分布式计算的基本原理
从最近几次MMI设计会议讨论的结果来看,嵌入式程序员对于分布式计算知之甚少。他们对分布式计算有种恐惧,所以对分布式架构极力排斥。而他们的人数又占绝对优势,讨论N次,MMI的架构还是没有确定下来。分布式计算已经进入桌面环境,不是企业应用的专利了,像GNOME(GNU Network Object Model Environment)的名字本身就暗示着分布式计算了。本文介绍一下分布式的基本原理,揭开分布式神秘的面纱,让嵌入式程序员熟悉一下。
分布式计算可以分为以下几类:
传统的C/S模型。如HTTP/FTP/SMTP/POP/DBMS等服务器。客户端向服务器发送请求,服务器处理请求,并把结果返回给客户端。客户端处于主动,服务器处于被动。这种调用是显式的,远程调用就是远程调用,本地调用就是本地调用,每个细节你都要清楚,一点都含糊不得。
集群技术。近年来PC机的计算能力飞速发展,而服务器的计算能力,远远跟不上客户端的要求。这种多对一的关系本来就不公平,人们已经认识到靠提高单台服务器的计算能力,永远满足性能上的要求。一种称集群的技术出现了,它把多台服务器连接起来,当成一台服务器来用。这种技术的好处就是,不但对客户来说是透明的,对服务器软件来说也是透明的,软件不用做任何修改就可以在集群上运行。集群技术的应用范围也仅限于此,只能提高同一个软件的计算能力,而对于多个不同的软件协同工作无能为力。
通用型分布式计算环境。如CORBA/DCOM/ RMI/ DBUS等,这些技术(规范)差不多都有具有网络透明性,被调用的方法可能在另外一个进程中,也可能在另外一台机器上。调用者基本上不用关心是本地调用还是远程调用。当然正是这种透明性,造成了分布式计算的滥用,分布式计算用起来方便,大家以为它免费的。实际上,分布式计算的代价是可观的,据说跨进程的调用,速度可能会降低一个数量级,跨机器的调用,速度可能降低两个数量级。一些专家都建议减少使用分布式计算,即使要使用,也要使用粗粒度的调用,以减少调用的次数。
还其一些混合形式(SOAP?),这里不再多说。我们主要介绍第三种分布式模型,这类分布式模型即适用于企业级应用,也适用于桌面应用。有的专注于企业级应用(如CORBA),有的专注于桌面环境(如DBUS)。它们的实现原理都差不多,基本上都基于传统的RPC或者仿RPC实现的,下面介绍一下它们的基本原理。
我们先看一下分布式的最简模型:
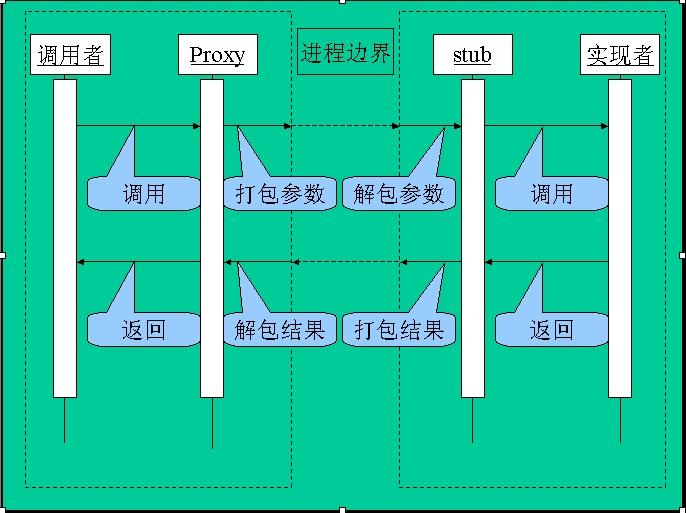
在传统的方法中,调用一个对象的函数很简单:创建这个对象,然后调用它的函数就行了。而在分布式的环境中,对象在另外一个进程中,完全在不同的地址空间里,要调用它的函数可能有点困难了。
看看传统的C/S模型的请求方式,客户端把参数通过网络发给服务器,服务器根据参数要求完成相应的服务,然后把结果返回给客户端,客户端拿到结果了,一次请求算完成。由此看来,调用远程对象似乎并不难,问题在于这种方式不是网络透明的,每一个细节你都要自己处理,非常复杂。
要简化软件的设计,当然是网络操作透明化,调用者和实现者都无需关心网络操作。要做到这一点,我们可以按下列方法:
在客户端要引入一个代理(Proxy)对象。它全权代理实际对象,调用者甚至都不知道它是一个代理,可以像调用本地对象一样调用这个对象。当调用者调用Proxy的函数时,Proxy并不做实际的操作,而是把这些参数打包成一个网络数据包,并把这个数据包通过网络发送给服务器。
在服务器引入一个桩(Stub)对象,Stub收到Proxy发送的数据包之后,把数据包解开,重新组织为参数列表,并用这些参数就调用实际对象的函数。实际对象执行相关操作,把结果返回给Stub,Stub再把结果打包成一个网络数据包,并把这个数据包通过网络发送给客户端的Proxy。
