一看就明白的爬虫入门讲解-基础理论篇(上篇)
作者:孔淼
关于爬虫内容的分享,我会分成两篇,六个部分来分享,分别是:
1) 我们的目的是什么
2) 内容从何而来
3) 了解网络请求
4) 一些常见的限制方式
5) 尝试解决问题的思路
6) 效率问题的取舍
本文先聊聊前三个部分。
一、我们的目的是什么
一般来讲对我们而言需要抓取的是某个网站或者某个应用的内容,提取有用的价值,内容一般分为两部分,非结构化的文本,或者结构化的文本。
1. 关于非结构化的数据
1.1 HTML文本(包含javascript代码)
HTML文本基本上是传统爬虫过程中最常见的,也就是大多数时候会遇到的情况,例如抓取一个网页,得到的是HTML,然后需要解析一些常见的元素,提取一些关键的信息。HTML其实理应属于结构化的文本组织,但是又因为一般我们需要的关键信息并非直接可以得到,需要进行对HTML的解析查找,甚至一些字符串操作才能得到,所以还是归类于非结构化的数据处理中。
常见解析方式如下:
- CSS选择器
现在的网页样式比较多,所以一般的网页都会有一些CSS的定位,例如class,id等等,或者我们根据常见的节点路径进行定位,例如腾讯首页的财经部分:

这里id就为finance,我们用css选择器,就是"#finance"就得到了财经这一块区域的html,同理,可以根据特定的css选择器可以获取其他的内容。
- XPATH
XPATH是一种页面元素的路径选择方法,利用chrome可以快速得到,如:
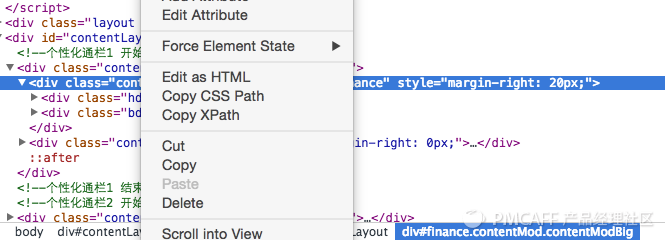
copy XPATH 就能得到——//*[@id="finance"]
- 正则表达式
正则表达式,用标准正则解析,一般会把HTML当做普通文本,用指定格式匹配当相关文本,适合小片段文本,或者某一串字符,或者HTML包含javascript的代码,无法用CSS选择器或者XPATH。
- 字符串分隔
同正则表达式,更为偷懒的方法,不建议使用。
1.2 一段文本
例如一篇文章,或者一句话,我们的初衷是提取有效信息,所以如果是滞后处理,可以直接存储,如果是需要实时提取有用信息,常见的处理方式如下:
- 分词
根据抓取的网站类型,使用不同词库,进行基本的分词,然后变成词频统计,类似于向量的表示,词为方向,词频为长度。
- NLP
自然语言处理,进行语义分析,用结果表示,例如正负面等。
2. 关于结构化的数据
结构化的数据是最好处理,一般都是类似JSON格式的字符串,直接解析JSON数据就可以了,提取JSON的关键字段即可
二、内容从何而来
过去我们常需要获取的内容主要来源于网页,一般来讲,我们决定进行抓取的时候,都是网页上可看到的内容,但是随着这几年移动互联网的发展,我们也发现越来越多的内容会来源于移动app,所以爬虫就不止局限于一定要抓取解析网页,还有就是模拟移动app的网络请求进行抓取,所以这一部分我会分两部分进行说明。
1 网页内容
网页内容一般就是指我们最终在网页上看到的内容,但是这个过程其实并不是网页的代码里面直接包含内容这么简单,所以对于很多新人而言,会遇到很多问题,比如:
明明在页面用Chrome或者Firefox进行审查元素时能看到某个HTML标签下包含内容,但是抓取的时候为空。
很多内容一定要在页面上点击某个按钮或者进行某个交互操作才能显示出来。
