【别用大批量mini-batch训练神经网络,用局部SGD】Don’t Use Large Mini-batches, Use Local SGD
转载 https://blog.csdn.net/weixin_34356138/article/details/89158834
2020 ICLR Don’t Use Large Mini-batches, Use Local SGD


\\
介绍
\\
随机梯度下降(SGD)由于其极高的效率,成为目前大多数机器学习应用中最常见的训练方法。在考虑计算效率时,mini-batch SGD同时计算多个随机梯度,似乎不符合计算效率的要求。但是mini-batch SGD可以在不同网络之间并行化,所以它是现代分布式深度学习应用的更好选择。有以下两个原因:(1)mini-batch SGD可以利用在GPU上的局部计算并行性;(2)降低参数更新频率有助于减轻不同设备间的通信瓶颈,这对于大型模型的分布式设置是十分重要的。
\\
目前有些方法为了减少训练时间,使用大批量的SGD。但是这一选择是错误的,因为它没有正确考虑设备的局部并行化以及设备间的通信效率。尤其是当设备的数量增加时,每台设备的并行化程度会严重约束通信效率。
\\
为了解决这个问题,我们提出在每个网络上使用局部SGD的一种新变体。局部SGD在几次迭代后(无通信)对网络的平均来更新参数。我们发现,调整通信间隔中的迭代次数可以成功地将局部并行性与通信延迟分离。
\\
我们进一步将该想法推广到去中心化和异质的系统上。如下图所示的层次化网络结构推动了局部SGD的层次化扩展。
\\
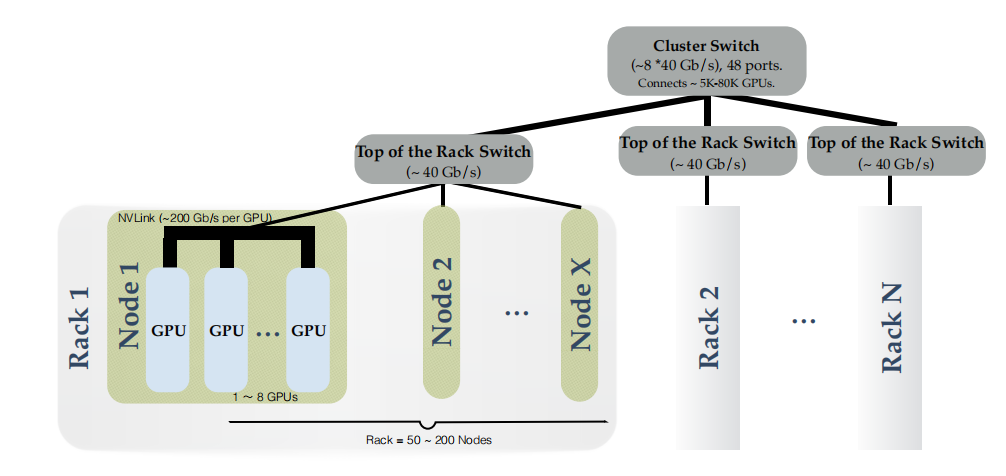
\\
图1 数据中心某集群的层次化网络结构示意图。
\\
