KD树(网易游戏笔试)
从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
前言
- 第一部分讲K近邻算法,其中重点阐述了相关的距离度量表示法,
- 第二部分着重讲K近邻算法的实现--KD树,和KD树的插入,删除,最近邻查找等操作,及KD树的一系列相关改进(包括BBF,M树等);
- 第三部分讲KD树的应用:SIFT+kd_BBF搜索算法。
同时,你将看到,K近邻算法同本系列的前两篇文章所讲的决策树分类贝叶斯分类,及支持向量机SVM一样,也是用于解决分类问题的算法,
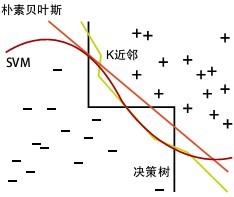
而本数据挖掘十大算法系列也会按照分类,聚类,关联分析,预测回归等问题依次展开阐述。
OK,行文仓促,本文若有任何漏洞,问题或者错误,欢迎朋友们随时不吝指正,各位的批评也是我继续写下去的动力之一。感谢。
第一部分、K近邻算法
1.1、什么是K近邻算法
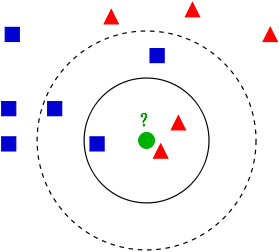
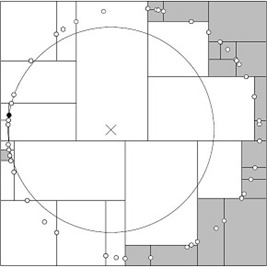
如上图所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。也就是说,现在,我们不知道中间那个绿色的数据是从属于哪一类(蓝色小正方形or红色小三角形),下面,我们就要解决这个问题:给这个绿色的圆分类。
我们常说,物以类聚,人以群分,判别一个人是一个什么样品质特征的人,常常可以从他/她身边的朋友入手,所谓观其友,而识其人。我们不是要判别上图中那个绿色的圆是属于哪一类数据么,好说,从它的邻居下手。但一次性看多少个邻居呢?从上图中,你还能看到:
- 如果K=3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
- 如果K=5,绿色圆点的最近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
于此我们看到,当无法判定当前待分类点是从属于已知分类中的哪一类时,我们可以依据统计学的理论看它所处的位置特征,衡量它周围邻居的权重,而把它归为(或分配)到权重更大的那一类。这就是K近邻算法的核心思想。
1.2、近邻的距离度量表示法
第二部分、K近邻算法的实现:KD树
2.0、背景
- 一种是范围查询,范围查询时给定查询点和查询距离阈值,从数据集中查找所有与查询点距离小于阈值的数据
- 另一种是K近邻查询,就是给定查询点及正整数K,从数据集中找到距离查询点最近的K个数据,当K=1时,它就是最近邻查询。
- 最容易的办法就是线性扫描,也就是我们常说的穷举搜索,依次计算样本集E中每个样本到输入实例点的距离,然后抽取出计算出来的最小距离的点即为最近邻点。此种办法简单直白,但当样本集或训练集很大时,它的缺点就立马暴露出来了,举个例子,在物体识别的问题中,可能有数千个甚至数万个SIFT特征点,而去一一计算这成千上万的特征点与输入实例点的距离,明显是不足取的。
- 另外一种,就是构建数据索引,因为实际数据一般都会呈现簇状的聚类形态,因此我们想到建立数据索引,然后再进行快速匹配。索引树是一种树结构索引方法,其基本思想是对搜索空间进行层次划分。根据划分的空间是否有混叠可以分为Clipping和Overlapping两种。前者划分空间没有重叠,其代表就是k-d树;后者划分空间相互有交叠,其代表为R树。

2.1、什么是KD树
2.2、KD树的构建

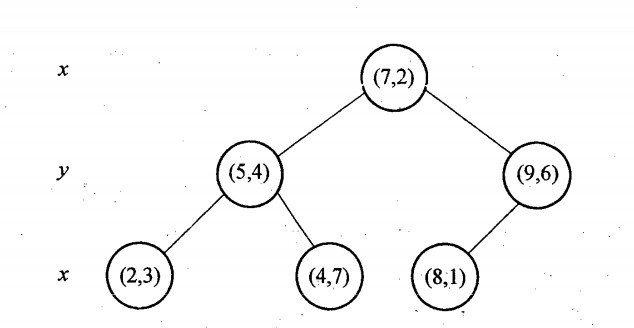
再举一个简单直观的实例来介绍k-d树构建算法。假设有6个二维数据点{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},数据点位于二维空间内,如下图所示。为了能有效的找到最近邻,k-d树采用分而治之的思想,即将整个空间划分为几个小部分,首先,粗黑线将空间一分为二,然后在两个子空间中,细黑直线又将整个空间划分为四部分,最后虚黑直线将这四部分进一步划分。
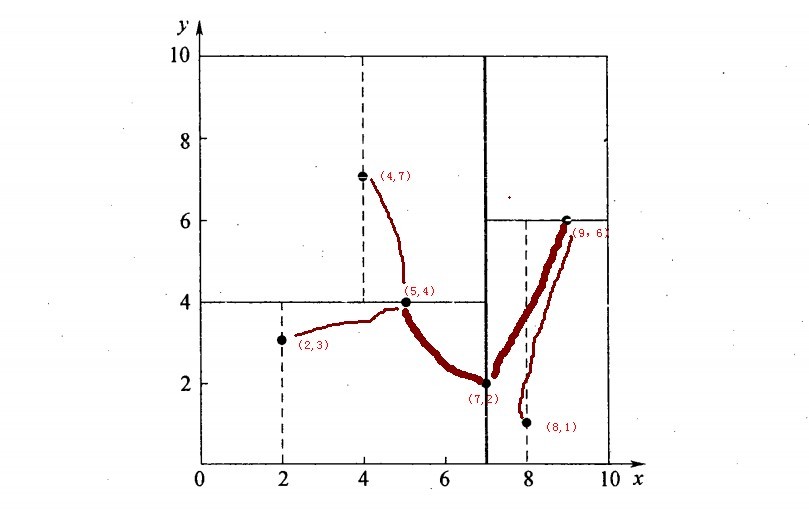
6个二维数据点{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)}构建kd树的具体步骤为:
- 确定:split域=x。具体是:6个数据点在x,y维度上的数据方差分别为39,28.63,所以在x轴上方差更大,故split域值为x;
- 确定:Node-data = (7,2)。具体是:根据x维上的值将数据排序,6个数据的中值(所谓中值,即中间大小的值)为7,所以Node-data域位数据点(7,2)。这样,该节点的分割超平面就是通过(7,2)并垂直于:split=x轴的直线x=7;
- 确定:左子空间和右子空间。具体是:分割超平面x=7将整个空间分为两部分:x<=7的部分为左子空间,包含3个节点={(2,3),(5,4),(4,7)};另一部分为右子空间,包含2个节点={(9,6),(8,1)};
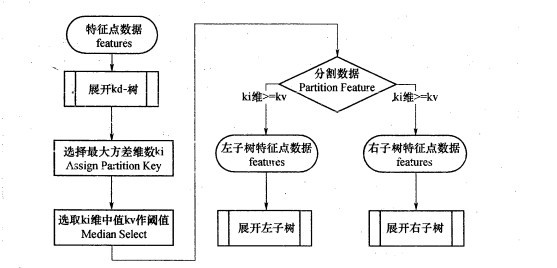
与此同时,经过对上面所示的空间划分之后,我们可以看出,点(7,2)可以为根结点,从根结点出发的两条红粗斜线指向的(5,4)和(9,6)则为根结点的左右子结点,而(2,3),(4,7)则为(5,4)的左右孩子(通过两条细红斜线相连),最后,(8,1)为(9,6)的左孩子(通过细红斜线相连)。如此,便形成了下面这样一棵k-d树:
k-d树的数据结构

针对上表给出的kd树的数据结构,转化成具体代码如下所示(注,本文以下代码分析基于Rob Hess维护的sift库):
- /** a node in a k-d tree */
- struct kd_node
- {
- int ki; /**< partition key index *///关键点直方图方差最大向量系列位置
- double kv; /**< partition key value *///直方图方差最大向量系列中最中间模值
