重新开始学Java——集合框架之Collection
为什么需要集合框架呢?因为之前使用数组进行存储对象的时候,会发现,经常不能够确定大小的存在,那么这里就需要使用集合框架的存在。集合框架分为两种,第一个是 java.util.Collection ;而另外一个是java.util.Map。这是两种不同的东西,所以,本博客先来描述 Collection 的使用,以及其实现方式。
java.util.Colllection
声明
public interface Collection<E> extends Iterable<E>
可以看到这里是一个接口,继承了Iterable接口。先不管<>内部的东西是什么,也先不管Iterable这个接口是干什么的。
描述
官方描述如下:
The root interface in the collection hierarchy. A collection represents a group of objects, known as its elements. Some collections allow duplicate elements and others do not. Some are ordered and others unordered. The JDK does not provide any direct implementations of this interface: it provides implementations of more specific subinterfaces like Set and List. This interface is typically used to pass collections around and manipulate them where maximum generality is desired.
翻译如下: 集合层次结构中的根接口。集合表示一组对象,称为其元素。某些集合允许重复元素,而其他集合不允许。有些是有序的,有些是无序的。JDK 不提供此接口的任何直接实现:它提供更具体的子接口(如 Set 和 List)的实现。此接口通常用于传递集合,并在需要最大通用性时操作它们。
那么就可以知道:java.util.Collection是集合层次的根接口,其中的对象称为元素,元素可能有序,也可能无序,不建议直接实现java.util.Collection接口,有更加具体的子接口(Set、List)。最常的使用的方式是用来传递集合(比如将Set转成List、将List转成Set等操作)。
Collection的使用
注意:Collection是一个接口,那么在使用的过程中,要么使用匿名内部类的方式实现,要么使用其子类进行实例化操作。
可以看到具体的实现子类是比较多的,那么在这里就使用HashSet作为实现子类,从而了解一下Collection的使用以及其内部方法。
public class TestCollection1 { // 用 HashSet 测试 Collection 中的方法public static void main(String[] args) {Collection<String> coll = new HashSet<>();// 无序的coll.add("孙悟空");coll.add("白龙马");coll.add("猪悟能");coll.add("沙悟净");System.out.println(coll);// coll.toString();System.out.println(coll.size());System.out.println(coll.contains("猴子"));System.out.println(coll.contains("孙悟空"));String[] array = new String[5];String[] returnArray = coll.toArray(array);System.out.println(array == returnArray);for (int i = 0; i < returnArray.length; i++) {System.out.println(array[i]);}Collection<String> xiyouTeam = new HashSet<>();xiyouTeam.add("陈玄奘"); //xiyouTeam.addAll(coll); // 将 coll 中的内容全部添加到xiyouTeam 集合中System.out.println(xiyouTeam);System.out.println(coll);// 判断 coll 中包含的元素是否在 xiyouTeam 中全部都存在// 判断 xiyouTeam 集合中是否包含 coll 中的每一个元素System.out.println(xiyouTeam.containsAll(coll));// 从 xiyouTeam 集合中删除 coll 所包含的所有元素xiyouTeam.removeAll(coll);System.out.println(xiyouTeam);// 将 coll 中的内容全部添加到 xiyouTeam 集合中xiyouTeam.addAll(coll);System.out.println(xiyouTeam);// 保留 xiyouTeam 集合中的 coll 包含的那些元素,删除其 元素,只要是 coll 中存放的元素留下来。xiyouTeam.retainAll(coll);System.out.println(xiyouTeam);}
}
那么在这里,可以发现大部分的方法都进行了举例应用,具体的方法描述可以进行查看官方API。
泛型
泛型是Java SE 1.5的新特性,泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。这种参数类型可以用在类、接口和方法的创建中,分别称为泛型类、泛型接口、泛型方法。 Java语言引入泛型的好处是安全简单。————百度百科
