机器学习常用模型:决策树_fairmodels:让我们与有偏见的机器学习模型作斗争
机器学习常用模型:决策树
TL; DR (TL;DR)
The R Package fairmodels facilitates bias detection through model visualizations. It implements a few mitigation strategies that could reduce bias. It enables easy to use checks for fairness metrics and comparison between different Machine Learning (ML) models.
R Package 公平模型 通过模型可视化促进偏差检测。 它实施了一些缓解策略,可以减少偏差。 它使易于使用的公平性检查检查和不同机器学习(ML)模型之间的比较成为可能。
长版 (Long version)
Bias mitigation is an important topic in Machine Learning (ML) fairness field. For python users, there are algorithms already implemented, well-explained, and described (see AIF360). fairmodels provides an implementation of a few popular, effective bias mitigation techniques ready to make your model fairer.
偏差缓解是机器学习(ML)公平性领域的重要主题。 对于python用户,已经实现,充分解释和描述了算法(请参阅AIF360 )。 fairmodels提供了一些流行的有效的偏差缓解技术的实现,这些技术可以使您的模型更加公平。
我的模型有偏见,现在呢? (I have a biased model, now what?)
Having a biased model is not the end of the world. There are lots of ways to deal with it. fairmodels implements various algorithms to help you tackle that problem. Firstly, I must describe the difference between the pre-processing algorithm and the post-processing one.
带有偏见的模型并不是世界末日。 有很多方法可以处理它。 fairmodels实现了各种算法来帮助您解决该问题。 首先,我必须描述预处理算法和后处理算法之间的区别。
Pre-processing algorithms work on data before the model is trained. They try to mitigate the bias between privileged subgroup and unprivileged ones through inference from data.
在训练模型之前, 预处理算法会对数据进行处理 。 他们试图通过数据推断来减轻特权子群体与非特权子群体之间的偏见。
Post-processing algorithms change the output of the model explained with DALEX so that its output does not favor the privileged subgroup so much.
后处理算法更改了用DALEX解释的模型的输出,因此其输出不太喜欢特权子组。
这些算法如何工作? (How do these algorithms work?)
In this section, I will briefly describe how these bias mitigation techniques work. Code for more detailed examples and some visualizations used here may be found in this vignette.
在本节中,我将简要描述这些偏差缓解技术的工作原理。 在此插图中可以找到更详细的示例代码和此处使用的一些可视化效果。
前处理 (Pre-processing)
不同的冲击消除剂(Feldman等,2015) (Disparate impact remover (Feldman et al., 2015))
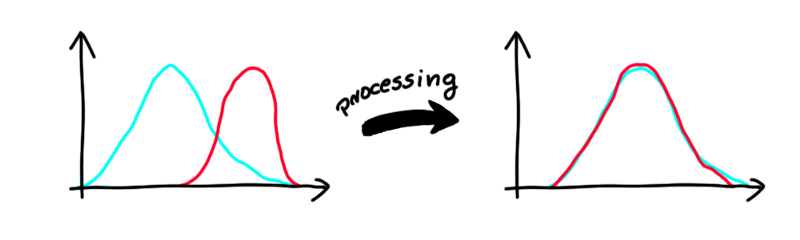
This algorithm works on numeric, ordinal features. It changes the column values so the distributions for the unprivileged (blue) and privileged (red) subgroups are close to each other. In general, we would like our algorithm not to judge on value of the feature but rather on percentiles (e.g., hiring 20% of best applicants for the job from both subgroups). The way that this algorithm works is that it finds such distribution that minimizes earth mover’s distance. In simple words, it finds the “middle” distribution and changes values in this feature for each subgroup.