- int leaf; /**< 1 if node is a leaf, 0 otherwise */
- struct feature* features; /**< features at this node */
- int n; /**< number of features */
- struct kd_node* kd_left; /**< left child */
- struct kd_node* kd_right; /**< right child */
- };


- /** a node in a k-d tree */
- struct kd_node
- {
- int ki; /**< partition key index *///关键点直方图方差最大向量系列位置
- double kv; /**< partition key value *///直方图方差最大向量系列中最中间模值
- int leaf; /**< 1 if node is a leaf, 0 otherwise */
- struct feature* features; /**< features at this node */
- int n; /**< number of features */
- struct kd_node* kd_left; /**< left child */
- struct kd_node* kd_right; /**< right child */
- };
也就是说,如之前所述,kd树中,kd代表k-dimension,每个节点即为一个k维的点。每个非叶节点可以想象为一个分割超平面,用垂直于坐标轴的超平面将空间分为两个部分,这样递归的从根节点不停的划分,直到没有实例为止。经典的构造k-d tree的规则如下:
- 随着树的深度增加,循环的选取坐标轴,作为分割超平面的法向量。对于3-d tree来说,根节点选取x轴,根节点的孩子选取y轴,根节点的孙子选取z轴,根节点的曾孙子选取x轴,这样循环下去。
- 每次均为所有对应实例的中位数的实例作为切分点,切分点作为父节点,左右两侧为划分的作为左右两子树。
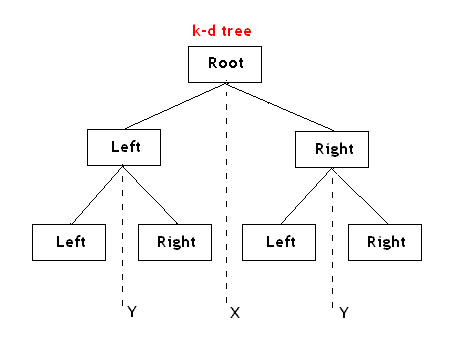
对于n个实例的k维数据来说,建立kd-tree的时间复杂度为O(k*n*logn)。
以下是构建k-d树的代码:
- struct kd_node* kdtree_build( struct feature* features, int n )
- {
- struct kd_node* kd_root;
- if( ! features || n <= 0 )
- {
- fprintf( stderr, "Warning: kdtree_build(): no features, %s, line %d\n",
- __FILE__, __LINE__ );
- return NULL;
- }
- //初始化
- kd_root = kd_node_init( features, n ); //n--number of features,initinalize root of tree.
- expand_kd_node_subtree( kd_root ); //kd tree expand
- return kd_root;
- }
- struct kd_node* kdtree_build( struct feature* features, int n )
- {
- struct kd_node* kd_root;
- if( ! features || n <= 0 )
- {
- fprintf( stderr, "Warning: kdtree_build(): no features, %s, line %d\n",
- __FILE__, __LINE__ );
- return NULL;
- }
- //初始化
- kd_root = kd_node_init( features, n ); //n--number of features,initinalize root of tree.
- expand_kd_node_subtree( kd_root ); //kd tree expand
- return kd_root;
- }
上面的涉及初始化操作的两个函数kd_node_init,及expand_kd_node_subtree代码分别如下所示:
- static struct kd_node* kd_node_init( struct feature* features, int n )
- { //n--number of features
- struct kd_node* kd_node;
- kd_node = (struct kd_node*)(malloc( sizeof( struct kd_node ) ));
- memset( kd_node, 0, sizeof( struct kd_node ) ); //0填充
- kd_node->ki = -1; //???????
- kd_node->features = features;
- kd_node->n = n;
- return kd_node;
- }
- static struct kd_node* kd_node_init( struct feature* features, int n )
- { //n--number of features
- struct kd_node* kd_node;
- kd_node = (struct kd_node*)(malloc( sizeof( struct kd_node ) ));
- memset( kd_node, 0, sizeof( struct kd_node ) ); //0填充
- kd_node->ki = -1; //???????