首先可以创建一个MySet,在实现添加方法,但是这个方法只能添加 Object 类型的对象。
public class MySet {public void add( Object o) {System.out.println("添加 : "+ o );}
}
然后写一个测试类,如下所示:
public class TestMySet{public static void main(String[] args) {MySet ms = new MySet();ms.add(250);ms.add("hello");}
}
通过上述的例子可以发现这样的缺点:类型比较杂乱,所以我们需要添加一个限制。
然后创建一个MyList 的类:
/**
*为该类指定类型参数
* @param <E> 形参参数 E 用来确定类型,叫类型参数
* 可以在声明 类 或接口时,使用泛型参数
*/
public class MyList<E>{public void add(E o){System.out.println("保存: " + o);}
}
根据上边的MyList类进行测试:
public class TestMyList {public static void main(String[] args) {// 使用时可以通过<> 为类型参数传入实参MyList<String> list = new MyList<>(); // 有黄线表示 不确定类型// 因为声明时 使用了泛型参数(实参),因此 add 方法的 传入参数要求必须跟泛型参数一致list.add("hello");//list.add(250); // 当参数与泛型参数不一致时,编译无法通过(失败)/**JDK 1.7 开始支持“菱形语法”: 等号之后可以不用写泛型参数,* 通过“感应”等号前声明的变量类型的泛型参数来确定*/MyList<Integer> numbers = new MyList<>();}
}
泛型方法
首先创建一个实体类:
public class Tank {private Integer id;private String name;// getter and setter
}
然后创建对应的测试类:
/**
* 可以在方法声明中,使用泛型参数
* 如果参数中使用了泛型,可以通过入参来确定泛型的具体类型
* 如果参数中,没有使用泛型,则可以通过声明“接收者”来确定返
回值的类型29
*/
public class Flighter {public static void main(String[] args) {Flighter f = new Flighter();String o = new String("hello");// 通过传入的实际参数确定了返回值的类型String s = f.attack(o);//这个地方如何确定传入的类型System.out.println(s);// 通过等号前声明的那个变量的类型确定被调用的泛型方法返回值的类型Tank t = f.create(999, "苏-890");// 不写 Tank 的时候,返回 Object ,写了 Tank 之后,返回 TankSystem.out.println(t.getName());}/*** 定义一个泛型方法(在返回类型和参数中使用泛型)* @param o 需要攻击的对象* @return 返回被攻击的对象<E> 表示传入到这个方法中的参数类型*/public <E> E attack(E o){System.out.println("向" + o +"发起进攻");return o;}/*** 定义一个泛型方法(在返回类型使用泛型、参数中没有使用)* 指定了泛型参数的上限,将来实际传入的泛型参数必须是某个类型的后代(可以是他自己)*/// 参看 LinkedList 中的 addAll 中的(Collection< ? extendsE>)就是说你可以是任意类型,但是必须继承 Epublic <T extends Tank> T create(int id, String name){// 在这里写一个泛型,但是最好是 Tank 的后代// 可能是 Tank 向子类类型转换(可能触发类型转换异常)T tank = ( T )new Tank(); // 这里要想 :多态:父类类型 引用指向子类类型对象,但是子类类型引用不能指向父类类型对象tank.setId(id);tank.setName(name);return tank ;// 非要造一个 tank 怎么办?}// 通过等号前声明的那个变量的类型确定被调用的泛型方法返回值的类型// 定义一个泛型方法(在返回类型使用泛型、参数中没有使用)// 返回值的类型需要通过声明接收变量来确定31// Tank t = f.create(999, "苏-890");/*public <E> E create(int id, String name){return null;}*/
}
简单来说, 可以通过在定义方法的时候指定泛型,让其作为参数或返回,这样的方法就可以定义为泛型方法。
迭代器
迭代器就相当于安检的那个机器,如果有下一个,就继续,发现违禁产品, remove,如果继续有下一个,就继续运转。 Collection 所有的后代都有 Iterator 这个方法。但是在输出的时候不建议使用toString。
/**
* 用迭代器迭代 Collection 集合
*/
public class TestIterator { // 迭代器public static void main(String[] args) {Collection<String> coll = new HashSet<>();// 无序的coll.add("孙悟空");34coll.add("白龙马");coll.add("猪悟能");coll.add("沙悟净");System.out.println( coll );// coll.toString():HashSet 重写了 toString 方法// 获得迭代器Iterator<String> itor = coll.iterator();// 迭代器的 hasNext 方法用来判断是否还有下一个元素需要处理while(itor.hasNext()){String string = itor.next(); // 如果有下一个元素需要处理,就获得它System.out.println(string);if( string.equals("白龙马")){itor.remove();// 删除当前的元素}}System.out.println(coll);}