此算法适用于数字顺序特征。 它更改列的值,以便非特权(蓝色)和特权(红色)子组的分布彼此接近。 总的来说,我们希望我们的算法不是根据功能的价值来判断,而是根据百分位数来判断(例如,从两个子组中聘请20%的最佳求职者)。 该算法的工作方式是找到使推土机距离最小的分布。 用简单的话说,它找到“中间”分布并为每个子组更改此功能中的值。
Reweightnig (Kamiran et al。,2012) (Reweightnig (Kamiran et al., 2012))

Reweighting is a simple but effective tool for minimizing bias. The algorithm looks at the protected attribute and on the real label. Then, it calculates the probability of assigning favorable label (y=1) assuming the protected attribute and y are independent. Of course, if there is bias, they will be statistically dependent. Then, the algorithm divides calculated theoretical probability by true, empirical probability of this event. That is how weight is created. With these 2 vectors (protected variable and y ) we can create weights vector for each observation in data. Then, we pass it to the model. Simple as that. But some models don’t have weights parameter and therefore can’t benefit from this method.
重新加权是最小化偏差的简单但有效的工具。 该算法查看受保护的属性和实标签。 然后,假设受保护的属性和y独立,则计算分配有利标签(y = 1)的可能性。 当然,如果存在偏差,它们将在统计上相关。 然后,算法将计算出的理论概率除以该事件的真实,经验概率。 重量就是这样产生的。 使用这两个向量(保护变量和y),我们可以为数据中的每个观察值创建权重向量。 然后,我们将其传递给模型。 就那么简单。 但是某些模型没有权重参数,因此无法从该方法中受益。
重采样(Kamiran et al。,2012) (Resampling (Kamiran et al., 2012))
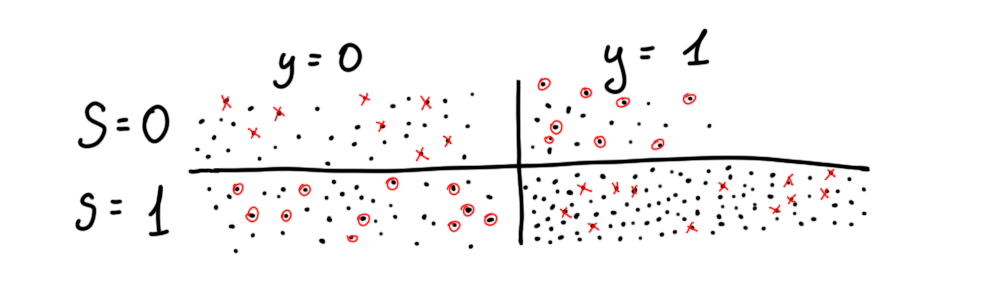
Resampling is closely related to the prior method as it implicitly uses reweighting to calculate how many observations must be omitted/duplicated in a particular case. Imagine there are 2 groups, deprived (S = 0) and favored (S = 1). This method duplicates observations from a deprived subgroup when the label is positive and omits observations with a negative label. The opposite is then performed on the favored group. There are 2 types of resampling methods implemented- uniform and preferential. Uniform randomly picks observations (like in the picture) whereas preferential utilizes probabilities to pick/omit observations close to cutoff (default is 0.5).
重采样与先前的方法密切相关,因为它隐式使用重新加权来计算在特定情况下必须省略/重复多少个观测值。 想象一下,有2个组,被剥夺(S = 0)和受青睐(S = 1)。 当标签为正时,此方法复制来自被剥夺子组的观察结果,而忽略带有负标签的观察。 然后对喜欢的组执行相反的操作。 有两种重采样方法: 统一和优先 。 均匀地随机选择观测值(如图中所示),而“ 优先级”则利用概率来选择/忽略接近临界值的观测值(默认值为0.5)。
后期处理 (Post-processing)
Post-processing takes place after creating an explainer. To create explainer we need the model and DALEX explainer. Gbm model will be trained on adult dataset predicting whether a certain person earns more than 50k annually.
