图解集成学习中的梯度提升思想
摘要: 本文讲述集成学习中的梯度提升方法的思想,以简单算术及图片的形式展示整个过程,一看就懂!
简介
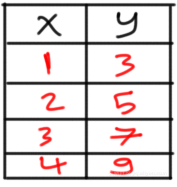
机器学习(ML)中的一个关键步骤是选择适合数据的最佳算法,根据数据中的一些统计数据和可视化信息,机器学习工程师将选择最佳算法。假设数据如下图所示,现在将其应用于回归示例:
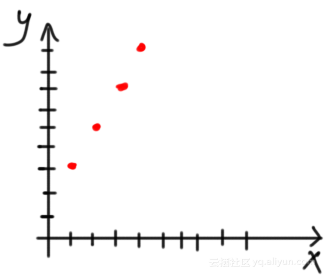
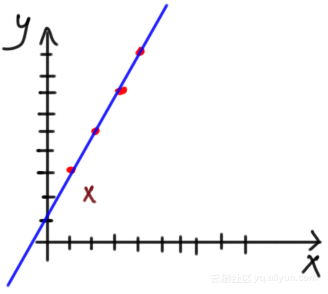
对数据进行可视化,如下图示所示,似乎线性回归模型对其比较合适:
将根据线性等式制定仅具有一个输入x和一个输出y的回归模型:
y=ax+by=ax+b
其中a和b是上述等式的两个参数。
由于我们不知道适合数据的最佳参数,因此可以从初始化取值开始。可以将a设置为1.0,将b设置为0.0,并可视化等式,如下图所示:
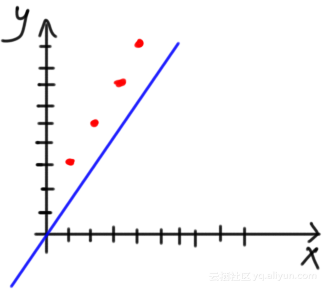
从图中可以看到,似乎该模型不能基于参数初始化取值来拟合数据。
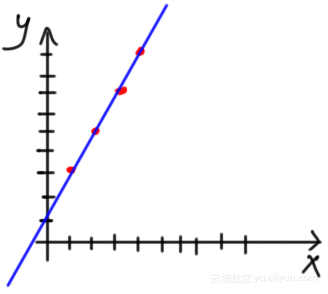
很明显,不可能第一次试验初始化就能取得很好的结果。但问题是如何在这种情况下提高性能?换句话说,如何最大化分类准确度或最小化回归误差?下面有不同的方法。其中一种简单的方法就是尝试更改先前选择的参数。经过多次试验,模型将知道最佳参数是a = 2和b = 1,该模型适合这种情况下的数据,如下图所示,可以看见拟合得非常好:
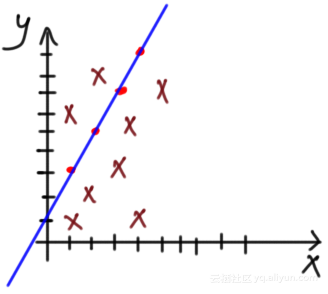
但是在某些情况下,更改模型参数并不会使得模型很好地拟合数据,仍然会有一些错误的预测。假设数据有一个新点(x = 2, y = 2)。从下图可以看出,不可能找到使模型完全适合每个数据点的参数,不适用于线性拟合。
有人可能会说,该模型能够拟合四个点而缺少一个点,这是可以接受的。但是,如果有更多的点,如下图所示呢?在这种情况下,该模型将做出更多的错误预测。没有一条直线可以拟合整个数据。该模型只对线上点的预测很强,但对其他点则较弱。
集成学习|Ensemble Learning
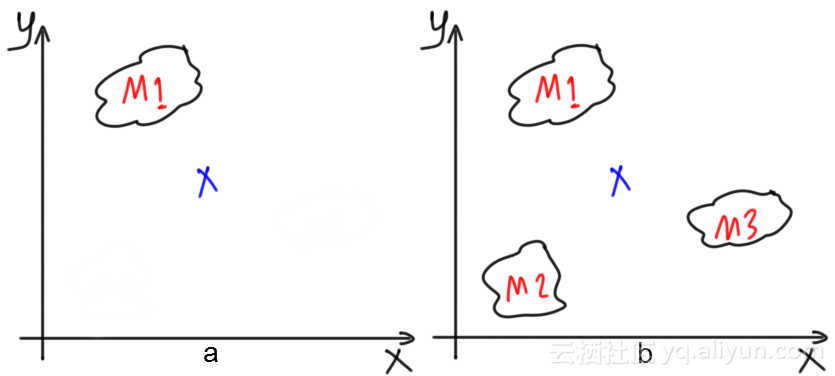
由于单个回归模型不适合整个数据,因此另一种解决方案是使用多个回归模型。每个回归模型都能够强有力地适应部分数据,将所有模型组合起来将减少整个数据的总误差,并产生一个通用的强大模型。在问题中使用多个模型的这种方法称为集合学习。使用多个模型的重要性如下图所示。图中显示了在预测样本结果时的误差很大。从图b中可以看到,当存在多个模型(例如,三个模型)时,其结果的平均值将能够比以前做出更准确的预测。