Proxy收到结果数据包后,把数据包解开为返回值,返回给调用者。至此,整个操作完成了。怎么样,简化吧。
Proxy隐藏了客户端的网络操作,Stub隐藏了服务器端的网络操作,这就实现了网络透明化。你也许会说,根本没有简化,只是把网络操作隔离开了,仍然要去实现Proxy和Stub两个对象,一样的麻烦。
没错。不过仔细研究一下Proxy和Stub的功能,我们会发现,对于不同对象,这些操作都差不多,无非就是打包和解包而已,单调重复。单调重复的东西必然有规律可循,有规律可循就可以用代码产生器自动产生代码。
像DCOM和CORBA等也确实是这样做的,先用IDL语言描述出对象的接口,然后用IDL编译器自动产生Proxy和Stub代码,整个过程完全不需要开发人员操心。
打包和解包的专业术语叫做marshal和unmarshal,中文常用翻译为列集和散集。不过这两个词太专业了,翻译成中文之后更加让人不知所云。我想还是用打包和解包两个词更通俗一点。
在以上模型中,调用对象的方法,确实做到了网络透明化。读者可以会问,我要访问对象的属性怎么办呢?对象的属性就是变量,变量就一块内存区域,内存区域在不同的进程里完全是独立的,这看起来确实是一个问题。还记得很多关于软件设计书籍里面讲过的吗:不要暴露对象属性,调用者若要访问对象的属性,通过get/set方法去访问。这样不行了吗,对属性的访问转换为对对象方法的调用。
OK,调用对象的方法和访问对象的属性都解决了。还有重要的一点,如何创建对象呢。因为实际的对象并不固定在某台机器上,它的位置可能是动态的。甚至Proxy本身也不知道Stub运行在哪里。如果要让调用者来指定,创建对象的过程仍未达到网络透明化。通常的做法是引入一个第三方中介,这个第三方中介是固定的,可以通过一定的方法找到它。第三方中介负责在客户端的Proxy和服务器的Stub之间穿针引线。第三方中介通常有两种:一种是只负责帮客户端找到服务器,之后客户端与服务器直接通信。另外一种就是不但负责找到服务器,而且负责转发所有的请求。
以上的模型仍然不完整,因为现实中的对象并不是一直处理于被动的地位。而是在一定的条件下,会主动触发一些事件,并把这些事件上报给调用者。也就是说这是一个双向的动作,单纯的C/S模型无法满足要求,而要采用P2P的方式。原先的客户端同时作为一个服务器存,接受来自己服务器的请求。像COM里就是这样做的,客户端要注册对象的事件,就要实现一个IDispatch接口,给对象反过来调用。
自己实现时还要考虑以下几点:
l 传输抽象层。分布可能是跨进程也可能是跨机器。在不同的情况下,采用不同的通信方式,性能会有所不同。做一个传输抽象层,在不同的情况下,可选用不同的传输方式,是一种好的设计。
l 文本还是二进制。把数据打包成文本还是二进制?打包成文本的好处是,可移植性好,由于人也可以看懂,调试方便。坏处是速度稍慢,打包后的数据大小会明显变大。采用二进制的好处是,速度快,打包后的数据大小与打包前相差不大。坏处是不易调试,可移植性较差。
l 字节顺序和字节对齐。若采用二进制方式传输,可移植性是个问题。因为不同的机器上,字节顺序和字节对齐的方式都有些差异,在数据包中要加入这些说明,以提高可移植性。
分布式计算的基本原理相关推荐
- 李开复:拥抱美丽的网络应用模式——云计算
很难用一句话说清楚到底什么才是真正的云计算.单单是"云计算"这个名字就已经足够新潮,足够浪漫了.其实,我们可以简单地把整个互联网看成是一片美丽的云彩,现在,连接到这片云彩的网民在全 ...
