webclient无法获取html文件,C# WebClient获取网页源码的方法
效果如图
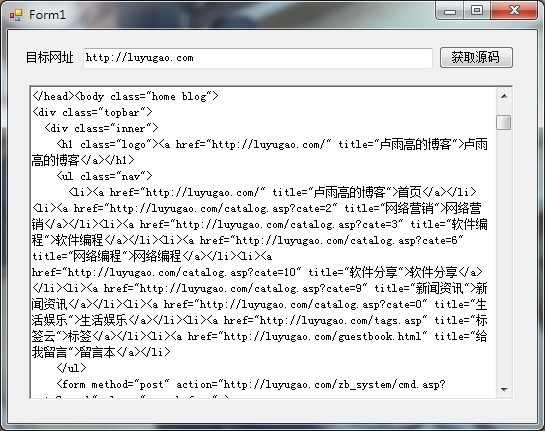
完整代码如下using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Text;
using System.Windows.Forms;
//引入以下命名空间
using System.Net;
using System.IO;
using System.Threading;
namespace splitstr
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
}
Thread t = null;
Encoding EE = Encoding.UTF8;//网页编码,根据实际情况来哈
private void bt_gethtml_Click(object sender, EventArgs e)
{
if (tb_url.Text.Trim() != "")
{
t = new Thread(new ThreadStart(Ss));
t.Start();
}
}
private delegate void SetObject();
private void Ss()
{
//CheckForIllegalCrossThreadCalls = false;
this.Invoke(new SetObject(delegate { bt_gethtml.Enabled = tb_url.Enabled = false; }));
this.Invoke(new SetObject(delegate { richTextBox1.Text = GetHtml(tb_url.Text.Trim(), EE); }));
this.Invoke(new SetObject(delegate { bt_gethtml.Enabled = tb_url.Enabled = true; }));
t.Abort();
}
private string GetHtml(string url,Encoding ecd)
{
//参数说明:目标网址,网页编码
string htmldata = "获取网页内容失败";
try
{
WebClient wclient = new WebClient();//实例化WebClient类对象
wclient.BaseAddress = url;//设置WebClient的基URI
wclient.Encoding = ecd;//指定下载字符串的编码方式
//为WebClient类对象添加标头
wclient.Headers.Add("Content-Type", "application/x-www-form-urlencoded");
//使用OpenRead方法获取指定网站的数据,并保存到Stream流中
Stream stream = wclient.OpenRead(url);
//使用流Stream声明一个流读取变量sreader
StreamReader sreader = new StreamReader(stream);
string str = string.Empty;//声明一个变量,用来保存一行从WebCliecnt下载的数据
//循环读取从指定网站获得的数据
while ((str = sreader.ReadLine()) != null)
{
htmldata += str + "\n";
}
}
catch { }
return htmldata;
}
}
}
当然获取网页源码还有其他的方法,过后再分享
webclient无法获取html文件,C# WebClient获取网页源码的方法相关推荐
- 使用WebBrowser控件获取网页源码的方法
使用WebBrowser控件获取网页源码的方法,网上有很多介绍,但绝大多数的人都是使用以下的方法获取: (WebBrowser1.Document as IHtmlDocument2).body.ou ...
- java 爬虫js渲染_java_爬虫_获取经过js渲染后的网页源码
md 弄了一天了--(这个月不会在摸爬虫了,浪费生命) 进入正题: 起初是想写一个爬虫来爬一个网站的视频,但是怎么爬取都爬取不到,分析了下源代码之后,发现源代码中并没有视频的dom 但是在浏览器检查元 ...
- python 爬虫源代码-Python爬虫学习之获取指定网页源码
本文实例为大家分享了Python获取指定网页源码的具体代码,供大家参考,具体内容如下 1.任务简介 前段时间一直在学习Python基础知识,故未更新博客,近段时间学习了一些关于爬虫的知识,我会分为多篇 ...
- C# -爬虫之WebBrowser跨域跨iframe获取网页源码
前言:这里关键写用WebBrowser跨域跨iframe获取网页源码的部分,本意是要爬取全职高手的有声小说,这类网站特殊,网页上广告大堆,爬起来真麻烦,比如我爬取的网站的mp3源文件下载还需要秘钥的, ...
- NanoPi NEO Air使用七:获取并编译U-boot和Linux的源码
NanoPi NEO Air使用一:介绍 NanoPi NEO Air使用二:固件烧录 NanoPi NEO Air使用三:OverlayFS.CPU温度和频率.wifi.蓝牙.npi-config ...
- webbrowser抓取php网页源码,获取webbrowser控件 网页的源码(收藏)
获取webbrowser控件 网页的源码(收藏) 翻译|其它|编辑:郝浩|2005-04-28 09:45:00.000|阅读 3152 次 概述: 我在网上找到使用rft控件保存webbrowse文 ...
- vc++获取网页源码之使用import+接口方式
1.使用IWinHttpRequest获取网页源码 首先要创建基于对话框的mfc应用程序 2.import+接口方式 首先导入winhttp.dll,使用IWinHttpRequest接口 #impo ...
- 获取Favicon.ico网站图标接口api源码
介绍: 获取Favicon.ico网站图标接口 favicon.ico一般用于作为缩略的网站标志,它显示位于浏览器的地址栏或者在标签上用于显示网站的logo, 目前主要的浏览器都支持favicon.i ...
- [转载]关于webbrowser,innet,xmlhttp获取网页源码的比较!
webbrowser: 示例: For i = 0 To WebBrowser1.Document.All.length - 1 If WebBrowser1.Document.All(i) ...
最新文章
- linux命令--提升
- 与旷视、商汤等上百家企业同台竞技?AI Top 30+案例评选等你来秀!
- 大数据背景下的高职院校信息化建设探索
- 流式机器学习算法的入门和认知
- linux sort命令 性能,linux sort 命令详解
- git@github.com: Permission denied (publickey).
- 【BZOJ - 4754】独特的树叶(树哈希)
- int.class 与 Integer.class
- 贴一个数据结构老师布置的作业(各种排序) c 语言实现
- Linux-rhel6.4 编译安装PHP,Nginx与php连接
- opencv ubuntu 汉字_ubuntu下没有中文输入法的解决办法
- 牛客练习赛23: D. 托米的咒语(暴力)
- 基于.net开发chrome核心浏览器【五】
- redis 配置文件配置
- PCI Express (PCIe) 介绍
- Chrome浏览器主页被hao123、360和2345篡改恢复到默认的方法
- 【深度】关于跨境出口B2C,你只需要看这篇文章!从“产品、物流、流量”三个维度分析出口B2C电商
- C语言实现(小米面试题)给定一个句子(只包含字母,空格,逗号和句号), 将句子中的单词位置反转,符号不变。(使用指针)
- c#为什么用的人很少
- Oracle数据库练习2
热门文章
- 【渝粤题库】国家开放大学2021春1258房屋建筑混凝土结构设计题目
- signature=a662b42175c342c2f67535627a2cf0a4,California and Nevada Railroad
- 蓝桥杯基础模块06_1:定时器计数器
- oracle impdp导入时卡住,Oracle:impdp导入等待statement suspended, wait error to be cleared
- 怎么安装红旗Linux5,如何用硬盘安装红旗LINUX5_0.doc
- IDEA中注解注释快捷键及模板
- linux系统基本使用教程,Linux系统的基本使用入门
- oracle查看存储过程最近编译,Oracle恢复被误编译覆盖的存储过程
- bzoj3143: [Hnoi2013]游走
- 剑指Offer 斐波那契数列