在创建解释器后进行后处理。 要创建解释器,我们需要模型和DALEX解释器。 Gbm模型将接受成人训练 预测某个人的年收入是否超过5万的数据集。
library(gbm)library(DALEX)library(fairmodels)data("adult")adult$salary <- as.numeric(adult$salary) -1protected <- adult$sexadult <- adult[colnames(adult) != "sex"] # sex not specified# making modelset.seed(1)gbm_model <-gbm(salary ~. , data = adult, distribution = "bernoulli")# making explainergbm_explainer <- explain(gbm_model, data = adult[,-1], y = adult$salary, colorize = FALSE)基于拒绝选项的分类(数据透视) (Kamiran等,2012) (Reject Option based Classification (pivot) (Kamiran et al., 2012))
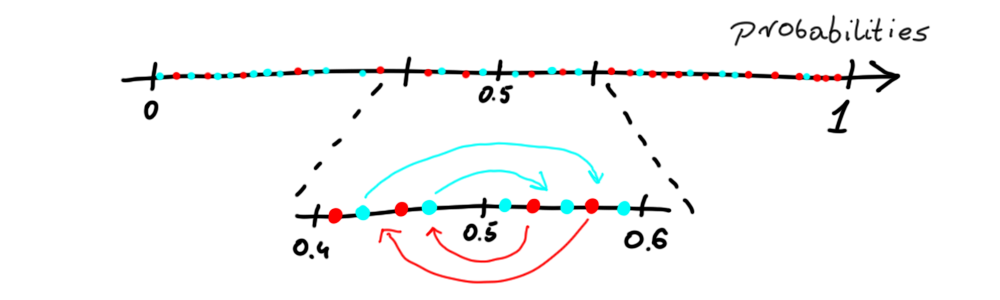
ROC pivot is implemented based on Reject Option based Classification. Algorithm switches labels if an observation is from the unprivileged group and on the left of the cutoff. The opposite is then performed for the privileged group. But there is an assumption that the observation must be close (in terms of probabilities) to cutoff. So the user must input some value theta so that the algorithm will know how close must observation be to the cutoff for the switch. But there is a catch. If just the label was changed DALEX explainer would have a hard time properly calculating the performance of the model. For that reason