- kd_node->features = features;
- kd_node->n = n;
- return kd_node;
- }
- static void expand_kd_node_subtree( struct kd_node* kd_node )
- {
- /* base case: leaf node */
- if( kd_node->n == 1 || kd_node->n == 0 )
- { //叶节点 //伪叶节点
- kd_node->leaf = 1;
- return;
- }
- assign_part_key( kd_node ); //get ki,kv
- partition_features( kd_node ); //creat left and right children,特征点ki位置左树比右树模值小,kv作为分界模值
- //kd_node中关键点已经排序
- if( kd_node->kd_left )
- expand_kd_node_subtree( kd_node->kd_left );
- if( kd_node->kd_right )
- expand_kd_node_subtree( kd_node->kd_right );
- }
- static void expand_kd_node_subtree( struct kd_node* kd_node )
- {
- /* base case: leaf node */
- if( kd_node->n == 1 || kd_node->n == 0 )
- { //叶节点 //伪叶节点
- kd_node->leaf = 1;
- return;
- }
- assign_part_key( kd_node ); //get ki,kv
- partition_features( kd_node ); //creat left and right children,特征点ki位置左树比右树模值小,kv作为分界模值
- //kd_node中关键点已经排序
- if( kd_node->kd_left )
- expand_kd_node_subtree( kd_node->kd_left );
- if( kd_node->kd_right )
- expand_kd_node_subtree( kd_node->kd_right );
- }
构建完kd树之后,如今进行最近邻搜索呢?从下面的动态gif图中,你是否能看出些许端倪呢?

k-d树算法可以分为两大部分,除了上部分有关k-d树本身这种数据结构建立的算法,另一部分是在建立的k-d树上各种诸如插入,删除,查找(最邻近查找)等操作涉及的算法。下面,咱们依次来看kd树的插入、删除、查找操作。
2.3、KD树的插入
下面4副图(来源:中国地质大学电子课件)说明了插入顺序为(a) Chicago, (b) Mobile, (c) Toronto, and (d) Buffalo,建立空间K-D树的示例:
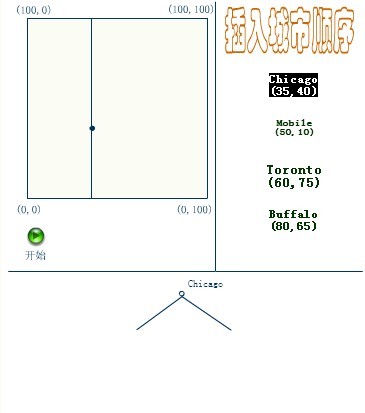
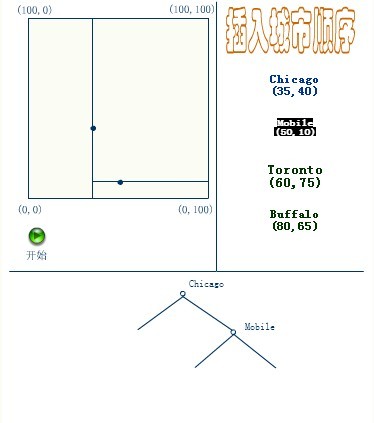
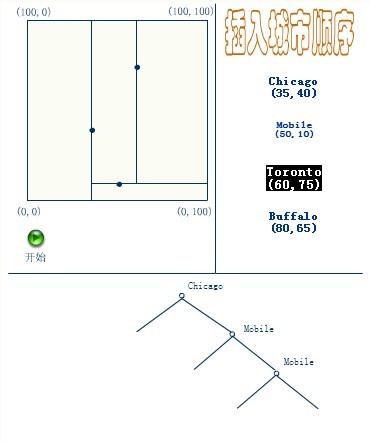
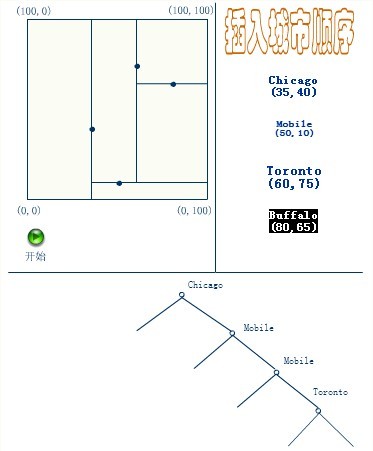
应该清楚,这里描述的插入过程中,每个结点将其所在的平面分割成两部分。因比,Chicago 将平面上所有结点分成两部分,一部分所有的结点x坐标值小于35,另一部分结点的x坐标值大于或等于35。同样Mobile将所有x坐标值大于35的结点以分成两部分,一部分结点的Y坐标值是小于10,另一部分结点的Y坐标值大于或等于10。后面的Toronto、Buffalo也按照一分为二的规则继续划分。
2.4、KD树的删除
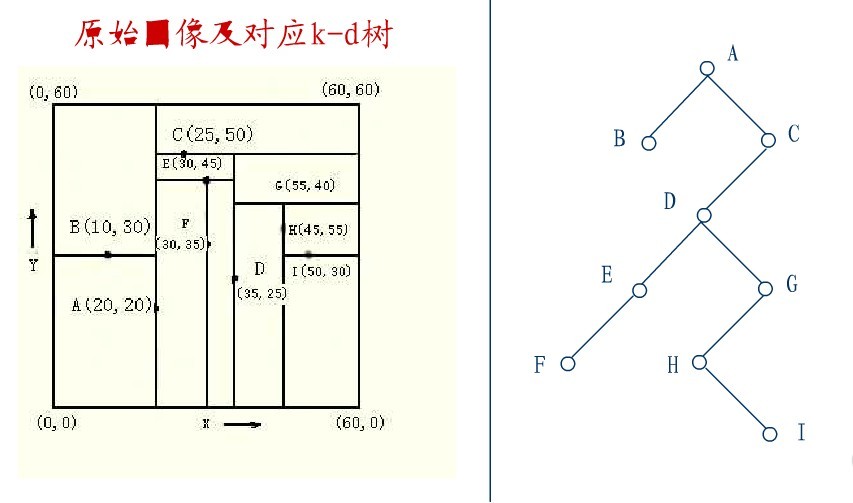
