海量数据寻找最频繁的数据_在数据中寻找什么
海量数据寻找最频繁的数据
Some activities are instinctive. A baby doesn’t need to be taught how to suckle. Most people can use an escalator, operate an elevator, and open a door instinctively. The same isn’t true of playing a guitar, driving a car, or analyzing data. Once you get comfortable with what to look for in a data set, you’ll find data analysis can be as much fun as playing a guitar or driving a car.
有些活动是本能的。 不需要教婴儿如何哺乳。 大多数人可以本能地使用自动扶梯,操作电梯和开门。 弹吉他,开汽车或分析数据并非如此。 一旦您对数据集中的内容感到满意,就会发现数据分析和弹吉他或开车一样有趣。
目的 (Objective)
When faced with new data, the first thing to consider is the objective you, your boss, or your client have in analyzing the dataset. Consider these four possibilities, three are comparatively easy and one is a relative challenge.
面对新数据时,首先要考虑的是您,您的老板或客户在分析数据集时要达到的目标。 考虑这四种可能性 ,三种相对容易,一种相对挑战。
Conduct a Specific Analysis — Your client only wants you to conduct a specific analysis, perhaps like descriptive statistics or a statistical test between two groups. No problem, just conduct the analysis. There’s no need to go further. That’s easy.
进行特定分析 -您的客户只希望您进行特定分析,例如描述性统计或两组之间的统计检验。 没问题,只需进行分析即可。 无需进一步。 这很简单。
Answer a Specific Question — Some clients only want one thing — answer a specific question. Maybe it’s something like “is my water safe to drink” or “is traffic on my street worse on Wednesdays.” This will require more thought and perhaps some experience, but again, you have a specific direction to go in. That makes it easier.
回答一个特定的问题 -有些客户只想要一件事-回答一个特定的问题。 可能是“我的水可以安全饮用”或“星期三街道上的交通情况是否更糟”。 这将需要更多的思考和也许的一些经验,但是同样,您有一个特定的方向可以进入。这使它更容易。
Address a General Need — Projects with general goals often involve model building. You’ll have to establish whether they need a single forecast, map or model, or a tool that can be used again in the future. This will require quite a bit of thought and experience but at least you know what you need to do and where you need to end up. Not easy but straightforward.
解决一般需求 -具有一般目标的项目通常涉及模型构建。 您必须确定他们是否需要单个预测,地图或模型,或者需要将来可以再次使用的工具。 这将需要大量的思想和经验,但是至少您知道您需要做些什么以及最终需要去哪里。 不容易,但直接。
Explore the Unknown — Every once in a while, a client will have nothing specific in mind, but will want to know whatever can be determined from the dataset. This is a challenge because there’s no guidance for where to start or where to finish. This blog will help you address this objective.
探索未知 -每隔一段时间,客户就不会有什么特别的主意,但希望知道可以从数据集中确定的内容。 这是一个挑战,因为没有关于从哪里开始或从哪里结束的指导。 该博客将帮助您解决此目标。
If your client is not clear about their objective, start at the very end. Ask what decisions will need to be made based on the results of your analysis. Ask what kind of outputs would be appropriate — a report, an infographic, a spreadsheet file, a presentation, or an application. If they have no expectations, it’s time to explore.
如果您的客户端没有明确自己的目标,开始在最后 。 询问根据分析结果需要做出哪些决定。 询问哪种输出是合适的-报告,信息图,电子表格文件,演示文稿或应用程序。 如果他们没有期望,那就该去探索了。
有数据吗? (Got data?)
Scrubbing your data will make you familiar with what you have. That’s why it’s a good idea to know your objective first. There are many things you can do to scrub your data but the first thing is to put it into a matrix. Statistical analyses all begin with matrices. The form of the matrix isn’t always the same, but most commonly, the matrix has columns that represent variables (e.g., metrics, measurements) and rows that represent observations (e.g., individuals, students, patients, sample units, or dates). Data on the variables for each observation go into the cells. Usually, this is done with spreadsheet software.
整理数据将使您熟悉所拥有的内容。 这就是为什么首先了解您的目标是一个好主意。 您可以执行许多操作来清理数据,但首先要将其放入矩阵中。 统计分析都是从矩阵开始的。 矩阵的形式并不总是相同的,但是最常见的是,矩阵具有代表变量(例如度量,度量)的列和代表观察值的行(例如个人,学生,患者,样本单位或日期) 。 每个观察变量的数据都进入单元格。 通常,这是通过电子表格软件完成的。
Data scrubbing can be cursory or exhaustive. Assuming the data are already available in electronic form, you’ll still have to achieve two goals — getting the numbers right and getting the right numbers.
数据清理可能是粗略的或详尽的。 假设数据已经以电子形式提供,您仍然必须实现两个目标-正确地编号和正确地编号。
Getting the numbers right requires correcting at least three types of data errors:
正确计算数字要求至少纠正三种类型的数据错误 :
Alphanumeric substitution, which involves mixing letters and numbers (e.g., 0 and o or O, 1 and l, 5 and S, 6 and b), dropped or added digits, spelling mistakes in text fields that will be sorted or filtered, and random errors.