instead of labels, in fairmodels implementation of this algorithm that is the probabilities that are switched (pivoted). They are just moved to the other side but with equal distance to the cutoff.
ROC数据透视是基于基于拒绝选项的分类实现的。 如果观察值来自非特权组且位于截止值的左侧,则算法会切换标签。 然后对特权组执行相反的操作。 但是有一个假设,即观察结果(在概率方面)必须接近临界值。 因此,用户必须输入一些值theta,以便算法将知道必须观察到与开关的截止点有多接近。 但是有一个问题! 如果仅更改标签,DALEX解释器将很难正确计算模型的性能。 因此,在公平模型中 ,此算法代替了标签,而是切换(枢轴化)的概率。 它们只是移动到另一侧,但与截止点的距离相等。
截止操作 (Cutoff manipulation)
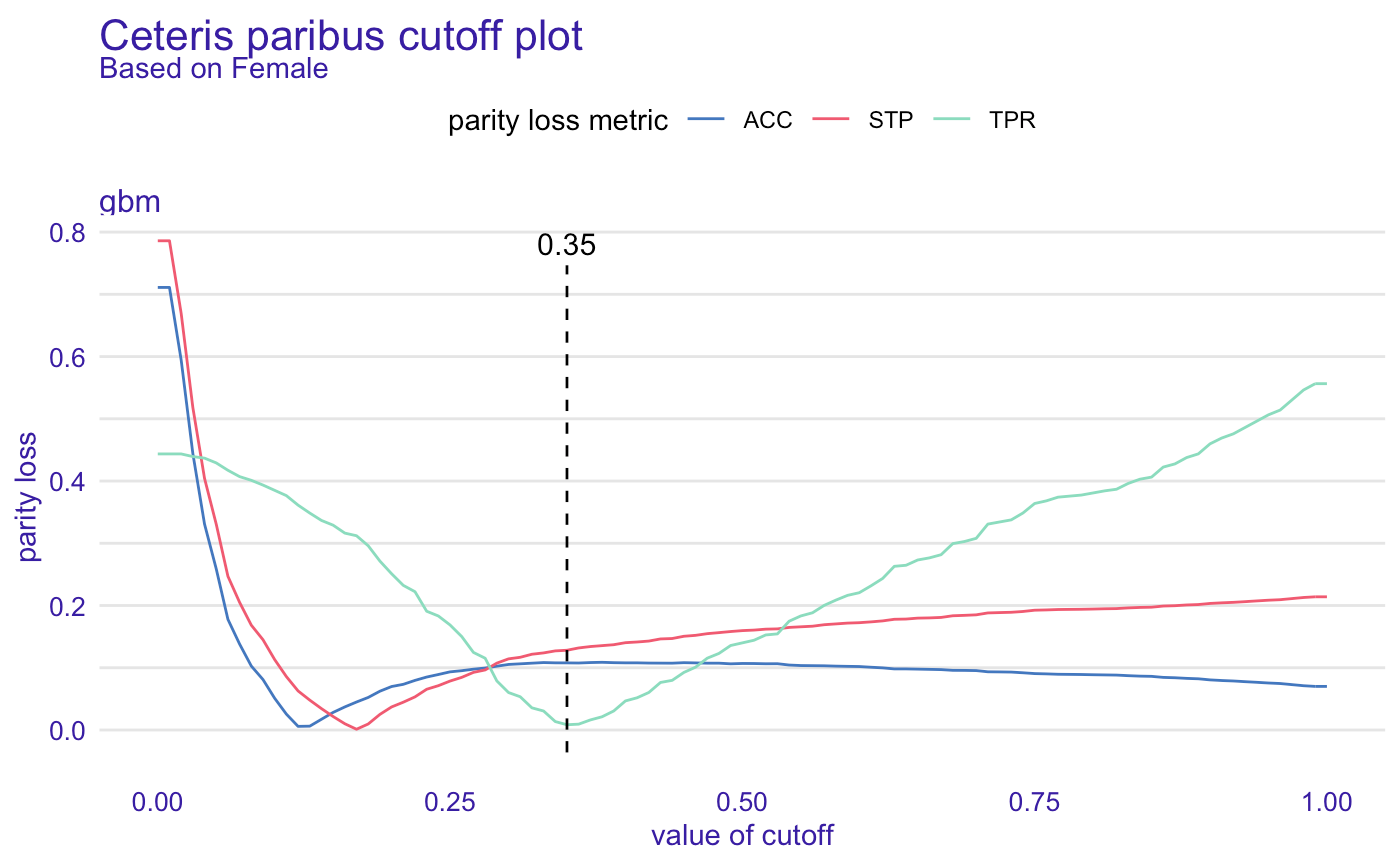
Cutoff manipulation might be a great idea for minimizing the bias in a model. We simply choose metrics and subgroup for which the cutoff will change. The plot shows where the minimum is and for that value of cutoff parity loss will be the lowest. How to create fairness_object with the different cutoff for certain subgroup? It is easy!
截断操作对于最小化模型中的偏差可能是一个好主意。 我们仅选择截止值将更改的指标和子组。 该图显示了最小值所在的位置,并且对于该阈值, 奇偶校验损耗将是最低的。 如何为某些子组创建具有不同截止值的fairness_object? 这很容易!
fobject <- fairness_check(gbm_explainer, protected = protected, privileged = "Male", label = "gbm_cutoff", cutoff = list(Female = 0.35))Now the fairness_object (fobject) is a structure with specified cutoff and it will affect both fairness metrics and performance.