}
foreach
foreach 循环,有人称之为(增强的 for 循环),但是这种说法不准 确,我们统一称之为 foreach 。
/*** 用 for-each 循环迭代 Collection 集合
* 除了数组,只有实现过 java.util.Iterable 接口的类型的对象,
才可以被 foreach 语句处理
*/
public class TestCollection3 {public static void main(String[] args) {Collection<String> coll = new HashSet<>();// 无序的coll.add("孙悟空");coll.add("白龙马");coll.add("猪悟能");coll.add("沙悟净");System.out.println( coll );// coll.toString();/*** foreach 语句的冒号之后那个变量对应的类型必须实现过 java.util.Iterable 接口* for( 类型 变量名 : Collection 或 数组){* // 通过变量名来访问集合或数组中的每个元素* }* 注意:冒号之前的变量类型必须由集合(数组)中的类型确定,冒号之后必须是 Collection 或数组*///JDK1.5+提供的 forEach 循环(也就是一些人所谓的 增强的 for 循环)for (String string : coll) {System.out.println(string);}Object[] array = coll.toArray();for (Object object : array) {System.out.println(object);}}
}
Collection体系

可以在这里看到, Collection接口中有三个主要分支,分别是java.util.Set、java.util.List、java.util.Queue三个主要分支。可以根据这幅图进行理解Collection体系。
java.util.Set
官方API声明如下:
public interface Set<E> extends Collection<E>
可以看到依旧是一个接口,但是直接继承了Collection接口,那么在使用的过程中依旧要使用子类来构建对应的对象。
官方API描述如下:
A collection that contains no duplicate elements. More formally, sets contain no pair of elements e1 and e2 such that e1.equals(e2), and at most one null element. As implied by its name, this interface models the mathematical set abstraction.
具体翻译如下:
不包含重复元素的集合。更正式的是,集不包含一对元素 e1 和 e2,因此 e1.equal(e2) 最多包含一个空元素。顾名思义,此接口对数学集抽象进行模型。
那么针对于这个描述来说,也就是说Set集合中是不允许有重复元素的,这点要注意。
java.util.Set 接口的特点:
Set 特点:
默认无序:放入元素时的顺序,跟集合中元素存放的顺序不同
不可重复:在 Set 集合中,任何一个元素都只能有一个(数学中的集)
可以有 null:在 Set 集合中,默认是可以有 null 元素的
因为Set接口是Collection的接口,那么具体的方法就不再描述,这里仅仅描述一下关于子类中的一些操作
java.util.HashSet
HashSet是满足 Set 所有特点的一个 Set 接口的实现类。那么就可以使用HashSet充当实现类,从而感受到Set 的特点。示例如下:
/**
* Set 集合的特点:无序、不重复、可以有 null
* 如果是 SortedSet,就是有顺序的
*/
public class TestSet {public static void main(String[] args) {// HashSet 内部存储数据用的是 HashMap(而 HashMap内部用数组存储数据)Set<String> set = new HashSet<>();boolean r = set.add("hello, world");System.out.println(r);r = set.add("hello, world");System.out.println(r); // false 表示放入失败,因为已经有这个元素存在System.out.println(set.size());set.add("google.xyz");// 放入的顺序 与 显示的顺序不同System.out.println(set) ; // set.toString : HashSet 类中重写了 toString 方法set.add(null);System.out.println(set);}
}
当然,如果想要知道HashSet内部的存储方式,那么就可以通过add方法的内部去查看。注意,当点击内部的时候,要采用HashSet的实现方式,然后可以发现内部使用了HashMap作为存储方式,并调用HashMap的方法,但是归根到底依旧是采用数组的方式进行存储。
注意:HashSet的实现是不同步的。(Note that this implementation is not synchronized.)