除此之外,端用户的设备,例如移动手机,组成了巨大的异质网络。在这里,机器学习模型的分布式计算和数据局部训练具有极大的优势。
\\
论文贡献
\\
我们提出了一个新的局部SGD的层次化扩展训练框架,进一步提高了局部SGD对实际应用中异质分布系统的适应性。对于实际情况下多服务器或数据中心的训练,层次结构的局部SGD比局部SGD和mini-batch SGD均提供了更好的表现性能,尤其是在达到同样准确率的情况下,层次结构的SGD提高了通信效率。
\\
我们在多个计算机视觉模型上进行了局部SGD训练方法的实证研究,实验显示了该方法相比于mini-batch SGD有明显优势。结果显示局部SGD在保证预测准确率的前提下大大降低了通信需求。在ImageNet上,局部SGD的表现超出了现有的大批量训练方法约1.5倍。
\\
分布式训练
\\
我们主要考虑标准的求和结构的优化问题:
\\
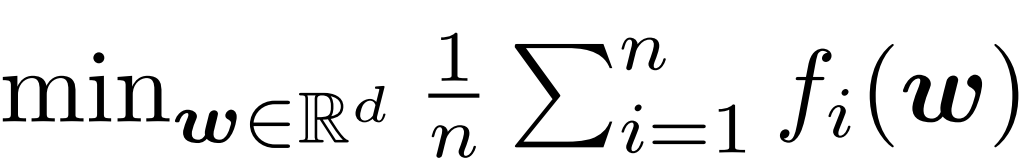
\\
其中w是模型(神经网络)的参数,fi是第i个训练样本的损失函数。
\\
Mini-batch SGD表达式为:
\\
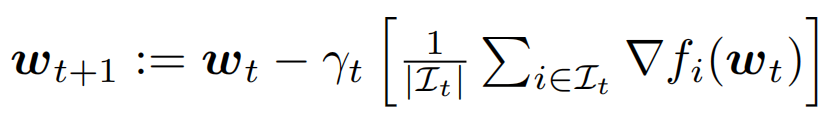
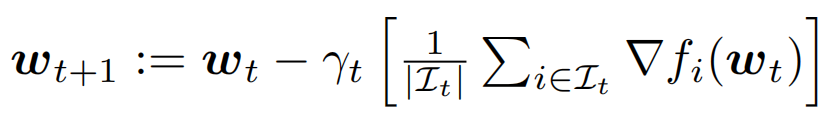
\\
在分布式设置中,数据样本被划分到K个设备上,每个设备只能访问局部的训练数据。在这种情况下的mini-batch SGD算法表达式为:
\\
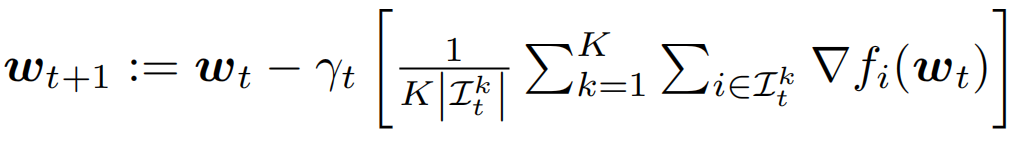
\\
这里第k个设备的mini-batch来自本地数据,这K个设备并行计算梯度,然后通过平均来同步局部梯度。
\\
局部SGD
\\