现在, fairness_object(fobject)是具有指定截止值的结构,它将同时影响公平性指标和性能。
公平与准确性之间的权衡 (The tradeoff between fairness and accuracy)
If we want to mitigate bias we must be aware of possible drawbacks of this action. Let’s say that Statical Parity is the most important metric for us. Lowering parity loss of this metric will (probably) result in an increase of False Positives which will cause the accuracy to drop. For this example (that you can find here) a gbm model was trained and then treated with different bias mitigation techniques.
如果我们想减轻偏见,我们必须意识到这一行动的可能弊端。 假设静态奇偶校验是我们最重要的指标。 降低此度量的奇偶校验损失将(可能)导致误报的增加,这将导致准确性下降。 对于此示例(您可以在此处找到),对gbm模型进行了训练,然后使用了不同的偏差缓解技术对其进行了处理。
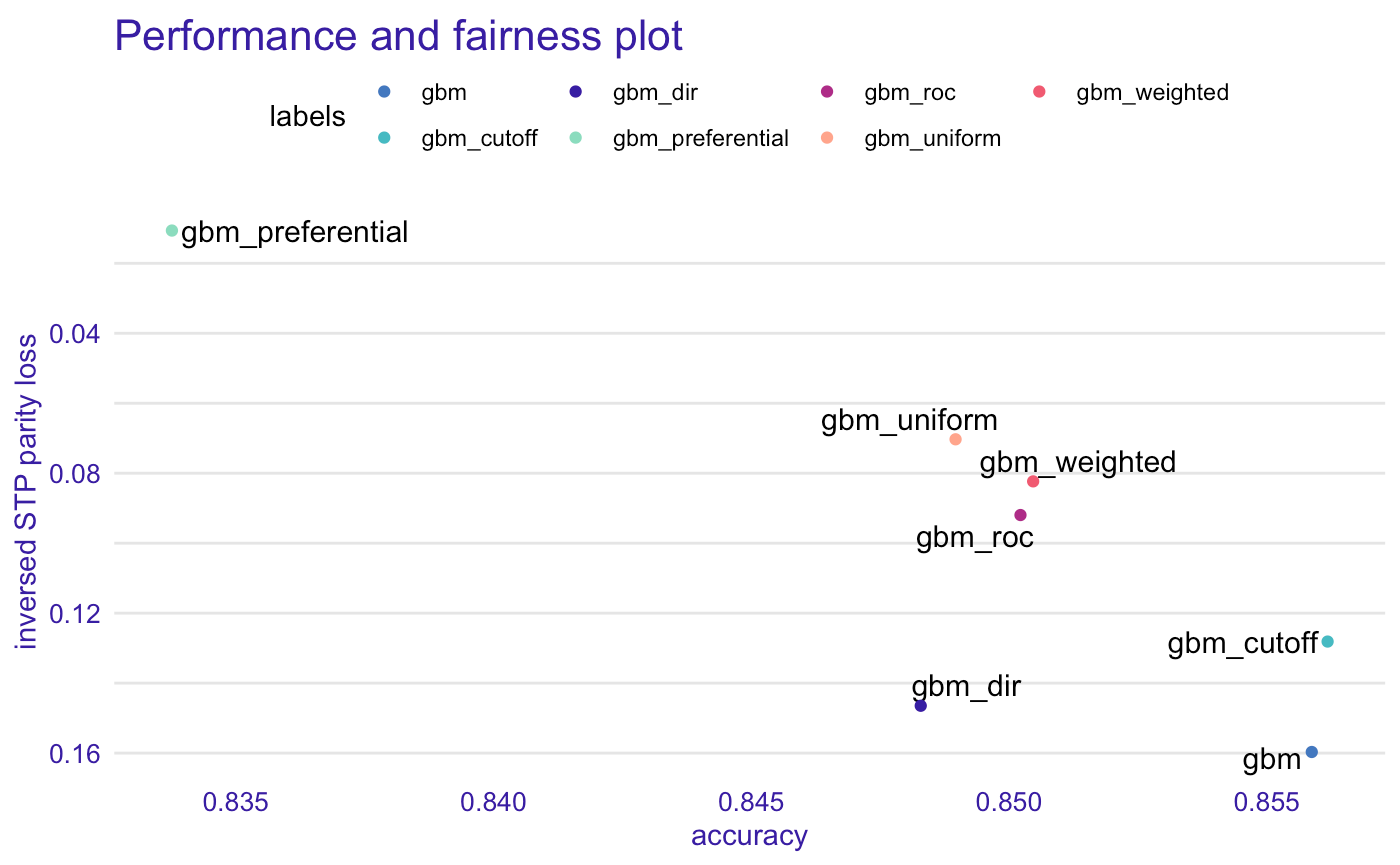
The more we try to mitigate the bias, the less accuracy we get. This is something natural for this metric and the user should be aware of it.