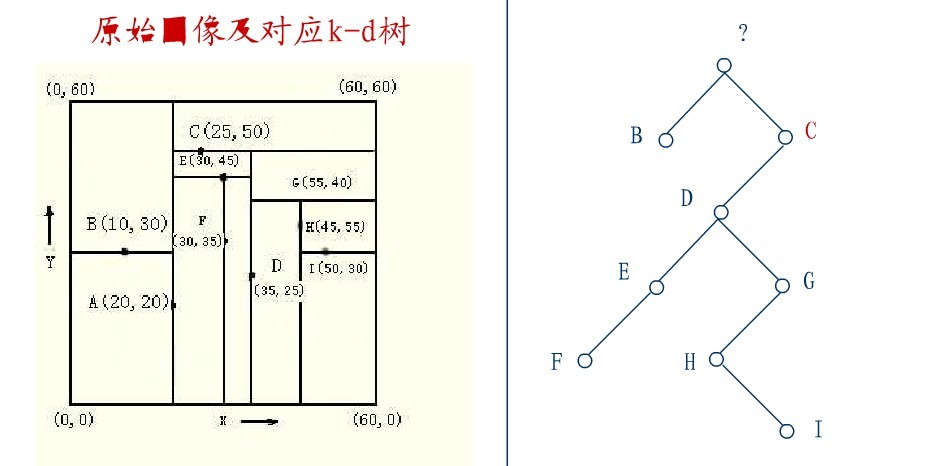
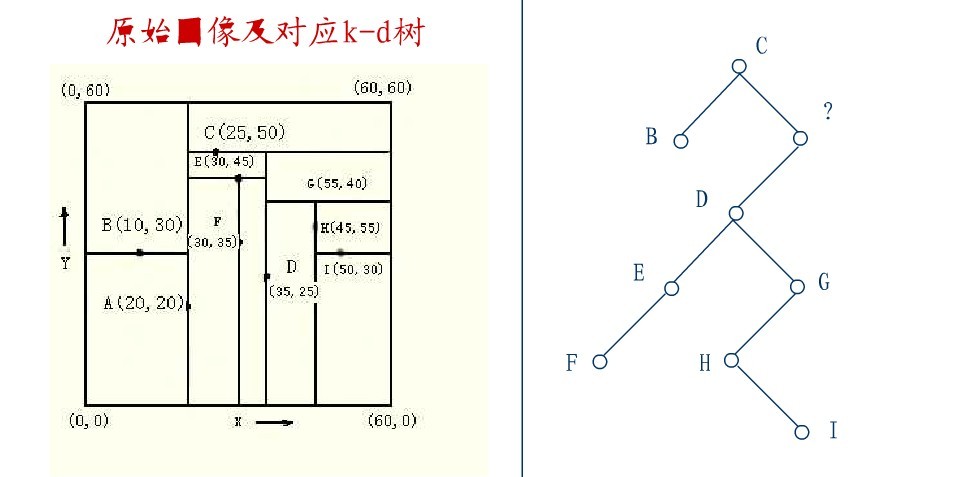
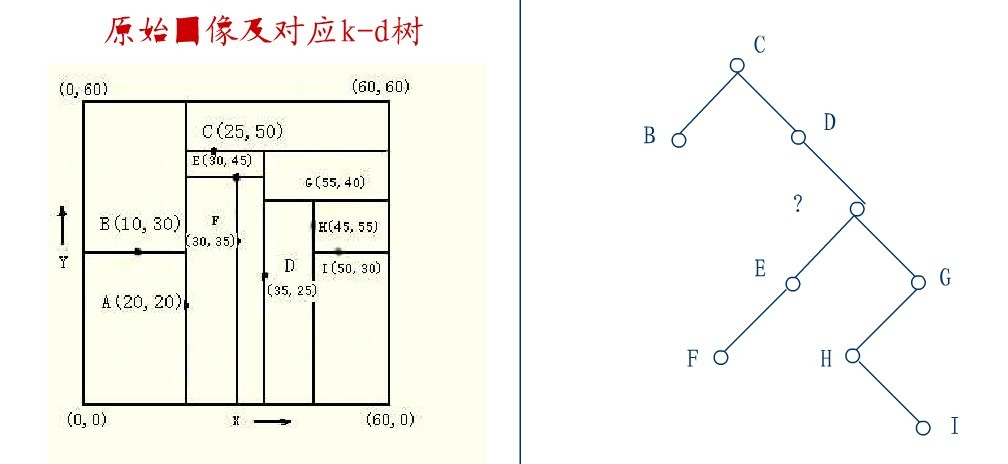
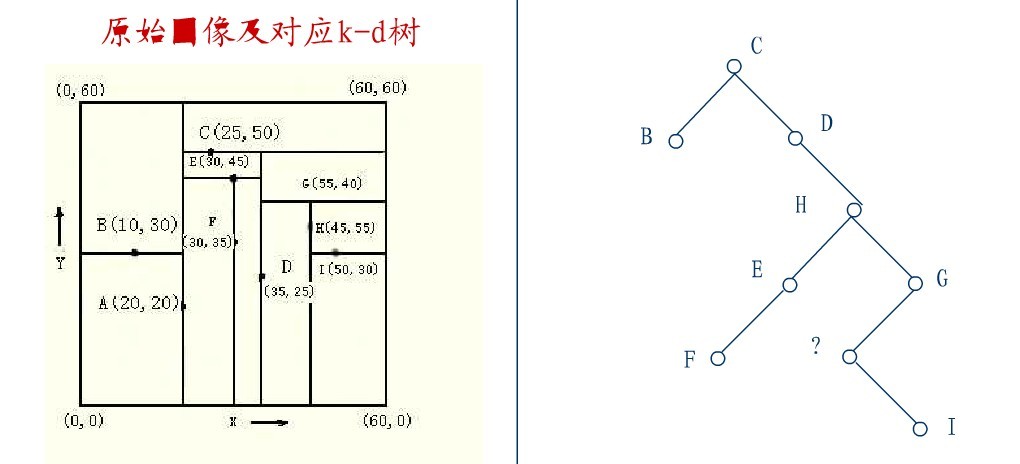
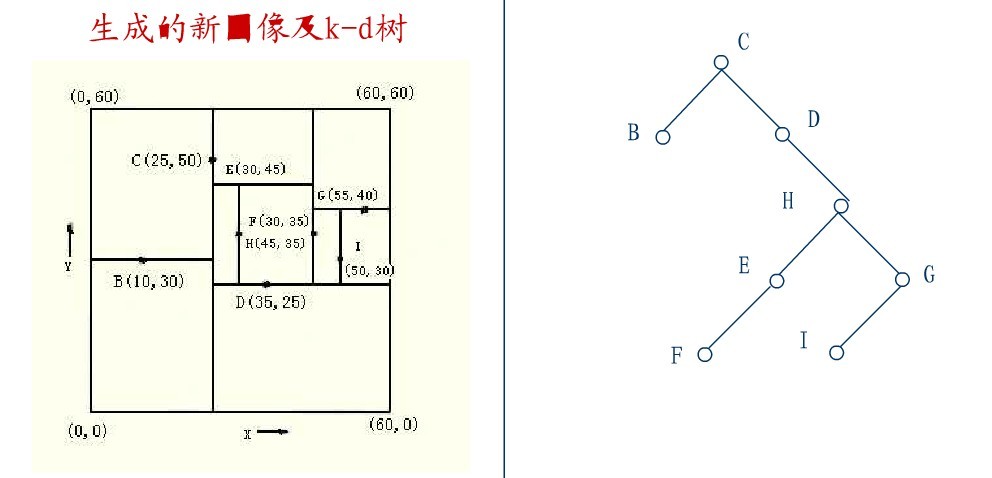
从K-D树中删除一个结点是代价很高的,很清楚删除子树的根受到子树中结点个数的限制。用TPL(T)表示树T总的路径长度。可看出树中子树大小的总和为TPL(T)+N。 以随机方式插入N个点形成树的TPL是O(N*log2N),这就意味着从一个随机形成的K-D树中删除一个随机选取的结点平均代价的上界是O(log2N) 。
2.5、KD树的最近邻搜索算法
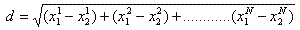
2.5.1、k-d树查询算法的伪代码
- 算法:k-d树最邻近查找
- 输入:Kd, //k-d tree类型
- target //查询数据点
- 输出:nearest, //最邻近数据点
- dist //最邻近数据点和查询点间的距离
- 1. If Kd为NULL,则设dist为infinite并返回
- 2. //进行二叉查找,生成搜索路径
- Kd_point = &Kd; //Kd-point中保存k-d tree根节点地址
- nearest = Kd_point -> Node-data; //初始化最近邻点
- while(Kd_point)
- push(Kd_point)到search_path中; //search_path是一个堆栈结构,存储着搜索路径节点指针
- If Dist(nearest,target) > Dist(Kd_point -> Node-data,target)
- nearest = Kd_point -> Node-data; //更新最近邻点
- Min_dist = Dist(Kd_point,target); //更新最近邻点与查询点间的距离 ***/
- s = Kd_point -> split; //确定待分割的方向
- If target[s] <= Kd_point -> Node-data[s] //进行二叉查找
- Kd_point = Kd_point -> left;
- else
- Kd_point = Kd_point ->right;
- End while
- 3. //回溯查找
- while(search_path != NULL)
- back_point = 从search_path取出一个节点指针; //从search_path堆栈弹栈
- s = back_point -> split; //确定分割方向
- If Dist(target[s],back_point -> Node-data[s]) < Max_dist //判断还需进入的子空间
- If target[s] <= back_point -> Node-data[s]
- Kd_point = back_point -> right; //如果target位于左子空间,就应进入右子空间
- else
- Kd_point = back_point -> left; //如果target位于右子空间,就应进入左子空间
- 将Kd_point压入search_path堆栈;
- If Dist(nearest,target) > Dist(Kd_Point -> Node-data,target)
- nearest = Kd_point -> Node-data; //更新最近邻点
- Min_dist = Dist(Kd_point -> Node-data,target); //更新最近邻点与查询点间的距离的
- End while
