数据科学和人工智能技术笔记 八、特征选择
八、特征选择
作者:Chris Albon
译者:飞龙
协议:CC BY-NC-SA 4.0
用于特征选取的 ANOVA F 值
如果特征是类别的,计算每个特征与目标向量之间的卡方(χ2\chi^{2}χ2)统计量。 但是,如果特征是定量的,则计算每个特征与目标向量之间的 ANOVA F 值。
F 值得分检查当我们按照目标向量对数字特征进行分组时,每个组的均值是否显着不同。
# 加载库
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_classif# 加载鸢尾花数据
iris = load_iris()# 创建特征和标签
X = iris.data
y = iris.target# 创建 SelectKBest 对象来选择两个带有最佳 ANOVA F 值的特征
fvalue_selector = SelectKBest(f_classif, k=2)# 对 SelectKBest 对象应用特征和标签
X_kbest = fvalue_selector.fit_transform(X, y)# 展示结果
print('Original number of features:', X.shape[1])
print('Reduced number of features:', X_kbest.shape[1])'''
Original number of features: 4
Reduced number of features: 2
'''
用于特征选择的卡方
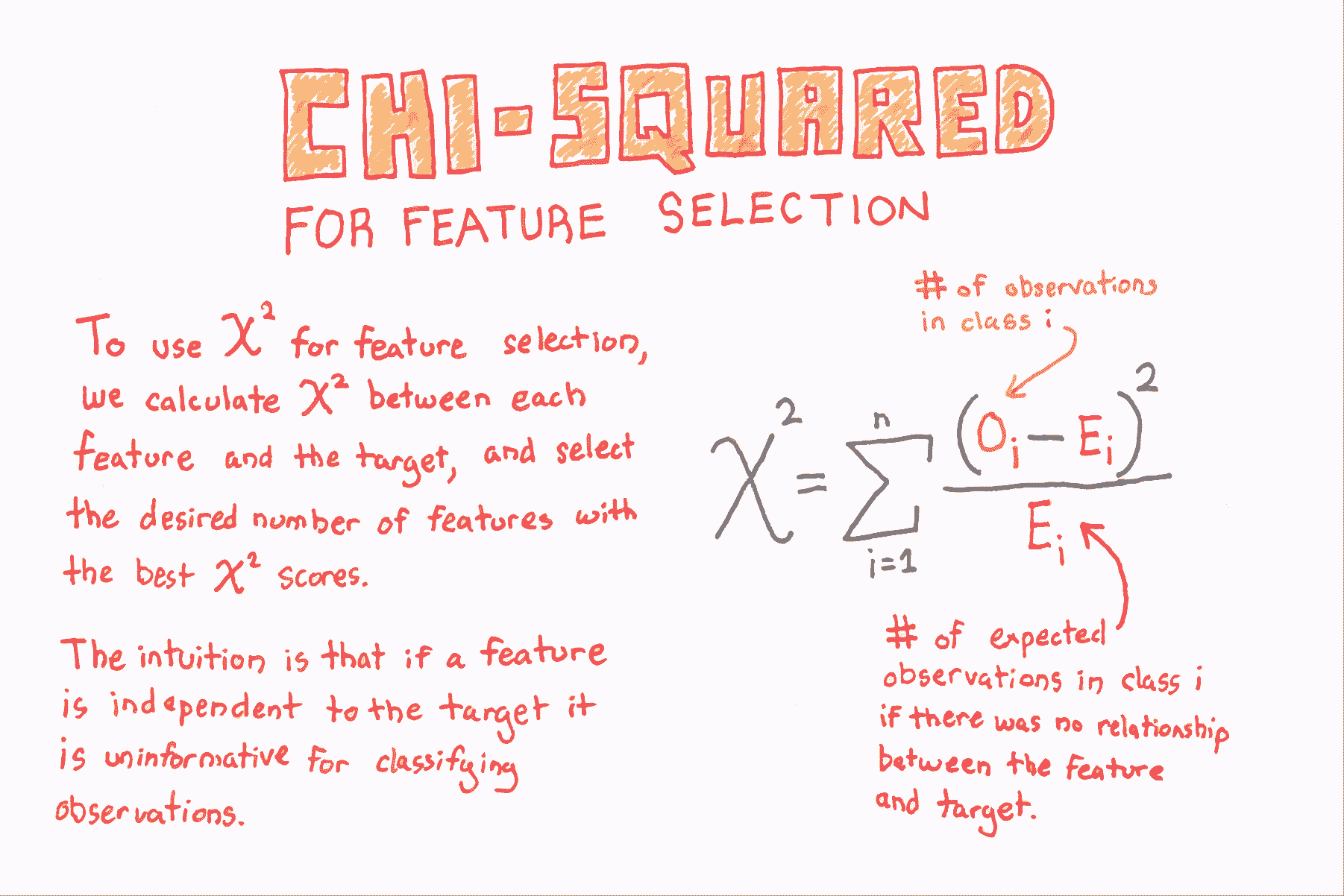
# 加载库
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2# 加载鸢尾花数据
iris = load_iris()# 创建特征和目标
X = iris.data
y = iris.target# 通过将数据转换为整数,转换为类别数据
X = X.astype(int)# 选择两个卡方统计量最高的特征
chi2_selector = SelectKBest(chi2, k=2)
X_kbest = chi2_selector.fit_transform(X, y)# 展示结果
print('Original number of features:', X.shape[1])
print('Reduced number of features:', X_kbest.shape[1])'''
Original number of features: 4
Reduced number of features: 2
'''
丢弃高度相关的特征
# 加载库
import pandas as pd
import numpy as np# 创建特征矩阵,具有两个高度相关特征
X = np.array([[1, 1, 1],[2, 2, 0],[3, 3, 1],[4, 4, 0],[5, 5, 1],[6, 6, 0],[7, 7, 1],[8, 7, 0],[9, 7, 1]])# 将特征矩阵转换为 DataFrame
df = pd.DataFrame(X)# 查看数据帧
df
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 1 | 1 | 1 |
| 1 | 2 | 2 | 0 |
| 2 | 3 | 3 | 1 |
| 3 | 4 | 4 | 0 |
| 4 | 5 | 5 | 1 |
| 5 | 6 | 6 | 0 |
| 6 | 7 | 7 | 1 |
| 7 | 8 | 7 | 0 |
| 8 | 9 | 7 | 1 |
# 创建相关度矩阵
corr_matrix = df.corr().abs()# 选择相关度矩阵的上三角
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(np.bool))# 寻找相关度大于 0.95 的特征列的索引
to_drop = [column for column in upper.columns if any(upper[column] > 0.95)]# 丢弃特征
df.drop(df.columns[to_drop], axis=1)
| 0 | 2 | |
|---|---|---|
| 0 | 1 | 1 |
| 1 | 2 | 0 |
| 2 | 3 | 1 |
| 3 | 4 | 0 |
| 4 | 5 | 1 |
| 5 | 6 | 0 |
| 6 | 7 | 1 |
| 7 | 8 | 0 |
| 8 | 9 | 1 |
递归特征消除