与mini-batch SGD相比,局部SGD先在每个设备上进行局部的序列更新,然后累积K个设备之间的参数更新,如下图所示。
\\

\\
图2 一轮局部SGD(左)与一次mini-batch SGD(右)对比。每个设置中批尺寸B_loc均为2,对于局部SGD,进行H=3次局部迭代。局部参数更新由红色箭头表示,而全局平均(同步)由紫色箭头表示。
\\
每个网络k反复地从局部数据中提取固定数量的样本,批尺寸为B_loc,然后进行H次局部参数更新,在此之后再与其他设备进行全局参数累积。因此,每一次同步(通信),局部SGD在每一台设备上已经访问了B_glob=H x B_loc个训练样本(亦为梯度计算次数)。
\\
一轮局部SGD可以描述为:
\\
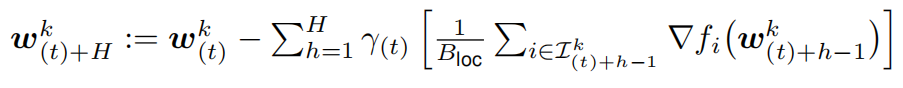
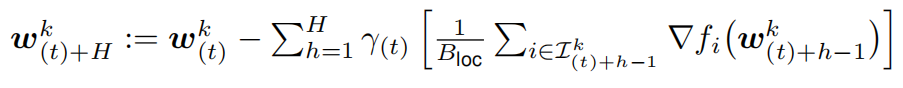
\\
其中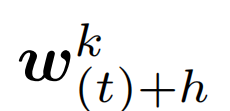 表示设备k上的局部模型在t次全局同步以及h次局部更新之后的参数。在H次局部更新后,同步的全局模型
表示设备k上的局部模型在t次全局同步以及h次局部更新之后的参数。在H次局部更新后,同步的全局模型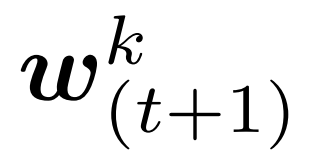 通过平均K个模型得到:
通过平均K个模型得到:
\\
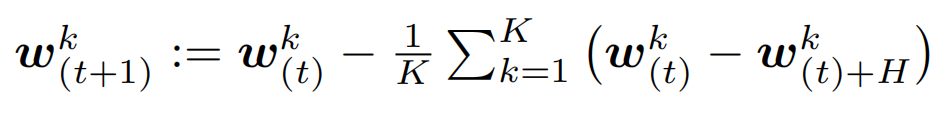
\\
层次化局部SGD
\\
实际的系统都会有不同的通信带宽,因此我们提出将局部SGD部署在不同层级上,使之适应相应层级的计算能力与通信效率的平衡。层次化局部SGD在系统适应性和表现性能上均具有显著优势。
\\