- 算法:k-d树最邻近查找
- 输入:Kd, //k-d tree类型
- target //查询数据点
- 输出:nearest, //最邻近数据点
- dist //最邻近数据点和查询点间的距离
- 1. If Kd为NULL,则设dist为infinite并返回
- 2. //进行二叉查找,生成搜索路径
- Kd_point = &Kd; //Kd-point中保存k-d tree根节点地址
- nearest = Kd_point -> Node-data; //初始化最近邻点
- while(Kd_point)
- push(Kd_point)到search_path中; //search_path是一个堆栈结构,存储着搜索路径节点指针
- If Dist(nearest,target) > Dist(Kd_point -> Node-data,target)
- nearest = Kd_point -> Node-data; //更新最近邻点
- Min_dist = Dist(Kd_point,target); //更新最近邻点与查询点间的距离 ***/
- s = Kd_point -> split; //确定待分割的方向
- If target[s] <= Kd_point -> Node-data[s] //进行二叉查找
- Kd_point = Kd_point -> left;
- else
- Kd_point = Kd_point ->right;
- End while
- 3. //回溯查找
- while(search_path != NULL)
- back_point = 从search_path取出一个节点指针; //从search_path堆栈弹栈
- s = back_point -> split; //确定分割方向
- If Dist(target[s],back_point -> Node-data[s]) < Max_dist //判断还需进入的子空间
- If target[s] <= back_point -> Node-data[s]
- Kd_point = back_point -> right; //如果target位于左子空间,就应进入右子空间
- else
- Kd_point = back_point -> left; //如果target位于右子空间,就应进入左子空间
- 将Kd_point压入search_path堆栈;
- If Dist(nearest,target) > Dist(Kd_Point -> Node-data,target)
- nearest = Kd_point -> Node-data; //更新最近邻点
- Min_dist = Dist(Kd_point -> Node-data,target); //更新最近邻点与查询点间的距离的
- End while
读者来信点评@yhxyhxyhx,在“将Kd_point压入search_path堆栈;”这行代码后,应该是调到步骤2再往下走二分搜索的逻辑一直到叶结点,我写了一个递归版本的二维kd tree的搜索函数你对比的看看:
- void innerGetClosest(NODE* pNode, PT point, PT& res, int& nMinDis)
- {
- if (NULL == pNode)
- return;
- int nCurDis = abs(point.x - pNode->pt.x) + abs(point.y - pNode->pt.y);
- if (nMinDis < 0 || nCurDis < nMinDis)
- {
- nMinDis = nCurDis;
- res = pNode->pt;
- }
- if (pNode->splitX && point.x <= pNode->pt.x || !pNode->splitX && point.y <= pNode->pt.y)