# 加载库
from sklearn.datasets import make_regression
from sklearn.feature_selection import RFECV
from sklearn import datasets, linear_model
import warnings# 消除烦人但无害的警告
warnings.filterwarnings(action="ignore", module="scipy", message="^internal gelsd")# 生成特征矩阵,目标向量和真实相关度
X, y = make_regression(n_samples = 10000,n_features = 100,n_informative = 2,random_state = 1)# 创建线性回归
ols = linear_model.LinearRegression()# 创建递归特征消除器,按照 MSE 对特征评分
rfecv = RFECV(estimator=ols, step=1, scoring='neg_mean_squared_error')# 拟合递归特征消除器
rfecv.fit(X, y)# 递归特征消除
rfecv.transform(X)'''
array([[ 0.00850799, 0.7031277 , -1.2416911 , -0.25651883, -0.10738769],[-1.07500204, 2.56148527, 0.5540926 , -0.72602474, -0.91773159],[ 1.37940721, -1.77039484, -0.59609275, 0.51485979, -1.17442094],..., [-0.80331656, -1.60648007, 0.37195763, 0.78006511, -0.20756972],[ 0.39508844, -1.34564911, -0.9639982 , 1.7983361 , -0.61308782],[-0.55383035, 0.82880112, 0.24597833, -1.71411248, 0.3816852 ]])
'''# 最佳特征数量
rfecv.n_features_# 5
方差阈值二元特征
from sklearn.feature_selection import VarianceThreshold# 创建特征矩阵:
# 特征 0:80% 的类 0
# 特征 1:80% 的类 1
# 特征 2:60% 的类 0,40% 的类 1
X = [[0, 1, 0],[0, 1, 1],[0, 1, 0],[0, 1, 1],[1, 0, 0]]
在二元特征(即伯努利随机变量)中,方差计算如下:
Var(x)=p(1−p)\operatorname {Var} (x)= p(1-p)Var(x)=p(1−p)
其中 ppp 是类 1 观测的比例。 因此,通过设置 ppp,我们可以删除绝大多数观察是类 1 的特征。
# Run threshold by variance
thresholder = VarianceThreshold(threshold=(.75 * (1 - .75)))
thresholder.fit_transform(X)'''
array([[0],[1],[0],[1],[0]])
'''
用于特征选择的方差阈值

from sklearn import datasets
from sklearn.feature_selection import VarianceThreshold# 加载鸢尾花数据
iris = datasets.load_iris()# 创建特征和目标
X = iris.data
y = iris.target# 使用方差阈值 0.5 创建 VarianceThreshold 对象
thresholder = VarianceThreshold(threshold=.5)# 应用方差阈值
X_high_variance = thresholder.fit_transform(X)# 查看方差大于阈值的前五行
X_high_variance[0:5]'''
array([[ 5.1, 1.4, 0.2],[ 4.9, 1.4, 0.2],[ 4.7, 1.3, 0.2],[ 4.6, 1.5, 0.2],[ 5\. , 1.4, 0.2]])
'''
数据科学和人工智能技术笔记 八、特征选择相关推荐
- 数据科学和人工智能技术笔记 十三、树和森林
十三.树和森林 作者:Chris Albon 译者:飞龙 协议:CC BY-NC-SA 4.0 Adaboost 分类器 # 加载库 from sklearn.ensemble import AdaB ...