字母数字替换 ,包括字母和数字的混合(例如0和o或O,1和l,5和S,6和b),数字的掉落或增加,文本字段中的拼写错误(将被排序或过滤)以及随机错误。
Specification errors involve bad data generation, perhaps attributable to recording mistakes, uncalibrated equipment, lab mistakes, or incorrect sample IDs and aliases.
规范错误涉及不良的数据生成,可能归因于记录错误,未校准的设备,实验室错误或不正确的样品ID和别名。
Inappropriate Data Formats, such as extra columns and rows, inconsistent use of ND, NA, or NR flags, and the inappropriate presence of 0s versus blanks.
不适当的数据格式 ,例如多余的列和行,ND,NA或NR标志的使用不一致,以及0与空白之间的不适当存在。
Getting the right numbers requires addressing a variety of data issues:
获取正确的数字需要解决各种数据问题:
Variables and phenomenon. Are the variables sufficient to explore the phenomena in question?
变量和现象 。 这些变量是否足以探索所讨论的现象 ?
Variable scales. Review the measurement scales of the variables so you know what analyses might be applicable to the data. Also, look for nominal and ordinal scale variables to consider how you might segment the data.
可变比例尺 。 查看变量的度量范围 ,以了解哪些分析可能适用于数据。 另外,查找名义和次序比例变量以考虑如何分割数据。
Representative sample. Considering the population being explored, does the sample appear to be representative.
代表性样品 。 考虑到正在探索的种群,样本是否具有代表性。
Replicates. If there are replicate or other quality control samples, they should be removed from the analysis appropriately.
复制 。 如果有重复样品或其他质量控制样品 ,则应将其从分析中适当除去。
Censored data. If you have censored data (i.e., unquantified data above or below some limit), you can recode the data as some fraction of the limit, but not zero.
审查数据 。 如果您检查了数据(即,超出或低于某个限制的未量化数据),则可以将数据重新编码为限制的一部分,但不能为零。
Missing data. If you have missing data, they should be recoded as blanks or use another accepted procedure for treating missing data.
缺少数据 。 如果您有丢失的数据,应将它们重新编码为空白或使用其他可接受的过程来处理丢失的数据。
Data scrubbing can consume a substantial amount of time, even more than the statistical calculations.
数据清理会消耗大量时间,甚至比统计计算还要多。
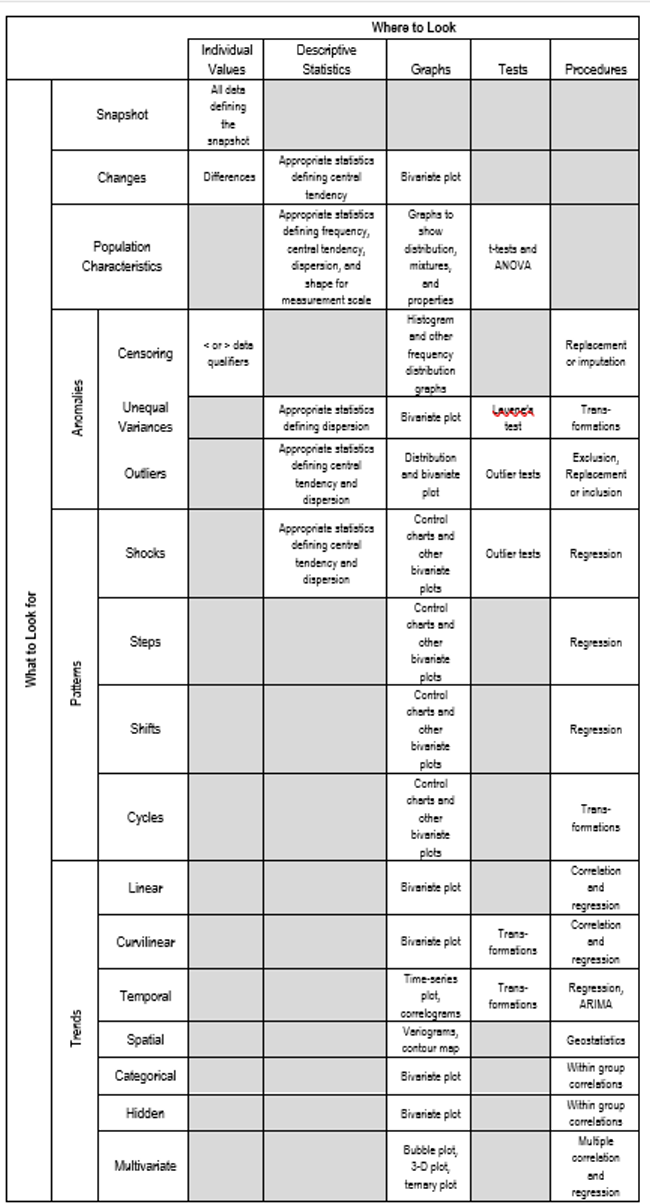
要找什么 (What To Look For)
If you’re new to applied statistics, you might wonder where to start looking at a dataset. Here are five places to consider looking.