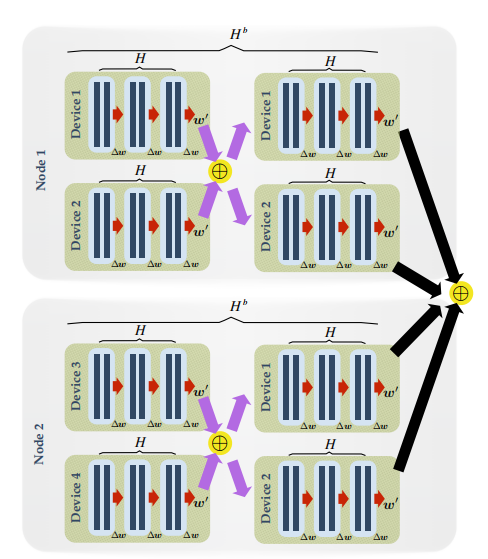
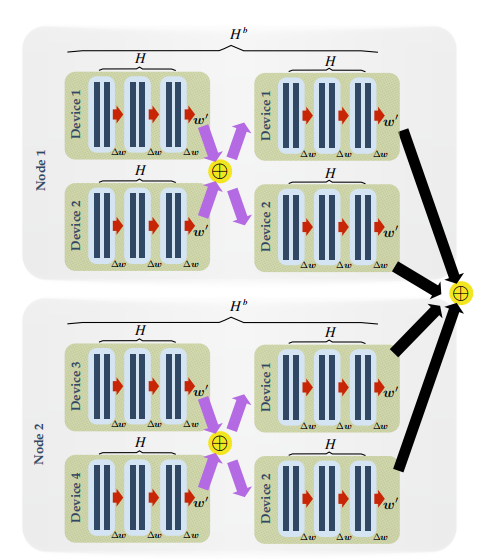
下图是层次化局部SGD的示意图:
\\
\\
图3 层次化局部SGD示意图。设批尺寸B_loc=2,局部迭代次数为H=3,区块迭代次数H_b=2。局部参数更新用红色箭头表示,而区块和全局同步分别用紫色和黑色箭头表示。
\\
我们以GPU计算集群为例,将大量GPU成组分布于几个机器上,将每组称为一个GPU区块。层次化的局部SGD连续更新每块GPU上的局部模型,在H次局部更新之后,会在GPU区块内部进行一次快速同步。在外层,在H_b次区块更新后,会对所有的GPU区块进行全局的同步。完整的过程可以表达如下:
\\
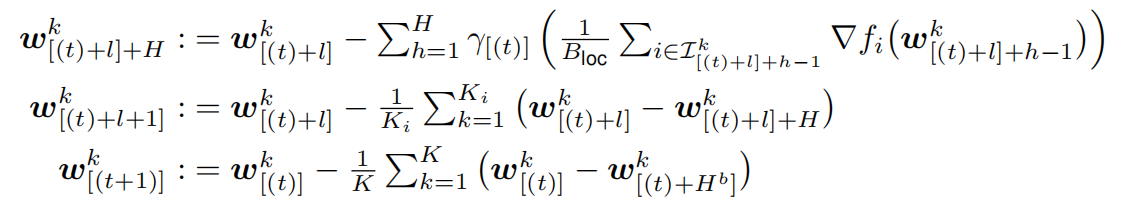
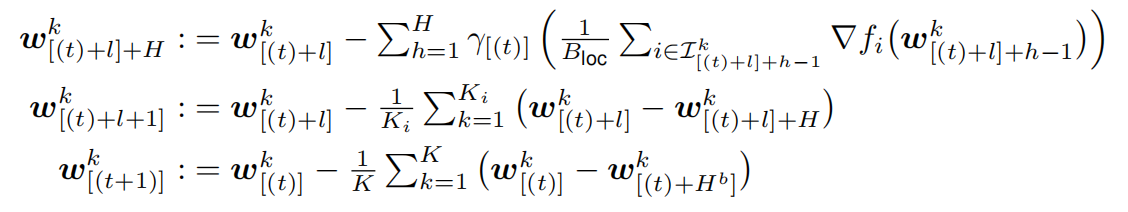
\\
实验结果
\\
在这一部分,我们通过实验分析对比mini-batch SGD和我们提出的层次化局部SGD的性能。
\\
数据集
\\
- CIFAR-10/100。训练集包含50K张彩色图像,测试集包含10K张彩色图像,大小均为32 x 32,分别具有10个和100个类别标签。我们采用标准数据增强方法和预处理方法处理数据集。\\t
- ImageNet。ILSVRC2012图像分类数据集包含128百万张训练图像,50K张验证图像,具有1000个类别标签。网络输入图像大小为224 x 224。\
模型选择
\\
我们用ResNet-20来测试(层次化)局部SGD在CIFAR-10/100上的表现,然后用ResNet-50来测试(层次化)局部SGD在ImageNet上的准确率和可扩展性。我们也用DenseNet和WideResNet进行了实验,验证局部SGD对不同模型的泛化能力。