所以对于很多新人的做法是用某个语言别人模拟浏览器操作的库,其实就是调用本地浏览器或者是包含了一些执行javascript的引擎来进行模拟操作抓取数据,但是这种做法显然对于想要大量抓取数据的情况下是效率非常低下,并且对于技术人员本身而言也相当于在用一个盒子,那么对于这些内容到底是怎么显示在网页上的呢?主要分为以下几种情况:
- 网页包含内容
这种情况是最容易解决的,一般来讲基本上是静态网页已经写死的内容,或者动态网页,采用模板渲染,浏览器获取到HTML的时候已经是包含所有的关键信息,所以直接在网页上看到的内容都可以通过特定的HTML标签得到
- javascript代码加载内容
这种情况是由于虽然网页显示时,内容在HTML标签里面,但是其实是由于执行js代码加到标签里面的,所以这个时候内容在js代码里面的,而js的执行是在浏览器端的操作,所以用程序去请求网页地址的时候,得到的response是网页代码和js的代码,所以自己在浏览器端能看到内容,解析时由于js未执行,肯定找到指定HTML标签下内容肯定为空,这个时候的处理办法,一般来讲主要是要找到包含内容的js代码串,然后通过正则表达式获得相应的内容,而不是解析HTML标签。
- Ajax异步请求
这种情况是现在很常见的,尤其是在内容以分页形式显示在网页上,并且页面无刷新,或者是对网页进行某个交互操作后,得到内容。那我们该如何分析这些请求呢?这里我以Chrome的操作为例,进行说明:
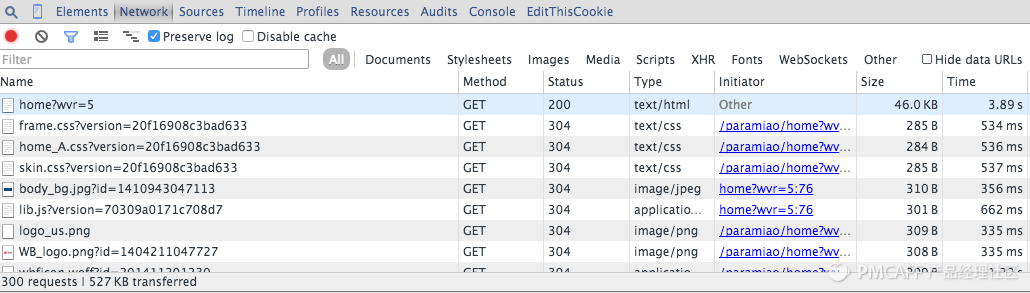
所以当我们开始刷新页面的时候就要开始跟踪所有的请求,观察数据到底是在哪一步加载进来的。然后当我们找到核心的异步请求的时候,就只用抓取这个异步请求就可以了,如果原始网页没有任何有用信息,也没必要去抓取原始网页了。
2 App内容
因为现在移动应用越来越多,很多有用信息都在App里面,另外解析非结构化文本和结构文本对比而言,结构化文本会简单多了,不同去找内容,去过多分析解析,所有既有网站又有App的话,推荐抓取App,大多数情况下基本上只是一些JSON数据的API了。那么App的数据该如何抓取呢?通用的方法就是抓包,基本的做法就是电脑安装抓包软件,配置好端口,然后记下ip,手机端和电脑在同一个局域网里面,然后在手机的网络连接里面设置好代理,这个时候打开App进行一些操作,如果有网络数据请求,则都会被抓包软件记下,就如上Chrome分析网络请求一样,你可以看到所有的请求情况,可以模拟请求操作。这里Mac上我推荐软件Charles,Windows推荐Fiddler2。
具体如何使用,之后我再做详述,可能会涉及到HTTPS证书的问题。
三、了解网络请求
刚刚一直在宽泛的提到一些我们需要找到请求,进行请求,对于请求只是一笔带过,但请求是很重要的一部分,包括如何绕过限制,如何发送正确地数据,都需要对的请求,这里就要详细的展开说下请求,以及如何模拟请求。
我们常说爬虫其实就是一堆的HTTP请求,找到待爬取的链接,不管是网页链接还是App抓包得到的API链接,然后发送一个请求包,得到一个返回包(也有HTTP长连接,或者Streaming的情况,这里不考虑),所以核心的几个要素就是:
1)URL
2)请求方法(POST, GET)
3)请求包headers
4)请求包内容
5)返回包headers
在用Chrome进行网络请求捕获或者用抓包工具分析请求时,最重要的是弄清楚URL,请求方法,然后headers里面的字段,大多数出问题就出在headers里面,最常限制的几个字段就是User-Agent, Referer,Cookie 另外Base Auth也是在headers里面加了Autheration的字段。