如果您不熟悉应用统计信息,则可能想知道从哪里开始查看数据集。 这里有五个要考虑的地方。

- Snapshot快照
- Population or Sample Characteristics总体或样本特征
- Change更改
- Trends and Patterns趋势与模式
- Anomalies异常现象
Start with the entire dataset. Don’t divide the data into groups based on categoral variables. Divide and aggregate groupings later after you have a feel for the global situation. The reason for this is that the number of possible combinations of variables and levels of grouping variables can be large, overwhelming, each one being an analysis in itself. Like peeling an onion, explore one layer of data at a time until you get to the core.
从整个数据集开始。 不要根据类别变量将数据分为几类。 在对全球形势有所了解之后,请对分组进行分组和汇总。 这样做的原因是,变量的可能组合和分组变量级别的数量可能很大,令人不知所措,每个变量本身就是一项分析。 就像剥洋葱一样,一次浏览一层数据,直到到达核心为止。
快照 (Snapshot)
What does the data look like at one point. Usually it’s at the same point in time but it could also be some common conditions, like after a specific business activity, or at a certain temperature and pressure.
数据在某一点是什么样的。 通常是在同一时间点,但也可能是某些常见条件,例如在进行特定业务活动之后,或在一定温度和压力下。
Snapshots aren’t difficult to analyze. You just decide where you want a snapshot and record all the variable values at that point. There are no descriptive statistics, graphs, or tests unless you decide to subdivide the data later. The only challenge is deciding whether taking a snapshot makes any sense for exploring the data.
快照并不难分析。 您只需确定要快照的位置,然后记录所有变量值。 除非您决定稍后再细分数据,否则没有描述性的统计信息,图表或测试。 唯一的挑战是确定拍摄快照是否对浏览数据有意义。
The only thing you look for in a snapshot is something unexpected or unusual that might direct further analysis. It can also be used as a baseline to evaluate change.
您在快照中唯一需要查找的是意外或异常情况,可能会导致进一步的分析。 它也可以用作评估变化的基准。
人口特征 (Population Characteristics)
It’s always a good idea to know everything you can about the populations you are exploring. The approach is straightfoward; calculate descriptive statistics. Here’s a summary of what you might look at. It’s based on the measurement scale of the variable you are assessing.
了解您所探索的人群的一切都是一个好主意。 这种方法是直截了当的; 计算描述统计 。 这是您可能会看到的摘要。 它基于您正在评估的变量的度量范围。
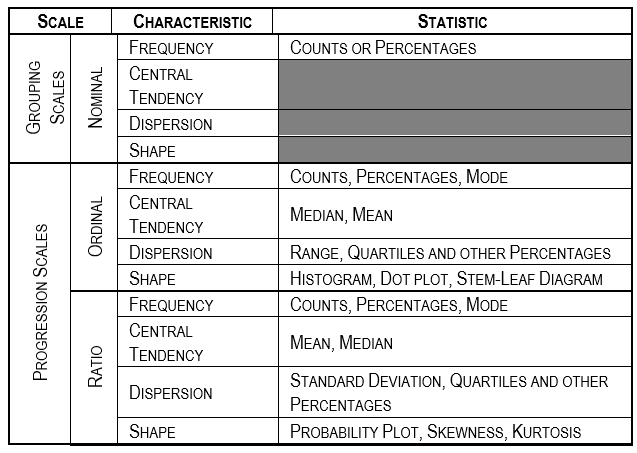
For grouping (nominal scale) variables, look at the frequencies of the groups. You’ll want to know if there are enough observations in each group to break them out for further analysis. For progression (continuous) scales, look at the median and the mean. If they’re close, the frequency distribution is probably symmetrical. You can confirm this by looking at a histogram or the skewness. If the standard-deviation-divided-by-the-mean (called the coefficient of variation) is over 1, the distribution may be lognormal, or at least, asymmetrical. Quartiles and deciles will support this finding. Look at the measures of central tendency and dispersion. If the dispersion is relatively large, statistical testing may be problematical.
对于分组(标称比例)变量,请查看组的频率。 您可能想知道每个组中是否有足够的观测值可以将其分解以进行进一步的分析。 对于进展(连续)量表,请查看中位数和均值。 如果它们很接近,则频率分布可能是对称的。 您可以通过查看直方图或偏度来确认这一点。 如果按均值划分的标准偏差(称为变异系数 )超过1,则分布可能是对数正态分布,或者至少是不对称分布。 四分位数和十分位数将支持这一发现。 看一下集中趋势和分散性的度量。 如果离散度相对较大,则统计测试可能会出现问题。
Graphs are also a good way, and in my mind the best way, to explore population characteristics. Never calculate a statistic without looking at its visual representation in a graph. There are many types of graphs that will let you do that.