\\
CIFAR-10/100实验
\\
- 局部SGD训练\
对于CIFAR-10,我们在2个服务器上进行局部SGD训练,每个服务器有1块GPU。
\\
保证准确率的同时提高通信效率
\\
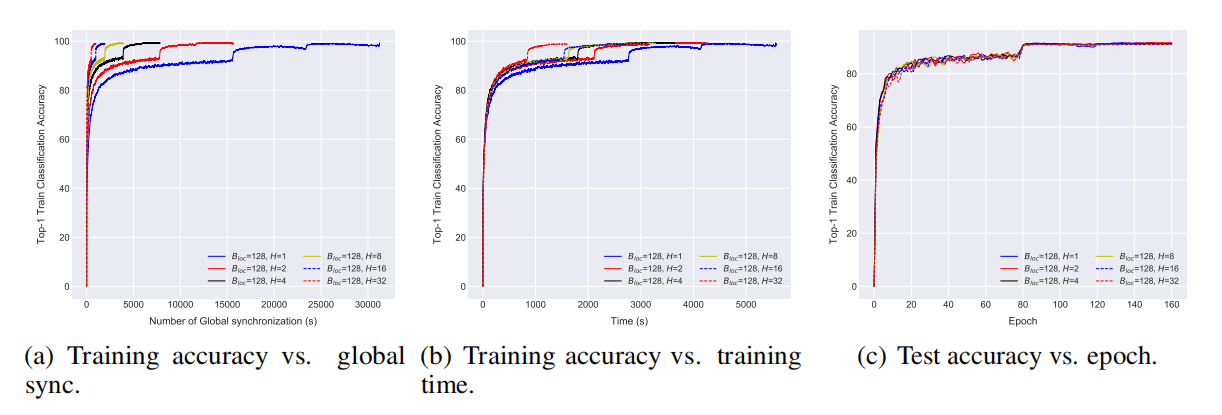
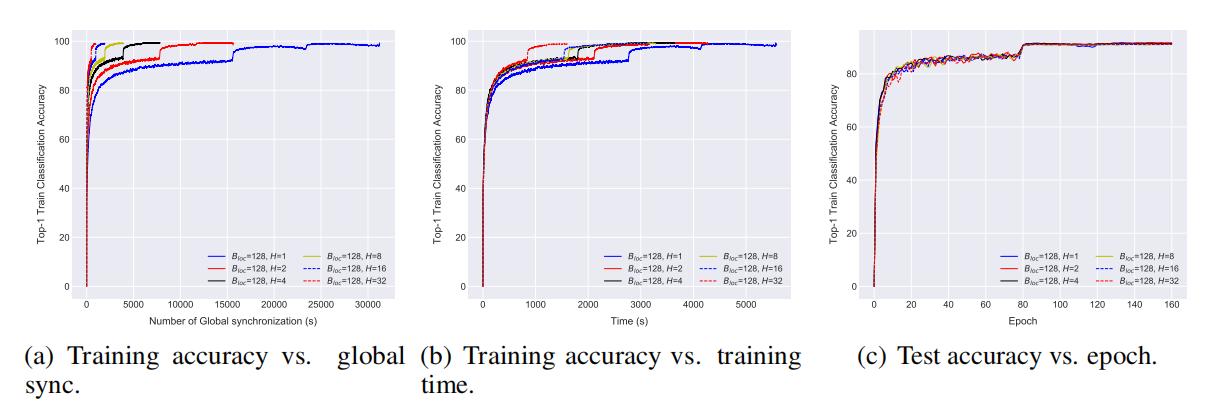
\\
图4 通过局部SGD在CIFAR-10数据集上训练ResNet-20。批尺寸B_loc=128,局部更新次数从1到32。
\\
从图4中可以看出,局部SGD在保证了准确率的同时,极大提高了通信效率,并且具有更快的收敛速度。在实验中,mini-batch SGD是局部SGD的一种特殊形式,(局部迭代次数)H=1。从图4(a)可以看出,对于同样数量的样本,局部SGD缓解了通信瓶颈的问题。图4(b)给出了局部SGD对于整体训练时间的影响:局部迭代次数H越大,影响越大,H=32时局部SGD至少比mini-batch SGD快3倍。从图4(c)中可以看出,对于不同的H值,最终的准确率会趋于稳定,并且与测试准确率并无大的差异。
\\
比“大批量训练”更好的泛化能力
\\

\\
表1 通过局部SGD在CIFAR-10数据集上训练ResNet-20。给出了固定访问数据量B_glob时,mini-batch SGD和局部SGD的top-1测试准确率。
\\
从表1中可以看出当访问同样的样本数时,局部SGD比mini-batch SGD具有更好的泛化能力。大批量训练方法提出了很多技巧来克服收敛问题,包括改变学习率和逐渐开始。Mini-batch SGD如果采用大批量训练方法仍然会有很多问题,而局部SGD通过局部迭代次数很自然的解决了这个问题。