- innerGetClosest(pNode->pLft, point, res, nMinDis);
- else
- innerGetClosest(pNode->pRgt, point, res, nMinDis);
- int rang = pNode->splitX ? abs(point.x - pNode->pt.x) : abs(point.y - pNode->pt.y);
- if (rang > nMinDis)
- return;
- NODE* pGoInto = pNode->pLft;
- if (pNode->splitX && point.x > pNode->pt.x || !pNode->splitX && point.y > pNode->pt.y)
- pGoInto = pNode->pRgt;
- innerGetClosest(pGoInto, point, res, nMinDis);
- }
- void innerGetClosest(NODE* pNode, PT point, PT& res, int& nMinDis)
- {
- if (NULL == pNode)
- return;
- int nCurDis = abs(point.x - pNode->pt.x) + abs(point.y - pNode->pt.y);
- if (nMinDis < 0 || nCurDis < nMinDis)
- {
- nMinDis = nCurDis;
- res = pNode->pt;
- }
- if (pNode->splitX && point.x <= pNode->pt.x || !pNode->splitX && point.y <= pNode->pt.y)
- innerGetClosest(pNode->pLft, point, res, nMinDis);
- else
- innerGetClosest(pNode->pRgt, point, res, nMinDis);
- int rang = pNode->splitX ? abs(point.x - pNode->pt.x) : abs(point.y - pNode->pt.y);
- if (rang > nMinDis)
- return;
- NODE* pGoInto = pNode->pLft;
- if (pNode->splitX && point.x > pNode->pt.x || !pNode->splitX && point.y > pNode->pt.y)
- pGoInto = pNode->pRgt;
- innerGetClosest(pGoInto, point, res, nMinDis);
- }
下面,以两个简单的实例(例子来自图像局部不变特性特征与描述一书)来描述最邻近查找的基本思路。
2.5.2、举例:查询点(2.1,3.1)
- 二叉树搜索:先从(7,2)点开始进行二叉查找,然后到达(5,4),最后到达(2,3),此时搜索路径中的节点为<(7,2),(5,4),(2,3)>,首先以(2,3)作为当前最近邻点,计算其到查询点(2.1,3.1)的距离为0.1414,
- 回溯查找:在得到(2,3)为查询点的最近点之后,回溯到其父节点(5,4),并判断在该父节点的其他子节点空间中是否有距离查询点更近的数据点。以(2.1,3.1)为圆心,以0.1414为半径画圆,如下图所示。发现该圆并不和超平面y = 4交割,因此不用进入(5,4)节点右子空间中(图中灰色区域)去搜索;
- 最后,再回溯到(7,2),以(2.1,3.1)为圆心,以0.1414为半径的圆更不会与x = 7超平面交割,因此不用进入(7,2)右子空间进行查找。至此,搜索路径中的节点已经全部回溯完,结束整个搜索,返回最近邻点(2,3),最近距离为0.1414。
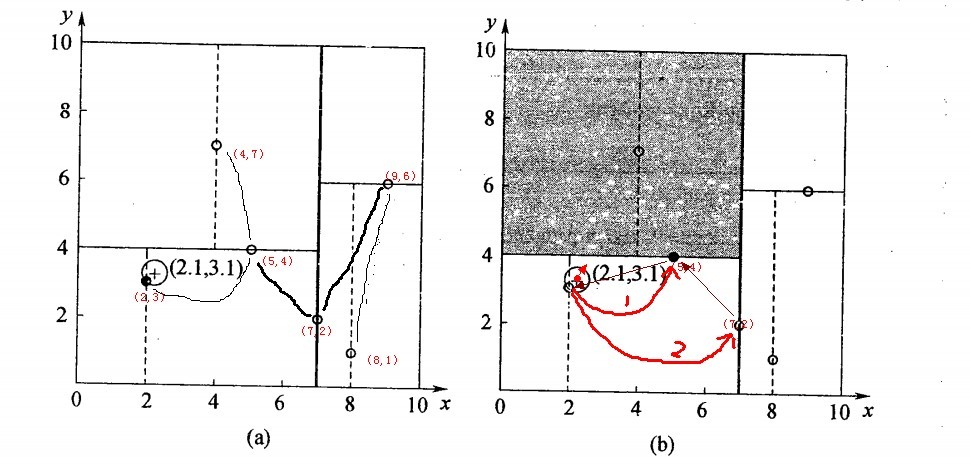