HashSet的构造方法
构造方法如下:
HashSet() : Constructs a new, empty set; the backing HashMap instance has default initial capacity (16) and load factor (0.75).构造一个新的空集;返回HashMap实例具有默认初始容量(16)和加载因子(0.75)。
HashSet(int initialCapacity)Constructs a new, empty set; the backing HashMap instance has the specified initial capacity and default load factor (0.75).构造一个新的空集;返回HashMap实例具有指定的初始容量和默认加载因子(0.75)。
HashSet(int initialCapacity, float loadFactor) : Constructs a new, empty set; the backing HashMap instance has the specified initial capacity and the specified load factor.构造一个新的空集;返回HashMap实例具有指定的初始容量和指定的加载因子。
HashSet(Collection<? extends E> c): Constructs a new set containing the elements in the specified collection.构造一个包含指定集合中元素的新集合。
示例如下:
/**
* HashSet 的构造方法
* HashSet() : 默认初始容量是 16,加载因子是 0.75
* HashSet( capacity ) : 初始容量是capacity,加载因子是0.75
* HashSet( capacity , loadFactor ) : 初始容量是 capacity,
加载因子是 loadFactor(是 float 类型)
* HashSet( Collection co ) : 将一个集合包装成一个 HashSet
*/
public class TestSet2 { // 我们添加的顺序 与 我们存储的顺序不同public static void main(String[] args) {// 注意 加载因子(loadFactor)是 float 类型Set<String> names = new HashSet<>(10,0.5f);names.add("hello"); // 按住 ctrl + 鼠标左键,进入到HashSet 的 add 方法,发现 HashSet 的本质是 HashMap,并且存储在数组中names.add("world");names.add("你");names.add("好");System.out.println(names); // [你, world, hello, 好]names.add("挺好 ");41System.out.println(names); // [你, 挺好 , world, hello,好]names.add("不好 ");names.add("还行");System.out.println(names); // [你, 挺好 , world, 还行,hello, 好, 不好 ]}
}
加载因子指的是什么时候进行扩容,扩容的方法可以进入到add方法中进行查看。
java.util.TreeSet
TreeSet 是 Set 的另一种实现类, TreeSet 继承了 SortedSet,而SortedSet 又继承了 Collection。具体继承体系如下:
Iterable--> Collection --> Set -->SortedSet ---> NavigableSet ---> TreeSet
首先简单说一下SortedSet,SortedSet进一步提供关于元素的总体排序的 Set,这些元素使用其“自然顺序”进行排序(java.lang.Comparable,自然顺序必须实现这个接口)或者根据通常在创建有序 Set 时提供的 Comparator进行排序(java.util.Comparator)。具体的信息可以去查看对应的API文档。
TreeSet的特点:
1、一定是有序集合(自然顺序 或 用比较器排序 )
2、元素不能重复
3、元素不能为 null
4、不是同步的(不是线程安全的)
示例如下:
public class TestTreeSetIsOrder {public static void main(String[] args) {TreeSet<String> ts = new TreeSet<>();ts.add(null);//测试能否存放 nullSystem.out.println( ts.add("孙悟空"));//是否有序System.out.println( ts.add("沙悟净"));System.out.println( ts.add("猪悟能"));System.out.println( ts );}
}
TreeSet 内部基于 TreeMap 存储数据,TreeMap 内部使用红黑树(Red-Black tree)存储数据
红黑树( Red-Black tree ) :是一种特殊的二叉树(数据结构)在某种情况下满足条件,那么就是红色的或者是黑色的。
示例如下:
public class TestTreeSet {public static void main(String[] args) {// numbers 是放在栈空间的// 真正的 TreeSet 对象 是放在堆空间中Set<Integer> numbers = new TreeSet<>();// 创建一个默认根据元素的自然顺序进行排序的有序 Set集合numbers.add(250);// 当向集合中添加元素时,就会触发排序(比较)System.out.println(numbers);// number.toStringnumbers.add(125);System.out.println(numbers);numbers.add(1234);System.out.println(numbers);numbers.add(1000);System.out.println(numbers);}
}
TreeSet 是有顺序的,但是在每次添加的时候都会进行一次比较,所以应用比较少一些。当数据量足够大的时候,会非常慢。
支持自然排序就是实现了 Comparable 这个接口,必须是实现了Comparable 的 compareTo 方法。所以排序的方式是由 compareTo方法实现的。
示例如下:
public class Panda implements Comparable<Panda> {private Integer id;private String name;private Date birthdate;// birthday 表示生日 ,出生年月日birthdateprivate char gender;@Overridepublic int compareTo(Panda anotherPanda) {// this.id - anotherPanda.id ; // this.id 是准确的,可能造成 anotherPanda 的 id 没有指定int r = 0;if (this.id != null && anotherPanda.id != null) {System.out.println("比较了");// this 小于 another :返回负数// this 等于 another :返回 0// this 大于 another :返回正数r = this.id - anotherPanda.id;}return -r; // 比较的顺序翻转过来,也就是倒序//return r;// 正常比较的结果}@Overridepublic String toString() {return "( " + id + ", name=" + name + " ) ";}// getter and setter
