处理分类数据 非数值型编码
处理分类数据
目前为止,我们处理的都是数值型变量。但是真实世界的数据集通常都含有分类型变量(categorical value)的特征。当我们讨论分类型数据时,我们不区分其取值是否有序。比如T恤尺寸是有序的,因为XL>L>M。而T恤颜色是无序的。
在讲解处理分类数据的技巧之前,我们先创建一个新的DataFrame对象:

上面创建的数据集含有无序特征(color),有序特征(size)和数值型特征(price)。最后一列存储的是类别。在本书中类别信息都是无序的。
映射有序特征
为了保证学习算法能够正确解释有序特征(ordinal feature),我们需要将分类型字符串转为整型数值。不幸地是,并没有能够直接调用的方法来自动得到正确顺序的size特征。因此,我们要自己定义映射函数。在接下来的简单的示例,假设我们知道特征取值间的不同,比如 XL=L+1=M+2。
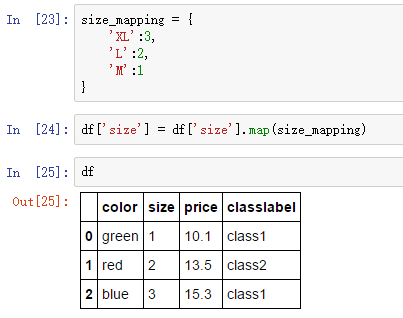
如果我们还想将整型变量转换回原来的字符串表示,我们还可以定义一个反映射字典 inv_size_mapping={v: k for k, v in size_mapping.items()}。
对类别进行编码
许多机器学习库要求类别是整型数值。虽然sklearn中大部分Estimator都能自动将类别转为整型,我还是建议大家手动将类别进行转换。对类别进行编码,和上一节中转化序列特征很相似。但不同的是类别是无序的,所以我们可以从0开始赋整数值:

接下来我们可以利用映射字典对类别进行转换:
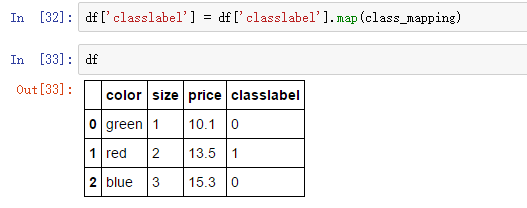
得到整型类别值,也可以用映射字典转为原始的字符串值:
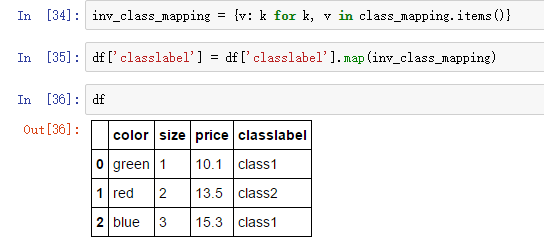
上面是我们自己手动创建的映射字典,sklearn中提供了LabelEncoder类来实现类别的转换:

fit_transform方法是fit和transform两个方法的合并。我们还可以调用inverse_transform方法得到原始的字符串类型值:

对离散特征进行独热编码
前面一节我们使用字典映射来转化有序特征,由于sklearn中Estimator把类型信息看做无序的,我们使用LabelEncoder来进行类别的转换。而对于无序的离散特征,我们也可以使用LabelEncoder来进行转换:

现在我们将无序离散特征转换为整型了,看起来下一步就是直接训练模型了。如果你这样想,恭喜你,你犯了一个很专业的错误。在处理分类型数据(categorical data)时,这是很常见的错误。你能发现问题所在吗?虽然“颜色”这一特征的值不含有顺序,但是由于进行了以下转换:

学习算法会认为‘green’比‘blue’大,‘red’比‘green’大。而这显然是不正确的,因为本身颜色是无序的!模型错误的使用了颜色特征信息,最后得到的结果肯定不是我们想要的。
那么如何处理无序离散特征呢?常用的做法是独热编码(one-hot encoding)。独热编码会为每个离散值创建一个哑特征(dummy feature)。什么是哑特征呢?举例来说,对于‘颜色’这一特征中的‘蓝色’,我们将其编码为[蓝色=1,绿色=0,红色=0],同理,对于‘绿色’,我们将其编码为[蓝色=0,绿色=1,红色=0],特点就是向量只有一个1,其余均为0,故称之为one-hot。
在sklearn中,可以调用OneHotEncoder来实现独热编码:

在初始化OneHotEncoder时,通过categorical_features参数设置要进行独热编码的列。还要注意的是OneHotEncoder的transform方法默认返回稀疏矩阵,所以我们调用toarray()方法将稀疏矩阵转为一般矩阵。我们还可以在初始化OneHotEncoder时通过参数sparse=False来设置返回一般矩阵。
除了使用sklearn中的OneHotEncoder类得到哑特征,我推荐大家使用pandas中的get_dummies方法来创建哑特征,get_dummies默认会对DataFrame中所有字符串类型的列进行独热编码:
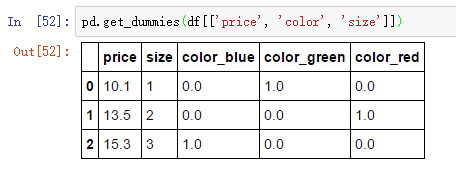
处理分类数据 非数值型编码相关推荐
- Python数据分析中数据预处理:编码将文字型数据转换为数值型
[小白从小学Python.C.Java] [Python-计算机等级考试二级] [Python-数据分析] Python数据分析中 数据预处理:编码 将文字型数据转换为数值型 选择题 对于以下pyth ...
- excel 回归 - 输入区域包含非数值型数据
回归 - 输入区域包含非数值型数据 每天一点点,记录工作中实操可行 excel中在用f1:h128范围的数据做做回归分析时,一直提示"回归 - 输入区域包含非数值型数据",不要把第 ...
- K-modes聚类-全中文特征-非数值型特征
最近对K-modes聚类进行了简单尝试,产生了一点小小感悟,在此和大家分享一下,若有不妥之处欢迎大家留言讨论. 场景:所有用于聚类的变量都是中文类别变量,非常懒非常硬核就是不想数值化之后再聚类,选择了 ...
- 【R】分类数据与数值型数据分组与绘图
分类数据与数值型数据分组 绘制条形图,分组条形图,堆砌条形图,饼图,直方图,茎叶图,箱线图,小提琴图,散点图,3d散点图,气泡图 #数据预处理 load("E:\\研究生学习\\大数据统计基 ...
- python非数值型数据_Python机器学习实战:如何处理非数值特征
机器学习实战:这里没有艰深晦涩的数学理论,我们将用简单的案例和大量的示例代码,向大家介绍机器学习的核心概念.我们的目标是教会大家用Python构建机器学习模型,解决现实世界的难题. 本文来自<数 ...
- MySQL分区:range(范围)list(in)columns(多字段)hash(散列)key(非数值型的hash)复合(hash key)
1.了解 分区是把一个表分成若干个部分,就是分区,分而化之,表明上还是一张表,内容存放在不同的文件了: 数据存放在不同的分区的依据就是分区键: 3.优势:存储量大 查询快 查询大 方便删除 存储量:和 ...
- EXCEL公式-文本型数据转换为数值型数据
从后台导出的销售数据中,金额.订单数等均为文本型数据,无法进行求和计算. 这个时候可以通过*1将文本型数据快速转换为数值型数据. 如下所示: 其中clean函数用于去除字符串中的非打印字符,如Tab制 ...
- 机器学习中如何处理非数值型的特征
前言 传统的机器算法一般处理的是结构化数据,而结构化数据中往往包含以下几种类别: 传统的机器学习算法 SVM,LR,lightgbm,xgboost等 结构化数据类别 Categorical,类别型变 ...
- 数据预处理:分类和顺序变量转化为数值型数据
分类数据和顺序数据要参与模型计算,通常都会转化为数值型数据.当然,某些算法是允许这些数据直接参与计算的,例如决策树.关联规则等. 真值转换 要将非数值型数据转换为数值型数据的最佳方法是:将所有分类或顺 ...
- 计算机中的数值和信息编码有哪些,[转载]信息编码 (数值型和字符型编码)...
信息编码 1.数值型编码 2.字符型编码 一.数值在计算机中的表现形式.计算机采用二进制数进行数据存储与计算,这是由计算机中所使用的逻辑器件所决定的.这种逻辑器件是具有两种状态的电路(触发器),好处是 ...
最新文章
- 【LeetCode】87. Scramble String
- windows 下更新 npm 和 node
- 分类分布(categorical分布)
- scala中循环守卫_Scala中的循环
- php新闻列表排序,javascript 新闻列表排序简单封装
- 计算机竞赛满分学霸,湖北学霸斩获信息学奥赛金牌 将直接保送清华大学 立志做一名计算机科学家...
- SAP License:ERP失败案例集
- JOPL的配置文件Bug
- [原创]手动配置Ubuntu Linux系列3-缺省网关和主机名
- 南阳oj-----D的小L(algorithm全排列用法)
- 非参数统计单样本非参数检验之符号检验
- React结合es6实例教程
- php 数组json失败,php json转数组出错
- 解决vue项目更新版本后浏览器的缓存问题
- steam桌面图标空白问题解决
- office 论文 页码_毕业论文页码格式word操作
- 雷军做程序员时写的博客,有点东西!
- figma:使用mac上的字体 | 转换ttc字体文件
- 如何判断mp4的moov的位置
- 练习题:让用户提供半径,然后计算出对应圆的周长和面积