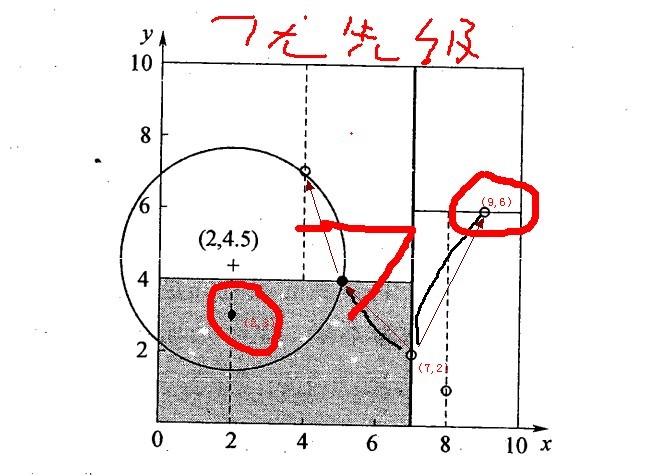
2.5.3、举例:查询点(2,4.5)
一个复杂点了例子如查找点为(2,4.5),具体步骤依次如下:
- 同样先进行二叉查找,先从(7,2)查找到(5,4)节点,在进行查找时是由y = 4为分割超平面的,由于查找点为y值为4.5,因此进入右子空间查找到(4,7),形成搜索路径<(7,2),(5,4),(4,7)>,但(4,7)与目标查找点的距离为3.202,而(5,4)与查找点之间的距离为3.041,所以(5,4)为查询点的最近点;
- 以(2,4.5)为圆心,以3.041为半径作圆,如下图所示。可见该圆和y = 4超平面交割,所以需要进入(5,4)左子空间进行查找,也就是将(2,3)节点加入搜索路径中得<(7,2),(2,3)>;于是接着搜索至(2,3)叶子节点,(2,3)距离(2,4.5)比(5,4)要近,所以最近邻点更新为(2,3),最近距离更新为1.5;
- 回溯查找至(5,4),直到最后回溯到根结点(7,2)的时候,以(2,4.5)为圆心1.5为半径作圆,并不和x = 7分割超平面交割,如下图所示。至此,搜索路径回溯完,返回最近邻点(2,3),最近距离1.5。
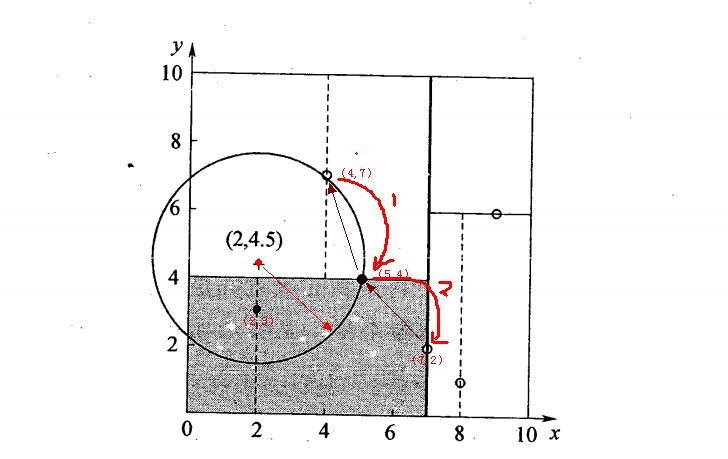
上述两次实例表明,当查询点的邻域与分割超平面两侧空间交割时,需要查找另一侧子空间,导致检索过程复杂,效率下降。
研究表明N个节点的K维k-d树搜索过程时间复杂度为:tworst=O(kN1-1/k)。
同时,以上为了介绍方便,讨论的是二维或三维情形。但在实际的应用中,如SIFT特征矢量128维,SURF特征矢量64维,维度都比较大,直接利用k-d树快速检索(维数不超过20)的性能急剧下降,几乎接近贪婪线性扫描。假设数据集的维数为D,一般来说要求数据的规模N满足N»2D,才能达到高效的搜索。所以这就引出了一系列对k-d树算法的改进:BBF算法,和一系列M树、VP树、MVP树等高维空间索引树(下文2.6节kd树近邻搜索算法的改进:BBF算法,与2.7节球树、M树、VP树、MVP树)。
2.6、kd树近邻搜索算法的改进:BBF算法
咱们顺着上一节的思路,参考统计学习方法一书上的内容,再来总结下kd树的最近邻搜索算法:
输入:以构造的kd树,目标点x;
输出:x 的最近邻
算法步骤如下:
- 在kd树种找出包含目标点x的叶结点:从根结点出发,递归地向下搜索kd树。若目标点x当前维的坐标小于切分点的坐标,则移动到左子结点,否则移动到右子结点,直到子结点为叶结点为止。
- 以此叶结点为“当前最近点”。
- 递归的向上回溯,在每个结点进行以下操作:
(a)如果该结点保存的实例点比当前最近点距离目标点更近,则更新“当前最近点”,也就是说以该实例点为“当前最近点”。
(b)当前最近点一定存在于该结点一个子结点对应的区域,检查子结点的父结点的另一子结点对应的区域是否有更近的点。具体做法是,检查另一子结点对应的区域是否以目标点位球心,以目标点与“当前最近点”间的距离为半径的圆或超球体相交:
如果相交,可能在另一个子结点对应的区域内存在距目标点更近的点,移动到另一个子结点,接着,继续递归地进行最近邻搜索;
如果不相交,向上回溯。 - 当回退到根结点时,搜索结束,最后的“当前最近点”即为x 的最近邻点。
如果实例点是随机分布的,那么kd树搜索的平均计算复杂度是O(NlogN),这里的N是训练实例树。所以说,kd树更适用于训练实例数远大于空间维数时的k近邻搜索,当空间维数接近训练实例数时,它的效率会迅速下降,一降降到“解放前”:线性扫描的速度。
也正因为上述k最近邻搜索算法的第4个步骤中的所述:“回退到根结点时,搜索结束”,每个最近邻点的查询比较完成过程最终都要回退到根结点而结束,而导致了许多不必要回溯访问和比较到的结点,这些多余的损耗在高维度数据查找的时候,搜索效率将变得相当之地下,那有什么办法可以改进这个原始的kd树最近邻搜索算法呢?
