数(如352个E、248个S等),也可以是字符在来自特定领域的示例文本中出现的次数。频率表则列出了字母在一种特定语言(如英语)中出现的频率。使用这些频率,可以构建一种二进制代码的结构。创建这种结构的方法确保了最常用的字符对应于最短的位串。
《计算机科学概论》—第3章3.3节文本表示法相关推荐
- 《计算机科学概论》—第2章2.2节位置记数法
本节书摘来自华章出版社<计算机科学概论>一书中的第2章,第2.2节位置记数法,作者[美]内尔·黛尔(Nell Dale)约翰·路易斯(John Lewis),更多章节内容可以访问云栖社区& ...
- 《计算机科学概论》—第3章3.2节数字数据表示法
本节书摘来自华章出版社<计算机科学概论>一书中的第3章,第3.2节数字数据表示法,作者[美]内尔·黛尔(Nell Dale)约翰·路易斯(John Lewis),更多章节内容可以访问云栖社 ...
- 《计算机科学概论(第12版)》—第0章0.3节学习大纲
本节书摘来自异步社区<计算机科学概论(第12版)>一书中的第0章0.3节学习大纲,作者[美]J. 格伦•布鲁克希尔(J. Glenn Brookshear) , 丹尼斯•布里罗(Denni ...
- 《计算机科学概论》—第1章1.3节计算工具与计算学科
本节书摘来自华章出版社<计算机科学概论>一书中的第1章,第1.3节计算工具与计算学科,作者[美]内尔·黛尔(Nell Dale)约翰·路易斯(John Lewis),更多章节内容可以访问云 ...
- 《计算机科学概论(第12版)》—第1章1.10节通信差错
本节书摘来自异步社区<计算机科学概论(第12版)>一书中的第1章1.10节通信差错,作者[美]J. 格伦•布鲁克希尔(J. Glenn Brookshear) , 丹尼斯•布里罗(Denn ...
- 《计算机科学概论》—第1章1.2节计算的历史
本节书摘来自华章出版社<计算机科学概论>一书中的第1章,第1.2节计算的历史,作者[美]内尔·黛尔(Nell Dale)约翰·路易斯(John Lewis),更多章节内容可以访问云栖社区& ...
- 《计算机科学概论》读书笔记
<计算机科学概论>第十版 一.第一章 1.布尔运算:假设0代表假值,1代表真值,这样对位的运算看作是对真.假值的操作:则将处理真/假值运算命名为布尔运算 布尔运算包含3种基本运算:与.或. ...
- 计算机科学概论读后感
计算机科学概论 用了很长时间,通读了一遍<计算机科学概论>第12版,首先说一下整体印象,在计算机科学层面,老外的书比国内的某些"大教授"编写的教科书明显不是一个档次,老 ...
- 我读《计算机科学概论》第12版 J.Gleen.Brookshear Dennis Brylow
用了很长时间,通读了一遍<计算机科学概论>第12版,首先说一下整体印象,在计算机科学层面,老外的书比国内的某些"大教授"编写的教科书明显不是一个档次,老外用通俗易懂的语 ...
最新文章
- 小程序页面跳转传参参数值为url时参数时 会出现丢失
- (0080)iOS开发之上传本地项目到github
- BitBlt和StretchBlt的区别
- .net和php 哪个难,对于ASP.NET和PHP的性能对比
- 小学计算机课程表说课稿,小学信息技术《制作课程表》说课稿.doc
- 转使用jQuery Ajax的内存回收
- Unity3d常用插件
- 逼自己玩命学了3个多月,吃透了Python技术核心!分享给你
- TurnipBit开发板DIY呼吸的吃豆人教程实例
- 数据治理方案技术调研 Atlas VS Datahub VS Amundsen
- 关于获取安卓手机MAC地址的问题
- 解决Chrome插件安装时程序包无效:CRX_HEADER_INVALID
- 网址导航哪个好(最好的导航网站)
- 怎么彻底删除手机上的微信聊天记录?百看不如一试的删除方法!
- android studio记账,Android Studio——记账本以及图表可视化实现
- HTML+JS 前端雪花飘落
- Normal模式下ASM中的空间参数解析
- 8款炫酷的HTML5特效源码
- 实例比较单精度浮点型,双精度浮点型运算结果精度
- type-c转type A 3.0线以及otg线序
热门文章
- 【算法系列之九】合并两个有序数组
- java使用三种循环打印99表_编程题:利用for循环打印 9*9 表
- 关于“三门问题”的一些想法
- 剑指offer:22-25记录
- ArrayList和HashMap遍历比较
- xvid 详解 代码分析 编译等
- springCloud - 第4篇 - 消费者调用服务 ( Feign )
- 解决:Cannot read property ‘component‘ of undefined ( 即 vue-router 0.x 转化为 2.x)
- CSS 中 的 margin、border、padding 区别 (内边距、外边距)
- Intellij IDEA Debug调试技巧