\\
- 层次化的局部SGD训练\
下面我们在分布式异质系统上测试我们提出的训练方法。我们模仿真实情况的设定,即计算设备(GPU)在不同的服务器上的集群,网络带宽限制了大型模型更新所需的通信效率。
\\

\\
表2 随机SGD在CIFAR-10数据集上训练ResNet-20模型(5 x 2GPU集群)。在局部批尺寸B_loc和区块迭代次数H_b固定的情况下,我们给出了H从1到1024,训练时间的变化情况。
\\
训练时间 vs 局部迭代步数
\\
表2给出了局部SGD与训练时间的关系。通信需求主要来自于5个节点的全局同步,每个节点有2个GPU。我们发现过大的局部更新迭代次数甚至会降低局部更新带来的通信优势。这一性能降级或许是由于独立的局部过程增加了同步时间。
\\
层次化局部SGD对网络延迟的高容忍度
\\
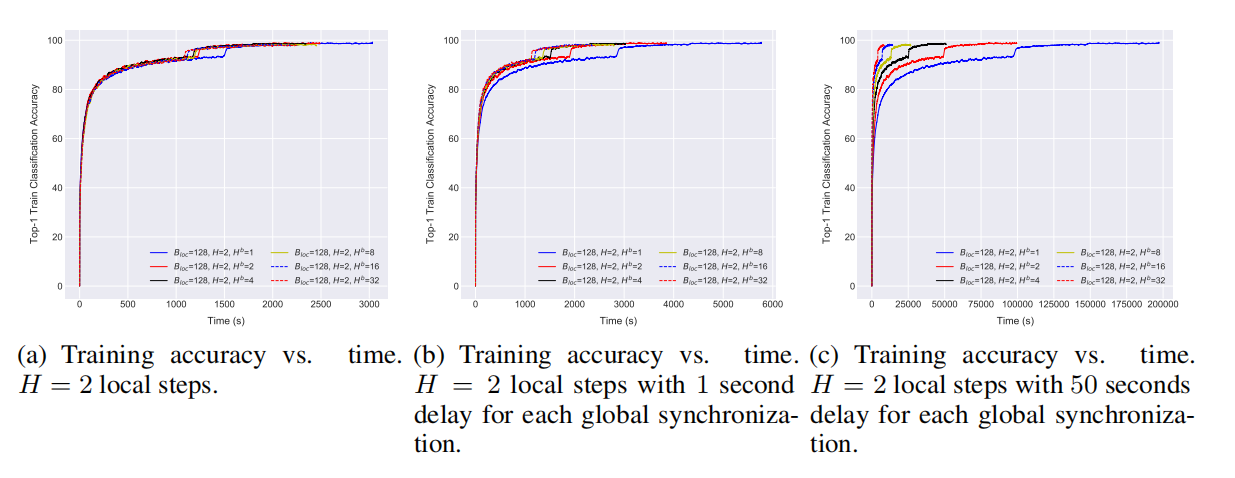
\\
图5 层次化局部SGD在CIFAR-10数据集上训练ResNet-20模型(2 x 2GPU集群)表现性能。局部迭代次数H=2(a)训练准确率vs时间(b)每次全局同步有1秒延迟情况下的训练准确率vs时间(c)每次全局同步有50秒延迟情况下的训练准确率vs时间.
\\
层次化的局部SGD对网络延迟具有鲁棒性。例如,对于固定的H=2,通过减少在所有模型上进行全局同步的次数,我们可以减少一定的训练时间,如图5(a)所示。图5(b)进一步展示了网络对于较慢的通信的影响,其中每个全局通信都增加了1秒的延时。图5(c)显示增加区块内迭代次数能够克服通信瓶颈的问题,而不会对表现造成影响。
\\
层次化局部SGD能够进行更大的扩展并且具有更好的表现
\\


\\