从上述标准的kd树查询过程可以看出其搜索过程中的“回溯”是由“查询路径”决定的,并没有考虑查询路径上一些数据点本身的一些性质。一个简单的改进思路就是将“查询路径”上的结点进行排序,如按各自分割超平面(也称bin)与查询点的距离排序,也就是说,回溯检查总是从优先级最高(Best Bin)的树结点开始。
针对此BBF机制,读者Feng&书童点评道:
- 在某一层,分割面是第ki维,分割值是kv,那么 abs(q[ki]-kv) 就是没有选择的那个分支的优先级,也就是计算的是那一维上的距离;
- 同时,从优先队列里面取节点只在某次搜索到叶节点后才发生,计算过距离的节点不会出现在队列的,比如1~10这10个节点,你第一次搜索到叶节点的路径是1-5-7,那么1,5,7是不会出现在优先队列的。换句话说,优先队列里面存的都是查询路径上节点对应的相反子节点,比如:搜索左子树,就把对应这一层的右节点存进队列。
如此,就引出了本节要讨论的kd树最近邻搜索算法的改进:BBF(Best-Bin-First)查询算法,它是由发明sift算法的David Lowe在1997的一篇文章中针对高维数据提出的一种近似算法,此算法能确保优先检索包含最近邻点可能性较高的空间,此外,BBF机制还设置了一个运行超时限定。采用了BBF查询机制后,kd树便可以有效的扩展到高维数据集上。
伪代码如下图所示(图取自图像局部不变特性特征与描述一书):

还是以上面的查询(2,4.5)为例,搜索的算法流程为:
- 将(7,2)压人优先队列中;
- 提取优先队列中的(7,2),由于(2,4.5)位于(7,2)分割超平面的左侧,所以检索其左子结点(5,4)。同时,根据BBF机制”搜索左/右子树,就把对应这一层的兄弟结点即右/左结点存进队列”,将其(5,4)对应的兄弟结点即右子结点(9,6)压人优先队列中,此时优先队列为{(9,6)},最佳点为(7,2);然后一直检索到叶子结点(4,7),此时优先队列为{(2,3),(9,6)},“最佳点”则为(5,4);
- 提取优先级最高的结点(2,3),重复步骤2,直到优先队列为空。
如你在下图所见到的那样(话说,用鼠标在图片上写字着实不好写):
KD树(网易游戏笔试)相关推荐
- 腾讯,百度,网易游戏,华为笔面经验
应届生上泡了两年,一直都是下资料,下笔试题,面试题.一直都在感谢那些默默付出的人. 写这个帖子花了我两个夜晚的时间,不是为了炫耀,只是为了能给那些"迷惘"的学弟学妹,一点点建议而已 ...
- 【转】【天道酬勤】 腾讯、百度、网易游戏、华为Offer及笔经面经
面试完毕,已跟网易游戏签约.遂敲一份笔经面经,记录下面试经过.类似于用日记记录自己,同时希望对师弟师妹有一定帮助.不是炫耀,只是希望攒RP,希望各位不要鄙视我. 正所谓"饮水思源" ...
- 【转】腾讯、百度、网易游戏、华为Offer及笔经面经
[转]腾讯.百度.网易游戏.华为Offer及笔经面经 [题注]:转载的目的是告诫自己,认清差距.时时警示自己,要加油! 转自:http://bbs.yingjiesheng.com/thread-10 ...
- 【转】腾讯 百度 网易游戏 华为Offer及笔经面经
分享一下我老师大神的人工智能教程!零基础,通俗易懂!http://blog.csdn.net/jiangjunshow 也欢迎大家转载本篇文章.分享知识,造福人民,实现我们中华民族伟大复兴! [转]腾 ...
- 【天道酬勤】 腾讯、百度、网易游戏、华为Offer及笔经面经
面试完毕,已跟网易游戏签约.遂敲一份笔经面经,记录下面试经过.类似于用日记记录自己,同时希望对师弟师妹有一定帮助.不是炫耀,只是希望攒RP,希望各位不要鄙视我. 正所谓"饮水思源" ...
- 腾讯、百度、网易游戏、华为Offer及笔经面经
面试完毕,已跟网易游戏签约.遂敲一份笔经面经,记录下面试经过.类似于用日记记录自己,同时希望对师弟师妹有一定帮助.不是炫耀,只是希望攒RP,希望各位不要鄙视我. 正所谓"饮水思源" ...
- 腾讯 美团 百度 网易游戏 2015校园招聘南京笔试面试之总结分析
补充(20141106): 三方已经寄出,综合评价下自己的不足和OFFER分析. 网易游戏终面 10月28号,网易游戏定好了往返的飞机票让我去广州参加终面,事前我对技术准备还是挺充分的,可对网易游戏本 ...
- 2021网易游戏雷火2021春招游戏功能测试工程师 笔试记录----春招补录
目录 2021网易游戏雷火2021春招游戏功能测试工程师 笔试记录----春招补录 单选题 逻辑题 问:最坏情况下,教授问到第几个学生,学生才知道自己头顶帽子的颜色? 2021网易游戏雷火2021春招 ...
- 秋招迟迟没消息?免笔试直通网易游戏的offer在这里!
网 易 Cli Cli 游戏开发 扶持计划 6周做出你的第一款游戏 不会编程也能轻松开发爆款游戏 关于我们 CliCli是由网易核心技术团队历经数年,自主研发的一款游戏编辑器. 如果你是 # 编程小白 ...
- 网易游戏游戏开发工程师笔试试题
网易游戏游戏开发工程师笔试试题 1.一次考试,有25人参加,有ABC三题,每人至少会做一题,在不会做A的人中,会做B的人是会做C的人的两倍,在会做A的人中,只会做A的人比其他的少一人,不会做A的人和只 ...
最新文章
- 市面上不成熟的系统Java_回顾java基础知识
- 枚举法 之Java实现凑硬币
- Android 拖动条(SeekBar)实例 附完整demo项目代码
- 苹果手机看python文件大小_Python练习题:你有一个目录,装了很多照片,把它们的尺寸变成都不大于iPhone5分辨率的大小...
- @angular/platform-browser-dynamic
- Openstack云计算项目实施 其一(安装环境)
- 他人收藏的精彩视频(一)
- 生活在REPL中(续):在REPL中动态加载依赖的库
- python处理出租车轨迹数据_1-出租车数据的基础处理,由gps生成OD(pandas).ipynb...
- Caffe安装 (OPENCV4 Cuda10.2 Xavier)
- C# wpf NotifyIcon空间模仿qqz最小化,关闭功能(12)
- 基于matlab算法的可靠度分析,参考基于matlab算法的可靠度分析
- 红米note3android版本,小米-红米note3-LOS-安卓9.0.0-稳定版Stable3.0-来去电归属-农历等-本地化增强适配...
- 制作rime配色的fcitx皮肤
- Ubuntu 10.04 HP LaserJet 无法打印 **** Unable to open the initial device, quitting 错误
- 自学基础1_linux_1_man命令详解
- STM32F103系列芯片的地址和寄存器映射原理、LED轮流闪烁实现
- uniapp使用canvas完成手写电子签名
- 使用Excel创建线性回归模型
- libconfig c语言实例