图也是探索人口特征的一种好方法,也是我认为最好的方法。 在不查看图形的直观表示的情况下,切勿计算统计信息。 有许多类型的图形可以帮助您做到这一点。
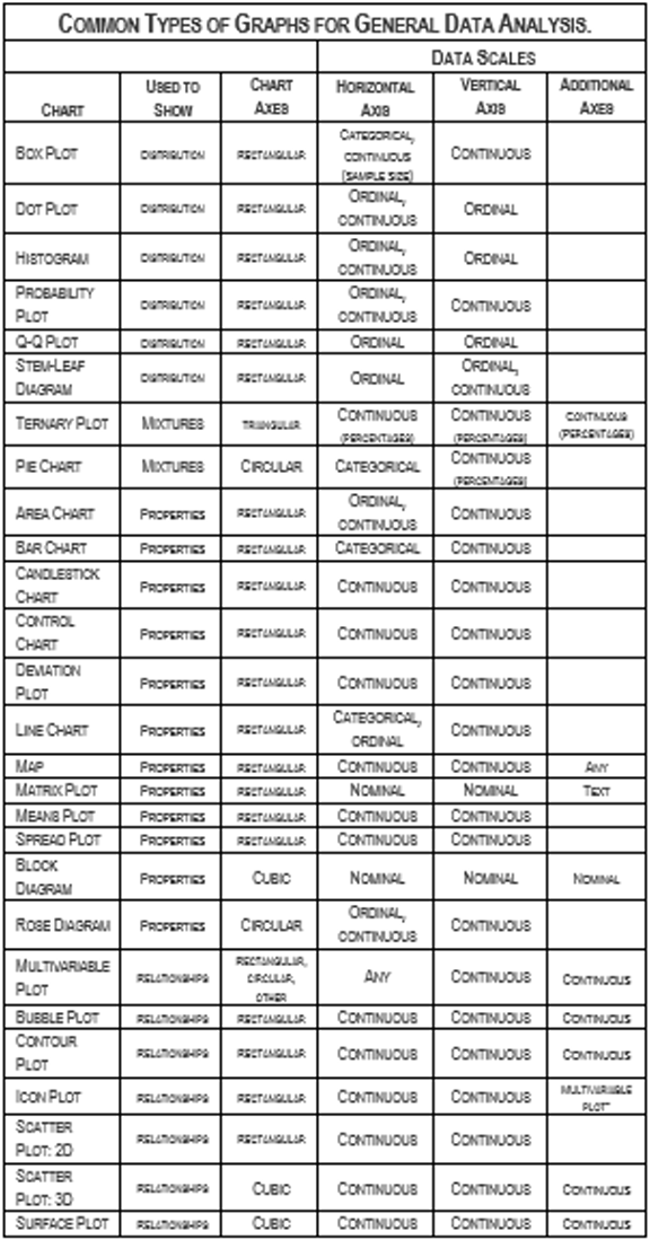
What you look for in a graph depends on what the graph is supposed to show — distribution, mixtures, properties, or relationships. There are other things you might look for but here are a few things to start with.
您在图表中寻找的内容取决于图表应显示的内容-分布,混合,属性或关系。 您可能还会寻找其他东西,但是这里有一些开始的事情。
For distribution graphs (box plots, histograms, dot plots, stem-leaf diagrams, Q-Q plots, rose diagrams, and probability plots), look for symmetry. That will separate many theoretical distributions, say a normal distribution (symmetrical) from a lognormal distribution (asymmetrical). This will be useful information if you do any statistical testing later.
对于分布图(箱形图,直方图,点图,茎叶图,QQ图,玫瑰图和概率图),请寻找对称性 。 这会将许多理论分布(例如,正态分布(对称)和对数正态分布(不对称))分开。 如果以后进行任何统计测试,这将是有用的信息。
For mixture graphs (pie charts, rose diagrams, and ternary plots), look for imbalance. If you have some segments that are very large and others very small, there may be common and unique themes to the mix to explore. Maybe the unique segments can be combined. This will be useful information if you break out subgroups later.
对于混合图(饼图,玫瑰图和三元图),请查找不平衡度 。 如果您的某些细分受众群很大,而其他细分受众群很小,那么可能会有一些共同而独特的主题可供探索。 也许可以组合独特的细分。 如果以后再细分子组,这将是有用的信息。
For properties graphs (bar charts, area charts, line charts, candlestick charts, control charts, means plots, deviation plots, spread plots, matrix plots, maps, block diagrams, and rose diagrams), look for the unexpected. Are the central tendency and dispersion what you might expect? Where are big deviations?
对于特性图(条形图,面积图,折线图,烛台图,控制图,均值图,偏差图,散布图,矩阵图,地图,框图和玫瑰图),请查找意外的 。 您所期望的主要趋势和分散是吗? 大的偏差在哪里?
For relationship graphs (icon plots, 2D scatter plots, contour plots, bubble plots, 3D scatter plots, surface plots, and multivariable plots), look for trends and patterns. You might find linear or curvilinear trends, repeating cycles, one-time shifts, continuing steps, periodic shocks, or just random points. This is the prelude for looking for more detailed patterns.
对于关系图(图标图,2D散点图,轮廓图,气泡图,3D散点图,表面图和多变量图),请查找趋势和模式 。 您可能会发现线性或曲线趋势,重复周期,一次移位,连续步骤,周期性冲击或只是随机点。 这是寻找更详细模式的序幕。
更改 (Change)
Change usually refers to differences between time periods but, like snapshots, it could also refer to some common conditions. Change can be difficult, or at least complicated, to analyze because you must first calculate the changes you want to explore. When calculating changes, be sure the intervals of the change are consistent. But after that, here’s what might you do.