我们越努力减轻偏差,获得的准确性就越低。 这对于该指标是很自然的事情,用户应该意识到这一点。
摘要 (Summary)
Debiasing methods implemented in fairmodels are certainly worth trying. They are flexible and most of them are suited for every model. Most of all they are easy to use.
在公平模型中实现的去偏置方法当然值得尝试。 它们非常灵活,并且大多数适用于每种型号。 最重要的是它们易于使用。
接下来要读什么? (What to read next?)
Blog post about introduction to fairness, problems, and solutions
关于公平,问题和解决方案介绍的博客文章
Blog post about fairness visualization
关于公平可视化的博客文章
学到更多 (Learn more)
Check the package’s GitHub website for more details
检查软件包的GitHub网站以获取更多详细信息
Tutorial on full capabilities of the fairmodels package
fairmodels软件包的全部功能教程
Tutorial on bias mitigation techniques
缓解偏见技术的教程
翻译自: https://towardsdatascience.com/fairmodels-lets-fight-with-biased-machine-learning-models-f7d66a2287fc
机器学习常用模型:决策树
http://www.taodudu.cc/news/show-997508.html
相关文章:
- 100米队伍,从队伍后到前_我们的队伍
- mongodb数据可视化_使用MongoDB实时可视化开放数据
- Python:在Pandas数据框中查找缺失值
- Tableau Desktop认证:为什么要关心以及如何通过
- js值的拷贝和值的引用_到达P值的底部:直观的解释
- struts实现分页_在TensorFlow中实现点Struts
- 钉钉设置jira机器人_这是当您机器学习JIRA票证时发生的事情
- 小程序点击地图气泡获取气泡_气泡上的气泡
- PopTheBubble —测量媒体偏差的产品创意
- 面向Tableau开发人员的Python简要介绍(第3部分)
- pymc3使用_使用PyMC3了解飞机事故趋势
- 吴恩达神经网络1-2-2_图神经网络进行药物发现-第2部分
- 数据图表可视化_数据可视化十大最有用的图表
- 接facebook广告_Facebook广告分析
- eda可视化_5用于探索性数据分析(EDA)的高级可视化
- css跑道_如何不超出跑道:计划种子的简单方法
- 熊猫数据集_为数据科学拆箱熊猫
- matplotlib可视化_使用Matplotlib改善可视化设计的5个魔术技巧
- 感知器 机器学习_机器学习感知器实现
- 快速排序简便记_建立和测试股票交易策略的快速简便方法
- 美剧迷失_迷失(机器)翻译
- 我如何预测10场英超联赛的确切结果
- 深度学习数据自动编码器_如何学习数据科学编码
- 图深度学习-第1部分
- 项目经济规模的估算方法_估算英国退欧的经济影响
- 机器学习 量子_量子机器学习:神经网络学习
- 爬虫神经网络_股市筛选和分析:在投资中使用网络爬虫,神经网络和回归分析...
