python推荐_利用Python构建一个简单的推荐系统
原标题:利用Python构建一个简单的推荐系统
摘要:快利用python构建一个属于你自己的推荐系统吧,手把手教学,够简单够酷炫。在此之前读者需要对pandas和numpy等数据分析包有所了解。
什么是推荐系统?
推荐系统的目的是通过发现数据集中的模式,为用户提供与之最为相关的信息。当你访问Netflix的时候,它也会为你推荐电影。音乐软件如Spotify及Deezer也使用推荐系统进行音乐推荐。
下图说明了推荐系统是如何在电子商务网站的上下文中工作的。
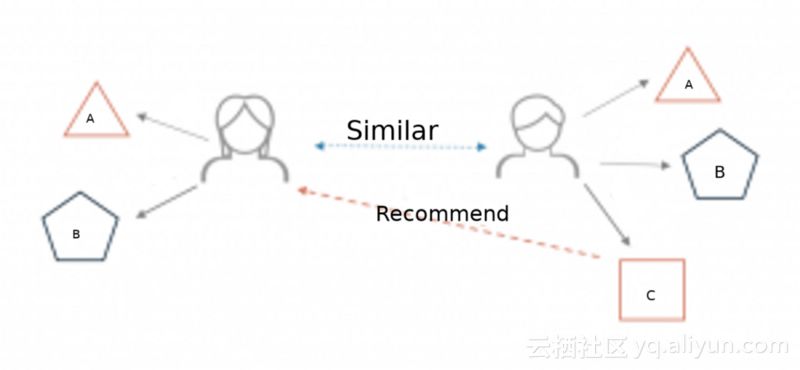
两名用户都在某电商网站购买了A、B两种产品。当他们产生购买这个动作的时候,两名用户之间的相似度便被计算了出来。其中一名用户除了购买了产品A和B,还购买了C产品,此时推荐系统会根据两名用户之间的相似度会为另一名用户推荐项目C。
推荐系统的主要分类
目前,主流的推荐系统包括。协同过滤简单来说就是根据用户对物品或者信息的偏好,发现物品或者内容本身的相关性,或者是发现用户的相关性,然后再基于这些关联性进行推荐。
举个简单的例子,如果要向个用户推荐一部电影,那么一定是基于他/她的朋友对这部电影的喜爱。基于协同过滤的推荐又可以分为两类:启发式推荐算法(Memory-based algorithms)及基于模型的推荐算法(Model-based algorithms)。启发式推荐算法易于实现,并且推荐结果的可解释性强。启发式推荐算法又可以分为两类:
基于用户的协同过滤(User-based collaborative filtering):主要考虑的是用户和用户之间的相似度,只要找出相似用户喜欢的物品,并预测目标用户对对应物品的评分,就可以找到评分最高的若干个物品推荐给用户。举个例子,Derrick和Dennis拥有相似的电影喜好,当新电影上映后,Derick对其表示喜欢,那么就能将这部电影推荐给Dennis。
基于项目的协同过滤(Item-based collaborative filtering):主要考虑的是物品和物品之间的相似度,只有找到了目标用户对某些物品的评分,那么就可以对相似度高的类似物品进行预测,将评分最高的若干个相似物品推荐给用户。举个例子,如果用户A、B、C给书籍X,Y的评分都是5分,当用户D想要买Y书籍的时候,系统会为他推荐X书籍,因为基于用户A、B、C的评分,系统会认为喜欢Y书籍的人在很大程度上会喜欢X书籍。
基于模型的推荐算法利用矩阵分解,有效的缓解了数据稀疏性的问题。矩阵分解是一种降低维度的方法,对特征进行提取,提高推荐准确度。基于模型的方法包括[决策树]()、基于规则的模型、贝叶斯方法和潜在因素模型。
基于内容的推荐系统会使用到元数据,例如流派、制作人、演员、音乐家等来推荐电影或音乐。如果有人看过并喜欢范·迪塞尔主演的《速度与激情》,那么系统很有可能将他主演的另一部电影《无限战争》推荐给这些用户。同样,你也可以从某些艺术家那里得到音乐推荐。基于内容的推荐的思想是:如果你喜欢某样东西,你很可能会喜欢与之相似的东西。
数据集
我们将使用到MovieLes数据集,该数据集是关于电影评分的,由明尼苏达大学的Grouplens研究小组整理,分为1M,10M,20M三个规格。Movielens还有一个网站,可以注册,撰写评论并获取电影推荐。若不想用此数据集,你也可以从Dataquest的数据资源中找到更多用于各种数据科学任务的数据集。
推荐系统构建
我们将使用movielens构建一个基于项目相似度的推荐系统,首先导入pandas和numpy。