更改通常是指时间段之间的差异,但是,像快照一样,它也可以指某些常见情况。 因为您必须首先计算要探索的变更,所以变更可能很难分析,或者至少很复杂。 计算更改时,请确保更改间隔一致。 但是之后,这就是您可能会做的。
First, look for very large, negative or positive changes. Are the percentages of change consistent for all variables? What might be some reasons for the changes.
首先,寻找非常大的,消极的或积极的变化。 所有变量的变化百分比是否一致? 进行更改可能是某些原因。
Calculate the mean and median changes. If the indicators of central tendency for the changes are not near zero, you might have a trend. Verify the possibility by plotting the change data. You might even consider conducting a statistical test to confirm that the change is different from zero. If you do think you have a pattern, trend, or anomaly, graphs are always the best place to look.
计算均值和中位数变化。 如果变化的主要趋势指标不接近于零,则可能具有趋势。 通过绘制更改数据来验证可能性。 您甚至可以考虑进行统计测试,以确认更改不为零。 如果您确实认为自己有模式,趋势或异常,则图形始终是最佳的查看位置。
趋势与模式 (Trends and Patterns)
There are at least ten types of data relationships — direct, feedback, common, mediated, stimulated, suppressed, inverse, threshold, and complex — and of course spurious relationships. They can all produce different patterns and trends, or no recognizable arrangement at all.
至少有十种类型的数据关系 -直接,反馈,公共,中介,刺激,抑制,逆向,阈值和复杂-当然是虚假关系。 它们都可以产生不同的模式和趋势,或者根本没有可识别的安排。

There are four patterns to look for:
有四种模式可寻找:
- Shocks电击
- Steps脚步
- Shifts转变
- Cycles.周期。
Shocks are seemingly random excursions far from the main body of data. They are outliers but they often reoccur, sometimes in a similar way suggesting a common, though sporadic cause. Some shocks may be attributed to an intermittent malfunction in the measurement instrument. Sometimes they occur in pairs, one in the positive direction and another of similar size in the negative direction. This is often seen when reporting dates for business data are missed.
冲击似乎是远离数据主体的随机漂移。 它们是异常值,但它们经常重复出现,有时以类似的方式暗示了一个常见的零星原因。 某些冲击可能归因于测量仪器的间歇性故障。 有时它们成对出现,一个在正方向,另一个在大小相似,在负方向。 当错过业务数据的报告日期时,通常会看到这种情况。
Steps are periodic increases or decreases in the body of the data. Steps progress in the same direction because they reflect a progressive change in conditions. If the steps are small enough, they can appear to be, and be analyzed as, a linear trend.
步骤是数据主体中的周期性增加或减少。 步骤沿同一方向前进,因为它们反映了条件的逐步变化。 如果步长足够小,则它们看起来可能是线性趋势,并且被分析为线性趋势。
Shifts are increases and/or decreases in the body of the data like steps, but shifts tend to be longer than steps and don’t necessarily progress in the same direction. Shifts reflect occasional changes in conditions. The changes may remain or revert to the previous conditions, making them more difficult to analyze with linear models.
移位是数据主体(如步长)中的增加和/或减少,但移位往往比步长,并且不一定沿相同方向进行。 变动反映了情况的偶然变化。 这些更改可能会保留或恢复为先前的条件,从而使使用线性模型进行分析变得更加困难。
Cycles are increases and decreases in the body of the data that usually appear as a waveform having fairly consistent amplitudes and frequencies. Cycles reflect periodic changes in conditions, often associated with time, such as daily or seasonal cycles. Cycles cannot be analyzed effectively with linear models. Sometimes different cycles add together making them more difficult to recognize and analyze.
周期是数据主体中的增加和减少,通常以具有相当一致的幅度和频率的波形形式出现。 周期反映出条件的周期性变化,通常与时间相关,例如每日或季节性周期。 使用线性模型无法有效地分析周期。 有时,不同的循环加在一起会使它们更加难以识别和分析。
Trends are often easy to identify because they are more familiar to most data analysts. Again, graphs are the best place to look for trends.
趋势通常很容易识别,因为大多数数据分析人员对趋势更为熟悉。 同样, 图形是寻找趋势的最佳位置。
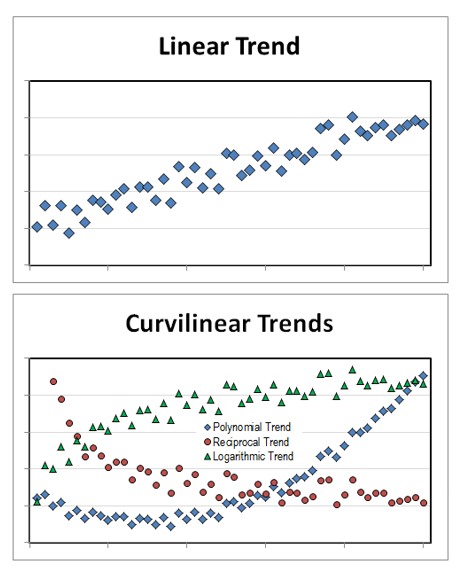
Linear trends are easy to see; the data form a line. Curvilinear trends can be more difficult to recognize because they don’t necessarily follow a set path. With some experience and intuition, however, they can be identified. Nonlinear trends look similar to curvilinear trends but they require more complicated nonlinear models to analyze. Curvilinear trends can be analyzed with linear models with the use of transformations.