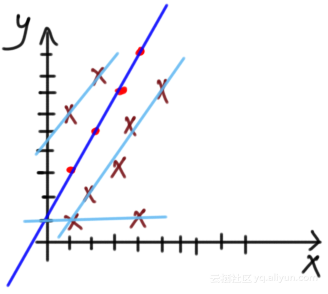
当应用于图7中的先前问题时,拟合数据的4个回归模型的集合在图9中已经表示出:
这就带了了另外的一个问题,如果有多个模型可以拟合数据,那么如何获得单个数据的预测?有两种方法可以组合多个回归模型来返回单个结果。它们是bagging和boosting(本文重点内容)。
在bagging中,每个模型将返回其结果,并对所有模型的输出结果进行综合,进而返回最终结果。一种综合方法是将所有模型的输出结果进行平均,bagging是平行工作的,因为所有模型都在同时工作。
相反,boosting被认为是顺序处理的,因为一个模型的输出结果是下一个模型的输入。boosting的想法是使用弱学习器来拟合数据。由于模型很弱,所以无法正确拟合数据,这种学习器的弱点将由另一个弱学习器来解决。如果仍然存在一些弱点,那么将使用另一个弱学习器来修复它们,直到最终从多个弱学习器中产生了强大的学习器。接下来将解释梯度增强的工作原理。
梯度提升|Gradient Boosting
以下是基于一个简单示例梯度提升的工作原理:
假设要构建一个回归模型,并且数据具有单个输出,其中第一个样本的输出为15,如下图所示。最终目标是建立能够正确预测这种输出的回归模型。

第一个弱模型预测第一个样本的输出为9而不是15,如下图所示:
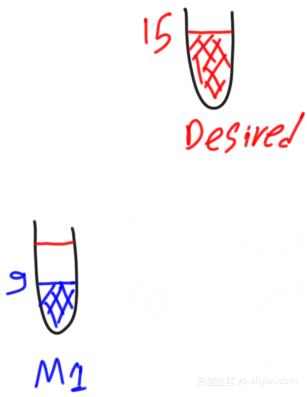
为了衡量预测的损失量,对其计算残差,剩余量是期望和预测输出之间的差异。计算等式如下:
期望−预测1=残差1期望−预测1=残差1
其中预测和残差1分别是第一个弱模型的预测输出和残差。
因此,上述例子的残差将为为:
15−9=615−9=6
由于预测输出和期望输出之间存在残差值为6的差距,因此可以创建第二个弱模型,其目标是预测输出等于第一模型的残差。所以,第二个模型将解决第一个模型的弱点。根据下面这个等式,两个模型的输出总和将等于期望输出:
期望输出=预测1+预测2(残差1)期望输出=预测1+预测2(残差1)
如果第二个弱模型能够正确地预测残差1,则期望输出将等于所有弱模型的预测,如下所示:
期望输出=预测1+预测2(残差1)=9+6=15期望输出=预测1+预测2(残差1)=9+6=15
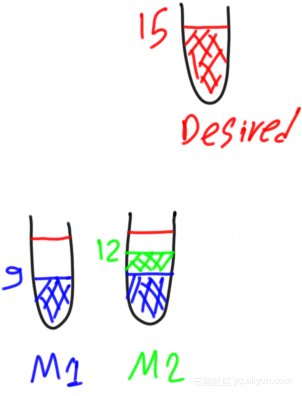
但是,如果第二个弱模型未能正确预测残差1的值,而仅返回的值为3,那么第二个弱学习器也将具有如下的残差:
残差2=预测1−预测2=6−3=3残差2=预测1−预测2=6−3=3
如下图所示:
为了解决第二个弱模型的弱点,将创建第三个弱模型。其目标是预测第二弱模型的残差。因此,它的目标输出值为3。所以,样本的期望输出将等于所有弱模型的预测,如下所示:
期望输出=预测1+预测2(残差1)+预测3(残差2)期望输出=预测1+预测2(残差1)+预测3(残差2)
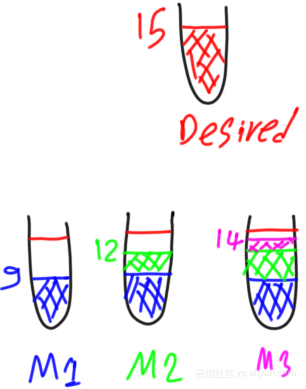
如果第三弱模型预测是2,不等于3,即它不能预测出第二个弱模型的残差,那么对于这样的第三个弱模型将存在残差:
残留3=预测2−预测3=3−2=1残留3=预测2−预测3=3−2=1
如下图所示
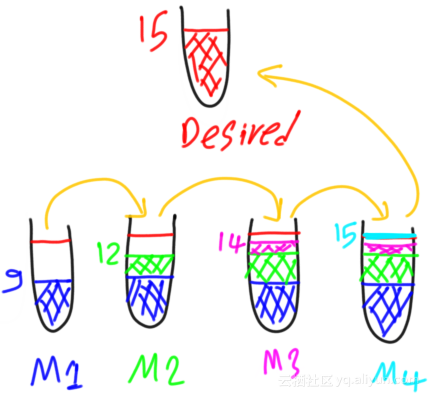
因此,将创建第四个弱模型来预测第三个弱模型的残差,其值等于1。期望输出将等于所有弱模型的预测,如下所示:
期望输出=预测1+预测2(残差1)+预测3(残差2)+预测4(残差3)期望输出=预测1+预测2(残差1)+预测3(残差2)+预测4(残差3)
如果第四个弱模型正确地预测其目标(即,残差值3),则总共使用四个弱模型即可达到15的期望输出,如下图所示。
这就是梯度增强算法的核心思想,使用先前模型的残差作为下一个模型的目标,有点类似于递归算法,满足终止条件即退出递归。
梯度提升总结
总而言之,梯度提升始于弱模型预测,这种弱模型的目标是使其预测值与问题的理想输出一致。在模型训练之后,计算其残差。如果残差不等于零,则创建另一个弱模型以修复前一个的弱点。但是这种新模型的目标并不是获得期望输出,而是先前模型的残差。也就是说,如果给定样本的期望输出是T,则第一模型的目标是T。在训练之后,对于这样的样本可能存在R的残差,所以要创建一个的新模型,并将其目标设置为R,而不是T,新模型填补以前模型的空白。
梯度增强类似于多个力量弱的人抬一个重物上楼梯。没有一个力量弱的人能够抬着重物走完真个楼梯,每个人只能抬着走一步。第一个人将重物提升一步并在此之后变得疲惫,无法继续;另一个人继续抬起重物并向前走另一步,依此类推,直到走完所有楼梯,重物到达指定位置。
原文链接
本文为云栖社区原创内容,未经允许不得转载。
图解集成学习中的梯度提升思想相关推荐
- 集成学习—SGBT随机梯度提升树
上一篇集成学习-GBDT原理理解中提到,由于GBDT的弱学习器之间存在依赖关系,难以并行训练数据,因此若数据量较大时程序运行太慢.这里可以通过加入了自采样的SGBT来达到部分并行,这是一个能改善GBD ...
- 深度学习中的梯度消失、梯度爆炸问题
写在前面: 有些博主对这个问题的解释很好,这里参考了: 详解机器学习中的梯度消失.爆炸原因及其解决方法 我在这方面的工作经验和知识面还不够,还需要积累后再做出更为专业的解答. 参考我之前转发过的一篇文 ...