接下来利用pandas中的read_csv()对数据进行加载。数据集中的数据以tab进行分隔,我们需要设置sep = t来指定字符的分隔符号,然后通过names参数传入列名。
接下来,检查正在处理的数据。
相比只知道电影的ID,能看到它们的标题更为方便。接下来,下载电影的标题并将它们整合到数据集中。

因为item_id列是相同的,我们便可以在此列上对数据进行合并。

每列释义如下:
User_id:用户ID
Item_id:电影ID
Rating:用户给电影的评分,介于1到5分之间
Timestamp:对电影进行评分的时间点
Title:电影标题
使用deion或info命令,可以得到数据集的简要描述,以帮助我们更好的理解数据集。
通过上一步,可以知道电影的平均分为3.52,最高为5分。
接下来构建一个包含每部电影的平均评分和被评分次数的dataframe,用来计算电影间的相关性。相关性是一种统计度量,用来表示两个或多个变量在一起波动的程度,电影之间的相关系数越高,越相似。
在本例中,我们将使用皮尔逊相关系数,它的变化范围为-1到1。当相关系数为1时,为完全正相关;当相关系数为-1时,为完全负相关;相关系数越接近于0,相关度越弱。利用pandas 中的groupby功能创建dataframe,按标题列对数据集进行分组,并计算每部电影的平均分。

接下来计算每部电影被评分的次数,观察它与电影平均评分之间的关系。一部5分的电影很可能只有一个用户评分。从统计学上来说,把它视为5分电影是不合理的。
因此,在构建推荐系统时,我们需要为评分次数设置一个阈值。使用pandas中的 groupby功能创建number_of_ratings列,按title列进行分组,然后使用count函数计算每部电影的被评分次数。之后,使用head()函数查看新的dataframe。

利用pandas中的绘图功能绘制直方图,可视化评分分布。

从中可以看出,多数电影的分值在2.5到4分之间。接下来将以同样的方式对number_of_ratings进行可视化。
从直方图中可以清楚地看出大多数电影都只有较少的评分,那些评分次数多的电影都拥有较高的知名度。
接下来探索电影评分和被评分次数之间的关系。使用seaborn绘制散点图,通过jointplot()函数实现。

从图中可以看出电影的平均评分和被评分次数之间呈正相关关系。图表显示,一部电影的评分越高,平均分也就越高。在为每部电影的评分设置阈值时,这一点尤其重要。
接下来构建基于项目的推荐系统。我们需要将数据集转换为一个矩阵,以电影标题为列,以user_id为索引,以评分为值。之后会得到一个dataframe,其中列是movie标题,行是user_id。每列代表所有用户对所有电影的评分。若评分为NaN(Not a Number),则表示用户没有对某一部电影进行评分。矩阵被用来计算电影之间的相关性。使用pandas中的 pivot_table创建电影矩阵。

接下来,使用pandas中的 sort_values工具,设置升序为false,以便从评分最高的电影中进行选择,然后使用head()函数查看分数前10的电影。
假设某用户看过《空军一号》和《超时空接触》,我们想根据观看历史向该用户推荐电影。通过计算这两个电影和数据集中其他电影的之间的相关性,寻找与之最为相似的电影,为用户进行推荐。首先,用movie_matrix中的电影评分创建一个dataframe。

Dataframe中包含user_id和对应用户给这两个电影的评分。利用如下代码进行查看。

使用pandas中的corwith功能计算两个dataframe对象的行或列的两两相关关系,从而得出每部电影与《空军一号》电影之间的相关性。
可以看到,《空军一号》与《直到有你》之间的相关性是0.867,表明这两部电影有很强的相似性。
接下来,计算《超时空接触》和其他电影之间的相关性。程序与上面相同。
通过计算,我们发现《超时空接触》和《直到有你》之间的相关性更强,为0.904。
由于只有部分用户对部分电影进行了评分,导致矩阵中有许多缺失的值。为了使结果看起来更有吸引力,我们将删除null值并将correlation results转化为dataframe。
通过上述步骤,计算出了与《超时空接触》和《空军一号》最为相似的电影。然而,有些电影被评价的次数很低,最终可能仅仅因为一两个人给了5分而被推荐。设置阈值可解决这个问题。从之前的直方图中我们看到评分次数从100急剧下降,于是我们将阈值设为100,不过你可以根据自己的需求进行调整。接下来,利用number_of_ratings列将两个dataframe连接起来。

获取并查看前10部最为相关的电影。

由于阈值不同,结果也会有所不同。在设置阈值后,与《空军一号》最相似的电影是《猎杀红色十月》,相关系数为0.554。
接下来获取并查看与《超时空接触》最为相关的前10部电影。