线性趋势很容易看到; 数据排成一行。 曲线趋势可能更难以识别,因为它们不一定遵循设定的路径。 但是,凭着一些经验和直觉,就可以确定它们。 非线性趋势看起来与曲线趋势相似,但是它们需要更复杂的非线性模型进行分析。 曲线趋势可以通过使用变换的线性模型进行分析。
There are also more complex trends involving different dimensions, including:
还有涉及不同方面的更复杂的趋势,包括:
- Temporal颞
- Spatial空间空间
- Categorical分类的
- Hidden隐
- Multivariate多变量
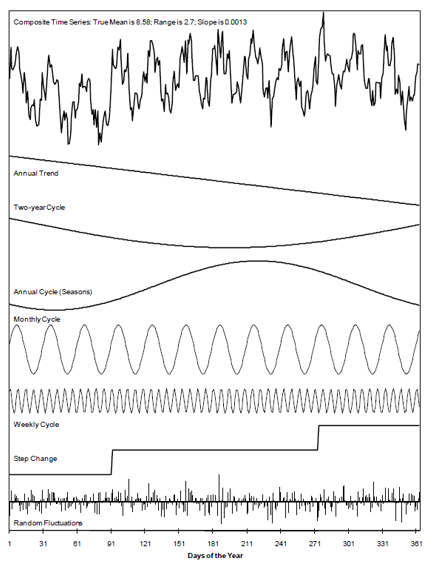
Temporal Trends can be more difficult to identify because Time-series data can be combinations of shocks, steps, shifts, cycles, and linear and curvilinear trends. The effects may be seasonal, superimposed on each other within a given time period, or spread over many different time periods. Confounded effects are often impossible to separate, especially if the data record is short or the sampled intervals are irregular or too large.
时间趋势可能更难识别,因为时间序列数据可以是冲击,阶跃,移位,周期以及线性和曲线趋势的组合。 这些影响可以是季节性的,也可以在给定的时间段内相互叠加,也可以分布在许多不同的时间段内。 混淆的效果通常是无法分离的,尤其是在数据记录较短或采样间隔不规则或太大的情况下。

Spatial Trends present a different twist. Time is one-dimensional (at least as we now know it); distance can be one-, two-, or three-dimensional. Distance can be in a straight line (“as the crow flies”) or along a path (such as driving distance). Defining the location of a unique point on a two-dimensional surface (i.e., a plane) requires at least two variables. The variables can represent coordinates (northing/easting, latitude/longitude) or distance and direction from a fixed starting point. At least three variables are needed to define a unique point location in a three-dimensional volume, so a variable for depth (or height) must be added to the location coordinates. Looking for spatial patterns involves interpolation of geographic data using one of several available algorithms, like moving averages, inverse distances, or geostatistics.
空间趋势呈现出不同的变化。 时间是一维的(至少我们现在知道)。 距离可以是一维,二维或三维。 距离可以是直线(“乌鸦飞翔”)或沿路径(例如行驶距离)。 在二维表面(即平面)上定义唯一点的位置至少需要两个变量。 变量可以表示坐标(北/东,纬度/经度)或距固定起点的距离和方向。 至少需要三个变量来定义三维体积中的唯一点位置,因此必须将深度(或高度)变量添加到位置坐标中。 寻找空间模式涉及使用几种可用算法之一对地理数据进行插值,例如移动平均值,反距离或地统计学 。
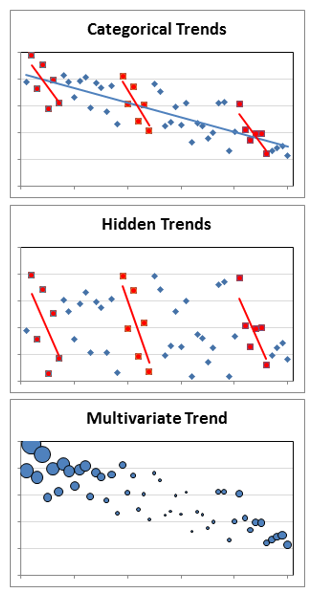
Categorical Trends are no more difficult to identify than any trend except you have to break out categories to do it, which can be a lot of work. One thing you might see when analyzing categories is Simpson’s paradox. The paradox occurs when trends appear in categories that are different from the overall group. Hidden Trends are trends that appear only in categories and not the overall group. You may be able to detect linear trends in categories without graphs if you have enough data in the categories to calculate correlation coefficients within each.
分类趋势比任何趋势都更容易识别,除了您必须细分类别来进行,这可能需要很多工作。 分析类别时,您可能会看到的一件事是Simpson的悖论 。 当趋势出现在与整个组不同的类别中时,就会发生自相矛盾。 隐藏趋势是仅显示在类别中而不显示在整个组中的趋势。 如果您在类别中有足够的数据来计算每个类别中的相关系数,则可以在没有图形的情况下检测类别中的线性趋势。
Multivariate Trends add a layer of complexity to most trends, which are bivariate. Still, you look for the same things, patterns and trends, only you have to examine at least one additional dimension. The extra dimension may be an additional axis or some other way of representing data, like icon type, size, or color.