- java架构师和大数据架构师有哪些不同
Java是我们熟悉的编程语言,大数据是当今科学技术的明星技术.Java和Java大数据架构的内容是否相同??两者有什么不同呢?今天小编就从Java和大数据架构的以下方面谈谈两者的区别. Java架构方 ...
- Hive性能调优实战 分享
获取方式 链接:https://pan.baidu.com/s/1TmkWssL1K45af7GDrj2QWw 提取码:26uv 关注我的公众号[宝哥大数据],更多干货 目录 第1章 举例感受Hive ...
- 互联网公司的招聘职位需求
2019独角兽企业重金招聘Python工程师标准>>> 职位要求:3年以上相关工作经验,最好本科及以上,感兴趣的可加我QQ:1654704304 一.搜索离线开发/算法工程师 岗位描 ...
- java网络编程与分布式计算_Java网络编程与分布式计算
基本信息 书名:Java网络编程与分布式计算 定价:38.00元 作者:[澳]赖利 出版社:机械工业出版社 出版日期:2003-03-00 ISBN:9787111115786 字数: 页码: 版次: ...
- 《Python分布式计算》 第8章 继续学习 (Distributed Computing with Python)
序言 第1章 并行和分布式计算介绍 第2章 异步编程 第3章 Python的并行计算 第4章 Celery分布式应用 第5章 云平台部署Python 第6章 超级计算机群使用Python 第7章 测试 ...
- HDFS基本原理及数据存取实战
---------------------------------------------------------------------------------------------------- ...
- 分布式计算、网格计算和云计算
前几天与几个同事无意中聊起了云计算,还说Google也推出了相应的服务. 心里就一直在想这到底是个什么东西哪,上网搜索了一把,又找到几个相近的概念,就在这里记录一下. 1.分布式计算 所谓分布式计算是 ...
- 网络与分布式计算复习
第一章 概论 分布计算系统的定义 分布式计算系统是由多个相互连接的计算机组成的一个整体,这些计算机在一组系统软件环境下,合作执行一个共同的或不同的任务,最少依赖于集中的控制过程.数据和硬件. 分布式计 ...
最新文章
- matlab 信号的原子产生,MATLAB随机产生原子结构代码
- Shell中创建序列和数组(list、array)的方法
- 【JavaWeb】已解决:Resource interpreted as Stylesheet but transferred with MIME type text/html
- selenium 翻页_利用selenium实现自动翻页爬取某鱼数据
- java包装项目_项目包装组织
- 运行java是提示 选择未包含 main 类型 如何解决_RuoYi 若依 代码生成器使用教程...
- java 安卓调试_【转】Android 调试技术
- oracle左连接没用_oracle左外连接不显示正确的空值
- android 水波纹进度,Android自定义View-水波纹progressbar
- 用旧手机搭建服务器保姆级教程,不需要root也能成功
- 地形建模(二)--TIN拉伸成模型并贴纹理
- 测试功能点----方法
- 环境参数智能监测站设计(说明书篇)
- gpu云服务器运行游戏_显卡云主机-游戏安卓模拟器GPU独立显卡云服务器
- python独立网站教程_python做网站教程_如何免费做网站的教程
- ping是什么,有什么作用?
- Vue项目之Element-UI(Breadcrumb)动态面包屑效果
- 基于springboot的汽车租赁管理系统的设计与实现
- chrome 实验室
- Win7 查看端口占用的进程,并根据进程id杀死进程。