- 双城记s001_双城记! (使用数据讲故事)
- rfm模型分析与客户细分_如何使用基于RFM的细分来确定最佳客户
- 数据仓库项目分析_数据分析项目:仓库库存
机器学习常用模型:决策树_fairmodels:让我们与有偏见的机器学习模型作斗争相关推荐
- 图解机器学习算法(6) | 决策树模型详解(机器学习通关指南·完结)
作者:韩信子@ShowMeAI 教程地址:https://www.showmeai.tech/tutorials/34 本文地址:https://www.showmeai.tech/article-d ...
- python机器学习常用模型
python机器学习 算法分类 监督学习 定义︰输入数据是由输入特征值和目标值所组成.函数的输出可以是一个连续的值(称为回归),或是输出是有限个离散值(称作分类). 分类: k-近邻 贝叶斯 决策树 ...
- Spark:基于PySpark的逻辑回归和决策树模型对泰旦尼克号幸存者预测的机器学习流程
pyspark的ML回顾下 文章目录 官网文档 环境 泰坦尼克号数据分析 泰坦尼克号数据清洗整理 Spark ML Pipeline Titanic幸存者预测:逻辑回归LR模型 模型训练 模型预测 T ...
- 机器学习-分类之决策树原理及实战
决策树 简介 决策树是一个非参数的监督学习方法,又称为判定树,是运用于分类的一种树结构,其中的每个内部节点代表对某一属性的一次测试,每条边代表一个测试结果,叶子节点代表某个类或者类的分布. 简单决策树 ...
- 机器学习——常用算法的总结
机器学习常用算法总结 机器学习--常用算法的总结 学习方式 一.监督式学习: 1.分类 2.回归 补充--线性回归与逻辑回归 二.非监督式学习: 三.半监督式学习: 四.强化学习: 算法类似性 一.回 ...
- 机器学习-Sklearn-01(决策树)
机器学习-Sklearn-01 学习01 素人的数据分析之路: 什么是sklearn? sklearn是一个开源的基于python语言的机器学习工具包 它通过Numpy,Scipy和Matplotli ...
- 刻意练习:机器学习实战 -- Task01. 决策树
背景 这是我们为拥有 Python 基础的同学推出的精进技能的"机器学习实战" 刻意练习活动,这也是我们本学期推出的第三次活动了. 我们准备利用8周时间,夯实机器学习常用算法,完成 ...
- 机器学习常用算法归详细纳整理
作者:进击的西西弗斯 本文链接:https://blog.csdn.net/qq_42216093/article/details/116434557 版权声明:本文为作者原创文章,未经作者同意禁止转 ...
- 机器学习算法之--决策树总结
文章目录 一.决策树算法数学原理 (1)算法思路 (2)两个阶段 (3)模型优缺点 (4)决策树本质 (5)决策树损失函数与学习策略 (6)常用算法 二.决策树算法思路 (1)特征选择 信息增益定义 ...
最新文章
- Spring Boot+Redis+拦截器+自定义Annotation实现接口自动幂等
- 线程关键字、锁、同步集合笔记
- linux下把进程绑定到特定cpu核上运行
- 动态链接库与静态链接库
- php arrayaccess 二维,php的ArrayAccess(数组式访问接口)
- Oozie 出现 ClassNotFoundException 解决方法
- jqGrid edit总结
- Elasticsearch-5.1.2分词器IK+pinyin简单测试
- redis 同步化操作
- Chrome扩展应用Angular state inspector的使用方法
- mysql 哈希缓存_MySQL数据库性能优化思路总结
- 父组件传递值给子组件(一)
- SQL SERVER将多行数据合并成一行(转载)
- 春晚亲民,快手上行:探秘春晚红包的另一种打开方式
- linux中删除特殊文件
- 在浏览器中输入url地址 - 显示主页的过程
- java所有代码都需要编译吗_为什么要编译此Java代码?
- 麦克风阵列技术 二 (自动增益控制 自动噪声抑制 回声消除 语音活动检测)
- w10系统asp服务器搭建,在windows10系统下搭建asp环境的方法
- Intel VT学习笔记(一)—— 基础知识支持检测