}
/**
* 在 TreeSet 中存放元素,并按照自然顺序进行排序
* 所谓自然顺序,就是指集合中存放的元素的类型 Panda 实现了Comparable 接口中的 compareTo 方法,
* 而这个 compareTo 方法决定了元素的顺序
*/
public class TestTreeSet {public static void main(String[] args) {Set<Panda> pandas = new TreeSet<>();Panda p1 = new Panda();p1.setId(999);p1.setName("阿宝");pandas.add(p1); // 在 Panda类中如果没有实现Comparable 接口,就会有 ClassCastException 类型转换异常System.out.println(pandas);Panda p2 = new Panda();p2.setId(888);p2.setName("师傅");pandas.add(p2);System.out.println(pandas);Panda p3 = new Panda();p3.setId(900);p3.setName("二师傅");pandas.add(p3);System.out.println(pandas);}
}
使用比较器进行比较
/**
* 因为 Eagle 没有实现 java.lang.Comparable 接口,因此 Eagle类型的对象,不支持自然排序
*/
public class Eagle {private Integer id;private String name;private double weight;47private Date birthdate;// 出生年月日// getter and setter
}
public class TestTreeSet2 {public static void main(String[] args) {final Calendar cal = Calendar.getInstance(); // 表示系统当前时刻// 通过匿名内部类来实现 Comparator接口(实现 compare方法)Comparator<Eagle> comparator = new Comparator<Eagle>(){@Overridepublic int compare(Eagle o1, Eagle o2) {/** if( o1 大于 o2 ){return 整数;}else if( o1 等于 o2){return 0;}else{return 负数;}48*/// 明确比较的东西double r = o1.getWeight() - o2.getWeight() ; //这是 double 类型的数据,但是结果要 int,// 不建议强制类型转换,容易有问题比如(6.0-5.5)return r == 0 ? 0 : ( r > 0 ? 1 : -1 ) ;}} ;/*** 对于不支持自然排序的元素组成的集合,可以通过创建set 时,提供的 Comparator 进行排序*/Set<Eagle> eagles = new TreeSet<>(comparator); // 比较器相当于天平Eagle e1 = new Eagle();e1.setId(1);e1.setName("Eagle-20");cal.set(1974, 8, 9);Date birthdate = cal.getTime();e1.setBirthdate(birthdate);e1.setWeight(6.0);49eagles.add(e1);Eagle e2 = new Eagle();e2.setId(2);e2.setName("Eagle-12");cal.set(1988, 8, 9);e2.setBirthdate(cal.getTime());e2.setWeight(5.9);eagles.add(e2);// 迭代集合Iterator<Eagle> iter = eagles.iterator();while(iter.hasNext()){Eagle e = iter.next();System.out.println(e.getId() + " , " + e.getName()+ " ," + e.getWeight());}}
}
java.util.List
声明如下:
public interface List<E> extends Collection<E>
描述如下:
An ordered collection (also known as a sequence). The user of this interface has precise control over where in the list each element is inserted. The user can access elements by their integer index (position in the list), and search for elements in the list.(有序的集合(也称为序列)。此接口的用户可以精确控制列表中每个元素的插入位置。用户可以按其整数索引(在列表中的位置)访问元素,并搜索列表中的元素)
List的特点:
I、 有序:1、元素放入的顺序几位 List 的存储顺序2、可以对 List 进行排序操作(自然顺序、比较器排序)3、因为是有顺序的,因此可以根据"索引"操作指定位置的元素
II、 可重复
III、 可以有 null
List 接口除了继承 Collection 接口的所有方法外,另外还有很多基于索引进行操作的方法。 实现了这几个接口: List , RandomAccess,Cloneable, Serializable, 其中 RandomAccess, Serializable 是标记接口,实现了 Cloneable 中的 clone 方法,但是这个方法继承于Object, 是 List 接口的数组版的实现(内部用数组存储数据)、Resizable-array (大小可变数组)不是说数组的长度可以变,而是说数组变量可以指向长度不同的数组。
因为List是接口,那么只能通过其子类进行构造对象,常用的子类有:ArrayList、Stack、LinkedList等。这就不再描述List中的方法,因为List继承了Collection接口,如果有什么特殊的方法可以进行查看官方API。
java.util.ArrayList
声明如下:
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, Serializable
描述如下:
Resizable-array implementation of the List interface. Implements all optional list operations, and permits all elements, including null. In addition to implementing the List interface, this class provides methods to manipulate the size of the array that is used internally to store the list. (This class is roughly equivalent to Vector, except that it is unsynchronized.).