- 数据科学和人工智能技术笔记 十二、逻辑回归
十二.逻辑回归 作者:Chris Albon 译者:飞龙 协议:CC BY-NC-SA 4.0 C 超参数快速调优 有时,学习算法的特征使我们能够比蛮力或随机模型搜索方法更快地搜索最佳超参数. sci ...
- 数据科学和人工智能技术笔记 七、特征工程
七.特征工程 作者:Chris Albon 译者:飞龙 协议:CC BY-NC-SA 4.0 稀疏特征矩阵上的降维 # 加载库 from sklearn.preprocessing import St ...
- 数据科学和人工智能技术笔记 十六、朴素贝叶斯
十六.朴素贝叶斯 作者:Chris Albon 译者:飞龙 协议:CC BY-NC-SA 4.0 伯努利朴素贝叶斯 伯努利朴素贝叶斯分类器假设我们的所有特征都是二元的,它们仅有两个值(例如,已经是独热 ...
- 数据科学和人工智能技术笔记 十、模型选择
十.模型选择 作者:Chris Albon 译者:飞龙 协议:CC BY-NC-SA 4.0 在模型选择期间寻找最佳预处理步骤 在进行模型选择时,我们必须小心正确处理预处理. 首先,GridSearc ...
- 数据科学和人工智能技术笔记 二十一、统计学
二十一.统计学 作者:Chris Albon 译者:飞龙 协议:CC BY-NC-SA 4.0 贝塞尔校正 贝塞尔的校正是我们在样本方差和样本标准差的计算中使用 n−1n-1n−1 而不是 nnn 的 ...
- 数据科学和人工智能技术笔记 十七、聚类
十七.聚类 作者:Chris Albon 译者:飞龙 协议:CC BY-NC-SA 4.0 凝聚聚类 # 加载库 from sklearn import datasets from sklearn.p ...
- 数据科学和人工智能技术笔记 十五、支持向量机
十五.支持向量机 作者:Chris Albon 译者:飞龙 协议:CC BY-NC-SA 4.0 校准 SVC 中的预测概率 SVC 使用超平面来创建决策区域,不会自然输出观察是某一类成员的概率估计. ...
- 数据科学和人工智能技术笔记 十一、线性回归
十一.线性回归 作者:Chris Albon 译者:飞龙 协议:CC BY-NC-SA 4.0 添加交互项 # 加载库 from sklearn.linear_model import LinearR ...
最新文章
- MYSQL_使用外键约束(constraint)或触发器(trigger)来进行级联更新、删除
- POJ3268 Silver Cow Party(最短路径)
- 详解Android实现全屏正确方法
- C++ 在派生类中使用using声明改变基类成员的可访问性
- scala 空列表_如何在Scala中展平列表列表?
- 《小学生C++趣味编程》第2课 春晓 动动脑 第1题-2018-12-12
- 【AI视野·今日Robot 机器人论文速览 第十九期】Mon, 5 Jul 2021
- 漫步线性代数三——高斯消元法
- vertical-align属性探究
- 管理nuget程序包中搜索不到任何程序包
- RabbitMQ 概念
- LVS-DR+Ldirectord+FreeNas实现负载均衡群集
- 常见面试问题整理(考研复试面试/计算机408+数据库基础概念)
- 怎么在我们的App中集成条码扫描功能?
- 互联网DSP广告系统架构及关键技术解析 | 广告行业资深架构师亲述
- python day8
- 青柚文案:水果店青柚推广文案,水果青柚广告文案
- mac输密码麻烦?一位数密码来了!
- C++ STL 中大根堆,小根堆的应用。
- hexo博客next主题添加对数学公式的支持