多元趋势为大多数是双变量的趋势增加了一层复杂性。 尽管如此,您仍在寻找相同的事物,模式和趋势,只需要检查至少一个额外的维度。 额外的维度可以是额外的轴或其他表示数据的方式,例如图标类型,大小或颜色。
异常现象 (Anomalies)
Sometimes the most interesting revelations you can garner from a dataset are the ways that it doesn’t fit expectations. Three things to look for are:
有时,您可以从数据集中获得的最有趣的启示是它不符合预期的方式。 要寻找的三件事是:
- Censoring审查制度
- Heteroskedasticity异方差
- Outliers.离群值。
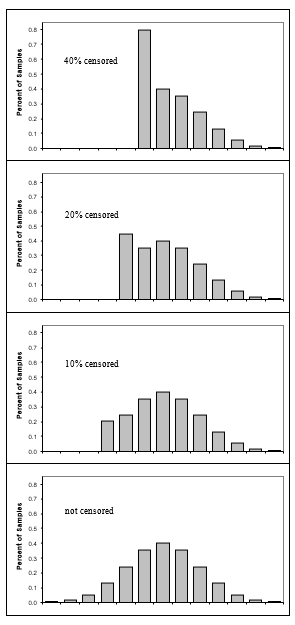
Censoring is when a measurement is recorded as a <value or as a >value, indicating that the measurement instrument was unable to quantify the real value. For example, the real value may be outside the range of a meter, or counts can’t be approximated because there are too many or too few, or a time can only be estimated as before or after. Censoring is easy to detect in a dataset because they should be qualified with < or >.
删减是指将测量记录为<值或>值,表示测量仪器无法量化实际值。 例如,实际值可能超出了仪表的范围, 或者由于数量太多或太少而无法近似计数, 或者只能估计之前或之后的时间。 审查在数据集中很容易检测,因为它们应使用<或>进行限定。
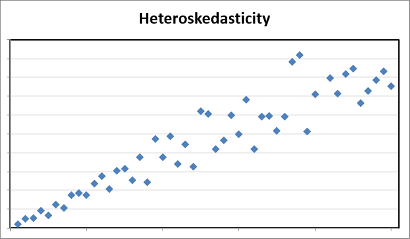
Heteroskedasticity is when the variability in a variable is not uniform across its range. This is important because homo-scedasticity (the opposite of heteroskedasicity) is assumed by parametric statistics. Look for differing thicknesses in plotted data. This is often seen in automated measurements when a measurement instrument is upgraded to one with a greater precision.
异是当在一个变量中的变化是不是在其整个范围内均匀。 这很重要,因为参数统计量假定为均方差性(与异方差性相反)。 在绘图数据中查找不同的厚度。 当自动将测量仪器升级为更高精度的仪器时,通常会看到这种情况。
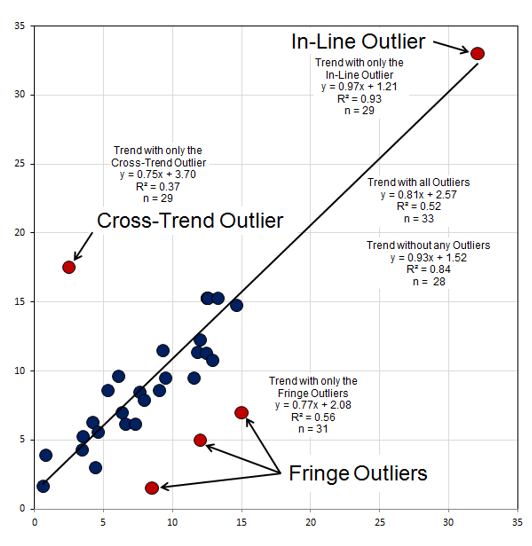
Influential observations and outliers are the data points that don’t fit the overall trends and patterns. Finding anomalies isn’t that difficult; deciding why they are anomalous and what to do with them are the really tough parts. Here are some examples of the types of outliers to look for.
有影响力的观察结果和离群值是与总体趋势和模式不符的数据点。 查找异常并不困难; 决定它们为什么异常以及如何处理它们是真正困难的部分。 以下是一些要查找的异常值类型的示例。
如何看待 (How and Where to Look)
That’s a lot of information to take in and remember, so here’s a summary you can refer to in the future if you ever need it.
需要记住的很多信息,因此,如果需要,这里是您将来可以参考的摘要。
And when you’re done, be sure to document your results so others can follow what you did.
完成后,请务必记录您的结果,以便其他人可以照做。
Originally published at http://statswithcats.net on January 21, 2019.
最初于 2019年1月21日 发布在 http://statswithcats.net 上。
翻译自: https://medium.com/@charliekufs/what-to-look-for-in-data-e63209bb9c30
海量数据寻找最频繁的数据
http://www.taodudu.cc/news/show-995337.html
相关文章:
- 可视化 nlp_使用nlp可视化尤利西斯
- python的power bi转换基础
- 自定义按钮动态变化_新闻价值的变化定义
- 算法 从 数中选出_算法可以选出胜出的nba幻想选秀吗
- 插入脚注把脚注标注删掉_地狱司机不应该只是英国电影历史数据中的脚注,这说明了为什么...