翻译如下:
可调整列表接口的可调整大小数组实现。实现所有可选的列表操作,并允许所有元素,包括 null。除了实现 List 接口外,此类还提供操作内部用于存储列表的数组大小的方法。(此类大致等效于 Vector,只不过它是未同步的。)
示例如下:
/***
* 放入的顺序就是存放的顺序
* 通过索引在指定的位置进行添加元素
*/
public class TestArrayList {public static void main(String[] args) throws Exception{// Constructs an empty list with an initial capacity often.// 创建一个初始容量(DEFAULT_CAPACITY)是 10 的空的 list 对象List<String> list = new ArrayList<>();list.add("孙悟空"); // Collection 中就存在的方法list.add("沙悟净");list.add(1,"猪悟能"); // 在 1 处添加新元素System.out.println(list); // [孙悟空, 沙悟净, 猪悟能] // [孙悟空, 猪悟能, 沙悟净]list.set(1, "二师兄"); // 替换 1 处 的元素为新内容System.out.println(list); // [孙悟空, 二师兄, 沙悟净]System.out.println(list.size());}
}
在这里要说明的就是除了构造之外,依旧要会的就是对应的add方法的具体过程:
在 执 行 add 方 法 的 时 候 , 会 构 建 数 组 , 具 体 过 程 如 下 :
DEFAULT_CAPACITY = 10
Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}
List<String> list = new ArrayList()
this.elementData = EFAULTCAPACITY_EMPTY_ELEMENTDATA;list.add("孙悟空")做的事情:
ensureCapacityInternal(size + 1);// size 的默认值是 0
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {minCapacity = Math.max(DEFAULT_CAPACITY, 1); // 确定容量是 10
}
ensureExplicitCapacity(minCapacity);
// minCapacity (10) - 0 > 0
if (minCapacity - elementData.length > 0){grow(minCapacity);
}
newCapacity = minCapacity;
elementData = Arrays.copyOf(elementData, newCapacity);
elementData[size++] = e;// 先有 size,后++
ArrayList的构造方法
无参构造 : ArrayList() : this.elementData =DEFAULTCAPACITY_EMPTY_ELEMENTDATA; 什 么 也 没 有
做; 无参构造并没有为数组提供足够的空间来存放元素,而是等到第一次 add 时才通过 ensureCapacityInternal 来确保数组有足够空间存放元素ArrayList(int initialCapacity ) :this.elementData = new Object[initialCapacity];如果容量不够了,怎么办?找 ensureCapacityInternal
迭代 List 的几种方法
/***
* 遍历 List 集合:
* 1、 直接通过索引访问
* 2、通过 foreach 循环
* 3、通过 Iterator60
* 4、通过 ListIterator
*/
public class TestArrayList2 {public static void main(String[] args) throws Exception{List<String> list = new ArrayList<>();list.add("孙悟空"); // Collection 中就存在的方法list.add("沙悟净");list.add(1,"猪悟能"); // 在 1 处添加新元素list.add(0,"唐三藏");System.out.println(list);for (int i = 0; i < list.size(); i++) {String s = list.get(i); // 取出索引是 i 的元素System.out.println(s);}System.out.println("*********foreach*****************");// 迭代集合// list 的类型是 List, List 接口继承了 Collection ,Collection 继承了 Iterablefor (String s : list) {System.out.println(s);}System.out.println("*********iterator*****************");Iterator<String> itor = list.iterator();while(itor.hasNext()){String s = itor.next();System.out.println(s);}System.out.println("*********ListIterator*****************");ListIterator<String> listItor = list.listIterator();while(listItor.hasNext()){String s = listItor.next(); // 从前往后System.out.println(s);}System.out.println("从后往前");while (listItor.hasPrevious()) {String s = listItor.previous();System.out.println(s);}}
}
java.util.Vector