请求内容也就是post时需要发送的数据,一般都是将Key-Value进行urlencode返回包headers大多数会被人忽视,可能只得到内容就可以了,但是其实很多时候,很多人会发现明明url,请求方法还有请求包的内容都对了,为什么没有返回内容,或者发现请求被限制,其实这里大概有两个原因:
一个是返回包的内容是空的,但是在返回包的headers的字段里面有个Location,这个Location字段就是告诉浏览器重定向,所以有时候代码没有自动跟踪,自然就没有内容了;
另外一个就是很多人会头疼的Cookie问题,简单说就是浏览器为什么知道你的请求合法的,例如已登录等等,其实就是可能你之前某个请求的返回包的headers里面有个字段叫Set-Cookie,Cookie存在本地,一旦设置后,除非过期,一般都会自动加在请求字段上,所以Set-Cookie里面的内容就会告诉浏览器存多久,存的是什么内容,在哪个路径下有用,Cookie都是在指定域下,一般都不跨域,域就是你请求的链接host。
所以分析请求时,一定要注意前四个,在模拟时保持一致,同时观察第五个返回时是不是有限制或者有重定向。
本文由诸葛io CEO 孔淼原创发布于PMCAFF产品经理社区,转载请注明出处,欢迎关注诸葛io公众号(zhugeio),更多精彩,尽在其中。
一看就明白的爬虫入门讲解-基础理论篇(下篇)
http://www.taodudu.cc/news/show-546694.html
相关文章:
- 产品经理如何提升自己的配色能力
- 创业公司产品经理如何画好原型图
- 浅谈O2O行业的猎人与农夫【更新完毕】
- 概念模型让产品更简单
- 创业?你还差一位合格的产品经理
- 产品经理在工作中如何进行沟通
- 说说成为顶级运营人员的一个先决条件:做事的霸气!
- 从投票应用说起,功能才不是轻社交App的核心呢!
- 再谈扁平化
- 你是一个有价值的产品经理吗?
- 一个鉴黄师的产品之路(11-12更新)
- UGC产品的氛围和秩序
- 10万点击率的“干货”,其实人人都写得出来
- O2O上门实战复盘:10万元如何换来937个订单?
- 如何快速学习产品?实践才是王道!同为小白的人儿加油!
- 被1.5W用户吐成翔的10大互联网产品,你躺枪了吗?
- 产品经理该不该强势
- 产品经理真的是「背锅侠」吗?
- 一看就明白的爬虫入门讲解-基础理论篇(下篇)
- 德式秘籍:产品总监最该学会的管理方法是什么?(一)
- 如何运营垂直类产品
- 如何更好的解决问题 : The puzzle of die
- 来吧,我教你画真正的流程图
- 浅谈O2O产品信息结构化
- PMCAFF原创作者人气榜,快来看看你排第几?
- 你不知道的APP色彩跟产品场景的关联因素(干货多图)
- 用户金字塔模型详解及在实际运营工作中的意义
- 如何跟各种人解释什么是产品经理
- 利用「接口」做产品时我们该如何思考?
- 有逼格的产品经理都用什么样的杯子?
一看就明白的爬虫入门讲解-基础理论篇(上篇)相关推荐
- 一看就明白的爬虫入门讲解-基础理论篇(下篇)
文/孔淼 上篇我分享了爬虫入门中的"我们的目的是什么"."内容从何而来"."了解网络请求"这三部分的内容,这一篇我继续分享以下内容: 1) 一些常见的限制方式 2) 尝试解决问题的思路 3) 效率问题 ...