表3 层次化局部SGD在CIFAR-10数据集上训练ResNet-20模型(10GPU Kubernetes 集群)表现性能。
\\
表3对比了mini-batch SGD和层次化的局部SGD。我们可以发现,具有足够区块迭代次数的层次化局部SGD可以有效缓解准确率降低的问题。并且,内节点同步次数更多的层次化局部SGD的表现也超过了局部SGD。结合表2和表3可以发现,层次化的局部SGD的表现超过了局部SGD和mini-batch SGD的训练速度和模型表现。
\\
ImageNet-1K实验
\\
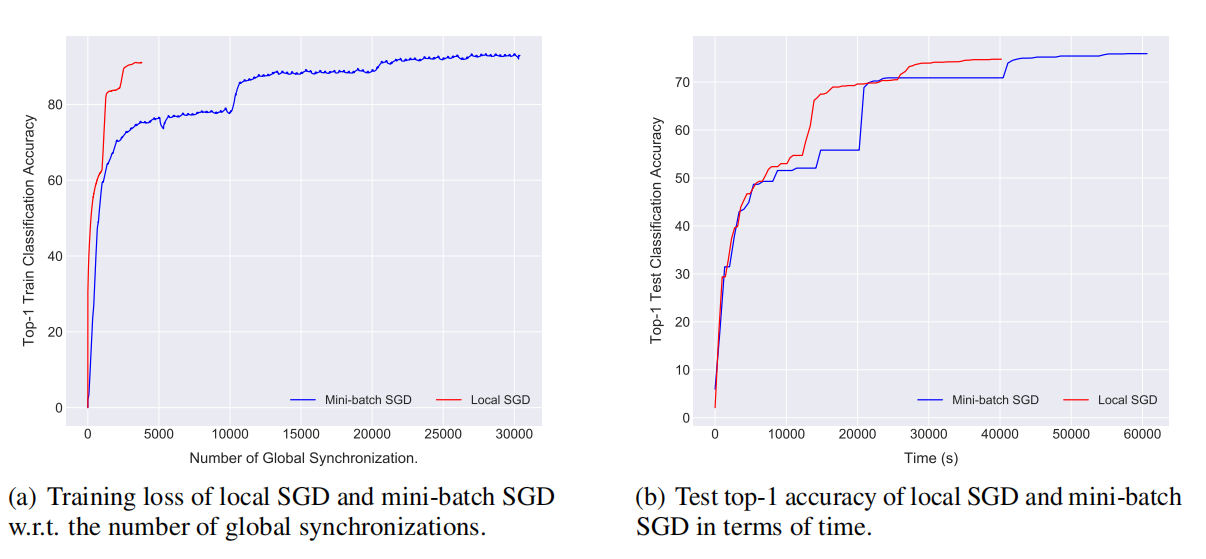
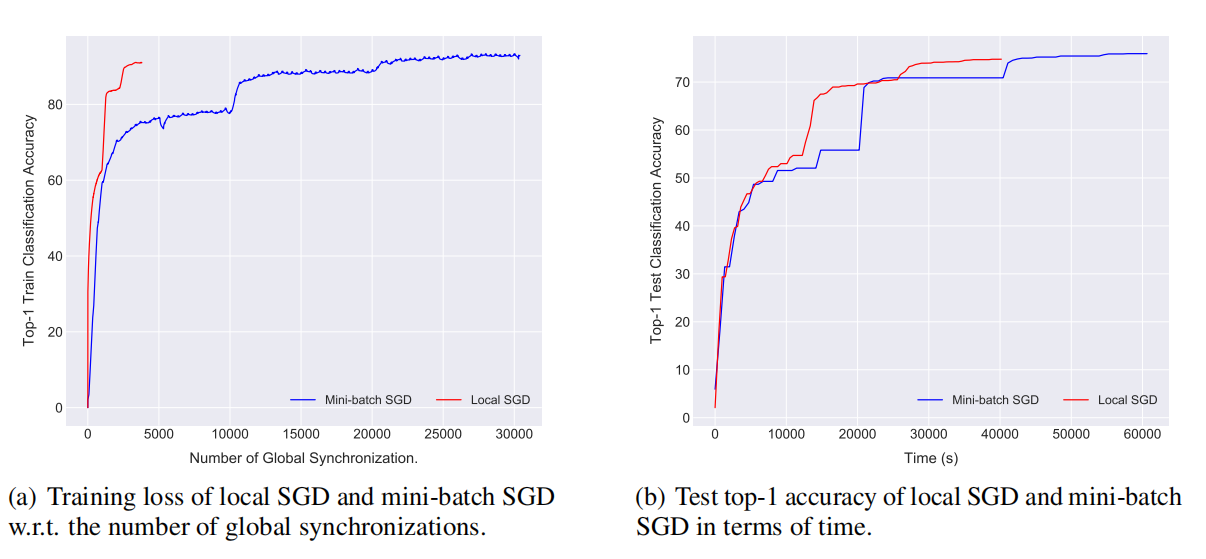
\\
图6 局部SGD在ImageNet-1k数据集上训练ResNet-50模型(15 x 2GPU集群)表现性能。
\\
图6显示我们可以通过局部SGD在15 x 2GPU集群上有效训练(快1.5倍)ResNet-50。在达到同样准确率时,局部SGD只需要很少的时间和同步次数,节省了计算量,并且提高了通信效率。
\\
结论
\\
在这篇文章中,我们利用局部SGD的思想,将其扩展至去中心化和异质的系统环境。我们提出了层次化的局部SGD,能够有效适应于实际情况中的异质系统。此外,我们实证研究了局部SGD在不同的计算机视觉模型上的表现,实验显示算法在整体性能和通信效率方面均有显著提高。
\\
查看论文原文:Don't Use Large Mini-Batches, Use Local SGD
\\
感谢蔡芳芳对本文的审校。
【别用大批量mini-batch训练神经网络,用局部SGD】Don’t Use Large Mini-batches, Use Local SGD相关推荐
- 训练神经网络如何确定batch大小?