/**
* Vector 是线程安全的(形式上, Vector 的大部分方法都有
synchronized)
* ArrayList 不是线程安全的(形式上, ArrayList 的所有方法都
没有 synchronized)
*/
public class TestVector {public static void main(String[] args) throws Exception{List<String> vector = new Vector<>();vector.add("孙悟空"); // Collection 中就存在的方法vector.add("沙悟净");vector.add(1,"猪悟能"); // 在 1 处添加新元素vector.add(0,"唐三藏");System.out.println(vector);/**** 遍历 vector*/for (int i = 0; i < vector.size(); i++) {String s = vector.get(i);System.out.println(s);}}
}
ava.util.Stack
/**
* 测试栈的特点:后进先出
*/
public class TestStack {public static void main(String[] args) {Stack<String> stack = new Stack<>();// stack.add("猴子"); // add 可以放,但是不能模拟栈的特点stack.push("孙悟空"); // 向栈顶压入一个元素(入栈)System.out.println(stack);stack.push("猪悟能"); // 向栈顶压入元素System.out.println(stack); // [孙悟空, 猪悟能]String top = stack.peek(); // 检查栈顶元素(谁在栈顶就返回谁)System.out.println(top);System.out.println(stack);String lastIn = stack.pop() ; // 弹出栈顶元素(谁在顶部就弹出谁,出栈)System.out.println(lastIn);System.out.println(stack);}
}
队列
队列分为单端队列和双端队列。
单端队列
/**
* 单端队列
* 特点:先进先出(First In First Out)
*/
public class TestQueue {public static void main(String[] args) {Queue<String> queue = new LinkedList<>();queue.add("唐三藏") ; // 添加的时候是添加在队列的末尾System.out.println( queue );queue.add("孙悟空"); // 向队列尾部添加元素System.out.println( queue );queue.offer("白龙马");// 向队列尾部添加元素System.out.println( queue );// 检查队列的头部String head = queue.peek() ; // 只获取不删除 获取到队列的头System.out.println(head);System.out.println(queue);head = queue.element(); // 获取,不删除System.out.println(head);System.out.println(queue);head = queue.poll() ; // 删除队列的头,并返回;如果队列为空,则返回 nullSystem.out.println(head);head = queue.remove(); // 获取并移除掉 此列的头部System.out.println(head);System.out.println( queue);}
}
双端队列
/**
* 双端队列66
* 1、先进先出(First In First Out)
* 2、双端,两端都可以添加或删除元素
*/
public class TestDuque{public static void main(String[] args) {Deque<String> deque = new LinkedList<>();/*** 以 first 为头,以 last 为尾*/// 在其中的一端(last)加入元素deque.addLast("白龙马");deque.addLast("猪悟能");deque.addLast("沙悟净");System.out.println(deque);// 查看另一端(first)的“头部”元素String first = deque.peekFirst(); // 以first 为头,以last结尾System.out.println(first);// 获取并删除“头部”元素String head = deque.pollFirst();// deque.removeFirst();System.out.println(head);System.out.println(deque);/*** 以 first 为头,以 last 为尾*/// 在队尾添加元素deque.addFirst("孙悟空");System.out.println(deque);head = deque.peekLast(); // 查看队列头部的元素System.out.println(head);System.out.println(deque);head = deque.pollLast() ; // 获取并移除队头的元素System.out.println(head);System.out.println(deque);}
}
性能比较
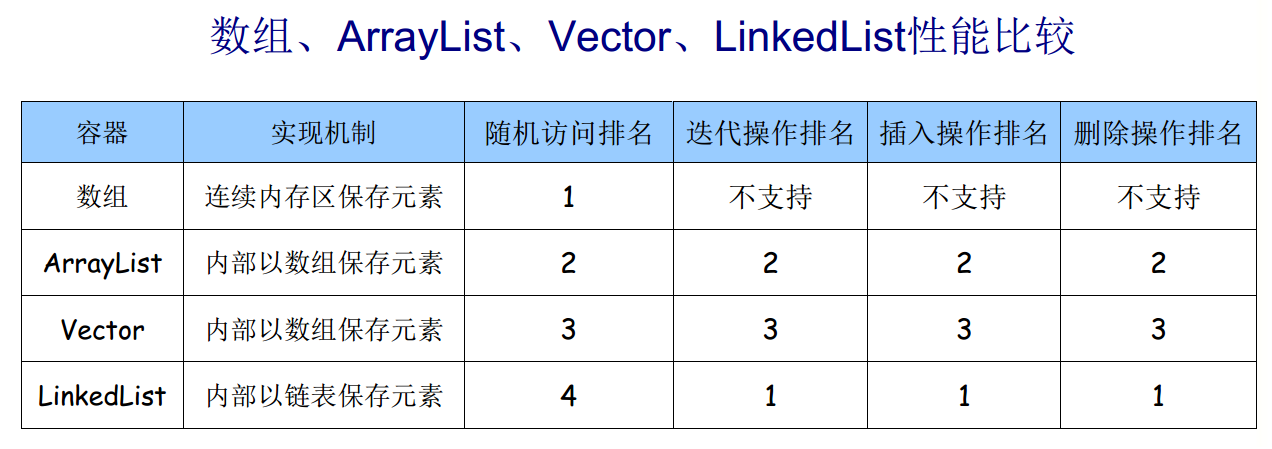
转载于:https://my.oschina.net/lujiapeng/blog/3090201
重新开始学Java——集合框架之Collection相关推荐
- Java集合框架之Collection集合
为什么80%的码农都做不了架构师?>>> 一.引言 Java集合框架和IO框架一样,看似很庞杂的体系框架,但是当你逐一深入每个集合的用法后,就能明显的看出他们之间的区别和联系. ...