《超时空接触》最相似的电影是《费城》,相关系数为0.446,被评分次数为137。根据此结果,我们可以向喜欢《超时空接触》的用户推荐列表中的电影。
改进
本文所构建的推荐系统可以通过基于记忆的协同过滤方法进行改进。我们可以将数据集划分为训练集和测试集,使用诸如余弦相似度之类的方法来计算电影之间的相似度。还可以通过建立基于模型的协同过滤系统,更好地处理可伸缩性和稀疏性问题。同时也可以利用如均方根误差(RMSE)之类的方法对模型进行评估。除此之外,当所处理的数据量十分庞大时,还可以结合深度学习构建推荐系统。自动编码器和受限的Boltzmann机器也常用于构建高级推荐系统。
以上为译文
文章原标题《How to build a Simple Recommender System in Python》,作者:Derrick Mwiti,译者:Elaine,审校:袁虎。
责任编辑:
python推荐_利用Python构建一个简单的推荐系统相关推荐
- 基于python的系统构建_利用python构建一个简单的推荐系统
摘要: 快利用python构建一个属于你自己的推荐系统吧,手把手教学,够简单够酷炫. 本文将利用python构建一个简单的推荐系统,在此之前读者需要对pandas和numpy等数据分析包有所了解. 什 ...
- python推荐系统-利用python构建一个简单的推荐系统
摘要: 快利用python构建一个属于你自己的推荐系统吧,手把手教学,够简单够酷炫. 本文将利用python构建一个简单的推荐系统,在此之前读者需要对pandas和numpy等数据分析包有所了解. 什 ...
- java完成一个学生信息调查程序_利用Java设计一个简单的学生信息管理程序
利用Java设计一个简单的控制台学生信息管理程序 此程序可作为课设的参考,其中信息存储于文件中. 创建了学生类Student,用于存储学号等的信息.创建StudentFunction类,用于实现诸如学 ...
- java调python 监控_利用Python实现一个简单的系统监控图表
作为运维人员,想必大家肯定都做过这样的事情:为了监控系统资源使用情况,开了若干个窗口,来回切换看输出: 只要我切得够快,性能异常点就逃不过我的眼睛! 这个时候你要是有个监控工具自然是很好的,例如我们美 ...
- 利用python发送邮件_利用python实现简单的邮件发送客户端示例
脚本过于简单,供学习和参考.主要了解一下smtplib库的使用和超时机制的实现.使用signal.alarm实现超时机制. #!/usr/bin/env python # -*- coding: ut ...
- python框架实例,从零构建一个简单的 Python 框架
为什么你想要自己构建一个 web 框架呢?我想,原因有以下几点: 你有一个新奇的想法,觉得将会取代其他的框架 你想要获得一些名气 你遇到的问题很独特,以至于现有的框架不太合适 你对 web 框架是如何 ...
- 记事本如何运行python代码_利用Python开发实现简单的记事本
前言 本文的操作环境:ubuntu,Python2.7,采用的是Pycharm进行代码编辑,个人很喜欢它的代码自动补齐功能. 示例图 如上图,我们可以看到这个记事本主要分为三个模块:文件,编辑和关于, ...
- excel python插件_利用 Python 插件 xlwings 读写 Excel
Python 通过 xlwings 读取 Excel 数据 去年底公司让我做设备管理,多次委婉拒绝,最终还是做了.其实我比较喜欢技术.做管理后发现现场没有停机率统计,而原始数据有,每次要自己在Exce ...
- 动态照片墙 python 实现_利用python生成照片墙的示例代码
这篇文章主要介绍了利用python生成照片墙的示例代码,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧 PIL(Python Im ...
最新文章
- 排列组合算法的实现代码
- 机器人煮面机创始人_秋天的第一杯枸杞拿铁,由机器人冲泡
- C语言数组的深入理解
- WPF 实现大转盘抽奖~
- java spring注入 静态方法_JAVA静态方法中如何使用spring@Value进行注入的成员变量...
- 字节跳动新加坡职位 Algorithm Engineer (Platform Governance)
- Struts2中UI标签之非表单标签
- windows2003与文件共享有关的几个进程
- 源码编译安装screen
- 王道计算机考研机试指南部分代码
- 一个完整的html代码是什么,html是什么?一个完整的html代码告诉你(完整实例版)...
- 怎么把PDF转换成JPG图片?这个方法你了解吗
- 把mysql一个表的部分或全部数据复制追加到另一个表的方法
- 西门子smart plc远程监控应用实例
- 前有标兵,后有追兵,自热老兵莫小仙胜算还剩几成?
- 报错 Illegal instruction
- Eslint代码规范
- IPsec VPN 实验
- DLL注入的8种姿势
- 动作游戏(ACT)——棱角战士(基于Unity3D 5.4.2)