训练神经网络如何确定batch大小? 本文转载于:https://dwz.cn/0Suxu3NX,经作者同意 有兴趣的同学可以看看:https://www.zhihu.com/question/616 ...
- 神经网络中的批量归一化Batch Normalization(BN)原理总结
0.概述 深层神经网络存在的问题(从当前层的输入的分布来分析):在深层神经网络中,中间层的输入是上一层神经网络的输出.因此,之前的层的神经网络参数的变化会导致当前层输入的分布发生较大的差异.在使用随机 ...
- 神经网络的三种训练方法,训练神经网络作用大吗
神经网络到底有什么作用,具体是用来干什么的? . 神经网络(ArtificialNeuralNetworks,简写为ANNs)也简称为神经网络(NNs)或称作连接模型(ConnectionModel) ...
- 从零开始教你训练神经网络(附公式学习资源)
来源:机器之心 作者:Vitaly Bushaev 本文长度为8900字,建议阅读15分钟 本文从神经网络简单的数学定义开始,沿着损失函数.激活函数和反向传播等方法进一步描述基本的优化算法. 作者从神 ...
- 使用TensorFlow训练神经网络进行价格预测
Using Deep Neural Networks for regression problems might seem like overkill (and quite often is), bu ...
- 聚类分析(三)Mini Batch KMeans算法
在当前大数据的背景下,工程师们往往为了追求更短的计算时间,不得不在一定程度上减少算法本身的计算精度,我说的是在一定程度上,所以肯定不能只追求速度而不顾其它.在KMeans聚类中,为了降低计算时间,KM ...
- 【机器学习】无监督学习--(聚类)Mini Batch K-Means
1. Mini Batch K-Means概述 Mini-Batch-K-MEANS算法是K-Means算法的变种,采用小批次量的数据子集减少计算时间.这里所谓的小批量是指每次训练算法时所随机抽取的数 ...
- 模拟数据集上训练神经网络,网络解决二分类问题练习
#2018-06-24 395218 June Sunday the 25 week, the 175 day SZ ''' 模拟数据集上训练神经网络,网络解决二分类问题.'''import tens ...
- P7 P8:训练神经网络
子豪兄YYDS https://www.bilibili.com/video/BV1K7411W7So?p=7 https://www.bilibili.com/video/BV1K7411W7So? ...
最新文章
- pandas使用groupby函数计算dataframe数据中每个分组的N个数值的滚动标准差(rolling std)、例如,计算某公司的多个店铺每N天(5天)的滚动销售额标准差
- 第二阶段个人冲刺10
- python求解方程组_python如何解方程组
- c语言字符数组给字符指针,C语言常见有关问题之字符串数组和字符指针数组有关问题...
- qt中tinyxml2的基本使用方法
- android 指示灯权限,Android实现LED灯显示效果
- SpringMVC_04 拦截器 【拦截器的编程步骤】【session复习?】
- java编译sql存过_SQL SERVER 临时表导致存储过程重编译(recompile)的一些探讨
- 英国PHP轴承,php – 纵向宽度将如何影响轴承
- SharePoint 2010 添加“我的链接”菜单
- 有哪些激光雷达SLAM算法?
- 总结一下用caffe跑图片数据的研究流程接上篇
- Hive exited with status 1
- HCIA网络基础17-HDLC和PPP
- springboot使用logback
- 2020.8.13 京东Android开发二面
- 第17课:强化学习的模型训练
- 5.服务网关:GateWay
- 光猫、交换机、路由器三者的区别在哪里?如何选择?
- uni-app app项目运行至夜神模拟器