- Java集合框架之Collection实例解析
转载自https://blog.csdn.net/qq_28261343/article/details/52614411 0.集合引入 1)集合的由来? Java是面向对象编程语言,经常操作很多对象 ...
- JavaSE入门学习34:Java集合框架之Collection接口、子接口及其实现类
一Collection接口 Collection接口定义了存取一组对象的方法,其子接口Set.List和Queen分别定义了存储方式. 使用Collection接口需要注意: 1Collection接 ...
- Java集合框架系列教程三:Collection接口
翻译自:The Collection Interface 一个集合表示一组对象.Collection接口被用来传递对象的集合,具有最强的通用性.例如,默认所有的集合实现都有一个构造器带有一个Colle ...
- Java 集合框架 : Collection、Map
1. Collection接口是Java集合框架的基本接口,所所有集合都继承该接口. 1.1 方法 : public interface Collection<E> extends Ite ...
- collection集合 多少钱_面试必备-Java集合框架
Java集合框架面试题 常见集合 集合可以看作是一种容器,用来存储对象信息. 数组和集合的区别: (1)数组长度不可变化而且无法保存具有映射关系的数据:集合类用于保存数量不确定的数据,以及保存具有映射 ...
- Java集合框架概述及Collection接口方法讲解
Java集合框架概述 一方面, 面向对象语言对事物的体现都是以对象的形式,为了方便对多个对象 的操作,就要对对象进行存储.另一方面,使用Array存储对象方面具有一些弊 端,而Java 集合就像一种容 ...
- Java集合框架之接口Collection源码分析
本文我们主要学习Java集合框架的根接口Collection,通过本文我们可以进一步了解Collection的属性及提供的方法.在介绍Collection接口之前我们不得不先学习一下Iterable, ...
- java集合框架的接口_Java集合框架之Collection接口详解
Java是一门面向对象的语言,那么我们写程序的时候最经常操作的便是对象了,为此,Java提供了一些专门用来处理对象的类库,这些类库的集合我们称之为集合框架.Java集合工具包位于Java.util包下 ...
最新文章
- BlockChain:Python一步一步实现(流程最清楚)区块链底层技术流程图(理解一目了然,值得收藏)
- 10个趣味的物理与化学动图欣赏,看过直称神奇!
- 为view设置虚线边框
- 室内定位之蓝牙定位精度(蓝牙AOA定位)
- Windows7安装无法识别硬盘分区
- 用python对《三国演义》的人物出场进行统计
- android修改渠道,Android 多渠道定制化打包
- Cura工程环境配置教程
- java if经典程序_java经典程序题15道(另附自己做的答案)
- CAD图纸如何转换成Word文档呢?
- 图神经网络中同质图与异质图等区别
- 2019春季学期总结
- Linux-less
- 使用BitLocker加密磁盘
- symbian模拟器的修正
- 【步态识别】MvGGAN 基于多视角步态生成对抗网络 算法学习《Multi-View Gait Image Generation for Cross-View Gait Recognition》
- sd卡数据怎么恢复?
- 用Linux一年来的体会
- 大电容并小电容的作用
- 那些“躲避”微软autoruns工具的方法