- 一看就明白的爬虫入门讲解:基础理论篇
一看就明白的爬虫入门讲解:基础理论篇 发表于2015-11-13 18:50| 5909次阅读| 来源CSDN| 37 条评论| 作者孔淼 爬虫经验分享HTMLCSSAjaxApp网络 width=& ...
- Python爬虫入门教程 71-100 续上篇,python爬虫爬取B站视频
写在前面 上篇博客我们用比较大的篇幅分析了B站视频传输方式,这篇博客填一下之前留下的坑,我们把代码部分写出来. 文章来源:梦想橡皮擦,其实这个ID是一个组合 分析的步骤与逻辑这里不再重复给大家演示了, ...
- python爬虫-Python爬虫入门这一篇就够了
何谓爬虫 所谓爬虫,就是按照一定的规则,自动的从网络中抓取信息的程序或者脚本.万维网就像一个巨大的蜘蛛网,我们的爬虫就是上面的一个蜘蛛,不断的去抓取我们需要的信息. 爬虫三要素 抓取 分析 存储 基础 ...
- 摄影入门-之三-基础理论篇
焦距 镜头的焦距分为像方焦距和物方焦距.像方焦距是像方主面到象方焦点的距离,同样,物方焦距就是物方主面到物方焦点的距离.必须注意,由于照相机镜头设计,特别是变焦距镜头中广泛采用了望远镜结构,物方焦距与 ...
- 学python买什么书-Python爬虫入门看什么书好 小编教你学Python
Python爬虫入门看什么书好 小编教你学Python 时间:2018-01-12 来源:Python爬虫入门讲解 生活在21世纪的互联网时代,各类技术的发展可谓是瞬息万变,这不今天编程界又出 ...
- python爬虫进阶案例,Python进阶(二十)-Python爬虫实例讲解
#Python进阶(二十)-Python爬虫实例讲解 本篇博文主要讲解Python爬虫实例,重点包括爬虫技术架构,组成爬虫的关键模块:URL管理器.HTML下载器和HTML解析器. ##爬虫简单架构 ...
- 爬虫入门到精通-HTTP协议的讲解
HTTP协议的讲解 本文章属于爬虫入门到精通系统教程第三讲 什么是HTTP协议? 引用自维基百科 超文本传输协议(英文:HyperText Transfer Protocol,缩写:HTTP)是互联网 ...
- python爬虫挖掘平台搭建_一篇非常棒的安装Python及爬虫入门博文!
原标题:一篇非常棒的安装Python及爬虫入门博文! 一. 大数据及数据挖掘基础(私信小编007即可获取大量Python学习资料!) 第一部分主要简单介绍三个问题: 1.什么是大数据? 2.什么是数据 ...
最新文章
- hdu2041java
- 在MSBuild.exe中使用条件编译(Conditional Compile)
- ubuntu12.04安装及配置过程详解1
- java复制一个对象_Java中对象的复制
- python 输入文件名查找_python 查找文件名包含指定字符串的方法
- 《Web安全之机器学习入门》一 第3章 机器学习概述
- (BFS)Meteor Shower (poj3669)
- 【MySQL】ERROR 1055 (42000) ROUP BY clause this is incompatible with sql_mode=only_full_group_by
- 加州大学欧文计算机工程硕士,UCI加州大学尔湾分校软件工程硕士Master of Software Engineering...
- Uva220 Othello
- 【图像融合】基于matlab对比度和结构提取多模态解剖图像融合【含Matlab源码 1539期】
- 帆软报表-快速入门(持续更新)
- 怎么网上兼职赚钱?盘点5个互联网赚钱的方法!
- 国外6大高效免费在线学习编程网站
- 微机——微型计算机系统组成及工作原理
- 按步搭建简单IoT微服务(2)
- 优秀产品经理必备的“十个证书”+项目管理工具
- 锐龙r7 6800u和酷睿i7 11800h差距 r76800u和i711800h对比
- linux 处理匹配文本的前后行
- 学习使用php实现无限极评论和无限极转二级评论解决方案