- 贝叶斯统计 传统统计_统计贝叶斯如何补充常客
- 因为你的电脑安装了即点即用_即你所爱
- 团队管理新思考_需要一个新的空间来思考讨论和行动
- bigquery 教程_bigquery挑战实验室教程从数据中获取见解
- java职业技能了解精通_如何通过精通数字分析来提升职业生涯的发展,第8部分...
- kfc流程管理炸薯条几秒_炸薯条成为数据科学的最后前沿
- bigquery_到Google bigquery的sql查询模板,它将您的报告提升到另一个层次
- 数据科学学习心得_学习数据科学时如何保持动力
- python多项式回归_在python中实现多项式回归
- pd种知道每个数据的类型_每个数据科学家都应该知道的5个概念
- xgboost keras_用catboost lgbm xgboost和keras预测财务交易
- 走出囚徒困境的方法_囚徒困境的一种计算方法
- 平台api对数据收集的影响_收集您的数据不是那么怪异的api
- 逻辑回归 概率回归_概率规划的多逻辑回归
- ajax不利于seo_利于探索移动选项的界面
- 数据探索性分析_探索性数据分析
- stata中心化处理_带有stata第2部分自定义配色方案的covid 19可视化
- python 插补数据_python 2020中缺少数据插补技术的快速指南
- ab 模拟_Ab测试第二部分的直观模拟
- 亚洲国家互联网渗透率_发展中亚洲国家如何回应covid 19
- 墨刀原型制作 位置选择_原型制作不再是可选的
- 使用协同过滤推荐电影
- 数据暑假实习面试_面试数据科学实习如何准备
- 谷歌 colab_如何在Google Colab上使用熊猫分析
- 边际概率条件概率_数据科学家解释的边际联合和条件概率
海量数据寻找最频繁的数据_在数据中寻找什么相关推荐
- redis一般缓存什么样数据_门户数据展示_Redis缓存数据
学习主题:门户数据展示_Redis缓存数据 一.Redis_3主3从集群环境搭建 谈单你对读写分离和主从同步的理解 读写分离:Master负责写数据的操作,salve负责读数据的操作 主从同步:sal ...
- 同时删除两张表的数据_把数据表中对应工作表的数据首先删除,然后导入数据...
大家好,我们今日继续讲解VBA数据库解决方案的第28讲内容:利用VBA,把数据表中对应工作表的数据首先删除,然后向数据表中导入工作表数据.数据库的讲解已经持续一段时间了,从对简单数据库的认识到利用VB ...
- go 捕获数据库新增数据_更改数据捕获的经验教训
go 捕获数据库新增数据 The article summarizes experiences from various projects with a log-based change data c ...
- 机器学习 处理不平衡数据_在机器学习中处理不平衡数据
机器学习 处理不平衡数据 As an ML engineer or data scientist, sometimes you inevitably find yourself in a situat ...
- hive 导入hdfs数据_将数据加载或导入运行在基于HDFS的数据湖之上的Hive表中的另一种方法。
hive 导入hdfs数据 Preceding pen down the article, might want to stretch out appreciation to all the well ...
- 管道过滤模式 大数据_大数据管道配方
管道过滤模式 大数据 介绍 (Introduction) If you are starting with Big Data it is common to feel overwhelmed by t ...
- 数字经济的核心是对大数据_大数据崛起为数字世界的核心润滑剂
数字经济的核心是对大数据 "Information is the oil of the 21st century, and analytics is the combustion engin ...
- kaggle比赛数据_表格数据二进制分类:来自5个Kaggle比赛的所有技巧和窍门
kaggle比赛数据 This article was originally written by Shahul ES and posted on the Neptune blog. 本文最初由 Sh ...
- 刷新table数据_关于数据透视表的刷新功能最值得了解的几个操作
在职场办公中,会用数据透视表来处理数据是多么爽的一件事情. 在用透视表时常常会遇到明细表发生数据更新了,我们总希望总报表也能自动发生变化,那怎么操作呢? 今天老余来和大家分享几种方法,望对你在工作中有 ...
最新文章
- 参加维基链超级节点竞选有什么好处呢?
- jQuery拼接页面元素
- 如何传输文件到linux服务器?
- react第三方组件库_如何自定义您的第三方React组件
- linux 文件系统字体小,基于嵌入式Linux平台的最小文件系统的制作
- 【个人笔记】OpenCV4 C++ 快速入门 14课
- html屏幕阅读器,支持移动触摸的网页版PDF格式文件阅读器插件
- 基于fpga+stm32的数字示波器
- java 求方差_java计算方差、标准差(均方差)实例代码
- Linux遇到删除不掉的文件或者文件夹解决办法
- ESP32 LVGL8.1 ——msgbox 消息框 (msgbox 28)
- Iron WebScraper 网络爬虫
- 高僧斗法--Staircase Nim
- 使用 eclipse 编写 xtend
- webp转换gif动图的方法-批量转换并保留动画效果
- Vue2 轮播图组件 原生slide组件
- 学习python的书籍
- ACL 2020 | 特定风格标题生成《Hooks in the headline》论文阅读笔记
- SAP schema增强
- 10g文件复制到linux,怎样将LINUX服务器上的10G文件下载到本地