- (七)集成学习中-投票法Voting
集成学习第一法宝:投票! 参考:DataWhale教程链接 集成学习(上)所有Task: (一)集成学习上--机器学习三大任务 (二)集成学习上--回归模型 (三)集成学习上--偏差与方差 (四)集成 ...
- 集成学习中的随机森林
摘要:随机森林是集成算法最前沿的代表之一.随机森林是Bagging的升级,它和Bagging的主要区别在于引入了随机特征选择. 本文分享自华为云社区<集成学习中的随机森林>,原文作者:ch ...
- 深度学习中的梯度下降算法
深度学习中的梯度下降算法 梯度下降算法-----致力于找到函数极值点的算法,深度学习中的核心算法. 所谓的学习便是改进模型参数,以便通过大量训练步骤将损失最小化. 有了这个概念,将梯度下降法应用于寻找 ...
- 图解连续学习中的蓄水池抽样算法(The Illustrated Reservoir sampling)
图解连续学习中的蓄水池抽样算法The Illustrated Reservoir sampling 前言 什么是Reservoir Sampling? 蓄水池抽样算法(Reservoir sampli ...
- 做时间序列预测有必要用深度学习吗?梯度提升回归树媲美甚至超越多个DNN模型...
©作者 | 杜伟.陈萍 来源 | 机器之心 在深度学习方法应用广泛的今天,所有领域是不是非它不可呢?其实未必,在时间序列预测任务上,简单的机器学习方法能够媲美甚至超越很多 DNN 模型. 过去几年,时 ...
- 深度学习中的梯度下降优化算法综述
1 简介 梯度下降算法是最常用的神经网络优化算法.常见的深度学习库也都包含了多种算法进行梯度下降的优化.但是,一般情况下,大家都是把梯度下降系列算法当作是一个用于进行优化的黑盒子,不了解它们的优势和劣 ...
- 深度学习中的梯度消失与梯度爆炸及解决方案
1.梯度消失与梯度爆炸 反向传播算法在神经网络中非常常见,可以说是整个深度学习的基石.在反向传播中,经常会出现梯度消失与梯度爆炸的问题.梯度消失产生的原因一般有两种情况:一是结构较深的网络,二是采用了 ...
最新文章
- 喜欢把代码写一行的人_我最喜欢的代码行
- 劝你别把开源的AI项目写在简历上了!!!
- es安装ik后报错无法启动 read write
- NLP-Beginner:自然语言处理入门练习-任务一
- MySQL动态行转列
- 操作系统:再见CentOS,将于本月底终止维护!
- 解决自定义actionbar 两边空隙
- oracle bookauthor,Oracle 聚簇(征集)
- 微信云支付so seay
- 3 基于采样的路径规划 —— RRT算法
- 申通核心业务系统上云战役
- SCI/ISTP和EI论文检索号IDS number和收录号查询方法,详细使用教程和指南手册
- IdentityServer4 去掉验证
- 硬件模块应用之超声波测距模块SRF05应用
- 杂记-Macbook Pro M1芯片能玩深度学习吗?
- 政府信息化与电子政务、企业信息化与电子商务、数据库和数据仓库的区别、商业智能系统处理过程、数据仓库结构图、数据挖掘、数据仓库和数据湖的对比
- 桌面任务栏不见了解决办法
- Springboot快递代取系统的设计与实现3i0v9计算机毕业设计-课程设计-期末作业-毕设程序代做
- 关于GPRS(cmnet、cmwap)和CDMA 1X的比较及最优方案
- 【加密解密】对exe文件的加密解密 含源代码》
热门文章
- 零基础自学编程应读书籍
- 【LeetCode笔记】42. 接雨水(Java、动态规划)
- kubernetes怎么读_每个 Kubernetes 应聘者应该知道的 5 个面试题 | Linux 中国
- strace命令_在软件部署中使用 strace 进行调试
- mysql 中caption_Django-Model操作数据库(增删改查、连表结构)(示例代码)
- php 强制刷新,web端实现后退强制刷新功能代码
- linux 常用参数,Linux 常用命令及参数整理
- 100999凑整到万位进一_四年级数学专项练习
- a jni error has occurred_A-08 幂函数、有理函数、代数函数
- 特斯拉工程师当UP主评测自动驾驶,结果被公司开除